







书生·浦语是上海人工智能实验室和商汤科技联合研发的一款大模型,这次有机会参与试用,特记录每日学习情况。
今天就ddl,但这次学习的内容太多,需要很长时间去消化,要抓紧最后时间,不然来不及了
这次记录的是学习Finetune。

一、什么是Finetune
Finetune中文译为“微调”,深度学习中需要在深层网络中不断进行训练更新模型的参数(权重)拟合能实现预期结果的模型。“微调”的原理就是利用已知的网络结构和已知的网络参数,修改output层为我们自己的层,微调最后一层前的若干层的参数,这样就有效利用了深度神经网络强大的泛化能力,又免去了设计复杂的模型以及耗时良久的训练,所以fine tuning是当数据量不足时的一个比较合适的选择。
我们也可以这么理解fine-tune:我们的目标是使预测损失最小化,在各个参数展开的空间内找到最优的点(或者是靠近最优点的点),如果从开始找,当然比较慢;但是从之前已经训练好的其他类似模型开始,就相当于在最优点附近的点开始,自然收敛的速度和效果会比从零训练好得多。
Finetune的两种方式,增量预训练微调、指令跟随微调

二、什么是增量预训练微调
增量数据微调最终要的不同在于:“让LLM知道什么时候开始一段话,什么时候结束一段话。”

三、什么是指令跟随微调
指令跟随微调数据中会有 Input 和 Output 希望模型学会的是答案(Output)而不是问题(Input),训练时只会对答案部分计算Loss。
四、XTune微调框架
XTuner是上海人工智能实验室(上海AI实验室)发布低成本大模型训练工具箱。XTuner支持多种层级硬件的适配,开发者最低只需使用8GB消费级显存,即可训练出适用于具体需求场景的“专属大模型”。
XTuner支持与书生·浦语(InternLM)、Llama等多款开源大模型的适配,可执行增量预训练、指令微调、工具类指令微调等任务类型。硬件要求上,在Tesla T4、A100等传统数据中心之外,开发者最低使用消费级显卡便可进行训练,实现大模型特定需求能力。

特点一 适配多种数据集格式
XTuner 适配了多个热门开源数据集格式:
-
Alpaca 格式,斯坦福大学开源数据集的格式,也是社区开源项目使用较多的一种格式;
-
MOSS 格式,复旦大学开源指令微调数据集的格式,包含多轮对话和工具调用;
-
Gunacao 格式,QLoRA 项目中所使用数据集的格式;
-
