









参考学习视频:哔哩哔哩中的图灵课堂中的徐庶老师。
本篇博客是自己学习jpa的笔记记录,笔记主要来源是视频中老师的讲解和加上个人的一些理解,仅供参考。
目录
hibernate搭建与测试(hibernate原始的操作)
jpa学习前言
为什么要用spring data
spring data主要是用来实现数据存储的,那么我们使用mybatis,jdbc不行吗?为什么还要去学一门新技术?因为随着互联网业务的发展,业务的场景越来越复杂,单一的关系型数据库不再是最优的选择,但是随着数据库种类与数据库中间技术的变多,开发人员的学习成本和企业的招聘成本都会加剧上升,但是spring data可以对多种数据库进行操作,这样就大大减少了我们的学习成本。spring data帮我们统一了数据访问层,减低了学习成本,提升了开发效率。
什么是jpa
JPA全称Java Persistence API(2019年重新命名为 Jakarta Persistence API ),是Sun官方提出的一种ORM规范。 O:Object R: Relational M:mapping
该规范为我们提供了:
① ORM映射元数据:JPA支持XML和注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对 象持久化到数据库表中; 如:@Entity 、 @Table 、@Id 与 @Column等注解。
② JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和 SQL代码中解脱出来。 如:entityManager.merge(T t);
③ JPQL查询语言:通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。 如:from Student s where s.name = ? (注意这个查询语句中的Student是类对象,name是该对象的属性)
jpa与jdbc对比
与jdbc的相同处:
1、都跟数据∙库操作有关,JPA 是JDBC 的升华,升级版。
2、JDBC和JPA都是一组规范接口
3、都是由SUN官方推出的
与jdbc的不同处:
1、JDBC是由各个关系型数据库实现的, JPA 是由ORM框架实现
2、JDBC 使用SQL语句和数据库通信。 【JPA用面向对象方式】, 通过ORM框架来生成SQL,进行操作。
3、JPA在JDBC之上的, JPA也要依赖JDBC才能操作数据库。
jpa的作用:
1、简化持久化操作的开发工作:让开发者从繁琐的 JDBC 和 SQL 代码中解脱出来,直接面向对象持久化操作。
2、Sun希望持久化技术能够统一,实现天下归一:如果你是基于JPA进行持久化你可以随意切换数据库。
Hibernate与JPA:Hibernate就是实现了JPA接口的ORM框架。JPA是一套ORM规范,Hibernate实现了JPA规范!
mybatis与hibernate的对比
mybatis:小巧、方便?、高效、简单、直接、半自动 半自动的ORM框架
小巧: mybatis就是jdbc封装 在国内更流行。
场景: 在业务比较复杂系统进行使用
hibernate:强大、方便、高效、(简单)复杂、绕弯子、全自动 全自动的ORM框架
强大:根据ORM映射生成不同SQL 在国外更流。
场景: 在业务相对简单的系统进行使用,随着微服务的流行。(适用于普通的增删改查)
一个技术好不好用主要是看它在什么应用场景中使用,在实际的开发中技术选型是非常重要的,选择合适的技术来进行开发,可以大大的提高开发效率。
hibernate搭建与测试(hibernate原始的操作)
1、创建数据库
可以先不创建表,只要我们在数据库中创建一个数据库就行(配置文件中要写这个数据库名的名称的),然后在编写的Java实体的时候使用注解配置好Java实体类与数据库中表的映射关系就行,在执行代码的时候这个hibernate会自动帮我们去创建这个表,这个自动创建的表是根据我们编写的映射来生成的。

2、引入pom配置依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springdata</artifactId>
<groupId>com.tuling.springdata</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>01-jpa-hibernate</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- junit4 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
<!-- hibernate对jpa的支持包 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.4.32.Final</version>
</dependency>
<!-- 注意驱动包的版本 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<!--openjpa-->
<dependency>
<groupId>org.apache.openjpa</groupId>
<artifactId>openjpa-all</artifactId>
<version>3.2.0</version>
</dependency>
</dependencies>
</project>3、编写Java对应的实体类
@Entity // 该注解是表示该类是作为hibernate的实体类
@Table(name = "tb_customer") // 映射的表名,就是自动生成的表对应的表名
public class Customer {
/**
* @Id:声明主键的配置
* @GeneratedValue:配置主键的生成策略
* strategy
* GenerationType.IDENTITY :自增,mysql
* * 底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)
* GenerationType.SEQUENCE : 序列,oracle
* * 底层数据库必须支持序列
* GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增
* GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略
* @Column:配置属性和字段的映射关系
* name:数据库表中字段的名称
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long custId; //客户的主键
@Column(name = "cust_name")
private String custName;//客户名称
@Column(name="cust_address")
private String custAddress;//客户地址
//对应属性的get,set,toString方法,这里就省略不在写出来了......
