







简介
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫技能总览图
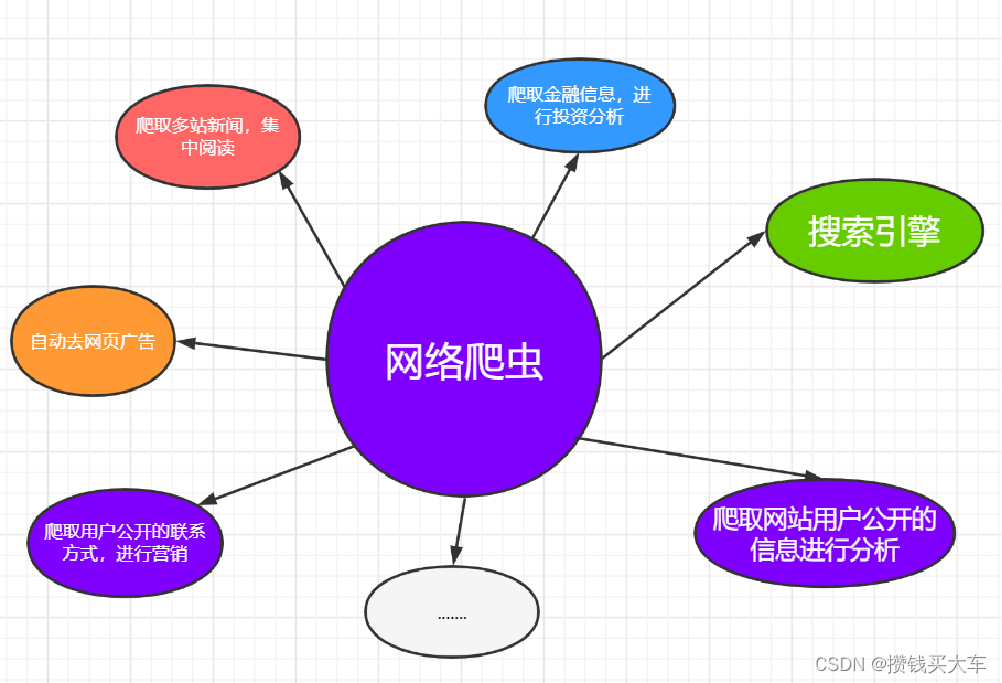
爬虫分类
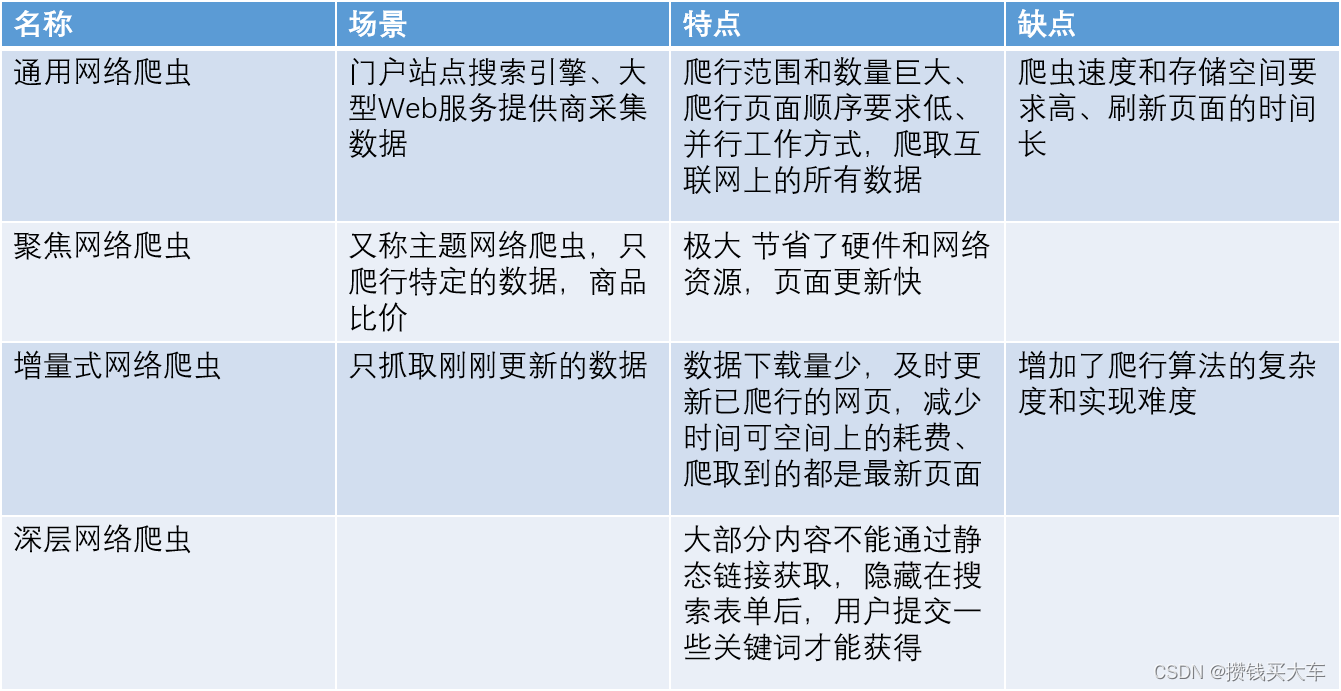
爬虫基本原理
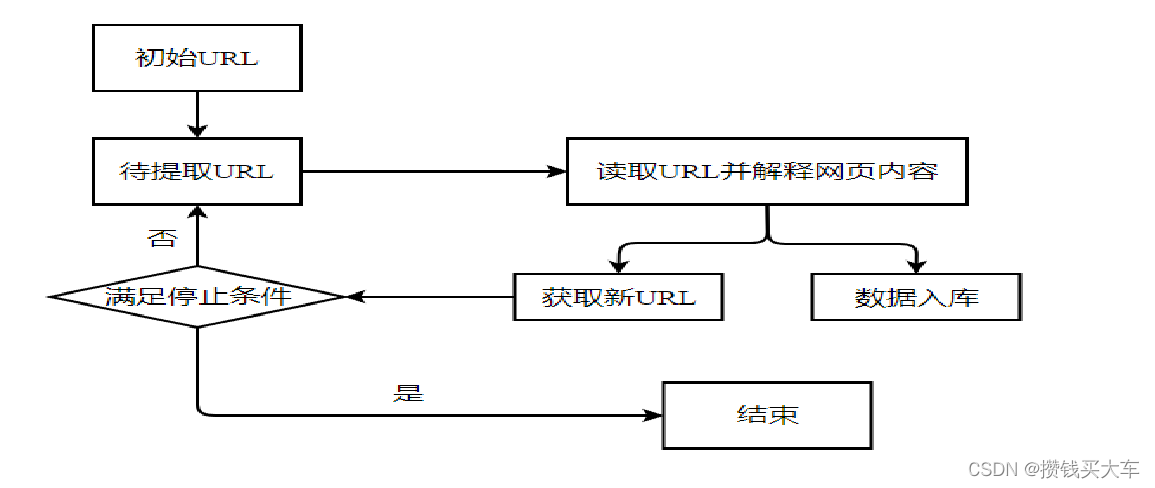
(1)获取初始的URL。初始的URL地址可以人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。
(2)根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,先爬取当前URL地址中的网页信息,然后解析网页信息内容,将网页存储到原始数据库中,并且在当前获得的网页信息里发现新的URL地址,存放于一个URL队列里面。
(3)从URL队列中读取新的URL,从而获得新的网页信息,同时在新网页中获取新URL,并重复上述的爬取过程。
(4)满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件,爬虫则会在停止条件满足时停止爬取。如果没有设置停止条件,爬虫就会一直爬取下去,一直到无法获取新的URL地址为止。
现在介绍完了,上点干货,下面会从俩个方面(图片,音乐)来对网站进行数据爬取,本文只是对技术研究,不针对网站,如果有侵权的行为,请联系我删除。再次强调只是对技术的研究,不涉及别的内容。
1.图片爬取
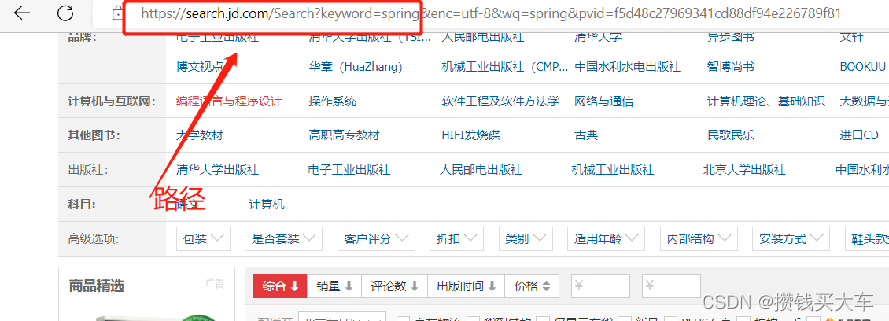
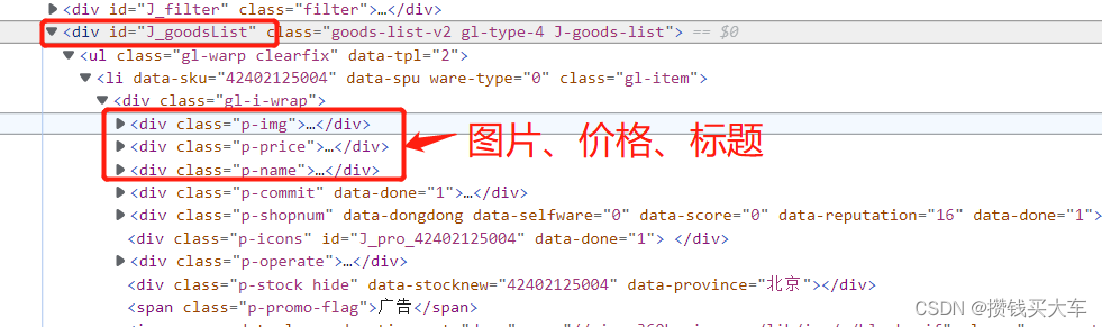
先对页面进行分析,找出规律
public List<Content> prasePic(String str) throws Exception{
ArrayList<Content> arrayList = new ArrayList<Content>();
//获取请求
String url="https://search.jd.com/Search?keyword="+str;
Document document = Jsoup.parse(new URL(url), 20000);
Element element = document.getElementById("J_goodsList");
//获取所有li标签
Elements elements = element.getElementsByTag("li");
for(Element el:elements){
String img=el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price=el.getElementsByClass("p-price").eq(0).text();
String title=el.getElementsByClass("p-name").eq(0).text();
Content t= new Content();
t.setImg(img);
t.setPrice(price);
t.setTitle(title);
