






这次我要阅读的文献是轴承故障检测与诊断:基于凯斯西储大学数据集与深度学习方法的综述
原文及翻译如下:
主要内容
轴承故障检测与诊断:基于凯斯西储大学数据集与深度学习方法的综述
摘要
智能工厂作为高度数字化与互联的生产设施,其核心依赖于智能制造技术,而人工智能则是智能工厂的核心技术。机器学习与深度学习算法在图像处理、语音识别、故障检测、目标检测及医学等领域已取得显著成果。随着智能机械的普及,设备故障率预期将上升。通过多种深度学习算法实现机械故障检测与诊断的研究日益增多,其中大量工作基于开源或闭源数据集展开。在众多公开数据集中,凯斯西储大学(CWRU)轴承数据集被广泛用于机械轴承故障检测与诊断,并被视为验证模型有效性的标准基准。
本文系统梳理了近期利用CWRU轴承数据集结合深度学习算法进行机械故障检测与诊断的研究工作。通过综述已发表文献,本文各研究采用的核心算法、实验结果及其他关键细节。我们相信,本综述能为未来研究者基于CWRU数据集开展机械故障检测与诊断研究提供重要参考。
关键词:轴承,深度学习,机器学习,机械故障检测与诊断,CWRU数据集



I. 引言
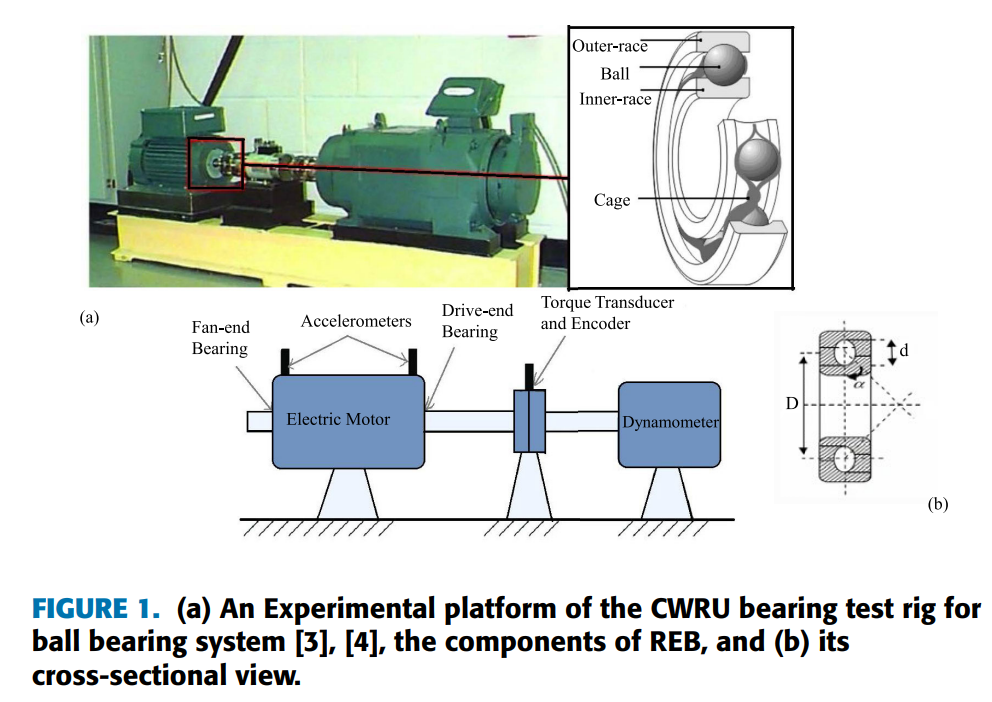
如今,电力机械在制造应用中无处不在。随着科学技术的快速发展和现代工业的进步,机械设备几乎全天候运行于各种应用场景中,有时甚至需要在不利条件(如高湿度或超负荷)下工作。这可能导致电机故障,进而引发高昂的维护费用、生产水平下降、重大经济损失甚至人员伤亡风险。旋转机械和感应电机在工业系统中扮演着关键角色,而这些旋转机械由定子、转子、轴和轴承等多个部件组成[1]。滚动体轴承(又称轴承)作为机械的核心脆弱部件,其在不同负载下的健康状态(如裂纹或故障位置)会直接影响机器的性能效率、稳定性和使用寿命[2]。滚动轴承包含四个组件:内圈、外圈、滚珠和保持架。图1展示了CWRU轴承测试台的实验平台[3][4]、轴承组件及其横截面视图。
大量研究[5][6]表明,轴承故障是导致感应电机故障的首要原因,占比高达三分之一。滚动轴承的失效是机器故障最常见的原因之一,可能引发严重的安全事故和财产损失,甚至导致机器损毁或人员伤亡[7]。因此,轴承故障检测与诊断已成为工程研发的重要领域。轴承状态监测和故障检测机制需在不中断生产线的条件下实时反映机械运行状态。
对于轴承故障机理的理解,机械振动信号被认为是最有效的信息来源之一。振动信号能够检测、定位和区分不同类型的故障[1][8]。轴承故障检测的工作流程通常包括:在机器不同位置安装传感器采集信号,将信号传输至数据采集系统进行后续处理[9]。图2(a)展示了CWRU数据集的振动数据采集过程。故障检测方法的性能不仅取决于采集的振动信号质量,还与所采用的信号处理和特征提取技术密切相关[1]。
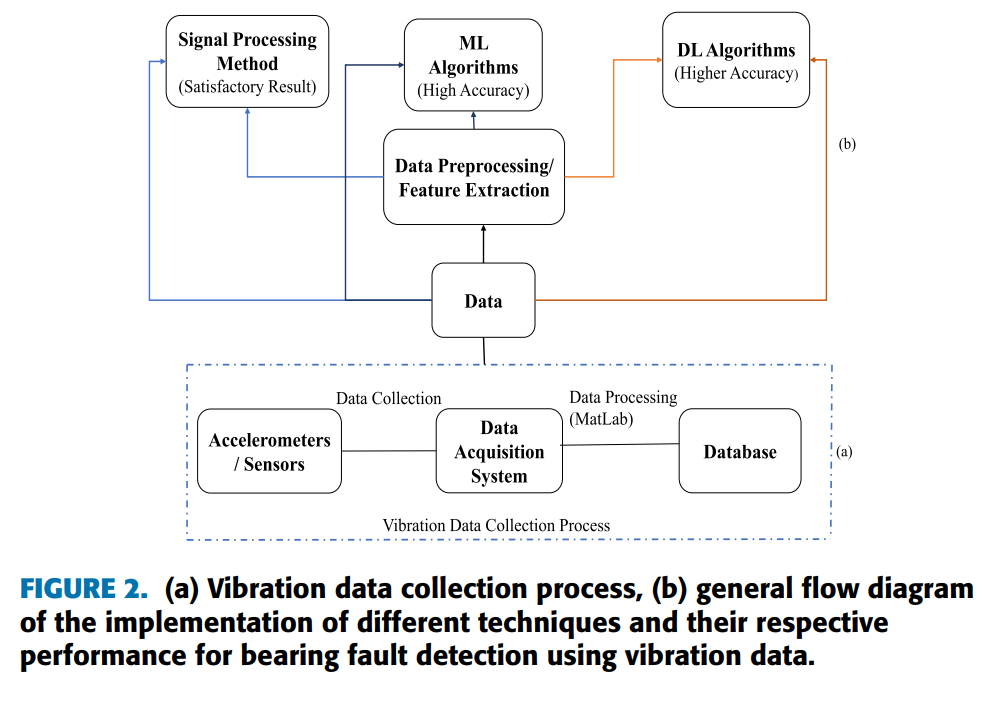
传统维护方式通常在故障发生后进行检修,这种被动维护往往导致意外停机,造成经济损失。因此,实时监测轴承健康状态至关重要。针对机械和轴承故障检测与诊断,研究者提出了多种信号处理方法、机器学习(ML)和深度学习(DL)方法。
传统信号处理方法可分为时域分析、频域分析和时频域分析。快速傅里叶变换(FFT)[11]、小波变换(WT)[12]、经验模态分解(EMD)[13]、集合经验模态分解(EEMD)[14]、经验小波变换(EWT)、小波包变换(WPT)[15]、变分模态分解(VMD)、随机共振、稀疏分解等方法已被广泛应用于故障信号分析和振动数据分类。这些方法分属时域、频域或时频域分析。
时域分析通过标量指标判断轴承状态,是最直接的轴承故障检测技术[16]。该方法通过时域振动信号数据进行分析,依据特征值评估轴承状态。常用指标包括峰值、峰峰值、均方根(RMS)、波峰因子[17]、偏度、峭度[18]、谱峭度[19]、脉冲因子、形状因子和间隙因子[20]等。频域或频谱分析则是轴承故障诊断最广泛使用的方法,通过FFT将时域振动信号转换为离散频率成分。FFT和离散傅里叶变换(DFT)算法用于分析频域原始振动信号。相较于时域分析,频域方法能更轻松检测特定频率成分[16]。
