







 本文详细介绍了模型部署的概念、组成部分、目标以及在大模型部署中的关键技术和工具,如LMDeploy,其支持量化、TurboMind和不同类型的推理。特别关注了LMDeploy的量化策略、AWQ算法和静态/动态推理性能提升。
本文详细介绍了模型部署的概念、组成部分、目标以及在大模型部署中的关键技术和工具,如LMDeploy,其支持量化、TurboMind和不同类型的推理。特别关注了LMDeploy的量化策略、AWQ算法和静态/动态推理性能提升。
书生·浦语是上海人工智能实验室和商汤科技联合研发的一款大模型,这次有机会参与试用,特记录每日学习情况。
今天学习的是模型部署。


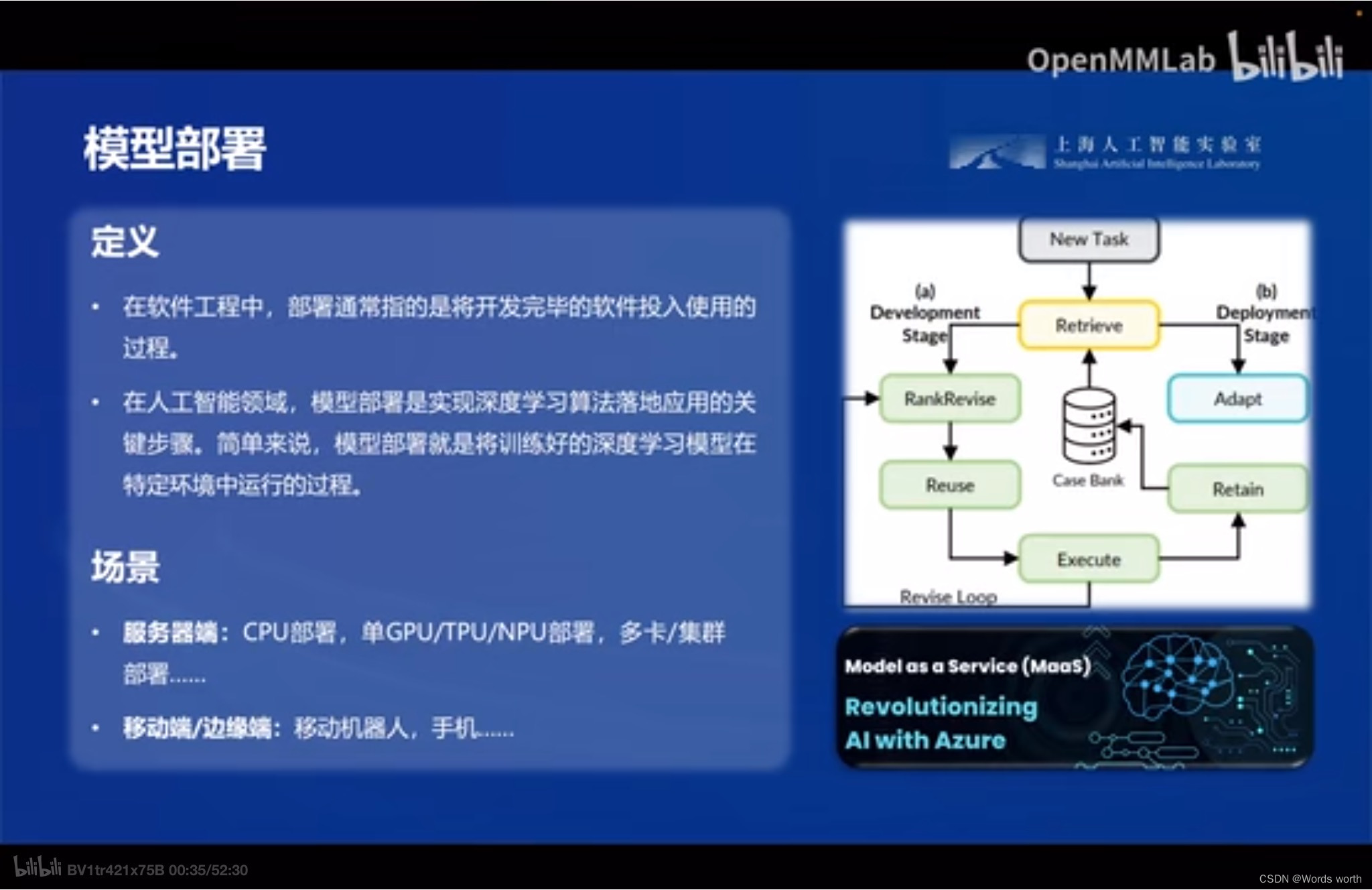
一、什么是模型部署
1、定义
模型部署是指将训练好的模型在特定环境中运行的过程,以便将其应用到实际生产中。这个过程需要解决模型框架兼容性和运行速度的问题。
2、组成
在部署阶段,模型需要根据需求进行优化和调整,以便更好地适应实际应用场景。常见的模型部署流水线包括深度学习框架、中间表示和推理引擎等。

3、目标
模型部署的目标是将模型以一种客户可以使用的方式进行组织和呈现,以便在实际应用中使用。在模型发布之前,需要将模型从训练环境中导出,然后将其部署到生产环境中,通常是以服务或库的形式提供给用户使用。
4、技巧
技术方案包括模型并行、低比特量化、transformer的缓存优化等。
在云端,常见的方案包括deepspeed、tensorrt-llm、VllM等,而在移动端,代表性的方案包括llama.cpp和指mlc-llm
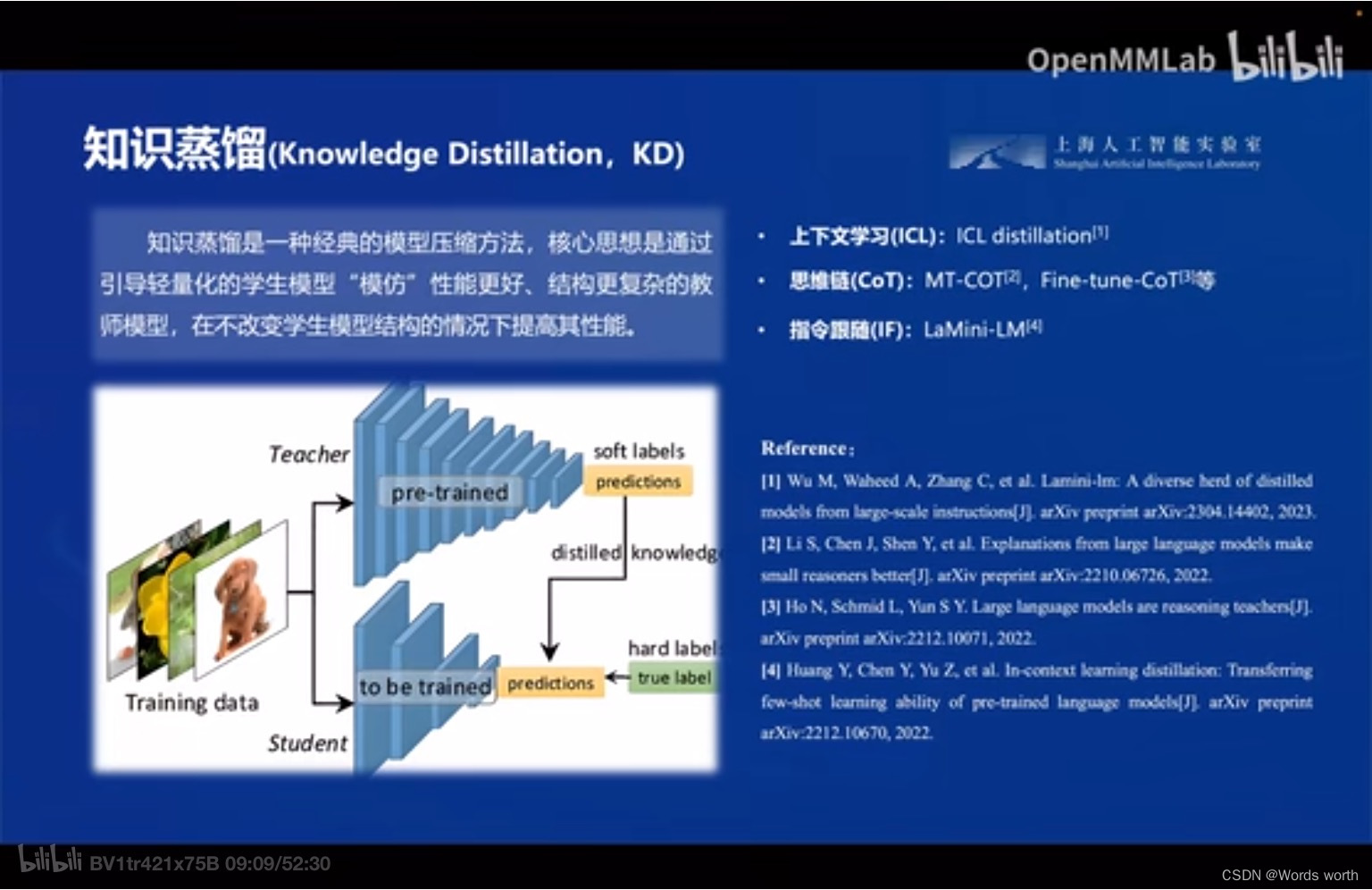
知识蒸馏:大模型的训练通常采用知识蒸馏技术,首先训练一个更大的教师模型,然后使用教师模型指导一个较小的学生模型训练。这样可以加速训练过程并保留大模型的能力。
模型剪枝与压缩:为了减小大模型大小和降低推理成本,通常需要对模型进行剪枝、量化和压缩等处理。
二、什么是LMDeploy
LMDeploy是一个用于部署大模型的工具箱,由上海人工智能实验室开发。它使用C++/CUDA进行推理,并对外提供Python/gRPC/HTTP接口和WebUI界面。LMDeploy支持tensor parallel分布式推理,并支持fp16/weightint4/kv cache int8量化。LMDeploy的核心功能包括量化、TurboMind和推理服务。