arrayList.add(t);
}
return arrayList;
}
2.音乐爬取
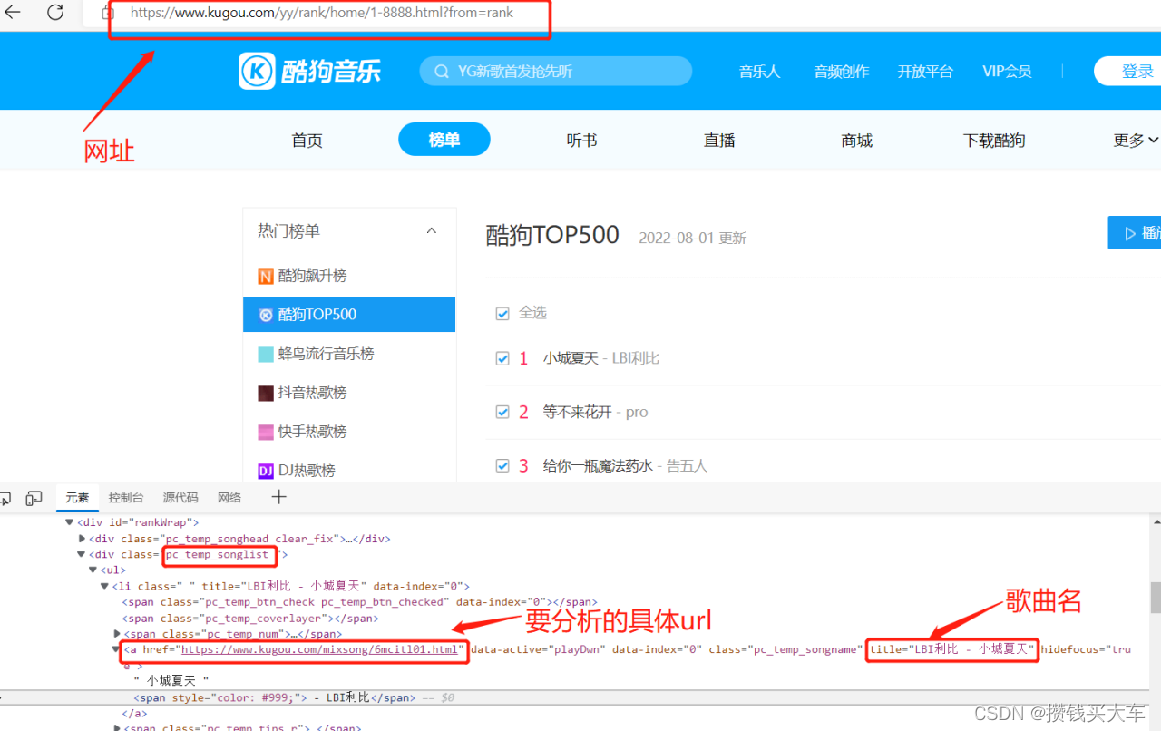
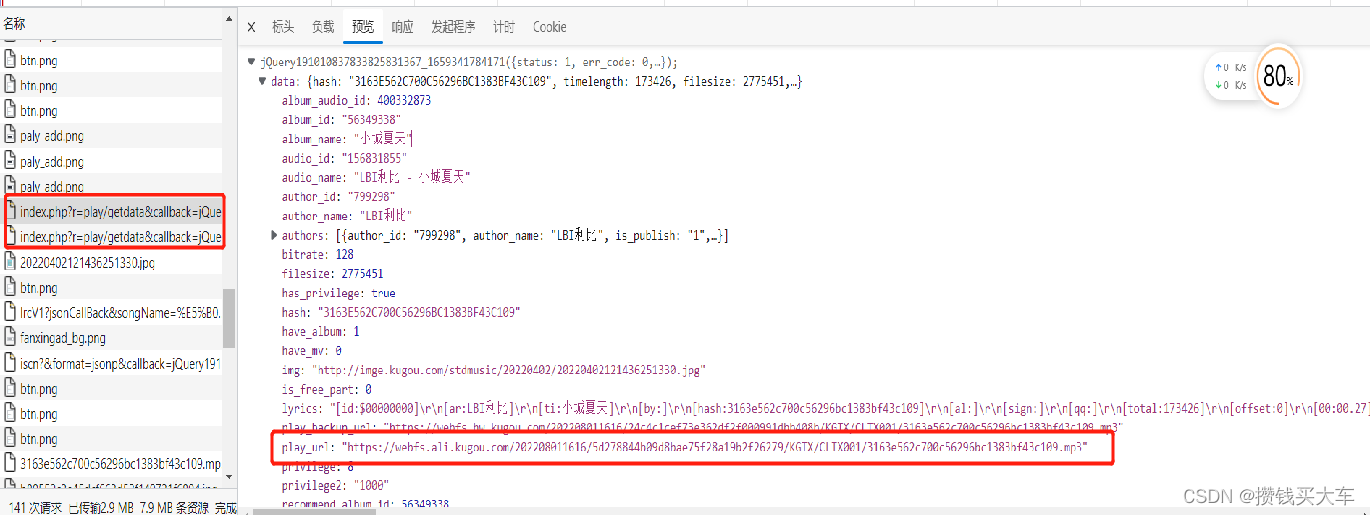
分析页面,找出规律,找到mp3源。
public class MusicKugou {
public static String filePath = "F:/music/";
public static String mp3 = "https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191038960086800209215_1659073717065&"
+ "hash=HASH&dfid=3x7oTa4CIf2I1SVTzb2DjMmq&appid=1014&mid=e556b9c8a0ee081cb8dc25db8dbae264&platid=4&album_id=ALBUM_ID&album_audio_id=ALBUM_AUDIO_ID&_=TIME";
public static String LINK = "https://www.kugou.com/yy/rank/home/PAGE-8888.html?from=rank";
public static void main(String[] args) throws IOException {
for(int i = 1 ; i < 2 ; i++){
String url = LINK.replace("PAGE", i + "");
getTitle(url);
}
}
public static String getTitle(String url) throws IOException{
HttpGetConnect connect = new HttpGetConnect();
String content = connect.connect(url, "utf-8");
HtmlManage html = new HtmlManage();
Document doc = html.manage(content);
Element ele = doc.getElementsByClass("pc_temp_songlist").get(0);
Elements eles = ele.getElementsByTag("li");
for(int i = 0 ; i < 5 ; i++){
Element item = eles.get(i);
String title = item.attr("title").trim();
String link = item.getElementsByTag("a").first().attr("href");
System.out.println(title);
download(link,title);
}
return null;
}
public static String download(String url,String name) throws IOException{
HttpGetConnect connect = new HttpGetConnect();
