






1、gcc,g++,gdb常用命令
首先了解gcc,g++的区别。要先知道我们写的源代码是如何被编译器运行的。大概有四个阶段:
预处理:处理宏定义等宏命令,删除空格等,生成后缀为“.i”的文件
编译:将预处理后的文件转换成汇编语言,生成后缀为“.s”的文件
汇编:由汇编生成的文件翻译为二进制目标文,生成后缀为“.o”的文件
连接:多个目标文件(二进制)结合库函数等综合成的能直接独立执行的执行文件——生成后缀为“.out”的文件(exe文件)。
gcc无法进行库文件的连接;而g++则能完整编译出可执行文件。前三个阶段g++也是调用gcc实现的。
简单来说gcc是C语言编译器,g++是C++语言编译器。但是事实上,二者都可以编译c或cpp文件。区别在于,对于 .c和.cpp文件,gcc分别当做c和cpp文件编译,g++则统一当做cpp文件编译。
gdb调试是一个功能强大的命令调试程序,也就是一个debug的工具。
安装gdb: sudo apt install gdb
生成可执行代码:gcc test.c -g -o test或者g++ -g test.cpp -o test(注意添加-g参数,才可以调试)
进入gdb调试:gdb ./test
**list:**查看源代码,默认显示10行,可以修改。后面可以加文件名:行号,显示指定文件的以那一行为中心的附近的代码。这个很重要,因为我们需要观察源代码来了解程序逻辑,知道在哪里设置断点等。
插入断点:b 行号(或者函数入口处) 显示断点:info break 删除断点:delete 断点号
知道如何使用断点很重要,这样我们才知道程序中变量的值是如何变化的。
watch 可以用来监视一个变量或者一段内存,当这个变量或者该内存处的值发生变化时,GDB 就会中断下来。被监视的某个变量或者某个内存地址会产生一个 watch point(观察点)。这用于我们想要观察一个变量是否改变,如果一句句地调试太慢了。
关于调试还有**setp[n]和next[n]**两个但不调试命令,二者都代表每隔n行就自动断点,但是前者遇到函数会进入函数体执行,后者则会把函数执行完出来,整个函数体当成是一行。
知道了断点之后,我们可以用run命令运行程序,在断点处会中断,我们进行查看相应的变量的操作,再用continue或者go继续向下执行。
接下来很重要的一部分就是如何查看变量的值、地址、寄存器的值等操作。
查看变量的值**:print/p**. p 变量名,就可以查看变量的值。p/a按十六进制显示,p/c按字符显示等。也可以用display来显示变量的值,display在每次断点都会自动显示,不需要每次都p了,更方便。
查看内存地址的值:x/<n/f/u> n代表往后显示几个地址的内容,f代表显示的格式,比如十六进制十进制浮点数等,如果址所指的是字符串,那么格式可以是s,如果地十是指令地址,那么格式可以是i。u代表指定的字节作为一个值,默认是4个字节。
查看寄存器的值**:info registers**查看所有寄存器的情况。也可以使用print命令来访问寄存器的情况,只需要在寄存器名字前加一个$符号就可以了。如:p $eip。寄存器中可能存放了下一条指令的地址、函数返回地址、堆栈地址等,很重要。
**set args [arguments]:**重新指定被调试程序的命令行参数。show args显示被调试程序的命令行参数。这对于程序参数的相关调试有用。
GDB调试多线程看面试场景题积累汇总那一篇文章。
5、死锁问题
死锁就是,两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。比如很多进程需要以独占方式占用资源,这样进程间互相等待,无限期陷入僵持。
原因有:资源不足、资源分配不当、进程执行顺序不当等。
死锁的四个必要条件,即只有这四个条件成立,才可能发生死锁,不是肯定的。
互斥:一个资源只能同时被一个进程使用;
占有等待:进程资源得不到满足等待时,不释放已有的资源
不可剥夺:进程资源不能被别的进程抢占;
循环等待:每个进程都在等待链中等待下一个进程所持有的资源
死锁解决办法:
死锁防止:破坏四个必要条件之一即可。比如采用静态分配的方式,静态分配的方式是指进程必须在执行之前就申请需要的全部资源,且直至所要的资源全部得到满足后才开始执行。实现简单,但是严重的减低了资源利用率。剥夺调度能够防止死锁,但是只适用于内存和处理器资源。给系统的所有资源编号,规定进程请求所需资源的顺序必须按照资源的编号依次进行。
总结,死锁防止方法能够防止发生死锁,但必然会降低系统并发性,导致低效的资源利用率。
死锁避免:典型的就是银行家算法。本质就是,每次分配的时候,保证系统处于安全状态,如果这次分配导致不安全状态,则不分配。安全状态就是可以找到一个执行序列,满足每个进程对资源的最大需求,顺利完成执行序列。
银行家算法就是有最大需求矩阵,已分配矩阵,还需要矩阵,可用资源矩阵。分配资源时,若分配大于所需要或分配大于可用资源,不分配;若分配后导致进入不安全状态,不分配。
死锁检测:当且仅当资源分配图不可完全简化,就是死锁。
死锁解除:抢占资源、终止进程。
7、进程间通信方式
1.管道:
匿名管道:两个特点:信息单向传输,只能在父子兄弟进程之间使用(因为没有显式的管道文件,只能fork复制父进程的fd)。
例子:ps auxf | grep mysql 这个就是打印出所有进程信息,通过管道送入右边,再获取其中mysql进程。
命名管道FIFO:可以在不相关的进程间传递信息。使用方法:先需要通过mkfifo命令来创建,并且指定管道名字:mkfifo myPipe
echo “hello” > myPipe // 将数据写进管道 cat < myPipe // 读取管道里的数据。可以看出,管道这种通信方式效率低, 不适合进程间频繁地交换数据。当然,它的好处就是简单。
2、消息队列:
A进程要给B进程发送消息,A进程把数据放在对应的消息队列后就可以正常返回了,B进程需要的时候再去读取数据就可以了。效率更高。
消息队列是内核中消息链表,发送消息是消息体,固定大小的存储块,所以克服了字节流效率低的特点。消息队列生命周期内核持续,不是随进程的。
缺点:消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销,因为进程写入数据到内核中的消息队列时,会发生从用户态拷贝数据到内核态的过程,同理 另一进程 读取内核中的消息数据时,会发生从内核态拷贝数据到用户态的过程
3、共享内存
消息队列的读取和写入的过程,都会有发生用户态与内核态之间的消息拷贝过程。那共享内存的方式,就很好的解决了这一问题。
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去, 大大提高了进程间通信的速度。
缺点是:多人写的话,会产生覆盖问题,读没问题。
4、信号量(按理说不严格属于进程通信)
为了防止多进程竞争共享资源,而造成的数据错乱,所以需要保护机制,使得共享的资源,在任意时刻只能被一个进程访问。正好,信号量就实现了这一保护机制。信号量其实是一个整型的计数器,主要用于实现进程间的互斥与同步,而不是用于缓存进程间通信的数据。控制信号量的方式有两种原子操作:一个是P操作,这个操作会把信号量减去1,另一个是V操作,这个操作会把信号量加上1。P操作是用在进入共享资源之前,V操作是用在离开共享资源之后,这两个操作是必须成对出现的。初始为0是同步信号量,初始为1是互斥信号量。
5、信号
信号一般用于一些异常情况下的进程间通信,是一种异步通信,它的数据结构一般就是一个数字。信号来源主要是键盘或者命令(比如kill)。crtrl+C就是产生 SIGINT 信号,表示终止该进程;资源管理器结束进程;kill -9 1050,表示给PID为1050的进程发送SIGKILL 信号,用来立即结束该进程
6、socket
socket就是常见的网络编程。跨网络与不同主机上的进程之间通信,就需要Socket通信。
8、程序、进程、线程、协程
进程是程序在某个数据集合上的一次运行活动,也是操作系统进行资源分配和保护的基本单位。
所以程序是静态的,进程是动态的,有生命周期的。
进程的组成:PCB(进程描述符,进程控制管理信息比如阻塞挂起等,资源分配信息,CPU寄存器相关信息)、数据段、程序段。
进程三种基本状态:阻塞(等待某一事件,比如IO完成)、运行、就绪(缺少CPU,比如CPU时间用完)
线程:一个进程可以有很多线程,是轻量级的进程,不同的线程共享进程的资源(内存,IO等),没有自己的地址空间,但有自己的堆栈和局部变量。线程是处理器调度的基本单位,而进程是资源分配的基本单位。
比如浏览器是一个进程,其中的HTTP 请求线程、事件响应线程、渲染线程等等,所以线程并发程度比进程高,同时由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,需要较大的时空开销,而线程相对开销小。从属于不同进程的线程间切换,它是会导致进程切换的,所以开销也大
缺点:一个线程崩溃会影响其他线程,所以健壮性不够。
协程:协程是一个用户态的轻量级线程。线程是同步的,协程是异步的。
进程线程的痛点是涉及到线程阻塞状态和可运行状态之间的切换,同步锁,上下文切换。比如JDBC,数据库是最大性能瓶颈,因为是同步阻塞的,线程占用的CPU一直在空转。
协程切换:当出现IO阻塞的时候,协程调度切换时,将数据流立刻yield掉(主动让出),将寄存器上下文和栈保存到其它地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,且其他协程可以继续运行,不会使整个线程阻塞住;
第二是可以不加锁的访问全局变量,所以上下文的切换非常快,因为协程都是属于一个线程的,不存在同时写变量冲突。
临界资源:一次仅允许一个进程使用的资源称为临界资源。许多物理设备都属于临界资源,如打印机等。访问临界资源的那段代码称为临界区
10. 二叉搜索树、平衡二叉树、红黑树、B树、B+树
二叉搜索树:为了使查找的平均时间复杂度为logn,性质是左子树节点小于根,右子树节点大于根,同时左右子树也是二叉搜索树,是一个递归定义。特点是中序遍历的话是递增序列。
但是,如果本身是一个递增序列,那么构造的二叉搜索树就退化成链表了,查找复杂度变成O(n)了,所以才有平衡二叉搜索树。
AVL的特点是左右子树的高度差不超过1,左右子树也满足。把插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)。但是频繁旋转会使插入和删除牺牲掉O(logN)左右的时间(为了保持平衡,插入删除元素都要调整二叉树)。
因此,才有了红黑树。
红黑树一些特点:节点是红色或黑色,根节点是黑色;红色节点的孩子是黑色节点;从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
虽然这么构造深意我也不理解,但是是为了从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的,但不是AVL限制那么严格。这么做原因是换来了保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。AVL调整旋转次数就不可预计了。
红黑树虽然减少了树的高度,但是当数据量很大时,树高度还是很高,不适合io级别的操作,更适合内存级别的应用。比如STL中哈希表unordered_map的底层实现就是红黑树,可以实现查找插入删除的复杂度都是logn级别。
那么,适用于io操作的是B树和B+树,适用于数据库的索引
B树就是一个多路的二叉搜索树,B树每个节点有键、数据、指针三部分。每个节点有m-1个元素和2-m个孩子节点,这样就大大减小树的高度,从而减小io操作次数。
B+树是B树的变种,B+树的非叶子结点只保存指针和键,数据保存在叶子结点。B+树在叶子结点添加了指向相邻叶子结点的指针。B+树由于非叶子节点没有数据域,所以能够携带更多的键,所以B+树的层数少,看起来更矮胖一点。那么查询时,B+树所进行的I/O次数更少;由于B+树在叶子结点增加了指向相邻叶子结点的指针,当进行区间查询时,只要沿着指针读取就可以,天然具备排序功能。而B树的索引字段大小相邻近的结点可能隔得很远。
11.深拷贝和浅拷贝
浅拷贝只是复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化;深拷贝是将对象及值复制过来,指向两个独立的地方,两个对象修改其中任意的值另一个值不会改变,这就是深拷贝。
进一步思考,在对对象进行浅拷贝时,如果两个对象都析构函数的话,就会导致多次析构造成崩溃。
同时,在传参时,值传递就是深拷贝,比如vector a作为形参,那么函数里的a变化,不会导致函数外面的a变化,就会发现你的a没变化,因为函数退出时,局部的a已经销毁了。而且深拷贝复制对象时还浪费时间空间,开销很大。如果传vector& a,就是浅拷贝了,只复制了地址。
13、计算机系统开机的过程
第一阶段:BIOS,基本输入输出系统,控制硬件的一段代码,存放在ROM中,无法更改的,断电不消失。其中主要包含了自检程序、系统自动装载程序、IO驱动程序中断服务等。
1.1 BIOS程序首先检查,计算机硬件能否满足运行的基本条件,这叫做**”硬件自检”;**
1.2 **启动顺序:BIOS知道下一阶段的启动程序”具体存放在哪一个设备
第二阶段:主引导记录
BIOS按照”启动顺序”,把控制权转交给排在第一位的储存设备(U盘,硬盘等),然后读取启动设备的主引导记录,存放在最前面的512字节。它主要包含分区表,它的主要作用是,告诉计算机到硬盘的哪一个位置去找操作系统。
第三阶段:**硬盘启动,**计算机的控制权就要转交给硬盘的某个分区
第四阶段,操作系统
控制权转交给操作系统后,操作系统的内核首先被载入内存。以Linux系统为例,内核加载成功后,第一个运行的程序是/sbin/init。它根据配置文件产生init进程。这是Linux启动后的第一个进程,pid进程编号为1,其他进程都是它的后代。
然后,init线程加载系统的各个模块,比如窗口程序和网络程序,直至执行/bin/login程序,跳出登录界面,等待用户输入用户名和密码。
- Linux系统的目录结构及目录的主要功能
我们可以用ls /命令来查看linux的目录。ls就是显示目录下的文件名。/就是根目录,显示根目录下的文件,目录也是文件。

bin: cd bin;ls就可以看到bin目录下的文件。普通用户可以使用的必须的命令的存放目录。比如ls,pwd等等。是二进制文件。
sbin:超级root用户可以使用的系统管理的必须的命令的存放目录。普通用户无法执行。普通用户用$标识,root用#标识。
boot: 引导程序,内核等存放的目录。
dev :是 Device 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。设备文件可以使用mknod命令来创建。想要Linux系统支持某个设备,只要:相应的硬件设备,支持硬件的驱动模块,以及相应的设备文件。
/home:用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,保存了用户自己的配置文件,定制文件,文档,数据等。
/lost+found:看名字就知道是系统崩溃非法关机等文恢复的位置。一般是空的。
/mnt:系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。
/proc: 是 Processes(进程) 的缩写,/proc 是一种伪文件系统,存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器。
/tmp:tmp 是 temporary(临时) 的缩写这个目录是用来存放一些临时文件的。实际上是内存中的,当关机重启后tmp清空了。
/var: 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件、缓冲文件等。
/etc: 是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件。例如,要配置系统开机的时候启动那些程序,配置某个程序启动的时候显示什么样的风格等等。通常这些配置文件都集中存放在/etc目录中,所以想要配置什么东西的话,可以在/etc下面寻找我们可能需要修改的文件。
/lib:lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件(system32目录)。几乎所有的应用程序都需要用到这些共享库。按理说,这里存放的文件应该是/bin目录下程序所需要的库文件的存放地。
/media:linux 系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。比如插入U盘会在里面建一个disk目录,就能通过disk来访问u盘。
/opt:opt 是 optional(可选) 的缩写,这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
/usr这个目录中包含了命令库文件和在通常操作中不会修改的文件。这个目录对于系统来说也是一个非常重要的目录,其地位类似Windows上面的”Program Files”目录
