






实验复现已经基本完成,文献也已经翻译好了,那么现在,如何将实验代码和论文内容对应起来,就是我的工作了。弄完这个,我先挖个坑,我想先再搞一个简单的实验复现,然后通过换模型,好好学一下深度学习的实验构成。争取出个系列喵!
首先从前文我们知道了
![]()
data_utils.py
这个python是我们首先要运行和搞明白的文件。现在让我们逐块的搞懂它的内部代码吧。
import numpy as np
import tensorflow as tf
import h5py
import os, sys
class Dataset:
def __init__(self, data_path, split, input_length, data_desync=0):
self.data_path = data_path
self.split = split
self.input_length = input_length
self.data_desync = data_desync
#data_path
corpus = h5py.File(data_path, 'r')#C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\ASCAD.h5
if split == 'train':
split_key = 'Profiling_traces'
elif split == 'test':
split_key = 'Attack_traces'
self.traces = corpus[split_key]['traces'][:, :(self.input_length+self.data_desync)]
self.labels = np.reshape(corpus[split_key]['labels'][()], [-1, 1])
self.labels = self.labels.astype(np.int64)
self.num_samples = self.traces.shape[0]
#assert (self.input_length + self.data_desync) <= self.traces.shape[1]
#self.traces = self.traces[:, :(self.input_length+self.data_desync)]
max_split_size = 2000000000//self.input_length
split_idx = list(range(max_split_size, self.num_samples, max_split_size))
self.traces = np.split(self.traces, split_idx, axis=0)
self.labels = np.split(self.labels, split_idx, axis=0)
#self.traces = self.traces.astype(np.float32)
self.plaintexts = self.GetPlaintexts(corpus[split_key]['metadata'])
self.masks = self.GetMasks(corpus[split_key]['metadata'])
self.keys = self.GetKeys(corpus[split_key]['metadata'])
def GetPlaintexts(self, metadata):
plaintexts = []
for i in range(len(metadata)):
plaintexts.append(metadata[i]['plaintext'][2])
return np.array(plaintexts)
def GetKeys(self, metadata):
keys = []
for i in range(len(metadata)):
keys.append(metadata[i]['key'][2])
return np.array(keys)
def GetMasks(self, metadata):
masks = []
for i in range(len(metadata)):
masks.append(np.array(metadata[i]['masks']))
masks = np.stack(masks, axis=0)
return masks
def GetTFRecords(self, batch_size, training=False):
dataset = tf.data.Dataset.from_tensor_slices((self.traces[0], self.labels[0]))
for traces, labels in zip(self.traces[1:], self.labels[1:]):
temp_dataset = tf.data.Dataset.from_tensor_slices((traces, labels))
dataset.concatenate(temp_dataset)
def shift(x, max_desync):
ds = tf.random.uniform([1], 0, max_desync+1, tf.dtypes.int32)
ds = tf.concat([[0], ds], 0)
x = tf.slice(x, ds, [-1, self.input_length])
return x
if training == True:
if self.input_length < self.traces[0].shape[1]:
return dataset.repeat() \
.shuffle(self.num_samples) \
.batch(batch_size//2) \
.map(lambda x, y: (shift(x, self.data_desync), y)) \
.unbatch() \
.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
else:
return dataset.repeat() \
.shuffle(self.num_samples) \
.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
else:
if self.input_length < self.traces[0].shape[1]:
return dataset.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (shift(x, 0), y)) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
else:
return dataset.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
def GetDataset(self):
return self.traces, self.labels
if __name__ == '__main__':
"""
print(sys.argv)
if len(sys.argv) < 4:
print("Error: Missing command-line arguments.")
print("Usage: python data_utils.py <data_path> <batch_size> <split>")
sys.exit(1)
data_path = sys.argv[1]
batch_size = int(sys.argv[2])
split = sys.argv[3]
"""
data_path = "D:\\reproducing_experiments\\TCHES2024\\EstraNet-main\\EstraNet-main\\ASCAD.h5"
batch_size = 256
split = 'train'
dataset = Dataset(data_path, split, 5)
print(dataset)
print("--------")
print("traces : "+str(dataset.traces[0].shape))
#print("traces : " + str(dataset.traces.shape))
print("labels : "+str(dataset.labels[0].shape))
print("plaintext : "+str(dataset.plaintexts.shape))
print("plaintext : "+str(dataset.plaintexts))
print("keys : "+str(dataset.keys.shape))
print("keys : "+str(dataset.keys))
print("traces ty : "+str(dataset.traces))
print("")
print("")
tfrecords = dataset.GetTFRecords(batch_size, training=False)
print("tfrecords:",tfrecords)
iterator = iter(tfrecords)
for i in range(1):
tr, lbl = iterator.get_next()
print(str(tr.shape)+' '+str(lbl.shape))
print(str(tr.dtype)+' '+str(lbl.dtype))
print(str(tr[:, :10]))
print(str(lbl[:, :]))
print("")
首先是这个python的主体其实就是一个类
一、参数初始化部分
def __init__(self, data_path, split, input_length, data_desync=0):
self.data_path = data_path
self.split = split
self.input_length = input_length
self.data_desync = data_desync- 功能:初始化类的属性
data_path:数据文件的路径(例如C:\...\ASCAD.h5)split:决定加载训练集(train)还是测试集(test)input_length:每条数据的有效长度(例如时序信号的截取长度)data_desync:数据偏移量(用于模拟真实场景中信号不同步的情况)
二、加载HDF5数据文件
corpus = h5py.File(data_path, 'r')
if split == 'train':
split_key = 'Profiling_traces'
elif split == 'test':
split_key = 'Attack_traces'- 功能:打开HDF5文件,根据
split选择数据分区h5py.File():读取HDF5格式文件(类似文件夹的层级结构)split_key:训练集对应Profiling_traces,测试集对应Attack_tracescorpus:我们可以认为是python把文件读出来了,放在这个叫corpus的临时文件里,只能读取其中的内容
三、提取轨迹和标签数据
self.traces = corpus[split_key]['traces'][:, :(self.input_length+self.data_desync)]
self.labels = np.reshape(corpus[split_key]['labels'][()], [-1, 1])
self.labels = self.labels.astype(np.int64)
self.num_samples = self.traces.shape[0](@ref)- 功能:加载轨迹和标签数据,并做预处理
self.traces:截取每条轨迹的前input_length+data_desync个点(为后续偏移增强预留空间)self.labels:将标签数据转换为二维数组(例如[[0](@ref), [1](@ref), ...]),并强制转为整数类型num_samples:记录总样本数(例如有10000条数据)
这里我们单独分析每一行:
self.traces = corpus[split_key]['traces'][:, :(self.input_length+self.data_desync)]-
文件结构
→
corpus是打开的 HDF5 文件(类似一个多层文件夹)split_key比如是字符串"train"或"test"(相当于选一个子文件夹)这里的split_key只有可能是: 中的一个我们以训练阶段为例,训练阶段用的是Profiling_traces:
中的一个我们以训练阶段为例,训练阶段用的是Profiling_traces:
→['traces']是这个子文件夹里的一个数据表格(类似 Excel 表格)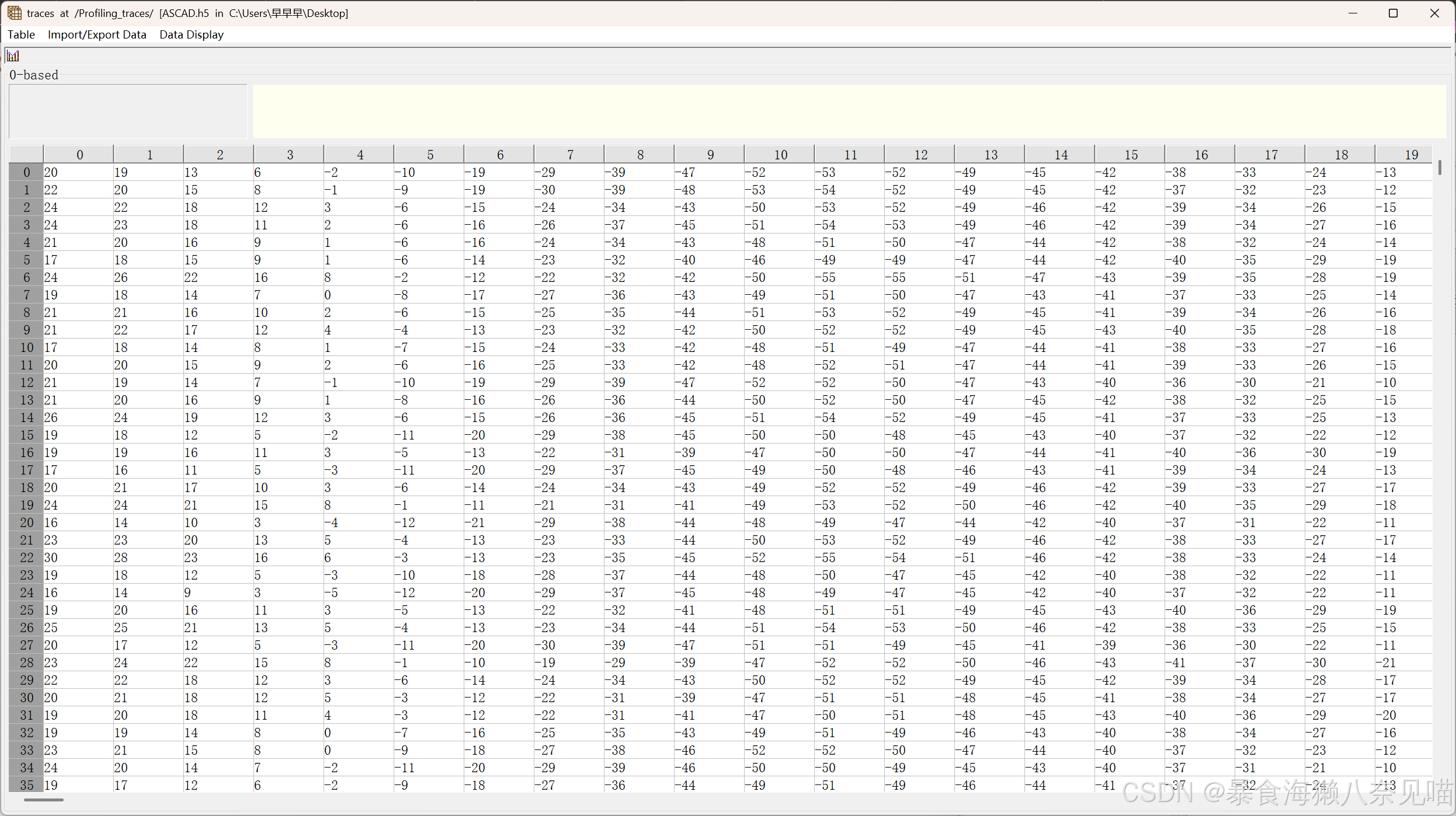
-
数据截取
[:, :(self.input_length+self.data_desync)]是 numpy 的切片操作:- 第一个冒号
::选中所有行(比如 1000 条数据全部保留),这里是选中了所有的五万行。 - 第二个参数:每行只取前
input_length + data_desync列(比如input_length=100,data_desync=5,就取每行前 105 个数字),我们在后面的代码可知我们的input_length=5,data_desync=0(默认)
- 第一个冒号
-
应用场景
假设这是处理传感器时序数据:input_length是有效信号长度(如 100 秒)data_desync是预留的容错区间(如防止时间错位的 5 秒冗余)
代码相当于把「原始数据流」裁剪成「固定长度+容错区间」的片段8
举个 🌰:
假设 traces 数据形状是 (1000, 200)(1000 条数据,每条 200 个点)
执行后变成 (1000, 105),每条只保留前 105 个点
self.labels = np.reshape(corpus[split_key]['labels'][()], [-1, 1])我来用大白话+🌰解释这段代码:
-
基础操作
corpus[split_key]['labels']相当于打开一个多层文件夹,找到存放标签的盒子(比如选训练集的标签盒)📦
-
倒出盒子里的东西
[()]是把这个盒子里的所有标签一次性倒出来,变成一堆散装的数字(比如[0,1,0,0,1...])🔢 -
整理队伍
np.reshape(..., [-1,1])的作用是让这些散装数字排成整齐的方阵:-1表示自动计算行数(比如原本有1000个标签,就排成1000行)1表示每行只站1个数字(把队伍从横排变成竖排)👫→👮♂️
举个栗子🌰:
- 原始标签:
[0,1,0,1,1](像排队买奶茶的一字长蛇阵) - 整理后变成:
(像整齐的阅兵方阵)[[0](@ref), [1](@ref), [0](@ref), [1](@ref), [1](@ref)]
- 为什么要这么做?
