






发个推文
写一下最近很多人问我的使用python写爬虫爬数据
我将分成四篇来进行
好的 开始写正文
第一部分
1.1任务描述:
爬取某免费代理网站的IP及端口并测试其能否使用,如果可以使用就存进一个列表待用
1.1.1免费代理网站地址:
https://xxx.com/cn/free-proxies/asia/china/#:~:text=%E5%85%8D%E8%B4%B9%E4%B8%AD%E5%9B%BD%E4%BB%A3%E7%90%86.%20%E6%B5%8F%E8%A7%88
(搜索引擎:bing 关键词:免费代理 这个网站提供下载json、txt、csv,如果短时间使用也可以直接去下载他们的文件,但是我不想每次都去下载,我想把这个爬取代理的python文件直接保存下来,可以在其他文件或者项目里直接调用)
网页截图:
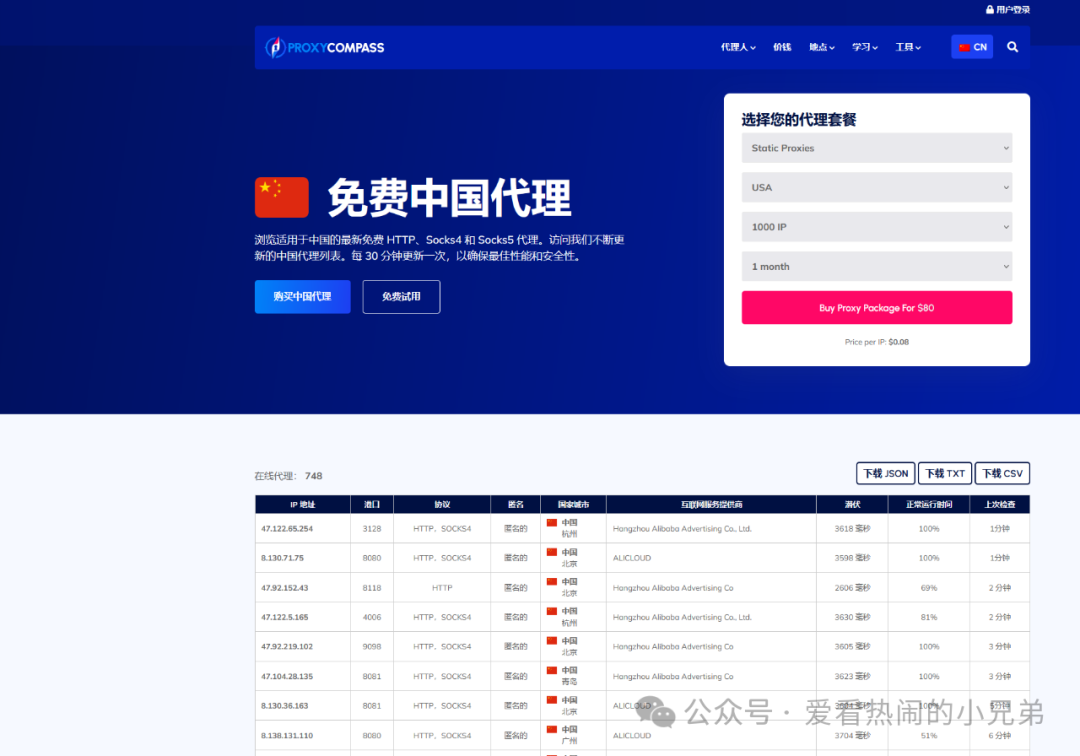
1.1.2 测试能否使用的网站:
https://httpbin.org
(网上很多教程会用百度来测试,但是我不喜欢用百度测试。这个很好用,可以返回很多东西。)
1.2 任务所需
1.2.1 request模块简介
Python requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。
requests 模块比 urllib 模块更简洁。
每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等:
-
1xx(信息性状态码):表示接收的请求正在处理。
-
2xx(成功状态码):表示请求正常处理完毕。
-
3xx(重定向状态码):需要后续操作才能完成这一请求。
-
4xx(客户端错误状态码):表示请求包含语法错误或无法完成。
-
5xx(服务器错误状态码):服务器在处理请求的过程中发生了错误。
import requests
response = requests.get(url,headers,proxies,timeout,parms)#示例
print(response.status_code) # 获取响应状态码
print(response.headers) # 获取响应头
print(response.content) # 获取响应内容表:
| apparent_encoding | 编码方式 |
| close() | 关闭与服务器的连接 |
| content | 返回响应的内容,以字节为单位 |
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
| elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
| encoding | 解码 r.text 的编码方式 |
| headers | 返回响应头,字典格式 |
| history | 返回包含请求历史的响应对象列表(url) |
| is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
| is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
| iter_content() | 迭代响应 |
| iter_lines() | 迭代响应的行 |
| json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| links | 返回响应的解析头链接 |
| next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
| ok | 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
| raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
| reason | 响应状态的描述,比如 "Not Found" 或 "OK" |
| request | 返回请求此响应的请求对象 |
| status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| text | 返回响应的内容,unicode 类型数据 |
| url | 返回响应的 URL |
requests 方法如下表:
| 方法 | 描述 |
|---|---|
| delete(url, args) | 发送 DELETE 请求到指定 url |
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
1.2.2 HTTP状态码简介
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码的信息头(server header)用以响应浏览器的请求。
HTTP 状态码的英文为 HTTP Status Code。
下面是常见的 HTTP 状态码:
-
1xx(信息性状态码):表示接收的请求正在处理。
-
2xx(成功状态码):表示请求正常处理完毕。
-
3xx(重定向状态码):需要后续操作才能完成这一请求。
-
4xx(客户端错误状态码):表示请求包含语法错误或无法完成。
-
5xx(服务器错误状态码):服务器在处理请求的过程中发生了错误。
HTTP 状态码分类
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型。响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599):
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
HTTP状态码列表:
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed(预期失败) | 服务器无法满足请求头中 Expect 字段指定的预期行为。 |
| 418 | I'm a teapot | 状态码 418 实际上是一个愚人节玩笑。它在 RFC 2324 中定义,该 RFC 是一个关于超文本咖啡壶控制协议(HTCPCP)的笑话文件。在这个笑话中,418 状态码是作为一个玩笑加入到 HTTP 协议中的。 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
1.2.3 parsel 简介
一个很有用的解析和提取 HTML 或 XML 数据的库
使用之前需要先声明Selector对象,再用xpath方式提取
示例代码:
import parselparsel = parsel.Selector() #声明Selector对象
1.3 任务主要步骤:
第一步:使用requests成功访问网站,并拿到全部页面数据;
第二步:使用parsel解析数据,并找到IP和端口数据;
第三步:使用https://httpbin.org与status_code是否等于200来判断是否可用,如果可用,则保存进某一特定列表。
本篇完(1/4)















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









