







你需要弄明白的问题:

1.回归算法
1.线性回归

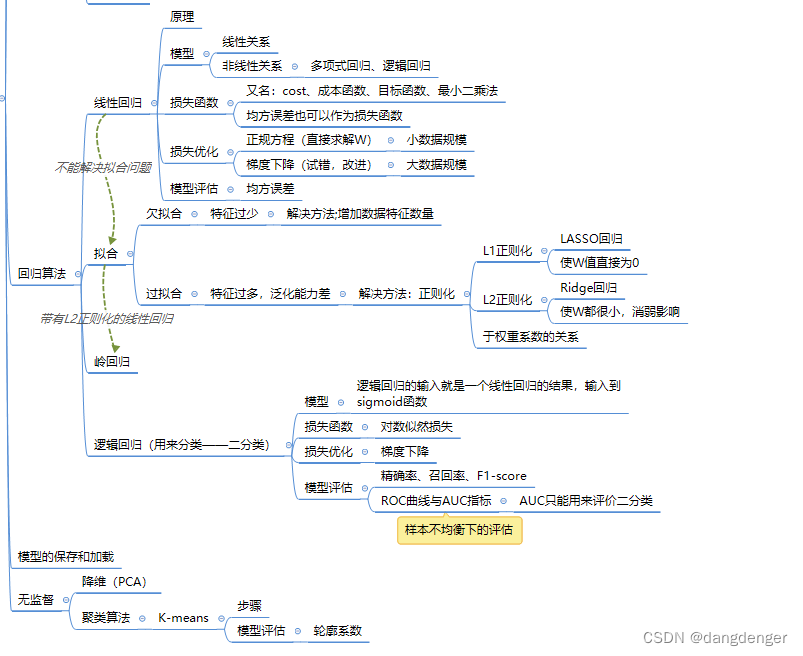
其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。
线性模型有两种:一种是线性关系,另一种是非线性关系。若曲线是一条直线,则为一元线性回归;若是超平面,则是多元线性回归;否则是非线性回归,常见的非线性回归包括多项式回归、逻辑回归。通过样本学习映射关系f:x->y,得到的预测结果y是连续值变量。
广义线性模型:
线性回归是用来预测的,存在偏差所以有损失函数
1.损失函数
损失函数又名:cost、成本函数、目标函数、最小二乘法
在模型中特征值和目标值都已知,我们要求模型参数它能够使得预测准确。

2.优化算法
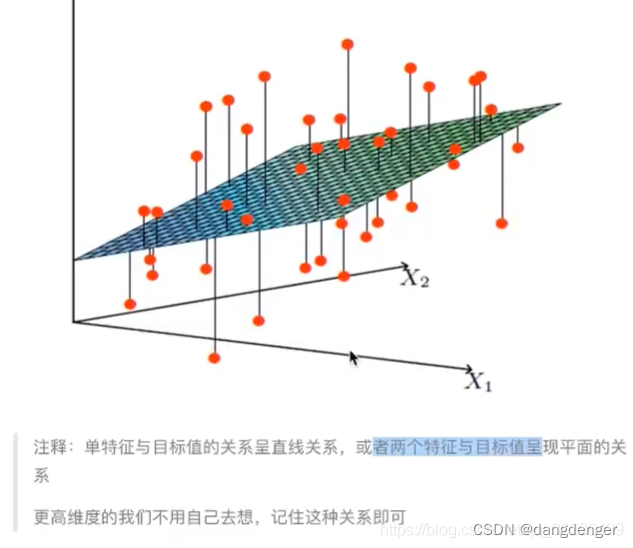
分为正规方程(直接求解W)和梯度下降(试错,改进)
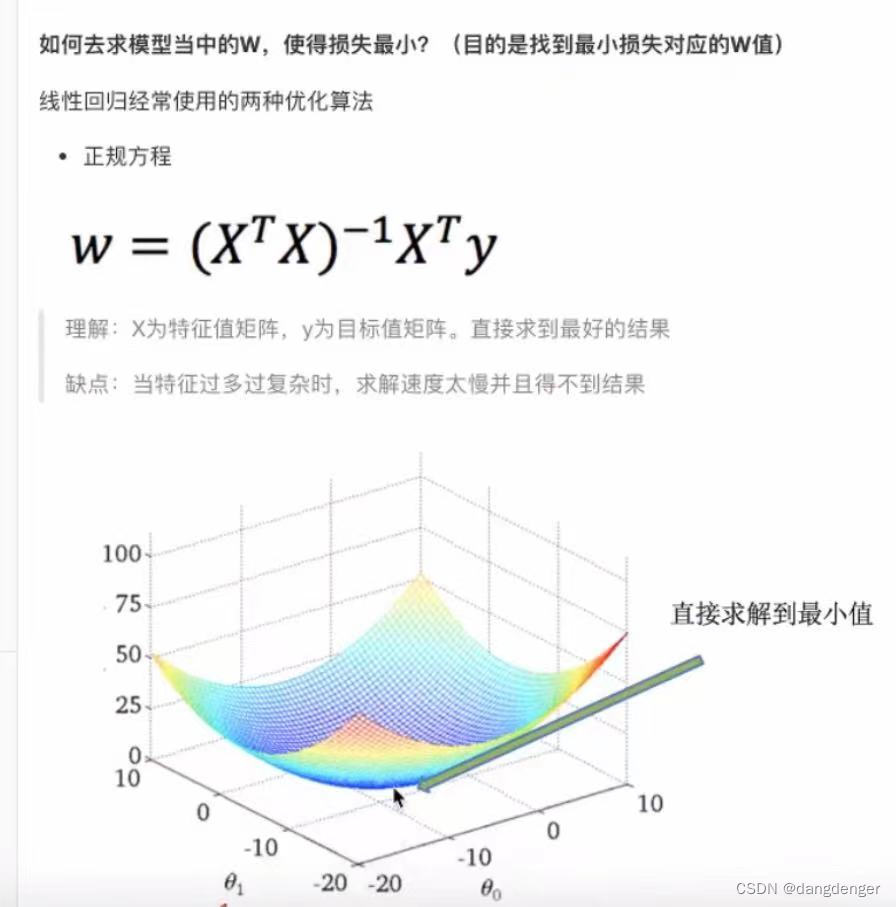
梯度下降: (迭代)