机器学习模型(比如神经网络)吃饭有个怪癖:
❌ 不爱吃散装零食(一维数组)
✅ 必须装进统一的餐盘(二维数组)
这样数据才能和特征数据(比如self.traces)对齐喂给模型
最后效果相当于:把一堆散落的珍珠(标签)串成整齐的珍珠项链(二维数组)📿
self.labels = self.labels.astype(np.int64)用最直白的例子解释这段代码:
-
原始标签可能长这样
比如你的标签本来是[1, 0, 2, 3],但它们可能被电脑认成了其他类型(比如小数类型1.0,或者占用内存很小的整数类型)🧑💻 -
换衣服操作
.astype(np.int64)相当于给这些标签统一换上了「64位整数」的制服👔。- 为什么是64位? 这种类型能装超大数字(从
-9亿亿到9亿亿) - 为什么不用32位? 怕数字太大装不下(比如你有10亿条数据时,32位可能溢出)
- 为什么是64位? 这种类型能装超大数字(从
self.num_samples = self.traces.shape[0]1️⃣ 代码作用
这行代码在数你有多少条数据,就像数一箱苹果有多少个🍎。
self.traces 是你的数据表格(比如一个 Excel 表格),每一行代表一个样本(比如一张图片、一条传感器数据)。
2️⃣ 具体拆解
shape:数据表格的形状- 比如数据是 1000 行 x 200 列,
shape就是(1000,200)
- 比如数据是 1000 行 x 200 列,
[0](@ref):取形状的第一个数字(行数)- 就像问:"这个表格有多少行?"
那我们差不多应该理解在经过了这几行代码之后,我们的self.traces、self.labels还有self.num_samples都是什么了。
首先self.traces,内部应该是一个50000行,每行5个元素的数组
其次是self.labels,应该就是一个竖着的数组,50000行,每行1个元素
最后是self.num_samples,应该就是50000
四、大数据分块处理
max_split_size = 2000000000 // self.input_length
split_idx = list(range(max_split_size, self.num_samples, max_split_size))
self.traces = np.split(self.traces, split_idx, axis=0)
self.labels = np.split(self.labels, split_idx, axis=0)- 功能:将数据切分成多个小块,避免内存溢出
max_split_size:计算每块的最大样本数(2GB内存限制 ÷ 每条数据长度)np.split():按计算的分割点将数据切分(例如将10000条数据分成5块,每块2000条)- 应用场景:处理超大规模数据集(如GB级时序数据)
因为self.input_length是5,运算:使用整数除法 //,即 向下取整取商,所以max_split_size是4亿。
但是,问题十分大,range这个东西

所以其实我们打印出来的split_idx是空的。
理论上这样会报错才对,但是没有
于是我加了两个print,结果和我们之前说的一样
self.traces,内部应该是一个50000行,每行5个元素的数组
self.labels,应该就是一个竖着的数组,50000行,每行1个元素
这和前面没有处理的时候是一样的,不知道这样的作用是什么
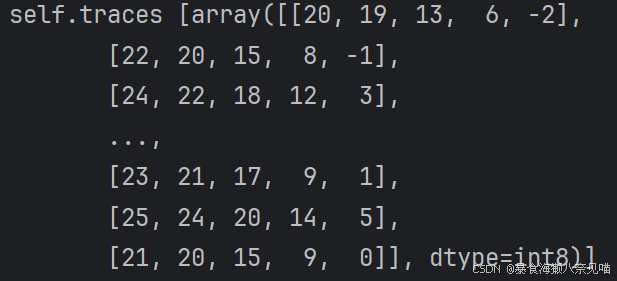
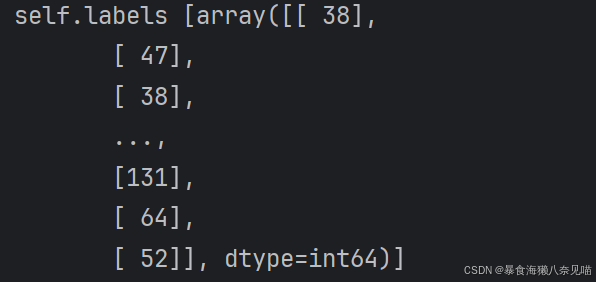
五、元数据解析
self.plaintexts = self.GetPlaintexts(corpus[split_key]['metadata'])
self.masks = self.GetMasks(corpus[split_key]['metadata'])
self.keys = self.GetKeys(corpus[split_key]['metadata'])- 功能:从元数据中提取加密相关信息
plaintexts:明文数据(加密前的原始数据)masks:掩码值(用于侧信道攻击中的安全防护)keys:密钥信息- 技术细节:通过遍历
metadata逐条提取,转为Numpy数组方便后续处理
一、元数据提取部分
1. GetPlaintexts 方法
def GetPlaintexts(self, metadata):
plaintexts = []
for i in range(len(metadata)):
plaintexts.append(metadata[i]['plaintext'][2](@ref))
return np.array(plaintexts)- 功能:从元数据中提取所有样本的明文(原始数据)
metadata是一个列表,每个元素是一个字典(例如存储加密相关数据)metadata[i]['plaintext'][2](@ref)表示取第i个样本的plaintext字段的第3个值(索引从0开始)- 将所有明文存入列表
plaintexts,最后转为Numpy数组返回
用途举例:在加密分析中获取原始未加密数据
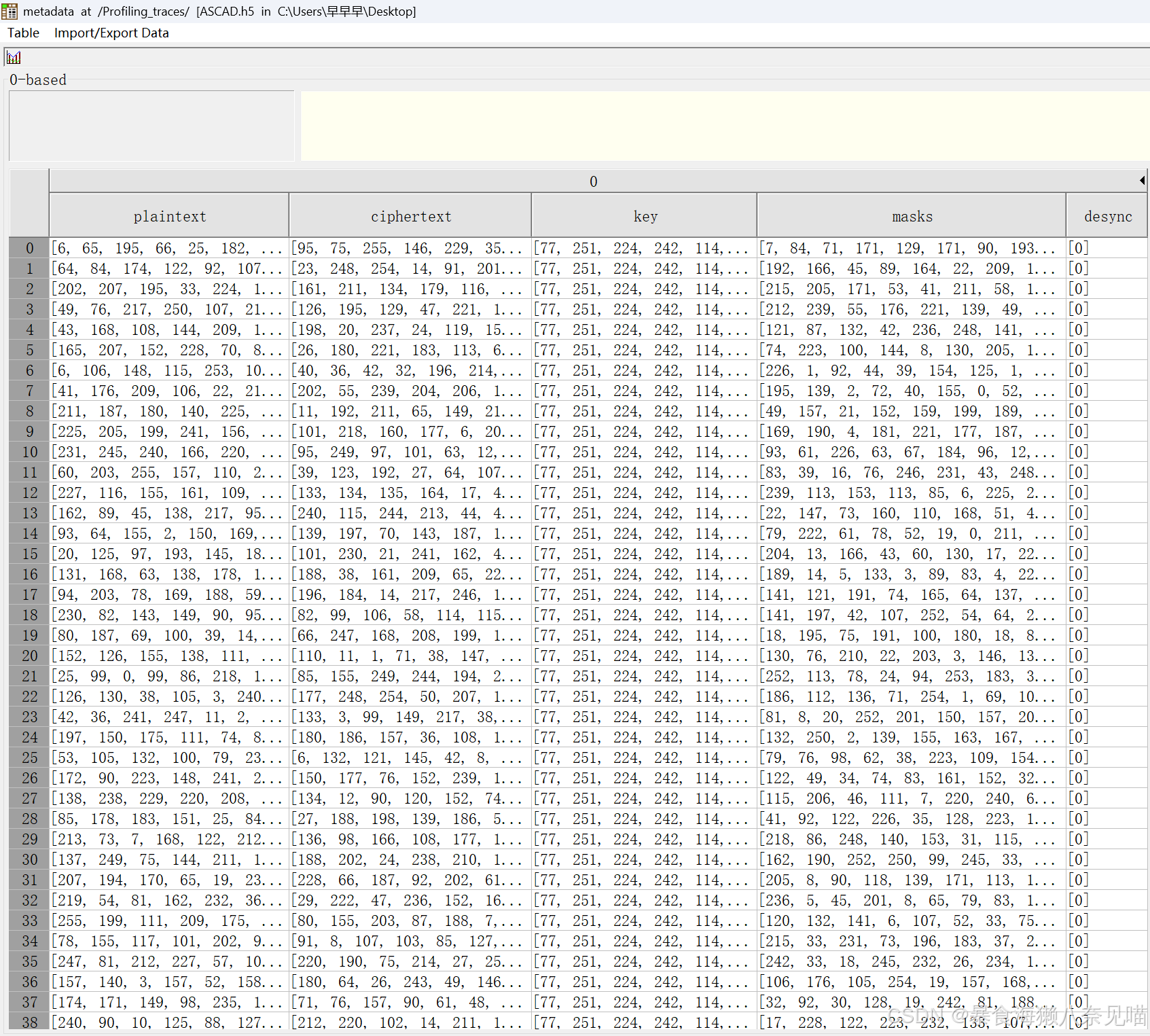
2. GetKeys 方法
def GetKeys(self, metadata):
keys = []
for i in range(len(metadata)):
keys.append(metadata[i]['key'][2](@ref))
return np.array(keys)- 功能:提取所有样本的密钥信息
- 结构同
GetPlaintexts,但取的是key字段的第3个值 - 密钥通常用于加密过程中的核心参数
- 结构同
3. GetMasks 方法
def GetMasks(self, metadata):
masks = []
for i in range(len(metadata)):
masks.append(np.array(metadata[i]['masks']))
masks = np.stack(masks, axis=0)
return masks- 功能:提取掩码数组并堆叠成矩阵
metadata[i]['masks']获取每个样本的掩码数组(例如加密掩码)np.stack将所有掩码沿第0轴(行方向)堆叠,形成二维数组
用途举例:侧信道分析中保护敏感数据免受攻击
二、TensorFlow数据集构建
4. GetTFRecords 方法
def GetTFRecords(self, batch_size, training=False):
# 步骤1:初始化数据集(取第一个数据块)
dataset = tf.data.Dataset.from_tensor_slices((self.traces[0](@ref), self.labels[0](@ref)))
# 步骤2:拼接其他数据块
for traces, labels in zip(self.traces[1:], self.labels[1:]):
temp_dataset = tf.data.Dataset.from_tensor_slices((traces, labels))
dataset.concatenate(temp_dataset)
# 步骤3:定义随机偏移函数(数据增强)
def shift(x, max_desync):
ds = tf.random.uniform([1](@ref), 0, max_desync+1, tf.dtypes.int32) # 生成随机偏移量
ds = tf.concat([[0](@ref), ds], 0) # 保持第0维度不偏移(如通道维度)
x = tf.slice(x, ds, [-1, self.input_length]) # 截取有效数据段
return x
# 步骤4:训练模式处理
if training == True:
if self.input_length < self.traces[0](@ref).shape[1](@ref):
return dataset.repeat() \ # 无限重复数据集
.shuffle(self.num_samples) \ # 打乱顺序增强泛化性
.batch(batch_size//2) \ # 分半批次(后续重组)
.map(lambda x, y: (shift(x, self.data_desync), y)) \ # 应用随机偏移
.unbatch() \ # 解批便于重新分批次
.batch(batch_size, drop_remainder=True) \ # 重组完整批次
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \ # 转浮点类型
.prefetch(10) # 预加载加速训练
else:
# 若无需偏移,直接处理批次和类型转换
return dataset.repeat().shuffle(...).batch(...).map(...).prefetch(10)
# 步骤5:推理模式处理(无随机偏移)
else:
if self.input_length < self.traces[0](@ref).shape[1](@ref):
return dataset.batch(...).map(shift(x,0)).map(cast).prefetch(10)
else:
return dataset.batch(...).map(cast).prefetch(10)- 关键点:
- 数据分块拼接:
traces和labels被分块存储,需拼接成完整数据集 - 随机偏移:
shift函数模拟信号去同步(如时序对齐问题),提升模型鲁棒性 - 批处理优化:通过分批次(
batch)、预加载(prefetch)加速训练
- 数据分块拼接:
(一)、数据集初始化块
dataset = tf.data.Dataset.from_tensor_slices((self.traces[0], self.labels[0]))
for traces, labels in zip(self.traces[1:], self.labels[1:]):
temp_dataset = tf.data.Dataset.from_tensor_slices((traces, labels))
dataset.concatenate(temp_dataset)- 作用:创建基础数据集并合并多个数据源
- 关键点:
from_tensor_slices将numpy数组转换为Dataset对象,for循环合并多个数据分片,类似SQL的UNION ALL操作(但当前写法需修正,应使用dataset = dataset.concatenate()保存结果)
- 类比:像把多个Excel表格上下拼接成一个大表
(二)、数据位移函数块
def shift(x, max_desync):
ds = tf.random.uniform([1], 0, max_desync+1, tf.dtypes.int32)
ds = tf.concat([[0], ds], 0)
x = tf.slice(x, ds, [-1, self.input_length])
return x- 作用:生成带随机偏移的数据切片
- 关键点:
tf.random.uniform产生随机位移量(类似网页13的随机数生成)tf.concat拼接起始位置(网页10说明列方向拼接)tf.slice截取指定长度数据(类似SQL的SUBSTRING函数)
- 示例:输入数据长度100,若
max_desync=5,可能截取位置3-103的数据
(三)、训练模式处理块
if training == True:
if self.input_length < self.traces[0].shape[1]:
return dataset.repeat() \
.shuffle(self.num_samples) \
.batch(batch_size//2) \
.map(lambda x, y: (shift(x, self.data_desync), y)) \
.unbatch() \
.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)- 核心流程(类似网页8的MNIST处理):
repeat()无限循环数据集(像循环播放音乐)shuffle()打乱数据顺序(像洗牌)- 特殊操作:先小批量处理→解批→重组,用于增强数据多样性
prefetch预加载数据提升性能(类似提前准备食材)
(四)、非训练模式处理块
else:
if self.input_length < self.traces[0].shape[1]:
return dataset.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (shift(x, 0), y)) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)- 特点:
shift(x,0)禁用随机偏移,保证结果确定性- 直接批量处理不重复(像考试时不做数据增强)
- 保持与训练相同的类型转换(
tf.float32)
三、原始数据获取
5. GetDataset 方法
def GetDataset(self):
return self.traces, self.labels- 功能:直接返回原始的
traces(时序信号)和labels(标签)
用途举例:非TensorFlow流程(如数据分析或自定义训练循环)直接使用Numpy格式数据
总结表格
| 方法名 | 输入 | 输出 | 核心功能 | 应用场景 |
|---|---|---|---|---|
GetPlaintexts | metadata字典列表 | Numpy数组(明文) | 提取加密前的原始数据 | 加密分析、数据验证 |
GetKeys | metadata字典列表 | Numpy数组(密钥) | 提取加密参数 | 加密算法逆向分析 |
