







1 集合的概念
集合的作用是用来存储数据。
集合的分类:
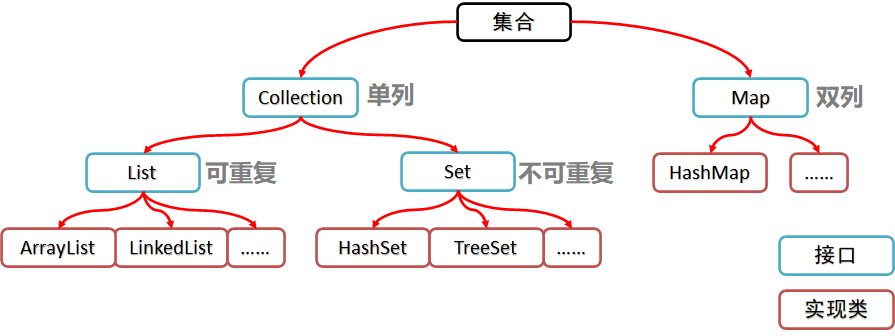
之前学习的数组也是用来存储数据的,可以对比学习:
1.1 数组的优缺点
-
优点
- 可以存储多个同类型的元素
- 存储地址连续
-
缺点
- 初始化后长度不可变
- 只能存储同种类型的数据
- 数组存储的元素时有限的
从操作的角度来说,数组的添加和删除效率低,查找的效率比较高(通过索引来获取元素)。
1.2 集合的特点
- 长度不限
- 只可以存储对象
- 元素可以是有序或无序
- 元素可以是单列也可以是由映射关系的双列
- 可以对存储在其中的元素进行比较
2 Collection(接口)
Collection 是集合的根接口,集合表示一组被称为其元素的对象。一些集合允许重复元素,而其他集合不允许。
- Collection 的常用方法:
| 返回值类型 | 方法 |
|---|---|
| boolean | add(Object e) 添加元素 |
| void | clear() 清空集合 |
| boolean | contains(Object o) 如果此集合包含指定的元素,则返回 true 。 |
| boolean | isEmpty() 如果此集合不包含元素,则返回 true 。 |
| boolean | remove(Object o) 从该集合中删除指定元素的单个实例(如果存在) |
| boolean | retainAll(Collection c) 仅保留此集合中包含在指定集合中的元素 |
| int | size() 返回此集合中的元素数。 |
| Object[] | toArray() 返回一个包含此集合中所有元素的数组。 |
实例:
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.ListIterator;
public class Test1 {
public static void main(String[] args) {
Collection c = new ArrayList();
//添加元素
c.add(123);
c.add('I');
c.add("Love");
c.add("java");
System.out.println("是否包含元素Love:" + c.contains("Love"));
System.out.println("判断集合是否为空:" + c.isEmpty());
//返回包含此集合中所有元素的数组
Object[] obj = c.toArray();
System.out.println("集合中元素:");
//遍历数组中元素
for(int i = 0 ; i < c.size() ; i++){
System.out.println(obj[i]);
}
System.out.println("-----------------");
System.out.println("删除元素123 : " + c.remove(123));
System.out.println("删除后集合中的元素数:" + c.size());
Object[] obj1 = c.toArray();
System.out.println("删除后集合中的元素:");
for(int i = 0 ; i < c.size() ;i++){
System.out.println(obj1[i]);
}
System.out.println("-----------------");
System.out.println("清空前集合中元素分数:" + c.size());
//清空集合
c.clear();
System.out.println("清空后集合中元素个数:" + c.size());
System.out.println("判断集合是否为空:" + c.isEmpty());
}
}
运行结果:
是否包含元素Love:true
判断集合是否为空:false
集合中元素:
123
I
Love
java
-----------------
删除元素123 : true
删除后集合中的元素数:3
删除后集合中的元素:
I
Love
java
-----------------
清空前集合中元素分数:3
清空后集合中元素个数:0
判断集合是否为空:true
- Collection 的高级方法
| 返回值类型 | 方法 |
|---|---|
| boolean | addAll(Collection c) 将指定集合中的所有元素添加到此集合。 |
| boolean | containsAll(Collection c) 如果此集合包含指定 集合中的所有元素,则返回true。 |
| boolean | removeAll(Collection<?> c) 删除指定集合中包含的所有此集合的元素。 |
| boolean | retainAll(Collection<?> c) 仅保留此集合中包含在指定集合中的元素。 |
实例:
import java.util.ArrayList;
import java.util.Collection;
public class test2{
public static void main(String[] args) {
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
c1.add(1);
c1.add(2);
c1.add("demo");
c2.add(1);
c2.add(2);
c2.add("java");
//判断集合c2中是否包含c1中的所有元素
boolean a = c2.containsAll(c1);
System.out.println("集合c2中是否包含c1中的所有元素:" + a);
//将c2中的元素添加到c1中,c2中的元素不受影响
c1.addAll(c2);
System.out.println("c2添加到c1,集合c1中的元素:");
Object[] obj = c1.toArray();
for(int i = 0 ; i < c1.size() ; i++){
System.out.println(obj[i]);
}
boolean b = c1.removeAll(c2);
System.out.println("从c1中删除包含c2的元素,集合c1中的元素:");
Object[] obj1 = c1.toArray();
for(int i = 0 ; i < c1.size() ; i++){
System.out.println(obj1[i]);
}
//c1重新赋值
c1.add(1);
c1.add(2);
c1.add("demo");
boolean c = c1.retainAll(c2);
System.out.println("仅保留c1与c2中都有的元素,集合c1中的元素:");
Object[] obj2 = c1.toArray();
for(int i = 0 ; i < c1.size() ; i++){
System.out.println(obj2[i]);
}
}
}
运行结果:
集合c2中是否包含c1中的所有元素:false
c2添加到c1,集合c1中的元素:
1
2
demo
1
2
java
从c1中删除包含c2的元素,集合c1中的元素:
demo
仅保留c1与c2中都有的元素,集合c1中的元素:
1
2
- 迭代器
| 返回值类型 | 方法 |
|---|---|
| Iterator | iterator() 返回此集合中的元素的迭代器。指的是对集合元素的遍历 |
| boolean | hasNext() 如果迭代具有更多元素,则返回 true 。 |
| E | next() 返回迭代中的下一个元素。 |
| default void | remove() 从底层集合中删除此迭代器返回的最后一个元素(可选操作)。 |
实现:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class test4 {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add("java");
c.add("spring");
c.add("super");
//使用while循环迭代
Iterator iter = c.iterator();
while(iter.hasNext()){
Object obj = iter.next();
System.out.println(obj);
}
}
}
运行结果:
java
spring
super
注:在while循环中,不能通过集合对象修改集合的元素
迭代器图示:

- 使用Collection保存自定义对象
实现:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class StudentsDemo {
public static void main(String[] args) {
Collection collection = new ArrayList();
Student st1 = new Student("小明",18);
Student st2 = new Student("小红",20);
collection.add(st1);
collection.add(st2);
Iterator iter = collection.iterator();
while(iter.hasNext()){
Object obj = iter.next();
System.out.println(obj);
}
}
}
运行结果:
Student{name='小明', age=18}
Student{name='小红', age=20}
3 List(有序集合)
有序集合也称为序列,该界面的用户可以精确控制列表中每个元素的插入位置。用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。
3.1 List 的特点
- 元素是有序的
- 列表通常允许重复的元素
3.2 List 方法
| 返回值类型 | 方法 |
|---|---|
| void | add(int index, E element) 将指定的元素插入此列表中的指定位置(可选操作)。 |
