






概述
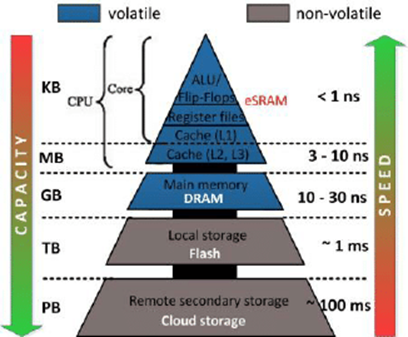
对于一个简单的计算机系统模型,我们可以将存储器系统看做是一个线性的字节数组,而 CPU 能够在一个常数时间内访问每个存储器的位置。实际上,存储器系统(memory system)是一个具有不同容量、成本和访问时间的存储设备的层次结构。CPU 寄存器保存着最常用的数据。靠近 CPU 的小、快速的高速缓存存储器(cache memory)做为一部分存储在相对慢速的主存储器(main memory)中数据和指令的缓冲区域。主存缓存存储在容量较大的、慢速磁盘上的数据,而磁盘常常作为存储在通过网络连接的其他机器的磁盘的缓存。
Cache 基本模型
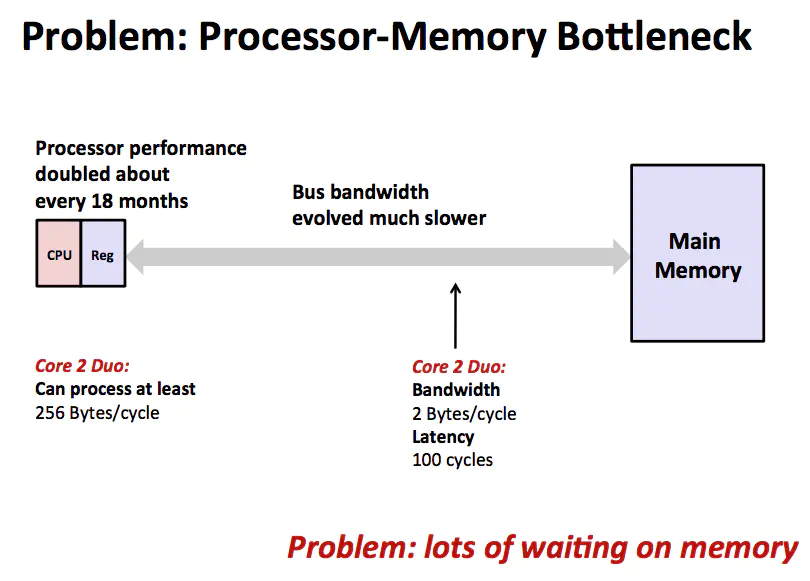
问题
CPU 通过总线从主存取指令和数据,完成计算之后再将结果写回内存。这个模型的瓶颈在于 CPU 的超级快的运算速度和主存相对慢的多的运算速度无法匹配,导致大量的时间都浪费在内存上。既然内存比较慢那么就尽量减少 CPU 对内存的访问,于是在 CPU 和 主存之间增加一层 Cache,如下图所示。
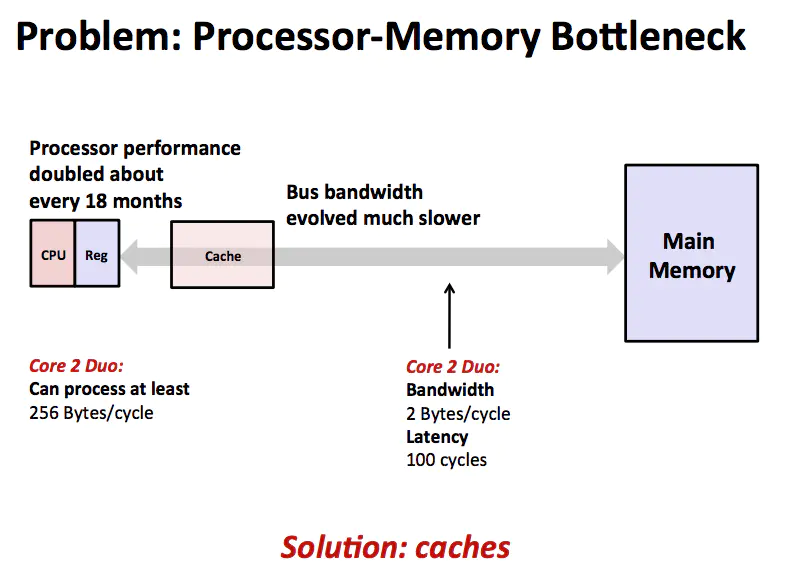
cache
在计算机中,Cache 就是访问速度快的计算机内存被用来保存频繁访问或者最近访问的指令和内存。通常 Cache 的造价比较高,所以相对 Memory 来说,容量比较小,保存的数据也有限。总而言之,由于 CPU 和内存之间的指令和数据访问存在瓶颈,所以增加了一层 Cache,用来尽力消除 CPU 和内存之间的瓶颈。这个模型如下图所示。
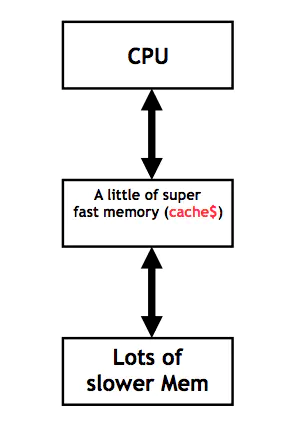
Cache 模型
局部性原理
你可能会问为什么在CPU 和内存之间增加一层 Cache,就可以尽力消除 CPU 和内存之间的瓶颈呢?