/usr/local这个目录存放的内容,一般都是我们后来自己安装的软件的默认路径
/usr/bin一般存放的只是对用户和系统来说“不是必需的”程序(二进制文件)。
/usr/sbin一般存放用于系统管理的系统管理的不是必需的程序(二进制文件)。
16. XSS攻击是什么?如何避免?
XSS攻击全称跨站脚本攻击(前端注入),注入攻击的本质,是把用户输入的数据当做前端代码执行(比如SQL注入)。
。XSS拼接的是网页的HTML代码,一般而言我们是可以拼接出合适的HTML代码去执行恶意的JS语句。在渲染DOM树的时候,执行了不可预期的JS脚本,从而发生了安全问题。(信息泄露、未授权操作、弹窗关不掉等)
常见的 XSS 攻击有三种:反射型XSS攻击、DOM-based 型XXS攻击以及存储型XSS攻击。
反射型 XSS 一般是攻击者通过特定手法(如电子邮件),诱使用户去访问一个包含恶意代码的 URL,当受害者点击这些专门设计的链接的时候,恶意代码会直接在受害者主机上的浏览器执行。反射型XSS通常出现在网站的搜索栏、用户登录口等地方,常用来窃取客户端 Cookies 或进行钓鱼欺骗。
例子:张三做了一个超链接发给阿伟,超链接地址为:http://www.xxx.com?content= 当阿伟点击这个链接的时候(假设他已经登录xxx.com),浏览器就会直接打开bbb.com,并且把xxx.com中的cookie信息发送到bbb.com。而bbb.com就是张三的非法网站,此时他已经得到了cookie信息。
存储型XSS也叫持久型XSS,主要将XSS代码提交存储在服务器端(数据库,内存,文件系统等),下次请求目标页面时不用再提交XSS代码。当目标用户访问该页面获取数据时,XSS代码会从服务器解析之后加载出来,返回到浏览器做正常的HTML和JS解析执行,XSS攻击就发生了。存储型 XSS 一般出现在网站留言、评论、博客日志等交互处,恶意脚本存储到客户端或者服务端的数据库中。
例子:张三在网站发布了文章,其中包含恶意代码:。
这样,只要你打开文章,就会丢失cookie信息,危害更大。
基于 DOM 的 XSS 攻击是指通过恶意脚本修改页面的 DOM 结构,是纯粹发生前端的攻击。属于前端 JavaScript 自身的安全漏洞。常见于类似JSON转换、翻译等工具区。
防御:1.对用户向服务器提交的信息(URL、关键字、HTTP头、POST数据等)进行检查,仅接受规定长度、适当格式、预期内容,其余的一律过滤。
2.对输入内容的特定字符进行编码,例如表示 html标记的 < > 等符号。
3. 对重要的 cookie设置 httpOnly, 防止客户端通过document.cookie读取 cookie.
4. 确定接收到的内容被规范化,仅包含最小最安全的tag(不含JavaScript),去掉对任何远程内容的引用(尤其是样式表和JavaScript)
17.Cmake怎么用?为什么要用?
为什么要CMAKE工具呢?
我们如果直接把可执行代码给别人运行,可能由于平台不一样无法运行,怎么办呢?就要用make工具,实际上make工具有很多种,而生成的makefile文件形式也千差万别,所以,CMAKE出现,允许开发者编写一种平台无关的 CMakeList.txt 文件来定制整个编译流程,然后再根据目标用户的平台进一步生成所需的本地化 Makefile 和工程文件。所以编译流程是先写 CMakeList.txt ,再cmake 路径生成makefile文件,再make一下生成可执行文件、动态库静态库等文件。实现写一次就可以运行在任何系统上。
CMakeList.txt 主要内容有
cmake_minimum_required(VERSION 3.0) //最小版本
project(sylar) //工程名字
set(CMAKE_VERBOSE_MAKEFILE ON)
set(CMAKE_CXX_FLAGS "$ENV{CXXFLAGS} -rdynamic -O3 -fPIC -ggdb -std=c++11 -Wall -Wno-deprecated -Werror -Wno-unused-function -Wno-builtin-macro-redefined -Wno-deprecated-declarations") #C++标准。比如-fPIC代表生成动态库,-O3优化级别,-ggdb可以用gdb调试
set(LIB_SRC
sylar/log.cc
) # 设置要编译的源文件
add_library(sylar SHARED ${LIB_SRC}) #编译成动态库 把log源文件编译成动态库,这样就可以给test的main函数用
#add_library(sylar_static STATIC ${LIB_SRC})
#SET_TARGET_PROPERTIES (sylar_static PROPERTIES OUTPUT_NAME "sylar")
add_executable(test tests/test.cc) #编译成可执行文件,将test源文件编译成可执行文件
add_dependencies(test sylar)
SET(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin) #设置可执行文件的存储路径,一般就在bin目录下
SET(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/lib) #设置动态库文件的存储路径,一般在lib文件下
总结一下,就是设置要编译的源文件、要生成的动态库静态库,可执行文件,设置生成文件的存储位置等。
18.堆和栈的区别
首先,从内存管理角度看。在C++中,内存分为几个区:内核区域、栈、堆、全局/静态存储区(初始化和未初始化)、常量存储区。堆和栈相向生长。一般堆空间大一点,栈空间小。
堆的内存分配是程序员控制的(malloc,new),申请时,系统遍历一个记录空闲区域地址的链表,找到第一个符合条件的,所以分配不连续,会产生碎片;栈是系统自动分配的,是连续的。
栈一般存储返回地址、局部变量、参数等。堆的话程序员自己控制。
形象一点,栈就是饭店点菜,不用烧不用洗碗,高效方便但是自由度小;堆就是自己烧,麻烦效率低还有可能内存泄漏,但是自由度大。
20 计算机存储系统层次
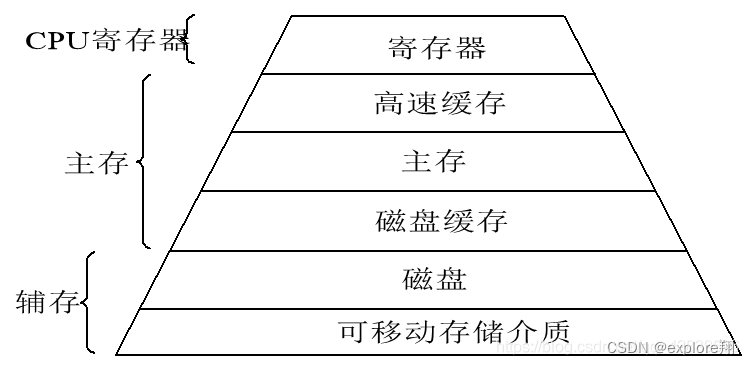
介绍几种存储介质
ram,随机存取,特点是断电后数据消失。分为sram和dram,前者更快,用双稳态电路,造价高,后者电容存储电荷表示0,1,电容会放电,所以需要刷新。
rom,只读存储,断电不消失,做外存。后来各种升级,flash等。
寄存器最快,用的ram或者dff等,不太了解;
高速缓存基本用sram,主存一般用dram。高速缓存的存在是解决CPU速度和内存速度的速度差异问题。利用时空局部性。而磁盘缓存是减少内存访问IO的次数,提高效率。
先到一级缓存中找,找不到再到二级缓存中找,如果还找不到就只有到内存中找了,再不行再到辅存找。
21. 程序装入和链接几种方式
预处理,编译,链接,装入,运行。
绝对装入:只适合单道程序环境。编译后产生绝对的物理地址;
可重定位装入:程序的地址以0开始计算,根据内存起始地址,真实物理地址为内存起始地址加程序中的地址;
动态重定位:可重定位装入不允许程序运行时在内存中移动位置(有点像多态的意思),实际上程序运行时会移动,比如对换技术。所以这种装入内存时依旧是逻辑地址,真正执行时再转换成物理地址,需要重定位寄存器的支持。
静态链接:在装入之前就变成一个完整的模块,已经可以执行了。需要修改相对地址,外部调用符号改成相对地址。
装入时动态链接:外部模块是分开单独存储的。在装入时,发生一个外部模块的调用,才链接。优点是方便修改更新,不用重新打开模块。而且容易实现模块的共享,不然程序很大占空间。
运行时动态链接:执行时才链接,不仅加快装入过程,还节省内存空间。比如错误处理模块,不出错时就不进入内存。
22 内存分配方式
主要分为连续分配和离散分配。
连续分配分为:单一连续,固定分区,动态分区,动态可重定位分区。缺点是产生碎片,紧凑时需要代价;
离散分配(虽然也会有内部碎片):分页,分段,段页结合(最好的)
动态分区分配有一个空闲分区表和空闲链表。分配算法有首次适应、最佳适应、哈希等。动态可重定位分区就是多了一个紧凑的功能,收拾碎片。
页面大小一般在1KB-8KB。太小导致一个进程占用页面太多,页表太大,占用内存,页面换进换出效率低。太大导致业内碎片正大。
这种地址为 :页号+页内偏移地址。
地址转换的过程:硬件完成。页表在内存中**,每个进程都有**,存的页号到块号的映射。页表寄存器存页表始址和页表长度。先判断页号是否超过页表长度。若没有,则利用页表寄存器,通过页表始址+页表项长度*页号找到页表项,得到块号,物理地址=块号+页内地址。
可见,CPU存取一个数据需要两次访问内存,第一次访问页表合成物理地址,第二次访问这个物理地址。比较慢。所以,出现了快表。相当于放在高速缓存中的页表,无则添加,有则直接利用快表给出块号。也是利用了程序的时空局部性。
由于现代计算机的逻辑地址空间很大(2的32到64次方),这样页表就很大,甚至可以到2MB。可以利用两级页表。这样就变成外层页号+外层页内地址+页内地址。其实是一种时间换空间的方法。
而段式管理不是为了内存利用率,而是为了方便用户编程。方便共享。信号保护等。
23 介绍虚拟内存
通过对换技术,允许部分程序放入内存就可执行程序,执行中,不需要的换出,需要的换入。过程对用户是透明的,所以用户感觉内存很大,虚拟内存一般受可寻址的大小和外存大小限制。虚拟内存可提高系统资源利用率,方便用户编程
由于利用局部性原理,所以CPU利用率和内存利用率都更高;
虚拟内存的页表结构
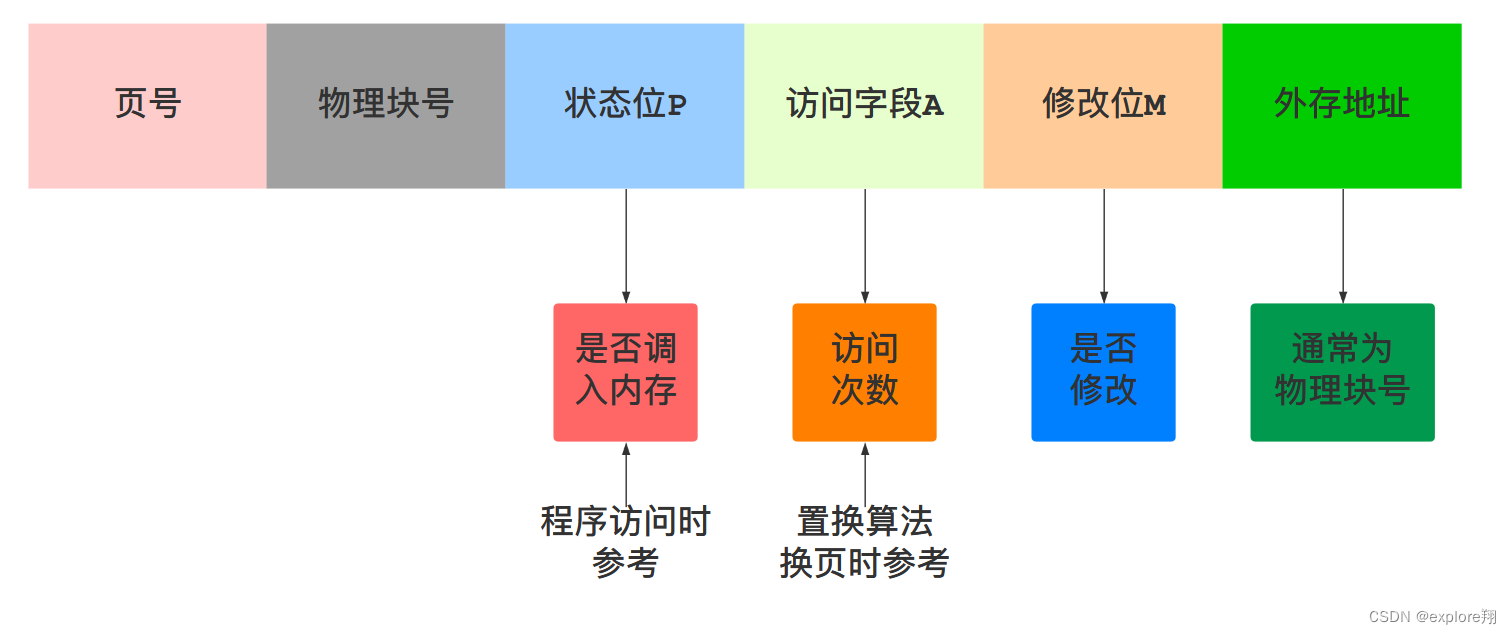
当访问一个不在内存的逻辑地址时,产生缺页中断/缺段中断;OS将阻塞该进程,启动磁盘I/O,如果内存有空闲,装入该页,没有空闲启用置换算法,装入所需的页/段后,将阻塞进程置为就绪态。
虚拟地址和物理地址转换过程前面已经说过了。
虚拟内存管理考虑的算法问题。
读取策略:某一页何时调入内存(请求调入/预调入)。预调入:考虑到启动磁盘的寻道和延迟开销,在调入所需页的同时,也调入若干可能马上访问的页面(通常是所需页的后面几页)
置换策略:
OPT最佳置换:淘汰那些永不再使用或者下次访问距当前时间最长的页面最佳,但不可实现,用于衡量其它置换算法性能。因为不知道未来的情况。