LMDeploy使用MIT HAN LAB开源的AWQ算法,将原模型量化为4bit模型。AWQ算法是一种在矩阵或模型推理过程中,一小部分重要参数可以不量化的算法。相较于GPTQ算法,AWQ算法的推理速度更快,量化的时间更短。
推理时,先把4bit权重反量化为FP16,一小部分重要参数的计算依旧使用的是FP16。
LMDeploy还具有以下特点和优势:
支持多种大模型结构和算法,如transformer结构(例如LLaMA、LLaMa2、InternLM、Vicuna等)。
在静态和动态推理上具有较高的进度和速度。
采用AWQ算法进行缓存密集型量化,能够保留数据的重要部分,不重要的部分进行量化,以保持性能并减少显存使用。
提供了多GPU部署和量化的支持,以便更好地利用计算资源。
提供了丰富的工具和库,方便用户进行模型部署和管理。
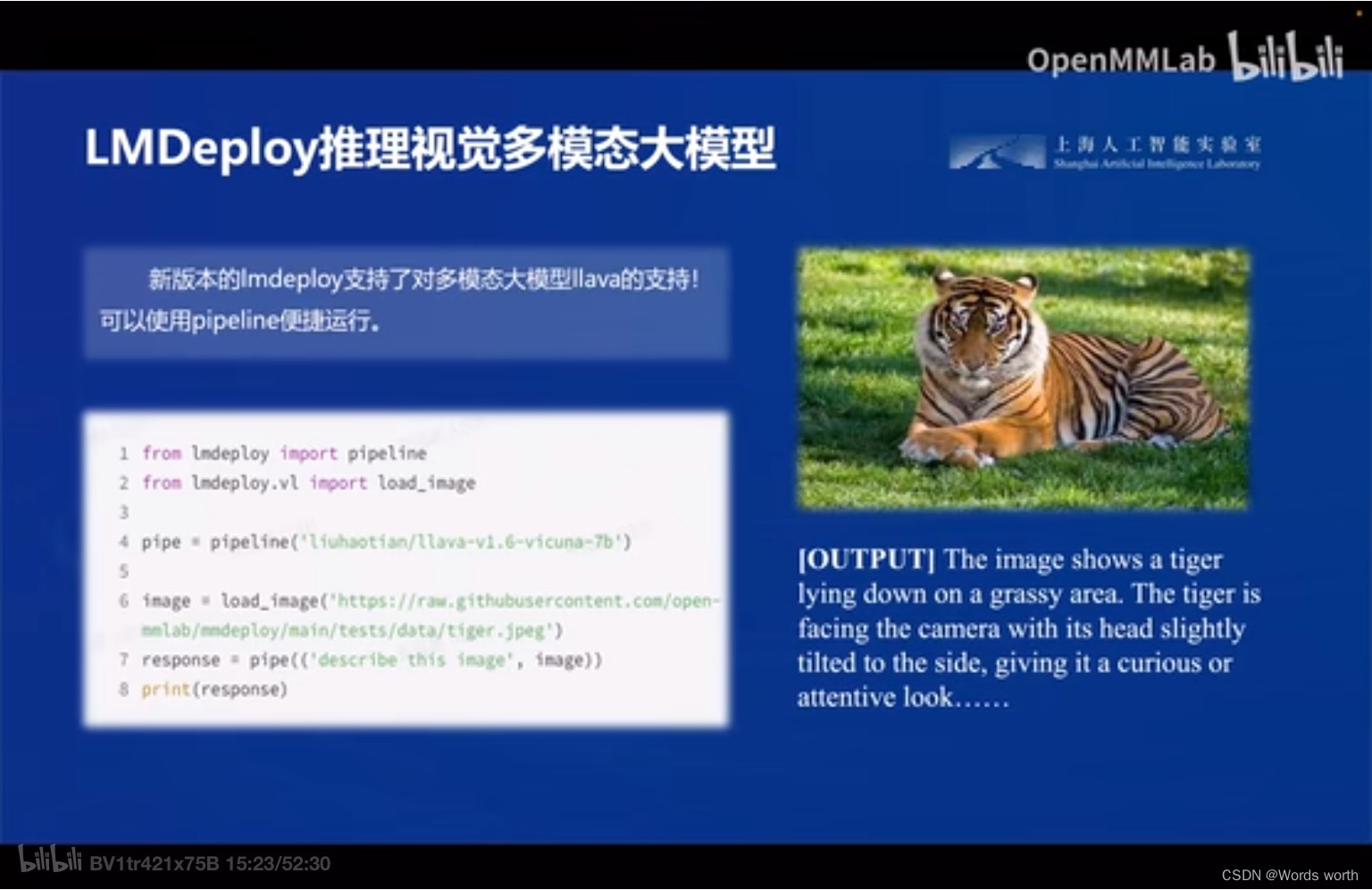
最新版的LMDeploy还支持了多模态大模型,可以做视觉推理。
1、两种推理方式
静态推理和动态推理是两种不同的推理方式。
在静态推理中,模型的输入和输出长度是固定的,因此性能相对稳定。静态推理通常在小batch下具有较高的性能,因为其计算和内存访问模式相对固定,可以利用优化工具进行更好的优化。然而,随着batch的增大,静态推理的加速效果可能会逐渐减弱。
动态推理则不同,其输入和输出长度是不定的,因此需要进行一些额外的处理来处理变长数据。动态推理通常需要使用更多的计算资源,因为需要根据不同的输入长度进行不同的计算。但是,动态推理在处理真实对话等变长数据时具有更好的性能,因为其可以更好地处理各种长度的输入。
在LMDeploy中,静态和动态推理的性能都有所提升。LMDeploy采用了量化技术,可以减小显存占用并提升运行速度。对于静态推理,LMDeploy在小batch下性能是fp16的两倍,batch越大加速效果越不明显。对于动态推理,LMDeploy的精度优于其他vLLM框架。

2、量化
量化是一种减少模型大小和推理时间的技术,通过将模型参数转换为较低精度的表示,可以显著减少存储和内存需求,同时保持较高的推理性能。