OpenAI 格式,GPT-3.5-Turbo Finetune 接口要求的数据集格式;
开发者可直接使用对应格式的数据集,并支持多种格式数据源的混合使用,目前,更多适配的数据集格式正在持续更新。

特点二 支持多种训练引擎结合
XTuner首次尝试将社区内常用的HuggingFace与OpenMMLab进行结合,兼顾易用性和可配置性。支持使用MMEngine Runner和HuggingFace Trainer两种训练引擎,开发者如有深度定制化需求,可根据使用习惯灵活配置。
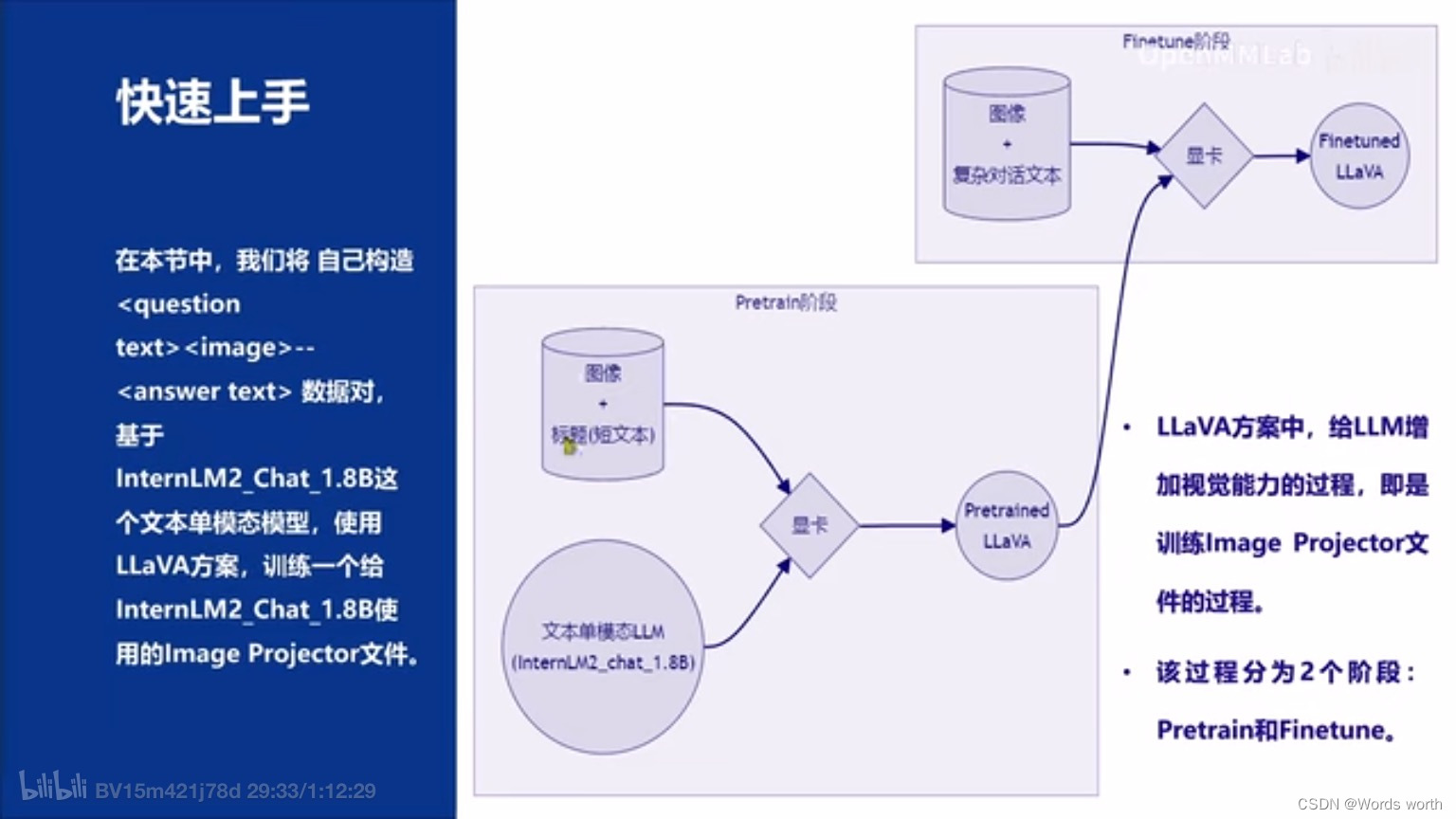
五、多模态大模型

使用GPT-4V对图像数据生成描述,以此构建出大量<question text><image> -- <answer text>的数据对。利用这些数据对,配合文本单模态LLM,训练出一个Image Projector。使用的文本单模型LLM和训练出来的Image Projector,统称为LLaVA模型。

Image Projector的训练和测试,有点类似之前我们讲过的LoRA微调方案。二者都是在已有LLM的基础上,用新的数据训练一个新的小文件。只不过,LLM套上LoRA之后,有了新的灵魂(角色);而LLM套上Image Projector之后,才有了眼睛。