| boolean | addAll(int index, Collection<? extends E> c) 将指定集合中的所有元素插入到此列表中的指定位置(可选操作)。 |
| E | get(int index) 返回此列表中指定位置的元素。 |
| int | indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。 |
| int | lastIndexOf(Object o) 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。 |
| ListIterator< E > | listIterator() 返回列表中的列表迭代器(按适当的顺序)。 |
| ListIterator< E > | listIterator(int index) 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。 |
| ListIterator< E > | listIterator() 返回列表中的列表迭代器(按适当的顺序)。 |
| ListIterator< E > | listIterator(int index) 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。 |
| E | set(int index, E element) 用指定的元素(可选操作)替换此列表中指定位置的元素。 |
| List< E > | subList(int fromIndex, int toIndex) 返回此列表中指定的 fromIndex (含)和 toIndex之间的视图。 |
3.3 实例
实例一:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class ListDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add(6);
list.add(null); //可存储null
list.add("java");
list.add(6); //元素可重复
list.add(2,"test"); //在2号位置添加元素
list.set(1,'I'); //修改指定位置的元素
System.out.println("list中的元素:");
for(int i = 0 ; i < list.size() ; i++){
System.out.println(list.get(i)); //get(i)返回此列表中指定位置的元素
}
System.out.println("元素6第一次出现的位置:" + list.indexOf(6));
System.out.println("元素6最后一次出现的位置:" + list.lastIndexOf(6));
//输出指定位置片段的元素
List list1 = list.subList(1,5); //区间为左闭右开
//迭代器迭代
Iterator iter = list1.iterator();
System.out.println("-----截取片段输出-----");
while(iter.hasNext()){
Object obj = iter.next();
System.out.println(obj);
}
ListIterator listIterator = list.listIterator();
System.out.println("-----正序输出-----");
while(listIterator.hasNext()){
Object obj = listIterator.next();
System.out.println(obj);
}
System.out.println("-----倒序输出-----");
while(listIterator.hasPrevious()){
Object obj = listIterator.previous();
System.out.println(obj);
}
}
}
运行结果:
list中的元素:
6
I
test
java
6
元素6第一次出现的位置:0
元素6最后一次出现的位置:4
-----截取片段输出-----
I
test
java
6
-----正序输出-----
6
I
test
java
6
-----倒序输出-----
6
java
test
I
6
| ListIterator | listIterator() 返回列表中的列表迭代器(按适当的顺序)。 |
|---|
listIterator方法可以按适当的顺序迭代集合中的元素,就是说可以逆序输出。但是在逆序迭代前要先正序迭代,使指针位于最后一个元素。
实例二:
import java.util.ArrayList;
import java.util.List;
public class ListDemo1 {
public static void main(String[] args) {
List list = new ArrayList();
list.add("java");
list.add("Spring");
list.add("Summer");
list.add("Day");
for(int i = 0 ; i < list.size() ; i++){
if(i == 2){
list.add("Hello");
list.set(2 , "World");
}
System.out.println(list.get(i));
}
}
}
运行结果:
java
Spring
World
Day
Hello
使用普通for循环,可以在循环过程中修改增加元素,所以可用普通for循环解决并发修改异常;同时也能说明增强for循环的底层是迭代器。
3.4 ArrayList (底层实现:数组)
可调整大小的数组的实现List接口。 实现所有可选列表操作,并允许所有元素,包括null 。
除了实现List 接口之外,该类还提供了一些方法来操纵内部使用的存储列表的数组的大小。 (这个类大致相当于Vector,不同之处在于它是不同步的)。
是非线程安全的
源码分析:
- 数组默认容量为10
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10; //数组默认容量为10
- 容量增长方式
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //容量
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
- 添加方式
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length) //判断数组的长度是否等于元素个数
elementData = grow(); //进行扩容
elementData[s] = e; //将元素存入数组
size = s + 1; //修改size的值
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
- 扩容机制
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
} //使用数组的工具类中提供的数组拷贝的方法
private Object[] grow() {
return grow(size + 1);
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
//扩容方法
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //新数组的长度=old + old/2
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
实例(遍历的三种方式):
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ArrayListDemo {
public static void main(String[] args) {
List list = new ArrayList();
Student st1 = new Student("小明" , 18);
Student st2 = new Student("小红" , 20);
Student st3 = new Student("小黑" , 19);
list.add(st1);
list.add(st2);
list.add(st3);
//for循环遍历
System.out.println("普通for循环:");
for(int i = 0 ; i < list.size() ; i++){
Object obj = list.get(i);
System.out.println(obj);
}
//增强for循环
System.out.println("增强for循环:");
for(Object obj : list){
System.out.println(obj);
}
//使用迭代器
System.out.println("迭代器迭代:");
Iterator iter = list.iterator();
while(iter.hasNext()){
Object obj = iter.next();
System.out.println(obj);
}
}
}
3.5 Vector
Vector类实现了可扩展的对象数组,它是同步的。
是线程安全的
源码分析:
Vector的默认容量为10
public Vector() {
this(10);
}
3.6 LinkedList (底层实现:双向链表)
双链表实现,并允许所有元素(包括null ) ,此实现不同步。
源码分析:
- 底层是双向链表
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
- 添加元素
public void addFirst(E e) {
linkFirst(e);
} //头插法
/**
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to {@link #add}.