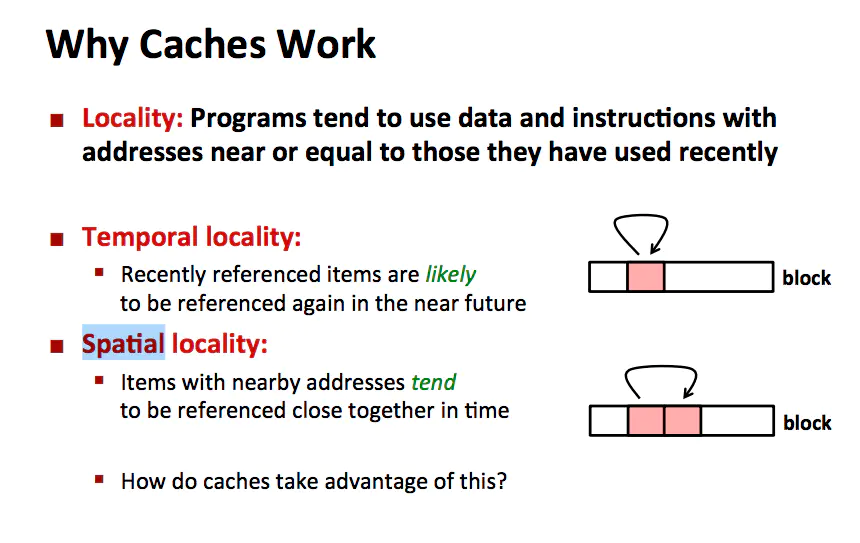
why cache work
如上图所示,是局部性原理(principle of locality)让 Cache 更好的工作。一个编写良好的计算机程序通常都具有良好的局部性(locality),程序倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身,这种倾向性被称作局部性原理。局部性通常有 2 种不同的形式:时间局部性(temporal locality)和空间局部性 (spatial locality)。在一个具有良好时间局部性的程序中,被引用过一次的内存地址很可能在不远的将来会再被多次引用。在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能在不远的将来会引用附近的一个内存位置。
程序是如何利用这个局部性原理呢?