LRU:最近最久未使用算法,淘汰在最近一段时间内最近未使用的一页。以过去预测将来。实现时注意时间戳。
FIFO:先入先出算法。淘汰驻留内存时间最久的一页。Belady异常现象:通常,帧越多则缺页次数越少,但FIFO算法中,有时**,帧越多反而缺页率越高**
简单时钟算法 某进程的所有页面(或整个内存的页框)排成一循环缓冲链;某页被装入或访问时,其使用位U置1 置换时顺序查找循环链,U=0,置换该页,U=1,将U置0,替换指针前移,下次置换时从替换处开始寻找。
抖动:
当系统并发度 ( 多道程序度 ) 过高时,缺页频繁,用 于调页的时间比进程实际运行的时间还多, CPU 利用率急剧下降,此时发生了 抖动
解决:抖动时,挂起 一 些进程,释放它们的帧
预防:L=S 准则:调整并发度,使得 产生缺页的平均时间 ( 即缺页中断之间的平均时间 ) 等于处理 一 次缺页中断的平均时间 ,此时 CPU 利用率最高。
24 前置++和后置++区别和效率
最初始的就是,前置是先自增,再赋值;后置是先赋值再自增。更深入一点的区别是:
++a表示取a的地址,增加它的内容,然后把值放在寄存器中;
a++表示取a的地址,把它的值装入寄存器,然后增加内存中的a的值;
int a=0;
b=++a; //b=1
b=a++; //b=0;
再深入:
对于迭代器和其他模板对象使用前缀形式 (++i) 的自增, 自减运算符.,理由是 前置自增 (++i) 通常要比后置自增 (i++) 效率更高
后置++编译器会生成一个临时空间进行存储,最后返回的也是临时空间的值,前置++不会生成临时对象,直接在原对象上++。
a++是线程安全的吗?
不是,从汇编角度看,他不是原子操作,因为要先找到a的地址,再把它装入寄存器,再把地址中的值加1.一共三个步骤,如果多线程的话,可能线程A还没来得及加1到内存,线程2就开始读,就是脏读。
int a=b是线程安全的吗?
也不是,因为对应两个语句,将b的值放入寄存器,再把寄存器的值放到a的内存。如果执行一半就被另一个线程占用CPU,就会出问题。
解决办法, 设置std::atomic类型。std::atomic value; value=99. 这样就可以避免在多线程编程时加锁,不但麻烦,而且效率还低。 atomic类型变量有一个特点,不可拷贝只能赋值。因为源码里拷贝构造函数delete了。(为什么这么做?可能是在没有原子指令的平台上,需要通过互斥体即不能复制提供原子性,所以。拷贝赋值时不能保证原子性)
29. epoll使用
IO多路复用是什么?
先介绍三种IO模型:阻塞IO,非阻塞IO,IO多路复用。
阻塞IO:所有套接口都是阻塞的。比如read调用必须等到缓冲区有内容才返回,不然一直阻塞在这里;
非阻塞IO:当我们把一个套接口设置为非阻塞时,就是在告诉内核,当请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。不会一直阻塞。
多路复用:此模型用到select poll epoll,这两个函数也会使进程阻塞,select先阻塞,有活动套接字才返回,但是和阻塞I/O不同的是,这两个函数可以同时阻塞多个I/O操作,而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写(就是监听多个socket)。select被调用后,进程会被阻塞,内核监视所有select负责的socket,当有任何一个socket的数据准备好了,select就会返回套接字可读,我们就可以调用recvfrom处理数据。
正因为阻塞I/O只能阻塞一个I/O操作,而I/O复用模型能够阻塞多个I/O操作,所以才叫做多路复用。
为什么epoll最好?
select: 1 由于只知道有几个fd准备好了,所以需要采用轮询的方式找到准备好的fd。所以会随着连接数的增加,性能变低。 2 调用时需要将fdset用用户态拷贝到内核态,遍历时再拷贝回用户空间,判断哪个fd就绪了。 3 fdset只能监视1024个。
poll:主要用链表代替fdset结构,监视数量不受限制了。新增水平触发,这次没处理,下次继续通知。
epoll:空间换时间。没有 fd 个数限制,用户态拷贝到内核态只需要一次,使用时间通知机制来触发。通过 epoll_ctl 注册 fd,一旦 fd 就绪就会通过 callback 回调机制来激活对应 fd,进行相关的 io 操作。
三个函数:
int epoll_create(int size);创建一个 epoll 的句柄(红黑树结构),参数 size 并非限制了 epoll 所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。它就会占用一个 fd 值,在 linux 中查看/proc/进程id/fd/,能够看到这个 fd,所以 epoll 使用完后,必须调用 close() 关闭,否则可能导致 fd 被耗尽。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
事件注册函数,将需要监听的事件和需要监听的 fd 交给 epoll 对象。第一个参数是epoll_create()的返回值,第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的fd,第四个参数是告诉内核需要监听什么事
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout)
等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。如果返回–1,则表示出现错误,需要检查 errno错误码判断错误类型。
要深刻理解epoll,首先得了解epoll的三大关键要素:mmap、红黑树、链表。
epoll是通过内核与用户空间mmap同一块内存实现的。mmap将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址(不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映射映射到物理地址),使得这块物理内存对内核和对用户均可见,减少用户态和内核态之间的数据交换。内核可以直接看到epoll监听的句柄,效率高。
红黑树将存储epoll所监听的套接字。上面mmap出来的内存如何保存epoll所监听的套接字,必然也得有一套数据结构,epoll在实现上采用红黑树去存储所有套接字,当添加或者删除一个套接字时(epoll_ctl),都在红黑树上去处理,红黑树本身插入和删除性能比较好,时间复杂度O(logN)。
当把事件添加进来的时候时候会完成关键的一步,那就是该事件都会与相应的设备(网卡)驱动程序建立回调关系,当相应的事件发生后,就会调用这个回调函数,该回调函数在内核中被称为:ep_poll_callback,这个回调函数其实就所把这个事件添加到rdllist这个双向链表中。一旦有事件发生,epoll就会将该事件添加到双向链表中。那么当我们调用epoll_wait时,epoll_wait只需要检查rdlist双向链表中是否有存在注册的事件,效率非常可观。这里也需要将发生了的事件复制到用户态内存中即可。成功时返回就绪的文件描述符的个数
关于ET、LT两种工作模式:默认情况下,epoll采用 LT模式工作,这时可以处理阻塞和非阻塞套接字,而上表中的 EPOLLET表示可以将一个事件改为 ET模式。ET模式的效率要比 LT模式高,它只支持非阻塞套接字。
当一个新的事件到来时,ET模式下当然可以从 epoll_wait调用中获取到这个事件,可是如果这次没有把这个事件对应的套接字缓冲区处理完,在这个套接字没有新的事件再次到来时,在 ET模式下是无法再次从 epoll_wait调用中获取这个事件的;而 LT模式则相反,只要一个事件对应的套接字缓冲区还有数据,就总能从 epoll_wait中获取这个事件。因此,在 LT模式下开发基于 epoll的应用要简单一些,不太容易出错,而在 ET模式下事件发生时,如果没有彻底地将缓冲区数据处理完,则会导致缓冲区中的用户请求得不到响应。默认情况下,Nginx是通过 ET模式使用 epoll的。
30 QPS,TPS,吞吐量
TPS就是每秒钟处理的事务数。用户一次请求到收到服务器响应。比如双十一一秒完成多少订单。
QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。QPS主要针对查询服务性能指标,不能描述增删改等操作,不建议用QPS描述系统整体性能。所以在最小并发数和最大并发数之间,一定有一个最合适的并发数值,在该并发数下,QPS能够达到最大。但是,这个并发并非是一个最佳的并发,因为当QPS到达最大时的并发,可能已经造成用户的等待时间变得超过了其最优值,所以对于一个系统,其最佳的并发数,一定需要结合QPS,用户的等待时间来综合确定。
假设一个查询功能需要调用N个查询接口
则QPS = N * TPS
吞吐量是指系统在单位时间内处理请求的数量。表现了一个系统的承压能力。
31 为什么有了epoll,非阻塞IO还需要reactor
技术角度,没有反应堆也能达到很高的并发,但是从编程角度,不行。即,某一瞬间,服务器共有10万个并发连接,此时,一次IO复用接口的调用返回了100个活跃的连接等待处理。先根据这100个连接找出其对应的对象,这并不难,epoll的返回连接数据结构里就有这样的指针可以用。接着,循环的处理每一个连接,找出这个对象此刻的上下文状态,再使用read、write这样的网络IO获取此次的操作内容,结合上下文状态查询此时应当选择哪个业务方法处理,调用相应方法完成操作后,若请求结束,则删除对象及其上下文。我们的主程序需要关注各种不同类型的请求,在不同状态下,对于不同的请求命令选择不同的业务处理方法。这会导致随着请求类型的增加,请求状态的增加,请求命令的增加,主程序复杂度快速膨胀,导致维护越来越困难。
反应堆模式可以在软件工程层面,将事件驱动框架分离出具体业务,将不同类型请求之间用OO的思想分离。通常,反应堆不仅使用IO复用处理网络事件驱动,还会实现定时器来处理时间事件的驱动(请求的超时处理或者定时任务的处理)
https://blog.csdn.net/fedorafrog/article/details/113849305具体内容看这篇文章
32. linux交换分区是什么?
