







思路
先理解
- Select / poll /epoll ?
基于事件驱动来做的 io 复用 - Reactor ?
用epoll来封装的反应堆 - Http
网络http协议 协议头 如何实现内部 get cgi - Webserver ?
做一个网络的服务端 基于reactor - 单线程 多线程 多进程reactor?
- Posix api 和协议栈 tcp协议栈
- Udp 协议 kcp
在理解
- 为什么会有协程?解决什么问题?
同步的线程 异步的操作 - 原语操作有哪些?同步和异步的切换 操作中最基本的单位,
eg create、yelid、resume。 - 切换 (Switch)
类似于线程 进程的切换 - 协程的运行流程
- 协程结构体定义
- 调度策略
类似于 进程调度 lua算法等一系列的策略 cfs - 调度器如何定义?
- 协程 api 的实现,hook?
- 多核模式
- 如何测试?
注意: 没有特别声明 fd、sockfd、连接、io 指的都是 fd!!!
为什么会有协程?解决什么问题?
- 理解什么是同步什么是异步?
- 理解什么是同步的编程方式异步的性能?同步的编程方式和异步的编程方式的优缺点是什么?
- 为什么异步的编程方式避免不了多个线程共用一个 fd?导致数据乱序?
- 适用于服务器与客户端异步处理。
IO 同步、异步操作对比:
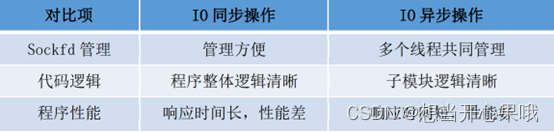
站在服务器端
比如 reactor 监听时间。
同步 7.5s 连接1000个 。
异步 1.4s 连接1000个。
//同步
while(1)
{
epoll_wait
For(;;)
{
Recv();
Send();
}
}
//异步
Push_other_thread()
{
Poll(); //检测 可读可写 治标不治本 不能根除 多个线程同用一个fd
Recv();
Send();
}
While(1)
{
Epoll_wait();
For(;;)
{
Push_other_thread();
}
}
分析:
- Io 异步的问题 push_other_thread 避免不了多个线程公用一个fd的现象 尽量的去避免
- 问题?乱序读的数据不对 A再读 B 关闭。莫名其妙的就出现问题 ,如何解决?
线程前加poll再次检测但是治标不治本 。
站在客户端的角度
客户端发送之后等待服务端的结果,发送50个域名给客户端进行请求同步的没异步的处理快。
总结:不管是再客户端还是服务端 io异步的性能总是快。
通过站在客户端与服务器端推出:
协程就是解决了同步的性能,异步的共用现象使用同步的编程,却实现了异步的操作处理
如何把同步的编程变成异步的呢?
正常的流程如下:
- 建立连接
- 当客户端发送一个请求到服务端时候,
send(); - Epoll_wait判断是否可读;
- 等待服务端一个回发数据
recv()(不可读会阻塞)同步,再去做一系列的操作
改成如下:
- 建立连接
- 当客户端发送一个请求到服务端时候
send(),send之后切换成epoll_wait,if(不可读){ 开另外一个流程再次send },相当于异步操作 开了另外一个io口去做send ,epoll_wait判断是否可读. - 等待服务端一个回发数据
recv()(不可读会阻塞) 但是不影响上面,因为上面会切换另外一个请求去再次处理其他的send,再去做一系列的操作。 - 在send完毕后做一个切换到
epoll_wait去判断fd是否可读不可读,让出回到主线程,去另外一个流程中再次send。
总结:
先理解io操作,io检测。核心:遇到 io 操作就 yeid
send() 一次 fd ----》 利用epoll_ctl()加入epoll_wait()中检测 ----》 yeid(让出)跳入到epoll_wait()检测 if(可读){ recv() , 继续epoll_wait()检测} else { resume()}
切换(Switch)
yield:IO 操作 ----》 IO 检测resume:IO 检测 ----》 IO 操作
协程入口函数
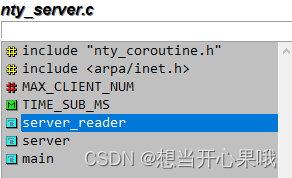
server_reader -> nty_recv -> nty_poll_inner -> nty_schedule_sched_wait -> _nty_coroutine_yield
协程结构体定义
举例:以客户端与服务器连接时,客户端流程
void client_func()
{
send(fd, buffer, length, 0);
int nready = epoll_wait(epfd, ); //加一个判断把同步的流程改成异步;
recv(fd, rbuffer, length, 0); //阻塞住 不要的
//....
//parser()解析服务端返回的数据
}
协程结构体定义
//用宏写 C++ 模板
#define queue_node(name type) struct name{\
struct type *next;
struct type *prev;
}
#define rbtree_node(name type) struct name{\
char color;
struct type *right;
struct type *left
struct parents;
}
struct cpi_register_set
{
void* eax; //寄存器上下文
void* ebx; //寄存器上下文
....
};
struct coroutine
{
// 类比线程 来定义协程需要的结构
struct cpi_register_set *set; //保存cpu
void *coroutine e_create;// entry 协程入口函数
void *arg; // 参数
void *reval; //返回值 不做计算的话没什么意义
// 函数调用如何调用? 利用栈
void *stack_addr; //指向栈空间的首地址,在堆上开辟一个空间当做栈
size_t stack_size;
// 协程的数量很多 要用什么结构来储存
// 从调度器的角度来看 栈的格式不符合(会导致最底部的协程调用不到)stack_coroutine *next;
// 队列的格式来用
queue_node(ready_name,coroutine) *ready;
rbtree_node(wait_name,coroutine) *wait;
rbtree_node(sleep_name,coroutine) *sleep;
}co;
协程的创建类比线程的创建
pthread_create(thid, NULL, entry_cb, arg) { } //线程id, 线程属性(堆栈大小的参数),线程入口函数,参数
只做了两件事情:
1. 创建一个线程实体:task_struct *task;
2. 加入就绪队列 :enqueue_ready;
//协程创建
oroutine_create(entry_cb,arg);
coroutine_join(coid,&reval) //获取子线程返回的值
{
co = search(coid)
if(co->reval ==NULL){
wait(); //单线程 用条件等待
}
return co->reval;
}
exec(co){
//启动了协程函数 取得返回值
co->reval = co->func(co->arg)
//存到了协程的结构体里
signal();//
}
调度策略
调度器
//调度器
struct scheduler{
struct scheduler_ops *ops;
//当前运行的协程 当调度器让出的时候、
struct coroutine *cur; //当前哪个协程
int epfd; //
queue_node *ready_set;
rbtree() *wait_set;
rbtree() *sleep_set;
}
协程 api 的实现,hook?
socket、bind、listen、connect、accept、send、recv同步改为异步- 利用
hook函数
//异步api
void my_accept(){
int ret=Poll(fd);
if(ret>0){
//就绪后 调用真正的accept
accept();
}
else{
//吧fd加入到epoll 后 “让出” epoll管理
epoll_ctl(epfd); //time out 值设成0 立刻返回 做成异步的操作
yield(); //调度器用
}
}
hook 是把代码段中的改变 在进程开启阶段会调用inin_hook(),把函数内部 把系统调用对应的 指定函数 (send/recv)改成(send_f/recv_f)。
在应用下 用到了send(普通函数了)或者recv(普通函数了) 会自动的调用send_f/recv_f替换。
Yield之后如何执行 yield和resume如何实现的呢?让出到对应的resume下 resume到对应的yield下。
充电站
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习














 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