}@Id:声明主键的配置
@GeneratedValue:配置主键的生成策略
strategy
GenerationType.IDENTITY :自增,mysql
底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)
GenerationType.SEQUENCE : 序列,oracle
底层数据库必须支持序列
GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增
GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略
@Column:配置属性和字段的映射关系
name:数据库表中字段的名称
4、编写hibernate的配置文件:hibernate.cfg.xml (下面也提供了使用注解的编程式配置)
注意:我的数据库环境是MySQL8以上,所以下面的配置文件要按照自己的数据库环境来配置;
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 配置数据库连接信息 -->
<property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/springdata_jpa?serverTimezone=Asia/Shanghai&characterEncoding=utf-8</property>
<property name="connection.username">root</property>
<property name="connection.password">root</property>
<!-- 会在日志中记录sql 默认false-->
<property name="show_sql">true</property>
<!--是否格式化sql(就是打印的sql的格式) 默认false-->
<property name="format_sql">true</property>
<!--表生成策略
默认none 不自动生成
update 如果没有表会创建,有会检查更新
create 创建-->
<property name="hbm2ddl.auto">update</property>
<!-- 配置方言:选择数据库类型 -->
<property name="dialect">org.hibernate.dialect.MySQL8Dialect</property>
<!--指定哪些(java类)pojo 需要进行ORM映射(帮我们生成数据库表的映射)-->
<mapping class="com.tuling.pojo.Customer"></mapping>
</session-factory>
</hibernate-configuration>或者是使用java编程式进行配置:
@Configuration // 标记当前类为配置类
//@EnableJpaRepositories(basePackages="com.tuling.repositories") // 启动jpa,这个包是自定义接口的的位置(实现repository或者是其子类 接口的位置),有点像dao/mapper
@EnableTransactionManagement // 开启事务
public class SpringDataJPAConfig {
//<!--数据源-->
@Bean
public DataSource dataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/springdata_jpa?serverTimezone=UTC&characterEncoding=UTF-8");
return dataSource;
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
vendorAdapter.setGenerateDdl(true);
vendorAdapter.setShowSql(true);
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(vendorAdapter);
factory.setPackagesToScan("com.tuling.pojo");
factory.setDataSource(dataSource());
return factory;
}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
5、编写和执行测试代码(这里使用的是简单的单元测试)
public class HibernateTest {
// Session工厂 Session:数据库会话 代码和数据库的一个桥梁
private SessionFactory sf;
@Before
public void init() {
StandardServiceRegistry registry = new StandardServiceRegistryBuilder().configure("/hibernate.cfg.xml").build();
//2. 根据服务注册类创建一个元数据资源集,同时构建元数据并生成应用一般唯一的的session工厂
sf = new MetadataSources(registry).buildMetadata().buildSessionFactory();
}
//进行数据插入的操作
@Test
public void testC(){
// session进行持久化操作
try(Session session = sf.openSession()){
Transaction tx = session.beginTransaction();
Customer customer = new Customer();
customer.setCustName("徐庶");
session.save(customer);
tx.commit();
}
}
} 执行结果:控制台会打印的sql执行流程(也可以关闭这个功能)

数据库自动生成的表:

其他相关的测试操作:自己按需测试
// Session工厂 Session:数据库会话 代码和数据库的一个桥梁
private SessionFactory sf;
@Before
public void init() {
StandardServiceRegistry registry = new StandardServiceRegistryBuilder().configure("/hibernate.cfg.xml").build();
//2. 根据服务注册类创建一个元数据资源集,同时构建元数据并生成应用一般唯一的的session工厂
sf = new MetadataSources(registry).buildMetadata().buildSessionFactory();
}
//查询操作
@Test
public void testR(){
// session进行持久化操作
try(Session session = sf.openSession()){
Transaction tx = session.beginTransaction();
Customer customer = session.find(Customer.class, 1L);
System.out.println("=====================");
System.out.println(customer);
tx.commit();
}
}
//保存操作
@Test
public void testU(){
// session进行持久化操作
try(Session session = sf.openSession()){