轴承振动信号兼具周期性、时不变性和非平稳性特点,推动了时频分析技术的发展。短时傅里叶变换(STFT)[21]、Wigner-Ville分布[22]和小波变换[12]等时频策略已在机械故障检测与诊断(MFDD)中得到应用。
尽管传统信号处理方法取得了可观的诊断精度,但仍存在局限性。时域分析无法确定故障具体部件;FFT分析中轴承故障频率峰值区分度不足;倒谱分析在零点附近产生大量干扰峰,影响结果判读;包络分析需预知共振频率和滤波带宽,依赖经验;小波变换存在母小波选择、分解层级和特征频带确定困难等问题[1]。此外,多数方法需针对不同振动数据人工选择特征,而人工特征可能无法最佳表征电机轴承数据,难以实现故障检测的根本性解决方案[23][24]。数据中可能存在人类难以识别的异常模式,这些特征在初期几乎无法被发现。因此,众多学者开始应用机器学习方法进行轴承故障检测。
机器学习作为人工智能的分支,教导机器高效处理数据。其工作流程可概括为:接收数据→发现模式→预测新模式[25]。在MFDD领域,基于ML的知识库系统已成功应用于缺陷早期诊断,预防灾难性故障并降低运维成本[26]。轴承故障检测中常用的ML算法包括人工神经网络(ANN)[27]、主成分分析(PCA)[28]、支持向量机(SVM)[29][30]、k近邻(k-NN)[31]和奇异值分解(SVD)[32]等。这些算法通过数据分析和学习,对轴承故障发生做出智能判断。
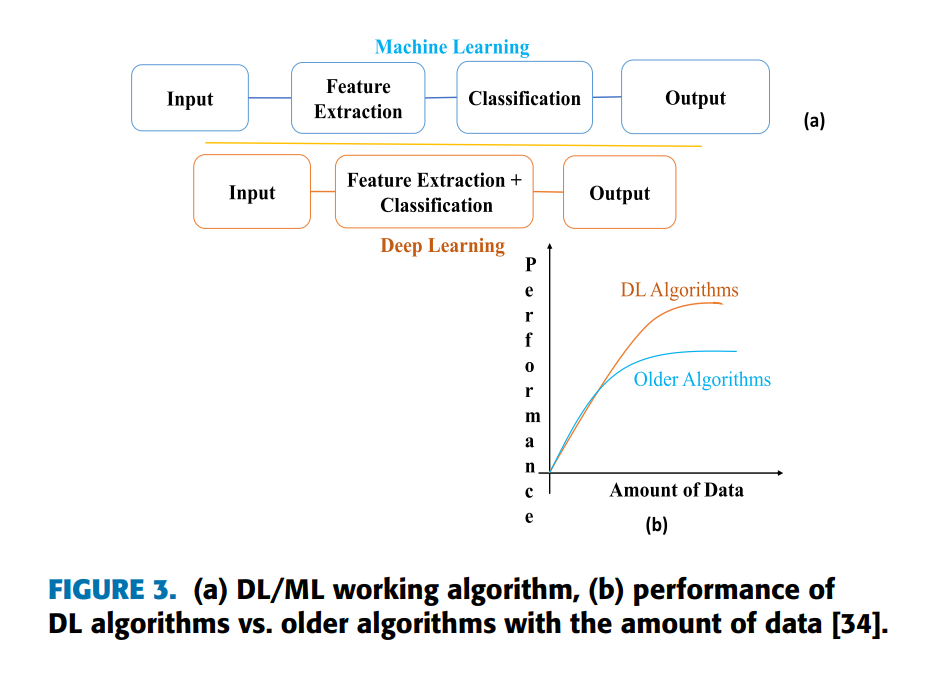
近年来,深度学习技术应用日益广泛。作为机器学习子领域,深度学习通过多级抽象实现数据表征学习,在语音识别、视觉对象识别、目标检测、异常检测等领域取得突破性进展[33]。图3展示了ML与DL的工作算法及数据量对性能的影响[34]。凭借显著优势,基于DL的方法在MFDD中的应用日益增多。图3(b)展示了使用振动数据进行轴承故障检测时不同技术的实施流程及性能对比。
本文综述采用CWRU轴承数据集、特别是驱动端(DE)缺陷数据和正常基线数据,运用深度学习算法进行机械故障检测与诊断的最新研究成果。我们系统回顾了相关文献,详细阐述了工作算法、实验结果及其他关键信息。本文可为未来研究者开展基于CWRU数据集的机械故障检测与诊断研究提供重要参考。
论文结构如下:第一节介绍机械故障、传统信号处理及ML/DL方法在轴承故障检测中的应用;第二节概述公开轴承故障数据集;第三节重点论述AE、CNN、DBN、GAN、RNN/LSTM和RL等主流DL算法;第四节探讨迁移学习和域适应方法;第五节分析CWRU数据集的不足;第六节讨论DL模型在MFDD中的挑战;第七节提出建议;第八节总结全文。



II.数据集
数据是机器学习(ML)或深度学习(DL)所有架构的基础单元。深度网络和深度学习算法作为强大的机器学习结构,其性能高度依赖于海量数据的训练[35]。在小规模训练数据集下,样本的多样性受限,网络效率会显著下降。因此,数据量和获取频率在深度学习应用中具有决定性作用。可以明确的是,每个类别充足的训练数据量将显著提升该类别的预测精度。一般而言,数据量越大,模型的准确性越高。通过丰富的样本变化,深度学习能够更好地学习数据中不同标签的结构特征,并识别出这些差异中隐含的共性模式[36]。
通常,数据集可基于复杂度分为两类:简单数据集与复杂数据集。简单数据集(常被称为优质数据集)具有以下特点:
- 便于直接使用,支持高效的统计分析与计算;
- 标签完整且分布均衡;
- 无异常值或缺失值[37]。
而复杂数据集则具备"4V"特征:
- 大容量(Volume):数据规模庞大;
- 多样性(Variety):包含结构化、半结构化和非结构化数据;
- 高速度(Velocity):数据生成和更新频率快;
- 真实性(Veracity):数据质量参差不齐[38]。
现实世界的数据往往呈现高度偏斜分布。传统分类算法基于数据平衡假设,在面对复杂不平衡数据集时,难以准确捕捉数据分布特征,导致分类结果偏向样本量较大的类别[39][40]。处理不平衡数据集的主要方法包括:
- 数据预处理:通过欠采样(减少多数类样本)或过采样(增加少数类样本)调整数据分布;
- 代价敏感学习:为不同类别样本分配差异化的误分类惩罚权重[41]。