Cache&locality
从数据方面来说,
-
sum 变量在每次循环迭代的时候都会被访问,符合时间局部性。
-
采用步长为 1 的方式访问数组 a ,符合空间局部性。
从指令方面来说,
-
循环迭代,符合时间局部性
-
线性执行指令,符合空间局部性
对于程序员来说,编写具有良好的局部性的程序是让程序运行更快的方法之一。
存储器的层次结构
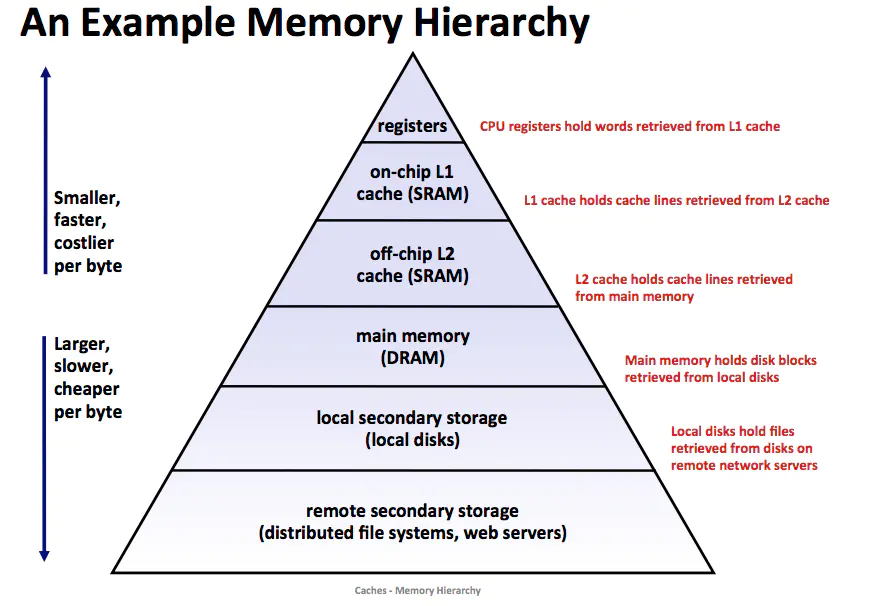
存储器层次结构
上图展示了一个典型的存储器层次结构。一般而言,从高层往底层走,存储设备变得更慢、更便宜和更大。在最高层是少量快速的CPU 寄存器,CPU 可以再一个时钟周期内访问它们。接下来是一个或者多个小型到中型的基于 SRAM 的高速缓存存储器,可以再几个 CPU 时钟周期内访问它们。然后是一个大的基于 DRAM 的主存,可以在几十或者几百个时钟周期内访问它们。接下来是慢速但是容量很大的本地磁盘。最后有些系统甚至包括了一层附加的远程服务器上的磁盘,要通过网络来访问它们,例如网络文件系统(Network File System,NFS)这样的分布式文件系统,允许程序访问存储在远程的网络服务器上的文件。
存储器层次结构的核心是,对于每个 k , 位于 k 层的更快更小的存储设备作为位于 k+1 层的更大更慢的存储设备的缓存。也就是说,层次结构中的每一层都缓存来自较低一层的数据对象。例如,本地磁盘作为通过网络从远程磁盘取出文件的缓存,以此类推知道 CPU 寄存器。
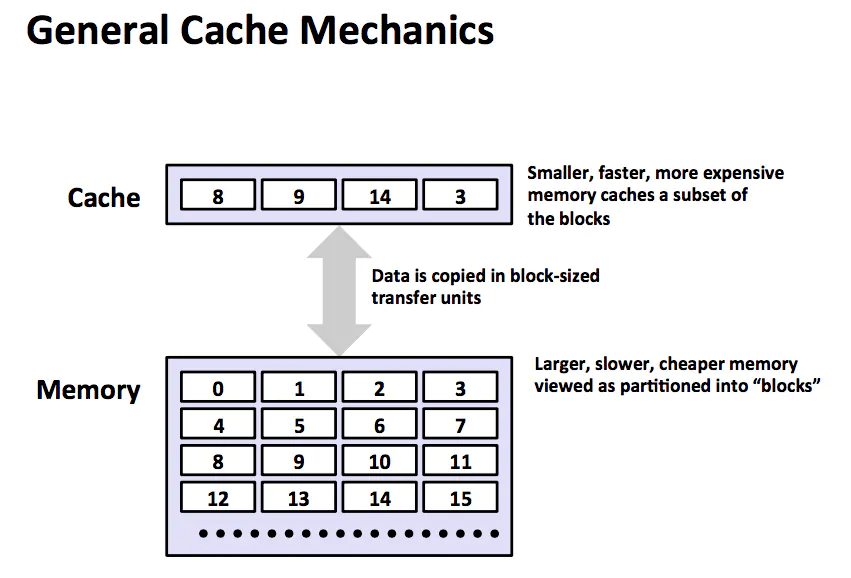 cache
cache
上图展示了存储器层次结构中缓存的一般性概念。第 k+1 层的存储器被划分成连续的数据对象组块(chunk),称为块(block)。每个块都有一个唯一的名字或者地址以区别其他的块。例如第 k+1 层存储器被划分成 16 个大小固定的块,编号为 0 ~ 15。第 k 层的存储器被划分成较少的块的集合,每个块的大小与 k+1 层的块的大小一样。在任何时刻,第 k 层的缓存包含了第 k+1 层块的一个子集的副本。例如,第 k 层的缓存有 4 个块的控件,当前包含了 8,9,14,3 的副本。
数据总是以块大小为传输单元在第 k 层 和 第 k+1 层之间来回复制的,虽然在层次结构总任何一对相邻的层次之间块大小是固定的,但是其他的层次对之间可以有不同的块大小。例如 L1 和 L2 之间的传送通常使用的是几十个个字大小的块,而 L5 和 L4 之间的传送用的是大小为几百或者几千字节的块。一般而言,层次结构中较低层(离 CPU 较远)的设备的访问时间较长,因此为了补偿这些较长的访问时间,倾向于使用较大的块。
