






1、IO复用和线程池哪个好?应用场景?
IO复用就是一个线程处理多个客户端连接。如果自己实现的话,就是要不断轮询每个客户端连接,看看有没有事件发生(数据到达),即使可以用非阻塞的read函数,但是也会花很多时间在CPU空转上,因为可能数据都没到达,就白轮询了。
而系统提供了这种机制,select等模型,让操作系统来实现,只要有一个可读事件就返回(或者超时返回),然后进行处理(至于底层的原理数据结构,看面经积累那篇文章)。至于处理是单线程,还是一个线程处理一个连接(这其实就是reactor模型),具体就看业务场景了。
IO复用适合的场景就是:
1、处理过程简单,因为创建切换线程是需要时间的,如果很简单,一个熟练工自己做就可以,分发给很多人做需要时间,可能分发的时间代价比自己做好这一个连接请求还大。如果处理过程复杂一点,代价比创建切换线程时间大,那么可以多线程。如果完全是一个计算密集的任务,IO消耗可忽略,多进程充分利用CPU核数的计算力更重要,多线程的重要目的就是在IO阻塞时挂起线程让CPU执行别的任务,充分利用CPU,不让他闲置。计算密集型任务基本上就没有IO阻塞这一说,CPU一直是满负载的。并且相对来说,进程更加健壮,进程之间不影响,而线程之间会互相影响,因为是公用内存空间的。
2.适合长连接,有很多闲置IO的场景。因为如果为每个IO设置一个线程,将会大大增加内存消耗,线程创建需要空间(10M左右)。
3.上层应用编程方便。因为多线程会有线程安全,并发编程问题,需要加锁等机制。方便也是一大因素,不然就不会有python这种方便但是性能不够好的语言了。因为可以实现需求比为了性能实现不了需求要好。
比如redis,nigix就是典型的IO复用,单线程的。
nigix反向代理的转发逻辑简单,所以是单线程的。redis因为是基于内存的,CPU不是瓶颈(也就是说逻辑处理很快,相对就是简单),瓶颈可能是网络带宽等,一个CPU完全有足够的算力去实现所有客户端连接的请求处理,单个的请求处理过程很快,不需要让客户端等待很久,反而是创建切换线程会让客户端等的更久。如果并发量特别大,希望充分利用其他的CPU,就可以多开几个redis进程。
redis为什么快
(基于内存,数据用哈希表存储,内存的读写速度非常快,查找和操作的时间复杂度都是O(1))
(redis是单线程的,省去了很多上下文切换线程的时间(避免线程切换和竞态消耗))
(redis使用IO多路复用技术(IO multiplexing, 解决对多个I/O监听时,一个I/O阻塞影响其他I/O的问题),可以处理并发的连接(非阻塞IO))
2、IO复用模型用的是非阻塞IO吗? 阻塞非阻塞,同步异步IO的区别?
首先阻塞IO是什么流程?
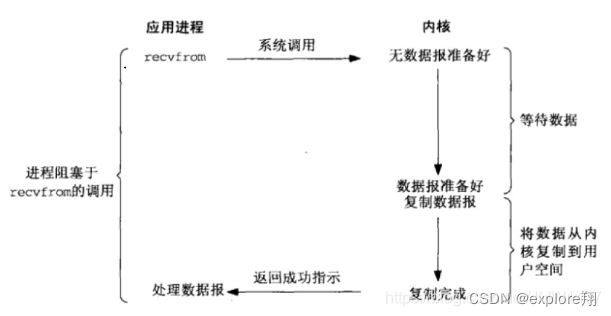
在读的时候,如果没有数据,就一直阻塞等待,这是第一部分,有数据后,将数据从内核复制到用户空间(定义的buffer中),这是第二部分。然后read才完成;
非阻塞IO
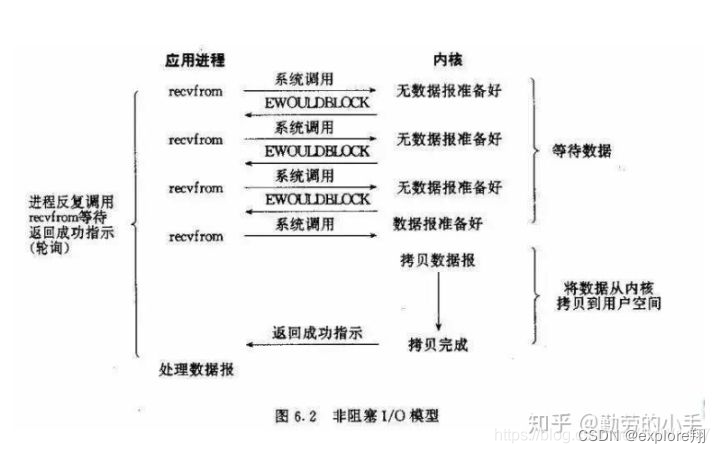
读调用时,如果没有数据,就直接返回错误,不需要阻塞等待,准备好后就拷贝数据到缓冲区。
可以发现,阻塞非阻塞第二步相同,都得等到数据拷贝完成才返回处理数据,因此它们都是同步IO。而异步IO就是第二步拷贝不需要等待完成就直接返回进行下面的代码,拷贝完成后会有信号通知即回调函数完成操作。
那么IO复用是不是阻塞呢?