Transaction tx = session.beginTransaction();
Customer customer = new Customer();
//customer.setCustId(1L);
customer.setCustName("徐庶");
// 插入session.save()
// 更新session.update();
session.saveOrUpdate(customer);
tx.commit();
}
}
//删除操作
@Test
public void testD(){
// session进行持久化操作
try(Session session = sf.openSession()){
Transaction tx = session.beginTransaction();
Customer customer = new Customer();
customer.setCustId(2L);
session.remove(customer);
tx.commit();
}
}spring data jpa基本入门
spirng data jpa是spring提供的一套简化JPA开发的框架,按照约定好的规则进行【方法命名】去写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
使用了SpringDataJpa,我们的dao层中只需要写接口,就【自动】具有了增删改查、分页查询等方法。
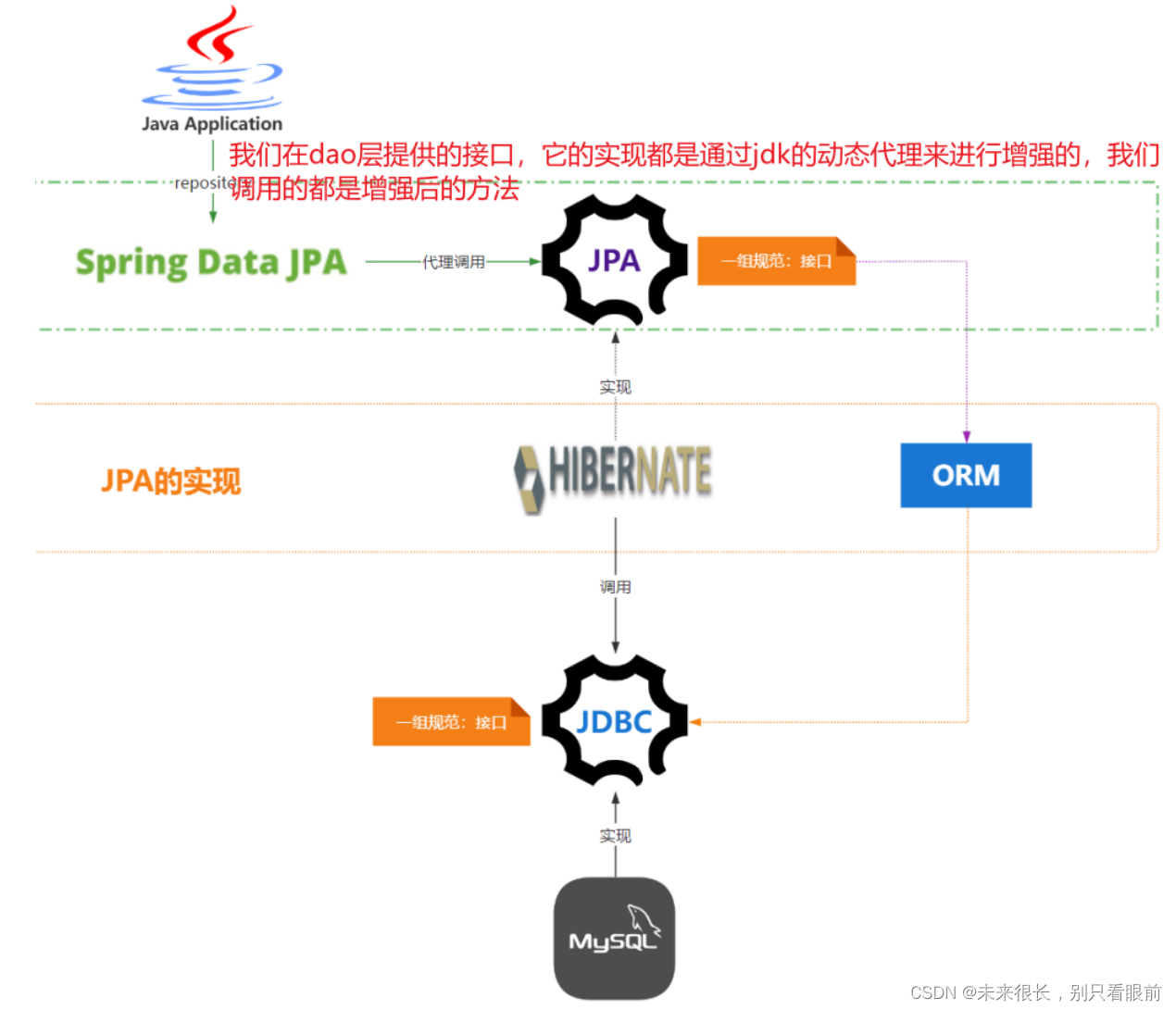
在dao层自己写一个接口继承这个CrudRepository<T1,T2> ,这个接口实现了基本的增删查改操作,里面的两个泛型,第一个代表要对那个实体类进行操作,第二个泛型表示进行删除,操作等操作的id是什么样的数据类型。我们自己定义的接口继承这个接口或者是其子接口(比如PagingAndSortingRepository, JpaRepository),那么我们自己定义的接口就有了基本的增删改查的功能了,就是这么简单!
public interface CustomerRepository extends CrudRepository<User,Long>
//第一个泛型表示对user实体类进行操作
//第二个泛型表示在【对user实体类】进行增删改查操作的时候,像findById与 deleteById等操作的时候这个参数的数据类型就行long
两个注意点:
-
使用这个接口提供的save方法的时候,如果我们指定了主键(一般是id)那这个save操作就是修改操作,如果没有指定主键那么这个save就是新增操作。
-
在使用这个接口提供的delete操作的时候,spring data jpa它会先帮我们去查找一次,然后再去删除,这样就可以不用担心删除的数据为null的情况。
CrudRepository接口提供的常用方法
// 用来插入和修改 有主键就是修改 没有就是新增
// 获得插入后自增id, 获得返回值
<S extends T> S save(S entity);
// 通过集合保存多个实体
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
// 通过主键查询实体
Optional<T> findById(ID id);
// 通过主键查询是否存在 返回boolean
boolean existsById(ID id);
// 查询所有
Iterable<T> findAll();
// 通过集合的主键 查询多个实体,, 返回集合
Iterable<T> findAllById(Iterable<ID> ids);
// 查询总数量
long count();
// 根据id进行删除
void deleteById(ID id);
// 根据实体进行删除
void delete(T entity);
// 删除多个
void deleteAllById(Iterable<? extends ID> ids);
// 删除多个传入集合实体
void deleteAll(Iterable<? extends T> entities);
// 删除所有
void deleteAll();基本的分页与排序演示
源码中提供了CrudRepository这个接口的另一个子类:PagingAndSortingRepository
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
//对查询的结果进行排序
Iterable<T> findAll(Sort sort);
//用来进行分页查询 这个Pageable可以通过PageRequest.of()方法来进行构建
Page<T> findAll(Pageable pageable);
}注意:这个findAll的分页操作后面还有其他的多种实现,这里只是先演示该方法最简单的分页。
分页演示:
@Autowired
CustomerRepository repository; //这个CustomerRepository是自己定义的接口,继承了CrudRepository这个接口
@Test
public void testPaging(){
//这个PageRequest.of(0, 2)方法的两个参数,第一个代表分页的索引,就是当前查询是从第几页开始,这里的0是表示从第一页开始,第二个参数的意思是一页里面你要显示多少数据
Page<Customer> all = repository.findAll(PageRequest.of(0, 2));
//可以对分页查询的结果进行处理
System.out.println(all.getTotalPages());
System.out.println(all.getTotalElements());
System.out.println(all.getContent());
}对属性进行硬编码排序演示:
@Autowired
CustomerRepository repository;
@Test
public void testSort(){
Sort sort = Sort.by("id").descending();
//对查询的结果进行id(这个id是Java实体类与数据库中表对应的)降序排序,当然如果你想使用组合排序,是可以使用and进行排序规则的拼接的 ,这里直接使用固定的字段进行排序是不推荐的,因为万一以后这个字段名发生了变化那还要回来修改,,,
Iterable<Customer> all = repository.findAll(sort);
System.out.println(all);
}对属性进行“安全的”排序:
@Autowired
CustomerRepository repository;
@Test
public void testSortTypeSafe(){
//构建排序对象 这个Customer是我们自己写的实体类
Sort.TypedSort<Customer> sortType = Sort.sort(Customer.class);
//对指定的字段进行排序
Sort sort = sortType.by(Customer::getCustId).descending();
Iterable<Customer> all = repository.findAll(sort);
System.out.println(all);
}jpa的自定义操作
使用jpql进行自定义
@Query 进行查询操作
-
查询如果返回单个实体就用pojo接收 , 如果是多个则需要通过集合。
-
参数设置方式:
-
索引 : ?数字
-
具名: :参数名 必须要结合@Param注解指定参数名字
-
增删改操作:
安装下面这个插件后,在query注解中书写sql就可以有提示了!