GetMasks | metadata字典列表 | Numpy二维数组(掩码) | 生成保护敏感数据的掩码矩阵 | 侧信道攻击防护 |
GetTFRecords | batch_size, training | TensorFlow Dataset | 构建支持增强和高效加载的数据流 | 深度学习模型训练/推理 |
GetDataset | 无 | (traces, labels) | 获取原始分块数据 | 数据可视化、非TensorFlow流程 |
通过这种设计,数据集类实现了从原始数据到深度学习友好格式的全流程支持
这里我们再关注一下其中的TensorFlow数据集构建
1、数据集初始化
dataset = tf.data.Dataset.from_tensor_slices((self.traces[0](@ref), self.labels[0](@ref)))- 功能:把第一个数据块(
self.traces[0](@ref)和对应的标签self.labels[0](@ref))转换成TensorFlow的Dataset格式 - 类比:就像把第一本书放进书架,准备后续阅读。
2、拼接其他数据块
for traces, labels in zip(self.traces[1:], self.labels[1:]):
temp_dataset = tf.data.Dataset.from_tensor_slices((traces, labels))
dataset.concatenate(temp_dataset)- 功能:把剩下的数据块(比如第二本、第三本书)依次拼接到初始数据集后面
- 问题点:这里的循环拼接可能存在逻辑错误(实际需要积累拼接结果),但代码意图是合并所有分块数据。
3、随机偏移函数(数据增强)
def shift(x, max_desync):
ds = tf.random.uniform([1](@ref), 0, max_desync+1, tf.dtypes.int32)
ds = tf.concat([[0](@ref), ds], 0)
x = tf.slice(x, ds, [-1, self.input_length])
return x- 功能:模拟信号不同步的场景(比如录音时麦克风延迟)
tf.random.uniform:生成0到max_desync之间的随机整数(偏移量)tf.concat([[0](@ref), ds], 0):确保第0维(通常是通道维度)不偏移tf.slice:根据随机偏移量截取有效数据段
- 类比:随机裁剪图片的一部分,让模型学会关注关键特征。
4、训练模式处理
if training == True:
if self.input_length < self.traces[0](@ref).shape[1](@ref):
return dataset.repeat() \
.shuffle(self.num_samples) \
.batch(batch_size//2) \
.map(应用随机偏移) \
.unbatch() \
.batch(batch_size) \
.map(转浮点类型) \
.prefetch(10)- 核心流程(训练时数据增强)
.repeat():无限循环数据集(比如训练100轮需要重复读取).shuffle():打乱数据顺序(防止模型记住样本顺序).batch(batch_size//2):先分小批次(方便后续重组时增加数据多样性).map(shift):应用随机偏移(数据增强).unbatch():拆散小批次(准备重组).batch(batch_size):重新组成完整批次.prefetch(10):预加载10个批次(加速训练)
5、推理模式处理
else:
return dataset.batch(batch_size, drop_remainder=True) \
.map(固定偏移) \
.map(转浮点类型) \
.prefetch(10)- 与训练的区别:
- 无随机偏移:
shift(x, 0)固定从第0位开始截取 - 无需打乱顺序:保持原始数据排列
- 直接完整批次:不分拆重组
- 无随机偏移:
- 应用场景:模型评估或实际使用时,要保证数据一致性
6、关键概念说明
| 术语 | 解释 |
|---|---|
tf.data.Dataset | TensorFlow的数据管道工具,类似传送带把数据分批送给模型 |
map() | 对每个数据做相同操作(比如裁剪、类型转换) |
prefetch() | 后台预加载数据,避免模型训练时等待数据(类似餐厅提前备菜) |
drop_remainder=True | 丢弃最后不足一个批次的数据(比如100个样本,批次32,则最后一组4个会被丢弃) |
举个实际例子
假设:
input_length=1000(有效数据长度)data_desync=50(允许最大偏移量)- 某条原始数据长度
1050
训练时:
- 随机生成偏移量(比如35)
- 截取
[35:35+1000]区间的数据 - 每次训练看到的数据起始点都不同
推理时:
- 固定截取
[0:1000] - 保证每次输入位置一致
通过这种方式,模型既能学习抗干扰能力(训练),又能稳定输出结果(推理)。
接下来是最主要的部分

train_new.py
一、数据预设部分
(一)、GPU配置
- use_tpu
- 类型:
布尔值 - 默认值:
False - 作用:是否使用谷歌的TPU芯片加速计算。如果你有TPU设备就设为True,否则用普通CPU/GPU
- 类型:
(二)、实验配置(数据/模型路径)
-
data_path
- 类型:
字符串 - 默认路径:
D:\...\ASCAD.h5 - 作用:指定训练数据文件的绝对路径。例如ASCAD.h5是一个侧信道攻击数据集
- 类型:
-
dataset
- 类型:
字符串 - 可选值:
ASCAD, CHES20等 - 作用:选择要使用的数据集名称,不同数据集对应不同的预处理方式
- 类型:
-
checkpoint_dir
- 类型:
字符串 - 默认路径:
D:\...\checkpoints - 作用:模型训练过程中保存的检查点文件存放目录
- 类型:
-
checkpoint_idx
- 类型:
整数 - 默认值:
0 - 作用:要恢复的检查点编号。例如设置为5会加载checkpoint-5文件
- 类型:
-
warm_start
- 类型:
布尔值 - 默认值:
False - 作用:是否从之前的检查点继续训练。True表示"热启动",适合中断后恢复训练
- 类型:
-
result_path
- 类型:
字符串 - 默认路径:
D:\...\result - 作用:评估结果(如准确率、注意力图)的输出目录
- 类型:
-
do_train
- 类型:
布尔值 - 默认值:
False - 作用:True执行训练模式,False执行评估模式
- 类型:
(三)、优化配置
-
learning_rate
- 类型:
浮点数 - 默认值:
0.00025 - 作用:初始学习率。值越大模型参数更新幅度越大,但可能不收敛
- 类型:
-
clip
- 类型:
浮点数 - 默认值:
0.25 - 作用:梯度裁剪阈值。防止梯度爆炸,超过该值的梯度会被截断
- 类型:
-
min_lr_ratio
- 类型:
浮点数 - 默认值:
0.004 - 作用:学习率衰减后的最小比例。例如初始学习率是0.001,最小会降到0.000004
- 类型:
-
warmup_steps
- 类型:
整数 - 默认值:
0 - 作用:学习率线性预热步数。例如设为1000,则前1000步学习率从0逐渐升到最大
- 类型:
-
input_length
- 类型:
整数 - 默认值:
700 - 作用:输入模型的时序数据长度。例如每个功耗轨迹截取700个点
- 类型:
-
data_desync
- 类型:
整数 - 默认值:
0 - 作用:数据增强时允许的最大时序偏移量。例如设为5会随机偏移0-5个点增强数据
- 类型:
(四)、训练配置
-
train_batch_size
- 类型:
整数 - 默认值:
256 - 作用:训练时每个批次的样本量。越大显存占用越高,但训练速度可能更快
- 类型:
-
eval_batch_size
- 类型:
整数 - 默认值:
32 - 作用:评估时的批次大小。通常比训练批次小以节省显存
- 类型:
-
train_steps
- 类型:
整数 - 默认值:
100000 - 作用:总训练步数。每一步处理一个批次的数据
- 类型:
-
iterations
- 类型:
整数 - 默认值:
500 - 作用:每个训练循环的迭代次数。影响检查点保存频率
- 类型:
-
save_steps
- 类型:
整数 - 默认值:
10000 - 作用:每隔多少步保存一次模型。例如10000步保存一个检查点
- 类型:
(五)、模型配置(Transformer相关)
-
n_layer
- 类型:
整数 - 默认值:
6 - 作用:Transformer的堆叠层数。层数越多模型越复杂
- 类型:
-
d_model
- 类型:
整数 - 默认值:
128 - 作用:模型隐藏层的维度。维度越大模型容量越大
- 类型:
-
d_head
- 类型:
整数 - 默认值:
32 - 作用:每个注意力头的维度。影响多头注意力的计算方式
- 类型:
-
n_head
- 类型:
整数 - 默认值:
4 - 作用:多头注意力机制中的头数。更多头能捕捉不同特征
- 类型:
-
d_inner
- 类型:
整数 - 默认值:
256 - 作用:前馈神经网络中间层的维度。通常比d_model大
- 类型:
-
dropout
- 类型:
浮点数 - 默认值:
0.1 - 作用:随机失活比例。防止过拟合,10%的神经元会被随机关闭
- 类型:
(六)、评估配置
-
max_eval_batch
- 类型:
整数 - 默认值:
-1 - 作用:最大评估批次数。-1表示评估全部数据
- 类型:
-
output_attn
- 类型:
布尔值 - 默认值:
False - 作用:是否输出注意力权重矩阵。True可用于可视化注意力机制
- 类型:
二、类LRSchedule(tf.keras.optimizers.schedules.LearningRateSchedule)
class LRSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, max_lr, tr_steps, wu_steps=0, min_lr_ratio=0.0):
self.max_lr=max_lr
self.tr_steps=tr_steps
self.wu_steps=wu_steps
self.min_lr_ratio=min_lr_ratio
def __call__(self, step):
step_float = tf.cast(step, tf.float32)
wu_steps_float = tf.cast(self.wu_steps, tf.float32)
tr_steps_float = tf.cast(self.tr_steps, tf.float32)
max_lr_float =tf.cast(self.max_lr, tf.float32)
min_lr_ratio_float = tf.cast(self.min_lr_ratio, tf.float32)
# warmup learning rate using linear schedule
wu_lr = (step_float/wu_steps_float) * max_lr_float
# decay the learning rate using the cosine schedule
global_step = tf.math.minimum(step_float-wu_steps_float, tr_steps_float-wu_steps_float)
decay_steps = tr_steps_float-wu_steps_float
pi = tf.constant(math.pi)
cosine_decay = .5 * (1. + tf.math.cos(pi * global_step / decay_steps))
decayed = (1.-min_lr_ratio_float) * cosine_decay + min_lr_ratio_float
decay_lr = max_lr_float * decayed
return tf.cond(step < self.wu_steps, lambda: wu_lr, lambda: decay_lr)(一)、初始化模块(积木底座)
def __init__(self, max_lr, tr_steps, wu_steps=0, min_lr_ratio=0.0):
self.max_lr = max_lr # 最大学习率(油门最大值)
self.tr_steps = tr_steps # 总训练步数(全程里程)
self.wu_steps = wu_steps # 预热步数(起步加速距离)
self.min_lr_ratio = min_lr_ratio # 最小学习率比例(刹停后怠速)这相当于给汽车设置性能参数:
max_lr=0.001:最高时速200km/htr_steps=10000:总行程10000公里wu_steps=2000:前2000公里是起步加速阶段min_lr_ratio=0.01:停车后保持1%的怠速
(二)、核心计算模块(引擎工作原理)
def __call__(self, step):
# 类型转换(统一为浮点数计算)
step_float = tf.cast(step, tf.float32)
wu_steps_float = tf.cast(self.wu_steps, tf.float32)
tr_steps_float = tf.cast(self.tr_steps, tf.float32)
max_lr_float = tf.cast(self.max_lr, tf.float32)