首先,IO复用在操作系统层面应该是不阻塞的,在应用层面阻塞。首先select函数返回必须有一个可读事件发生,没有的话是会阻塞的,但这是编程层面的,可以通过超时时间来控制。返回后遍历fdset,这时的read调用就是非阻塞的,没有数据直接返回错误,有数据就拷贝到缓冲区,并处理。
4、多线程为什么能提高并发度?和CPU核数的关系?单核跑多线程有意义吗?
多线程,多进程在单核跑有意义吗?我们要了解多线程的应用场景。
多线程主要用于有很多IO操作的地方,比如磁盘IO,网络IO。IO操作时不需要占用cpu时间的,一个cpu同一时刻只能被一个线程占用。当一个线程在IO操作被阻塞时,完全可以让出CPU,让需要CPU的线程执行。所以意义就是错开IO和cpu的使用。一个线程是串行处理所有操作,一个客户端处理完再处理下一个,有IO时CPU就空闲等待。而多线程的话,一个客户端处于IO时,CPU就让另一个需要IO的客户端执行,这样CPU利用率变高了,每个客户端处理的速度也变快了。但是如果计算密集的话,没有IO时间,就不需要多线程。
有多个CPU时,多线程就更加能发挥作用了,充分利用多个CPU的处理能力。现在的处理器一般都是好多CPU核心的。
所以个人经验:如果逻辑处理很简单,就用IO复用+单线程;如果逻辑处理稍微复杂,大于创建切换线程的时间,就用IO复用+多线程(线程池);如果完全是计算密集的任务,就看几个CPU核心,开几个进程,基本不需要调度进程。
5、系统调用(用户内核态切换)、切换线程,协程,进程到底要多少时间?做了什么事情?
首先,系统调用做的是就是进程内将用户态切换到内核态,然后再切回来。大概是ns级别,开销比较小;并且进程线程切换都得经过用户态到内核态的转换。
进程切换大概是3.5us,毫秒级别,开销较大。(实验方法是创建两个进程并在它们之间传送一个令牌。其中一个进程在读取令牌时就会引起阻塞。另一个进程发送令牌后等待其返回时也处于阻塞状态。如此往返传送一定的次数,然后统计他们的平均单次切换时间开销。)
这些开销主要分成两部分:直接开销:PCB的修改,调度器的执行,全局页表目录的修改,硬件上下文(返回地址等)
间接开销:虽然切换到一个新进程后,由于各种缓存并不热,速度运行会慢一些。如果进程始终都在一个CPU上调度还好一些,如果跨CPU的话,之前热起来的TLB、L1、L2、L3因为运行的进程已经变了,所以以局部性原理cache起来的代码、数据也都没有用了,导致新进程穿透到内存的IO会变多。
线程开销较小,因为共享进程的虚拟地址空间,没有页表的切换,TLB命中率降低等因素。只要切换自己的栈和程序计数器PC即可。也是毫秒级别。
为了实现异步,通常会用回调函数,这样可以尽量避免线程切换的开销。但是这么做不是人类正常的思维,代码维护困难。最好可以用同步的代码写出异步的效果,协程可以做到。协程在应用层又动起了主意,设计出了不需要进程/线程上下文切换的“线程”,协程。用协程去处理高并发的应用场景,既能够符合进程涉及的初衷,让开发者们用人类正常的线性的思维去处理自己的业务,也同样能够省去昂贵的进程/线程上下文切换的开销
协程开销大概是120ns,甚至比系统调用还快。并且协程的内存占用只有KB级别,也很小。
协程缺点就是,需要程序员自己执行切换时机,不像进程线程,操作系统会完成这些步骤。操作系统的一个主要设计目标是实时性,对优先级比较高的进程是会抢占当前占用CPU的进程。但是协程无法实现这一点,还得依赖于使用CPU的一方主动释放,与操作系统的实现目的不相吻合。协程的高效是以牺牲了可抢占性为代价的。所以协程的调度设计很重要。
另外,协程的栈空间太小了,一旦比较复杂的业务,很有可能会溢出。














 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