-
要加上事务的支持; 在实际开发中这个事务的注解是写在业务层的!!!
-
如果是插入方法:一定只能在hibernate下才支持 (Insert into ..select )
@Transactional // 通常会放在业务逻辑层上面去声明
@Modifying // 通知springdatajpa 是增删改的操作
public interface CustomerRepository extends PagingAndSortingRepository<Customer,Long>{
// 自定义增删查改操作
// 查询
//注意:使用这个注解书写查询语句的时候需要指定查询参数的位置或者是查询参数的属性名 下面这一种就是使用指定属性名来进行查询 也可以 FROM Customer where custName=?1 这个?表示占位符,这个问号后面的1表示参数的索引位置,这个索引是方法参数中参数的位置
@Query("FROM Customer where custName=:custName ") //推荐使用具名来完成参数的绑定
List<Customer> findCustomerByCustName(@Param("custName") String custName);
// 修改 返回的int是受影响的行数
@Transactional
@Modifying // 通知springdatajpa 是增删改的操作,必须要加上这个注解
@Query("UPDATE Customer c set c.custName=:custName where c.custId=:id")
int updateCustomer(@Param("custName") String custName,@Param("id")Long id);
@Transactional
@Modifying // 通知springdatajpa 是增删改的操作
@Query("DELETE FROM Customer c where c.custId=?1")
int deleteCustomer(Long id);
// 新增 JPQL 注意jpa是不支持新增语句的,但是如果jpa的实现是使用hibernate的话,就可以使用hibernate提供的伪新增
@Transactional
@Modifying // 通知springdatajpa 是增删改的操作
@Query("INSERT INTO Customer (custName) SELECT c.custName FROM Customer c where c.custId=?1")
int insertCustomerBySelect(Long id);
}
使用原生sql进行自定义
@Query(value="select * FROM tb_customer where cust_name=:custName ",nativeQuery = true)
//我们需要手动指定这个nativeQuery为true,它的默认是false,并且这个原生的sql要写在value属性中
List<Customer> findCustomerByCustNameBySql(@Param("custName") String custName);按照规定的方法名来进行操作
支持的查询方法主题关键字(前缀):
-
决定当前方法作用
-
只支持查询和删除

支持的查询方法 谓词关键字和修饰符来决定查询条件:

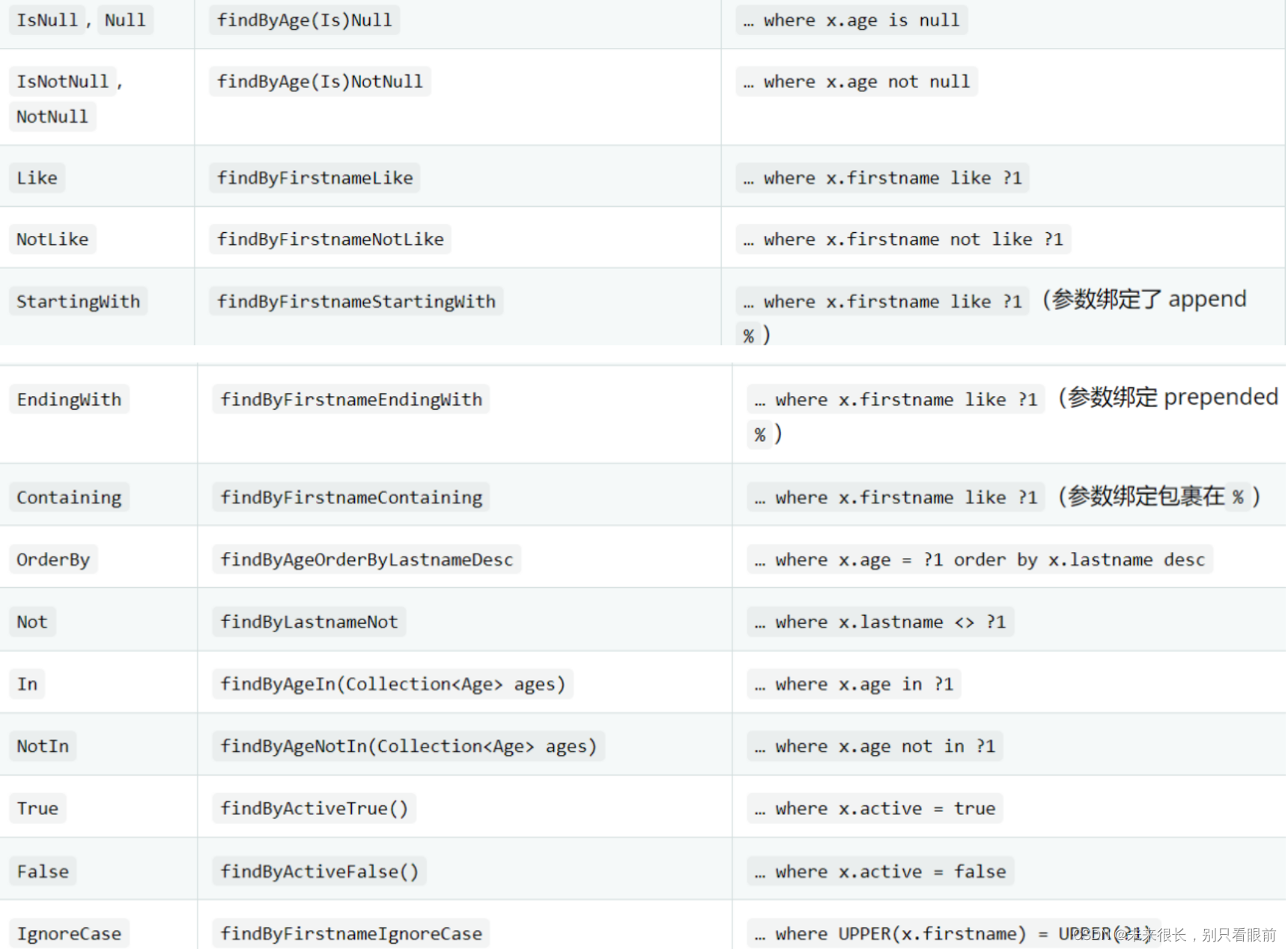
这些规定的方法命名都是不需要记忆的,只需要安装刚刚的jpa buddy 它就会有提示。

代码演示: 没错,就是这样定义一下接口就行,就可以直接对数据库中的表进行操作了。
public interface CustomerMethodNameRepository extends PagingAndSortingRepository<Customer,Long> {
//这个命名要特别注意,如果不按规范来的话就会导致失效的
List<Customer> findByCustName(String custName);
boolean existsByCustName(String custName);
@Transactional
@Modifying
int deleteByCustId(Long custName);
//通过名字进行模糊查询操作
List<Customer> findByCustNameLike(String custName);
}jpa的动态条件查询(重难点)
前面我们讲的自定义查询中,不管是使用jpql还是通过命名规范来进行查询,实际上查询语句都是已经被我们给写死的,不能达到动态查询的效果。
下面将介绍三种可以实现动态查询的方式,实际上它们各自都有自己的应用场景,每一种方法都有自己的局限。
Query by Example
使用步骤:
1、将Repository继承QueryByExampleExecutor
public interface CustomerQBERepository extends PagingAndSortingRepository<Customer,Long>, QueryByExampleExecutor<Customer> { //这个泛型表示的是你要操作的Java实体类
}我们看一下这个querybyexampleexecutor的源码定义了哪些方法:
public interface QueryByExampleExecutor<T> {
<S extends T> Optional<S> findOne(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort);
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);
<S extends T> long count(Example<S> example);
<S extends T> boolean exists(Example<S> example);
<S extends T, R> R findBy(Example<S> example, Function<FetchableFluentQuery<S>, R> queryFunction);
}方法使用演示:
@Autowired
CustomerQBERepository repository; //把刚刚自己定义的接口注入到容器
//根据客户名称 客户地址动态查询
@Test
public void test01(){
//构建实体类需要动态查询的条件 比如需要通过名字和地址进行动态查询
Customer customer=new Customer();
customer.setCustName("徐庶"); //在实际开发中这个查询的条件都是从前端传过来的,比如传了name和address过来,你需要使用对应的数据类型进行接收就行,这里是演示所以直接写死了查询条件
customer.setCustAddress("BEIJING");
// 通过Example构建查询条件 特别注意这个Example对象是spring data中的依赖,别引成了hibernate的
Example<Customer> example = Example.of(customer);
List<Customer> list = (List<Customer>) repository.findAll(example);
System.out.println(list);
}
/**
* 通过匹配器进行条件的限制 客户名称 客户地址动态查询
*/
@Test
public void test02(){
// 查询条件
Customer customer=new Customer();
customer.setCustName("庶");
customer.setCustAddress("JING");
// 通过匹配器 对条件行为进行设置
ExampleMatcher matcher = ExampleMatcher.matching()
//.withIgnorePaths("custName") // 设置忽略的属性
//.withIgnoreCase("custAddress") // 设置忽略大小写
//.withStringMatcher(ExampleMatcher.StringMatcher.ENDING); // 对所有条件字符串进行了结尾匹配
.withMatcher("custAddress",m -> m.endsWith().ignoreCase()); // 针对单个条件进行限制, 会使withIgnoreCase失效,需要单独设置,第一个参数是需要对那个属性进行匹配,第二个参数表示的是需要对属性使用什么样的匹配规则
//.withMatcher("custAddress",ExampleMatcher.GenericPropertyMatchers.endsWith().ignoreCase());
// 通过Example构建查询条件 加了匹配器的查询条件
Example<Customer> example = Example.of(customer,matcher);
List<Customer> list = (List<Customer>) repository.findAll(example);
System.out.println(list);
}
匹配器提供的一些方法:

Specifications
之前使用Query by Example只能针对字符串进行条件设置,那如果希望对所有类型支持,可以使用Specifications。
1、继承接口JpaSpecificationExecutor。
public interface CustomerSpecificationsRepository
extends PagingAndSortingRepository<Customer,Long>,
JpaSpecificationExecutor<Customer> { //这个泛型表示的是你要操作的Java实体类
}2、传入Specification的实现: 结合lambda表达式
-
Root:查询哪个表(关联查询) = from
-
CriteriaQuery:查询哪些字段,排序是什么 =组合(order by . where )
-
CriteriaBuilder:条件之间是什么关系,如何生成一个查询条件,每一个查询条件都是什么类型(> between in...) = where
-
Predicate(Expression): 每一条查询条件的详细描述
root对象可以让我们从表中获取我们想要的列
CriteriaBuilder where 设置各种条件 (> < in between......)