多源数据的整合常导致数据逻辑混乱,进一步增加复杂度。数据规模亦是关键因素——通常数据量越大,处理难度越高[42]。值得注意的是,传统方法难以充分挖掘不平衡数据的特征,因此需开发通用的组织原则,而非针对单一数据类型定制解决方案[41]。
在机械故障检测领域,轴承是研究最广泛的对象,这得益于公开数据集的易获取性[43]。当前主流的开放式轴承数据集包括:
A. CWRU数据集(后文详述)
B. 帕德博恩大学数据集
C. FEMTO数据集
D. MFPT数据集
E. IMS数据集
A. CWRU 数据集
CWRU 数据集是一个广受欢迎、开源且易于访问的数据集。该数据集由凯斯西储大学(Case Western Reserve University, CWRU)记录并发布在其官网上,提供了正常轴承和故障轴承的振动数据。该数据库包含正常轴承、单点驱动端(Drive-End, DE)和风扇端(Fan-End, FE)故障的轴承数据。CWRU 轴承数据集被广泛视为验证不同机器学习和深度学习算法性能的标准参考和基础数据集。
数据采集平台
图1展示了用于获取CWRU数据集的轴承试验台装置,主要包括一台2马力的Reliance感应电机、扭矩传感器、测功机及未显示的电子控制系统。被测轴承支撑电机轴,扭矩通过测功机和电子控制系统施加。故障通过电火花加工在滚动轴承的内圈(Inner-Race, IR)、外圈(Outer-Race, OR)和滚动体上人工引入单点缺陷,故障直径分别为7密耳(0.007英寸)、14密耳、21密耳、28密耳和40密耳(1密耳=0.001英寸)。其中,7、14和21密耳直径的故障使用SKF轴承,28密耳和40密耳故障使用NTN等效轴承。除内圈0.028英寸故障、外圈0.040英寸故障及滚动体0.028英寸故障外,其余故障深度均为0.011英寸而言,内圈0.028英寸和外圈0.040英寸故障的深度为0.050英寸,滚动体0.028英寸故障深度为0.150英寸[4]。
数据采集与处理
加速度数据通过布置在轴承附近的传感器采集。数据采集使用磁吸式加速度计,分别安装在电机轴承的驱动端(DE)和风扇端(FE)的12点钟位置。部分实验中,加速度计还安装在电机支撑底板上。数据通过16通道DAT记录仪采集,并在MATLAB环境中处理,所有数据文件以MAT格式存储,每个文件包含DE、FE或底板加速度(BA)的振动数据。采样频率分别为12 kHz和48 kHz:驱动端轴承实验使用12 kHz和48 kHz采样率,风扇端数据使用12 kHz采样率,正常基线数据采样率为48 kHz。
振动数据在电机负载0至3马力、转速1720至1797 RPM的条件下记录。数据集包含不同扭矩负载下的数据文件,但轴承故障诊断中“负载”的实际意义有限,因缺乏将扭矩转换为轴承径向负载的机制。负载的主要影响在于轴速(最大负载3马力时转速下降约4%),这对数据诊断性影响较小[4][23]。
数据结构与分类
数据集包含161条记录,分为四类:48k正常基线数据、48k驱动端故障数据、12k驱动端故障数据和12k风扇端故障数据。每组数据进一步细分为滚动体故障(B)、内圈故障(IR)和外圈故障(OR)。外圈故障根据负载区位置分为三类:中心位(6点钟方向)、正交位(3点钟方向)和对位(12点钟方向)。文件名格式示例:
B007_0:滚动体故障,直径0.007英寸,负载0马力。OR014@6_1:外圈故障,直径0.014英寸,中心位,负载1马力[4]。
故障特征频率
故障轴承的振动频率与各部件旋转频率相关,具体公式如下:
- 内圈故障频率(BPFI):
BPFI=2nfr(1+Ddcosα) - 外圈故障频率(BPFO):
BPFO=2nfr(1−Ddcosα) - 保持架频率(FTF):
FTF=2fr(1−Ddcosα) - 滚动体自转频率(BSF):
BSF=2dDfr(1−(Ddcosα)2) 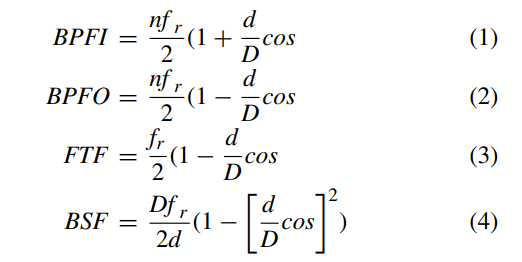
其中,fr为轴速,n为滚动体数量,d为滚动体直径,D为轴承节圆直径,α为接触角。表1和表2分别列出了CWRU数据集中轴承的物理参数和故障特征频率。
表 1 显示了 CWRU 数据集中使用的轴承信息,表 2 列出了不同的轴承故障频率,这些频率对信号处理检测故障很有帮助。