*
* @param e the element to add
*/
public void addLast(E e) {
linkLast(e);
} //尾插法
- 头插法的实现:
private void linkFirst(E e) {
final Node<E> f = first; //获取原链表的头节点
final Node<E> newNode = new Node<>(null, e, f); //构建一个新的头节点
first = newNode; //指定新的头节点为新节点
if (f == null) //判读原来链表是否为空
last = newNode; //此时的链表中只有一个节点
else
f.prev = newNode; //让原来的头节点的前驱指向新节点
size++; //链表元素个数加1
modCount++;
}
- 尾插法的实现:
void linkLast(E e) {
final Node<E> l = last; //获取尾节点的地址
final Node<E> newNode = new Node<>(l, e, null); //构建一个新的节点
last = newNode; //让原来的尾节点指向新节点,新节点称为新的尾节点
if (l == null)
first = newNode; //此时链表为空,让新节点成为头节点
else
l.next = newNode; //让新节点成为原尾节点的后继节点
size++;
modCount++;
}
默认采用尾插法:
import java.util.*;
public class ArrayListDemo {
public static void main(String[] args) {
LinkedList list = new LinkedList();
Student st1 = new Student("小明" , 18);
Student st2 = new Student("小红" , 20);
Student st3 = new Student("小黑" , 19);
list.add(st1);
list.add(st2);
list.add(st3);
//使用迭代器
System.out.println("迭代器迭代:");
Iterator iter = list.iterator();
while(iter.hasNext()){
Object obj = iter.next();
System.out.println(obj);
}
System.out.println("---------------");
Object first = list.getFirst(); //获取头节点
System.out.println(first);
Object last = list.getLast(); //获取尾节点
System.out.println(last);
}
}
3.7 Vector、ArrayList与LinkedList的区别
- Vector 和 ArrayList 的使用场景
- 在多线程的环境中使用Vector
- 在不需要保证数据同步的时候,优先使用ArrayList
- 因为Vector的效率比ArrayList低,在开发中一般都使用ArrayList
- ArrayList 和 LinkedList 的使用场景
- 如果数据查询的频率高, 而删除和插入的频率低,则使用ArrayList,ArrayList 的内部实现是基于基础的对象数组的,因此,使用get方法访问列表中的任意一个元素时,速度比LinkedList快;LinkedList 中的 get 方法是按照顺序从列表的一端开始检查,直到另一端。
- 如果查询的频率低,而删除和插入的频率高,则使用LinkedList
ArrayList 使用一个内置的数组来存储元素,初始容量为10 ,按1.5倍增长;它的空间浪费主要体现在 list 列表的结尾预留一定的容量空间。
对 ArrayList 与 LinkedList 而言,在列表末尾增加一个元素的开销是固定的;对ArrayList 而言,在内部数组中添加一项,指向所添加的元素,偶尔可能会导致对数组进行重新分配;而对 LinkedList 而言,开销的统一的,都是分配一个内部 Entry 对象
4 Set 集合的典型实现
Set接口的常用方法:使用同Collection
Set接口的常见实现:HashSet TreeSet LinkedHashSet
4.1 Set
- 特点:
- 元素是不能重复的 (只能有一个null,判断元素是否重复的标准:equals)
- 元素是无序的
- 实例(无序性)
import java.util.HashSet;
import java.util.Set;
public class ArrayListDemo {
public static void main(String[] args) {
Set set = new HashSet();
set.add("Java");
set.add("is");
set.add("a");
set.add("language");
for(Object obj : set){
System.out.println(obj);
}
}
}
Java
a
is
language
4.2 HashSet (使用hash表实现)
-
特点
- 底层数据结构的实现:哈希表
- 线程不同步
- 不保证元素的迭代顺序和存入顺序一致
- 元素不能重复(hashCode与equals)
-
哈希值:是jdk根据对象的地址或者字符串或数字计算得出的 int 类型的数值。
获取对象的哈希值的方法:Object 提供
哈希值的特点:
- 同一对象多次获取的 hashCode 值总是相同的
- 不同对象的 hashCode 值肯定是不同的
- 在自定义类中,需要重写 hashCode 方法,来保证每一个对象的 hash 值是独有的
- HashCode 的底层是借助于 HashMap(hash表) 实现
HashCode 的初始容量是16,默认的负载因子是0.75
源码:
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
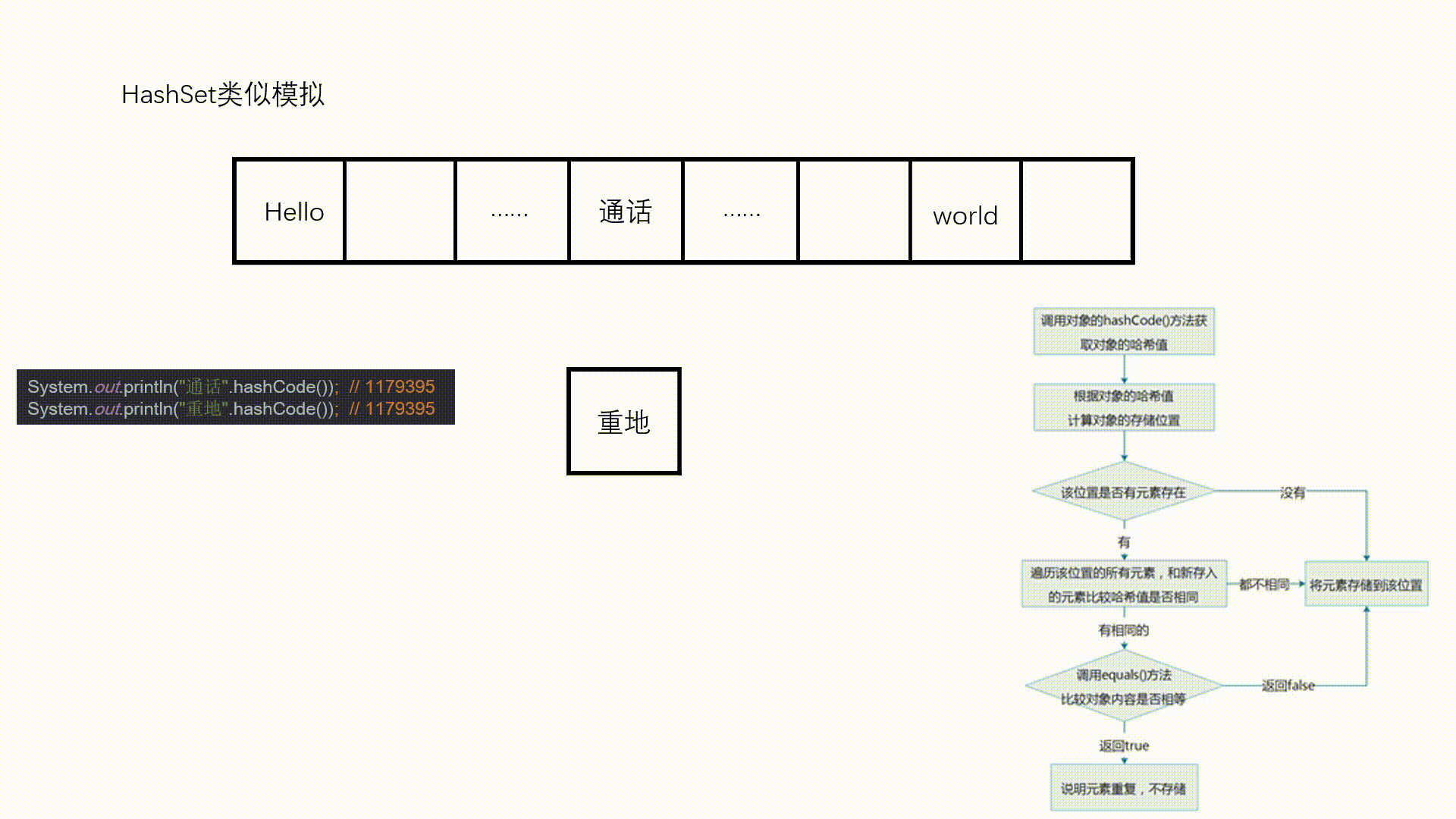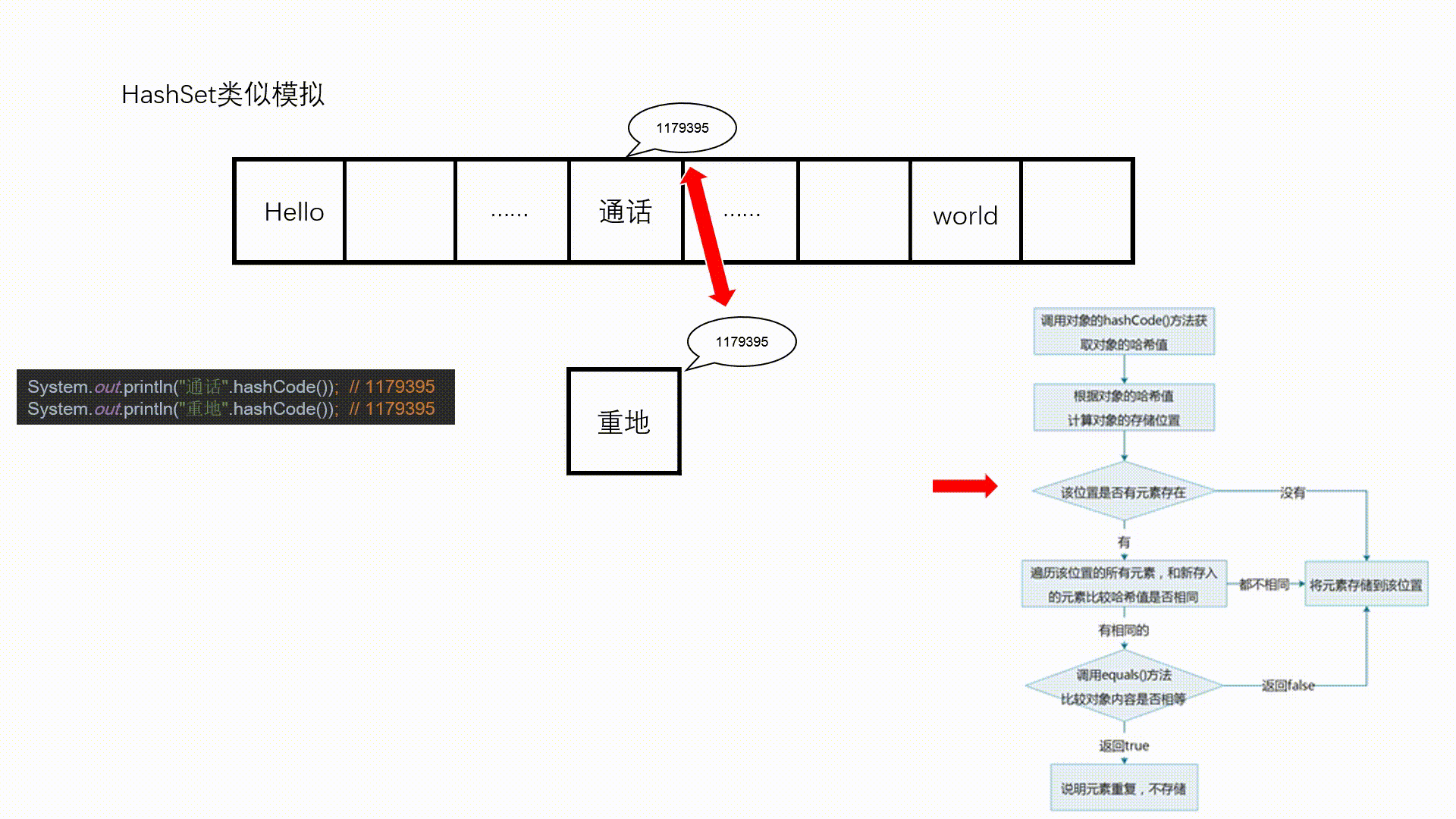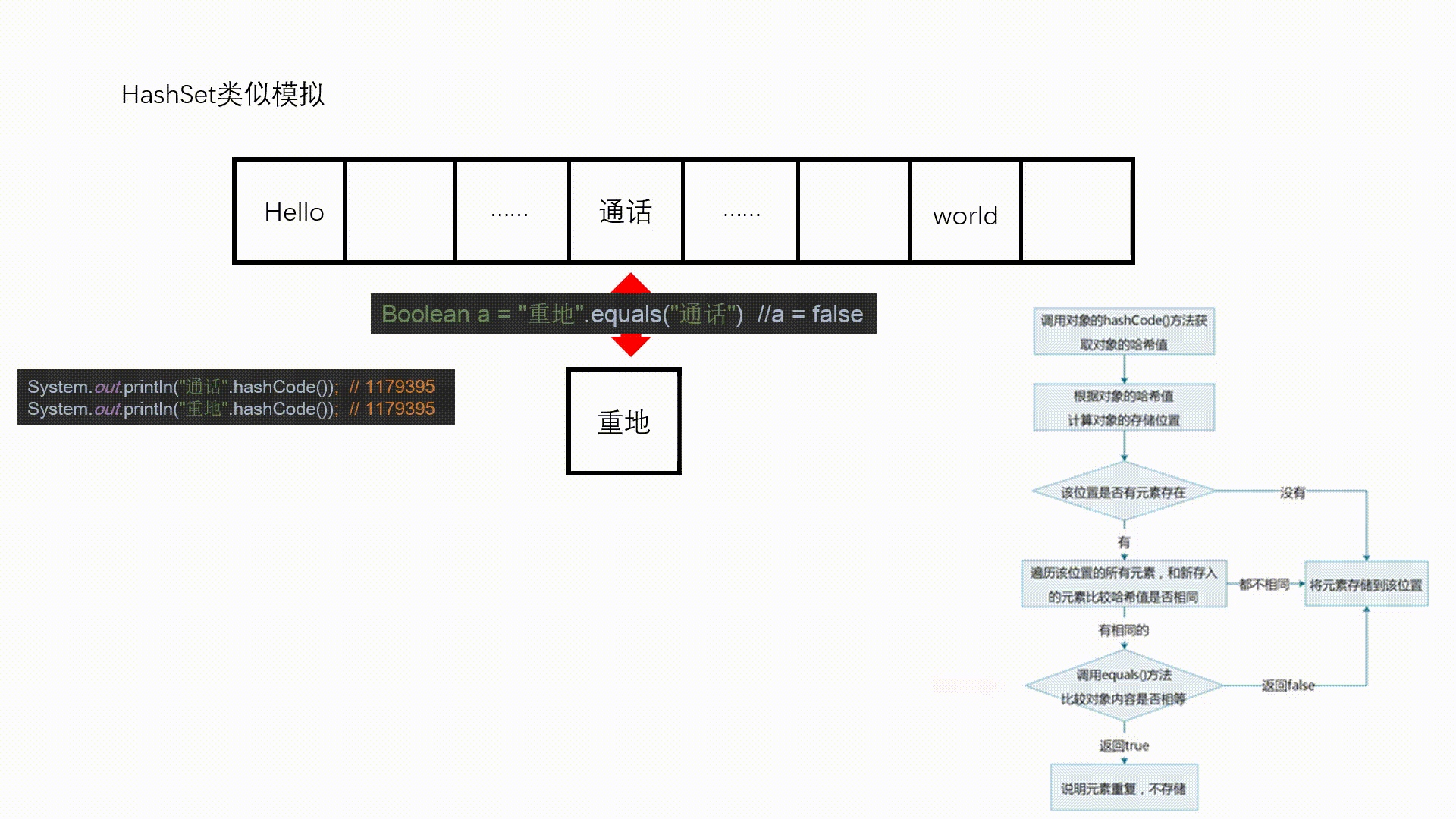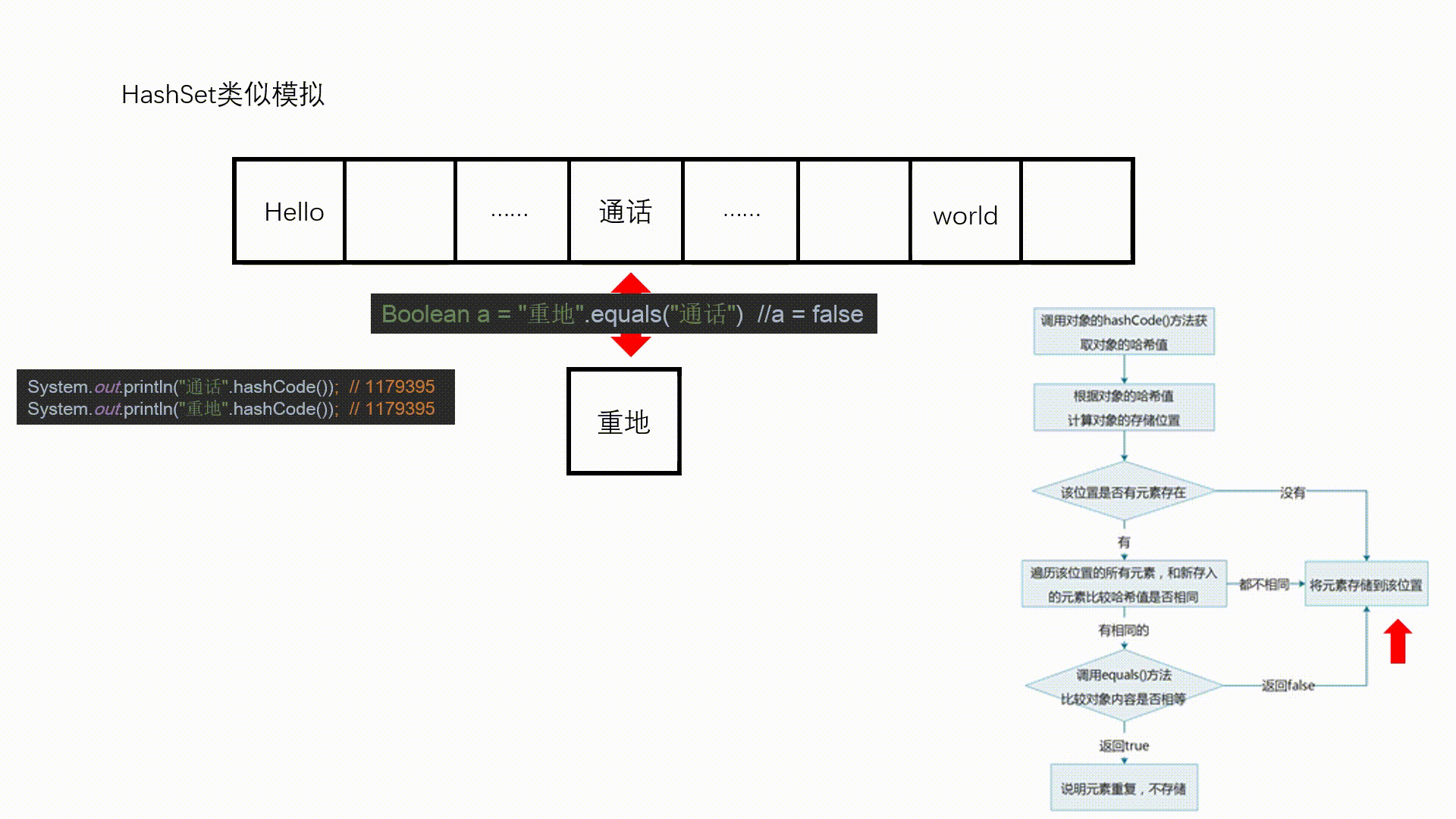
- HashSet 是如何保证元素是不可重复的
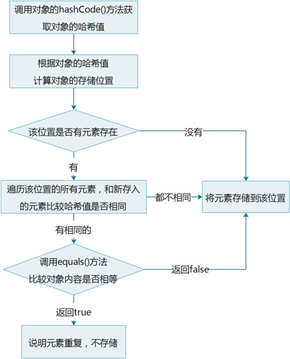
- 存储在hashSet 中的对象,在hashSet 中具体的存储位置是由对象的 hashSet 值计算所得
- 判断元素是否重复:hashSet 值相同且 equals 方法返回 true , 此时才会认定这两个对象重复
图示:
- 实例
import java.util.*;
public class ArrayListDemo {
public static void main(String[] args) {
Student st1 = new Student("小明" , 18);
Student st2 = new Student("小红" , 20);
Student st3 = new Student("小黑" , 19);
System.out.println(st1.hashCode());
System.out.println(st2.hashCode());
System.out.println(st3.hashCode());
System.out.println("Hello".hashCode());
System.out.println("World".hashCode());