query 组合(order by , where)
@Autowired
CustomerSpecificationsRepository repository; //把刚刚自定义的接口注入到容器中
//--------------- 前面两个测试都是把查询条件写死的,后面两个测试是动态查询,更加符合实际开发
//进行精确匹配,单一条件查询
@Test
public void testR2(){
List<Customer> customer = repository.findAll(new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
// root对象可以让我们从表中获取我们想要的列
// CriteriaBuilder where 设置各种条件 (> < in ..)
// query 组合(order by , where)
Path<Object> custId = root.get("custId"); //获取对应的字段
Path<Object> custName = root.get("custName");
Path<Object> custAddress = root.get("custAddress");
// 对字段进行精确匹配 参数1 :为哪个字段设置条件 参数2:值
Predicate predicate = cb.equal(custAddress, "BEIJING");
return predicate;
}
});
System.out.println(customer);
}
//进行多条件查询
@Test
public void testR3(){
List<Customer> customer = repository.findAll(new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//root对象可以让我们从表中获取我们想要的列
// CriteriaBuilder where 设置各种条件 (> < in ..)
// query 组合(order by , where)
Path<Long> custId = root.get("custId");
Path<String> custName = root.get("custName");
Path<String> custAddress = root.get("custAddress");
// 参数1 :为哪个字段设置条件 参数2:值
Predicate custAddressP = cb.equal(custAddress, "BEIJING"); //等于
Predicate custIdP = cb.greaterThan(custId, 0L); //大于
CriteriaBuilder.In<String> in = cb.in(custName); //in
in.value("徐庶").value("王五"); //通过点value来进行in范围的拼接
//对多个条件进行拼接
Predicate and = cb.and(custAddressP, custIdP,in);
return and;
}
});
System.out.println(customer);
}
//---------------------------------------------------------------------------------------------------------
//注意上面我们进行查询条件的构建的时候,是把查询条件给写死了,在实际开发中这个条件应该是动态的,我们需要根据前端传来的数据进行判断,然后通过判断的结果来进行查询条件的构建---主要是进行非空判断
//模拟动态条件查询
@Test
public void testR4(){
//模拟前端传过来的数据
Customer params=new Customer();
//params.setCustAddress("BEIJING");
params.setCustId(0L);
params.setCustName("徐庶,王五");
List<Customer> customer = repository.findAll(new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//root对象可以让我们从表中获取我们想要的列
// CriteriaBuilder where 设置各种条件 (> < in ..)
// query 组合(order by , where)
// 1. 通过root拿到需要设置条件的字段
Path<Long> custId = root.get("custId");
Path<String> custName = root.get("custName");
Path<String> custAddress = root.get("custAddress");
// 2. 通过CriteriaBuilder设置不同类型条件
//2.1 因为动态查询的时候条件是变化的,不确定的,所以需要使用集合来进行条件的保存
List<Predicate> list=new ArrayList<>();
if(!StringUtils.isEmpty(params.getCustAddress())) {
// 参数1 :为哪个字段设置条件 参数2:值
list.add(cb.equal(custAddress, "BEIJING")) ;
}
if(params.getCustId()>-1){
list.add(cb.greaterThan(custId, 0L));
}
if(!StringUtils.isEmpty(params.getCustName())) {
CriteriaBuilder.In<String> in = cb.in(custName);
in.value("徐庶").value("王五");
list.add(in);
}
// 组合条件 因为涉及动态查询,这个拼接的查询条件个数在上面的判断中已经确定了,这里需要我们传一个数组过来,通过集合转数组的方法进行转换,不过需要的是Prediccate类型的定长数组
Predicate and = cb.and(list.toArray(new Predicate[list.size()]));
return and;
}
});
System.out.println(customer);
}
//进行排序等多条件的操作
@Test
public void testR5(){
Customer params=new Customer();
//params.setCustAddress("BEIJING");
params.setCustId(0L);
params.setCustName("徐庶,王五");
List<Customer> customer = repository.findAll(new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//root对象可以让我们从表中获取我们想要的列
// CriteriaBuilder where 设置各种条件 (> < in ..)
