






泰坦尼克号代码简单分析
流程分析
1、导入相关库和类
2、获取数据
3、数据处理
4、数据集划分
5、特征工程
6、决策树预估
7、模型评估
内容介绍
首先我们需要清楚我们的目标,就是通过船上乘客的信息分析和建模,预测哪些乘客得以生还。其次,我们在说明一下文件中各个英文单词的意思:
PassengerId :乘客的id号
Survived :生存的标号,数值1表示这个人很幸运,生存了下来。数值0,则表示遗憾。
Pclass :船舱等级,就是我们坐船有等级之分。
Name :名字,这个不影响生存率。我觉得可以不用这列数据。可以忽略
Sex :性别,这个因为全球都说lady first,女士优先,所有这列保留。
Age : 年龄,因为优先保护老幼,这个保留。
SibSp :兄弟姐妹,就是有些人和兄弟姐妹一起上船的。这个会有影响,因为有可能因为救他们而导致自己没有上救生船船。保留这列
Parch : 父母和小孩。就是有些人会带着父母小孩上船的。这个也可能因为要救父母小孩耽误上救生船。保留
Ticket:票的编号。这个没有影响。
Fare:费用。这个和Pclass有相同的道理,有钱人和权贵比较有势力和影响力。这列保留
Cabin:舱号。住的舱号没有影响,忽略。
Embarked ,上船的地方。这列可能有影响。登陆地点不同,可能显示人的地位之类的不一样,保留这列。
接下来开始我们的分析
1、导入相关库和类
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
2、获取数据
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
其中train.csv 和 test.csv 已经放在当前文件夹中。
使用panda的head(n)函数,来检查一下读取的数据,其中默认是查看前5行(即n=5)数据:
train.head()