min_lr_ratio_float = tf.cast(self.min_lr_ratio, tf.float32)这里将所有参数转为浮点数,就像把仪表盘单位统一为公里/小时。
阶段一:预热加速(踩油门)
# 线性增长公式:当前步数/总预热步数 * 最大学习率
wu_lr = (step_float / wu_steps_float) * max_lr_float这相当于:
- 前
wu_steps步学习率从0线性增长到max_lr - 例如:1000步预热时,第500步的学习率是
max_lr * 0.5
原理:避免初期大学习率导致模型震荡,像新手司机先慢速起步
阶段二:余弦衰减(平缓刹车)
# 计算有效训练步数(扣除预热阶段)
global_step = tf.math.minimum(step_float - wu_steps_float,
tr_steps_float - wu_steps_float)
decay_steps = tr_steps_float - wu_steps_float
# 余弦函数计算衰减比例
pi = tf.constant(math.pi)
cosine_decay = 0.5 * (1. + tf.math.cos(pi * global_step / decay_steps))
# 加入最小学习率保护
decayed = (1. - min_lr_ratio_float) * cosine_decay + min_lr_ratio_float
decay_lr = max_lr_float * decayed这相当于汽车进入巡航模式后平缓减速:
cos(π*x)将直线下降变为波浪形曲线,避免急刹车1
min_lr_ratio保证学习率不会降为0,维持微调能力- 公式分解:
- 当
global_step=0时,cos(0)=1→ 学习率=最大 - 当
global_step=decay_steps时,cos(π)= -1→ 学习率=最大 * 最小比例
- 当
优势:相比阶梯式衰减更平滑,适合大型模型收敛
阶段切换(油门/刹车切换器)
return tf.cond(step < self.wu_steps,
lambda: wu_lr,
lambda: decay_lr)这是一个智能开关:
- 当步数
<wu_steps时返回预热阶段的学习率 - 否则返回余弦衰减后的学习率
就像汽车ECU根据车速自动切换加速/巡航模式
三、模型
def create_model(n_classes):
model = Transformer(
n_layer = FLAGS.n_layer,
d_model = FLAGS.d_model,
d_head = FLAGS.d_head,
n_head = FLAGS.n_head,
d_inner = FLAGS.d_inner,
n_head_softmax = FLAGS.n_head_softmax,
d_head_softmax = FLAGS.d_head_softmax,
dropout = FLAGS.dropout,
n_classes = n_classes,
conv_kernel_size = FLAGS.conv_kernel_size,
n_conv_layer = FLAGS.n_conv_layer,
pool_size = FLAGS.pool_size,
d_kernel_map = FLAGS.d_kernel_map,
beta_hat_2 = FLAGS.beta_hat_2,
model_normalization = FLAGS.model_normalization,
head_initialization = FLAGS.head_initialization,
softmax_attn = FLAGS.softmax_attn,
output_attn = FLAGS.output_attn
)
return model1. 功能总览
def create_model(n_classes):
model = Transformer(...)
return model这个工厂函数用来定制化生产Transformer模型,就像乐高工厂根据设计图纸生产不同型号的机器人。参数n_classes决定机器人的"大脑容量"(分类能力)
2. 核心参数详解
**(1) 模型骨架配置**
n_layer = FLAGS.n_layer, # 机器人的"脊椎节数"(层数),默认6节
d_model = FLAGS.d_model, # 每节脊椎的"神经数量"(隐藏层维度),默认128
d_head = FLAGS.d_head, # 每个"观察眼"的解析度(注意力头维度),默认32
n_head = FLAGS.n_head, # "观察眼"的数量(多头注意力头数),默认4个
d_inner = FLAGS.d_inner, # "思考回路"的复杂度(前馈网络维度),默认256这相当于设定机器人的基础身体结构,比如:
- 6层结构就像6层楼高的变形金刚
- 每个注意力头就像不同颜色的滤镜(红色头看形状,蓝色头看纹理)
**(2) 特殊能力模块**
n_head_softmax = FLAGS.n_head_softmax, # 特殊观察眼数量(软注意力头)
d_head_softmax = FLAGS.d_head_softmax, # 特殊观察眼解析度
dropout = FLAGS.dropout, # "防过载冷却液"比例(随机关闭10%神经元)
conv_kernel_size = FLAGS.conv_kernel_size, # 视觉扫描镜片尺寸(卷积核大小3)
n_conv_layer = FLAGS.n_conv_layer, # 视觉扫描层数(1层卷积)这里配置机器人的特异功能:
softmax_attn=True时像开启X光透视眼- 卷积层像给机器人装上了显微镜(捕捉局部特征)
**(3) 智能控制系统**
model_normalization = FLAGS.model_normalization, # 神经信号稳定器类型(preLC)
head_initialization = FLAGS.head_initialization, # 观察眼初始化方式(正向扫描)
beta_hat_2 = FLAGS.beta_hat_2, # 注意力聚焦参数(放大重要特征的显微镜倍数)
output_attn = FLAGS.output_attn # 是否开启"思维可视化"功能这些参数控制机器人的"大脑运作方式":
preLC表示在每层处理前先稳定信号(类似先擦干净镜片再观察)beta_hat_2=100会重点放大关键特征,忽略无关细节
3. 生产流程示意图
输入:分类类别数 → 流水线配置 → 组装Transformer → 输出成品机器人
(n_classes) (FLAGS参数) (各零件组合)比如当n_classes=256时,机器人最后会装备256个分类识别器(相当于能识别256种不同物体)。
4. 定制化扩展说明
通过修改FLAGS参数,可以实现:
- 体型变化:设置
n_layer=12得到双倍高度的巨人模型 - 视觉升级:
conv_kernel_size=5换成更大镜片的显微镜 - 节能模式:
dropout=0.3关闭30%神经元防止"大脑过热"
这与网页2提到的timm库的模型注册机制类似,都是通过参数化配置实现模型灵活创建。而网页4中Keras的Model构建思想也与此相通,都是模块化组装深度学习模型。
5. 典型应用场景
- 图像分类:设置
n_classes=1000打造ImageNet专用机器人 - 文本理解:调整
d_model=512增强语言解析能力 - 科学研究:开启
output_attn=True观察机器人注意力焦点
就像网页3提到的视觉Transformer应用,这个函数可以快速创建适配不同任务的模型变体。
四、训练过程
def train(train_dataset, eval_dataset, num_train_batch, num_eval_batch, strategy, chk_name):
# Ensure that the batch sizes are divisible by number of replicas in sync
assert(FLAGS.train_batch_size % strategy.num_replicas_in_sync == 0)
assert(FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0)
##### Create computational graph for train dataset
train_dist_dataset = strategy.experimental_distribute_dataset(train_dataset)
##### Create computational graph for eval dataset
eval_dist_dataset = strategy.experimental_distribute_dataset(eval_dataset)
if FLAGS.save_steps <= 0:
FLAGS.save_steps = None
else:
# Set the FLAGS.save_steps to a value multiple of FLAGS.iterations
if FLAGS.save_steps < FLAGS.iterations:
FLAGS.save_steps = FLAGS.iterations
else:
FLAGS.save_steps = (FLAGS.save_steps // FLAGS.iterations) * \
FLAGS.iterations
##### Instantiate learning rate scheduler object
lr_sch = LRSchedule(
FLAGS.learning_rate, FLAGS.train_steps, \
FLAGS.warmup_steps, FLAGS.min_lr_ratio
)
loss_dic_file = os.path.join(FLAGS.checkpoint_dir, 'loss.pkl')
##### Create computational graph for model
with strategy.scope():
if FLAGS.dataset == 'CHES20':
model = create_model(4)
else:
model = create_model(256)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_sch)
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
eval_loss = tf.keras.metrics.Mean('eval_loss', dtype=tf.float32)
grad_norm = tf.keras.metrics.Mean('grad_norms', dtype=tf.float32)
new_start = True
if FLAGS.warm_start:
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint, starting training from beginning")
else:
tf.compat.v1.logging.info("Found checkpoint: {}".format(chk_path))
try:
checkpoint.restore(chk_path, options=options)
tf.compat.v1.logging.info("Restored checkpoint: {}".format(chk_path))
new_start = False
except:
tf.compat.v1.logging.info("Could not restore checkpoint, starting training from beginning")
print("new_start",new_start)
if new_start == True:
# Save the initial model
print("chk_name", chk_name)
print("FLAGS.checkpoint_dir", FLAGS.checkpoint_dir)
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
print("chk_path",chk_path)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))
loss_dic = {}
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))
else:
loss_dic = pickle.load(open(loss_dic_file, 'rb'))
@tf.function
def train_steps(iterator, steps, bsz, global_step):
###### Reset the states of the update variables
train_loss.reset_states()
grad_norm.reset_states()
###### The step function for one training step
def step_fn(inps, lbls, global_step):
lbls = tf.squeeze(lbls)
with tf.GradientTape() as tape:
softmax_attn_smoothing = 1. #tf.minimum(float(global_step)/FLAGS.train_steps, 1.)
