







前言
大家好我是jiantaoyab,这是我所总结作为学习的笔记第19篇,在这里分享给大家,这篇文章讲存储器的一部分内容。
存储器的层次结构
SRAM
静态随机存取存储器的芯片,SRAM 之所以被称为“静态”存储器,是因为只要处在通电状态,里面的数据就可以保持存在。
而一旦断电,里面的数据就会丢失了。在 SRAM 里面,一个比特的数据,需要 6~8 个晶体管,所以 SRAM 的存储密度不高。同样的物理空间下,能够存储的数据有限。不过,因为 SRAM 的电路简单,所以访问速度非常快。
在 CPU 里,通常会有 L1、L2、L3 这样三层高速缓存。
每个 CPU 核心都有一块属于自己的 L1 高速缓存,通常分成指令缓存和数据缓存,分开存放 CPU 使用的指令和数据。这里的指令缓存和数据缓存,其实就是来自于哈佛架构。L1 的 Cache 往往就嵌在 CPU 核心的内部。
L2 的 Cache 同样是每个 CPU 核心都有的,不过它往往不在 CPU 核心的内部。所以,L2 Cache 的访问速度会比 L1 稍微慢一些。而 L3 Cache,则通常是多个 CPU 核心共用的,尺寸会更大一些,访问速度自然也就更慢一些。
DRAM
内存用的芯片是一种叫作DRAM(Dynamic Random Access Memory,动态随机存取存储器)的芯片,比起 SRAM 来说,它的密度更高,有更大的容量,而且它也比 SRAM 芯片便宜不少。
DRAM 被称为“动态”存储器,是因为 DRAM 需要靠不断地“刷新”,才能保持数据被存储起来。DRAM 的一个比特,只需要一个晶体管和一个电容就能存储。
所以,DRAM 在同样的物理空间下,能够存储的数据也就更多,也就是存储的“密度”更大。但是,因为数据是存储在电容里的,电容会不断漏电,所以需要定时刷新充电,才能保持数据不丢失。
DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问延时也就更长。
整个存储器的层次结构,其实都类似于 SRAM 和 DRAM 在性能和价格上的差异。SRAM 更贵,速度更快。DRAM 更便宜,容量更大
L1 Cache不仅受成本层面的限制,更受物理层面的限制。 L1 Cache 不仅昂贵,其访问速度和它到 CPU 的物理距离有关。芯片造得越大,总有部分离 CPU 的距离会变远。电信号的传输速度又受物理原理的限制,没法超过光速。所以想要快,并不是靠多花钱就能解决的。