表格解释:
-
表 1:轴承信息
轴承类型 内径(英寸) 外径(英寸) 厚度(英寸) 球直径(英寸) 节径(英寸) 6205 - 2RS JEM SKF (DE) 0.9843 2.0472 0.5906 0.3126 1.537 6203 - 2RS JEM SKF (FE) 0.6693 1.5748 0.4724 0.2656 1.122 该表展示两种轴承的尺寸参数,用于计算故障频率,如内径(I.D.)、外径(O.D.)、球直径(B.D.)和节径(P.D.)。 -
表 2:轴承故障频率信息
轴承类型 故障频率(Hz,轴转速倍数) BPFI BPFO FTF BSF 6205 - 2RS JEM SKF (DE 轴承) 5.4152 3.5848 0.39828 4.7135 6203 - 2RS JEM SKF (FE 轴承) 4.9469 3.0530 0.3817 3.9874 该表列出两种轴承的故障频率,包括内圈滚珠通过频率(BPFI)、外圈滚珠通过频率(BPFO)、保持架频率(FTF)和滚珠自旋频率(BSF),反映不同故障对应的频率特征。 -
表 3:数据集长度信息
数据集 数据集长度 最大值 最小值 标准差 平均值 12k DE IR007_3: 122917 B028_0: 120801 442.59 121895.96 48k DE IR021_2: 491446 IR014_0: 63788 131280 411861.71 12k FE B014_2: 122269 OR021@3_1: 120617 354.77 121306.51 正常基线 Normal_3: 485643 Normal_0: 243938 120468 424,636.75 该表展示 CWRU 数据集四类数据的长度统计,包括最大值、最小值、标准差和平均值,体现数据集长度的多样性与复杂性,且数据长度非 2 的整数倍。
数据特点与挑战
CWRU数据集具有以下特点:
- 复杂性:数据长度不均(所示),部分记录存在非平稳特征或电气噪声干扰。
- 多样性:涵盖不同故障位置、尺寸及负载条件,但部分故障特征在频谱中不易区分。
- 标准化:作为基准数据集,其无掩蔽源的特性便于算法验证,但某些记录因机械松动或采集问题影响诊断结果[23]。
应用与局限性
尽管CWRU数据集被广泛使用,但其局限性包括:
- 负载与速度固定:数据在固定负载和转速下采集,实际工况的动态变化未被充分反映。
- 噪声与干扰:部分记录存在信号截断或传感器噪声,需预处理以提高信噪比。
- 特征选择难度:传统信号处理方法(如FFT、小波变换)需人工选择特征,而深度学习可自动提取特征,但需处理数据不平衡等问题。
该数据集为轴承故障诊断研究提供了重要基础,但在实际应用中需结合数据增强、迁移学习等技术以应对复杂工况的挑战。
B. 帕德博恩大学数据集
该数据集[44]同样用于轴承故障诊断,由帕德博恩大学KAT数据中心提供。试验台的核心组件包括驱动电机、扭矩测量轴、测试模块和负载电机。图4(b)展示了帕德博恩大学数据集试验台的机械结构。该数据集包含高分辨率振动数据,这些数据通过六组健康轴承和26组损伤轴承(其中12组为人工损伤,14组通过加速寿命试验模拟真实损伤)的试验获得[45]。该数据集为滚动轴承状态监测(CM)方法的开发、验证和训练提供了基础。试验台在不同工况下运行以确保CM方法在多变工况下的鲁棒性[44]。总计对6203型球轴承进行了32种不同损伤类型的试验。
该数据集包含同步测量的电机电流和振动信号,这使得在实际应用(即通过老化和润滑逐渐失效产生的真实缺陷场景)中更精确地测试和实施机器学习算法成为可能[2]。参考文献[45]-[48]的研究均使用了该数据集。
关键要点解析:
-
数据来源
- 由德国帕德博恩大学KAT数据中心提供
- 包含人工损伤和自然失效两种故障模式
-
试验设备
- 核心组件包括驱动电机、扭矩测量轴、测试模块和负载电机组成的试验台
- 图4(b)展示了试验台机械结构示意图
-
数据特点
- 高分辨率振动数据(12组人工损伤 + 14组加速寿命试验损伤)
- 同步采集电流信号和振动信号
- 包含32种不同类型的轴承损伤
-
应用价值
