







本系列是想作为自己的学习笔记,作为入门有许多东西还是很初步的,得一步一步来了。
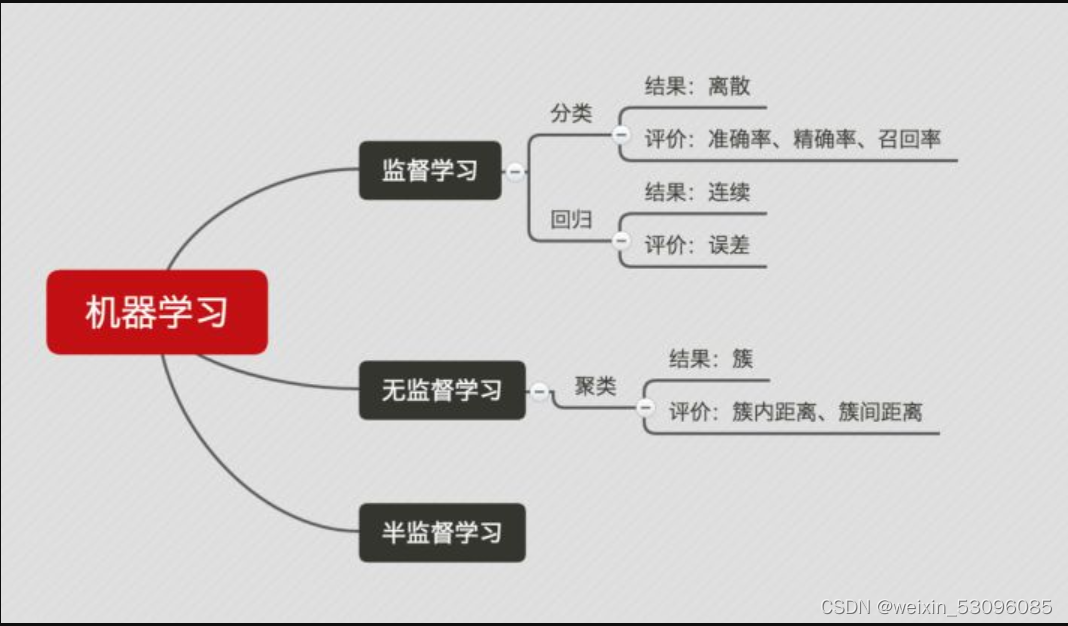
一、基础概念
`机器学习(Machine Learning,ML)` 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
1任务分类
监督学习:分类问题、回归问题
必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。关注对事物未知表现的预测
非监督学习:数据降维、聚类问题
在机器学习,无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案。数据没有类别信息,也不会给定目标值。倾向对事物本身特性的分析。
分类——离散的(知道有限个数量)回归——预测目标往往是连续变量
聚类——依赖数据的相似性,把相似数据样本划分为一个簇
评价是指评价其性能——好坏
正确率 —— 提取出的正确信息条数 / 提取出的信息条数
召回率 —— 提取出的正确信息条数 / 样本中的信息条数
F 值 —— 正确率 * 召回率 * 2 / (正确率 + 召回率)(F值即为正确率和召回率的调和平均值)
举个例子如下:
某池塘有 1400 条鲤鱼,300 只虾,300 只乌龟。现在以捕鲤鱼为目的。撒了一张网,逮住了 700 条鲤鱼,200 只虾, 100 只乌龟。那么这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70% 召回率 = 700 / 1400 = 50% F 值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