内存空间一般是有限的,没有办法放下所有数据。如果想要扩大空间的话,成本就会很高。于是对于内存来说,SSD(Solid-state drive 或 Solid-state disk,固态硬盘)、HDD(Hard Disk Drive,硬盘)这些被称为硬盘的外部存储设备就能很好的解决问题。
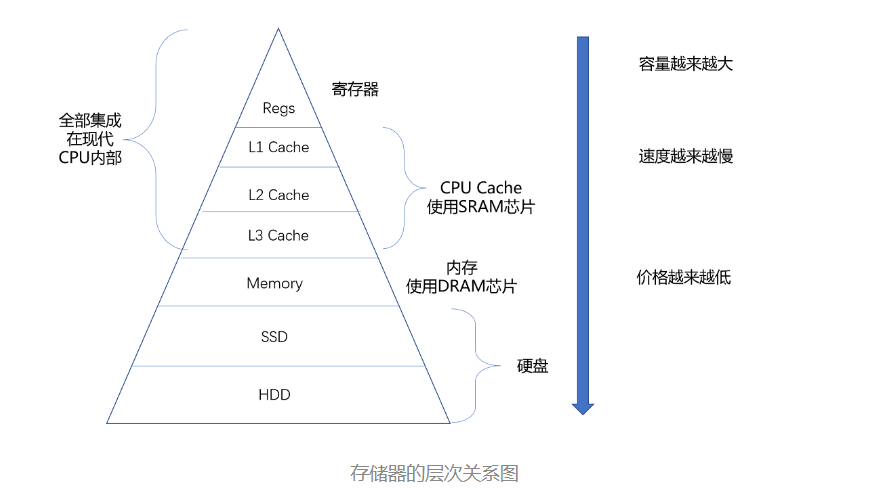
从 Cache、内存,到 SSD 和 HDD 硬盘,一台现代计算机中,就用上了所有这些存储器设备。其中,容量越小的设备速度越快,而且,CPU 并不是直接和每一种存储器设备打交道,而是每一种存储器设备,只和它相邻的存储设备打交道。比如,CPU Cache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPU Cache 中,而是先加载到内存,再从内存加载到 Cache 中。
这样,各个存储器只和相邻的一层存储器打交道,并且随着一层层向下,存储器的容量逐层增大,访问速度逐层变慢,而单位存储成本也逐层下降,也就构成了我们日常所说的存储器层次结构。
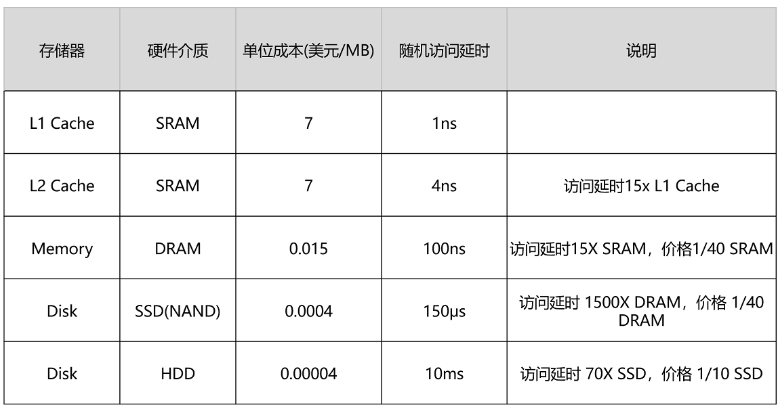
存储器在不同层级之间的性能差异和价格差异,都至少在一个数量级以上。L1 Cache 的访问延时是 1 纳秒(ns),而内存就已经是 100 纳秒了。在价格上,这两者也差出了 400 倍。
局部性原理
平时进行服务端软件开发的时候,我们通常会把数据存储在数据库里。而服务端系统遇到的第一个性能瓶颈,往往就发生在访问数据库的时候。
这个时候,大部分工程师和架构师会拿出一种叫作“缓存”的武器,通过使用 Redis 或者 Memcache 这样的开源软件,在数据库前面提供一层缓存的数据,来缓解数据库面临的压力,提升服务端的程序性能。
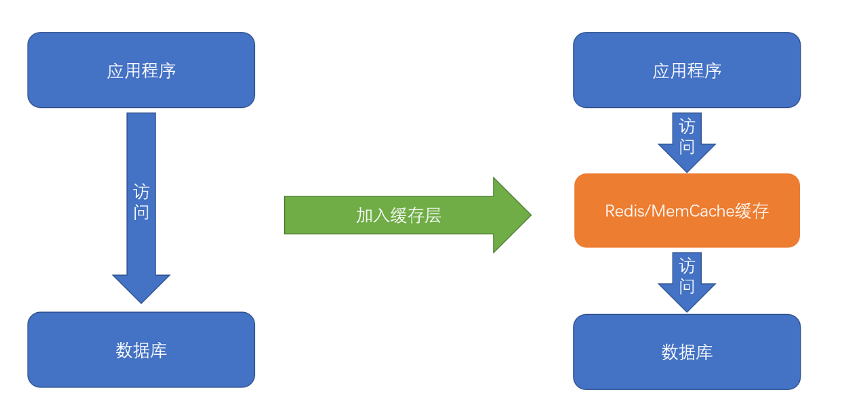
添加缓存一定是我们的最佳策略么?进一步地,如果我们对于访问性能的要求非常高,希望数据在 1 毫秒,乃至 100 微妙内完成处理,我们还能用这个添加缓存的策略么?除此之外还要考虑价格的问题。
所以我们能不能既享受 CPU Cache 的速度,又享受内存、硬盘巨大的容量和低廉的价格呢?
