






现在理解得还不是很好,先去做PA3,在做作业的过程中加深理解。
错误处理
在语法分析阶段,我们要检查程序中的语法是否正确,如果有错误,需要一些方法报错,以及越过错误点继续检查。
下面是几个错误处理方法
恐慌模式
最简单同时也是使用最多的方法。
当遇到一个错误时,我们跳过一些输入字符,直到遇到指定的字符(串)后从该处继续检查,这些指定的字符需要人为设置,通常称为同步字符(synchronizing token)。
错误产生式
在产生式集合中加入可以推导出常见错误的产生式,这样,在推导过程中会导出错误的字符串,此时我们就知道产生了错误,就可以基于此给出错误信息。
局部和全局纠正
当错误产生时,在错误点修改(增删改)尽可能少的字符,以使程序正确,这个方法目前仅具理论价值。
Abstract Syntax Tree
AST是语法分析树的简化版本,如:
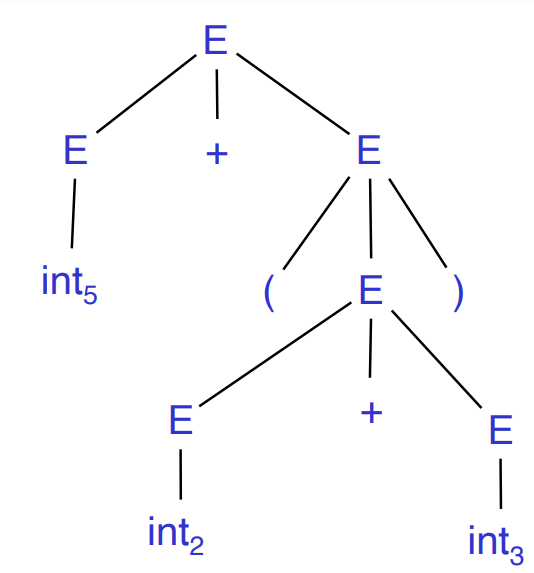
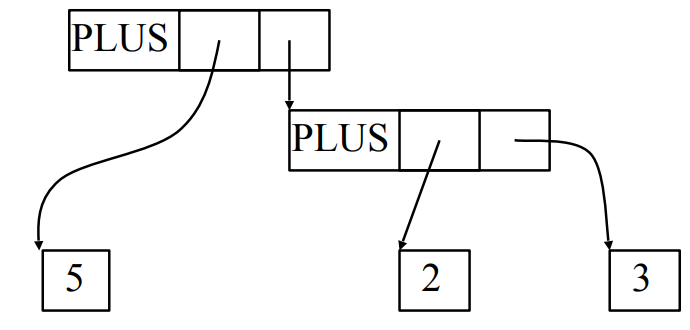
可以被如下AST代替:
自顶向下的语法分析
在自顶向下的分析中,我们要从开始符开始,如果通过推导得到了输入串,那么说明没有语法错误,并且在这个过程中我们也生成了语法分析树,如果不能推导出,则程序有语法错误。
有两种方法,第一种说白了,就是普通的深度搜索算法,其中会发生回溯,开销较大,不常用,而第二种是不会发生回溯的搜索,比较常用,结果都是给出一个字符串的最左推导或报错。
带回溯的深度搜索算法
对于当前的公式,从左到右对每个非终结符的可能推导一个一个尝试,直到找到结果(返回答案),或发现不匹配(回溯),如果所有可能都无法匹配,那么报错。
左递归
如果存在 S → S a ∣ b S\rightarrow Sa|b S→Sa∣b这种右侧的第一个符号为非终结符的表达式,可能会发生无限递归的情况,称为左递归,为了消除这种无线递归,将这种表达式重写为 S → b ∣ A S\rightarrow b|A S→b∣A和 A → a A A\rightarrow aA A→aA,更复杂的情况需要更一般化的处理。
不带回溯的预测算法
通过查看目标字符串中的下一个字符,可以指导我们选择哪一个产生式进行推导,从而避免了繁琐的回溯过程。在这里需要使用LL(k)语法。
LL(k)语法
LL(k)语法是产生式的另一种书写方式,下面的产生式:

可以写成:
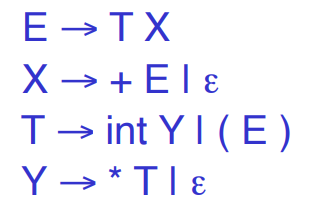
即将公式右侧以相同字符开始的部分合并,这样,每次对于相同的字符,仅有一种选择,就可以避免回溯的发生。
First(a)
从上面的LL(k)语法看出,我们需要知道从一个字符可以推导出的首个字符有哪些。
将从a可以推出的字符串的首字符的集合记为First(a)。
求First(a)的方法:
- 若
a为终结符,则First(a) = {a} - 若
a为非终结符,且有 a → Y 1 Y 2 . . . Y n a\rightarrow Y_1Y_2...Y_n a→Y1Y2...Yn,对于任意 i ∈ [ 1 , n ] i \in [1,n] i∈[1,n],若有 Y 1 Y 2 . . . Y i − 1 ⇒ ∗ ϵ Y_1Y_2...Y_{i-1} \Rightarrow ^* \epsilon Y1Y2...Yi−1⇒∗ϵ,则 F i r s t ( Y i ) ⊆ F i r s t ( a ) First(Y_i) \subseteq First(a) First(Yi)⊆First(a),即 F i r s t ( Y i ) First(Y_i) First(Yi)的元素都可以计入 F i r s t ( a ) First(a) First(a) - 如果有 a → ϵ a\rightarrow \epsilon a→ϵ,则将 ϵ \epsilon ϵ加入。
Follow(a)
龙书P 130。
自底向上的语法分析
与前面的方法相反,在这里,我们从输入串开始,通过反向推导产生式,最后如果得到开始符,说明没有语法错误,否则报错。















 3655
3655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