- 支持状态监测方法的开发与验证
- 通过多工况测试确保算法鲁棒性
- 特别适用于实际工业场景的算法测试
-
典型应用
- 被多篇轴承故障诊断领域的高水平研究引用(如文献[45]-[48])
C. FEMTO 数据集
FEMTO数据集[49]、[50]由法国贝桑松的FEMTO-ST研究所提供。该数据集基于PRONOSTIA实验平台生成的轴承加速寿命测试真实数据。PRONOSTIA是一个专门用于验证轴承故障检测、诊断和预后方法的实验平台[51],其主要目标是通过在线控制恒定和/或可变运行条件,提供与轴承加速退化相关的真实数据。该实验平台(如图4(a)所示)可在数小时内完成轴承退化过程能够在一周内获得大量实验数据。
PRONOSTIA测试台由三个主要部分组成:旋转部件、退化生成部件和测量部件。运行条件通过两个传感器表征:转速传感器和力传感器。在PRONOSTIA平台上,通过水平与垂直加速度计采集振动和温度信号,实现在线轴承健康监测。振动信号以25.6 kHz的采样频率每10秒记录一次,能够捕获轴承整个退化过程中的全频段信息。随后,将退化轴承的振动信号与未退化轴承的基准振动信号进行对比。传感器采集的监测数据可用于进一步处理,从而提取相关特征并持续评估轴承的健康状态。
FEMTO数据集共包含17组三种不同运行条件下的全寿命数据,但未明确声明每次测试中失效轴承的具体故障模式[52]、[53]。部分使用该数据集的研究包括:[54]-[56]。
D. MFPT 数据集
另一个用于滚动轴承故障检测与诊断的数据集是MFPT数据集[57],由机械故障预防技术协会(Society for Machinery Failure Prevention Technology)提供。该状态维护(CBM)故障数据库的目标是为轴承和齿轮提供多种已知正常与故障状态的数据集。轴承故障数据集的建立旨在促进轴承分析研究。该数据集包含来自轴承试验台的数据(包括正常轴承数据、不同负载下的外圈故障以及不同负载下的内圈故障),以及三个真实世界故障案例[57]。三个真实案例文件包括风力涡轮机中间轴轴承、风力涡轮机油泵轴轴承以及实际行星轴承故障。MFPT提供的数据使用了NICE轴承,但未描述缺陷生成过程。对于基线状态和外圈故障,提供了三种轴承负载为1201 N的测量数据;对于外圈和内圈故障,则提供了七种轴承负载范围在0-1334 N之间的测量数据[58]。该数据集免费分发并附有示例处理代码,期望研究人员和CBM从业者能够改进相关技术,从而开发更先进的CBM系统。使用该数据集进行滚动轴承故障检测的研究包括[58]-[61]。
E. IMS 数据集
该轴承数据集[62],[50]由美国辛辛那提大学智能维护系统中心(Center for Systems, IMS)提供,可从NASA预测数据仓库下载。该预测数据仓库专门收集用于开发预测算法的数据集,重点关注预测性数据集[50]。在IMS轴承数据集的采集过程中,四个测试轴承被安装在一个由交流电机驱动并通过摩擦带耦合的轴上,转速保持恒定在2000转/分钟[43]。该数据库包含三个不同子集:在第一个子集中,每个轴承安装了两个高精度加速度计;而第二和第三子集仅使用单个加速度计。每个子集数据以独立文件形式存储,每个文件包含1秒钟的振动信号快照,按特定时间间隔记录。每个文件包含20,480个数据点,采样率设置为20 kHz。文件名标识了数据采集的时间节点[62]。
部分使用该数据集的研究包括[63],[64]等。
在上述所有数据集中,凯斯西储大学(CWRU)轴承数据集作为验证机器学习(ML)和深度学习(DL)算法性能的基础数据集[23],被广泛应用于机械轴承故障分类与检测,因此被视为标准参考。本文重点综述采用CWRU数据集并运用深度学习算法进行轴承故障检测与诊断的研究工作。以下章节将详细阐述应用于轴承故障诊断的深度学习算法。








III. 基于深度学习的轴承故障诊断方法
深度学习是机器学习的一个分支,基于人工神经网络(Artificial Neural Networks, ANNs),其灵感来源于人脑神经元的功能。深度学习无需显式编程所有内容,而是通过多层处理结构使模型能够从数据中学习多层次的抽象表征。这些方法在语音识别、视觉对象识别、目标检测、异常检测等领域显著提升了技术水平。深度学习通过反向传播算法调整内部参数,利用数据特征逐层构建表征,最终实现分类或预测。与传统方法不同,深度学习能够自动从原始数据中提取特征,无需人工特征工程,因此在处理图像、视频、语音等结构化和非结构化数据时表现优异。