//特殊情况,有可能不同的对象返回相同的hashCode值
System.out.println("重地 = " + "重地".hashCode());
System.out.println("通话 = " + "通话".hashCode());
//不同对象的equals返回false,但是它们的hashCode值可能相同
System.out.println("重地".equals("通话"));
}
}
运行结果:
23458772
23653826
23909234
69609650
83766130
重地 = 1179395
通话 = 1179395
false
- 实例
需求:获取10个1~20的随机数,要求随机数不能重复
思路:hashSet中的元素不能重复,所以可以控制其size来实现
实现:
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
//获取10个1~20的随机数,随机数不能重复
public class SetDemo_1 {
public static void main(String[] args) {
//使用set集合
Set set = new HashSet();
Random random = new Random();
while(set.size() < 10){ //判断集合中元素个数
int randnumber = random.nextInt(20);
//将随机数保存到集合中
set.add(randnumber);
}
for(Object obj : set){
System.out.print(obj + " ");
}
}
}
运行结果:
1 2 18 3 5 7 8 9 10 11
4.3 TreeSet(基于TreeMap实现)
TreeSet 中的元素是有序的。此时的有序是指元素的顺序是字典顺序,元素不可重复。
实现:
public class TreeSetDemo_1 {
public static void main(String[] args) {
TreeSet set = new TreeSet();
set.add(20);
set.add(50);
set.add(10);
set.add(80);
set.add(30);
for(Object obj : set){
System.out.println(obj);
}
}
}
运行结果:
10
20
30
50
80
TreeSet 存储自定义对象
4.3.1 自然排序
- 自定义对象需要实现 Comparable 接口,此处体现的是接口的多态
- 凡是存入到 TreeSet 集合中的对象,都需要实现排序接口
- Comparable 接口,并实现其中的 compareTo() 方法。
| TreeSet() | 构造一个新的,空的树组,根据其元素的自然排序进行排序。 |
|---|
实例:
学生的属性有姓名与年龄,将姓名与年龄按以下要求排序:
如果字符串是英文,则是按照字典顺序进行排序。
如果是中文,则是按照中文的UniCode码进行排序。
在排序中,如果是中文,如果第一个字相同,则按照第二个字进行排序。
如果是英文,如果第一个字母相同,则按照第二个字母排序。
(1)按年龄排序
实现:
public class Student implements Comparable{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Object o) {
Student st = (Student)o; //强制类型转换
int age1 = this.getAge();
int age2 = st.getAge();
return age1 - age2;
}
}
public class ComparableDemo {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
Student st1 = new Student("Jone" , 21);
Student st2 = new Student("Amy" , 20);
Student st3 = new Student("Mike" , 18);
Student st4 = new Student("Yom" , 19);
treeSet.add(st1);
treeSet.add(st2);
treeSet.add(st3);
treeSet.add(st4);
//增强for循环
for(Object obj : treeSet){
System.out.println(obj);
}
}
}
运行结果:
Student{name='Mike', age=18}
Student{name='Yom', age=19}
Student{name='Amy', age=20}
Student{name='Jone', age=21}
结果可见为按年龄排序
(2)按姓名排序
实现
//其余代码与上述按姓名排序代码相同
@Override
public int compareTo(Object o) {
Student st = (Student)o; //强制类型转换
String name1 = this.getName();
String name2 = st.getName();
return name1.compareTo(name2);
}
运行结果:
Student{name='Amy', age=20}
Student{name='Jone', age=21}
Student{name='Mike', age=18}
Student{name='Yom', age=19}
(3)优先按照年龄排序,如果年龄相同,则按照姓名排序。
实现
import java.util.Objects;
public class Student implements Comparable{
private String name;
private Integer age; //int中没有compareTo方法,所以age的类型要改为Integer
public Student() {
}
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name) &&
Objects.equals(age, student.age);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//优先按照年龄排序,如果年龄相同,则按照姓名排序。
@Override
public int compareTo(Object o) {
Student st = (Student) o; //强制类型转换
int a = this.getAge().compareTo(st.getAge()); //如果两个人的年龄相同,则输出0
int n = a == 0 ? this.getName().compareTo(st.getName()) : a;
return n;
}
}
import java.util.TreeSet;
public class ComparableDemo {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
Student st1 = new Student("Jone" , 20);
Student st2 = new Student("Amy" , 20);
Student st3 = new Student("Mike" , 18);
Student st4 = new Student("Yom" , 18);
treeSet.add(st1);
treeSet.add(st2);
treeSet.add(st3);
treeSet.add(st4);
//增强for循环
for(Object obj : treeSet){