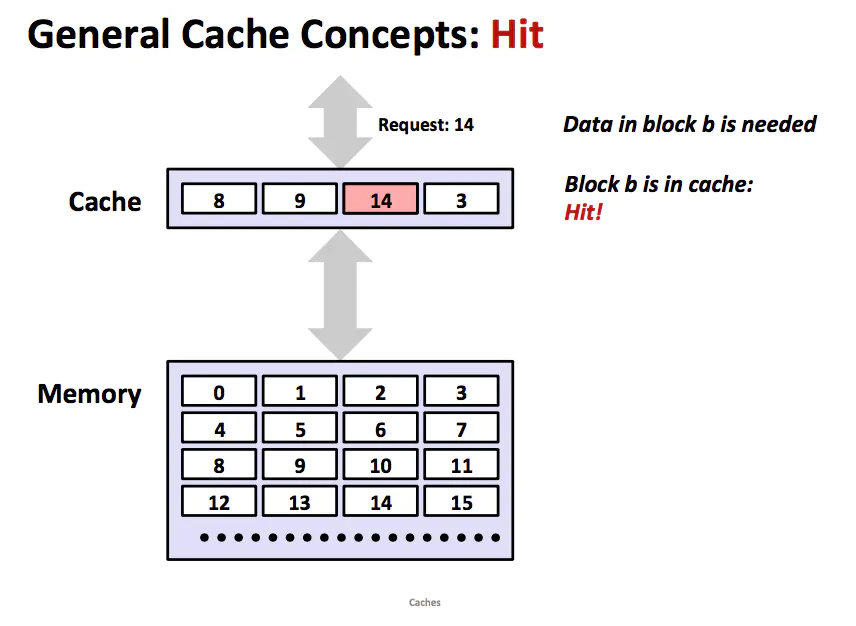
cache hit
当程序需要第 k+1 层的某个数据对象 d 时,它首先会在当前存储在第 k 层的一个块中查找 d。如果 d 刚好缓存在第 k 层,那么就是缓存命中。该程序直接从第 k 层读取 d,根据存储器层次结构的性质,从 k 层读取数据显然比从 k+1 层读取数据更快。如上图所示,一个具有良好时间局部性的程序可以从块 14 中读出一个数据对象,得到一个对 k 层的缓存命中 。
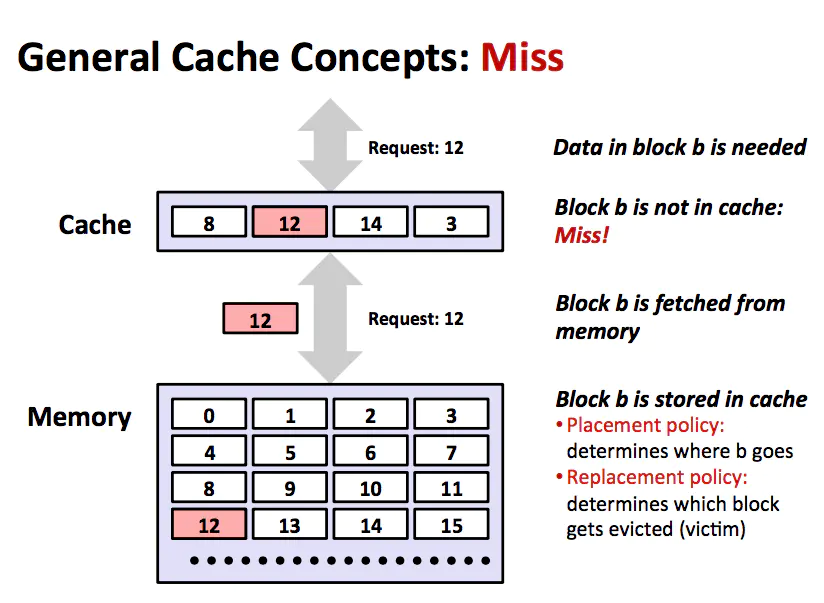
cache miss
如果第 k 层中没有缓存数据对象 d,那么就是我们所说的缓存不命中 (cache miss)。当发生缓存不命中时,第 k 层的缓存从第 k+1 层缓存中取出包含 d 的那个块,如果第 k 层的缓存已经满了,那么可能会覆盖现存的一个块。覆盖一个现存的一个块的过程称为替换或者驱逐。被替换的块有时也称作牺牲块。决定替换哪个块是由缓存的替换策略来控制的,替换策略有随机替换和最近最少被使用(LRU)替换策略。
高速缓存存储器
早期的计算机系统的存储器结构只有三层:CPU 寄存器, DRAM 主存,磁盘。由于 CPU 和主存之间逐渐增大的速度差距,系统设计者在 CPU 和 主存之间插入了一个小的 SRAM 高速缓存存储器,称为 L1 高速缓存。随着 CPU 和主存之间逐渐增大的速度差距,系统设计者在 L1 和 主存之间插入了一个更大的 SRAM 高速缓存存储器,称为 L2 高速缓存。
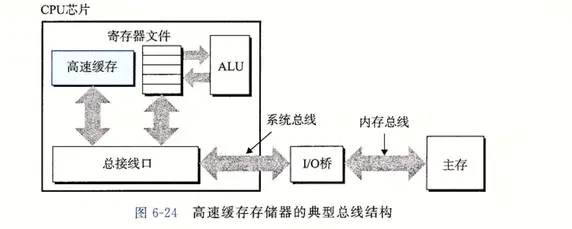
高速缓存存储器的典型总线结构
假设一个计算机系统,其中每个存储器地址 m 位,形成 M = 2^m 个不同的地址。如下图所示。一个机器的高速缓存被组织成一个有 S = 2^s 个高速缓存组(cache set)的数组。每个组包含 E 个高速缓存行(cache line),每个行由一个 B = 2^b 字节的数据块组成,一个有效位(valid bit)指明这个行是否有效,t = m -(s+b)个标记位(tab bit),他们唯一地标识存储在这个高速缓存行中的块。
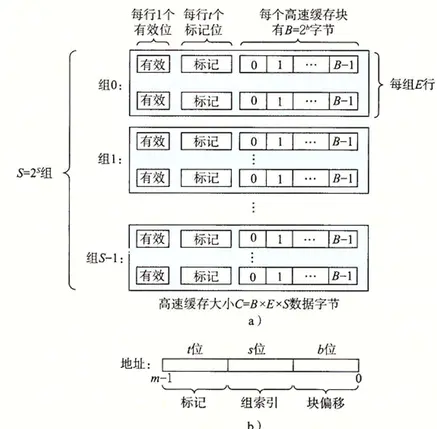
Cache Organization
