







回顾
- 线程池的作用?
- 线程池的工作原理?
本文重点
- 线程池工作方式的核心
- 线程池的API有哪些?具体怎么实现?
充电站
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习
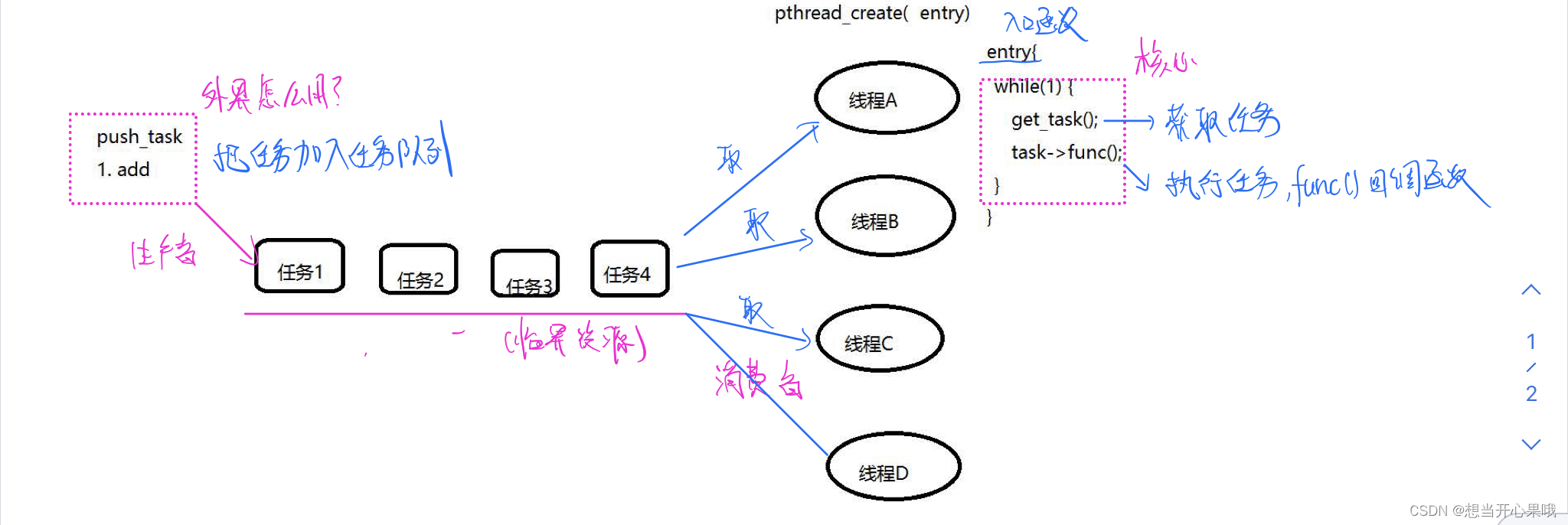
线程池工作方式的核心
1)外界作什么?
2)线程池做了些什么?
3)线程获取到任务后做了什么?
外界调用push_task将任务将入任务队列,线程池中的线程去取任务队列中的任务,取到任务后去执行任务,具体利用任务中的回调函数去处理。这样就构成了一个生产者、消费者的模式。
线程池API
核心: 1)
create/init; 2)push_task; 3)destroy/deinit
非核心有 task_count、free_thread,通过名称都很好理解API的作用。
API代码实现
线程池的创建
核心:对结构体struct NTREADPOOL中所有成员进行初始化。
// 线程创建
int ntyThreadPoolCreate(nThreadPool *workqueue, int numWorkers) {
//参数判断
if (numWorkers < 1) numWorkers = 1;
memset(workqueue, 0, sizeof(nThreadPool));
//对条件变量初始化
pthread_cond_t blank_cond = PTHREAD_COND_INITIALIZER;
memcpy(&workqueue->jobs_cond, &blank_cond, sizeof(workqueue->jobs_cond)); //不是基本类型建议使用memcpy进行数据初始化
//mutex init
pthread_mutex_t blank_mutex = PTHREAD_MUTEX_INITIALIZER;
memcpy(&workqueue->jobs_mtx, &blank_mutex, sizeof(workqueue->jobs_mtx));
//(thread, worker一一对应) thread count
int i = 0;
for (i = 0;i < numWorkers;i ++) {
nWorker *worker = (nWorker*)malloc(sizeof(nWorker));
if (worker == NULL) {
perror("malloc");
return 1;
}
memset(worker, 0, sizeof(nWorker));
worker->workqueue = workqueue;
//开始创建线程,参数:线程id、属性、入口函数、参数
int ret = pthread_create(&worker->thread, NULL, ntyWorkerThread, (void *)worker);
if (ret) { //ret > 0 创建失败
perror("pthread_create");
free(worker);
return 1;
}
LL_ADD(worker, worker->workqueue->workers);
}
return 0;
}
线程入口函数
取任务 --> 执行
// 线程入口函数
static void *ntyWorkerThread(void *ptr) {
nWorker *worker = (nWorker*)ptr;
while (1) {
pthread_mutex_lock(&worker->workqueue->jobs_mtx);
while (worker->workqueue->waiting_jobs == NULL) {
if (worker->terminate) break;
pthread_cond_wait(&worker->workqueue->jobs_cond, &worker->workqueue->jobs_mtx);
}
if (worker->terminate) {
pthread_mutex_unlock(&worker->workqueue->jobs_mtx);
break;
}