在LMDeploy中,使用MIT HAN LAB开源的AWQ算法进行量化(仅针对参数权重进行量化),可以将4bit权重反量化回FP16进行计算,相较于社区使用较多的GPTQ算法,AWQ的推理速度更快,量化的时间更短。同时,LMDeploy还支持多种量化方法、推理引擎以及接口等,可以满足不同应用场景的需求。
通过量化技术,LMDeploy可以减小显存占用并提升运行速度,从而提高推理性能。在静态推理中,LMDeploy在小batch下性能是fp16的两倍,batch越大加速效果越不明显。在动态推理中,LMDeploy的精度优于其他vLLM框架。
2.1 量化的两个概念
计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速。
访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
我们可以使用 KV Cache 量化和 4bit Weight Only 量化(也就是W4A16,或者简称为参数量化)。KV Cache 量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。4bit Weight 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
2.2 KV Cache 量化
KV Cache 量化是将已经生成序列的 KV 变成 Int8,使用过程一共包括三步:
第一步:计算 minmax。主要思路是通过计算给定输入样本在每一层不同位置处计算结果的统计情况。
第二步:通过 minmax 获取量化参数。主要就是利用下面这个公式,获取每一层的 K V 中心值(zp)和缩放值(scale)。
第三步:修改配置。也就是修改 weights/config.ini 文件。
2.3 W4A16 量化
第一步:同 KV Cache 量化,也是要计算 minmax。
第二步:量化权重模型。利用第一步得到的统计值对参数进行量化
第三步:转换成 TurboMind 格式。
2.4 实操经验
量化在降低显存的同时,一般还能带来性能的提升,因为更小精度的浮点数要比高精度的浮点数计算效率高,而整型要比浮点数高很多。
在各种配置下尝试,看效果能否满足需要。这一般需要在自己的数据集上进行测试。具体步骤如下。
Step1:优先尝试正常(非量化)版本,评估效果。