System.out.println(obj);
}
}
}
运行结果:
Student{name='Mike', age=18}
Student{name='Yom', age=18}
Student{name='Amy', age=20}
Student{name='Jone', age=20}
4.3.2 定制排序
在创建集合的时候,根据其元素的自然排序进行排序;实现Comparable接口,并实现其中的compareTo()方法。
| TreeSet(Comparator<? super E> comparator) | 构造一个新的,空的树集,根据指定的比较器进行排序。 |
|---|
方式一:编写一个普通类,去实现接口
实现:
import java.util.Comparator;
//实现Comparator接口
public class ComparatorStu implements Comparator {
@Override
public int compare(Object o1, Object o2) {
Student st1 = (Student) o1;
Student st2 = (Student) o2;
int st = st1.getAge().compareTo(st2.getAge());
return st == 0 ? st1.getName().compareTo(st2.getName()) : st;
}
}
运行结果:
Student{name='Mike', age=18}
Student{name='Yom', age=18}
Student{name='Amy', age=20}
Student{name='Jone', age=20}
方式二:使用内部类实现
实现:
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo_2 {
public static void main(String[] args) {
Comparator com = new ComparatorStudent();
TreeSet treeSet = new TreeSet(com);
Student st1 = new Student("Jone" , 20);
Student st2 = new Student("Amy" , 20);
Student st3 = new Student("Mike" , 18);
Student st4 = new Student("Yom" , 18);
treeSet.add(st1);
treeSet.add(st2);
treeSet.add(st3);
treeSet.add(st4);
//增强for循环
for(Object obj : treeSet){
System.out.println(obj);
}
}
//使用内部类实现
private static class ComparatorStudent implements Comparator{
@Override
public int compare(Object o1, Object o2) {
Student st1 = (Student) o1;
Student st2 = (Student) o2;
int st = st1.getAge().compareTo(st2.getAge());
return st == 0 ? st1.getName().compareTo(st2.getName()) : st;
}
}
}
运行结果:
Student{name='Mike', age=18}
Student{name='Yom', age=18}
Student{name='Amy', age=20}
Student{name='Jone', age=20}
方式三:使用匿名内部类(推荐)
实现:
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo_3 {
public static void main(String[] args) {
//使用匿名内部类
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
Student st1 = (Student) o1;
Student st2 = (Student) o2;
int st = st1.getAge().compareTo(st2.getAge());
return st == 0 ? st1.getName().compareTo(st2.getName()) : st;
}
});
Student st1 = new Student("Jone" , 20);
Student st2 = new Student("Amy" , 20);
Student st3 = new Student("Mike" , 18);
Student st4 = new Student("Yom" , 18);
treeSet.add(st1);
treeSet.add(st2);
treeSet.add(st3);
treeSet.add(st4);
//增强for循环
for(Object obj : treeSet){
System.out.println(obj);
}
}
}
运行结果:
Student{name='Mike', age=18}
Student{name='Yom', age=18}
Student{name='Amy', age=20}
Student{name='Jone', age=20}
结论:
- 用TreeSet存储自定义对象,使用无参构造来创建集合,此时默认使用的是自然排序,对元素的排序,需要让元素的所属类实现Comparable接口,并重写compareTo方法
- 重写的时候,可以自定义排序规则。必须区分清楚主要条件和次要条件,同时要注意排序的要求(升序、降序)
- 定制排序,在创建集合的时候,需要指定一个Compareator接口的对象
4.4 LinkedHashSet(哈希表+链表实现)
- 特点
- 底层实现是哈希表和链表的实现,具有可预知的迭代顺序
- 元素是有序的,有序是由链表保障的(迭代顺序与元素添加顺序相同)
- 元素是不可重复的(哈希表保障了唯一性)
- 此实现不同步
- 实例
import java.util.LinkedHashSet;
public class ArrayListDemo {
public static void main(String[] args) {
LinkedHashSet hash = new LinkedHashSet();
hash.add("Java");
hash.add("is");
hash.add("a");
hash.add("language");
for(Object obj : hash){
System.out.println(obj);
}
}
}
Java
is
a
language
4.5 面试题分析
import java.util.HashSet;
public class TreeSetDemo_4 {
public static void main(String[] args) {
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);//p1在集合中的存储位置是由1001和AA计算所得
set.add(p2);
System.out.println(set);
p1.setName("CC");//将AA改为了CC
System.out.println(set);
boolean b = set.remove(p1);//此时会根据p1的hash值来计算需要移除的元素所在的位置
System.out.println(b);//false
System.out.println(set);//修改失败