是磁盘上的一块区域,可以是一个分区或一个文件,或者是他们组合。当系统物理内存吃紧时,Linux会将内存中不常访问的数据保存到swap上,这样系统就有更多的物理内存为各个进程服务。
比如:一些软件只在启动时需要很大内存,运行时不需要,就可以将这些弄到交换分区;
比如一些休眠功能,就是把内存中的数据保存到 swap 分区上,等下次系统启动的时候,再将数据加载到内存中,这样可以加快系统的启动速度。
比如:在某些情况下,物理内存有限,但又想运行耗内存的程序怎么办?这时可以通过配置足够的 swap 空间来达到目标,虽然慢一点,但至少可以运行。
33.linux普通用户和超级用户
普通用户显示符号位**$**
超级用户显示符号位**#**
普通用户进入超级用户:
输入su root,回车,再输入登陆密码
超级用户切换到普通用户:
su zx (zx是我的普通用户名)
34. vim编辑器使用
1、输入vim 文件名就可以进入文件,不存在的话会新建一个文件;
2、刚进入时是命令模式,vim编辑器会将按键解释成命令,键入i可进入插入模式(a,o也可以进入插入模式)可以编辑代码了,返回命令模式用esc键。
3、x:删除当前光标所在位置的字符 dd:删除当前光标所在行 y复制,p粘贴 可使用/(斜线键)来查找文本
4、命令模式下输入冒号:就进入底行模式。wq 保存并退出vim(最常用)q! 强制退出vim(不保存)set nu 显示行号
切换用户主目录 cd ~ 一般用户的主目录就是home/zx,切换父目录 cd … cd 绝对路径 .代表当前目录
查看当前路径:pwd
如何查看文件内容:cat 文件名 vim 文件名
ls -a显示所有文件包含隐藏文件 ls -l显示文件及其属性(rwx,拥有者,时间戳等)
Linux的touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
touch 文件名 ——创建一个文件
mkdir 目录名 —— 创建一个目录
mkdir -p 目录名1/目录名2/目录名3 ——创建多层级目录
cp 原路径 目标路径 一般复制目录用cp -r 目录名 位置保证目录所有文件都被复制了。
mv 原路径 目标路径
ps 命令是最常用的监控进程的命令,通过此命令可以查看系统中所有运行进程的详细信息。(用户,PID,CPU和内存使用率,运行时间,状态等)
ps aux --sort -%mem按照内存使用率降序排列进程。
还可以通过一个管道给grep查看是否存在特定的进程。
rm 指令 :移除【删除】文件或目录 -r :递归删除整个文件夹
-f : 强制删除不提示 rm -rf要慎用
rmdir只能删除空文件夹
文件查看 head -n tail -n cat ; 长文件用less两边翻页 more可往下翻页
tail命令是实时显示日志文件的最常用解决方案 加上-f参数实时监控日志
ln -s target source 建立软连接,可以用ls -l查看这个文件夹的属性。
A 是 B 的硬链接(A 和 B 都是文件名),则 A 的目录项中的 inode 节点号与 B 的目录项中的 inode 节点号相同,即一个 inode 节点对应两个不同的文件名,两个文件名指向同一个文件,A 和 B 对文件系统来说是完全平等的。删除其中任何一个都不会影响另外一个的访问。
硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。
ln oldfile newfile建立硬链接。
echo命令将输入回显到屏幕上 -e参数表示转义字符会处理比如/n换行。
[root@localhost ~]# read name
Michael Zhang
[root@localhost ~]# echo “My name is $name”
My name is Michael Zhang
通配符
*表示匹配任意长度的任意字符 ?表示任意的一个字符 []表示括号内的匹配。
wc命令的功能为统计指定文件中的字节数、字数、行数, 并将统计结果显示输出。wc -lcw 文件名
-c, --bytes: 统计字节数。
-1,–lines: 统计行数。
-w,–words: 统计字数。
grep命令一般用来筛选数据,用来筛选我们需要的数据
grep [参数] [过滤的规则] [路径] 参数 -i : 忽略大小写 -n : 显示过滤出来的文本在文件内的行号 -v反向查找等等
标准输出 | grep [参数] [过滤规则] 用到了管道
grep -n “root” /etc/passwd 要求过滤出/etc/passwd中包含的root的行及其行号
linux进程几种状态:用ps top可以查看。S栏就是状态的意思。S 列可以看到 R、D、S、I 、Z 几个状态
R 是 Running,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
D是Disk Sleep 的缩写,也就是不可中断状态睡眠,一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。获得资源后才能运行。
Z 是 Zombie 的缩写,它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源
S 是 InterrupTIble Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
:I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上
如何让一个任务在后台执行:&加在一个命令的最后,可以把这个命令放在后台执行
jobs用于查看当前终端后台运行的任务
ctrl+Z也可以将一个正在前台执行的命令暂停,并且放到后台(不过在后台是暂停stop的)
fg命令 将后台中的命令调至前台继续运行 如果后台中有多个命令,可以先用jobs查看jobnun,然后用 fg %jobnum 将选中的命令调出。
bg命令 将一个在后台暂停的命令,变成在后台继续执行,比如crtl+Z之后的那个进程。
kill命令:结束进程 通过jobs命令查看jobnum,然后执行 kill %jobnum 或者通过ps命令查看进程号PID,然后执行 kill %PID 如果前台进程的话直接crtl+C就可以终止了。
linux搜索文件最强大命令:find
find 指定目录 指定条件 指定动作
比如使用find命令搜索在根目录下的所有interfaces文件所在位置,命令格式为”find / -name ‘interfaces’
还有别的locate whereis等。
查看使用过的命令 history
history 5查看近5条命令
删除序号为 534 的历史命令 history -d 534
history -c清空历史
命令who的功能较简单,仅显示用户登录名、终端标志、和登录日期和时间 w显示更多用户正在执行的程序、占用CPU时间、系统的运行时间和平均负载
命名who am i 最简单,仅显示当前用户正使用的终端和登录时间,例如:
[francis@localhost ~]$ who am i
francis pts/2 2010-04-19 10:29
df 是检查Linux安装程序上可用分区空间的最常用的命令之一。可以使用“df -TH”以直观易读的格式打印分区类型和分区大小。此命令将显示每个部分的总可用空间、已用空间和可用空间。
du查看目录大小,df查看磁盘使用情况。du是通过搜索文件来计算每个文件的大小然后累加,du能看到的文件只是一些当前存在 。文件被删除不是立马就消失了,当所有程序都不用时,才会根据OS的规则释放掉已经删除的文件。
查看Linux服务器网络连接的方法:1、在Linux服务器终端可使用ifconfig命令显示所有网络接口的详细情况;2、在Linux服务器终端可使用ping命令检查网络上某台主机是否正常工作;3、在Linux服务器终端可使用netstat命令显示网络连接、路由表和网络接口的相关信息。
环境变量
env命令可以显示当前操作系统所有的环境变量 使用 echo 命令查看单个环境变量,例如:echo $PATH
$ export TEST="Test..." # 增加一个环境变量 TEST
$ env|grep TEST # 此命令有输入,证明环境变量 TEST 已经存在了
TEST=Test...
unset TEST # 删除环境变量 TEST
$ env|grep TEST # 此命令没有输出,证明环境变量 TEST 已经删除
按照变量的生存周期划分,Linux 变量可分为两类:
永久的:需要修改配置文件,变量永久生效。
临时的:使用 export 命令声明即可,变量在关闭 shell 时失效。
在 Linux 中设置环境变量有三种方法:
所有用户永久添加环境变量: vi /etc/profile,在 /etc/profile 文件中添加变量。source /etc/profile # 激活后,环境变量才可永久生效
当前用户永久添加环境变量: vi ~/.bash_profile,在用户目录下的 ~/.bash_profile 文件中添加变量。
临时添加环境变量 PATH: 可通过 export 命令,如运行命令 export PATH=/usr/local/cuda/lib64:$PATH,将 /usr/local/cuda/lib64 目录临时添加到环境变量中。查看是否已经设置好,可用命令 export 查看。
37.同源策略和跨域问题
同源策略是浏览器安全功能,阻止一个域的js脚本和另一个域的内容进行交互,用于隔离潜在恶意文件,防止恶意网站窃取用户数据(不同源的网页不能共享cookie,获取dom,ajax请求)
当协议(http,https)域名(cc.com)端口号有一个不同就是跨域;
几乎任何时候安全性和便捷性都是负相关的,所以浏览器做了平衡,比如img,script,style等允许跨域引用,但是引用并不能读取资源的内容。
常见的几种磁盘调度算法
读写一个磁盘块的时间的影响因素有:
旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)
寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
实际的数据传输时间
其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短
1.先来先服务。寻道时间长
2.最短寻道时间优先,优先调度与当前磁头所在磁道距离最近的磁道。两端容易出现饥饿现象。
3、电梯调度算法。电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
抖动现象理解
刚刚换出的页面马上又要换入内存,刚刚换入的页面马上又要换出外存,这种频繁的页面调度行为称为抖动,或颠簸。产生抖动的主要原因是进程频繁访问的页面数目高于可用的物理块数(分配给进程的物理块不够)
为进程分配的物理块太少,会使进程发生抖动现象。为进程分配的物理块太多,又会降低系统整体的并发度,降低某些资源的利用率 为了研究为应该为每个进程分配多少个物理块,Denning 提出了进程工作集” 的概念
为什么栈比堆快?
1.分配方式看,栈是后入先出,有严格顺序,堆需要在空闲链表找一段合适的空间需要时间的;2、栈有CPU支持的命令push pop
经常是和寄存器相关的,把寄存器值入栈。;3 访问来看,堆需要两次访问内存,一次指针一次数据,栈只要一次。
常见内存分配内存错误
内存分配未成功就使用,概率较小;
内存未初始化就使用,比如局部变量必须初始化,堆上的变量,全局变量会自动初始化0,不过最好还是自己初始化;
下标越界,经常出现的;
忘记释放内存(内存泄漏):经常出现,比如忘记free或者delete,delete[],比如基类析构函数没用虚函数;
多次释放内存:程序中的对象调用关系过于复杂;比如返回值是局部对象的引用或指针,但是这个局部对象返回就销毁了,是野指针,使用free或delete释放了内存后,没有将指针设置为NULL。导致产生“野指针”(内存没了,指针变量依然存在);比如禁用了拷贝构造函数,在对象有指针成员时,默认的拷贝是位拷贝,把指针复制一遍,浅拷贝,那么析构的时候就会多次释放同一内存。
ASCII、Unicode和UTF-8编码的区别?
ASCII 只有127个字符,表示英文字母的大小写、数字和一些符号,但由于其他语言用ASCII 编码表示字节不够,一个字节表示一个字符。
由于每个国家的语言都有属于自己的编码格式,在多语言编辑文本中会出现乱码,这样Unicode应运而生,Unicode就是将这些语言统一到一套编码格式中,通常两个字节表示一个字符,而ASCII是一个字节表示一个字符,这样如果你编译的文本是全英文的,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
为了解决上述问题,又出现了把Unicode编码转化为“可变长编码”UTF-8编码,UTF-8编码将Unicode字符按数字大小编码为1-6个字节,英文字母被编码成一个字节,常用汉字被编码成三个字节,如果你编译的文本是纯英文的,那么用UTF-8就会非常节省空间,并且ASCII码也是UTF-8的一部分
原子操作的是如何实现的
CAS吗?