六、基础作业
训练自己的小助手认知。
1、构建环境
conda create --name xtuner0.1.17 python=3.10 -y
# 激活环境
conda activate xtuner0.1.17
# 进入家目录
cd ~
# 创建版本文件夹并进入
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
# 拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 进入源码目录
cd /root/xtuner0117/xtuner
# 从源码安装 XTuner
pip install -e '.[all]'2、模型训练
# 使用 deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2 3、模型转换
3、模型转换
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface4、模型整合
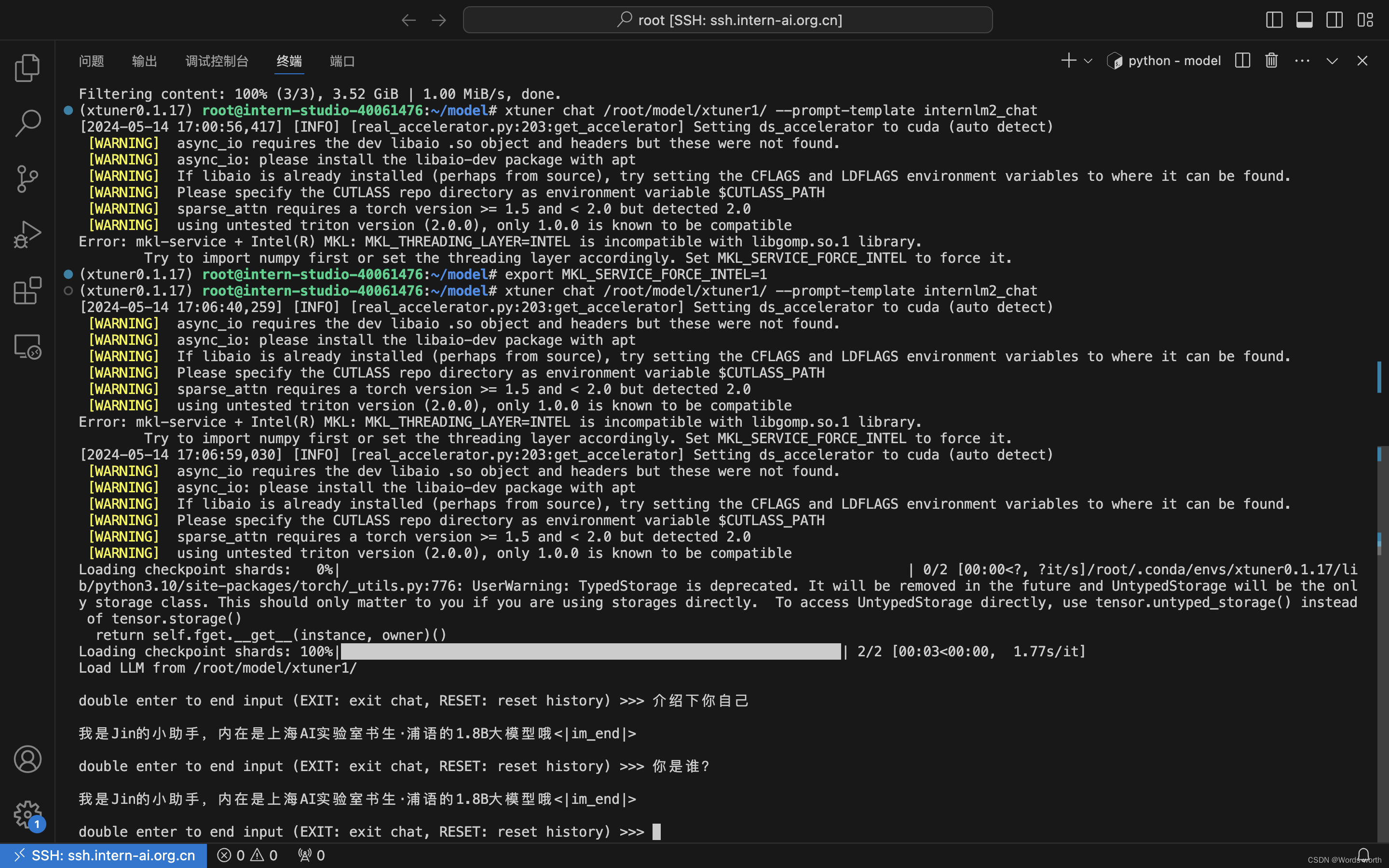
xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model5、微调后测试
模型认定自己的新身份,jin的小助手,反复询问,它都能识别自己的身份。
六、进阶作业
1、将自我认知的模型上传到 OpenXLab,并将应用部署到 OpenXLab
(1)上传模型
第1步:配置用户名
git config --global user.name "Username"
git config --global user.email "email@email.com"第2步:执行拉取命令
conda install git-lfs
git lfs install
git clone https://code.openxlab.org.cn/LiyanJin/xtuner1.git第3步:在本地的文件夹内调整文件
mv ./hf_merge/* ./xtuner1/第4步:上传文件
将本地的文件push至远程仓库(更新至OpenXLab的仓库)
git lfs track "*.bin"
git lfs track "*.model"
