







第一步
配置Flume配置文件
此配置可以去官网搜索,简单修改即可
链接:
https://flume.apache.org/releases/content/1.7.0/FlumeUserGuide.html
创建监听日志文件的配置:/usr/apps/flume-1.7.0/kafka-producer.conf
pro.sources = s1
pro.channels = c1
pro.sinks = k1
pro.sources.s1.type = exec
pro.sources.s1.command = tail -F /usr/apps/tmp/logs.log
pro.channels.c1.type = memory
pro.channels.c1.capacity = 1000
pro.channels.c1.transactionCapacity = 100
pro.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
pro.sinks.k1.kafka.topic = log-test
pro.sinks.k1.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
pro.sinks.k1.kafka.flumeBatchSize = 20
pro.sinks.k1.kafka.producer.acks = 1
pro.sinks.k1.kafka.producer.linger.ms = 1
pro.sinks.k1.kafka.producer.compression.type = snappy
pro.sources.s1.channels = c1
pro.sinks.k1.channel = c1
第二步
在虚拟机上开启监听
在flume的根目录下执行以下命令
第一种写法:
bin/flume-ng agent -c conf/ -n pro -f job/kafka-producer.conf -Dflume.root.logger=INFO,console
第二种写法:
bin/flume-ng agent --conf conf/ --name pro --conf-file job/kafka-producer.conf -Dflume.root.logger=INFO,console
参数说明:
–conf/-c:表示配置文件存储在 conf/目录
–name/-n:表示给 agent 起名为 pro
–conf-file/-f:flume 本次启动读取的配置文件是在 job 文件夹下的 kafka-producer.conf文件。
-Dflume.root.logger=INFO,console :-D 表示 flume 运行时动态修改 flume.root.logger参数属性值,
并将控制台日志打印级别设置为INFO 级别。日志级别包括:log、info、warn、error。
第三步
启动消费者
复制会话在kafka目录下开启消费者命令:
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.38.144:9092 --topic log-test
Flink连接Kafka进行消费
package 用Flink消费kafka中的数据
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import java.util.Properties
object Flink_test {
def main(args: Array[String]): Unit = {
val prop = new Properties()
//封装kafka的连接地址
prop.setProperty("bootstrap.servers", "192.168.38.144:9092")
//指定消费者id
prop.setProperty("group.id", "flink")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.addSource(new FlinkKafkaConsumer011[String]("log-test", new SimpleStringSchema(), prop))
stream.print()
env.execute()
}
}
效果图
遇到的问题:
如果Flink消费不到Kafka的消息:
第一步:检查config目录下的server.properties文件
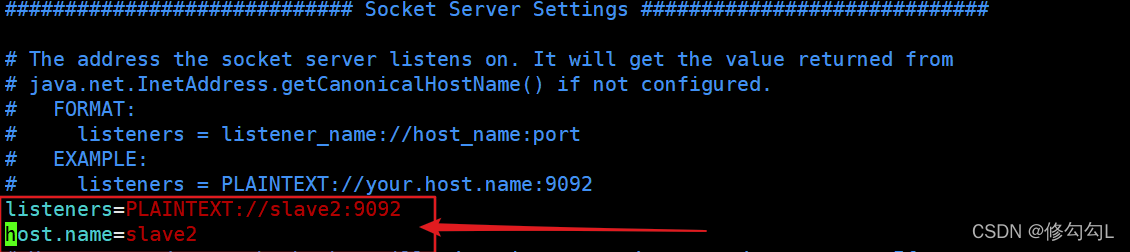
这两行必须要有!
(ip根据自己的机器所定:意思是将图中的slave2改成自己的虚拟机ip)
改完之后重启kafka!(重启之后保证以下进程都开启)
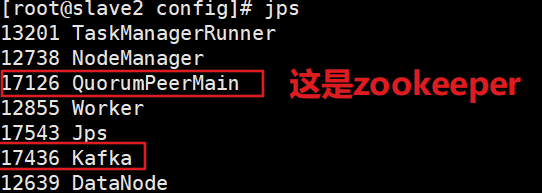
第二步:检查自己电脑的hosts文件
hosts文件的位置:C:\Windows\System32\drivers\etc