nJob *job = worker->workqueue->waiting_jobs;
if (job != NULL) {
LL_REMOVE( , worker->workqueue->waiting_jobs);
}
pthread_mutex_unlock(&worker->workqueue->jobs_mtx);
if (job == NULL) continue;
job->job_function(job);
}
free(worker);
pthread_exit(NULL);
}
线程池的销毁
// An highlighted block
void ntyThreadPoolShutdown(nThreadPool *workqueue) {
nWorker *worker = NULL;
for (worker = workqueue->workers;worker != NULL;worker = worker->next) {
worker->terminate = 1;
}
pthread_mutex _lock(&workqueue->jobs_mtx);
workqueue->workers = NULL;
workqueue->waiting_jobs = NULL;
//广播通知,所有的条件变量被激活
pthread_cond_broadcast(&workqueue->jobs_cond); //广播通知
pthread_mutex_unlock(&workqueue->jobs_mtx);
}
向任务队列增加任务函数
// 增加任务函数
void ntyThreadPoolQueue(nThreadPool *workqueue, nJob *job) {
pthread_mutex_lock(&workqueue->jobs_mtx);
LL_ADD(job, workqueue->waiting_jobs);
pthread_cond_signal(&workqueue->jobs_cond); //任务激活
pthread_mutex_unlock(&workqueue->jobs_mtx);
}
小结
实现了四个API,分别是线程池创建函数,线程入口函数,任务队列增加函数、线程池销毁函数。
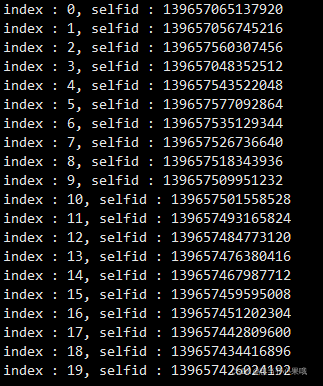
API的测试
为线程池准备一千个任务,任务主要做的就是打印。线程池中、准备八十个线程。
// 测试
#define KING_MAX_THREAD 80
#define KING_COUNTER_SIZE 1000
void king_counter(nJob *job) {
int index = *(int*)job->user_data;
printf("index : %d, selfid : %lu\n", index, pthread_self());
free(job->user_data);
free(job);
}
int main(int argc, char *argv[]) {
nThreadPool pool;
ntyThreadPoolCreate(&pool, KING_MAX_THREAD);
int i = 0;
for (i = 0;i < KING_COUNTER_SIZE;i ++) {
nJob *job = (nJob*)malloc(sizeof(nJob));
if (job == NULL) {
perror("malloc");
exit(1);
}
job->job_function = king_counter;
job->user_data = malloc(sizeof(int));
*(int*)job->user_data = i;
ntyThreadPoolQueue(&pool, job);
}
getchar();
printf("\n");
}
#endif
测试部分结果
总结
主要介绍了线程池的核心工作方式,把握核心逻辑。同时,详细讲述了线程池核心API以代码的实现,主要掌握代码逻辑。对API进行测试,达到预期的效果。














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