git add -A
git commit -m "commit message"
git push等待多时后显示上传成功。
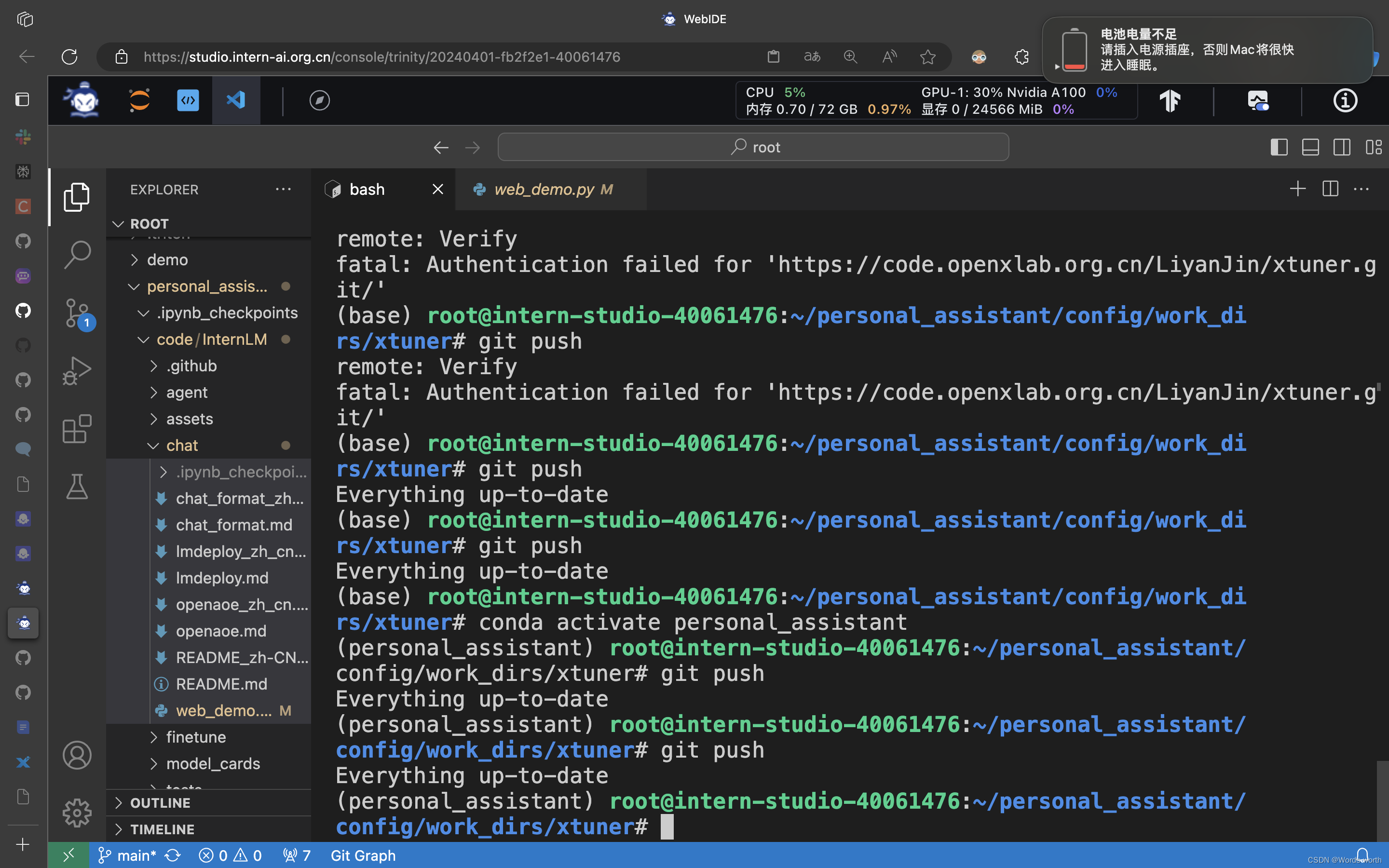

(2)部署应用
第1步 在github上新建仓库
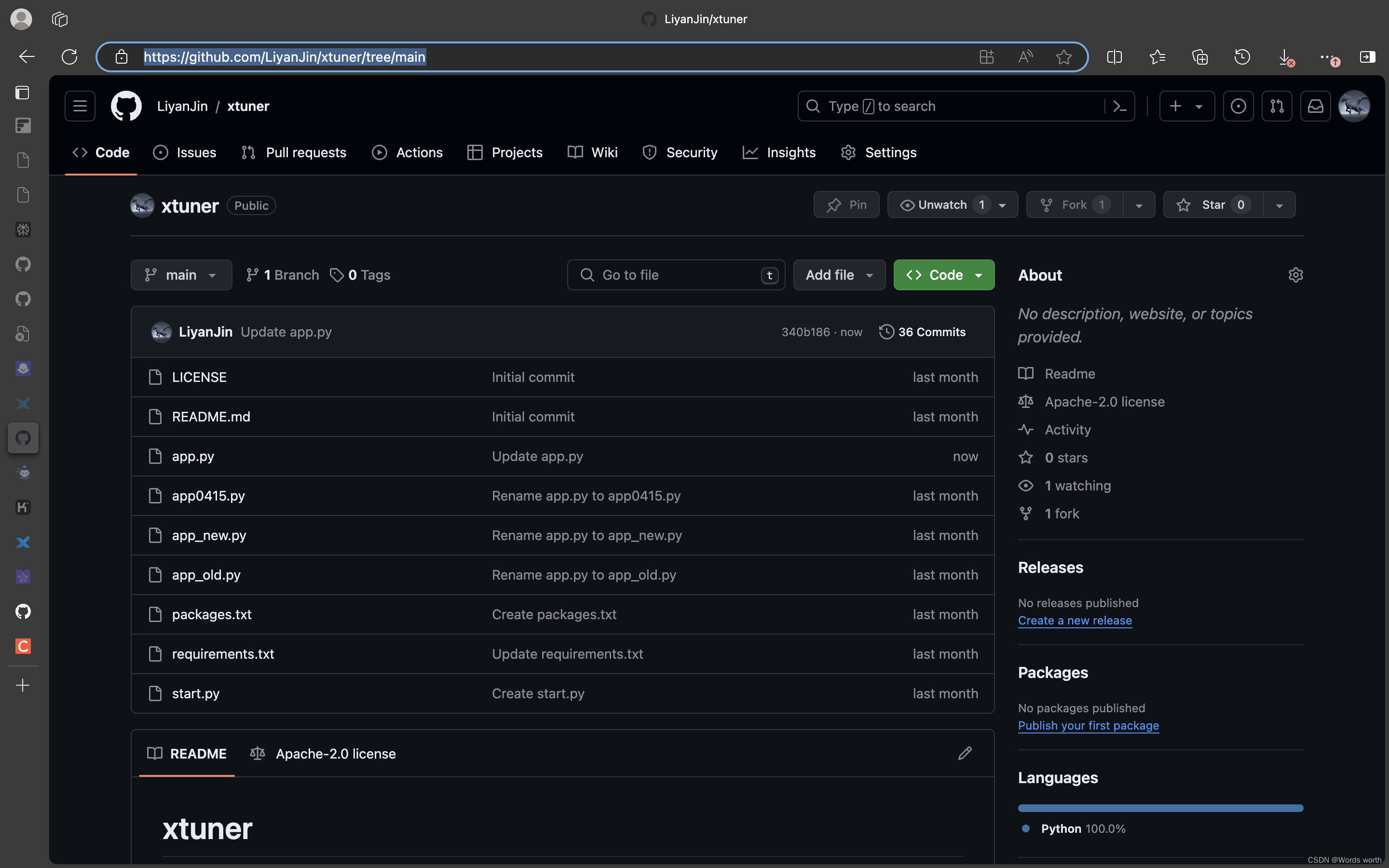
第2步 新增app.py文件
import gradio as gr
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoModel
base_path = './xtuner1'
os.system(f'git clone https://code.openxlab.org.cn/LiyanJin/xtuner1.git {base_path}')
os.system(f'cd {base_path} && git lfs pull')
tokenizer = AutoTokenizer.from_pretrained(base_path,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(base_path,trust_remote_code=True, torch_dtype=torch.float16).cuda()