深度学习方法的分类
深度学习方法可进一步分为监督学习、无监督学习、半监督学习和强化学习:
-
监督学习
监督学习通过带有标签的数据训练模型,学习输入变量到输出变量的映射函数,以预测新数据的标签。典型的应用包括逻辑回归、分类和反向传播神经网络。然而,现实场景中大量数据缺乏标签,限制了监督学习的应用。 -
无监督学习
无监督学习无需标签数据,通过发现数据内在结构进行聚类、降维或异常检测。例如,自编码器(Auto-Encoders, AE)通过重构输入数据学习潜在特征,适用于无标签数据的特征提取。 -
半监督学习
半监督学习结合少量标签数据和大量无标签数据,利用监督学习提升分类精度,同时通过无监督学习挖掘数据结构。这种方法在标签数据稀缺时具有优势。 -
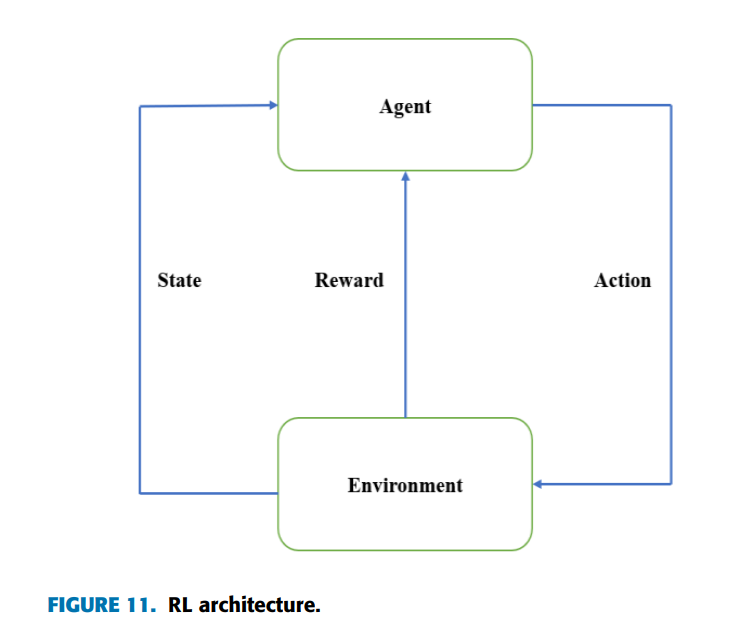
强化学习(Reinforcement Learning, RL)
强化学习通过试错机制,基于延迟奖励优化决策策略。智能体通过环境反馈调整行为,适用于序列决策问题,如机器人控制和游戏策略。
迁移学习与领域适应
传统机器学习模型通常针对孤立任务设计,而迁移学习(Transfer Learning)通过将源任务的知识迁移到目标任务,提升模型在目标域的表现。领域适应(Domain Adaptation)是迁移学习的子领域,专注于减少源域(训练数据分布)与目标域(测试数据分布)之间的差异。例如,通过对抗训练(Adversarial Training)或最大均值差异(Maximum Mean Discrepancy, MMD)等方法,模型可以学习跨域不变特征,增强泛化能力。
深度学习在轴承故障诊断中的优势
轴承故障诊断的核心挑战在于振动信号的非平稳性和复杂背景噪声。传统信号处理方法(如傅里叶变换、小波分析)依赖人工特征提取,而深度学习能够直接从原始信号中学习故障特征,避免了特征工程的繁琐。此外,深度模型(如卷积神经网络、深度信念网络)通过分层抽象,可捕捉故障的细微差异,提升诊断精度。
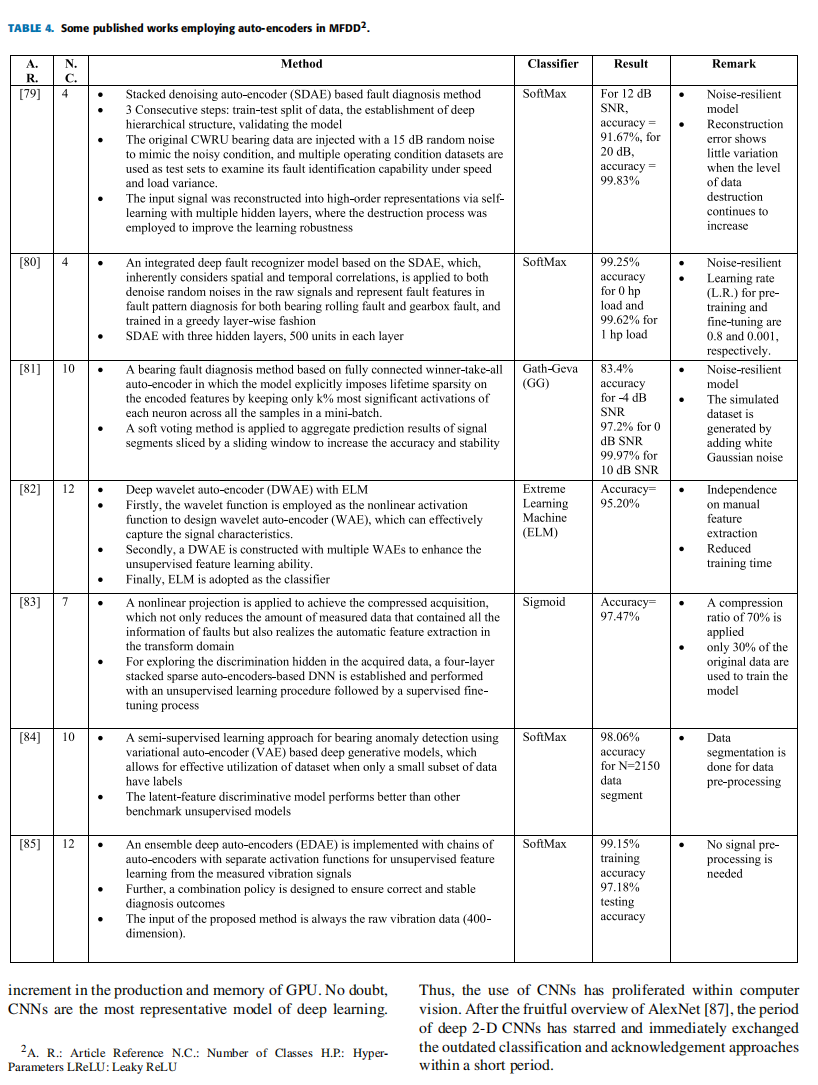
A. 自动编码器与改进的自动编码器
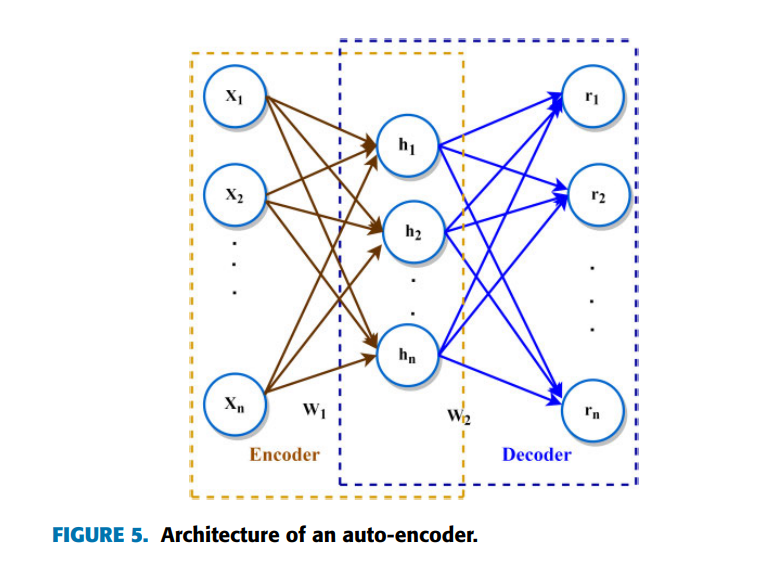
自动编码器(Auto-Encoder, AE)是一种广泛采用的无监督学习模型,其训练目标是将输入复制到输出。其内部包含一个隐藏层 h,用于编码输入数据的特征。网络由编码器函数 h=f(x) 和解码器 g(h) 组成,后者生成重构结果 r=g(h)。如图5所示,输入向量 x 通过权重矩阵 W1 映射到隐藏层 h,再通过 W2 重构为输出 r。训练时,通过最小化输入与输出的均方误差(MSE)学习特征表示,最终保留编码器部分作为后续分类器的特征提取器。
典型研究与改进方法
-
F. Jia 等人的工作(2016)[75]
- 方法:采用5层自动编码器构建深度神经网络(DNN),通过逐层无监督预训练和反向传播微调实现故障分类。
- 优势:自动提取故障特征,建立非线性映射关系,对CWRU数据集10类故障的分类准确率达 99.68%-99.95%,优于传统BPNN方法。
- 验证:通过PCA验证模型性能。
-
堆叠去噪自动编码器(SDAE)[79]
- 方法:在原始数据中注入15 dB随机噪声模拟复杂工况,通过多层SDAE学习鲁棒特征。
- 结果:在12 dB信噪比下准确率 91.67%,20 dB下提升至 99.83%。
- 特点:对噪声具有强鲁棒性,重构误差随噪声增强变化小。
-
深度小波自动编码器(DWAE)[82]
- 方法:将小波函数作为激活函数构建小波自动编码器(WAE),堆叠为DWAE增强特征学习能力,结合极限学习机(ELM)分类。
- 结果:分类准确率 95.20%,减少人工特征提取依赖。
- 优势:训练时间短,适用于高频信号特征提取。
-
半监督变分自动编码器(VAE)[84]