set.add(new Person(1001,"CC"));//存储的位置是由1001和CC计算所得
System.out.println(set);//添加成功
set.add(new Person(1001,"AA"));//虽然计算得到的位置和第二个对象相同,但是hash值不同且equals返回false
System.out.println(set);
}
}
运行结果:
[Person{number=1002, name='BB'}, Person{number=1001, name='AA'}]
[Person{number=1002, name='BB'}, Person{number=1001, name='CC'}]
false
[Person{number=1002, name='BB'}, Person{number=1001, name='CC'}]
[Person{number=1002, name='BB'}, Person{number=1001, name='CC'}, Person{number=1001, name='CC'}]
[Person{number=1002, name='BB'}, Person{number=1001, name='CC'}, Person{number=1001, name='CC'}, Person{number=1001, name='AA'}]
5 Map

- Map 的典型实现:HashMap,LinkedHashMap,TreeMap,HashTable(Properties)
- Map 的特点
- 是与Collection 并列的集合
- 用于保存具有映射关系的对象(映射对象以键值对的形式存在 ket-value)
- 不能包含重复的键,每个键可以映射到最多一个值
- 键不能重复,值可重复
- 元素的存取是无序的
5.1 Map 的常用方法
- 常用方法
| 返回值类型 | 方法 |
|---|---|
| void | clear() 从该Map中删除所有的映射(可选操作)。 |
| V | put(K key, V value) 将指定的值与该映射中的指定键相关联(可选操作)。 |
| void | putAll(Map<? extends K,? extends V> m) 将指定地图的所有映射复制到此映射(可选操作)。 |
| V | remove(Object key) 如果存在(从可选的操作),从该地图中删除一个键的映射。 |
| default boolean | remove(Object key, Object value) 仅当指定的密钥当前映射到指定的值时删除该条目。 |
| default V | replace(K key, V value) 只有当目标映射到某个值时,才能替换指定键的条目。 |
| default boolean | replace(K key, V oldValue, V newValue) 仅当当前映射到指定的值时,才能替换指定键的条目。 |
实例:
import java.util.HashMap;
import java.util.Map;
public class MapDemo_2 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1001,"小明");
map.put(1002,"小红");
map.put(1003,"小黑");
map.put(1004,"小李");
map.remove(1003); //删除
boolean a = map.remove(1004,"小田");
System.out.println("是否删除成功:" + a);
map.replace(1001,"小晓"); //替换元素
System.out.println(map);
Map<Integer,String> map1 = new HashMap<>();
map1.put(1010,"王一");
map1.put(1011,"周三");
map.putAll(map1); //将map1中的元素添加到map中
System.out.println(map);
}
}
运行结果:
是否删除成功:false
{1001=小晓, 1002=小红, 1004=小李}
{1010=王一, 1011=周三, 1001=小晓, 1002=小红, 1004=小李}
- 获取的方法
| 返回值类型 | 方法 |
|---|---|
| Set<Map.Entry<K,V>> | entrySet() 返回此地图中包含的映射的Set视图。 |
| V | get(Object key) 返回到指定键所映射的值,或 null如果此映射包含该键的映射。 |
| Set | keySet() 返回此地图中包含的键的Set视图。 |
| Collection | values() 返回此地图中包含的值的Collection视图。 |
实现:
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo_2 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1001,"小明");
map.put(1002,"小红");
map.put(1003,"小黑");
map.put(1004,"小李");
System.out.println("学号1002对应的姓名为:" + map.get(1002)); //通过键获取值
//获取集合中学生的学号,所有键的Set集合
System.out.println("学生的学号为:");
Set<Integer> keySet = map.keySet();
for(Integer i : keySet){ //遍历集合
System.out.println(i);
}
//获取集合中学生的姓名,所有值的Collection集合
System.out.println("学生的姓名为:");
Collection<String> value = map.values();
for(String va : value){
System.out.println(va);
}
//获取集合中的键值对
Set<Map.Entry<Integer,String>> entrySet = map.entrySet();
for(Map.Entry<Integer,String> entry : entrySet){
System.out.println(entry);
}
}
}
运行结果:
学号1002对应的姓名为:小红
学生的学号为:
1001
1002
1003
1004
学生的姓名为:
小明
小红
小黑
小李
1001=小明
1002=小红
1003=小黑
1004=小李
- 判断的方法
| 返回值类型 | 方法 |
|---|---|
| boolean | containsKey(Object key) 如果此映射包含指定键的映射,则返回 true 。 |
| boolean | containsValue(Object value) 如果此map将一个或多个键映射到指定的值,则返回 true 。 |
| boolean | isEmpty() 如果此map不包含键值映射,则返回 true 。 |
实现:
System.out.println(map.isEmpty()); //判断集合是否为空
System.out.println(map.containsKey(1001)); //判断集合中是否包含指定的key
System.out.println(map.containsValue("黑黑")); //判断集合中是否包含指定的value
运行结果:
false
true
false
5.2 Map 集合的遍历
- 方式一:获取Map 集合的键集,在使用map 所提供的通过键获取值的方式来进行遍历所有的元素