处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。
所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
但总线锁定把CPU和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大。频繁使用的内存会缓存在处理器的L1、L2和L3高速缓存里,那么原子操作就可以直接在处理器内部缓存中进行。当一个处理器修改了缓存,就会设置缓存行无效,其他的就无法修改了。这和CAS类似,CAS就是乐观锁,先尝试修改,如果发现已经被修改了,放弃修改。只不过原子操作实现是操作系统的,而且基于缓存,所以更快一些。
页面置换算法
最佳置换算法(OPT,Optimal) :每次选择淘汰的页面将是以后永不使用,或者在最长时间内不再被访问的页面,这样可以保证最低的缺页率。但是理想情况,无法实现。
先进先出置换算法(FIFO) :每次选择淘汰的页面是最早进入内存的页面 实现方法:把调入内存的页面根据调入的先后顺序排成一个队列。FIFO的性能较差,因为较早调入的页往往是经常被访问的页,这些页在FIFO算法下被反复调入和调出,并且有Belady现象。所谓Belady现象是指:采用FIFO算法时,如果对—个进程未分配它所要求的全部页面,有时就会出现分配的页面数增多但缺页率反而提高的异常现象
最近最久未使用置换算法(LRU,least recently used) :每次淘汰的页面是最近最久未使用的页面 实现方法:赋予每个页面对应的页表项中,用访问字段记录该页面自.上次被访问以来所经历的时间t(该算法的实现需要专门的硬件支持,虽然算法性能好,但是实现困难,开销大)。当需要淘汰一个页面时,选择现有页面中t值最大的,即最近最久未使用的页面。
LRU性能较好,但需要寄存器和栈的硬件支持。
(注意对于MySQL 和 Linux 操作系统是通过改进 LRU 算法来避免「预读失效和缓存污染」而导致缓存命中率下降的问题。
即活跃LRU和非活跃LRU,并且非活跃到活跃条件严格一点,不仅仅要活跃一次
注意手写LRU算法的实现。)
分析:为什么用哈希表+双向链表?
首先要分析需求,主要是put,get操作。LRU缓存:要求添加元素时判断是否存在,存在的话要找到它移动到头部,找不到就添加到头部;获取元素也要判断是否存在,存在的话就返回元素并移动到头部,不在的话添加元素到头部。
所以两大核心操作就是:判断元素是否存在,以及移动元素。判断元素的存在并找到位置很适合用_unordered_map。
而移动元素适合用链表,所以综合一下就是 unordered_map<int, DoubleList*> memory; 为什么是双向链表呢?因为涉及到删除中间某个元素,如果是单链表还需要从头找到前一个元素,线性复杂度,双向链表只要prev指针就能找到。
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
struct DoubleList {
int key, val;
DoubleList* pre, * next;
DoubleList(int _key,int _val):key(_key),val(_val),pre(nullptr),next(nullptr){ }
};
class LRU {
private:
int capacity;
DoubleList* head, * tail;
unordered_map<int, DoubleList*> memory;
public:
LRU(int _capacity) {
this->capacity = _capacity;
head = new DoubleList(-1, -1);
tail = new DoubleList(-1, -1);
head->next = tail;
tail->pre = head;
}
~LRU(){
if (head != nullptr) {
delete head;
head = nullptr;
}
if (tail != nullptr) {
delete tail;
tail = nullptr;
}
for (auto& a : memory) {
if (a.second != nullptr) {
delete a.second;
a.second = nullptr;
}
}
}
void set(int _key, int _val) {
if (memory.find(_key) != memory.end()) {
DoubleList* node = memory[_key];
removeNode(node);
node->val = _val;
pushNode(node);
return ;
}
if (memory.size() == this->capacity) {// 这里很重要,也很爱错,千万记得更新memory
int topKey = head->next->key;//取得key值,方便在后面删除
removeNode(head->next);//移除头部的下一个
memory.erase(topKey);//在memory中删除当前头部的值
}
DoubleList* node = new DoubleList(_key, _val);//新增node
pushNode(node);//放在尾部
memory[_key] = node;//记得在memory中添加进去
}
int get(int _key) {
if (memory.find(_key) != memory.end()) {
DoubleList* node = memory[_key];
removeNode(node);
pushNode(node);
return node->val;
}
return - 1;
}
void removeNode(DoubleList* node) {
node->pre->next = node->next;
node->next->pre = node->pre;
}
void pushNode(DoubleList* node) {
tail->pre->next = node;
node->pre = tail->pre;
node->next = tail;
tail->pre = node;
}
};
时钟置换算法是一种性能和开销较均衡的算法,又称CLOCK算法,或最近未用算法(NRU,Not Recently Used)为每个页面设置一个访问位,再将内存中的页面都通过链接指针链接成一个循环队列。当某页被访问时,其访问位置为1。当需要淘汰-一个页面时,只需检查页的访问位。如果是0,就选择该页换出;如果是1,则将它置为0,暂不换出,继续检查下一个页面。
在其他条件都相同时,应优先淘汰没有修改过的页面,避免I/O操作。这就是改进型的时钟置换算法的思想。
LFU算法:这是redis用的页面替换算法,防止LRU出现缓存污染。根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。 LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。
38.对虚拟内存的理解
单片机是没有操作系统的,所以每次写完代码,都需要借助工具把程序烧录进去,这样程序才能跑起来。并且单片机的 CPU 是直接操作内存的**「物理地址」。要想在内存中同时运行两个程序是不可能的。如果第一个程序在 2000 的位置写入一个新的值,将会擦掉第二个程序存放在相同位置上的所有内容,所以同时运行两个程序是根本行不通的,这两个程序会立刻崩溃。
如何解决?
我们可以把进程所使用的地址「隔离」开来,即让操作系统为每个进程分配独立的一套「虚拟地址」,人人都有,大家自己玩自己的地址就行(虚拟地址),互不干涉。但是有个前提每个进程都不能访问物理地址,至于虚拟地址最终怎么落到物理内存里,对进程来说是透明的,操作系统已经把这些都安排的明明白白了。操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。主要有两种方式,分别是内存分段和内存分页
分段管理
程序是由若干个逻辑分段组成的,如可由代码分段、数据分段、堆段、栈段**组成。不同的段是有不同的属性的,所以就用分段(Segmentation)的形式把这些段分离出来。
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量。
段选择因子里面有段号,可以通过它寻找段表中对应的段基址,然后加上偏移量就是物理地址了。
缺点:
内存碎片和内存交换效率低的问题。内存分段管理可以做到段根据实际需求分配内存,所以有多少需求就分配多大的段,所以不会出现内部内存碎片。但是会出现外部碎片,很多小块的内存分散,无法被利用。解决「外部内存碎片」的问题就是内存交换。这个内存交换空间,在 Linux 系统里,也就是我们常看到的 Swap 空间,这块空间是从硬盘划分出来的,用于内存与硬盘的空间交换。因为硬盘的访问速度要比内存慢太多了,每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个占内存空间很大的程序,这样整个机器都会显得卡顿。(swap分区的作用就是在物理内存不够时,将一些不用的程序移到swap分区中,要用时再进入内存,有可能不是原来的物理内存位置了,因为有内存交换紧凑碎片)
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。会出现页内碎片。
虚拟地址与物理地址之间通过页表来映射,CPU将地址解释为页号和偏移量,页表保存页号和物理块号的映射。
缺点:内部碎片;因为操作系统是可以同时运行非常多的进程的,那这不就意味着页表会非常的庞大。在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。(可以用多级页表解决)
多级页表对导致映射过程变复杂,时间开销大。所以有TLB快表。把最常访问的几个页表项存储到访问速度更快的硬件,于是计算机科学家们,就在 CPU 芯片中,加入了一个专门存放程序最常访问的页表项的 Cache,这个 Cache 就是 TLB(Translation Lookaside Buffer)。有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的页表。TLB 的命中率其实是很高的,因为程序最常访问的页就那么几个。
linux虚拟内存空间分布
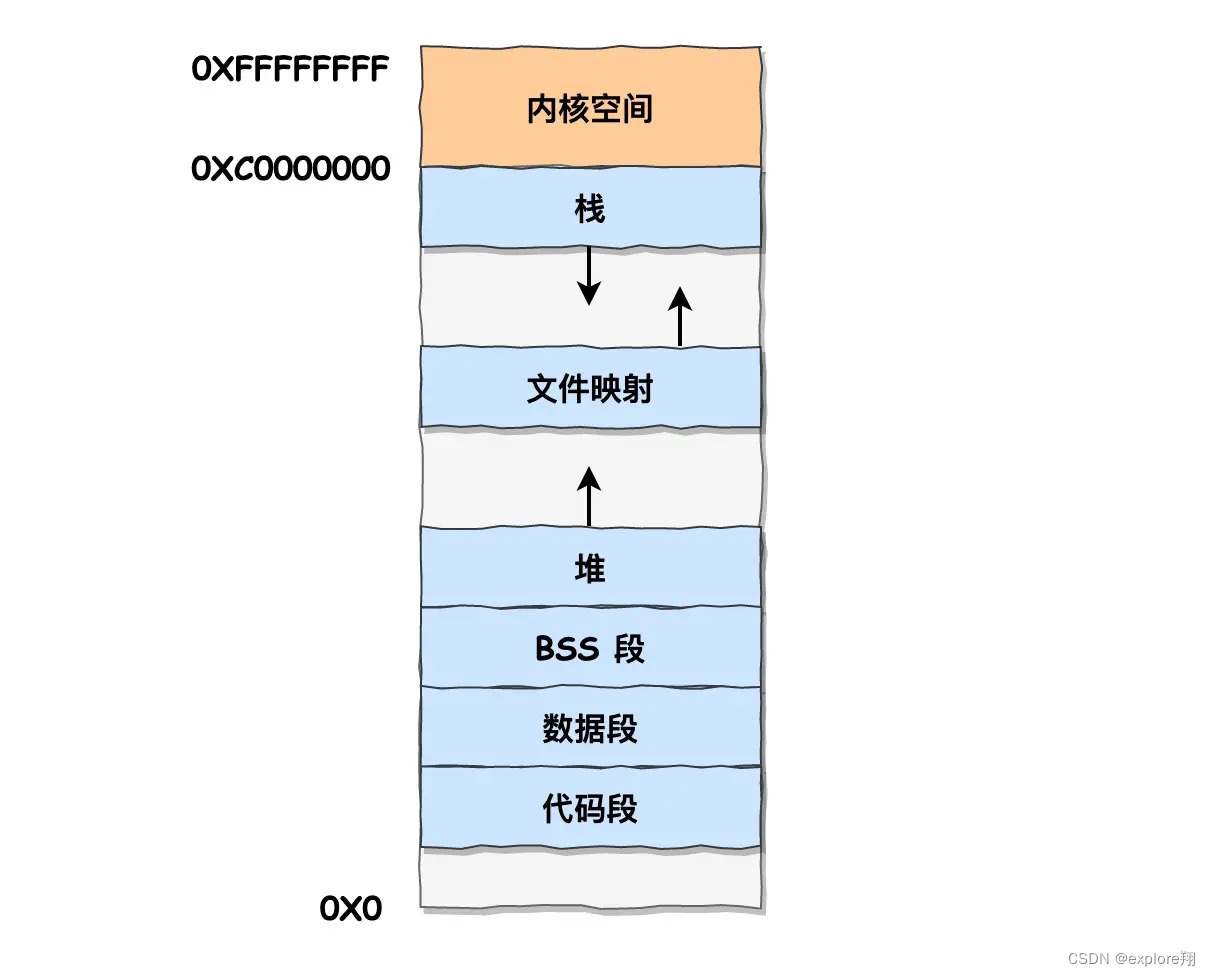
文件映射段,包括动态库、共享内存等。
代码段下面还有一段内存空间的(灰色部分),这一块区域是「保留区」,之所以要有保留区这是因为在大多数的系统里,我们认为比较小数值的地址不是一个合法地址,例如,我们通常在 C 的代码里会将无效的指针赋值为 NULL。因此,这里会出现一段不可访问的内存保留区,防止程序因为出现 bug,导致读或写了一些小内存地址的数据,而使得程序跑飞。
堆:注意和数据结构中堆不一样,联系malloc原理。如果分配空间小于128k用brk方法,就是堆顶指针移动,比如你需要10K,可能分配不止10K,是100多k,其余的会被放到内存池。因为堆组织方式类似于链表,频繁malloc/free产生内存碎片。释放资源也是回到内存池
如果空间大于128k,就会调用mmap()系统调用,会从内存映射区直接取一段空间,避免产生内存碎片。但是会有状态切换以及缺页中断(malloc使用时才会分配物理内存)。释放资源被操作系统回收,这也是需要时间的。
所以二者结合使用
ulimit -a #查看栈大小,一般8M
ulimit -s 32768 # 设置当前栈的大小为32M
总结虚拟内存作用:
1、最主要的就是为了实现多进程。由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的,解决了多进程之间地址冲突的问题。
2、在多进程时,内存空间可能不够用,就需要虚拟内存的换入换出技术,swap。将硬盘空间当成内存,让用户感觉内存很大。
3、段中有优先级等,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
39. 在4GB物理内存的机器上申请8GB内存空间会怎样
在 32 位操作系统,因为进程理论上最大能申请 3 GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
在 64位 位操作系统,因为进程理论上最大能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有 Swap 分区:
如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是 OOM(内存溢出);
如果有 Swap 分区,即使物理内存只有 4GB,程序也能正常使用 8GB 的内存,进程可以正常运行;
40 如何避免预读失效和缓存污染的问题?