- 方法:利用少量标签数据,通过VAE生成模型进行半监督异常检测。
- 结果:在2150个数据段上准确率达 98.06%。
- 应用:适用于标签稀缺场景,提升小样本学习效率。
-
集成深度自动编码器(EDAE)[85]
- 方法:采用多激活函数链式自动编码器,设计组合策略提升诊断稳定性。
- 结果:训练准确率 99.15%,测试准确率 97.18%。
- 特点:无需信号预处理,直接处理原始振动数据(400维)。
表格4 基于自动编码器的轴承故障诊断研究摘要
| 文献 | 类别数 | 方法 | 分类器 | 结果 | 备注 |
|---|---|---|---|---|---|
| [79] | 4 | 堆叠去噪自动编码器(SDAE) | SoftMax | 12 dB SNR下91.67%,20 dB下99.83% | 抗噪声模型,重构误差稳定 |
| [80] | 4 | 集成深度故障识别器(SDAE) | SoftMax | 0 hp负载下99.25%,1 hp下99.62% | 学习率动态调整,抗噪性强 |
| [81] | 10 | 全连接Winner-Take-All自动编码器 | Gath-Geva | 10 dB SNR下99.97% | 白噪声模拟数据集,稀疏激活 |
| [82] | 12 | 深度小波自动编码器(DWAE)+ ELM | ELM | 95.20% | 减少人工特征依赖,训练高效 |
| [83] | 7 | 压缩感知+稀疏自动编码器 | Sigmoid | 97.47% | 数据压缩率70%,仅用30%原始数据 |
| [84] | 10 | 变分自动编码器(VAE)半监督学习 | SoftMax | 98.06%(N=2150) | 小标签数据高效利用 |
| [85] | 12 | 集成深度自动编码器(EDAE) | SoftMax | 训练99.15%,测试97.18% | 无需预处理,多激活函数融合 |
技术优势与挑战
- 优势:自动编码器能够无监督学习数据的高维特征,适用于复杂振动信号的特征提取,对噪声和缺失数据具有鲁棒性。
- 挑战:需设计合适的网络深度和激活函数,预训练过程计算成本较高,且对异常样本敏感。
核心总结
自动编码器及其改进模型通过无监督学习有效提取轴承振动信号的特征,结合分类器(如SoftMax、ELM)实现高精度故障诊断。改进方法如去噪、小波变换和半监督学习进一步提升了模型在噪声环境和小样本场景下的性能,为工业轴承健康监测提供了可靠解决方案。
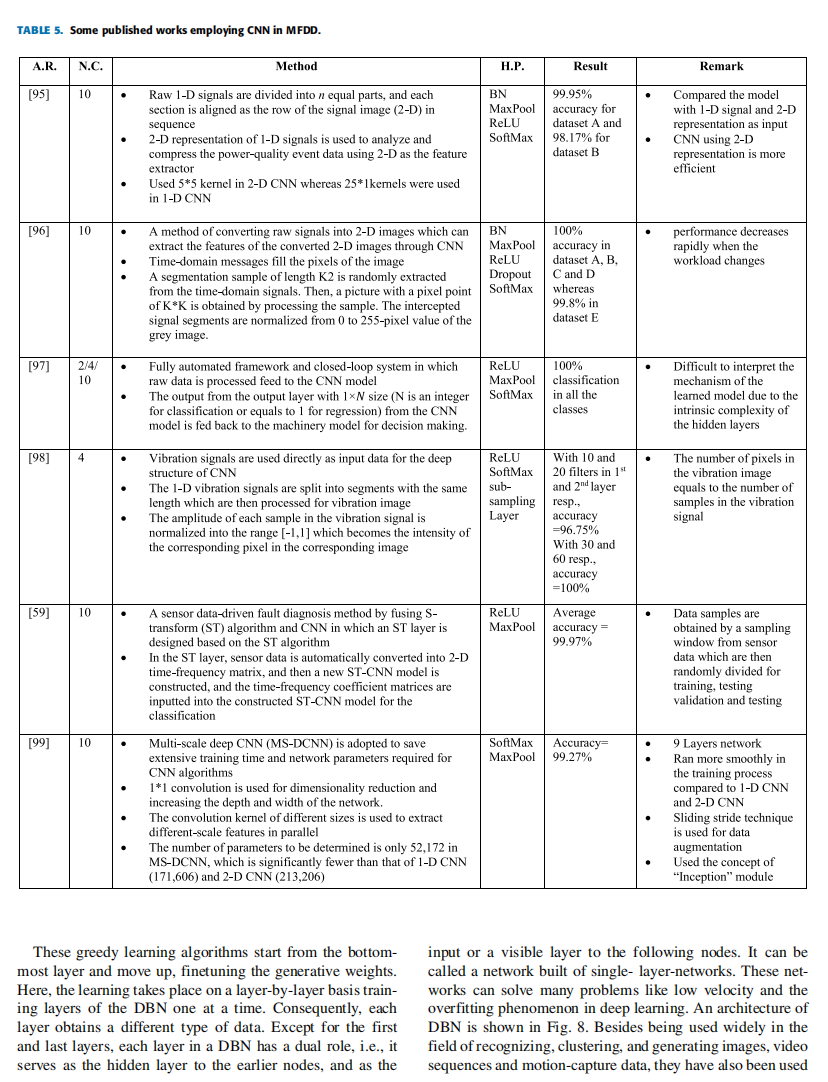
B. 卷积神经网络(CNN)
自LeCun首次提出用于图像处理的CNN以来,其在计算机视觉、目标检测、自然语言处理和语音识别领域的性能提升显著。随着GPU性能与内存的飞速发展,CNN已成为深度学习中最具代表性的模型。特别是AlexNet的突破性成果引领了深度二维CNN的时代,迅速替代了传统的分类与识别方法。
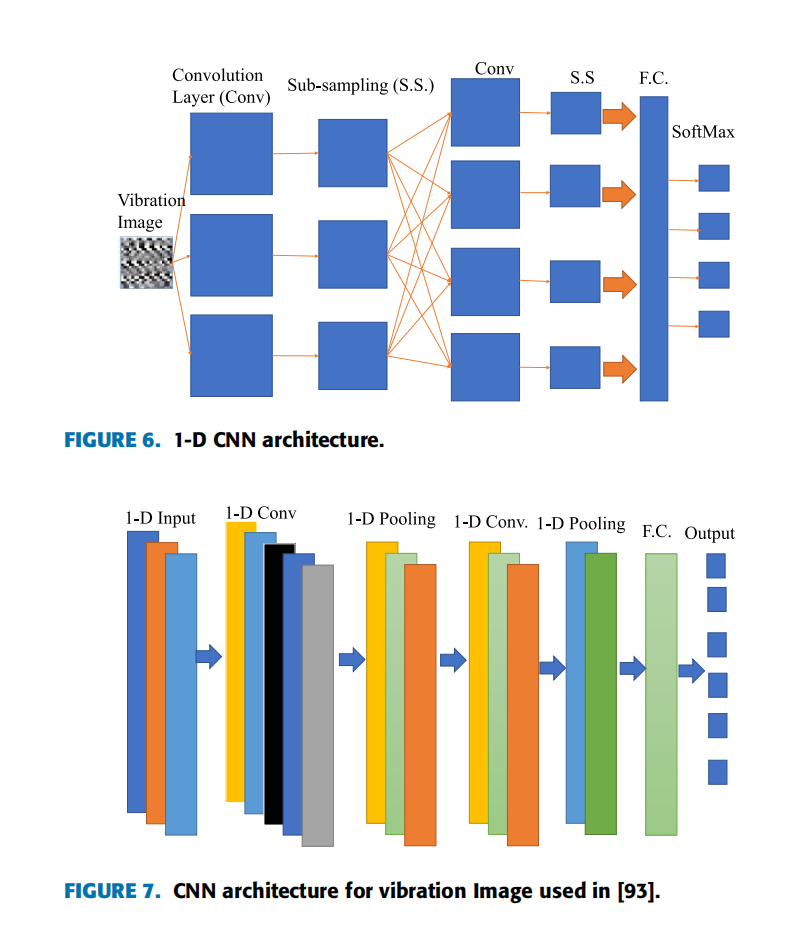
一维CNN(1D CNN)作为二维CNN的改进版本,其前向传播(FP)和反向传播(BP)通过数组运算而非矩阵运算实现,使其在处理一维信号任务中更具效率。此外,1D CNN的浅层结构使其能够有效学习复杂的一维信号任务,并适用于实时应用。图6和图7分别展示了二维和一维CNN的基本结构。近年来,CNN在轴承故障检测中的应用逐渐增多,以下简要介绍基于CWRU数据集的研究案例。
研究案例
-
自适应深度卷积神经网络(ADCNN)
[88]提出了一种分层自适应深度卷积神经网络,包含故障判定层和故障尺寸评估层。该模型基于经典LeNet5架构,动态调整学习率以平衡训练速度与精度。使用9层网络结构,批量大小为100,分类层采用SoftMax。实验结果表明,对4类(1类健康轴承,3类故障轴承)的分类准确率达97.7%。 -
多传感器融合的CNN方法
[89]提出一种结合驱动端和风扇端原始时空数据的CNN模型。将一维振动数据转换为二维输入矩阵,直接输入CNN进行特征学习,无需手工特征提取。训练中采用小批量随机梯度下降和Dropout防止过拟合。实验使用9类数据(70%训练,15%验证,15%测试),双传感器融合的平均准确率达99.41%,优于单传感器的98.35%。 -