聚类问题的标准一般基于距离:簇内距离(Intra-cluster Distance) 和 簇间距离(Inter-cluster Distance) 。簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。一般的,衡量聚类问题会给出一个结合簇内距离和簇间距离的公式。
2机器学习专业术语
学习算法(learning algorithm):从数据中产生模型的方法
数据集(data set):一组记录的合集
示例(instance):对于某个对象的描述
样本(sample):也叫示例
属性(attribute):对象的某方面表现或特征
特征(feature):同属性
属性值(attribute value):属性上的取值
属性空间(attribute space):属性张成的空间
特征向量(feature vector):在属性空间里每个点对应一个坐标向量,把一个示例称作特征向量
维数(dimensionality):描述样本参数的个数(也就是空间是几维的)
分类(classification):预测是离散值,比如把人分为好人和坏人之类的学习任务
回归(regression):预测值是连续值,比如你的好人程度达到了0.9,0.6之类的
二分类(binary classification):只涉及两个类别的分类任务
正类(positive class):二分类里的一个
反类(negative class):二分类里的另外一个
多类分类:多个类别中选一个
多标签分类:判断一个样本是否属于多个不同类别
测试(testing):学习到模型之后对样本进行预测的过程
聚类(clustering):把训练集中的对象分为若干组
簇(cluster):每一个组叫簇
泛化(generalization)能力:学得的模型适用于新样本的能力
分布(distribution):样本空间的全体样本服从的一种规律
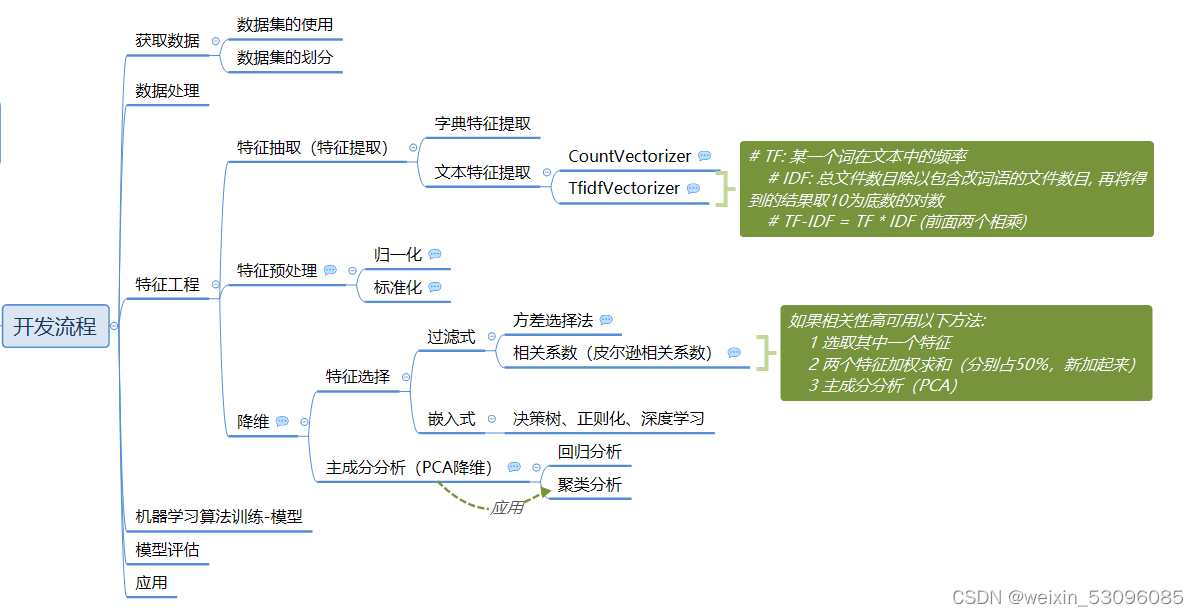
3机器学习流程

