






记录一下,我在部署的时候的过程,有问题一起学习。
首先 去AutoDL创建一个实例,我用的是RTX3090。(这里网上的教程很多,官网的文档也很清楚)。基础镜像 cuda1.8
创建好实例后,进入Jupyter。

在autodl-tmp (系统盘建一个文件夹,保存我们的代码。)

然后进入终端 cd 刚刚创建的文件夹下。使用git 将项目clone下来,记得在git的时候添加
--recursive 记得添加,我也不知道为啥,添加后,我们配置环境就会成功,没有好像就歇菜了。
git clone 地址 --recursive
然后我们就可以开始配置环境。
conda env create --file environment.yml
不出意外我们就把环境装好了。
下面我们就可以跑代码,因为我们没有装colmap等工具,所以使用官网提供的数据集,进行测试。数据可以在项目的readme中找到。
在进行之前,我们需要将数据集,上传到云端,在项目根目录下创建一个文件夹,data,将文件上传进去。
上传的方法很多:个人使用的xshell和xftp(网上有很多教程,官网下载可以申请免费使用)
目录结构:


到这里我们就可以开始跑起来了:
首先激活我们刚刚创建的环境:conda activate gaussian_splatting
运行程序 python train.py -s ./data/truck(目录结构根据自己创建的写)
等程序运行结束,会在output文件夹里面生成结果。大概这个样子:

后面我们就可以使用可视化工具查看结果viewer
使用方法:
下载viewer进行解压,创建一个文件家output,将我们训练得到的文件夹,放到output里面。
我是在自己电脑上查看的 在viewer中cmd
在命令行,键入 .\bin\SIBR_gaussianViewer_app -m output/<文件夹名字>
到此结束。
生命:本人小白,也在学习,只为记录,有不对的地方欢迎指正,共同学习,五险进入,谢谢。保命。《狗头》
效果:
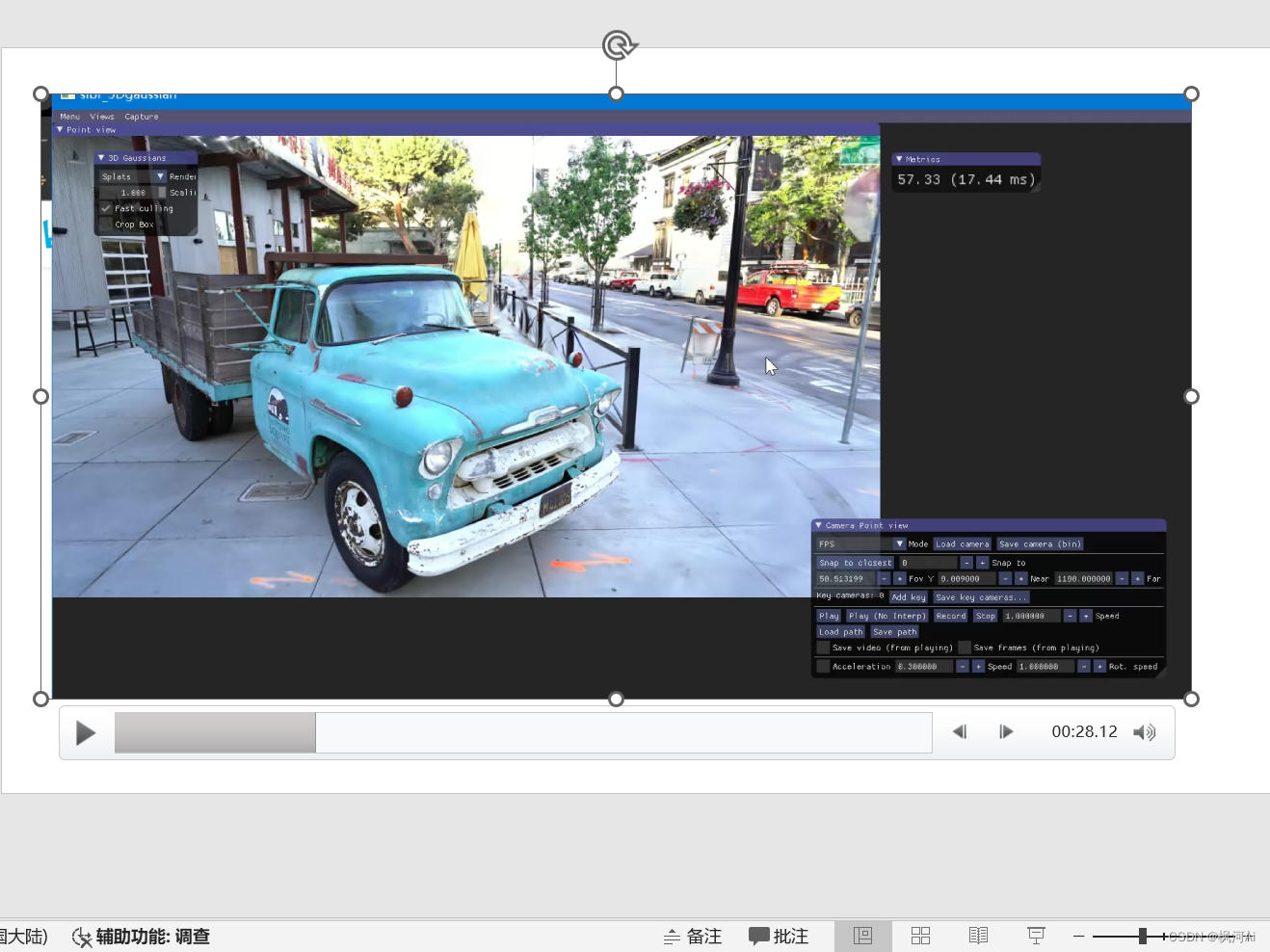
后面怎样怎进制作自己的数据集,大佬求教。联系:jobpg57@gmail.com















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