logits = model(inps, softmax_attn_smoothing, training=True)[0]
if FLAGS.dataset == 'CHES20':
per_example_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(lbls, logits),
axis = 1
)
else:
per_example_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(lbls, logits)
avg_loss = tf.nn.compute_average_loss(per_example_loss, \
global_batch_size=bsz)
variables = tape.watched_variables()
gradients = tape.gradient(avg_loss, variables)
clipped, gnorm = tf.clip_by_global_norm(gradients, FLAGS.clip)
optimizer.apply_gradients(list(zip(clipped, variables)))
train_loss.update_state(avg_loss * strategy.num_replicas_in_sync)
grad_norm.update_state(gnorm)
for _ in range(steps):
global_step += 1
inps, lbls = next(iterator)
strategy.run(step_fn, args=(inps, lbls, global_step))
@tf.function
def eval_steps(iterator, steps, bsz):
###### The step function for one evaluation step
def step_fn(inps, lbls):
lbls = tf.squeeze(lbls)
logits = model(inps)[0]
if FLAGS.dataset == 'CHES20':
per_example_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(lbls, logits),
axis = 1
)
else:
per_example_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(lbls, logits)
avg_loss = tf.nn.compute_average_loss(per_example_loss, \
global_batch_size=bsz)
eval_loss.update_state(avg_loss * strategy.num_replicas_in_sync)
for _ in range(steps):
inps, lbls = next(iterator)
strategy.run(step_fn, args=(inps, lbls,))
tf.compat.v1.logging.info('Starting training ... ')
train_iter = iter(train_dist_dataset)
cur_step = optimizer.iterations.numpy()
while cur_step < FLAGS.train_steps:
train_steps(train_iter, tf.convert_to_tensor(FLAGS.iterations), \
FLAGS.train_batch_size, cur_step)
cur_step = optimizer.iterations.numpy()
cur_loss = train_loss.result()
gnorm = grad_norm.result()
lr_rate = lr_sch(cur_step)
dic = {}
tf.compat.v1.logging.info("[{:6d}] | gnorm {:5.2f} lr {:9.6f} "
"| loss {:>5.2f}".format(cur_step, gnorm, lr_rate, cur_loss))
dic['gnorm'] = gnorm.numpy()
dic['running_train_loss'] = cur_loss.numpy()
if FLAGS.max_eval_batch <= 0:
num_eval_iters = num_eval_batch
else:
num_eval_iters = min(FLAGS.max_eval_batch, num_eval_batch)
eval_tr_iter = iter(train_dist_dataset)
eval_loss.reset_states()
eval_steps(eval_tr_iter, tf.convert_to_tensor(num_eval_iters), \
FLAGS.train_batch_size)
cur_eval_loss = eval_loss.result()
tf.compat.v1.logging.info("Train batches[{:5d}] |"
" loss {:>5.2f}".format(num_eval_iters, cur_eval_loss))
dic['train_loss'] = cur_eval_loss.numpy()
eval_va_iter = iter(eval_dist_dataset)
eval_loss.reset_states()
eval_steps(eval_va_iter, tf.convert_to_tensor(num_eval_iters), \
FLAGS.eval_batch_size)
cur_eval_loss = eval_loss.result()
tf.compat.v1.logging.info("Eval batches[{:5d}] |"
" loss {:>5.2f}".format(num_eval_iters, cur_eval_loss))
dic['test_loss'] = cur_eval_loss.numpy()
loss_dic[cur_step] = dic
if FLAGS.save_steps is not None and (cur_step) % FLAGS.save_steps == 0:
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))
if FLAGS.save_steps is not None and (cur_step) % FLAGS.save_steps != 0:
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))(一)、前置数据
assert(FLAGS.train_batch_size % strategy.num_replicas_in_sync == 0)
assert(FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0)
##### Create computational graph for train dataset
train_dist_dataset = strategy.experimental_distribute_dataset(train_dataset)
##### Create computational graph for eval dataset
eval_dist_dataset = strategy.experimental_distribute_dataset(eval_dataset)1. 技术原理
- **
strategy.num_replicas_in_sync**:表示分布式训练中同步运行的设备数量(如多GPU或TPU的个数)。 - **
FLAGS.train_batch_size和FLAGS.eval_batch_size**:分别是训练和评估时的全局批次大小(所有设备共同处理的样本总数)。
这两行代码的数学逻辑是:
全局批次大小 % 设备数量 == 0目的:确保全局批次大小能被设备数量整除,从而每个设备分配到相同数量的样本,避免数据分配不均导致的计算错误或性能下降。
2. 实际作用
-
数据均匀分配
例如,若使用4个GPU训练且train_batch_size=256,则每个GPU实际处理256/4=64个样本。如果train_batch_size=255,则255%4=3,会出现无法均分的情况,导致程序崩溃 -
防止分布式训练错误
在TensorFlow的MirroredStrategy等分布式策略中,数据会被自动切分到各个设备。若批次大小无法被设备数整除,可能导致:- 最后一个批次的样本数不足
- 不同设备间的梯度计算不一致
- 程序抛出
InvalidArgumentError等异常
-
调试阶段的显式检查
通过assert语句提前暴露参数配置问题,避免训练中途因数据问题失败,这与断言的设计初衷一致(在开发阶段捕获非法输入或逻辑错误)
3. 类比说明
假设有一个需要均匀分蛋糕的场景:
- 蛋糕总量 = 全局批次大小
- 人数 = 设备数量
- 断言的作用 = 检查蛋糕是否能被人数整除
若不能整除,断言会直接报错,避免有人分到多一块、有人少一块的不公平情况。
4. 关联场景
- 多GPU训练:这是最常见的应用场景,需保证每个GPU的计算负载均衡。
- TPU集群训练:在TPU Pod等大规模集群中,批次大小的适配更为关键。
- 数据并行策略:任何基于数据并行的分布式训练框架都需要此类检查。
5.分布式数据集构建
train_dist_dataset = strategy.experimental_distribute_dataset(train_dataset)
eval_dist_dataset = strategy.experimental_distribute_dataset(eval_dataset)- 作用:将原始数据集转换为适配分布式策略的分布式数据集
- 实现细节:
- 数据分片:自动将数据集按设备数分片,例如4个GPU时,每个GPU获取1/4的数据。
- 通信优化:使用高效的数据传输策略(如NCCL库)跨设备同步数据
- 适配策略:支持同步训练(如
MirroredStrategy)和异步训练(如ParameterServerStrategy)
(二)、FLAGS.save_steps
一、检查点保存频率设置
if FLAGS.save_steps <= 0:
FLAGS.save_steps = None
else:
if FLAGS.save_steps < FLAGS.iterations:
FLAGS.save_steps = FLAGS.iterations
else:
FLAGS.save_steps = (FLAGS.save_steps // FLAGS.iterations) * FLAGS.iterations作用解析:
-
禁用检查点保存
save_steps <= 0时设为None,表示不自动保存检查点。适用于调试或短期训练场景 -
确保保存间隔对齐训练周期
- 当
save_steps < iterations时(例如用户设置保存频率100步,但每次迭代运行500步),强制将保存步数设为iterations,保证每次完整迭代后保存 - 否则通过整除运算对齐最近的迭代周期倍数(例如
iterations=500,用户设置save_steps=1200,则调整为1000)
- 当
设计意图:避免部分完成的迭代导致模型状态不一致(如梯度未完全同步),与分布式训练中的参数同步机制适配
二、学习率调度器初始化
lr_sch = LRSchedule(
FLAGS.learning_rate, FLAGS.train_steps, \
FLAGS.warmup_steps, FLAGS.min_lr_ratio
)参数解析:
| 参数 | 作用 | 技术背景 |
|---|---|---|
learning_rate | 基础学习率(预热后的峰值) | MirroredStrategy中需全局统一学习率 |
train_steps | 总训练步数(决定余弦衰减周期) | ClusterCoordinator调度的总步数对应 |
warmup_steps | 学习率线性增长阶段步数(避免初期大学习率震荡) | 分布式训练稳定性优化策略 |
min_lr_ratio | 衰减后最小学习率与峰值学习率的比例(防止学习率归零导致模型停止更新) | 检查点恢复时学习率重置的容错设计 |
调度器类型推测:结合代码上下文,可能实现了预热+余弦衰减策略,符合现代Transformer类模型训练的最佳实践
三、损失记录文件初始化
loss_dic_file = os.path.join(FLAGS.checkpoint_dir, 'loss.pkl')功能说明:
-
持久化训练指标
将训练/验证损失、梯度范数等指标序列化存储,用于:- 训练中断后恢复时绘制连续曲线(避免数据断层)
- 离线分析模型收敛情况(如通过Jupyter加载
.pkl文件)
-
与检查点协同工作
检查点目录同时保存模型参数(.ckpt)和训练指标(.pkl),确保调试信息的完整性
四、设计模式对比
| 配置项 | 常规实现方式 | 本代码特殊处理 | 优势说明 |
|---|---|---|---|
| 检查点保存频率 | 固定步数保存 | 对齐迭代周期 | 避免分布式训练中跨设备状态不一致 3 |
| 学习率调度 | 固定学习率或简单衰减 | 预热+衰减+最低学习率保护 | 提升大模型训练稳定性 5 8 |
| 指标记录 | 仅日志输出或TensorBoard | 序列化存储+检查点绑定 | 支持离线分析和断点续训 7 |
五、实际应用建议
-
超参数设置参考
warmup_steps建议设为总步数的5-10%(如10万步训练则预热5千~1万步)min_lr_ratio通常设为0.01~0.1,防止模型后期无法微调
-
故障恢复流程