模型评估不正确后重新到获取数据循环
2.1数据集
用sklearn数据集

from sklearn.datasets import load_iris
def dataset_demo():
'''
sklearn 数据集的使用
'''
#获取数据集
iris = load_iris()
print("总数据集: \n",iris)
print("查看数据集描述: \n",iris["DESCR"])#字典用法1:用括号
print("查看特征值的名字: \n",iris.feature_names)#字典用法2:用.
print("查看特征值: \n",iris.data,iris.data.shape)
return None
if __name__=="__main__":
#数据集的使用
#dataset_demo()数据分为训练集(用于构建模型)和测试集(评估模型是否有效)
作用及整个流程如下图

代码如下
from sklearn.model_selection import train_test_split
def dataset_demo():
#数据集划分(有一部分来检验,评估模型是否有效)
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print("训练集的特征值:\n",x_train,x_train.shape)
return None
if __name__=="__main__":
#dataset_demo() 
2.2特征工程
特征工程是对特征所作的操作
将任意数据(如文本或图像)转化为可用于机器学习的数字特征
2.2.1特征抽取
- 字典特征提取
作用:对字典数据进行特征值化
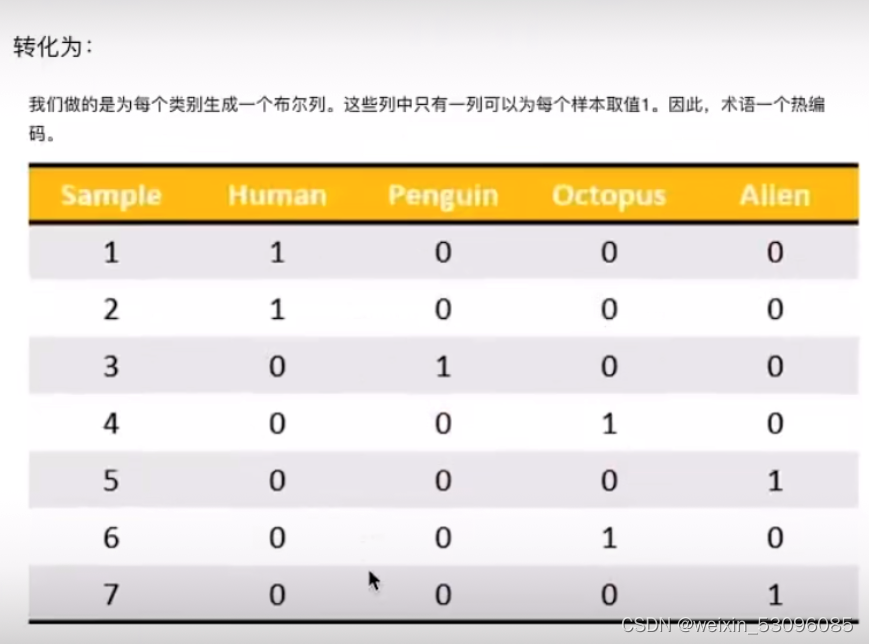
对数据进行特征提取:将类别转换为one-hot编码,节省内存,提高下载效率
one-hot编码的意思如下图所示:
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
'''字典特征抽取
'''
data=[{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]
#1.实例化一个转换器
transfer=DictVectorizer(sparse=False)#sparse为ture时为松散类型,不表示0
#2.调用fit_transform进行转换
data_new=transfer.fit_transform(data)
data_old=transfer.inverse_transform(data_new)#返回原来
print("data_new:\n",data_new)
print("data_old:\n",data_old)
print("特征名字:\n",transfer.get_feature_names())
return None应用场景:

- 文本抽取
作用:对文本数据进行特征值化
相关代码:
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import jieba
def count_demo():
'''文本特征抽取
统计每个样本特征词出现的个数
'''
#实例化
transfer=CountVectorizer(stop_word=["is","too"])
#文本里面没有设置参数转二维数组,则通过方法来转二维toarray
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new.toarray())
print("特征名字:\n",transfer.get_feature_names())
return None
def cut_word(text):
'''分词用jieba.cut 得到生成器
用list进行强转生成列表
我们要的是字符串所以用join
'''
a=" ".join(list(jieba.cut(text)))
print(a)
return text
def count_vector_jieba_Chinese(): # 中文自动分词
data = ["统计学作为数据分析的入门知识,非常的重要,作为入门,必须要掌握描述性统计以及里面各类图表的应用场景和理解。"
"而再深入到,如线性回归,贝叶斯,假设检验等,则是为以后成为高级数据分析师做铺垫,在未来做到建模和预测时,"
"会用到很多这类知识,同时在未来进阶过程中,学习机器学习的一些经典算法时,也需要这些知识来帮助理解和学习。",
"Excel作为数据分析的基础,是众多数据分析工具的入门工具,而且它的功能非常的强大,具有非常多的实用性,在快速处理一些数据,"
"快速出图的时候,非常的灵活,也非常的便捷,其中也有很多的函数,包括max,min,average,find,match,vlookup等,"
"可以非常灵活的查询数值或者进行统计分析,同时Excel的数据透视表功能也非常的强大,可以快速的选取所需元素进行分析。"
"非常适合用来做快速的数据清洗,入门门槛低,而且实用性非常强"]
new_data = []
for element in data:
sentence = cut_word(element)
new_data.append(sentence)
transfer = CountVectorizer(stop_words=[]) # 统计样本出现特征词的次数
data_new = transfer.fit_transform(new_data)
print("new data:\n", data_new.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def TF_IDF():
#一个词的重要性
# TF: 某一个词在文本中的频率
# IDF: 总文件数目除以包含改词语的文件数目, 再将得到的结果取10为底数的对数
# TF-IDF = TF * IDF (前面两个相乘)
data = ["统计学作为数据分析的入门知识,非常的重要,作为入门,必须要掌握描述性统计以及里面各类图表的应用场景和理解。"
"而再深入到,如线性回归,贝叶斯,假设检验等,则是为以后成为高级数据分析师做铺垫,在未来做到建模和预测时,"
"会用到很多这类知识,同时在未来进阶过程中,学习机器学习的一些经典算法时,也需要这些知识来帮助理解和学习。"
"非常适合用来做快速的数据清洗,入门门槛低,而且实用性非常强"]
new_data = []
for element in data:
sentence = cut_word(element)
new_data.append(sentence)
transfer = TfidfVectorizer(stop_words=["一些", "众多"])
data_new = transfer.fit_transform(new_data)
print("特征词:\n", transfer.get_feature_names())
print("new data:\n", data_new.toarray())
print("new data(sparse):\n", data_new)
return None对公式的解释:

2.2.2特征预处理
通过一些转换函数,将特征数据转换成更适合算法模型的特征数据的过程
无量纲化,也称为数据的规范化,是指不同指标之间由于存在量纲不同致其不具可比性,故首先需将指标进行无量纲化,消除量纲影响后再进行接下来的分析。
用到归一化和标准化进行无量纲化,使不同规格的数据转换到同一规格
- 归一化
通过对原始的数据进行变换把数据映射到(默认为[0,1]之间)

- 标准化
通过对原始数据进行变换把数据变换到均值为0,标准差为1的范围内
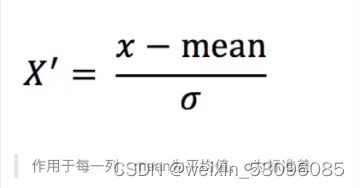
mean-平均值 为标准差 (为集中程度)
2.2.3降维
降维是为了降低特征的个数, 随机变量, 得到一组不相关的主变量的过程
特征选择分嵌入式(embeded)和过滤式(filter)
过滤式 :
1: 方差选择法 :低方差选择法 低方差代表某个特征大多样本的值比较相近则可以删掉
2: 相关系数(皮尔逊相关系数):特征与特征之间的相关程度强不强
如果相关性高可用以下方法:
1 选取其中一个特征
2 两个特征加权求和(分别占50%,新加起来)
3 主成分分析(PCA):高维数据变低维,舍弃原由数据,创造新数据,如: 压缩数据维数,降低原数据复杂度,尽量损失少量信息
应用:回归分析或者聚类分析
n_components=N:N为整数就是转为多少个特征 保留的至少都比原特征值少一个
N = 0.95 N为小数就是保留百分之多少的信息
嵌入式:决策树、正则化、深度学习
相关系数:
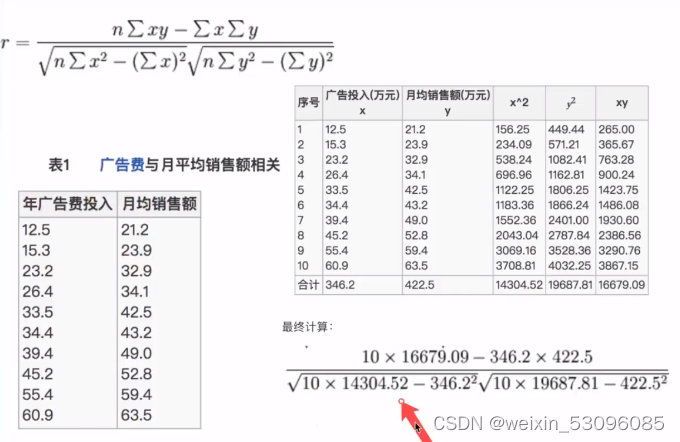

总结
我是跟着黑马学的,这里是黑马的文章连接:相关代码也在下面黑马程序员---三天快速入门Python机器学习(第一天)_zdb呀的博客-CSDN博客















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