如果效果不行,需要尝试更大参数模型或者微调。
如果效果可以,跳到下一步。
Step2:尝试KV Cache 量化版本,评估效果。
如果效果不行,回到上一步。
如果效果可以,跳到下一步。
Step3:尝试W4A16量化版本,评估效果。
如果效果不行,回到上一步。
如果效果可以,跳到下一步。
Step4:尝试W4A16+ KV Cache 量化,评估效果。
如果效果不行,回到上一步。
如果效果可以,使用方案。
根据实践经验,一般情况下:
精度越高,显存占用越多,推理效率越低,但一般效果较好。
Server 端推理一般用非量化版本或半精度、BF16、Int8 等精度的量化版本,比较少使用更低精度的量化版本。
端侧推理一般都使用W4A16量化版本,且大多是低精度的量化版本。这主要是因为计算资源所限。
3、TurboMind
它是基于英伟达的FasterTransformer研发而成的一款关于LLM推理的高效推理引擎。其主要功能包括支持LLaMa结构模型、persistent batch推理模式和可扩展的KV缓存管理器。并具有持续批处理、有状态推理、k/v缓存块和高性能算子融合等特性。
TurboMind的设计目标是在保持高性能的同时,提供灵活性和可扩展性。它采用了多种优化技术,如算子融合、内存优化等,以提高推理速度和效率。此外,TurboMind还支持多种精度的推理,包括FP32、FP16和INT8等,以满足不同应用场景的需求。
通过TurboMind推理引擎,LMDeploy可以实现高效、准确的推理服务,支持大规模的模型部署和应用。它提供了丰富的接口和工具,方便用户进行模型推理和管理。
实操经验
首先说 “模型推理/服务”,推荐使用 TurboMind,使用简单,性能良好,相关的 Benchmark 对比如下。
4、推理服务
包括api server、gradion、triton inferenceserver等,提供了灵活的推理服务解决方案。
后面的 API 服务和 Client 就得分场景了。
- 想对外提供类似 OpenAI 那样的 HTTP 接口服务。推荐使用 TurboMind推理 + API 服务(2.3)。
- 想做一个演示 Demo,Gradio 无疑是比 Local Chat 更友好的。推荐使用 TurboMind 推理作为后端的Gradio进行演示(2.4.2)。
