






希尔排序又称“缩小增量排序”,是插入排序的一种,从“减少记录个数” 和 “序列基本有序” 两个方面对直接插入排序进行了改进。希尔排序实质上是采用分组插入的方法。先将整个待排序记录序列分割成几组,从而减少参与直接插入排序的数据量,对每组分别进行直接插入排序,然后增加每组的数据量,重新分组。这样当经过几次分组排序后,整个序列中的记录“基本有序”时,在对全体记录进行一次直接插入排序。希尔对记录的分组,不是简单地 “逐段分割” ,而是将相隔某个 “增量” 的记录分成一组。 希尔排序中好的增量的选择是一个难题,增量大于1,就是跳跃式的移动。
希尔排序是不稳定的排序。
举例说明一下:
将数组{13,7,3,8,12,510,2}从小到大进行排序。
第一次分组排序:选择步长8/2=4,图下方的数组表示分组情况
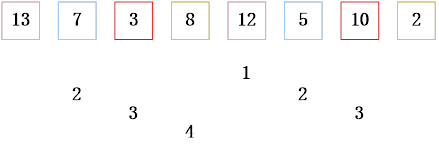

第二次排序:选择步长4/2=2;


第三次分组排序:选择步长2/2=1;


顺序表实现希尔排序完整代码如下:
/*关键字序列{49 38 65 97 76 13 27 49 55 04}
增量选取5、3和1*/
#include<bits/stdc++.h>
using namespace std;
const int Max=100;
typedef struct
{
int key;
}LNode;
typedef struct
{
LNode a[Max];
int len;
}Sqlist;
void ShellInsert(Sqlist &L,int dk)
{
int i,j;
for(i=dk+1;i<=L.len;i++)
{
if(L.a[i].key<L.a[i-dk].key)//需将L.a[i]插入有序增量子表
{
L.a[0]=L.a[i];//暂存在L.a[0]
for(j=i-dk;j>0&&L.a[0].key<L.a[j].key;j-=dk)
L.a[j+dk]=L.a[j];//记录后移,直到找到正确位置
L.a[j+dk]=L.a[0];
}
}
}
//按增量序列dt[0..t-1]对顺序表L作t趟希尔排序
void ShellSort(Sqlist &L,int dt[],int t)
{
for(int i=0;i<t;i++)
ShellInsert(L,dt[i]);//一趟增量为dt[t]的希尔插入排序
}
int main()
{
Sqlist L;
int dt[3]={5,3,1};
printf("请输入待排序数的个数:");
scanf("%d",&L.len);
printf("请输入待排序的数:");
for(int i=1;i<=L.len;i++)
scanf("%d",&L.a[i]);
ShellSort(L,dt,3);
printf("排序好的数列为:");
for(int i=1;i<=L.len;i++)
printf("%d ",L.a[i]);
return 0;
} 测试样例如下:
请输入待排序数的个数:10
请输入待排序的数:49 38 65 97 76 13 27 49 55 04
排序好的数列为:4 13 27 38 49 49 55 65 76 97















 2508
2508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