传统的 LRU 算法存在这两个问题:
「预读失效」导致缓存命中率下降(操作系统读磁盘时会多读一些没用的数据)
「缓存污染」导致缓存命中率下降(批量读数据可能会把热点数据挤出去)
Redis 的缓存淘汰算法则是通过实现 LFU 算法来避免「缓存污染」而导致缓存命中率下降的问题(Redis 没有预读机制)。
MySQL 和 Linux 操作系统是通过改进 LRU 算法来避免「预读失效和缓存污染」而导致缓存命中率下降的问题。
预读失效:由于空间局部性,如果想要0-4KB的数据,很可能把后面的8-16KB都读到缓存中,如果使用传统的 LRU 算法,就会把「预读页」放到 LRU 链表头部,而当内存空间不够的时候,还需要把末尾的页淘汰掉。
如果这些「预读页」如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率 。
我们不能因为害怕预读失效,而将预读机制去掉,大部分情况下,空间局部性原理还是成立的。
要避免预读失效带来影响,最好就是让预读页停留在内存里的时间要尽可能的短,让真正被访问的页才移动到 LRU 链表的头部,从而保证真正被读取的热数据留在内存里的时间尽可能长。
Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list);
MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
这两个改进方式,设计思想都是类似的,都是将数据分为了冷数据和热数据,然后分别进行 LRU 算法。不再像传统的 LRU 算法那样,所有数据都只用一个 LRU 算法管理。
有了这两个 LRU 链表后,预读页就只需要加入到 inactive list 区域的头部,当页被真正访问的时候,才将页插入 active list 的头部。如果预读的页一直没有被访问,就会从 inactive list 移除,这样就不会影响 active list 中的热点数据。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
当我们在批量读取数据的时候,由于数据被访问了一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
当某一个 SQL 语句扫描了大量的数据时,在 Buffer Pool 空间比较有限的情况下,可能会将 Buffer Pool 里的所有页都替换出去,导致大量热数据被淘汰了,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 I/O,MySQL 性能就会急剧下降。
前面的 LRU 算法只要数据被访问一次,就将数据加入活跃 LRU 链表(或者 young 区域),**这种 LRU 算法进入活跃 LRU 链表的门槛太低了!**只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉。Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
41.count(1),count( ),count(字段),select(1),select ( )效率比较
首先说一下select(1),select ( )。
select(1)主要用于查询表中是否有符合条件的记录(比如select 1 from seckill where id = 1001;),select 1一般用来当作条件使用,比如**exists( select 1 from 表名)**等;select 1配合count()、sum()函数。select 1的效率比select 列名和select快,因为不用查字典表。(为什么这么说,参数是 1,不是字段,所以不需要读取记录中的字段值。参数 1 很明显并不是 NULL,因此 server 层每从 InnoDB 读取到一条记录,就将 count 变量加 1。)
而select * from … 是返回所有行的所有列,性能很差,不推荐用。性能差的原因有:1 不需要的列会增加数据传输时间和网络开销(需要解析更多的对象、字段、权限、属性等相关内容,一些大的文本字段开销很大传输)2.大字段还会增加IO操作;3 失去MySQL优化器“覆盖索引”策略优化的可能性。如果用户使用select *,获取了不需要的数据,则首先通过辅助索引过滤数据,然后再通过聚集索引获取所有的列,这就多了一次b+树查询,速度必然会慢很多。而聚集索引很可能数据在磁盘(外存)中(取决于buffer pool**的大小和命中率),这种情况下,一个是内存读,一个是磁盘读,速度差异就很显著了,几乎是数量级的差异。
(覆盖索引是指 SQL 中 query 的所有字段,在索引 B+Tree 的叶子节点上都能找得到的那些索引,从二级索引中查询得到记录,而不需要通过聚簇索引查询获得,可以避免回表的操作。)
count(1),count( *),count(字段)

在通过 count 函数统计有多少个记录时,MySQL 的 server 层会维护一个名叫 count 的变量。
server 层会循环向 InnoDB 读取一条记录,如果 count 函数指定的参数不为 NULL,那么就会将变量 count 加 1,直到符合查询的全部记录被读完,就退出循环。最后将 count 变量的值发送给客户端。
count(1),count( *),InnoDB 循环遍历聚簇索引(主键索引)或二级索引,将读取到的记录返回给 server 层,但是不会读取记录中的任何字段的值,所以效率高一点。
count(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。
使用 count(字段) 来统计记录个数,因为它的效率是最差的,会采用全表扫描的方式来统计。如果你非要统计表中该字段不为 NULL 的记录个数,建议给这个字段建立一个二级索引。
使用 MyISAM 引擎时,执行 count 函数只需要 O(1 )复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息有存储了row_count值,由表级锁保证一致性,所以直接读取 row_count 值就是 count 函数的执行结果。
而 InnoDB 存储引擎是支持事务的,同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的,所以无法像 MyISAM一样,只维护一个 row_count 变量。
如何优化 count(*)
就可以使用 show table status 或者 explain 命令来表进行估算,不会真正查表;
或者每新插入一个记录就将计数表中的计数字段 + 1。也就是说,在新增和删除操作时,我们需要额外维护这个计数表。
static关键字的作用
最主要的是隐藏和对象共享某一数据功能。
作用在局部变量,使其存储在静态区(包括全局,静态),和程序生命一样长;作用在全局变量主要是其他文件不能引用它,防止不同文件重名的干扰;作用在成员变量,成为类的一部分,公共部分比如总数,只能在类外初始化不能在构造函数初始化。作用在成员函数主要是为了访问静态成员变量,只能访问它,因为没有this指针。
静态链接和动态链接
程序的几个步骤就是预处理,编译,汇编,链接,装入,运行。链接主要完成符号解析和重定位功能,如果在编译汇编时就完成链接,就是静态链接,如果这一步只添加参数信息,推迟到运行时链接,就是动态链接。
举个例子 test.c main.c源文件,静态链接方法
gcc -c test.c main.c -o test.o main.o
ar -rv test.lib test.o main.o
gcc test.lib -o test.exe
动态链接方法
gcc test.c -shared -o test.dll
gcc main.c test.dll -o test.exe
静态链接使每个进程都包含完整的库代码副本,比较占空间,且一个库修改就要重新编译整个代码。优点就是发布方便,可独立运行,不需要动态库依赖,前期编译速度快一点。动态链接相反,耦合度小,适合大项目。
变量声明和定义
变量声明不分配内存,可声明多次(extern int a),定义分配内存只有一次(int a,int a=1)
#ifdef 标识符
程序1
#else
程序2
#endif
条件编译
#idndef aaa
#define aaa 2
##endif 解决双重define嵌套问题
C++中类成员的访问权限****三种继承方式
**函数声明(函数原型)、函数调用、函数定义:**函数声明一般放在头文件中,没有函数体的,规定了参数和返回类型,参数名可以忽略,不开辟空间,目的是告诉编译器这是一个函数,在函数调用时编译器帮你检查函数写没写对。函数定义有函数体。函数调用不用写返回类型和参数类型。
多态的实现有哪几种?
多态分为静态多态和动态多态。其中,静态多态是通过重载和模板技术实现的,在编译期间确定;动态多态是通过虚函数和继承关系实现的,执行动态绑定,在运行期间确定。
重载和重写的区别:
是指同一可访问区内被声明的几个具有不同参数列(参数的类型,个数,顺序不同)的同名函数,根据参数列表确定调用哪个函数,重载不关心函数返回类型。
#include<bits/stdc++.h>
using namespace std;
class A
{
void fun() {};
void fun(int i) {};
void fun(int i, int j) {};
void fun(double i){};
};
重写(覆写)
是指派生类中存在重新定义的函数。其函数名,参数列表,返回值类型,所有都必须同基类中被重写的函数一致。只有函数体不同(花括号内),派生类调用时会调用派生类的重写函数,不会调用被重写函数。重写的基类中被重写的函数必须有virtual修饰。
#include<bits/stdc++.h>
using namespace std;
class A
{
public:
virtual void fun()
{
cout << "A";
}
};
class B :public A
{
public:
virtual void fun()
{
cout << "B";
}
};
int main(void)
{
A* a = new B(); 基类的指针指向派生类的对象,指向的是派生类中基类的部分。
所以只能操作派生类中从基类中继承过来的数据和基类自身的数据。C++的多态性可以解决基类指针不能操作派生类的数据成员的问题。
a->fun();//输出B
}
乐观锁、悲观锁的概念实现及应用场景
什么是悲观锁?使用场景是什么?
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。
也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
像 Java 中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
悲观锁通常多用于写多比较多的情况下(多写场景),避免频繁失败和重试影响性能。
什么是乐观锁?使用场景是什么?
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法)。
在 Java 中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS 实现的。
乐观锁通常多于写比较少的情况下(多读场景),避免频繁加锁影响性能,大大提升了系统的吞吐量。
版本号:一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
CAS 的思想很简单,就是用一个预期值和要更新的变量值进行比较,两值相等才会进行更新。
CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
CAS 涉及到三个操作数:
V :要更新的变量值(Var)
E :预期值(Expected)
N :拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了V,则当前线程放弃更新。
乐观锁的问题:
ABA问题:一开始是1,中间改成6,后来有改成1,这时是可以更新的,但是确实被修改过
循环开销大:CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。可以用pause指令来优化,不用循环。
只能保证一个共享变量的原子操作
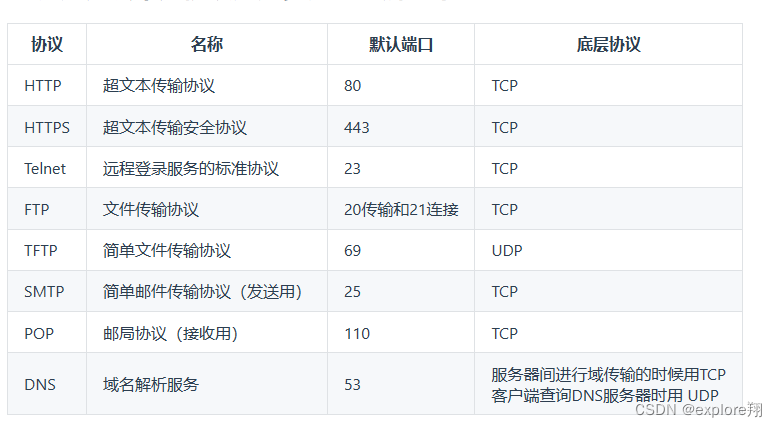
说一下常用的应用层协议
struct可以定义函数吗?
在C++中,class和struct是同样的东西
区别仅仅在于class中的成员函数和变量如果不指定访问类型的话,缺省是private的,而struct中的成员函数和变量如果不知定访问类型,缺省是public的而已
其他的都是一样的了,所以struct可以有任何函数(构造、析构也包括在内)
关于右值引用和转移构造
左值:变量,可以长时间保存,可以存在于=左边的值,可以取地址;
右值:临时值,不能存在于=左边的值,不可以取地址。常数、表达式、函数返回值。
int &t = a; // a为左值,所以可以赋给左值引用
// int &t1 = 3; // 错误 3为一个临时值,为右值,不能赋给左值引用
// int &&t = a; // 错误 a为左值,不能赋给右值引用
int &&t = 3; // 可以
int &&t = -a; // 可以
,C++11提供了更为优雅的转换函数std::move,std::move(a)无论a是左值还是右值都将转换为右值。就是将传入值强制转换为值原类型的右值引用。
常量右值引用没有用途。非常量右值引用可以用于移动语义,完美转发。
当右值引用作为构造函数参数时,这就是所谓的移动构造函数,也就是所谓的移动语义。
在返回对象时,需要拷贝构造函数,生成一个临时对象,再把临时对象拷贝给接收的变量,有一次拷贝是多余的。当堆内存很大时,多余的深拷贝以及其对象的堆内存析构耗时就会变的很可观,那么是否有一种方式,可以让函数中的返回的临时对象空间是否可以不析构,而可以重用呢?
基于上述原因,因此c++11提供了移动构造来解决上述问题。移动构造也是基于右值引用来实现的。
成员初始化列表的概念,为什么用它会快一些?
初始化列表只用了一次自定义构造函数,而函数体内赋值是先调用默认构造函数,再调用一次赋值函数。
若类的数据成员是静态的(const)和引用类型,必需用初始化列表。静态(const)的数据成员只能初始化而不能赋值,同样引用类型也是只可以被初始化,那么只有用初始化列表。
C++函数调用的压栈过程
当main函数开始调用func()函数时,编译器此时会将main函数的运行状态进行压栈,再将func()函数的返回地址、func()函数的参数从右到左、func()定义变量依次压栈;
写C++代码时有一类错误是 coredump ,很常见,你遇到过吗?怎么调试这个错误?