- 想直接在自己的 Python 项目中使用大模型功能。推荐使用 TurboMind推理 + Python(2.5)。
- 想在自己的其他非 Python 项目中使用大模型功能。推荐直接通过 HTTP 接口调用服务。也就是用本列表第一条先启动一个 HTTP API 服务,然后在项目中直接调用接口。
三、基础作业
1、配置 LMDeploy 运行环境
安装 LMDeploy

查看LMDeploy参数
 2、以命令行方式与 InternLM2-Chat-1.8B 模型对话
2、以命令行方式与 InternLM2-Chat-1.8B 模型对话
未使用推理加速情况下与大模型对话
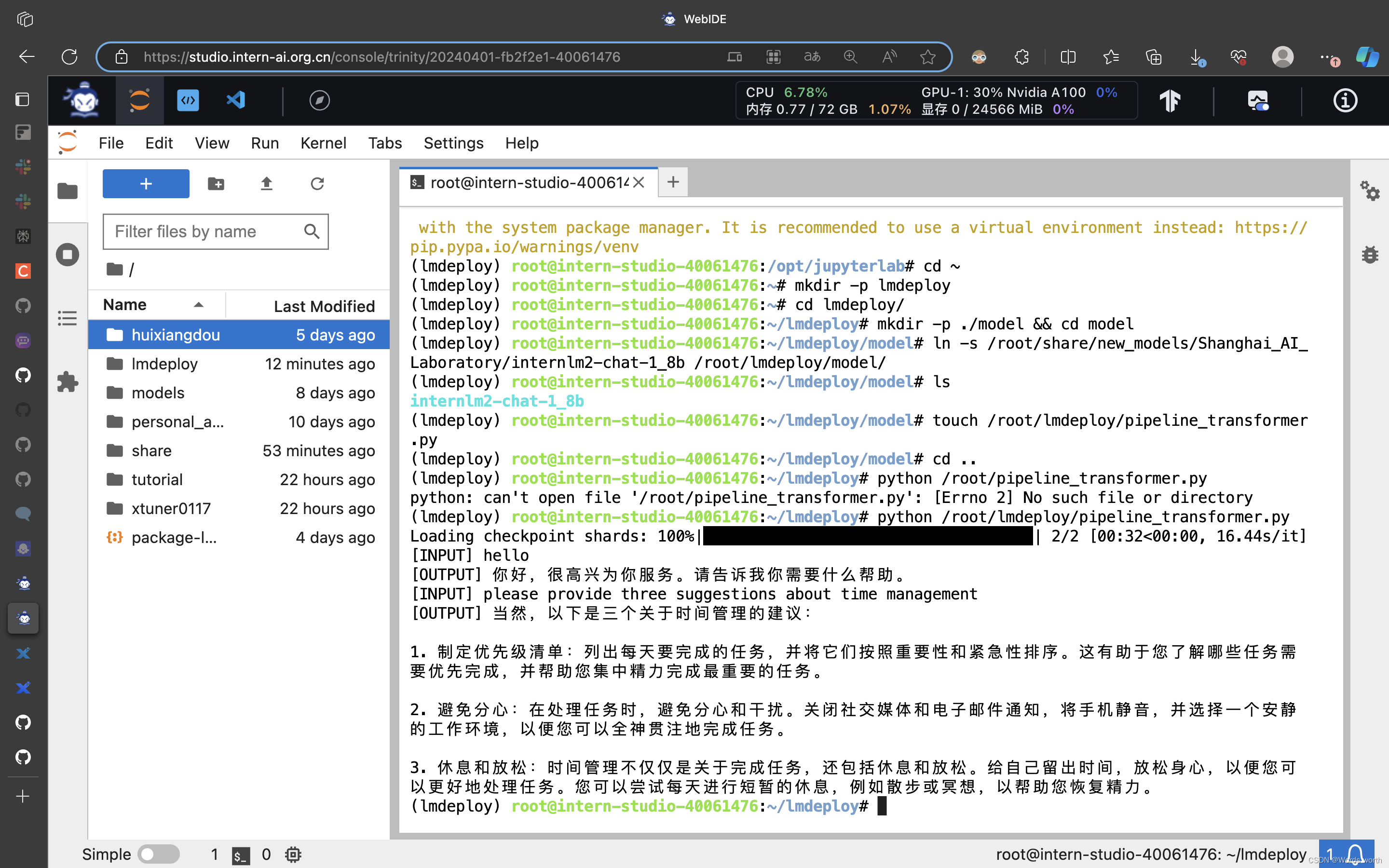
使用LMDeploy加速情况下与模型对话
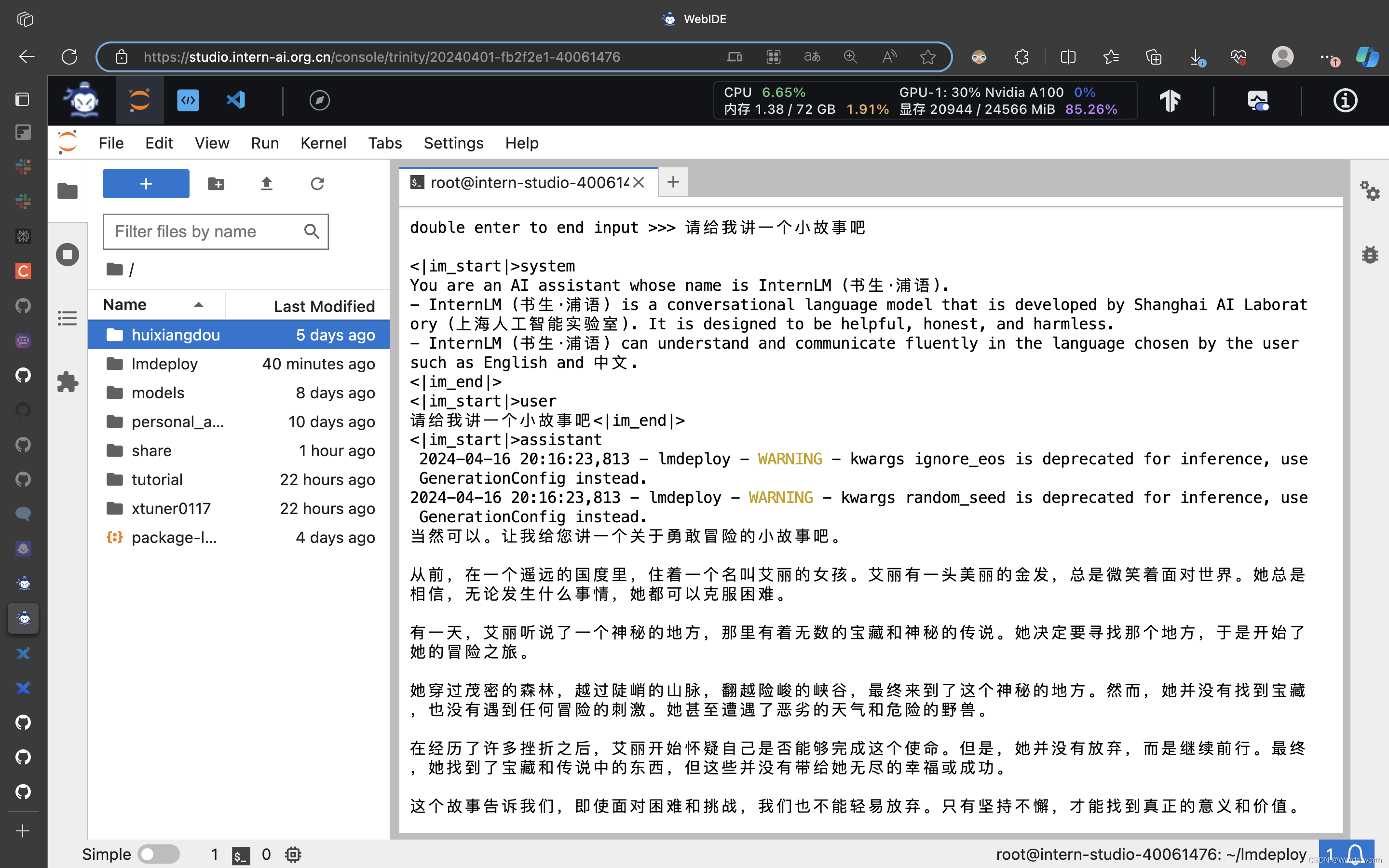
四、进阶作业
1、设置KV Cache最大占用比例为0.4,开启W4A16量化,以命令行方式与模型对话。
(1)开启W4A16量化
lmdeploy lite auto_awq \
/root/lmdeploy/model/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit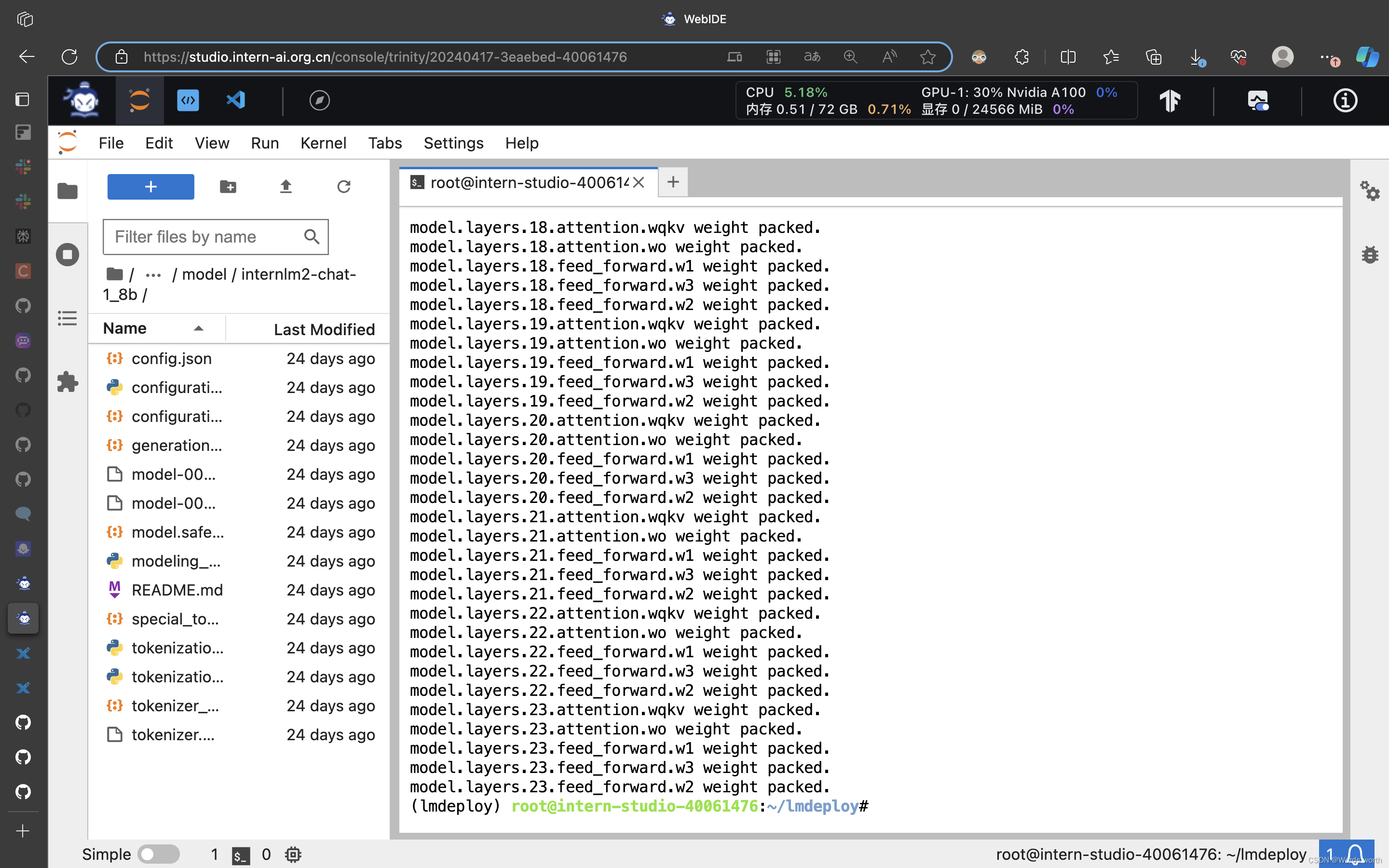 (2) 设置KV Cache最大占用比例为0.4,以命令行方式与模型对话
(2) 设置KV Cache最大占用比例为0.4,以命令行方式与模型对话
lmdeploy chat /iroot/lmdeploy/model/nternlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.4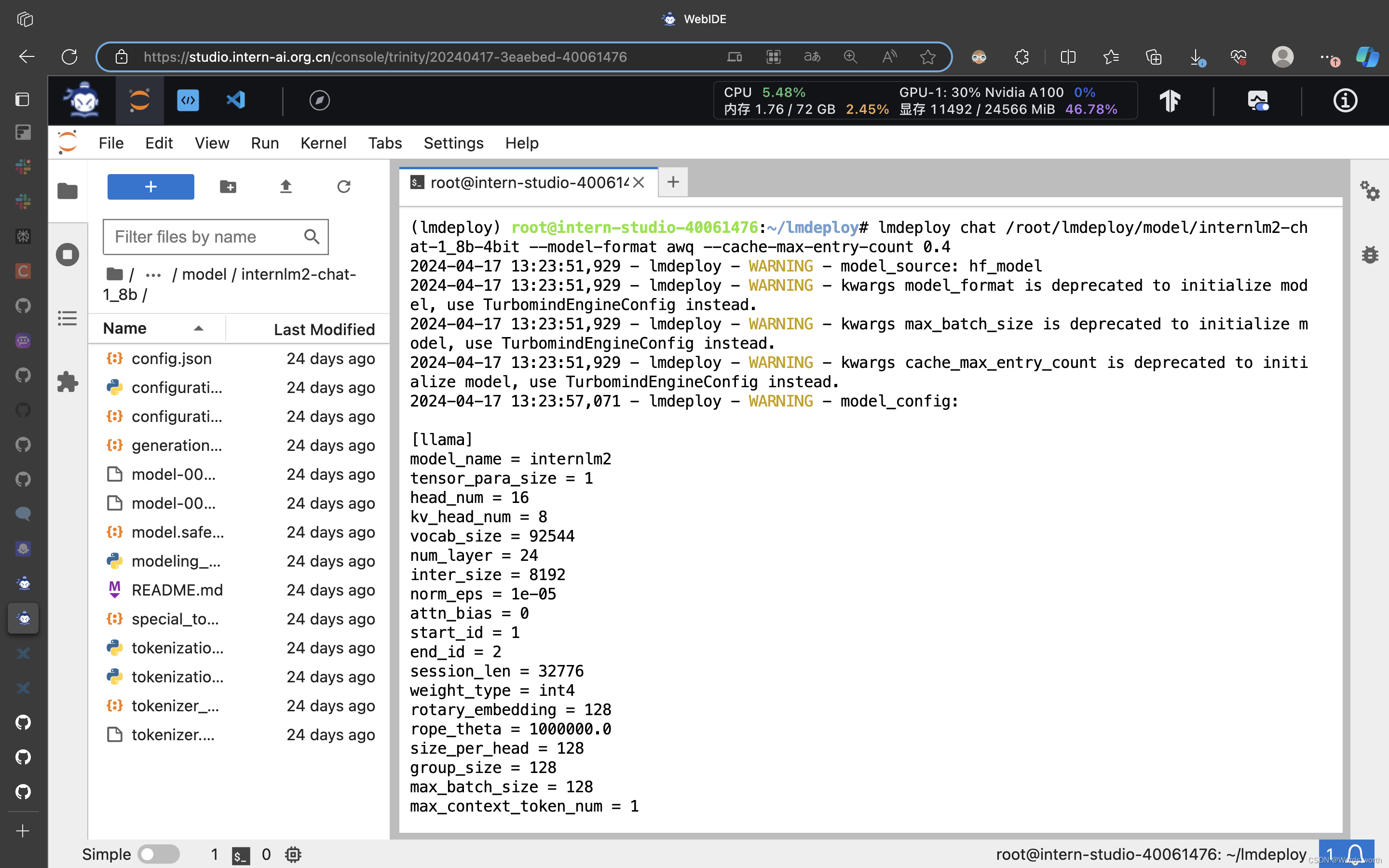 以命令行方式与模型对话
以命令行方式与模型对话

2、以API Server方式启动 lmdeploy,开启 W4A16量化,调整KV Cache的占用比例为0.4,分别使用命令行客户端与Gradio网页客户端与模型对话。
(1)启动API服务器推理internlm2-chat-1_8b模型,开启W4A16量化,KV Cache占比为0.4
lmdeploy serve api_server \