实现:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo_2 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1001,"小明");
map.put(1002,"小红");
map.put(1003,"小黑");
map.put(1004,"小李");
System.out.println("方式一:");
//获取Map集合的键集合,再通过方法获取其值
Set<Integer> keySet1 = map.keySet();
for(Integer i : keySet1){
System.out.println(i + " = " + map.get(i));
}
}
}
运行结果:
方式一:
1001 = 小明
1002 = 小红
1003 = 小黑
1004 = 小李
- 方式二:借助于Map.Entry 对象
实现:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo_2 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1001,"小明");
map.put(1002,"小红");
map.put(1003,"小黑");
map.put(1004,"小李");
System.out.println("方式一:");
//获取Map集合的键集合,再通过方法获取其值
Set<Integer> keySet1 = map.keySet();
for(Integer i : keySet1){
System.out.println(i + " = " + map.get(i));
}
System.out.println("方式二:");
//借助于Map.Entry对象
Set<Map.Entry<Integer,String>> entrySet1 = map.entrySet();
for(Map.Entry<Integer,String> entry : entrySet1){
System.out.println(entry);
}
}
}
运行结果:
方式二:
1001=小明
1002=小红
1003=小黑
1004=小李
- 实例
需求:使用Map集合存储自定义对象
学生对象:姓名 年龄
在map中,以学生对象为值 ,而以学生的学号为键
实现:
import java.util.*;
public class MapTest {
public static void main(String[] args) {
Map<String,Student> map = new HashMap<>();
Student st1 = new Student("小明" , 18);
Student st2 = new Student("小红" , 19);
Student st3 = new Student("小黑" , 20);
Student st4 = new Student("小刘" , 22);
map.put("20171101" , st1);
map.put("20171102" , st2);
map.put("20171103" , st3);
map.put("20171104" , st4);
//方式一
System.out.println("方式一:");
Set<String> keys = map.keySet();
Iterator<String> iter = keys.iterator();
while(iter.hasNext()){
String key = iter.next();
Student value = map.get(key);
System.out.println(key + "-" + value);
}
//方式二
System.out.println("方式二:");
Set<Map.Entry<String,Student>> entrySet = map.entrySet();
for(Map.Entry<String,Student> entry : entrySet){
System.out.println(entry);
}
}
}
运行结果:
方式一:
20171101-Student{name='小明', age=18}
20171103-Student{name='小黑', age=20}
20171102-Student{name='小红', age=19}
20171104-Student{name='小刘', age=22}
方式二:
20171101=Student{name='小明', age=18}
20171103=Student{name='小黑', age=20}
20171102=Student{name='小红', age=19}
20171104=Student{name='小刘', age=22}
注意:
-
在集合中,如果要使用泛型,都使用泛型;如果不使用泛型,那么都不要使用
-
泛型仅在编译期有效 ,在运行期是没有泛型的,称为泛型擦除
5.3 HashMap
-
特点:
- Hash是map所有实现类中使用频率最高的实现类
- 基于哈希表的实现的Map接口
- 允许null的值和null键
- 存取是无序的
- hashMap的键是不能重复
-
HashMap 的存储结构
jdk1.8 前 HashMap 使用的是数组+链表的实现

jdk1.8 及以后,HashMap 采用的是数组+链表+红红黑树的实现

- HashMap 的源码分析
DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 HashMap的默认容量为16
MAXIMUM_CAPACITY = 1 << 30;//HashMap的最大支持容量2^30
DEFAULT_LOAD_FACTOR = 0.75f//HashMap的默认加载因子
TREEIFY_THRESHOLD = 8// 链表转换为红黑树的默认长度
UNTREEIFY_THRESHOLD = 6;// 红黑树转换为链表的默认长度
MIN_TREEIFY_CAPACITY = 64//被转换为树时的hash表的容量
Node<K,V>[] table;// 存储元素的数组 大小总是2的n次幂
Set<Map.Entry<K,V>> //entrySet;// 键值对集
int size;//键值对个数
int modCount;//hashMap容量改变的次数
int threshold;//扩容的临界值 = 容量 * 负载因子
Jdk8以前:数组+ 链表 = 桶(bucket)
在map中 元素的存储位置是根据键的 hashCode来计算而得
Jdk8以后 采用的 数组+ 链表 + 红黑树
HashMap(jdk8+)的底层实现特点:
- HashMap map = new HashMap()默认 创建一个长度为16得数组,但是数组此时并不会立即创建
- 当我们第一次去put的时候,才会初始化长度为16的数组
- 数组的类型为Node类型
- 形成链表的结构时,新添加的键值对在链表的尾部
- 当数组中链表的长度>8 时 且map中数组的长度> 64时,此时会将链表转换为红黑树
5.4 LinkedHashMap
- LinkedHashMap是HashMap的子类
- 在LinkedHashMap中,对于HashMap进行了扩展:使用了双向链表,来记录元素的添加顺序
- 基于特殊的结构,迭代顺序和插入顺序是一致的。
HashMap 的 Node:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
LinkedHashMap 的 Node:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
由以上源码可得:在LinkedHashMap中,对于HashMap进行了扩展:使用了双向链表来记录元素的添加顺序