test.head()
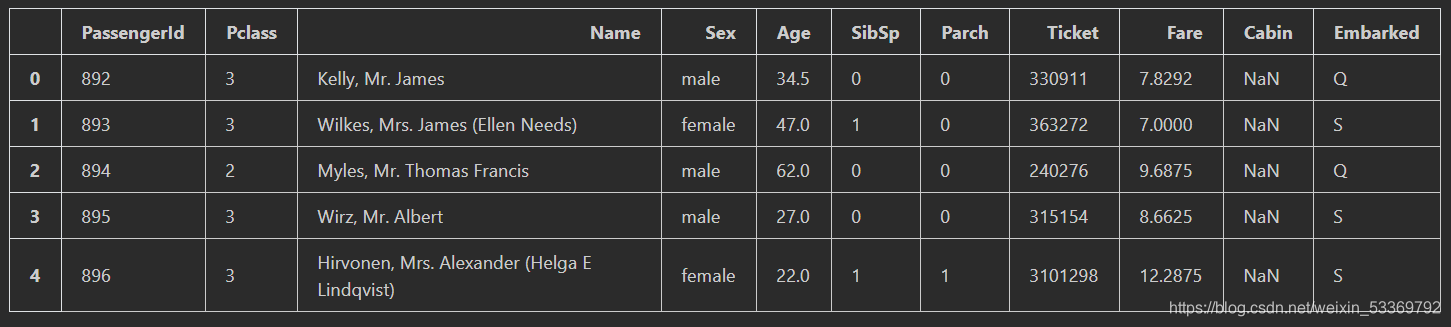
获取乘客的生存情况的测试集中的目标值(但在后面没有进行预测比较):
g_sub = pd.read_csv('gender_submission.csv')
g_sub.info()
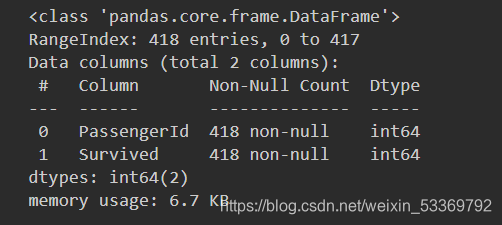
其中info()函数返回有哪些列、有多少非缺失值、每列的类型。
g_sub.head() #查看测试集
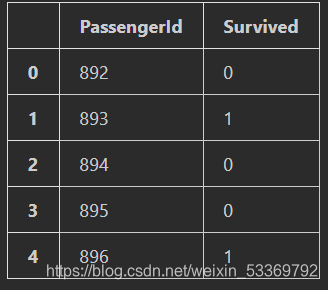
最后进行缺失值处理;
union['Age'].fillna(union['Age'].median(), inplace=True) # 旨在不创建副本的情况下, 将Age中的缺失值填充为中位数, 将Fare中的缺失值填充为平均数
union['Fare'].fillna(union['Fare'].mean(), inplace=True)
union = union.drop(['Name', 'Cabin'], axis=1) # 删除数据集中的名字和舱位,这些是无关信息
union['Embarked'].value_counts() # 查看Embarked列中有多少个不同值,并计算每个不同值有在该列中有多少重复值。
union['Embarked'].fillna('S', inplace=True) # 用出现最多的S填充Embarked中的缺失值
# 查看处理之后的数据
union.info()
union.head()
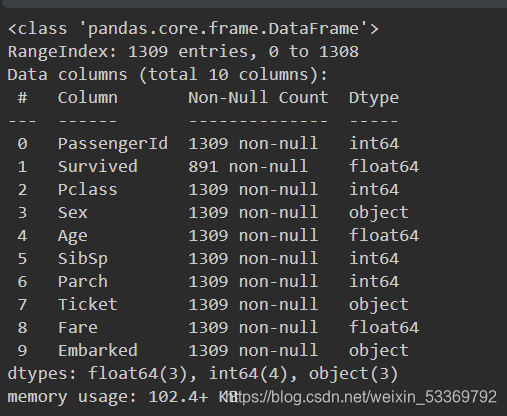
3、数据处理
首先先将训练集与测试集进行整合,便于处理特征值,在这里我们可以使用在训练集中追加测试集:
union = train.append(test, ignore_index=True) # 使用ignore_index=True主要是为避免添加的index出现重复的情况
print(union.info)
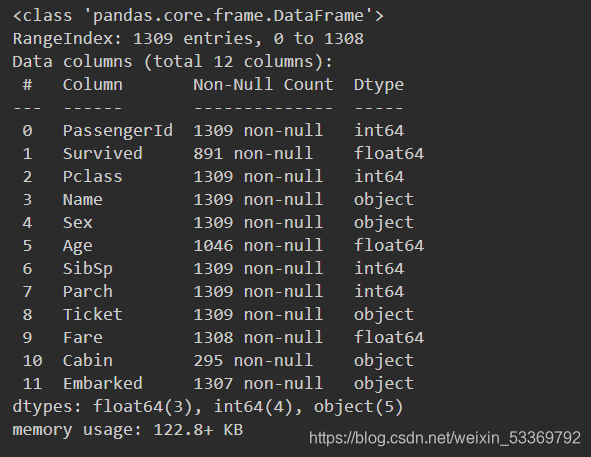
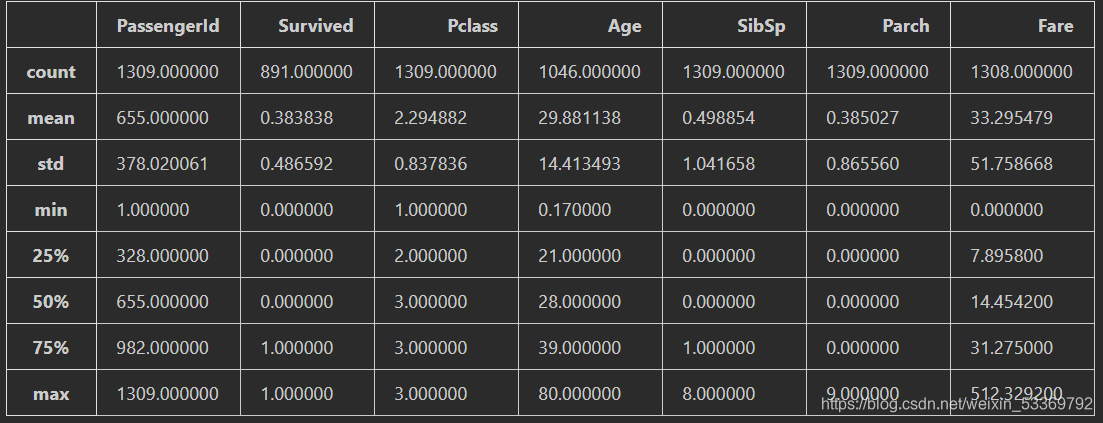
接着我们来查看一下两个数据集的统计变量:
"""describe()函数就是返回这两个核心数据结构的统计变量。
其目的在于观察这一系列数据的范围、大小、波动趋势等等,为后面的模型选择打下基础。"""
union.describe()
4、数据集划分
# 获取处理完的训练集和测试集
train = union.loc[0:890]
test = union.loc[891:]
# 数据集划分
x_train = train.drop(['Survived', 'Ticket'], axis=1) #训练集特征值
x_test = test.drop(['Survived', 'Ticket'], axis=1) #测试集特征值
y_train = train['Survived'] #训练集目标值
y_test = test['Survived'] #测试集目标值
5、特征工程
这一步其实是进行字典特征值抽取
dict = DictVectorizer(sparse=False) # 实例化一个转换器
X_train = dict.fit_transform(x_train.to_dict(orient='record')) # 拟合并且将其标准化
X_test = dict.transform(x_test.to_dict(orient='record'))
dict.get_feature_names() # 获取特征值的名字
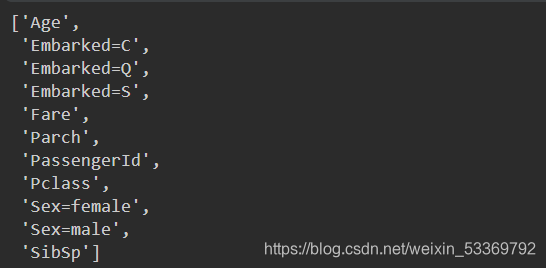
print(X_train)
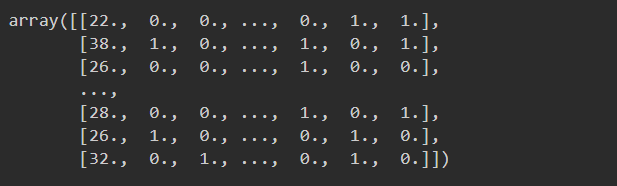
6、决策树预估
dec = DecisionTreeClassifier(max_depth=5)
dec.fit(X_train, y_train)
7、模型评估
# 直接比对真实值和预测值
y_predict = dec.predict(X_test).astype(np.int64) # astype()将测试集目标值转换为整形数据
print(y_predict)
id = test['PassengerId']
sub = {'PassengerId': id, 'Survived': y_predict}
submission = pd.DataFrame(sub) # 将乘客的ID和生存情况制成列表
submission.to_csv("sub.csv", index=False) # 保存文件
print(submission)
至此,我们完成对代码的浅显分析,欢迎指错改正!

















 2184
2184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