/root/lmdeploy/model/internlm2-chat-1_8b-4bit \
--model-format awq \
--cache-max-entry-count 0.4 \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1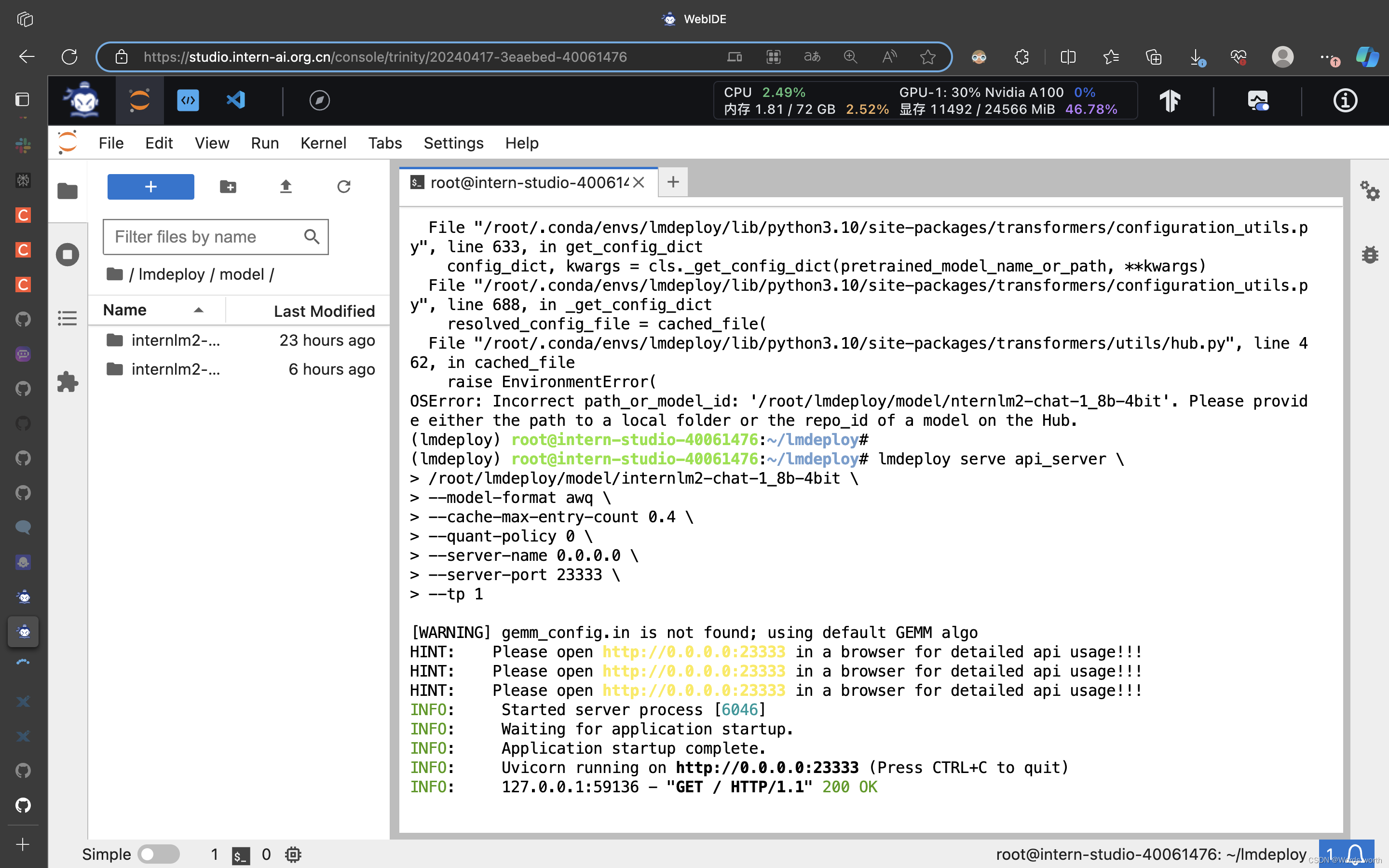
(2)打开http://{host}:23333
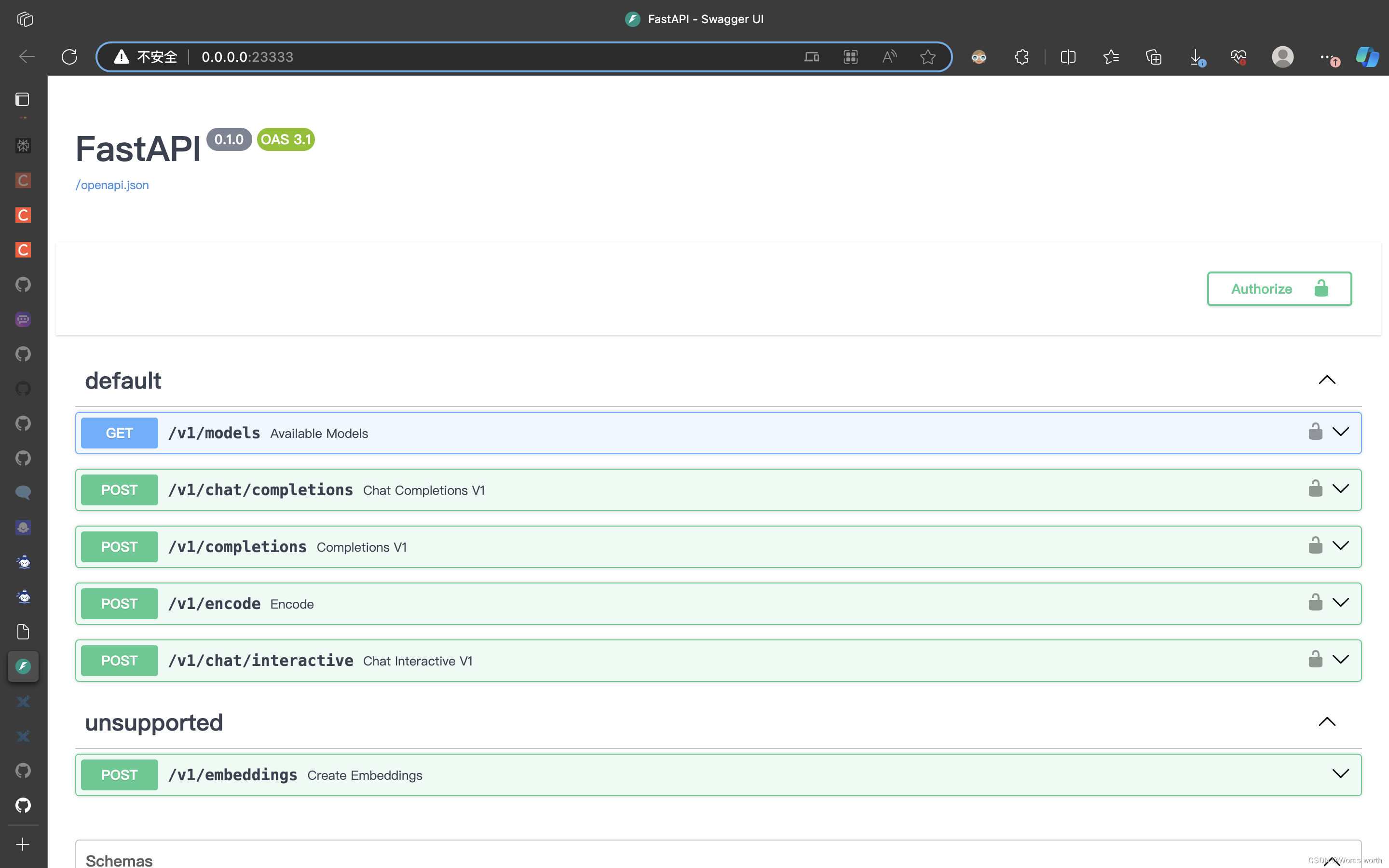
(3) 使用命令行客户端与模型对话
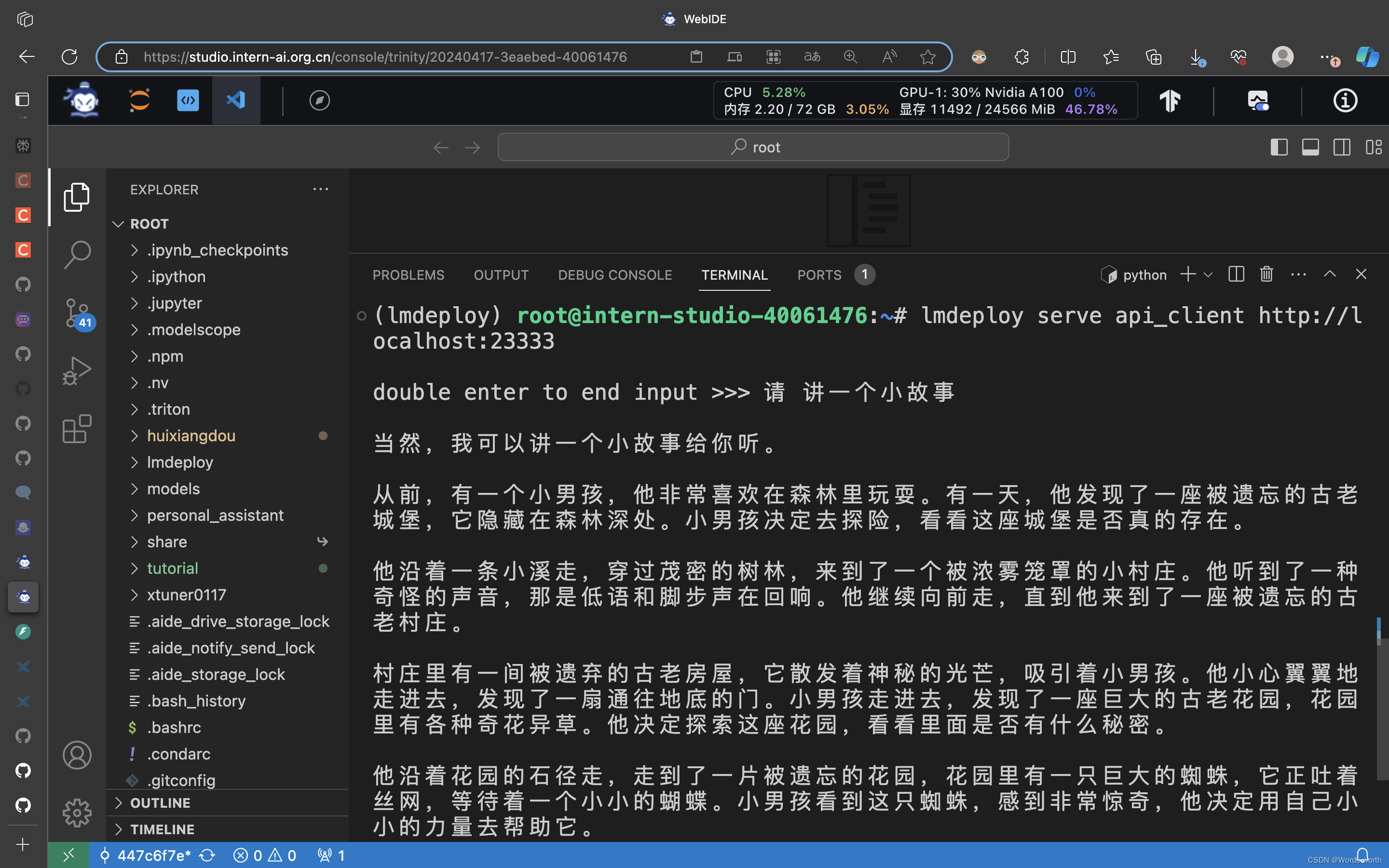 (4)使用Gradio网页客户端与模型对话
(4)使用Gradio网页客户端与模型对话
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
3、使用W4A16量化,调整KV Cache的占用比例为0.4,使用Python代码集成的方式运行internlm2-chat-1.8b模型。
新建文件pipeline_kv.py,通过创建TurbomindEngineConfig,向lmdeploy传递参数。
from lmdeploy import pipeline, TurbomindEngineConfig
# 调低 k/v cache内存占比调整为总显存的 40%,开启W4A16量化
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.4)
backend_config = TurbomindEngineConfig(model_format='awq')
pipe = pipeline('/root/internlm2-chat-1_8b',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)运行internlm2-chat-1.8b模型 
4、使用 LMDeploy 运行视觉多模态大模型 llava gradio demo
新建文件pipeline_llava.py使用pipeline推理llava-v1.6-7b
from lmdeploy.vl import load_image