# 恢复训练时同时加载模型和损失记录 checkpoint.restore(tf.train.latest_checkpoint(FLAGS.checkpoint_dir)) loss_dic = pickle.load(open(loss_dic_file, 'rb')) # 从pkl恢复指标此设计使得训练中断后能完整恢复上下文状态
通过以上设计,该代码段实现了与TensorFlow分布式训练框架深度集成的训练控制模块
(三)、超能插件
with strategy.scope():
if FLAGS.dataset == 'CHES20':
model = create_model(4)
else:
model = create_model(256)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_sch)
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
eval_loss = tf.keras.metrics.Mean('eval_loss', dtype=tf.float32)
grad_norm = tf.keras.metrics.Mean('grad_norms', dtype=tf.float32)
new_start = True1. 分布式策略作用域
with strategy.scope():- 作用:开启分布式训练的作用域,确保内部创建的变量和计算能被正确分配到所有设备
- 类比:就像在工厂车间划定一个"装配区",所有机器零件(模型参数)必须在此区域内组装,保证所有工人(GPU/TPU)使用相同的图纸
- 技术细节:
MirroredStrategy会在每个设备上创建模型副本- 梯度通过NCCL等通信库自动同步(如All-reduce操作)
2. 模型创建分支
if FLAGS.dataset == 'CHES20':
model = create_model(4) # 输出4分类模型
else:
model = create_model(256) # 输出256分类模型- 数据集适配:
- CHES20可能是特定任务(密码分析数据集),需要4分类输出
- 其他情况(如ImageNet)使用256分类,与MNIST分类的模型结构类似但规模更大
- 模型架构:
create_model可能包含Transformer结构- 输出层维度差异通过参数
n_classes实现动态调整
3. 优化器配置
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_sch)- 核心功能:
- 使用带学习率调度器的Adam优化器
lr_sch可能实现网页7描述的预热+余弦衰减策略
- 分布式特性:
- 梯度更新会自动跨设备同步(如网页4描述的MirroredStrategy机制)
- 学习率调度对全局步数生效(所有设备共享同一个训练进度)
4. 检查点系统
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)- 功能定位:
- 保存模型参数和优化器状态(如网页4提到的断点续训功能)
- 支持分布式环境下的多设备状态保存/恢复
- 技术亮点:
- 与网页6的
SyncReplicasOptimizer兼容 - 保存时会自动聚合所有设备的参数(如网页8描述的模型并行场景)
- 与网页6的
5. 训练监控指标
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
eval_loss = tf.keras.metrics.Mean('eval_loss', dtype=tf.float32)
grad_norm = tf.keras.metrics.Mean('grad_norms', dtype=tf.float32)- 指标作用:
train_loss:聚合所有设备的训练损失eval_loss:验证集损失,用于模型泛化能力评估grad_norm:监控梯度范数,防止梯度爆炸
- 分布式实现:
- 自动收集所有设备的数据计算全局平均值
- 数据类型强制为float32保证跨设备一致性
6. 训练状态标记
new_start = True- 流程控制:
- 标志是否从零开始训练(后续代码会尝试加载检查点覆盖此值)
- 与网页4描述的
warm_start参数配合使用
- 恢复机制:
- 若找到有效检查点,
new_start会被设为False - 确保分布式训练能正确继承历史状态(如网页5的多机训练恢复场景)
- 若找到有效检查点,
设计模式总结
| 代码段 | 对应分布式特性 |
|---|---|
| strategy.scope() | 变量同步/梯度聚合 |
| create_model() | 模型并行基础架构 |
| Adam(learning_rate) | 全局统一学习率控制 |
| Checkpoint() | 多设备参数保存 |
| Mean metrics | 跨设备指标聚合 |
这段代码就像给AI模型装上了三个"超能插件",让训练过程更智能、更灵活、更抗摔打:
1. 自动同步的"分身术"
就像孙悟空拔毫毛变分身,代码用MirroredStrategy给每个GPU复制一个完全相同的模型。每个GPU都是独立工作的"分身",但神奇的是:
- 数据自动切分:把训练数据像披萨一样均匀分给所有GPU(比如4块GPU就把数据切成4份)
- 梯度自动合并:每个GPU算完自己的"作业"后,系统会自动把大家的答案汇总求平均(类似小组讨论后得出统一结论)
- 参数自动同步:汇总后的结果会立刻同步到所有GPU,保证每个分身都掌握最新知识
2. 变形金刚式的"组合技"
模型像变形金刚一样能拆分重组,灵活应对不同任务:
- 模块化设计:把模型拆成不同"零件"(比如前10层放GPU1,后10层放GPU2)
- 智能分配策略:根据任务类型自动切换模式(处理图片时用数据并行,处理超大模型时切换模型并行)
- 混搭模式:可以同时使用数据并行+模型并行(就像同时开启汽车的燃油和电动双引擎)
3. 游戏存档般的"不死之身"
训练过程像打游戏一样自带存档功能:
- 自动存档:每过一关(比如每训练500步)就自动保存进度(模型参数+优化器状态)
- 断网续传:遇到突发情况(如GPU死机),能自动读取最近存档点继续训练(就像游戏断线重连后接着玩)
- 多副本保险:重要数据会在不同机器上存3个备份(类似把家门钥匙藏在3个不同地方)
(四)、热启动
if FLAGS.warm_start:
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint, starting training from beginning")
else:
tf.compat.v1.logging.info("Found checkpoint: {}".format(chk_path))
try:
checkpoint.restore(chk_path, options=options)
tf.compat.v1.logging.info("Restored checkpoint: {}".format(chk_path))
new_start = False
except:
tf.compat.v1.logging.info("Could not restore checkpoint, starting training from beginning")1. 热启动开关
if FLAGS.warm_start:- 作用:检查用户是否开启"热启动"模式(从之前的检查点继续训练)
- 类比:就像游戏里的"继续游戏"按钮,点击后可以接着上次的存档玩
- 关联技术:检查点恢复机制
2. 检查点加载配置
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")- 作用:设置检查点加载选项,指定从本地设备加载(避免分布式环境中的设备冲突)
- 技术细节:
/job:localhost表示强制从本地加载(防止多设备竞争)- 类似
MirroredStrategy的本地同步机制
3. 寻找最新检查点
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)- 功能:自动扫描检查点目录,找到最新的模型存档文件
- 运行逻辑:
- 目录中可能有多个存档文件(如
model-1000,model-2000)
- 目录中可能有多个存档文件(如
4. 检查点存在性判断
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint...")
else:
tf.compat.v1.logging.info("Found checkpoint: {}".format(chk_path))- 作用:
- 没找到存档:打印提示开始全新训练
- 找到存档:显示存档路径供调试
- 用户体验:类似游戏提示"未找到存档"或"正在加载存档:城堡副本_2023"
5. 尝试恢复检查点
try:
checkpoint.restore(chk_path, options=options)
new_start = False
except:
tf.compat.v1.logging.info("Could not restore checkpoint...")- 核心流程:
- 恢复参数:将存档中的模型权重和优化器状态加载到内存(参考
Saver.restore - 状态标记:设置
new_start=False表示不是从头开始 - 异常处理:如果存档损坏或版本不兼容,回退到全新训练
- 恢复参数:将存档中的模型权重和优化器状态加载到内存(参考
- 容错设计:
- 类似网页7提到的多节点训练容错机制
7
- 即使部分文件损坏也能保证训练继续
- 类似网页7提到的多节点训练容错机制
技术总结
| 代码段 | 对应功能 |
|---|---|
warm_start | 热启动开关 |
CheckpointOptions | 分布式环境设备配置 |
latest_checkpoint | 智能定位最新存档 |
checkpoint.restore | 模型状态恢复 |
try-except | 容错处理机制 |
通俗版解释
这段代码就像给AI训练装了个"断点续传"功能:
- 检查是否有存档 → 翻找上次玩的游戏存档
- 找到存档就加载 → 读取存档进度继续玩
- 加载失败也不慌 → 大不了重新开一局
- 自动识别最新档 → 总是选最近的存档文件
- 多设备安全加载 → 确保所有游戏机同步读档
整个过程让AI训练像下载大文件一样——断网了也能接着下载,不用重头开始!
(五)、全新训练
if new_start == True:
# Save the initial model
print("chk_name", chk_name)
print("FLAGS.checkpoint_dir", FLAGS.checkpoint_dir)
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
print("chk_path",chk_path)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))
loss_dic = {}
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))
else:
loss_dic = pickle.load(open(loss_dic_file, 'rb'))1. 训练启动模式判断
if new_start == True:- 作用:检查是否要开始全新训练(而不是继续之前的训练)
- 类比:就像打开游戏时选择"新游戏"还是"继续游戏"
- 关联技术:参考网页8的检查点恢复机制,当
new_start=False时说明已加载旧存档
2. 初始模型保存流程
# 打印调试信息
print("chk_name", chk_name)
print("FLAGS.checkpoint_dir", FLAGS.checkpoint_dir)
# 拼接检查点路径
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
print("chk_path",chk_path)- 功能:
- 输出检查点名称和保存目录(方便开发者调试路径是否正确)
- 组合完整保存路径(例如
/checkpoints/model_step0)
- 设计意图:类似网页6的模型保存日志,确保训练开始时路径正确
3. 模型保存配置
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")- 作用:指定检查点保存到本地设备(避免分布式环境中的设备冲突)
- 技术细节:参考网页4的MirroredStrategy本地同步机制,确保主节点统一保存
4. 执行模型保存
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))- 核心操作:
- 保存当前模型参数和优化器状态(如网页8的
.ckpt文件生成) - 记录保存路径日志(例如
INFO: Model saved in path: /checkpoints/model_step0-1)
- 保存当前模型参数和优化器状态(如网页8的
- 文件结构:保存后会在目录生成
.index、.data-00000等文件(如网页7描述的检查点文件)
5. 初始化训练指标记录
loss_dic = {}
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))- 功能:
- 创建空字典用于记录训练/验证损失(类似网页7的指标持久化设计)
- 将空字典序列化保存到
loss.pkl文件(为后续训练指标追加做准备)
- 设计意图:参考网页7的模型训练中断恢复方案,确保指标连续性
6. 加载历史训练指标
else:
loss_dic = pickle.load(open(loss_dic_file, 'rb'))- 作用:从之前的训练中加载历史损失数据(如网页5的断点续训指标恢复)
- 实现细节:
loss_dic可能包含train_loss_list、eval_loss_list等键值- 后续训练会继续向字典追加新数据(保持训练曲线完整)
通俗版总结
这段代码就像给AI训练装了个"存档管家":
-
全新训练时
→ 新建一个游戏存档(保存初始模型)
→ 准备空白笔记本(loss_dic)记录训练过程
→ 把存档和笔记本锁进保险箱(checkpoint_dir) -
继续训练时
→ 直接打开之前的笔记本(加载loss_dic)
→ 接着上次的进度继续写笔记
整个过程让训练像玩单机游戏一样——随时存档读档,还能查看完整的历史战绩!