API:
正规方程:

梯度下降:
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate='invscaling', eta0=0.01

要对模型进行评估,和之前分类算法中的评估方法(1、直接比对真实值和预测值2、计算准确率)不一样,线性回归是均方误差(Mean Squared Error)(MSE)评价机制。
3.回归性能评估


线性回归不能解决拟合问题——拟合是什么?
2.欠拟合与过拟合
定义:

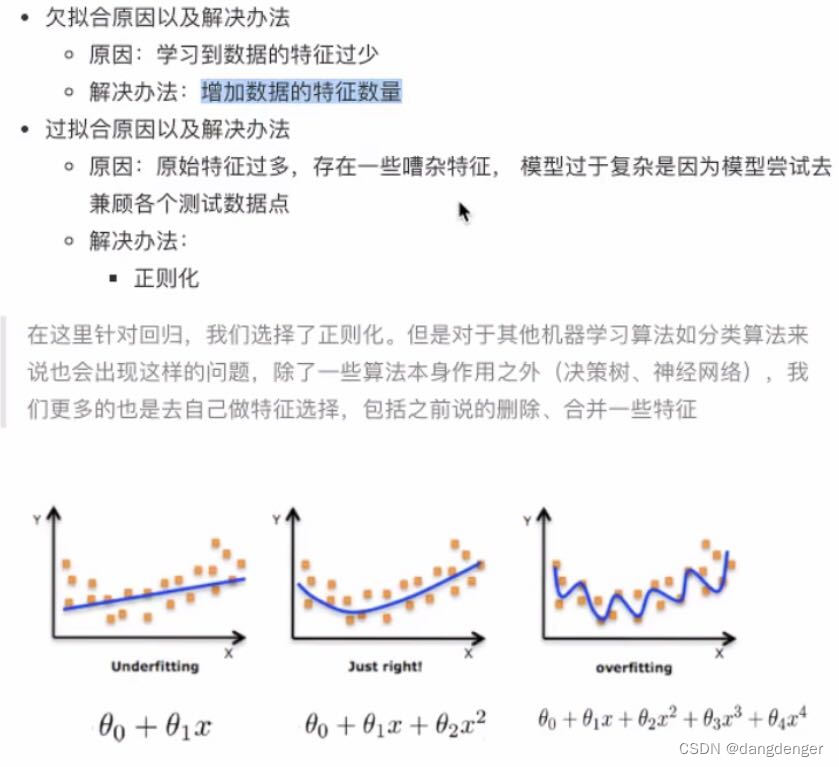
像图三在该训练集上是最吻合的可是把数据换成测试集,它还能和数据对应的那么贴合么?就是泛化能力差。
过拟合解决办法是正则化,正则化的类别分为L1正则化、L2正则化,更常用。
- 正则化


3.带有L2正则化的线性回归–岭回归
岭回归,其实也是一种线性回归。只不过在算法建立回归方程时候,加上正则化的限制,从而达到解决过拟合的效果
API:


正则化力度越大,权重系数会越小;正则化力度越小,权重系数越大
4.逻辑回归

- 逻辑回归的应用场景:

与线性回归的关系:
1.逻辑回归的输入就是一个线性回归的结果,输入到sigmoid函数
2.逻辑回归也有损失——对数似然损失;优化——梯度降低
总结:算法的思想流程和线性回归一样不过作用于分类