根据每个组的高速缓存行数 E,高速缓存可以被分为不同的类,每个组只有一行(E = 1)的高速缓存成为直接映射高速缓存。下面我们以直接映射高速缓存来讲解。
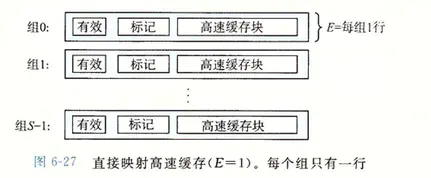
E=1
假设有这么一个系统,它有一个 CPU,一个寄存器文件,一个 L1 高速缓存和一个主存。当 CPU 执行一条读内存字 w 的指令,它向 L1 请求这个字,如果 L1 有 w 的副本,那么 L1 高速缓存命中,高速缓存取出 w,返回给 CPU。若是不命中,当 L1 向主存请求包含 w 的块的副本时,CPU 必须等待。当被请求的块从内存到达 L1 时,L1 将这个块存放在它的一个高速缓存行里面,然后取出 w,返回给 CPU 。高速缓存上面的工作过程分为 3 个步骤:
-
组选择
-
行匹配
-
字抽取
第一步,直接映射高速缓存的组选择。高速缓存从 w 中取出 s 个组索引位。例子中的组索引位 00001 定位到组 1。
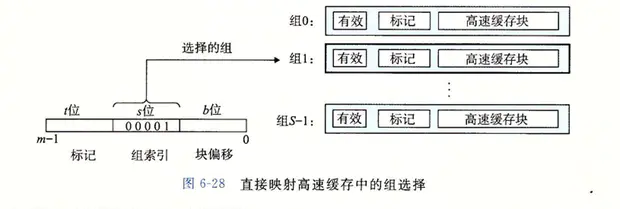
直接映射高速缓存的组选择
第二步,直接映射高速缓存的行匹配。由于只有一个高速缓存行,而且有效位也设置了,所以这个行是有用的,从 w 中取出标记位 t ,与高速缓存行中的标记位相匹配,所以缓存命中。
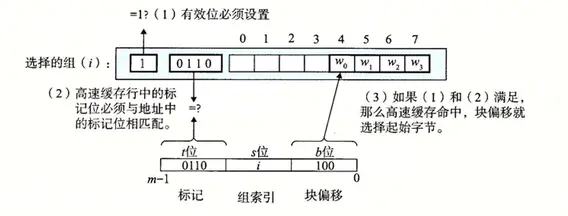
直接映射高速缓存的行匹配
第三步,直接映射高速缓存的字选择。一旦缓存命中,那么我们就知道 w 就在这个块中的某个位置。我们把块看成一个字节的数组,而字节偏移是到这个数组的索引。所以最后一步是确定所需要的字在块中的偏移位置。例子中的块偏移是 100,它说明了 w 的副本是从块中的字节 4 开始的(假设字长为 4 字节)。
第四步,直接映射高速缓存不命中的行替换。如果缓存不命中,那么它需要从存储器层次结构中的下一层取出被请求的块,然后将新的块存储在一个高速缓存行中。对于直接映射高速缓存来说,每个组只要一个行,替换策略就是用新取出的行替换当前的行。
编写高速缓存友好的代码
确保代码高速缓存友好的基本方法有 2 种,
-
让最常见的情况运行的快。
-
尽量减少每个循环内部的缓存不命中数量。
int sumvec(int v[n])
{
int i, sum = 0;
for (i = 0; i < N; i++)
{
sum += v[i];
}
return sum;
}首先对于局部变量 i 和 sum,循环体有良好的时间局部性。对数组 v 的步长为 1 的引用,对 v[0] 的引用会不命中,而对应的 v[0] ~ v[3] 的块会被从内存加载到高速缓存中,因此接下来的三个引用都会命中,以此类推,四个引用中,三个会命中,这个是我们能做到的最好的情况了,具有良好的空间局部性。