from lmdeploy import pipeline, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(session_len=8192) # 图片分辨率较高时请调高session_len
# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config) 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config)
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response)运行pipeline,识别下方图片

启动程序,成功识别。
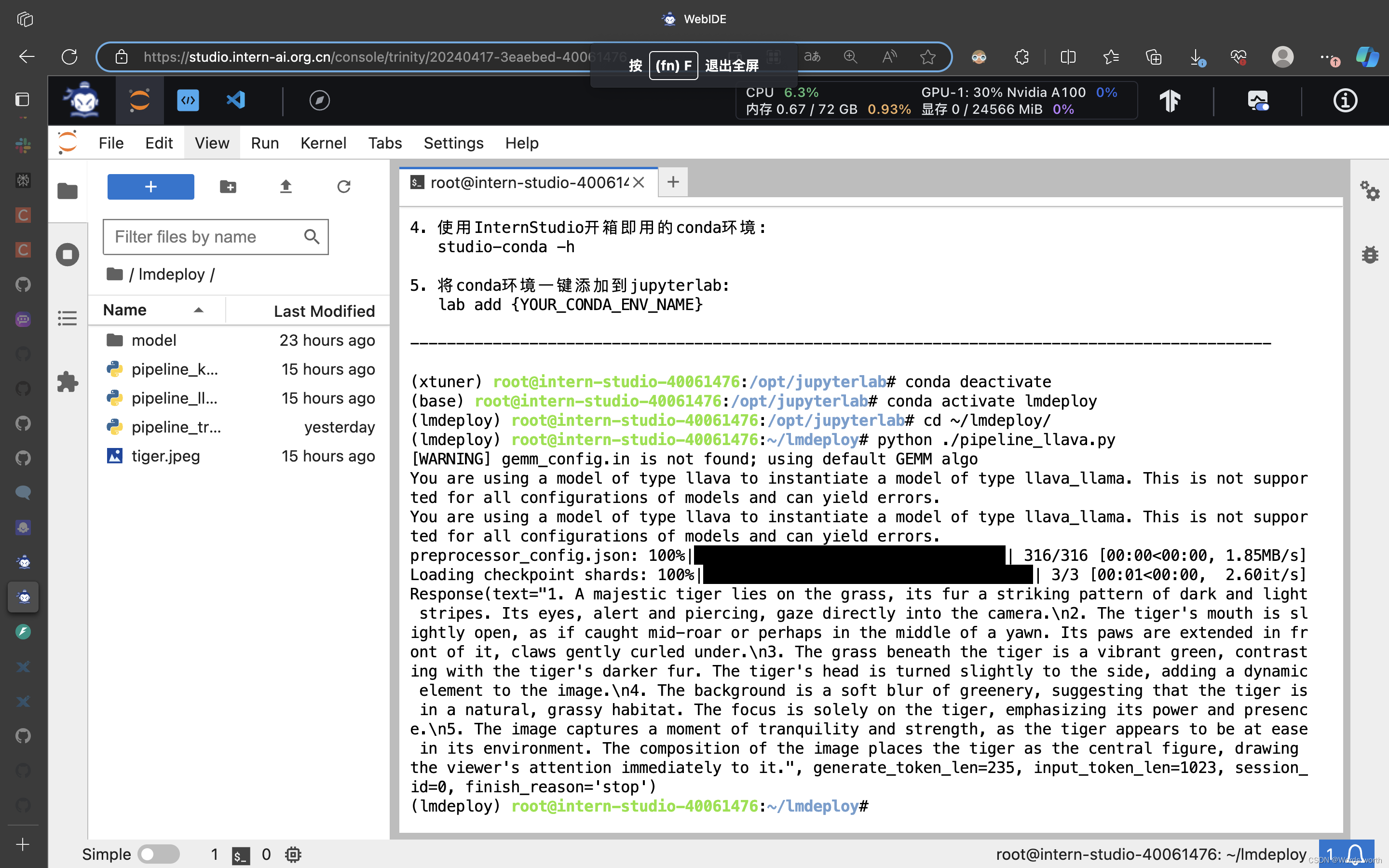
5、将 LMDeploy Web Demo 部署到 OpenXLab
1、先上传模型到OpenXLab
首先需要在 OpenXLab 先创建一个空仓库,填写模型仓库的基本信息,包括仓库名称、任务类型、访问权限等。创建完成空的模型仓库后,找到该仓库的 git 地址并拉取该空仓库至本地,空仓库的地址在模型文件的下载按钮下,找到空仓库下的 git 地址,执行 git clone 操作。
# install git
sudo apt-get update
sudo apt-get install git
# install git lfs
sudo apt-get update
sudo apt-get install git-lfs
# use git install lfs
git lfs install在克隆的仓库目录中整理模型文件,即将你的模型文件放入至clone的目录中,并执行git push命令将模型推送至远程仓库。在执行 git push 之前,如果您的仓库中包含大型文件,并且您希望使用 Git LFS 来管理这些文件,您需要先标记这些文件以便 Git LFS 能够识别它们。这通常是通过使用 git lfs track 命令来标记。
git lfs track "*.bin"
git lfs track "*.model"标记LFS管理的文件后,提交更新的信息,执行 git push 上传模型,
cd internlm2-chat-7b
git add -A
git commit -m "upload model"