String content = connect.connect(url, "utf-8");
HtmlManage html = new HtmlManage();
String regEx = "\"hash\":\"[0-9A-Z]+\"";
String hash=getregEx(content,regEx);
String regEx_album_id = "\"album_id\":[0-9]+";
String album_id=getregEx(content,regEx_album_id);
album_id=album_id.replace("album_id:", "");
String regEx_audio_id = "\"mixsongid\":[0-9]+";
String album_audio_id=getregEx(content,regEx_audio_id);
album_audio_id=album_audio_id.replace("mixsongid:", "");
System.out.println("hash:"+hash+"==album_id:"+album_id+"==album_audio_id:"+album_audio_id);
String item = mp3.replace("HASH", hash);
item = item.replace("ALBUM_ID", album_id);
item = item.replace("ALBUM_AUDIO_ID", album_audio_id);
item = item.replace("TIME", System.currentTimeMillis() + "");
String mp = connect.connect(item, "utf-8");
mp = mp.substring(mp.indexOf("(") + 1, mp.length() - 3);
JSONObject json = JSONObject.fromObject(mp);
String playUrl = json.getJSONObject("data").getString("play_url");
FileDownload down = new FileDownload();
down.download(playUrl, filePath + name + ".mp3");
System.out.println(name + "下载完成");
return playUrl;
}
public static String getregEx(String content,String regEx){
String hash="";
// 编译正则表达式
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
hash = matcher.group();
hash = hash.replace("\"hash\":\"", "");
hash = hash.replace("\"", "");
}
return hash;
}
public class HttpGetConnect {