时间局部性
如果一个数据被访问了,那么它在短时间内还会被再次访问。
在一个电子商务型系统中,如果一个用户打开了 App,看到了首屏。我们推断他应该很快还会再次访问网站的其他内容或者页面,我们就将这个用户的个人信息,从存储在硬盘的数据库读取到内存的缓存中来。这利用的就是时间局部性。

空间局部性
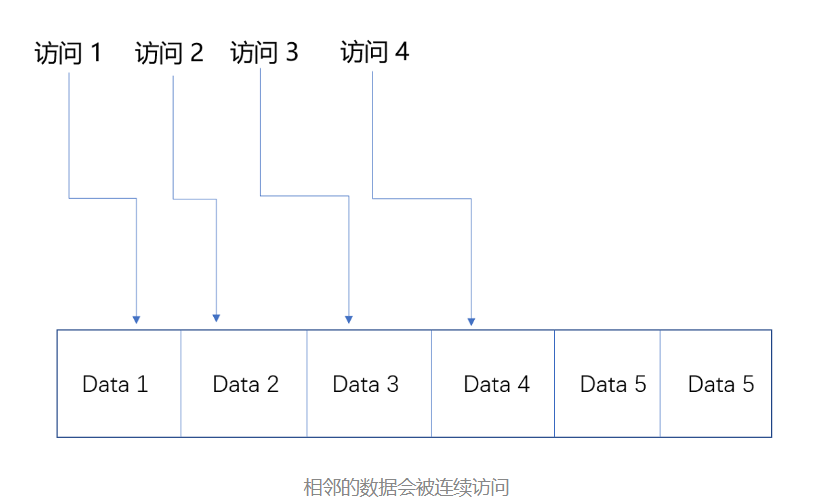
如果一个数据被访问了,那么和它相邻的数据也很快会被访问。
好比我们的程序,在访问了数组的首项之后,多半会循环访问它的下一项。因为,在存储数据的时候,数组内的多项数据会存储在相邻的位置。
那我们来思考一下,假设淘宝中有 亿件商品,如果每件商品需要 4MB 的存储空间,那么一共需要 2400TB的数据存储。
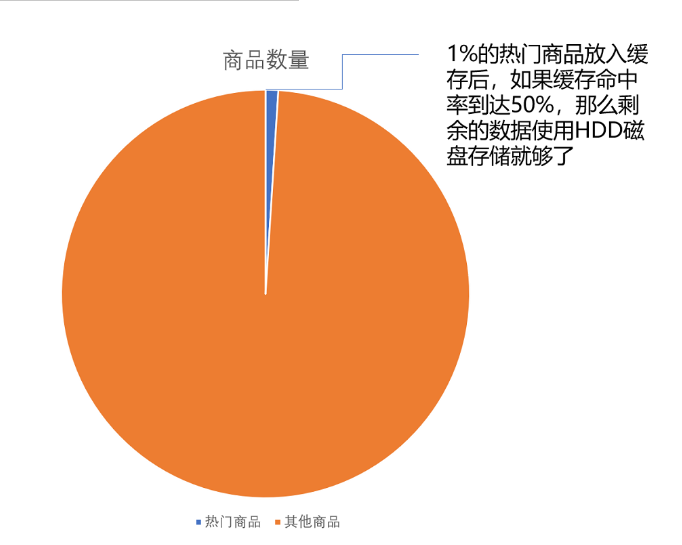
如果我们把数据都放在内存里面,那就需要 3600 万美元,但是,这 6 亿件商品中,不是每一件商品都会被经常访问。
如果我们只在内存里放前 1% 的热门商品,也就是 600 万件热门商品,而把剩下的商品,放在机械式的 HDD 硬盘上,那么,我们需要的存储成本就下降到 45.6 万美元,是原来成本的 1.3% 左右。
这里我们用的就是时间局部性。我们把有用户访问过的数据,加载到内存中,一旦内存里面放不下了,我们就把最长时间没有在内存中被访问过的数据,从内存中移走,这个其实就是我们常用的LRU(Least Recently Used)缓存算法。
那么,只放 600 万件商品真的可以满足我们实际的线上服务请求吗?
这个就要看 LRU 缓存策略的缓存命中率(Hit Rate/Hit Ratio)了,也就是访问的数据中,可以在我们设置的内存缓存中找到的物品占有多大比例。
但是如果数据没有命中内存,那么对应的数据请求就要访问到 HDD 磁盘了。一块 HDD 硬盘只能支撑每秒 100 次的随机访问,2400TB 的数据,以 4TB 一块磁盘来计算,有 600 块磁盘,也就是能支撑每秒 6 万次的随机访问。
这就意味着,所有的商品访问请求,都直接到了 HDD 磁盘,HDD 磁盘支撑不了这样的压力。我们至少要 50% 的缓存命中率,HDD 磁盘才能支撑对应的访问次数。不然的话,我们要么选择添加更多数量的 HDD 硬盘,做到每秒 12 万次的随机访问,或者将 HDD 替换成 SSD 硬盘,让单个硬盘可以支持更多的随机访问请求。
% 的缓存命中率,HDD 磁盘才能支撑对应的访问次数。不然的话,我们要么选择添加更多数量的 HDD 硬盘,做到每秒 12 万次的随机访问,或者将 HDD 替换成 SSD 硬盘,让单个硬盘可以支持更多的随机访问请求。















 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