// query 组合(order by , where)
Path<Long> custId = root.get("custId");
Path<String> custName = root.get("custName");
Path<String> custAddress = root.get("custAddress");
// 参数1 :为哪个字段设置条件 参数2:值
List<Predicate> list=new ArrayList<>();
if(!StringUtils.isEmpty(params.getCustAddress())) {
list.add(cb.equal(custAddress, "BEIJING")) ;
}
if(params.getCustId()>-1){
list.add(cb.greaterThan(custId, 0L));
}
if(!StringUtils.isEmpty(params.getCustName())) {
CriteriaBuilder.In<String> in = cb.in(custName);
in.value("徐庶").value("王五");
list.add(in);
}
Predicate and = cb.and(list.toArray(new Predicate[list.size()]));
//对id字段进行降序排序
Order desc = cb.desc(custId);
//使用呢query对象对条件和组合进行拼接
return query.where(and).orderBy(desc).getRestriction();
}
});
System.out.println(customer);
}缺点:不支持分组等相关聚合函数的操作,但是支持排序。 如果你还是想要通过jpa实现分组等聚合函数的操作,那就需要通过原生的jpa,通过自己获取root对象,CriteriaQuery和CriteriaBuilder对象,然后再使用他们继续操作。因为重写toPredicate方法提供的数据库操作是定死的字段,你想要修改就只能提供原生的jpa操作来自己实现。
Querydsl
QueryDSL是基于ORM框架或SQL平台上的一个通用查询框架。借助QueryDSL可以在任何支持的ORM框架或SQL平台上以通用API方式构建查询。 JPA是QueryDSL的主要集成技术,是JPQL和Criteria查询的代替方法。目前QueryDSL支持的平台包括JPA,JDO,SQL,Mongodb 等等。
Querydsl扩展能让我们以链式方式代码编写查询方法。该扩展需要一个接口QueryDslPredicateExecutor,它定义了很多查询方法。
我们自己定义的接口继承QueryDslPredicateExecutor该接口,那么我们就可以使用该接口提供的各种方法了。
public interface CustomerQueryDSLRepository extends
PagingAndSortingRepository<Customer,Long>
, QuerydslPredicateExecutor<Customer> { //这个泛型是我们需要操作的Java的实体类
}需要引入单独的依赖:
<querydsl.version>4.4.0</querydsl.version>
<!‐‐ querydsl ‐‐>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl‐jpa</artifactId>
<version>${querydsl.version}</version>
</dependency>引入组件:用于构建q类,但是加入这个组件后它不会自动编译,所以需要我们在maven的组件那里点击进行编译。

配置相关的maven插件:
<apt.version>1.1.3</apt.version>
<plugins>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>${apt.version}</version>
<dependencies>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>${querydsl.version}</version>
</dependency>
</dependencies>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/queries</outputDirectory>
<processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>
<logOnlyOnError>true</logOnlyOnError>
</configuration>
</execution>
</executions>
</plugin>
</plugins>编译完成后会在我们的target目录下生成对应的class文件,这样我们就可以自己去构建q类去了?实际上还是不行,因为这个编译后的只是一个class文件,这个时候我们书写代码去用这个Q类还是会报错,应该是压根点不出来。这是因为我们编写代码是用source文件夹进行编写的,而字节码文件是被排除在source(可以进行编码的文件夹)目录下的,所以这个需要我们手动的把这个Q类所在的文件夹变成source文件夹。

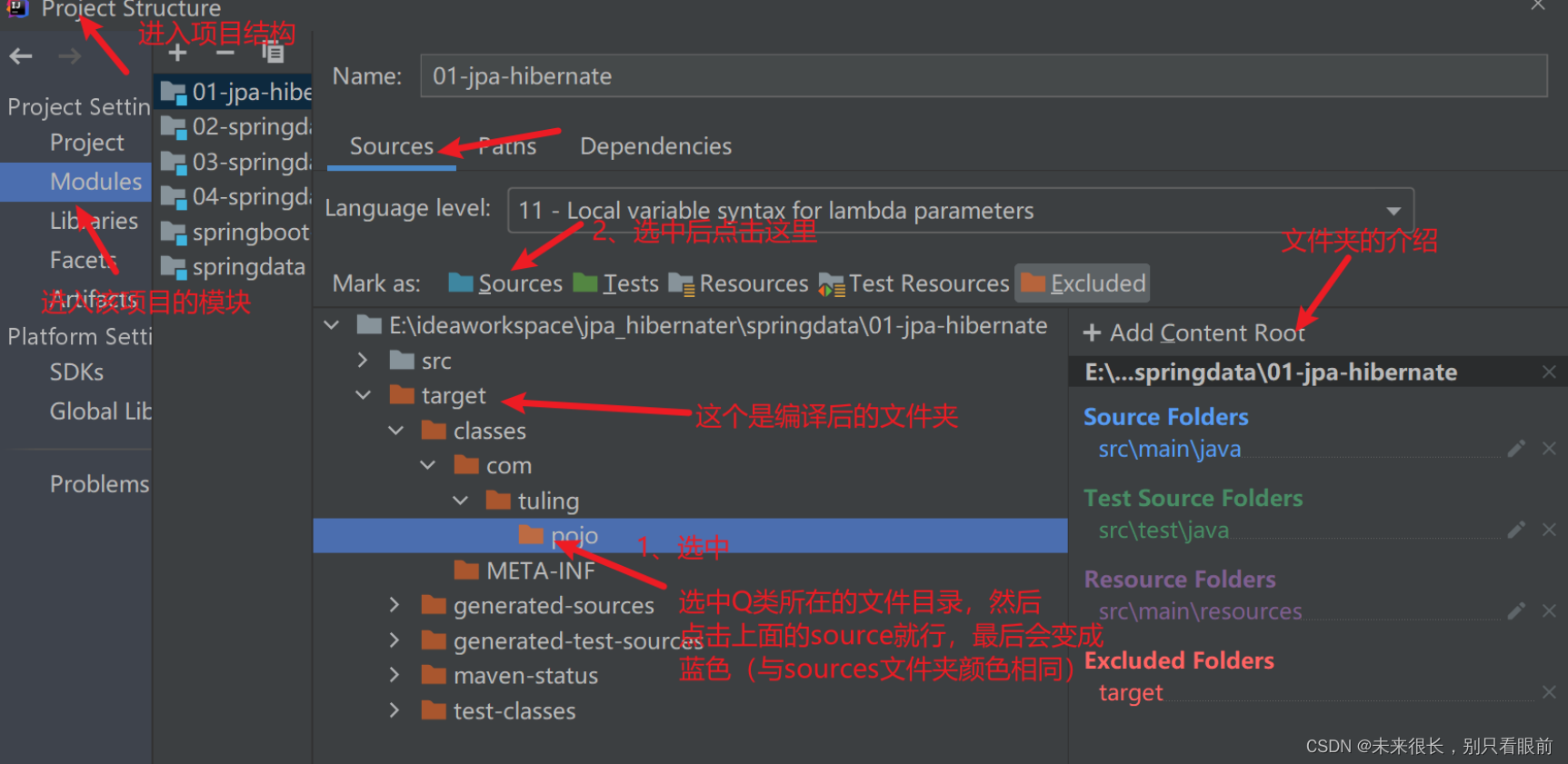

然后就可以进行编码测试了:
@Autowired
CustomerQueryDSLRepository repository; //把刚刚自定义的接口注入容器中
@Test
public void test01() {
//拿到Q类对象
QCustomer customer = QCustomer.customer;
// 通过Id查找 这里的id我们写死为1了,但是实际开发中是会用一个变量来接收前端传输过来的id的
BooleanExpression eq = customer.custId.eq(1L);