/**
* 获取html内容
* @param url
* @param charsetName UTF-8、GB2312
* @return
* @throws IOException
*/
public static String connect(String url,String charsetName) throws IOException{
BasicHttpClientConnectionManager connManager = new BasicHttpClientConnectionManager();
CloseableHttpClient httpclient = HttpClients.custom()
.setConnectionManager(connManager)
.build();
String content = "";
try{
HttpGet httpget = new HttpGet(url);
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(5000)
.setConnectTimeout(50000)
.setConnectionRequestTimeout(50000)
.build();
httpget.setConfig(requestConfig);
httpget.setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
httpget.setHeader("Accept-Encoding", "gzip,deflate,sdch");
httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
httpget.setHeader("Connection", "keep-alive");
httpget.setHeader("Upgrade-Insecure-Requests", "1");
httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
//httpget.setHeader("Hosts", "www.oschina.net");
httpget.setHeader("cache-control", "max-age=0");
CloseableHttpResponse response = httpclient.execute(httpget);
int status = response.getStatusLine().getStatusCode();
if (status >= 200 && status < 300) {
HttpEntity entity = response.getEntity();
InputStream instream = entity.getContent();
BufferedReader br = new BufferedReader(new InputStreamReader(instream,charsetName));
StringBuffer sbf = new StringBuffer();
String line = null;