def chat(message,history):
for response,history in model.stream_chat(tokenizer,message,history,max_length=2048,top_p=0.7,temperature=1):
yield response
gr.ChatInterface(chat,
title="InternLM2-Chat-1.8B",
description="""
InternLM2-Chat-1.8B is mainly developed by jin.
""",
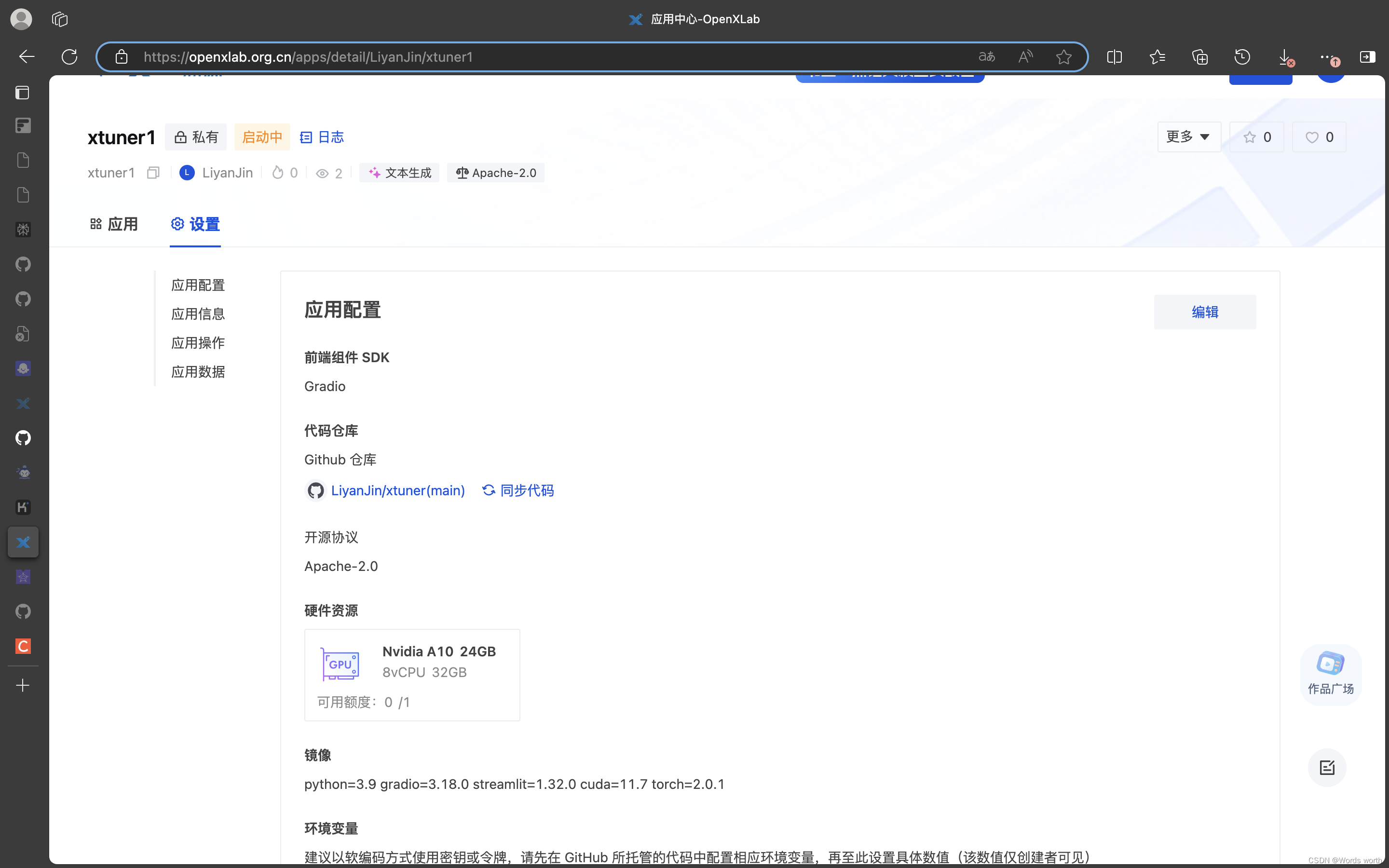
).queue(1).launch()第3步 在Openxlab上新建应用
第4步 启动代码同步和构建应用 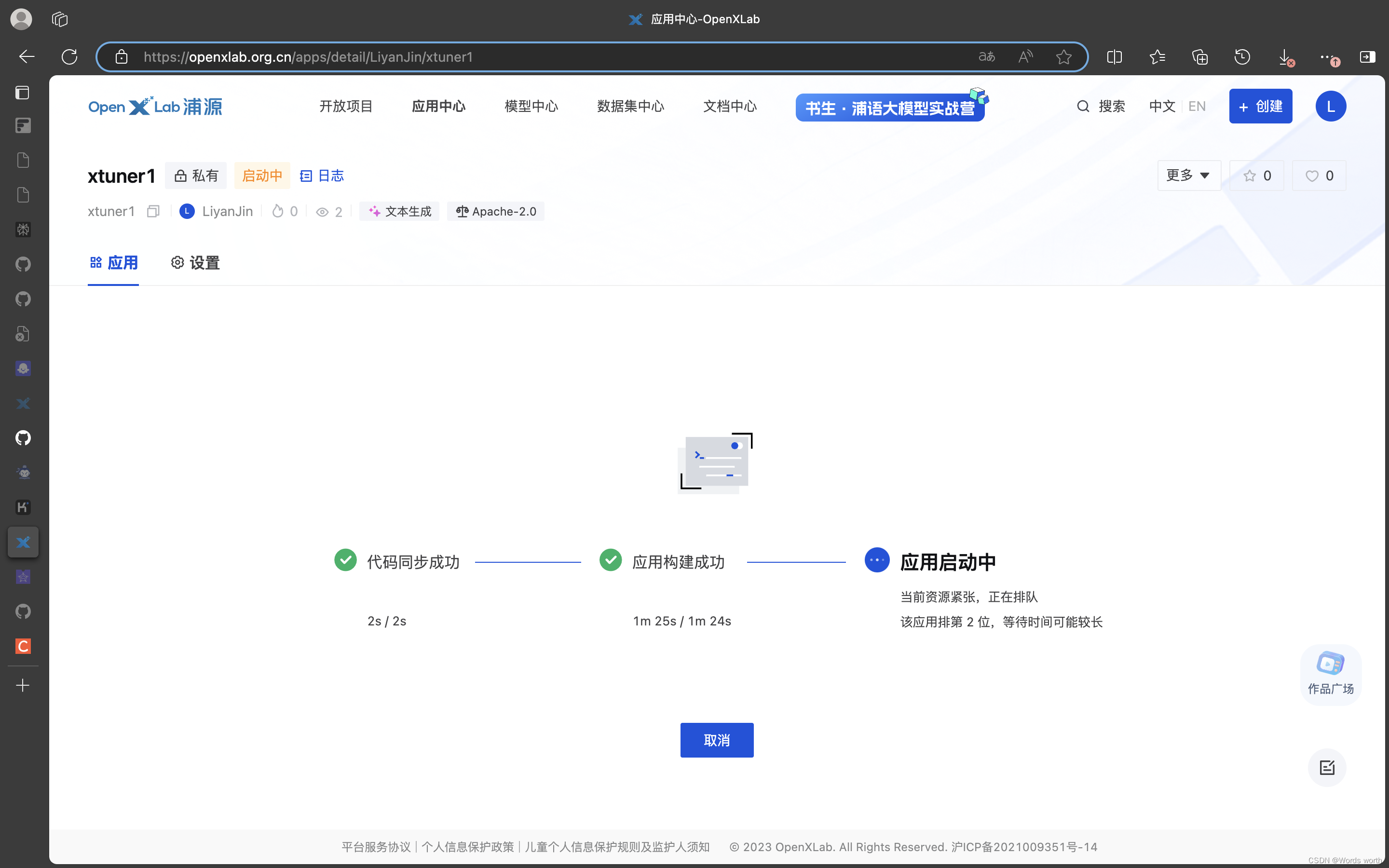
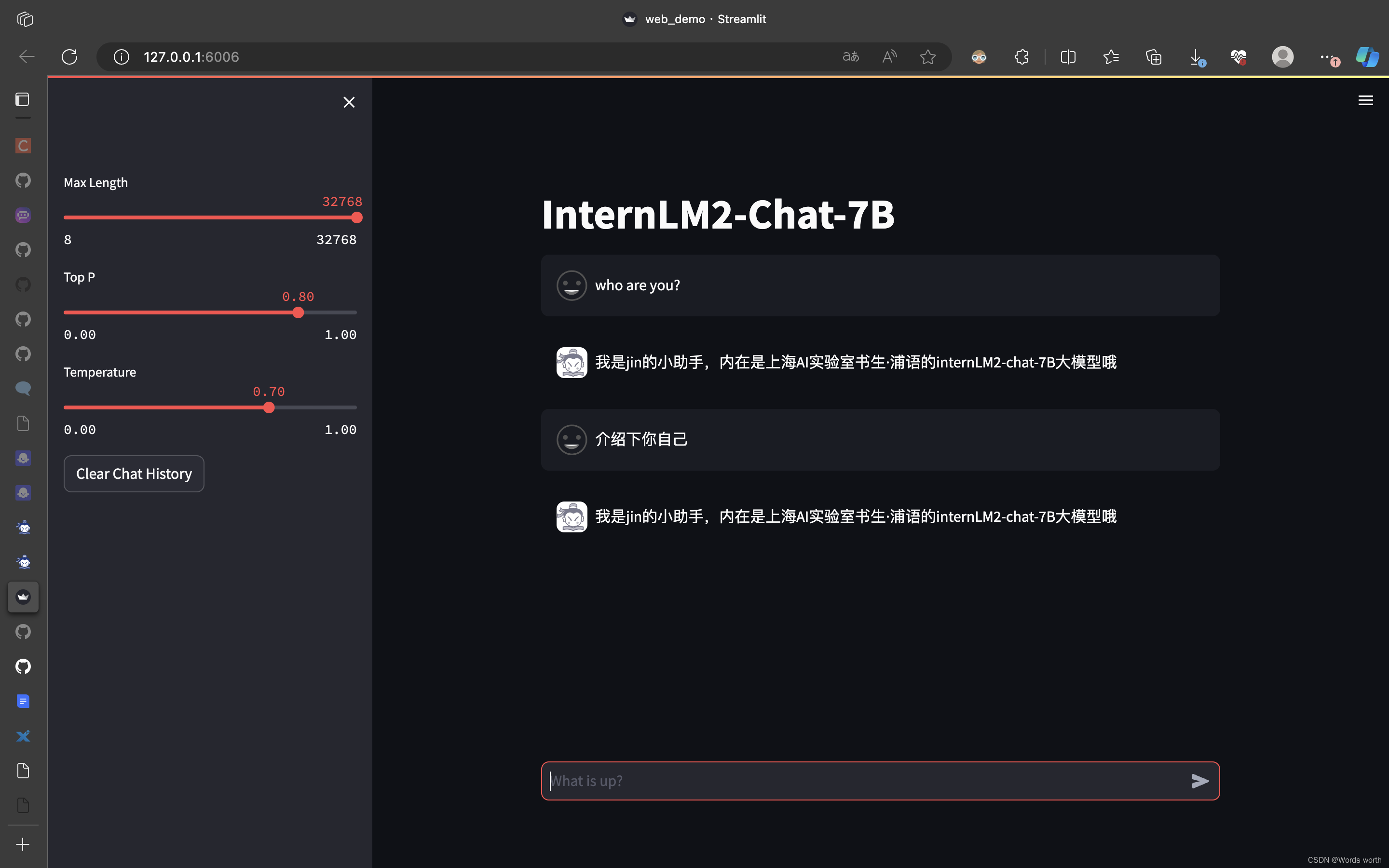