System.out.println(repository.findOne(eq));
}
/**
* 查询客户名称范围 (in)
等于 EQ : equal .eq
不等于 NE : not equal .ne
小于 LT : less than .lt
大于 GT : greater than .gt
小于等于 LE : less than or equal .loe
大于等于 GE : greater than or equal .goe
* id >大于
* 地址 精确
*/
@Test
public void test02() {
QCustomer customer = QCustomer.customer;
// 通过Id查找
BooleanExpression and = customer.custName.in("徐庶", "王五")
.and(customer.custId.gt(0L)) //id大于0
.and(customer.custAddress.eq("BEIJING")); //地址为BEIJING
System.out.println(repository.findOne(and));
}
//模拟动态查询
@Test
public void test03() {
Customer params=new Customer();
params.setCustAddress("BEIJING");
params.setCustId(0L);
params.setCustName("徐庶,王五");
QCustomer customer = QCustomer.customer;
// 初始条件 类似于1=1 永远都成立的条件
BooleanExpression expression = customer.isNotNull().or(customer.isNull());
//这里是使用三目运算来进行判断了,当然也可以使用if来进行判断
//注意:记得要使用and来进行拼接这个条件
expression=params.getCustId()>-1?
expression.and(customer.custId.gt(params.getCustId())):expression;
expression=!StringUtils.isEmpty( params.getCustName())?
expression.and(customer.custName.in(params.getCustName().split(","))):expression;
expression=!StringUtils.isEmpty( params.getCustAddress())?
expression.and(customer.custAddress.eq(params.getCustAddress())):expression;
System.out.println(repository.findAll(expression));
}
// 解决线程安全问题 如果使用@autowire来对EntityManager进行注入,那可能会出现线程安全问题,使用注解PersistenceContext可以为每一个线程单独绑定一个EntityManager,这样就可以解决线程不安全的问题了
@PersistenceContext
EntityManager em;
/**
* 自定义列查询、分组
* 需要使用原生态的方式(Specification)
* 通过Repository进行查询, 列、表都是固定
*/
@Test
public void test04() {
JPAQueryFactory factory = new JPAQueryFactory(em);
QCustomer customer = QCustomer.customer;
// 构建基于QueryDSL的查询 像写SQL一样来拼接条件 这个Tuple是一个自定义对象,主要是负责来接收你要查询信息,比如你只需要查一张表中的两个字段,实际上是没有对象来接收这个查询结果的两个字段的,而提供的Tuple这个对象就可以用来接收这种类型的数据
JPAQuery<Tuple> tupleJPAQuery = factory.select(customer.custId, customer.custName)
.from(customer)
.where(customer.custId.eq(1L))
.orderBy(customer.custId.desc());
// 执行查询
List<Tuple> fetch = tupleJPAQuery.fetch();
// 处理返回数据 对结果集进行遍历
for (Tuple tuple : fetch) {
System.out.println(tuple.get(customer.custId));
System.out.println(tuple.get(customer.custName));
}
}
//结合聚合函数进行查询,注意结果集的返回值
@Test
public void test05() {
JPAQueryFactory factory = new JPAQueryFactory(em);
QCustomer customer = QCustomer.customer;
// 构建基于QueryDSL的查询
JPAQuery<Long> longJPAQuery = factory.select(
customer.custId.sum())
.from(customer)
//.where(customer.custId.eq(1L))
.orderBy(customer.custId.desc());
// 执行查询
List<Long> fetch = longJPAQuery.fetch();
// 处理返回数据
for (Long sum : fetch) {
System.out.println(sum);
}
}














 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