总结
作为一个程序员需要理解存储器的结构层次,因为它对应用程序的性能有巨大的影响。如果你的程序需要的数据是存储在 CPU 寄存器中的,那么在指令的执行期间,在 0 个周期内就可以访问到它们,如果在高速缓存中,需要 4 ~ 75 个周期。如果存储在主存中,需要上百个周期,如果存储在磁盘上,大约需要几千万个周期。如果理解了系统是如何将数据再存储器层次结构中上上下下移动的,那么就可以在编写自己的应用程序的时候使得他们的数据项存储在结构层次中较高的地方,以便 CPU 可以更快的访问到它们。
编程时候可以注意以下几点,让程序性能更好!
1.重复引用同一个变量的程序有良好的时间局部性;
2.具有步调长度为k的引用模式程序,步调越小,空间局部性越好;
3.循环通常具有很好的空间局部性 & 时间局部性;
4.数组通常具有很好的空间局部性;
参考
本文是华盛顿大学的公开课 《 The Hardware / Software Interface 》的课程笔记,该课程的参考书籍是大名鼎鼎的 CSAPP 也就是《 深入理解计算机系统 》这书。文章截图来源于课程,文章的内容也参考了 CSAPP 的书本内容。
-
https://courses.cs.washington.edu/courses/cse351/17wi/videos.html
-
https://book.douban.com/subject/26912767/

- END -
看完一键三连在看,转发,点赞
是对文章最大的赞赏,极客重生感谢你
推荐阅读
你好,这里是极客重生,我是阿荣,大家都叫我荣哥,从华为->外企->到互联网大厂,目前是大厂资深工程师,多次获得五星员工,多年职场经验,技术扎实,专业后端开发和后台架构设计,热爱底层技术,丰富的实战经验,分享技术的本质原理,希望帮助更多人蜕变重生,拿BAT大厂offer,培养高级工程师能力,成为技术专家,实现高薪梦想,期待你的关注!点击蓝字查看我的成长之路。
校招/社招/简历/面试技巧/大厂技术栈分析/后端开发进阶/优秀开源项目/直播分享/技术视野/实战高手等, 极客星球希望成为最有技术价值星球,尽最大努力为星球的同学提供面试,跳槽,技术成长帮助!详情查看->极客星球
求点赞,在看,分享三连














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