while ((line = br.readLine()) != null){
sbf.append(line + "\n");
}
br.close();
content = sbf.toString();
} else {
content = "";
}
}catch(Exception e){
e.printStackTrace();
}finally{
httpclient.close();
}
return content;
}
private static Log log = LogFactory.getLog(HttpGetConnect.class);
}
public class FileDownload {
/**
* 文件下载
* @param url 链接地址
* @param path 要保存的路径及文件名
* @return
*/
public static boolean download(String url,String path){
boolean flag = false;
CloseableHttpClient httpclient = HttpClients.createDefault();
RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(2000)
.setConnectTimeout(2000).build();
HttpGet get = new HttpGet(url);
get.setConfig(requestConfig);
BufferedInputStream in = null;
BufferedOutputStream out = null;
try{
for(int i=0;i<3;i++){
CloseableHttpResponse result = httpclient.execute(get);
System.out.println(result.getStatusLine());
if(result.getStatusLine().getStatusCode() == 200){
in = new BufferedInputStream(result.getEntity().getContent());
File file = new File(path);
out = new BufferedOutputStream(new FileOutputStream(file));
byte[] buffer = new byte[1024];
int len = -1;
while((len = in.read(buffer,0,1024)) > -1){
out.write(buffer,0,len);
}
flag = true;
break;
}else if(result.getStatusLine().getStatusCode() == 500){
continue ;
}
}
}catch(Exception e){
e.printStackTrace();
flag = false;
}finally{
get.releaseConnection();
try{
if(in != null){
in.close();
}