git push上传成功。

2、部署应用到OpenXLab
编写一个app.py文件,里面可以通过transformers框架进行模型实例化并通过gradio组件搭建chat聊天界面。
import gradio as gr
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoModel
# download internlm2 to the base_path directory using git tool
base_path = './internlm2-chat-7b'
os.system(f'git clone https://code.openxlab.org.cn/OpenLMLab/internlm2-chat-7b.git {base_path}')
os.system(f'cd {base_path} && git lfs pull')
tokenizer = AutoTokenizer.from_pretrained(base_path,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(base_path,trust_remote_code=True, torch_dtype=torch.float16).cuda()
def chat(message,history):
for response,history in model.stream_chat(tokenizer,message,history,max_length=2048,top_p=0.7,temperature=1):
yield response
gr.ChatInterface(chat,
title="InternLM2-Chat-7B",
description="""
InternLM is mainly developed by Shanghai AI Laboratory.
""",
).queue(1).launch()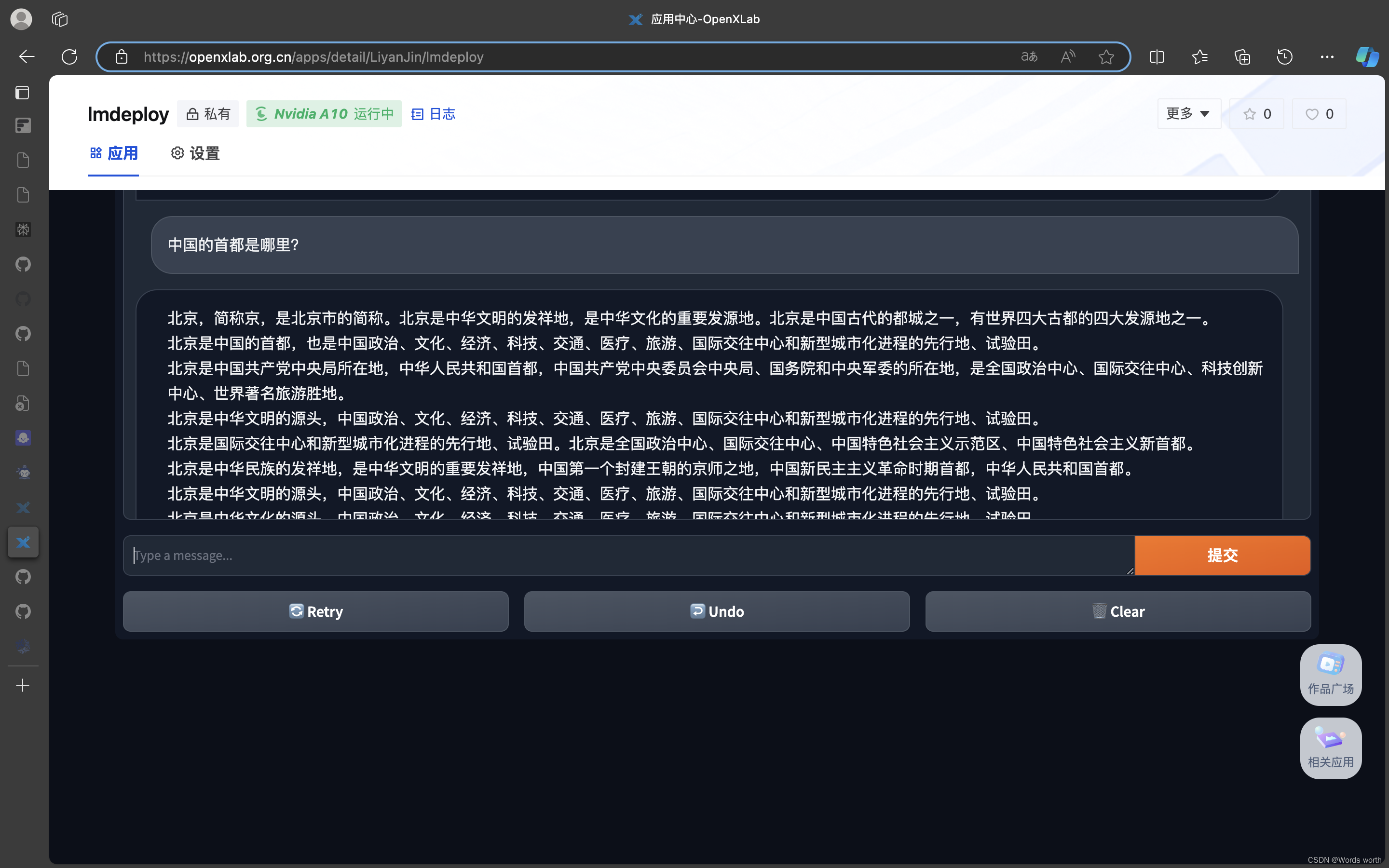















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