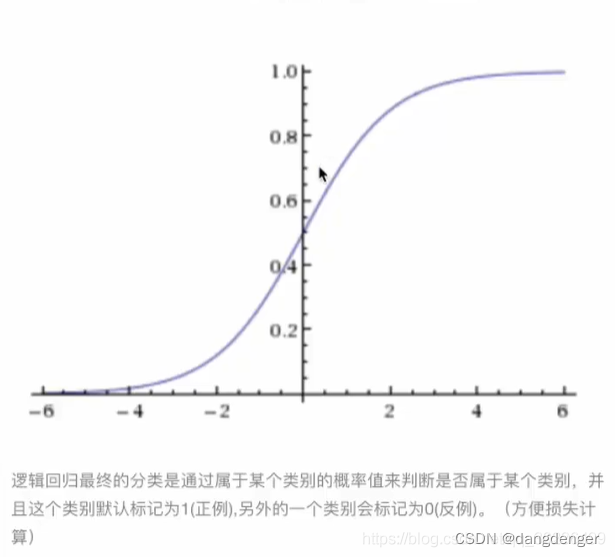
- 损失
线性回归损失函数是均方误差,(预测值—真实值)平方和/总数
但在逻辑回归中预测值和真实值是 是否属于某个类别 不是各种数据所以均方误差用的不贴合
引出:

- 优化:
同样使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率
API:

- 模型评估:
精确率、召回率、F1-score、ROC曲线与AUC指标



区分:
准确率:在总共100人下,预测癌症正确的概率
召回率:99的癌症样本下,全预测对了
精确率:在预测结果下(100个),真的得癌症
API:
在100人那个例子中,最后效果并不好因为样本不均衡,那么我们如何衡量样本不均衡下的评估?
用ROC曲线与AUC指标
5.ROC曲线与AUC指标
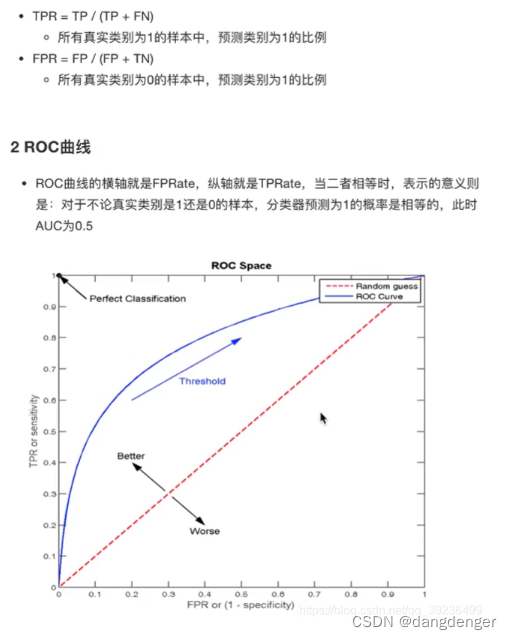

API:

- 总结:
1.AUC只能用来评价二分类
2.AUC非常适合评价样本在不平衡中的分类器性能
6.模型的保存和加载
API:
from sklearn.externals import joblib
joblib.dump(estimator,'test.pkl') #rf-预估器 序列化保存到本地
estimator = joblib.load('test.pkl')
#省去预估器流程 在别的内容中要加载时用estimator = joblib.load('test.pkl')2.无监督学习
没有目标值(无标签)—无监督学习
无监督学习算法:
聚类:K-means
降维:PCA
1.K-means算法(迭代)

API:

性能评估指标——轮廓系数:

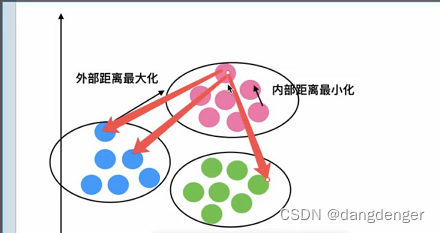
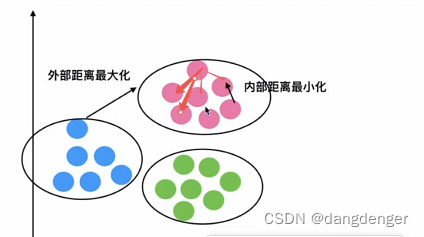

API:

总结;
特点分析:采用迭代式算法,直观易懂并且非常实用
缺点:容易收敛到局部最优解(多次聚类)
K-means算法用于第一次没有目标值的数据,然后形成模型+分类,下次遇到相似数据即可用K-means算法生成的模型直接分类。
跟着黑马程序员---三天快速入门Python机器学习(第三天)_zdb呀的博客-CSDN博客学的如有代码需求请看这篇文章。















 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