if(out != null){
out.close();
}
}catch(Exception e){
e.printStackTrace();
flag = false;
}
}
return flag;
}
private static Log log = LogFactory.getLog(FileDownload.class);
}
public class HtmlManage {
public Document manage(String html){
Document doc = Jsoup.parse(html);
return doc;
}
public Document manageDirect(String url) throws IOException{
Document doc = Jsoup.connect( url ).get();
return doc;
}
public List<String> manageHtmlTag(Document doc,String tag ){
List<String> list = new ArrayList<String>();
Elements elements = doc.getElementsByTag(tag);
for(int i = 0; i < elements.size() ; i++){
String str = elements.get(i).html();
list.add(str);
}
return list;
}
public List<String> manageHtmlClass(Document doc,String clas ){
List<String> list = new ArrayList<String>();
Elements elements = doc.getElementsByClass(clas);
for(int i = 0; i < elements.size() ; i++){
String str = elements.get(i).html();
list.add(str);
}
return list;
}
public List<String> manageHtmlKey(Document doc,String key,String value ){
List<String> list = new ArrayList<String>();
Elements elements = doc.getElementsByAttributeValue(key, value);
for(int i = 0; i < elements.size() ; i++){
String str = elements.get(i).html();
list.add(str);
}
return list;
}
private static Log log = LogFactory.getLog(HtmlManage.class);
}
再次强调只是对技术的研究,不涉及别的内容,如果有侵权的行为,请联系我删除。















 3126
3126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