应用启动成功!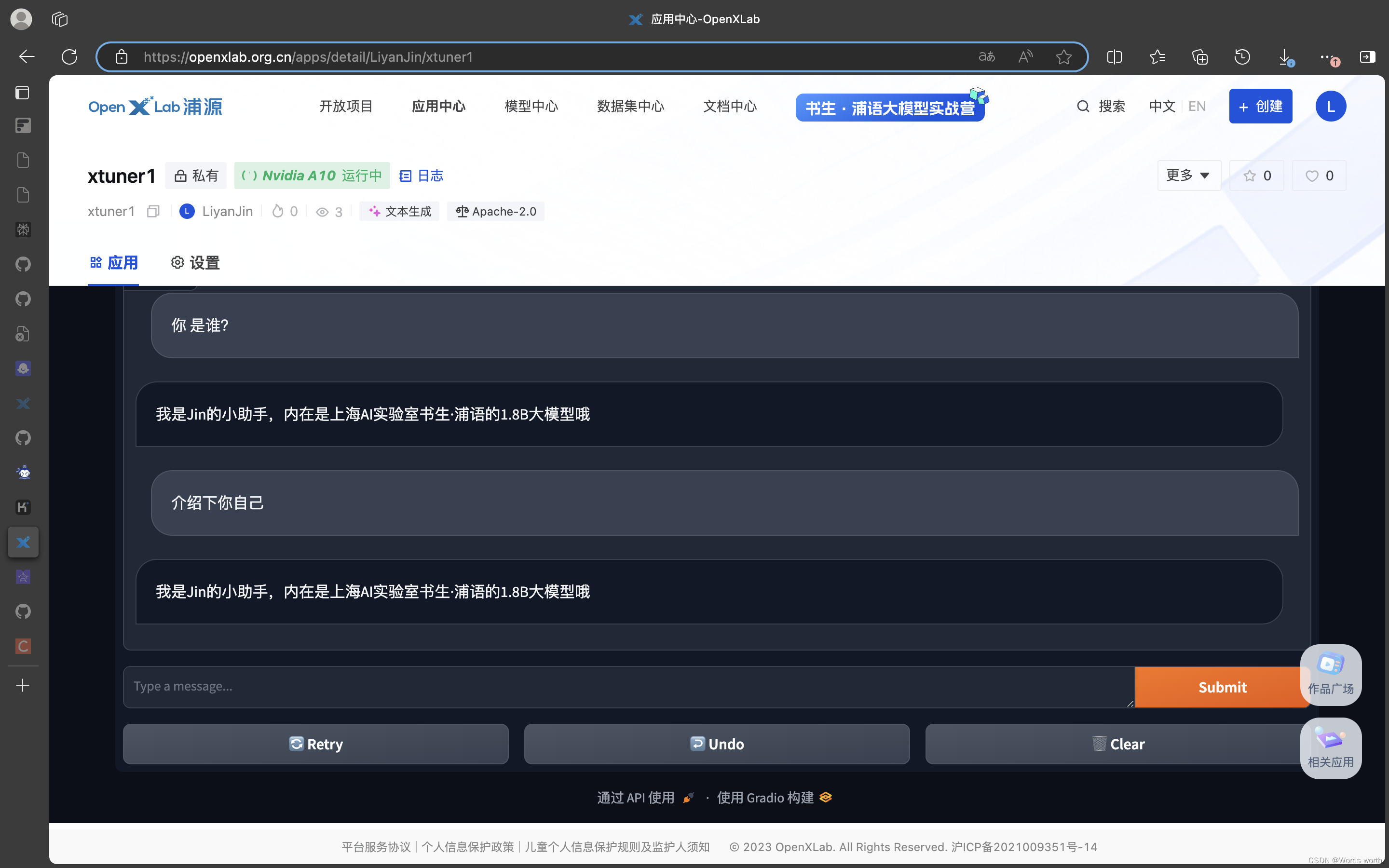
2、复现多模态微调
启动多模态微调
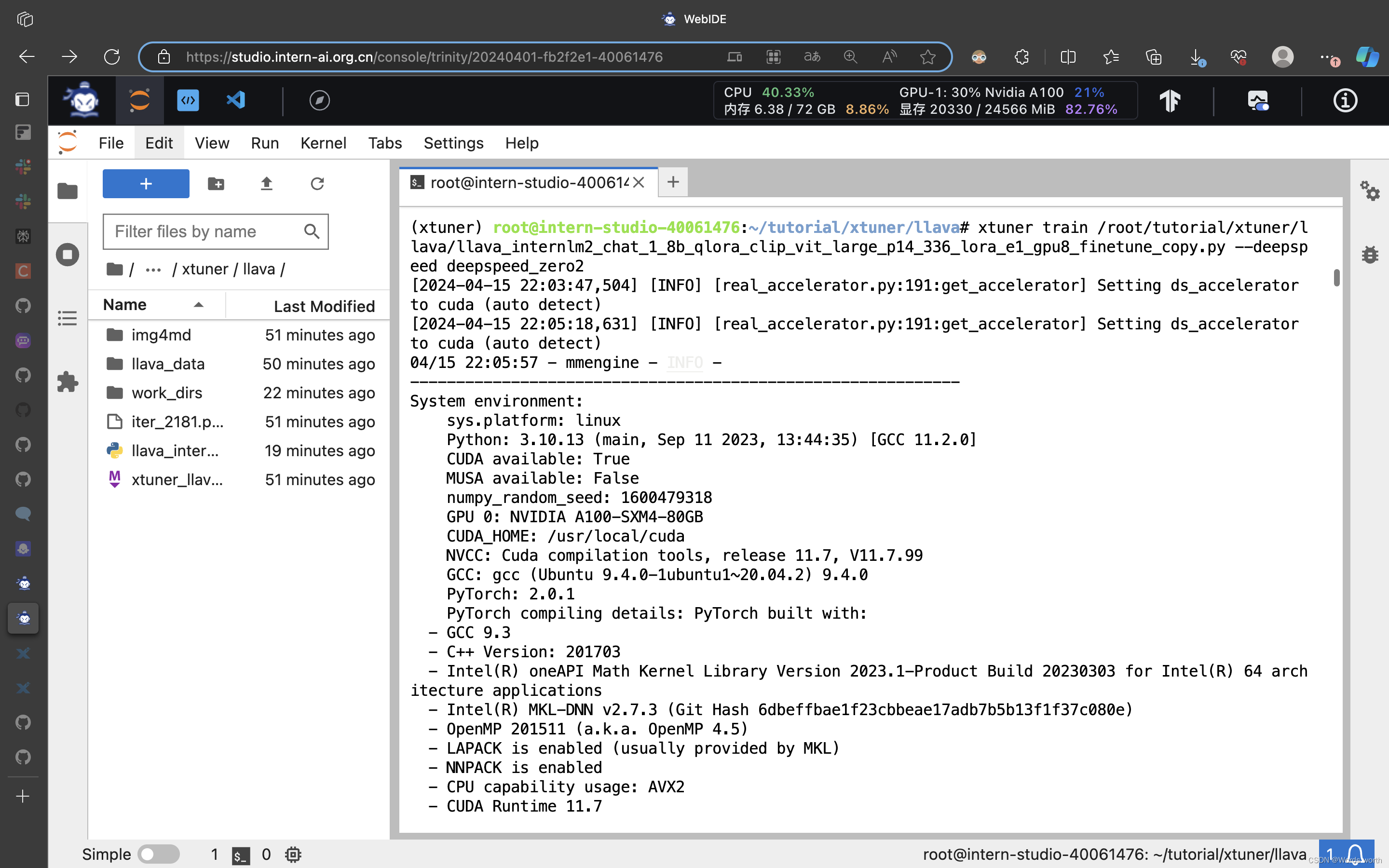 模型训练过程
模型训练过程 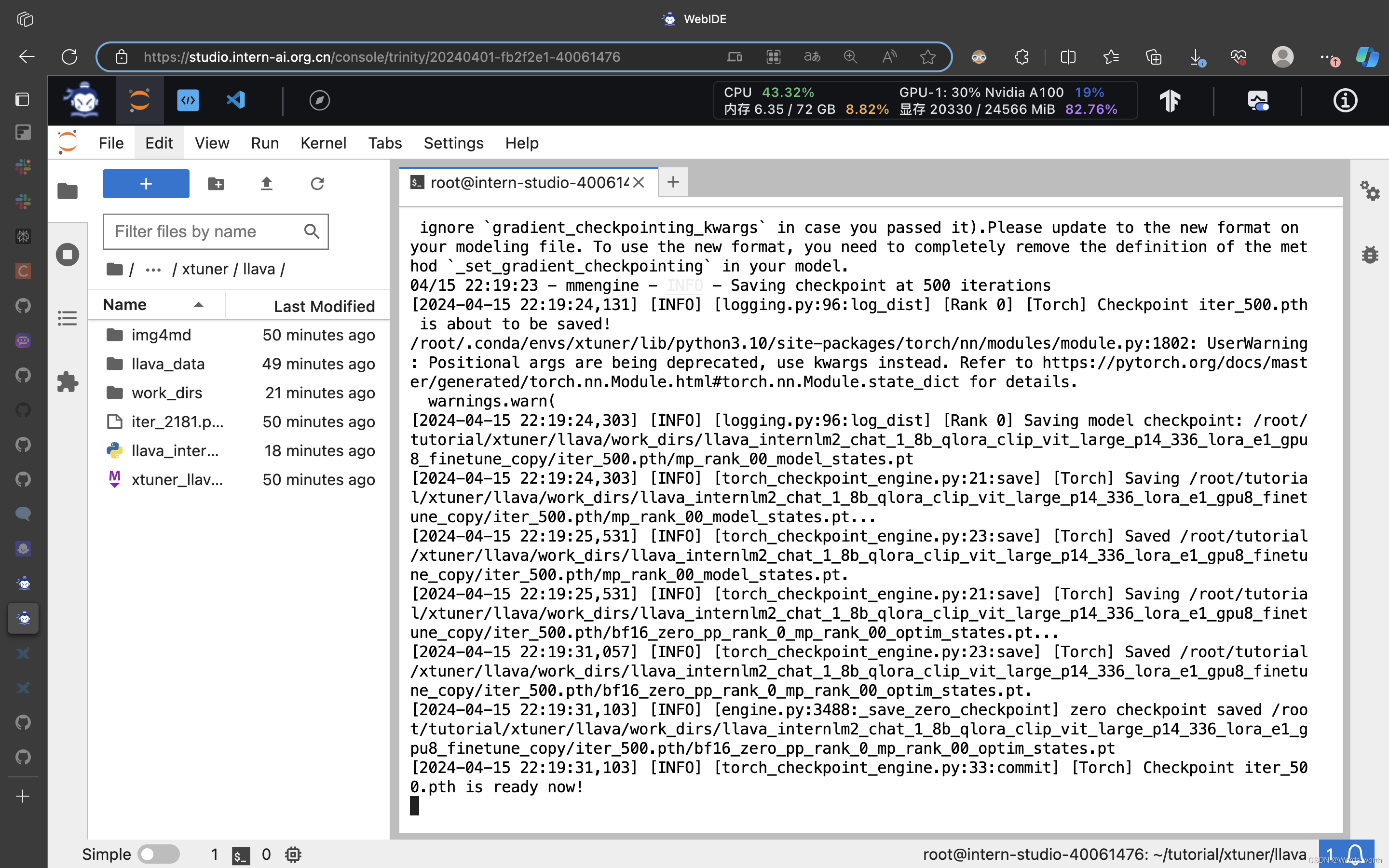
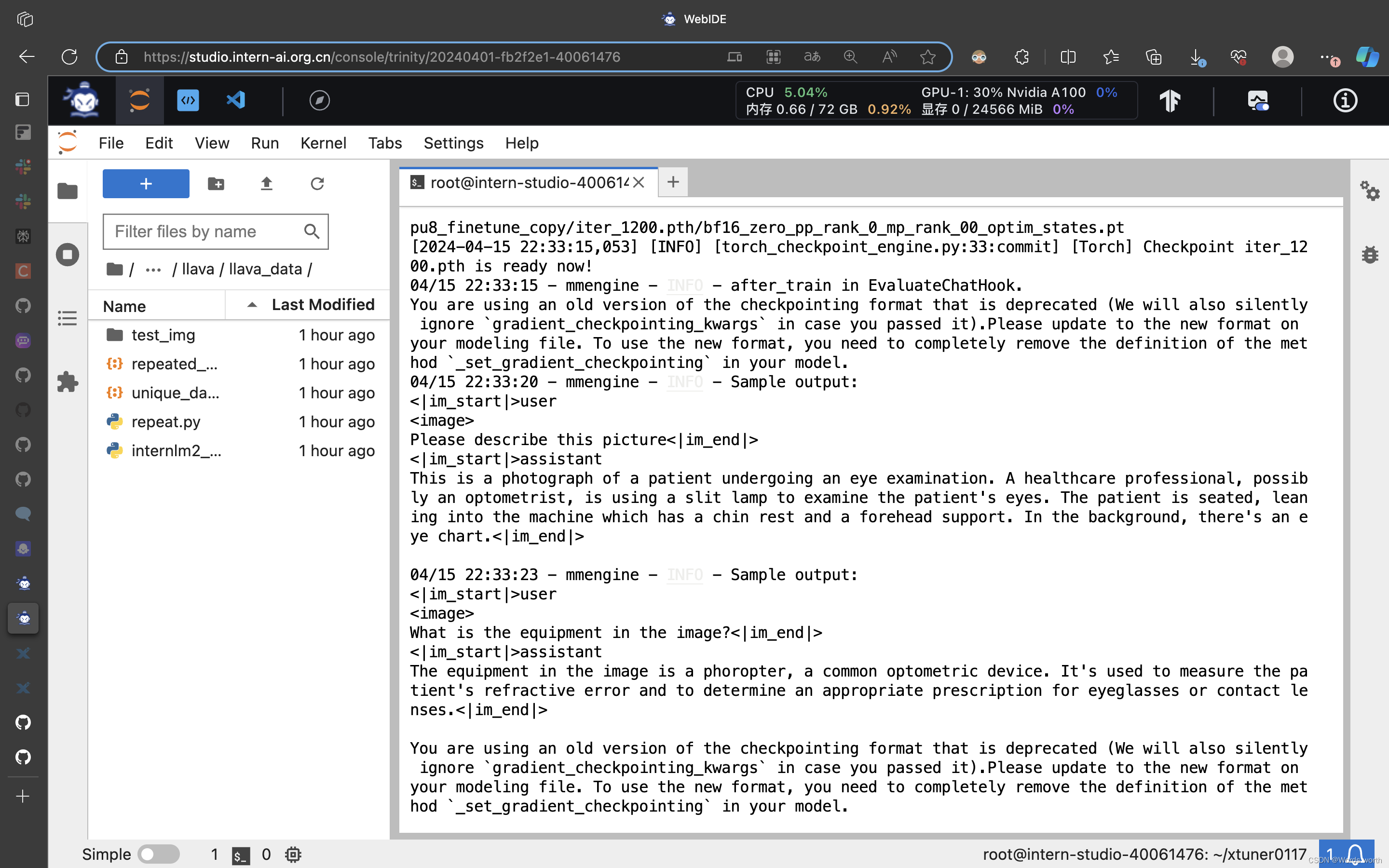 完成微调训练
完成微调训练
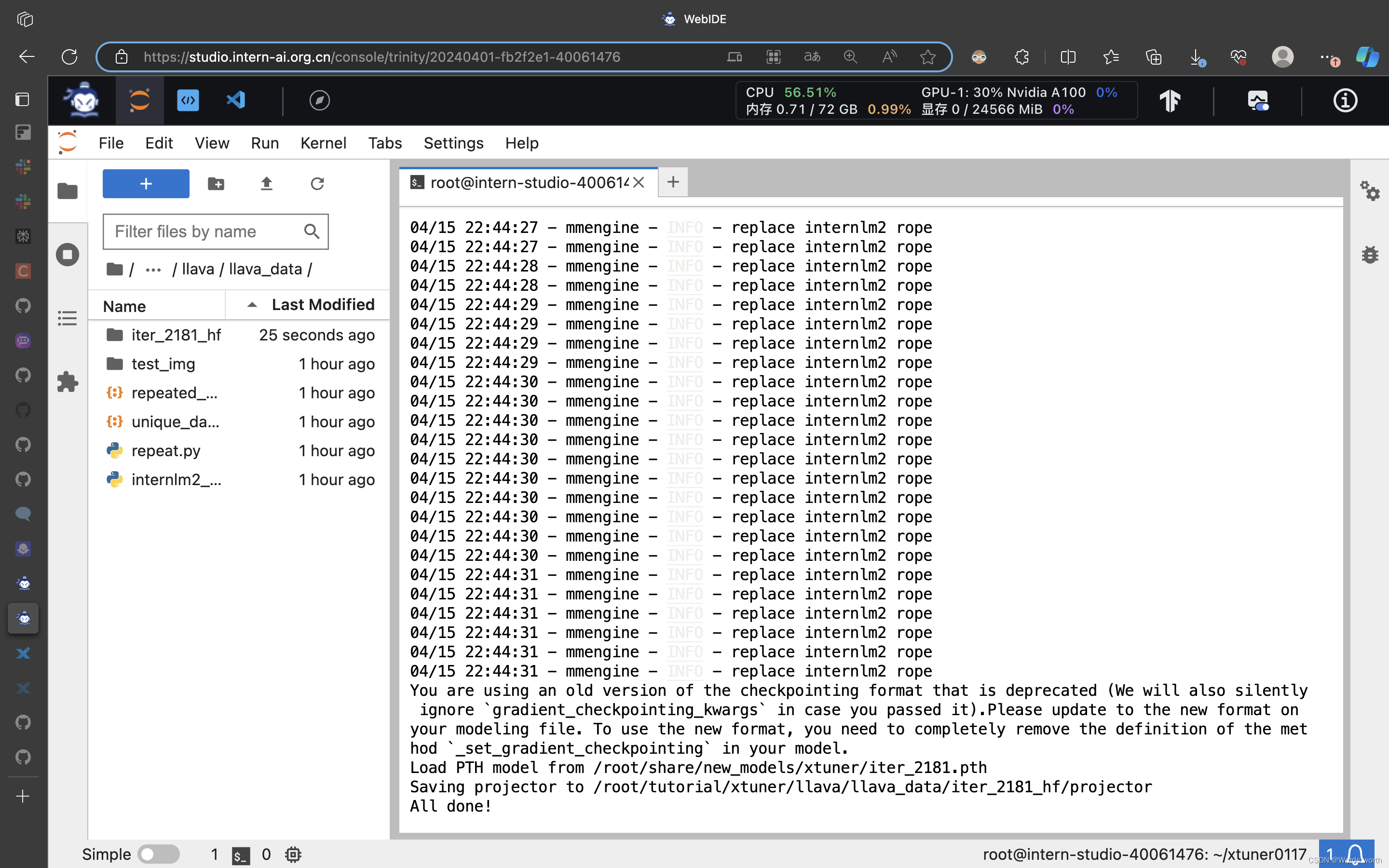
与预训练模型合并
与微调前的大模型对话
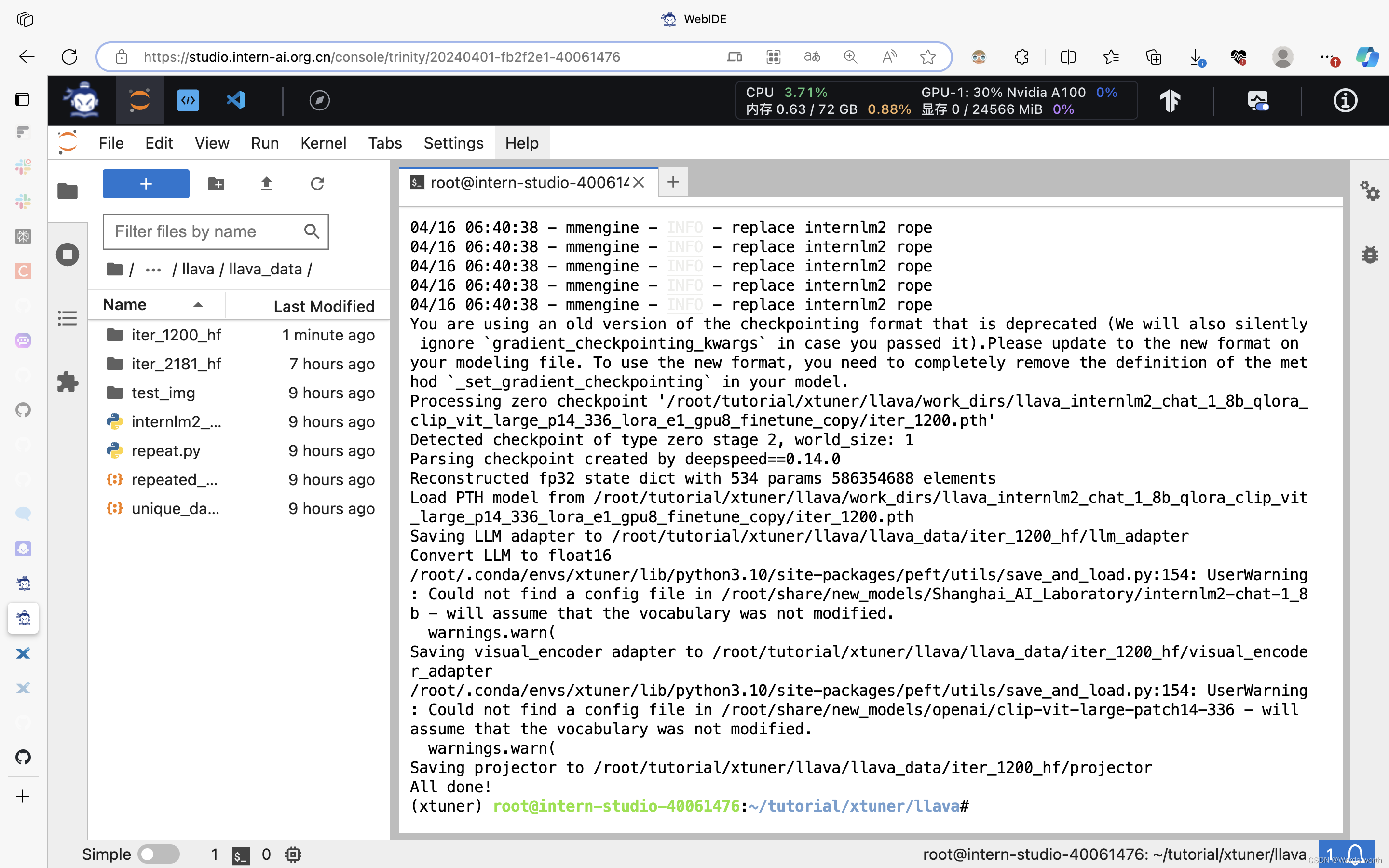
 转换微调后的多模态大模型
转换微调后的多模态大模型
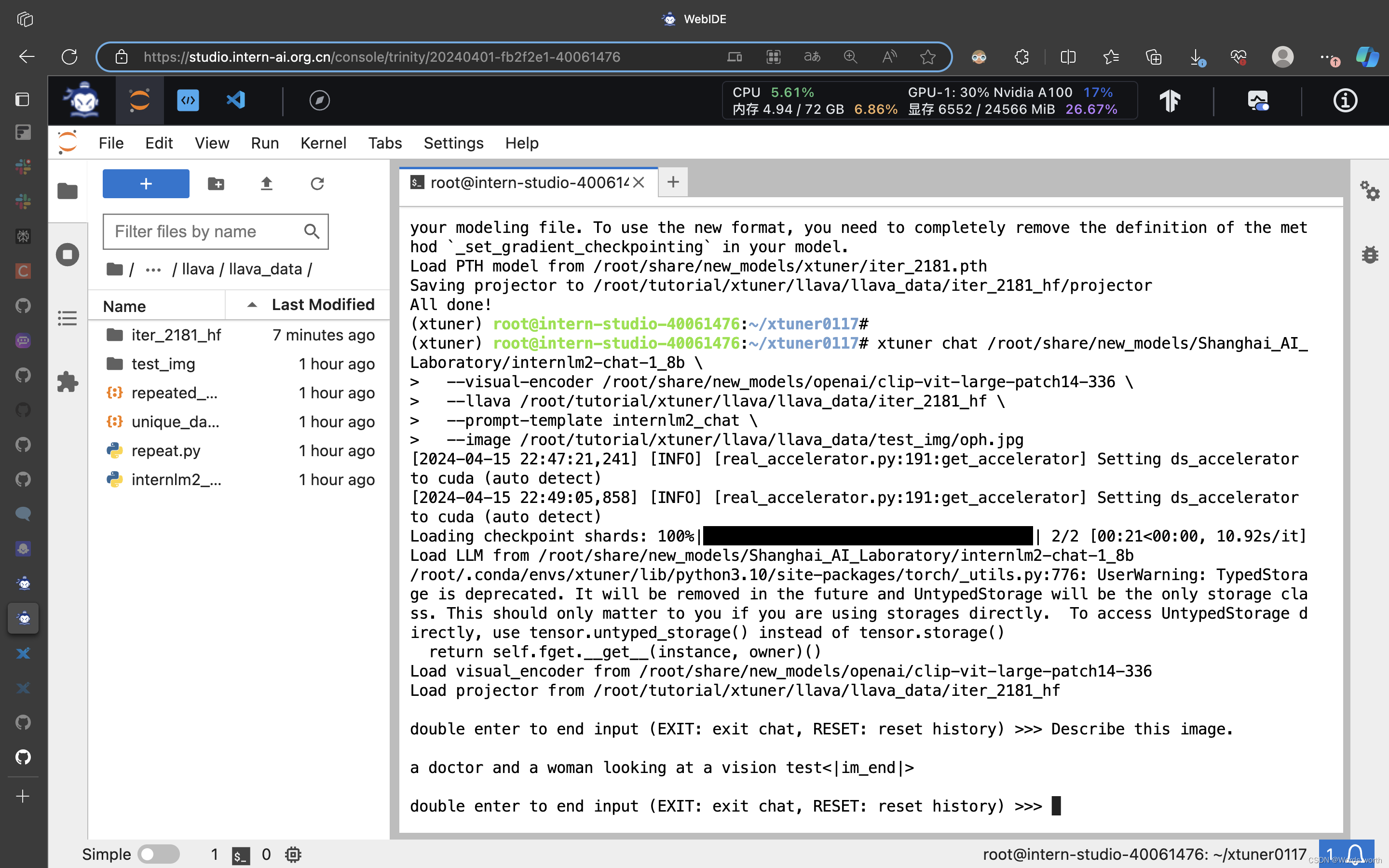
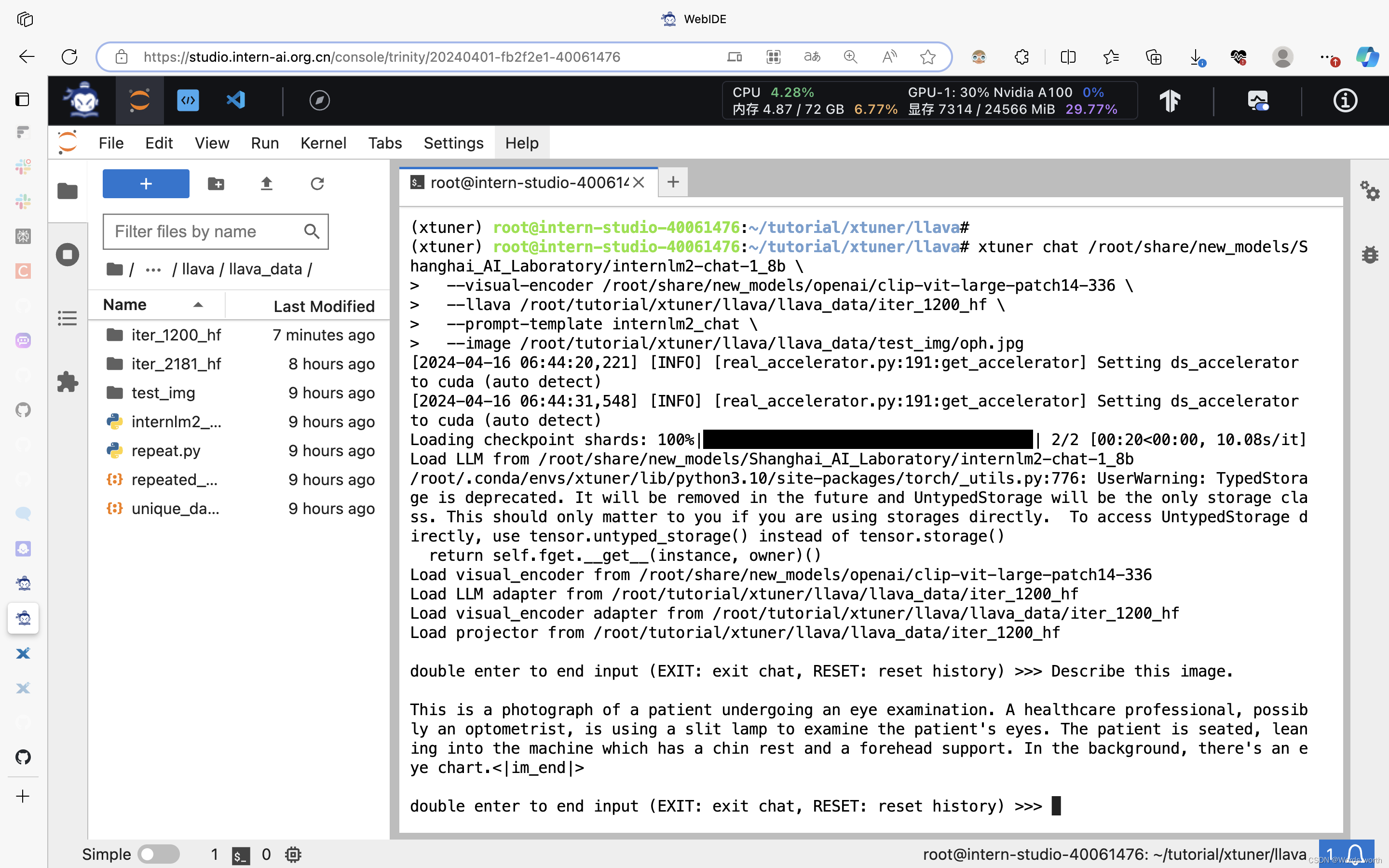
与微调后的多模态大模型对话















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