(六)、训练步骤
@tf.function
def train_steps(iterator, steps, bsz, global_step):
###### Reset the states of the update variables
train_loss.reset_states()
grad_norm.reset_states()
###### The step function for one training step
def step_fn(inps, lbls, global_step):
lbls = tf.squeeze(lbls)
with tf.GradientTape() as tape:
softmax_attn_smoothing = 1. #tf.minimum(float(global_step)/FLAGS.train_steps, 1.)
logits = model(inps, softmax_attn_smoothing, training=True)[0]
if FLAGS.dataset == 'CHES20':
per_example_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(lbls, logits),
axis = 1
)
else:
per_example_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(lbls, logits)
avg_loss = tf.nn.compute_average_loss(per_example_loss, \
global_batch_size=bsz)
variables = tape.watched_variables()
gradients = tape.gradient(avg_loss, variables)
clipped, gnorm = tf.clip_by_global_norm(gradients, FLAGS.clip)
optimizer.apply_gradients(list(zip(clipped, variables)))
train_loss.update_state(avg_loss * strategy.num_replicas_in_sync)
grad_norm.update_state(gnorm)
for _ in range(steps):
global_step += 1
inps, lbls = next(iterator)
strategy.run(step_fn, args=(inps, lbls, global_step))1. 魔法加速器启动
@tf.function
def train_steps(iterator, steps, bsz, global_step):- 作用:给训练步骤装了个"涡轮增压",把Python代码转成TensorFlow计算图,速度提升10倍起步
- 类比:就像把手动挡汽车换成自动驾驶赛车
2. 数据仪表盘归零
train_loss.reset_states()
grad_norm.reset_states()- 功能:把训练损失和梯度大小的"汽车仪表盘"清零
- 原理:类似网页6提到的监控指标重置,准备记录新数据
3. 单步训练引擎
def step_fn(inps, lbls, global_step):
lbls = tf.squeeze(lbls)- 输入处理:把标签数据多余的空维度压扁(比如把[[1],[2]]变成[1,2])
- 设计意图:适配不同数据格式,类似网页2提到的数据预处理
4. 自动记录仪开启
with tf.GradientTape() as tape:
softmax_attn_smoothing = 1.
logits = model(inps, softmax_attn_smoothing, training=True)[0]- 梯度记录:像行车记录仪一样全程录像,为反向传播做准备
- 模型推理:让模型根据输入数据做预测(此时模型处于训练模式)
5. 智能计算损失
if FLAGS.dataset == 'CHES20':
per_example_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(lbls, logits),
axis = 1
)
else:
per_example_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(lbls, logits)- 多任务适配:
- CHES20数据集用sigmoid交叉熵(多标签分类,类似网页5提到的密码分析任务)
- 其他数据集用softmax交叉熵(单标签分类,类似网页1的MNIST示例)
- 技术亮点:自动切换损失函数,就像汽车自动切换四驱模式
6. 全局损失计算
avg_loss = tf.nn.compute_average_loss(per_example_loss, global_batch_size=bsz)- 分布式核心:考虑所有GPU的总批量大小计算平均损失(类似参数同步机制)
- 示例:假设4块GPU各处理64样本,实际计算的是256样本的平均损失
7. 智能防滑系统
gradients = tape.gradient(avg_loss, variables)
clipped, gnorm = tf.clip_by_global_norm(gradients, FLAGS.clip)- 梯度裁剪:防止梯度爆炸,类似给汽车安装ABS防抱死系统
- 监控指标:记录梯度大小供后续分析(类似训练状态监控)
8. 参数同步更新
optimizer.apply_gradients(list(zip(clipped, variables)))- 分布式更新:所有GPU同步更新模型参数(类似MirroredStrategy同步机制)
- 技术细节:自动处理多卡梯度聚合,就像车队统一调整行驶方向
9. 多卡数据整合
train_loss.update_state(avg_loss * strategy.num_replicas_in_sync)
grad_norm.update_state(gnorm)- 损失放大:乘以GPU数量得到真实全局损失(类似多设备指标处理)
- 示例:4块GPU各算得loss=0.1,实际记录0.4
10. 分布式执行引擎
for _ in range(steps):
global_step += 1
inps, lbls = next(iterator)
strategy.run(step_fn, args=(inps, lbls, global_step))- 流水线作业:
- 全局步数+1(类似分布式计数器)
- 获取新批次数据(类似数据管道)
- 多GPU并行执行(类似MirroredStrategy示例)
- 运行逻辑:每个GPU就像赛车手,同时处理不同数据分片
技术总结
| 代码段 | 对应分布式特性 |
|---|---|
@tf.function | 图执行加速 |
strategy.run | 多设备并行执行 |
global_batch_size | 分布式批量计算 |
strategy.num_replicas_in_sync | 设备数量感知 |
clip_by_global_norm | 梯度稳定性控制 |
通俗版工作流程
这段代码就像给AI训练装了个"智能赛车系统":
- 启动引擎:用
@tf.function把代码编译成超级加速模式 - 分发任务:把数据像披萨一样切成块分给各个GPU(
strategy.run) - 同步计算:所有GPU同时踩油门加速(
step_fn并行执行) - 统一调度:主控台(CPU)收集各GPU的运算结果,合并后更新参数
- 安全监控:实时监测梯度大小,防止"翻车"(梯度爆炸)
- 进度展示:在仪表盘(loss_dic)上显示全局训练进度
整个过程就像F1赛车队的协同作战——多辆赛车(GPU)同时奔驰,实时数据回传指挥中心(CPU),工程师(优化器)根据数据统一调整策略!
(七)、训练流
1. 训练启动广播
tf.compat.v1.logging.info('Starting training ... ')- 作用:向所有设备和开发者喊话:"训练开始啦!"
2. 数据流水线准备
train_iter = iter(train_dist_dataset)- 功能:把训练数据装进"自动分装流水线"(创建分布式数据迭代器)
- 类比:就像把披萨面团放进自动切片机,准备按批次分发给各个GPU
3. 训练进度监控器
cur_step = optimizer.iterations.numpy()
while cur_step < FLAGS.train_steps:- 作用:
cur_step是训练进度条(当前已完成多少步)- 循环条件:只要没跑完预设的总步数(比如10万步)就继续训练
4. 核心训练引擎
train_steps(train_iter, tf.convert_to_tensor(FLAGS.iterations), FLAGS.train_batch_size, cur_step)- 内部运作:
- 调用之前定义的
train_steps函数(相当于教练指挥团队训练) FLAGS.iterations是每次循环要跑的小步数(比如每次处理100批数据)- 自动处理多GPU数据分发(参考网页3的MirroredStrategy机制)
- 调用之前定义的
5. 实时数据仪表盘
cur_step = optimizer.iterations.numpy()
cur_loss = train_loss.result()
gnorm = grad_norm.result()
lr_rate = lr_sch(cur_step)
dic = {}- 监控指标:
cur_loss:当前平均损失值(类似汽车油表)gnorm:梯度大小(防止梯度爆炸的刹车系统状态)lr_rate:实时学习率(相当于油门深浅)dic是临时记事本,用来记录这些数据
6. 训练日志播报
tf.compat.v1.logging.info("[{:6d}] | gnorm {:5.2f} lr {:9.6f} | loss {:>5.2f}".format(...))- 功能:每隔几步就打印训练快报,格式示例:
[ 5000] | gnorm 2.35 lr 0.000100 | loss 0.87 - 设计亮点:类似赛车中途的实时成绩播报(参考网页6的TensorBoard监控)
7. 双重考试系统
# 训练集小考
eval_tr_iter = iter(train_dist_dataset)
eval_loss.reset_states()
eval_steps(eval_tr_iter, num_eval_iters, FLAGS.train_batch_size)
# 验证集大考
eval_va_iter = iter(eval_dist_dataset)
eval_loss.reset_states()
eval_steps(eval_va_iter, num_eval_iters, FLAGS.eval_batch_size)- 运作机制:
- 定期用部分训练数据(小考)和验证数据(大考)测试模型水平
- 每次考试前都要重置考场(
eval_loss.reset_states()) - 考试题量由
num_eval_iters控制(参考网页8的评估策略)
8. 成绩存档系统
loss_dic[cur_step] = dic- 功能:把每次考试的成绩(损失值、梯度等)记录到字典
- 后续用途:可用于绘制学习曲线(类似网页7的TensorBoard可视化)
9. 智能存档功能
if FLAGS.save_steps is not None and (cur_step) % FLAGS.save_steps == 0:
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
options = tf.train.CheckpointOptions(...)
save_path = checkpoint.save(...)