不要打开错了,用记事本打开
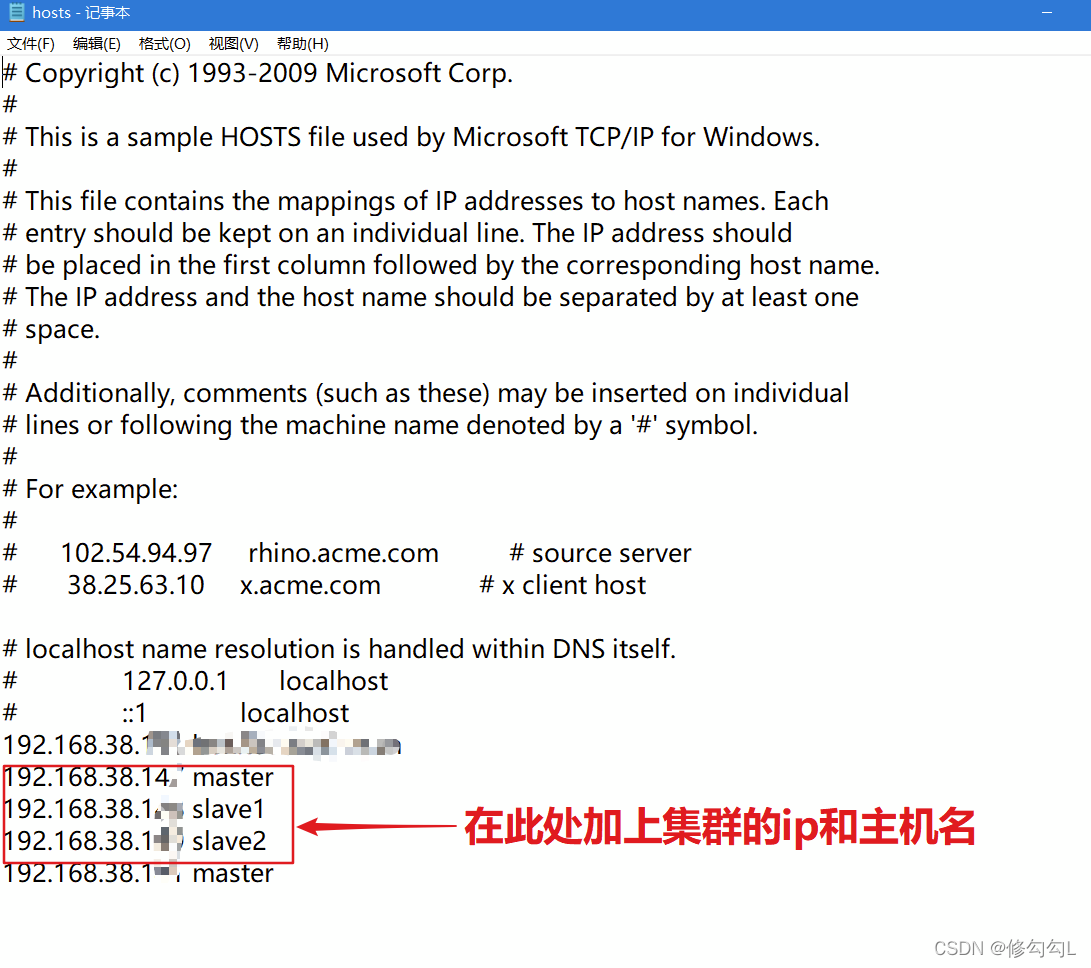
注意:ip和主机名之间要有空格
然后ctrl+s保存就可以了。

















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