生成的一个叫做core的文件,这个core文件会记录程序在运行时的内存,寄存器状态,内存指针和函数堆栈信息等等。对这个文件进行分析可以定位到程序异常的时候对应的堆栈调用信息。
RAII与RTTI
RAII:(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的技术。
利用的就是C++构造的对象最终会被销毁的原则。RAII的做法是使用一个对象,在其构造时获取对应的资源,在对象生命期内控制对资源的访问,使之始终保持有效,最后在对象析构的时候,释放构造时获取的资源。
主要表现为:使用智能指针,智能指针其实是模板类,然后你使用一个智能指针对象来管理你的资源,如果这个智能指针对象是栈对象,那么它超出作用域后,自动销毁时,也会释放掉它管理的资源,这样就可以避免你忘记释放资源而导致的资源泄露。
RTTI: (Run Time Type Identification)即通过运行时类型识别,程序能够使用基类的指针或引用来检查着这些指针或引用所指的对象的实际派生类型。
主要表现为:typeid和dynamic_cast操作符
typeid操作符:返回指针和引用所指的实际类型;
dynamic_cast操作符:将基类类型的指针或引用安全地转换为其派生类类型的指针或引用。
而运行期识别的信息存放在什么地方呢?
答案:存放在一个特定的对象中,这个对象的指针就放在虚函数表的其中一项。
(具体一点,如果类有虚函数,就会生成虚函数表,这是类共享的,每个对象都会有一个vptr指向这个虚函数表。当基类生成子类,子类也会继承这个虚函数表,如果子类重写了虚函数,就会替换该虚函数的地址,我们知道成员函数并不在类对象的内存布局中,是单独的。当基类指针指向派生类的时候,实际上既可以获得派生类的虚表指针,通过虚表指针,基类既可以去调用派生类中的成员函数。如此不同的派生类的虚函数不同,调用的时候实现的效果也就不同,也就符合了多态的定义,面对同一消息的不同应答。)
继承和组合的特点
继承是Is a 的关系,比如说Student继承Person,则说明Student is a Person。继承的优点是子类可以重写父类的方法来方便地实现对父类的扩展。
继承的缺点有以下几点:
①:父类的内部细节对子类是可见的。隐藏性不够
②:子类从父类继承的方法在编译时就确定下来了,所以无法在运行期间改变从父类继承的方法的行为。
③:如果对父类的方法做了修改的话(比如增加了一个参数),则子类的方法必须做出相应的修改。所以说子类与父类是一种高耦合,违背了面向对象思想。
组合也就是设计类的时候把要组合的类的对象加入到该类中作为自己的成员变量。has-a关系
组合的优点:
①:当前对象只能通过所包含的那个对象去调用其方法,所以所包含的对象的内部细节对当前对象时不可见的。隐藏性
②:当前对象与包含的对象是一个低耦合关系,如果修改包含对象的类中代码不需要修改当前对象类的代码。
③:当前对象可以在运行时动态的绑定所包含的对象。可以通过set方法给所包含对象赋值。
组合的缺点:①:容易产生过多的对象。②:为了能组合多个对象,必须仔细对接口进行定义
函数指针?
数指针的声明方法
int (pf)(const int&, const int&); (1)
上面的pf就是一个函数指针,指向所有返回类型为int,并带有两个const int&参数的函数。注意pf两边的括号是必须的,否则上面的定义就变成了:
int *pf(const int&, const int&); (2)
而这声明了一个函数pf,其返回类型为int *, 带有两个const int&参数。
为什么需要内存对齐?
1.不同硬件平台不一定支持访问任意内存地址数据,使用内存对齐可以保证每次访问都从块内存地址头部开始存取
2.提高cpu内存访问速度,内存是分块的,如两字节一块,四字节一块,考虑这种情况:一个四字节变量存在一个四字节地址的后三位和下一个四字节地址的前一位,这样cpu从内存中取数据便需要访问两个内存并将他们组合起来,降低cpu性能
用空间换时间
结构体字节对齐的细节和具体编译器实现相关,但一般而言满足三个准则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2) 结构体每个成员相对结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节{trailing padding}。
union的大小取决于它所有的成员中,占用空间最大的一个成员的大小。
有指定时其对齐的规则是:每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数(这里是8字节)中较小的一个对齐,并且结构的长度必须为所用过的所有对齐参数的整数倍,不够就补空字节。#pragma pack(2) //指定按2字节对齐。
你知道printf函数的实现原理是什么吗?
下面给出printf(“%d,%d”,a,b);(其中a、b都是int型的)的汇编代码
.section
.data
string out = “%d,%d”
push b
push a
push $out
call printf
你会看到,参数是最后的先压入栈中,最先的后压入栈中,参数控制的那个字符串常量是最后被压入的,所以这个常量总是能被找到的。函数通过判断字符串里控制参数的个数来判断参数个数及数据类型,通过这些就可算出数据需要的堆栈指针的偏移量了
i++,++i的区别以及效率
在单独存在的时候没区别。都是加1.
但是在运算时。
我们通过汇编代码,就可以很清楚地看到两者的不同了。
a=i++,先将i赋值给了a,然后才进行了+1操作,把加1结果赋值给了i。
b=++i,先进行加1操作,然后将加1结果先赋值给i,在赋值给了b。
效率没有区别,执行顺序不一样而已。
但是,在自定义类型时,就不一样了。i++是先用临时对象保存原来的对象,然后对原对象自增,再返回临时对象,不能作为左值;++i是直接对于原对象进行自增,然后返回原对象的引用,可以作为左值。
由于要生成临时对象,i++需要调用两次拷贝构造函数与析构函数(将原对象赋给临时对象一次,临时对象以值传递方式返回一次);
++i由于不用生成临时变量,且以引用方式返回,故没有构造与析构的开销,效率更高。
(一般编译器会有NRV优化,所以临时对象的拷贝可以优化,只有一次)
C++左值引用和右值引用
C++11正是通过引入右值引用来优化性能,具体来说是通过移动语义来避免无谓拷贝的问题,通过move语义来将临时生成的左值中的资源无代价的转移到另外一个对象中去,通过完美转发来解决不能按照参数实际类型来转发的问题(同时,完美转发获得的一个好处是可以实现移动语义)
(关于移动语义和完美转发间上面)
左值就是有名字的,可以取地址的,放在等号左边的。比如int a=1; a就是左值;
右值就是没有名字的,不能取地址的,比如常量值,函数返回值,表达式等。
左值引用就是左值的引用类型,比如马上初始化。比如int a=1; int &b=a
int &&d=10,就是右值引用,必须右值初始化。
左值常引用可以左值,右值初始化;
通过右值引用的声明,右值又“重获新生”,其生命周期与右值引用类型变量的生命周期一样长,只要该变量还活着,该右值临时量将会一直存活下去。右值值引用通常不能绑定到任何的左值,要想绑定一个左值到右值引用,通常需要std::move()将左值强制转换为右值。
如何在共享内存上使用STL标准库?
假设进程A在共享内存中放入了数个容器,进程B如何找到这些容器呢?
一个方法就是进程A把容器放在共享内存中的确定地址上(fixed offsets),则进程B可以从该已知地址上获取容器。另外一个改进点的办法是,进程A先在共享内存某块确定地址上放置一个map容器,然后进程A再创建其他容器,然后给其取个名字和地址一并保存到这个map容器里。
进程B知道如何获取该保存了地址映射的map容器,然后同样再根据名字取得其他容器的地址。
死锁之生产者消费者和哲学家进餐问题
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
为了防止死锁的发生,可以设置两个条件:
必须同时拿起左右两根筷子;
只有在两个邻居都没有进餐的情况下才允许进餐。
读写问题:不能同时读(可能出现覆盖数据),不能读写同时(可能数据不一致),可以同时读。
解决办法:最粗暴的,读写都加锁。并不满足题目读进程与读进程可以同时访问共享数据的要求!
引入count变量,用来记录当前有几个读进程在访问共享数据。

回收线程的几种方法
等待线程结束: int pthread_join(pthread_t tid, void retval);**
主线程调用,等待子线程退出并回收其资源,类似于进程中wait/waitpid回收僵尸进程,调用pthread_join的线程会被阻塞。
tid:创建线程时通过指针得到tid值。
retval:指向返回值的指针。
结束线程:*pthread_exit(void retval);
子线程执行,用来结束当前线程并通过retval传递返回值,该返回值可通过pthread_join获得。
retval:同上。
分离线程:int pthread_detach(pthread_t tid);
主线程、子线程均可调用。主线程中pthread_detach(tid),子线程中pthread_detach(pthread_self()),调用后和主线程分离,子线程结束时自己立即回收资源。
int status = pthread_create(&tid, NULL, ThreadFunc, NULL)
明确线程有joinable,unjoinable两种状态。如果线程是joinable状态,当线程函数自己返回退出时或pthread_exit时都不会释放线程所占用堆栈和线程描述符(总计8K多)。只有当你调用了pthread_join之后这些资源才会被释放。若是unjoinable状态的线程,这些资源在线程函数退出时或pthread_exit时
自动会被释放。而create创建的默认是joinable,所以需要join函数来回收资源,不然就内存泄露了。
pthread_detach用到这一个函数的目的是主线程在运行的时候可能希望不阻塞能够继续运行,让子线程自己运行完毕后自己释放资源,即异步结束,调用join()可以看成是同步结束。这一个函数既可以在主线程中写也可以在子线程中写,在子线程中一般会调用pthread_self()函数,主线程中则需要知道要detach的子线程ID。这个函数会让线程变成unjoinable状态。
线程终止的几种方法
1、代码执行完自然终止;
2、使用pthread_exit() 或者 return;
二者的区别:return既可以用于普通函数也可以用于终止线程,但是exit()只能用于终止线程;
return若在主线程中,会终止其他子线程,exit()不会影响子线程,另外exit()还会调用线程清理程序,而return做不到,所以最好用exit()终止。
3、线程执行过程中,接收到其它线程发送的“终止执行”的信号,然后终止执行。
也就是pthread_cancel(id);向目标线程发送 Cancel 信号,至于目标线程是否接收该信号,何时响应该信号,全由目标线程决定。类比于进程的kill函数,但是不同的是,调用函数时,并非一定能取消掉该线程,因为这个函数需要线程进到内核时才会被杀掉,所以线程如果一直运行于用户空间,就没有契机进入内核也就无法取消(例while(1){}空循环),此时可以使用pthread_testcancel();进入内核。
进程终止的几种方法
五种正常终止:main函数正常return ,或者exit()函数。调用_exit或_Exit函数(其目的是为进程提供一种无须运行终止处理程序或信号处理程序而终止的方法)。进程的最后一个线程在其启动历程中执行return语句或者pthread_exit().
异常终止:收到信号。比如调用abort。它产生SIGABRT信号,来自自身;ctrl+c (SIGINT信号)来自内核,最后一个线程收到pthread_cancel()信号,来自其他线程。
关于pthread_create()
四个参数,分别是线程id,属性(NULL一般),要执行的函数,传入函数的参数(有参数时输入参数的地址。当多于一个参数时应当使用结构体传入。)并且参数和函数返回值都是void*
如何后台运行程序一系列命令
(&,nohup,bg,fg,jobs -l,crtl+z)
&加在一个命令的最后,可以让这个命令放在后台执行
python test.py &
nohup加在一个命令的前面,不挂断的运行程序,退出终端不会影响程序的运行(终端退出会给bash进程发一个sighup信号,bash给其他进程发,如果没有设置处理sighup的信号处理函数,默认退出。)
nohup python test.py
nohup python test.py &
后台不挂断地运行程序,并且将输出到终端的内容输出到nohup.out
jobs命令
功能:查看当前终端后台运行的程序
jobs-l 可以显示当前终端所有任务的PID,jobs的状态可以是running,stopped,terminated,+号表示当前任务,-号表示后一个任务
查看当前的所有进程
ps -aux
关闭当前后台运行的命令
kill命令:结束进程
(1)通过jobs查看jobnum,然后执行 kill %jobnum
(2)通过ps命令查看进程号PID。然后执行 kill %PID
以及:crtl+z是将进程挂起到后台,停止执行,stopped状态。而&是弄到后台直接运行。
bg %num 是选择一个停止的后台进程继续运行;
fg %num是选择一个后台进程搞到前台运行,比如想要查看运行进度时。
关于快表
我的理解,页表是页号和块号的映射,快表相当于页表的一部分副本缓存。页表在内存中,快表在高速缓存中。用来加速地址变换的过程。
流程是:根据逻辑地址算出页号和偏移。如果快表命中有页号,直接得到块号,块号+偏移直接得到数据,一次访问内存;未命中,访问页表得到块号,再组合得到数据,两次访问内存,并把该页号加入到快表中,应该也有一个淘汰策略。
在执行malloc申请内存的时候,操作系统是怎么做的?