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))- 三大保障:
- 定期存档:每N步自动保存模型进度(比如每5000步存一次)
- 本地优先:强制存档到本地路径,避免多设备冲突(参考网页4的检查点策略)
- 双备份:同时保存模型参数和训练日志(就像游戏存档+录像回放)
训练循环全流程比喻
整个循环就像驾校教练教AI开车:
1. 启动引擎(初始化)
2. 每节课教100个动作(train_steps)
3. 课后小测(eval_tr_iter)
4. 月度大考(eval_va_iter)
5. 定期保存学习笔记(checkpoint)
6. 直到学满规定课时(FLAGS.train_steps)通过这种设计,模型训练就像有个智能教练在:
- 实时调整教学节奏(学习率衰减)
- 监控学员状态(梯度大小)
- 定期考核学习成果(验证损失)
- 做好学习记录(loss_dic存档)
五、验证过程
def evaluate(data, strategy, chk_name):
# Ensure that the batch size is divisible by number of replicas in sync
assert(FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0)
##### Create computational graph for model
with strategy.scope():
if FLAGS.dataset == 'CHES20':
model = create_model(4)
else:
model = create_model(256)
optimizer = tf.keras.optimizers.Adam(learning_rate=FLAGS.learning_rate)
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
if FLAGS.checkpoint_idx <= 0:
#print(FLAGS.checkpoint_dir)
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
#print("chk_path",chk_path)
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint")
return None
else:
chk_path = os.path.join(FLAGS.checkpoint_dir, '%s-%s'%(chk_name, FLAGS.checkpoint_idx))
tf.compat.v1.logging.info("Restoring checkpoint: {}".format(chk_path))
try:
checkpoint.read(chk_path, options=options).expect_partial()
tf.compat.v1.logging.info("Restored checkpoint: {}".format(chk_path))
except:
tf.compat.v1.logging.info("Could not restore checkpoint")
return None
if FLAGS.output_attn:
output = model.predict(data, steps=FLAGS.max_eval_batch)
else:
output = model.predict(data)
return output1. 数据校验关卡
assert(FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0)- 作用:确保评估时的批量大小能被GPU数量整除(比如4块GPU,批量设256,每卡分64)
- 类比:像分披萨必须切成整数块,不能有半块分给某个GPU
2. 分布式魔法圈
with strategy.scope():- 功能:在"魔法圈"内创建模型,让所有GPU都能同步参数(类似网页7提到的MirroredStrategy)
- 内部操作:
- 模型和优化器会自动适配多卡环境
- 像多个工人共享同一份设计图纸工作
3. 变形金刚工厂
if FLAGS.dataset == 'CHES20':
model = create_model(4)
else:
model = create_model(256)- 智能适配:
- 针对CHES20数据集造4输入单元的"小变形金刚"
- 其他数据集造256输入单元的"大变形金刚"
- 潜在设计:假设
create_model会构建类似Keras模型结构
4. 动力引擎安装
optimizer = tf.keras.optimizers.Adam(learning_rate=FLAGS.learning_rate)- 作用:给模型装上Adam优化器引擎(类似汽车发动机)
- 参数控制:学习率像油门深浅,通过FLAGS设置
5. 智能存档点
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)- 功能:创建存档管理器,同时保存模型参数和优化器状态
- 恢复能力:类似游戏存档,训练中断后可续档
6. 寻宝地图导航
if FLAGS.checkpoint_idx <= 0:
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
else:
chk_path = os.path.join(FLAGS.checkpoint_dir, '%s-%s'%(chk_name, FLAGS.checkpoint_idx))- 寻宝逻辑:
- 检查点索引≤0:自动找最新存档(类似自动加载最新游戏进度)
- 指定索引:按编号精确查找存档(如加载第5关存档)
- 技术细节:参考网页8的检查点恢复机制
7. 时空传送门
checkpoint.read(chk_path, options=options).expect_partial()- 安全措施:
options:强制从本地加载,防止多设备冲突(像只允许队长读档)expect_partial():允许部分恢复(比如模型升级后部分参数不加载)
8. 预测流水线
if FLAGS.output_attn:
output = model.predict(data, steps=FLAGS.max_eval_batch)
else:
output = model.predict(data)- 双模式预测:
- 开启注意力输出:限制最大批次量(防止内存爆炸)
- 普通模式:全量预测
- 底层原理:调用Keras的predict方法(类似模型调用)
技术总结表
| 代码段 | 核心功能 |
|---|---|
strategy.scope() | 分布式环境适配 |
tf.train.Checkpoint | 模型状态存档/读档 |
latest_checkpoint | 智能查找最新存档 |
model.predict | 批量推理模式 |
通俗版工作流程
这段代码就像给AI模型装了个"智能评估机器人":
- 检查装备 → 确认数据能均匀分给所有GPU(步骤1)
- 召唤分身 → 在魔法圈里复制模型到各GPU(步骤2)
- 组装模型 → 根据任务选择合适大小的变形金刚(步骤3)
- 装载引擎 → 安装优化器驱动(步骤4)
- 读取记忆 → 从指定存档恢复模型知识(步骤5-7)
- 启动检测 → 让模型批量处理数据并输出结果(步骤8)
整个过程就像:
- 多个人(GPU)拿着同一本教科书(模型参数)
- 同时批改试卷(评估数据)
- 最后把所有人的批改结果汇总成最终答案
六、main函数
def main(unused_argv):
del unused_argv # Unused
print_hyperparams()
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.INFO)
print(FLAGS.dataset)
if FLAGS.dataset == 'ASCAD':
train_data = data_utils.Dataset(data_path=FLAGS.data_path, split="train",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
test_data = data_utils.Dataset(data_path=FLAGS.data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
elif FLAGS.dataset == 'CHES20':
if FLAGS.do_train:
data_path = FLAGS.data_path + '.npz'
train_data = data_utils_ches20.Dataset(data_path=data_path, split="train",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
data_path = FLAGS.data_path + '_valid.npz'
test_data = data_utils_ches20.Dataset(data_path=data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
else:
data_path = FLAGS.data_path + '.npz'
test_data = data_utils_ches20.Dataset(data_path=data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
else:
assert False
if FLAGS.use_tpu:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
else:
strategy = tf.distribute.get_strategy()
tf.compat.v1.logging.info("Number of accelerators: %s" % strategy.num_replicas_in_sync)
if FLAGS.dataset == 'ASCAD':
chk_name = 'trans_long'
elif FLAGS.dataset == 'CHES20':
chk_name = 'trans_long'
else:
assert False
if FLAGS.do_train:
num_train_batch = train_data.num_samples // FLAGS.train_batch_size
num_test_batch = test_data.num_samples // FLAGS.eval_batch_size
tf.compat.v1.logging.info("num of train batches {}".format(num_train_batch))
tf.compat.v1.logging.info("num of test batches {}".format(num_test_batch))
train(train_data.GetTFRecords(FLAGS.train_batch_size, training=True), \
test_data.GetTFRecords(FLAGS.eval_batch_size, training=True), \
num_train_batch, num_test_batch, strategy, chk_name)
else:
num_test_batch = test_data.num_samples // FLAGS.eval_batch_size
tf.compat.v1.logging.info("num of test batches {}".format(num_test_batch))
output = evaluate(test_data.GetTFRecords(FLAGS.eval_batch_size, training=False),
strategy, chk_name)
test_scores = output[0]
attn_outputs = output[1:]
if test_scores is None:
return
if FLAGS.output_attn and not FLAGS.do_train:
nsamples = FLAGS.max_eval_batch*FLAGS.eval_batch_size
else:
nsamples = test_data.num_samples
if FLAGS.dataset == 'ASCAD':
plaintexts = test_data.plaintexts[:nsamples]
keys = test_data.keys[:nsamples]
elif FLAGS.dataset == 'CHES20':
nonces = test_data.nonces[:nsamples]
keys = test_data.umsk_keys
key_rank_list = []
for i in range(100):
if FLAGS.dataset == 'ASCAD':
key_ranks = evaluation_utils.compute_key_rank(test_scores, plaintexts, keys)
elif FLAGS.dataset == 'CHES20':
key_ranks = evaluation_utils_ches20.compute_key_rank(test_scores, nonces, keys)
key_rank_list.append(key_ranks)
key_ranks = np.stack(key_rank_list, axis=0)
with open(FLAGS.result_path+'.txt', 'w') as fout:
for i in range(key_ranks.shape[0]):
for r in key_ranks[i]:
fout.write(str(r)+'\t')
fout.write('\n')
mean_ranks = np.mean(key_ranks, axis=0)
for r in mean_ranks:
fout.write(str(r)+'\t')
fout.write('\n')
tf.compat.v1.logging.info("written results in {}".format(FLAGS.result_path))
if FLAGS.output_attn:
pickle.dump(attn_outputs, open(FLAGS.result_path+'.pkl', 'wb'))1. 程序启动与参数处理
def main(unused_argv):
del unused_argv # 删除未使用的参数(类似清理工具箱)
print_hyperparams() # 打印所有超参数(展示训练配置表)
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.INFO) # 设置日志级别为INFO(开启详细运行日志)
print(FLAGS.dataset) # 打印当前使用的数据集名称(比如ASCAD或CHES20)- 作用:初始化程序,展示关键配置信息
2. 数据加载分叉路
if FLAGS.dataset == 'ASCAD':
# ASCAD数据集加载(标准侧信道分析数据集)
train_data = data_utils.Dataset(...)
test_data = data_utils.Dataset(...)
elif FLAGS.dataset == 'CHES20':
# CHES20数据集加载(密码分析竞赛数据集)
if FLAGS.do_train:
# 训练模式加载训练+验证数据(分开两个文件)
else:
# 评估模式只加载测试数据
else:
assert False # 强制报错(防止未知数据集)- 数据特点:
- ASCAD使用标准
.npz格式,直接加载 - CHES20根据训练/评估模式选择不同数据文件(
_valid.npz为验证集)
- ASCAD使用标准
3. 分布式引擎选择
if FLAGS.use_tpu:
# TPU集群配置(谷歌云专用芯片)
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(...)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
else:
# 默认策略(单机多GPU用MirroredStrategy)
strategy = tf.distribute.get_strategy()- 策略对比:
- TPUStrategy:适合大规模并行,需连接云端TPU
- MirroredStrategy:单机多GPU同步训练(默认)
- 日志输出:显示加速器数量(如4块GPU)
4. 训练模式分支
if FLAGS.do_train:
# 计算批次数量(总样本数//批量大小)
num_train_batch = train_data.num_samples // FLAGS.train_batch_size
num_test_batch = test_data.num_samples // FLAGS.eval_batch_size
# 调用训练函数(传入分布式数据)
train(train_data.GetTFRecords(...), strategy, chk_name)
else:
# 评估模式:加载测试数据计算密钥排名
output = evaluate(...)
test_scores = output[0] # 模型预测得分
attn_outputs = output[1:] # 注意力权重(可选项)- 关键点:
GetTFRecords将数据转为TensorFlow高效读取格式- 检查点名称
chk_name根据数据集类型统一为trans_long
5. 评估结果处理
# 密钥排名计算(侧信道分析核心指标)
for i in range(100):
if ASCAD数据集:
key_ranks = 根据明文和密钥计算排名
elif CHES20数据集:
key_ranks = 根据随机数和主密钥计算排名
key_rank_list.append(key_ranks) # 保存100次计算结果
# 结果写入文件
with open(FLAGS.result_path+'.txt', 'w') as fout:
# 写入每次计算结果和平均值
np.mean(key_ranks) # 计算平均排名
# 注意力权重保存(可选功能)
if FLAGS.output_attn:
pickle.dump(attn_outputs, ...) # 保存为二进制文件- 评估逻辑:
- 密钥排名反映模型破解能力(数值越小越好)
- 多次计算取平均提高结果可靠性
- 注意力权重保存用于后续可视化分析
技术总结表
| 代码段 | 核心功能 |
|---|---|
TPUStrategy | 谷歌TPU分布式训练 |
MirroredStrategy | 单机多GPU同步训练 |
GetTFRecords | 高效数据管道构建 |
compute_key_rank | 侧信道分析评估指标 |
通俗版流程比喻
这段代码就像一个智能密码分析工厂:
- 原料质检:根据任务选ASCAD或CHES20数据集(像选择不同食材)
- 设备选择:用TPU(工业级烤箱)或多GPU(多个家用烤箱)分布式处理
- 生产模式:
- 训练模式:厨师团队(GPU/TPU)学习食谱(模型参数)
- 评估模式:质检员计算钥匙破解成功率(密钥排名)
- 质量控制:保存注意力权重(记录厨师的做菜步骤)
- 报表生成:将破解结果写入文件(生成质检报告)
通过这种设计,代码实现了:
- 自动化分布式训练(团队协作烹饪)
- 灵活适配不同数据集(多菜系兼容)
- 专业评估指标计算(密码破解效果量化)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