4.5 TreeMap
- 需要对存入其中的元素进行排序,TreeMap 可以保证元素处于有序状态,有序指遵循字典顺序;
- 排序方式:自然排序,定制排序
5.6 HashTable(了解)
- 允许hash 表实现,和HashMap 一样;
- 不允许null键,null值
- 是线程同步的
6 Collections(工具类)
是操作集合 Set,List,Map 的工具类;工具类中的方法都是静态的。
| 返回值类型 | 方法 |
|---|---|
| static void | copy(List<? super T> dest, List<? extends T> src) 将所有元素从一个列表复制到另一个列表中。 |
| static <T extends Object & Comparable<? super T>>T | max(Collection<? extends T> coll) 根据其元素的 自然顺序返回给定集合的最大元素。 |
| static <T extends Object & Comparable<? super T>>T | min(Collection<? extends T> coll) 根据其元素的 自然顺序返回给定集合的最小元素。 |
| static boolean | replaceAll(List list, T oldVal, T newVal) 将列表中一个指定值的所有出现替换为另一个。 |
| static void | reverse(List<?> list) 反转指定列表中元素的顺序。 |
| static void | shuffle(List<?> list) 使用默认的随机源随机排列指定的列表。 |
| static <T extends Comparable<? super T>> void | sort(List list) 根据其元素的natural ordering对指定的列表进行排序。 |
| static void | sort(List list, Comparator<? super T> c) 根据指定的比较器引起的顺序对指定的列表进行排序。 |
| static void | swap(List<?> list, int i, int j) 交换指定列表中指定位置的元素。 |
| static Collection | synchronizedCollection(Collection c) 返回由指定集合支持的同步(线程安全)集合。 |
| static List | synchronizedList(List list) 返回由指定列表支持的同步(线程安全)列表。 |
| static <K,V> Map<K,V> | synchronizedMap(Map<K,V> m) 返回由指定地图支持的同步(线程安全)映射。 |
| static Set | synchronizedSet(Set s) 返回由指定集合支持的同步(线程安全)集。 |
实例:
import java.util.*;
public class CollectionsDemo {
public static void main(String[] args) {
List list1 = new ArrayList();
list1.add(5);
list1.add(7);
list1.add(1);
list1.add(3);
list1.add(9);
List list2 = new ArrayList();
list2.add(2);
list2.add(4);
Collections.copy(list1,list2); //两个集合的拷贝,会覆盖相应索引的元素
System.out.println(list1);
System.out.println(Collections.max(list1)); //返回集合的最大(自然排序)的元素
System.out.println(Collections.min(list1)); //返回集合的最小(自然排序)的元素
Collections.reverse(list1); //反转列表中元素的顺序
System.out.println(list1);
boolean a = Collections.replaceAll(list1,9,11); //替换元素
System.out.println(list1);
Collections.shuffle(list1); //对列表中的元素进行随机排序
System.out.println(list1);
Collections.swap(list1,3,2); //交换元素索引为3与2处的位置
System.out.println(list1);
Collections.sort(list1); //对集合进行排序
System.out.println(list1);
System.out.println(Collections.synchronizedCollection(list1)); //返回集合
System.out.println(Collections.synchronizedList(list1)); //返回列表
}
}
运行结果:
[2, 4, 1, 3, 9]
9
1
[9, 3, 1, 4, 2]
[11, 3, 1, 4, 2]
[1, 11, 4, 3, 2]
[1, 11, 3, 4, 2]
[1, 2, 3, 4, 11]
[1, 2, 3, 4, 11]
[1, 2, 3, 4, 11]
7 集合小结
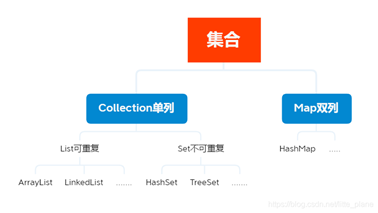
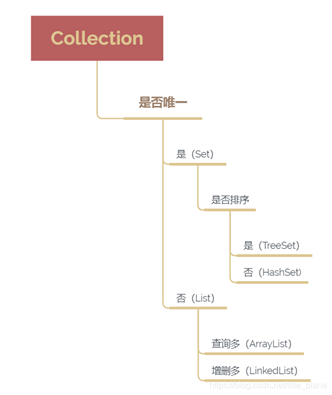
-
ArrayList:底层数据结构为数组,查询快,增删慢。其中的元素是有序的,允许存储 null 和重复的值。
Vector 允许存储重复的值,也允许存储 null。
LinkedList:底层数据结构为双向链表,查询慢,增删快
TreeSet:底层数据结构为红黑树(有序,唯一)
HashSet:底层数据结构为哈希表(无序,唯一) 【保证元素的唯一性:依赖两个方法:hashCode()和equals()】
HashMap :无序,键不重复
-
(1)集合主要分为单列Collection接口和双列Map接口
(2)Set接口和List接口继承于Collection接口
(3)Map接口为独立接口
(4)List可重复集合:ArrayList,LinkedList等
(5)Set不可重复集合:HashSet,TreeSet等
(6)Map集合:HashMap等
-
List 集合的遍历方式有如下:
- Iterator 迭代器实现
- 增强 for 循环实现
- get()和 size()方法结合实现
//get()和 size()方法结合实现
for(int x= 0;x<list.size();x++) {
Student g = (Student)list.get(x);
System.out.println(g.getName()+"----"+g.getAge());
}
-
Collection 接口存储一组不唯一,无序的对象
Set 接口继承 Collection 接口,存储一组唯一,无序的对象
List 接口继承 Collection 接口,存储一组不唯一,有序的对象 -
线程安全与线程不安全:
- 线程安全:Vector、HashTable、Properties
- 线程不安全:ArrayList、LinkedList、HashSet、TreeSet、HashMap、TreeMap等
值得注意的是:为了保证集合是线程安全的,相应的效率也比较低;线程不安全的集合效率相对会高一些。
















 2441
2441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