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存。
方式一:申请小于128KB,通过 brk() 系统调用从堆分配内存,将「堆顶」指针向高地址移动,获得新的内存空间.free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
方式二:大于128KB,通过 mmap() 系统调用在文件映射区域分配内存;free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
malloc() 分配的是虚拟内存。
如果分配后的虚拟内存没有被访问的话,虚拟内存是不会映射到物理内存的,这样就不会占用物理内存了。
malloc() 在分配内存的时候,并不是老老实实按用户预期申请的字节数来分配内存空间大小,而是会预分配更大的空间作为内存池。malloc(1) 实际上预分配 132K 字节的内存
为什么不全部使用 mmap 来分配内存?
频繁通过 mmap 分配的内存话,不仅每次都会发生运行态的切换,还会发生缺页中断(在第一次访问虚拟地址后),这样会导致 CPU 消耗较大。
既然 brk 那么牛逼,为什么不全部使用 brk 来分配?
随着系统频繁地 malloc 和 free ,尤其对于小块内存,堆内将产生越来越多不可用的碎片,导致“内存泄露”。而这种“泄露”现象使用 valgrind 是无法检测出来的。
中断和异常
中断由硬件产生比如键盘,传给CPU,CPU再通知内核,执行中断处理程序。(保存现场,还需要返回)
异常由软件程序CPU产生,比如缺页异常,除数为0异常,通知内核处理异常。
僵尸进程,孤儿进程,以及解决方案
一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。所以危害不大。
僵尸进程就是父进程没有设置子进程的waitpid函数,子进程终止后就变成僵尸进程,因为它的资源没有释放(进程id,中止状态,CPU运行时间等等)
如果父进程是一个服务器进程,一直循环着不退出,那子进程就会一直保持着僵尸状态
解决僵尸进程方法:
1、可以在父进程中加入一条语句:signal(SIGCHLD,SIG_IGN);表示父进程忽略SIGCHLD信号,该信号是子进程退出的时候向父进程发送的。会由内核init进程回收子进程信息;
2、父进程调用wait/waitpid等函数等待子进程结束,如果尚无子进程退出wait会导致父进程阻塞。如果父进程很忙可以用signal注册信号处理函数(处理sigchild信号),在信号处理函数调用wait/waitpid等待子进程退出。
3、两次fork。第一次fork子进程,子进程再fork一个孙进程(真正的任务进程)后退出。孙进程由于子进程退出是孤儿进程,所以会由Init接管。
文件系统知识汇总
首先,一个开胃的问题:硬链接和软连接区别
ln -s 原文件名 链接文件名
硬链接其实是给文件起了一个别名,也就是新建了一个目录项,只不过目录项中的索引节点指针是同一个。硬链接会让连接数加1,防止误删文件。但是它不能跨文件系统(因为不同系统就算索引节点一样,块号变了,找不到)
软连接其实是新增了一个索引节点也就是新增了一个文件,只不过这个文件的内容是原来文件的地址(索引节点的地址),相当于快捷方式,删除链接文件对源文件没有影响。可以跨文件系统。但是源文件路径改变,软连接就找不到了。
可能对于上面不太懂,学了文件系统就懂了。
Linux 文件系统会为每个文件分配两个数据结构:索引节点(index node)和目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
索引节点,也就是 inode,用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。
目录项,也就是 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。
(目录是文件的一种,保存在磁盘,目录项是为了加快查询速度,会把目录或者文件缓存在内存)
磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
文件系统的种类众多,而操作系统希望对用户提供一个统一的接口,于是在用户层与文件系统层引入了中间层,这个中间层就称为虚拟文件系统(Virtual File System,VFS)。VFS 定义了一组所有文件系统都支持的数据结构和标准接口,这样程序员不需要了解文件系统的工作原理,只需要了解 VFS 提供的统一接口即可。
磁盘的文件系统,它是直接把数据存储在磁盘中,比如 Ext 2/3/4、XFS 等都是这类文件系统。
内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的 /proc 和 /sys 文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据。
网络的文件系统,用来访问其他计算机主机数据的文件系统,比如 NFS、SMB 等等。
文件系统首先要先挂载到某个目录才可以正常使用,比如 Linux 系统在启动时,会把文件系统挂载到根目录
文件系统的作用:组成就是索引节点,目录项,磁盘物理块。为不同的文件系统组织统一接口。我们只要open,write,read,close。就可以。系统会为你分配一个fd文件描述符指定唯一的文件(索引节点以及指向的物理块).然后你写都是字节流形式,文件系统会为你自动分配物理块写,中间的差异文件系统屏蔽了。
为存储持久化,读取相关数据提供统一的接口。屏蔽字节流到数据块的转换细节
文件的存储方式
不同的存储方式,有各自的特点,重点是要分析它们的存储效率和读写性能
连续存储方式:需要在索引节点为每个文件定义文件起始位置和文件长度,文件紧密排列。这种方式读写效率很高,因为只要一次磁盘寻道时间就可以了。
但是有两个致命缺点:容易形成碎片,要想在磁盘移动紧凑空间不现实太慢了;第二就是文件长度固定不容易扩展,要想文件加点东西就要移动,很慢。反正就是文件长度不能增加减少,显然不符合现实需要的。
非连续存储:
非连续空间存放方式分为**「链表方式」和「索引方式」。**
链表有隐式链表和显式链表之分。隐式链表就是平常看到的,每个数据块有一个指针指向下一个数据块,索引节点存储第一块」和「最后一块」的位置。缺点是只能通过链表顺序访问,没办法直接访问了,而且指针会销毁磁盘空间,损坏的话就相当于丢失了。
显式就是在内存里保存一个文件分配表FAT,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号,以一个不属于有效磁盘编号的特殊标记(如 -1 )结束。在内存中,因而不仅显著地提高了检索速度,而且大大减少了访问磁盘的次数。但也正是整个表都存放在内存中的关系,它的主要的缺点是不适用于大磁盘。
索引的实现是为每个文件创建一个「索引数据块」,里面存放的是指向文件数据块的指针列表,说白了就像书的目录一样,要找哪个章节的内容,看目录查就可以。另外,文件头需要包含指向「索引数据块」的指针,这样就可以通过文件头知道索引数据块的位置,再通过索引数据块里的索引信息找到对应的数据块。
这种方式优点:可扩展,没有碎片(对于连续分配)支持随机访问(对于链表)唯一的缺点是索引数据块也有空间消耗,但是可以忽略。如果文件很大一个块都装不下,就会有二级索引,三级索引出现。
空闲空间管理
前面这些都是对已经分配的空间进行管理。那么如果我要保存一个数据块,我应该放在硬盘上的哪个位置呢?难道需要将所有的块扫描一遍,找个空的地方随便放吗?
**空闲表法 :对于连续分配适用。一般不用
空闲链表法:不支持随机访问,指针消耗
位图法:利用二进制的一位来表示磁盘中一个盘块的使用情况,磁盘上所有的盘块都有一个二进制位与之对应。当值为 0 时,表示对应的盘块空闲,值为 1 时,表示对应的盘块已分配。
键盘敲入A 字母时,操作系统期间发生了什么吗
那要想知道这个发生的过程,我们得先了解了解「操作系统是如何管理多种多样的的输入输出设备」的。
为了屏蔽设备之间的差异,每个设备都有一个叫设备控制器(Device Control) 的组件,比如硬盘有硬盘控制器、显示器有视频控制器等。设备控制器里有芯片,它可执行自己的逻辑,也有自己的寄存器(数据,状态,命令),用来与 CPU 进行通信。
另外, 输入输出设备可分为两大类 :块设备(Block Device)和字符设备(Character Device)。
块设备,把数据存储在固定大小的块中,每个块有自己的地址,硬盘、USB 是常见的块设备。
字符设备,以字符为单位发送或接收一个字符流,字符设备是不可寻址的,也没有任何寻道操作,鼠标是常见的字符设备。
块设备通常传输的数据量会非常大,于是控制器设立了一个可读写的数据缓冲区。
IO控制方式:设备如何告诉CPU数据准备好了,轮询肯定不行;中断可以;对于频繁IO的设备经常中断影响CPU性能,DMA控制器方式,DMA完成把数据放到对应内存,再告诉CPU。
设备驱动程序
虽然设备控制器屏蔽了设备的众多细节,但每种设备的控制器的寄存器、缓冲区等使用模式都是不同的,所以为了屏蔽「设备控制器」的差异,引入了设备驱动程序。
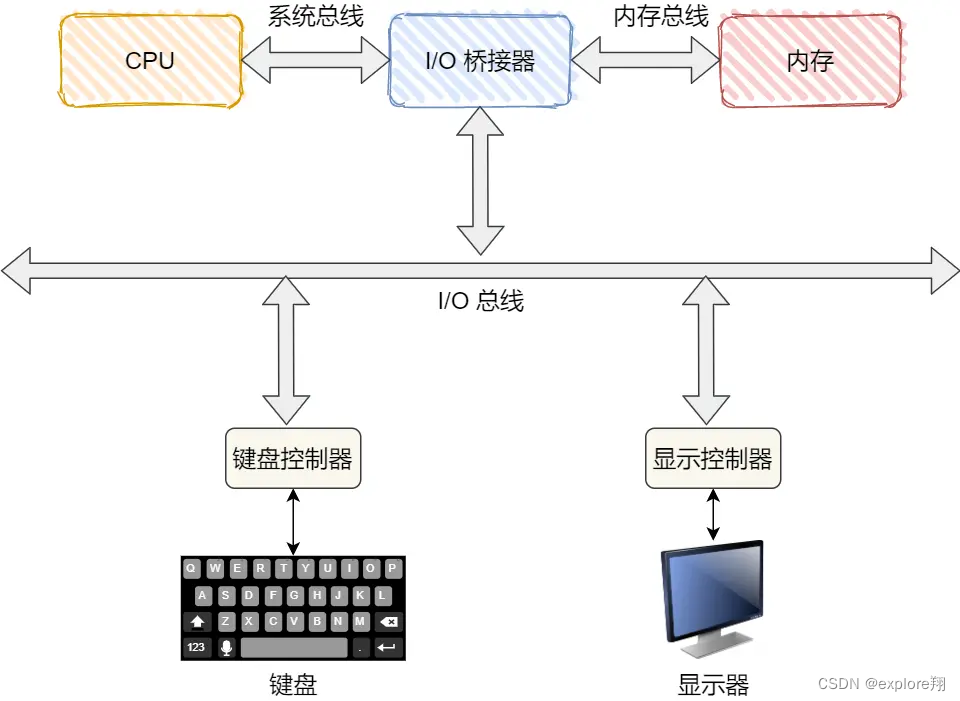
1、键盘控制器先把数据缓存在数据寄存器中,然后通过IO总线发送中断请求;
2、CPU 收到中断请求后,操作系统会保存被中断进程的 CPU 上下文,然后调用键盘的中断处理程序。
(键盘的中断处理程序是在键盘驱动程序初始化时注册的,那键盘中断处理函数的功能就是从键盘控制器的寄存器的缓冲区读取扫描码,再根据扫描码找到用户在键盘输入的字符,如果输入的字符是显示字符,那就会把扫描码翻译成对应显示字符的 ASCII 码,把 ASCII 码放到「读缓冲区队列」,接下来就是要把显示字符显示屏幕了)
memcpy,strcpy,strncpy区别和效率
strcpy和memcpy区别。
- 复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
从参数也可以看出来,char* strcpy(char* dst,char* src) void* memcpy(void* dst,void* src,ssizet size);void*可以代表任何类型; - 复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度,如果长度超出了原来的数据长度,就会发生内存越界。
效率:看网上的代码,二者是一样的,但是源码实现不一样。strcpy是按字符一个字节一个字节复制的,而memcpy最低也是按照机器字长word复制的(4或8字节),而且对于处于内存对齐的位置可以优化成按页复制,所以更快。
strncpy就是更安全,因为可以防止内存溢出。
内存泄漏,内存越界怎么检查?
内存安全问题:内存重复释放,越界访问等。
C++中内存泄漏(主要指堆内存,当然也有socket等其他资源)很常见,因为没有垃圾回收需要自己处理,而malloc允许自己控制内存,即使你是经验老到的程序员,一些STL和其他库中涉及很多内存操作,很难防范。
1.阅读代码检查。要知道编写规范,比如哪些场景会出现内存泄漏(析构函数不用虚函数,忘记free,free[],构造函数抛出异常,浅复制一个含有指针的对象造成内存重复释放,用智能指针代替原始指针,free后要指针设为NULL)
怎么解决:
1、可以借助工具比如valgrind定位内存泄漏,但是这个运行内存较大,不适合在虚拟机跑,当然也有其他的软件;内存泄漏其实不算内存安全问题;
2. 内存越界如果马上崩溃的话比较好查,写个backtrace模块,捕捉越界信号打印堆栈,有的工具tengine就是利用这个原理;
3. 如果越界不立刻崩溃的话就不好查(比如缓冲区溢出),可以在一些内存操作比如memcpy,malloc函数hook一下,测试的时候加一层日志。















 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