数据增强与残差学习
[90]提出基于数据增强和残差学习的智能诊断方法。通过添加高斯噪声、掩码噪声、信号平移等五种数据增强技术扩充数据集,结合一维卷积层和残差块提取特征。模型在10类CWRU数据上达到99.91%的准确率,展示了数据增强对提升模型鲁棒性的有效性。
其他研究总结
表5列出了更多基于CNN的研究方法,包括:
- 二维信号表示:将一维信号分段转换为二维图像输入CNN([95]),在CWRU数据上实现99.95%的准确率。
- 多尺度深度CNN(MS-DCNN):通过不同尺寸卷积核并行提取多尺度特征([99]),参数规模较传统CNN显著减少,训练效率更高。
- S变换与CNN融合:结合S变换层生成时频矩阵作为输入([59]),平均准确率达99.97%。
关键技术与挑战
- 输入处理:多数研究直接使用原始振动信号,通过归一化(如[-1, 1]范围)或时频转换(如FFT、小波变换)预处理数据。
- 网络架构:常见结构包括卷积层、池化层(MaxPool)、批归一化(BN)和Dropout层,分类层多采用SoftMax。
- 性能优化:数据增强、残差连接、动态学习率调整等技术被广泛用于提升模型泛化能力。
结论
CNN凭借其自动特征提取和高精度分类能力,成为轴承故障诊断的核心方法。结合数据增强、多传感器融合和新型网络架构(如残差网络、多尺度卷积),CNN在处理复杂振动信号时展现出显著优势。未来的研究方向可能包括轻量化模型设计、跨域适应技术以及结合迁移学习的泛化能力提升。
表5. 部分采用CNN的机械故障检测与诊断(MFDD)研究
| 文献编号 | 类别数 | 方法 | 超参数 | 结果 | 备注 |
|---|---|---|---|---|---|
| [95] | 10 | • 将原始一维信号等分为n段,每段按顺序排列为二维信号图像 • 使用5×5卷积核的二维CNN分析电能质量事件数据,并与一维CNN对比 • 通过自学习多层次隐藏层重构高维特征,破坏过程增强学习鲁棒性 | BN MaxPool ReLU SoftMax | 数据集A准确率99.95% 数据集B准确率98.17% | • 二维信号表示的CNN效率更高 • 二维输入减少了参数需求 |
| [96] | 10 | • 将时域信号转换为K×K像素的灰度图像 • 随机截取长度为K²的信号段,归一化为0-255像素值 • 通过CNN提取二维图像特征 | BN MaxPool ReLU Dropout SoftMax | 数据集A-D准确率100% 数据集E准确率99.8% | • 工况变化时性能显著下降 • 保留所有原始时序信息 |
| [97] | 2/4/10 | • 全自动闭环诊断框架,原始数据直接输入CNN模型 • 输出层反馈至机械模型进行决策优化 • 输出层维度可配置(分类N类或回归) | ReLU MaxPool SoftMax | 所有类别均达100%分类 | • 隐藏层机制解释性不足 • 支持分类与回归任务 |
| [98] | 4 | • 振动信号等长分段后生成振动图像 • 归一化采样点幅值至[-1,1]作为像素强度 • 图像像素数等于原始信号采样点数 | ReLU SoftMax 二次采样层 | 30+60滤波器组合达100%准确率 10+20组合准确率96.75% | • 无需特征工程 • 滤波器数量影响特征提取能力 |
| [59] | 10 | • 融合S变换与CNN的传感器数据诊断方法 • 设计S变换层自动生成时频矩阵 • 时频系数矩阵输入定制ST-CNN模型 | ReLU MaxPool | 平均准确率99.97% | • 滑动窗口生成训练样本 • 随机划分训练/验证/测试集 |
| [99] | 10 | • 多尺度深度CNN(MS-DCNN)采用并行多尺寸卷积核 • 使用1×1卷积降维,增加网络深度 • 参数量(52k)显著低于1D-CNN(171k)和2D-CNN(213k) | SoftMax MaxPool | 准确率99.27% | • 9层网络结构 • 采用滑动步长数据增强 • 引入"Inception"模块思想 |
C. 深度信念网络
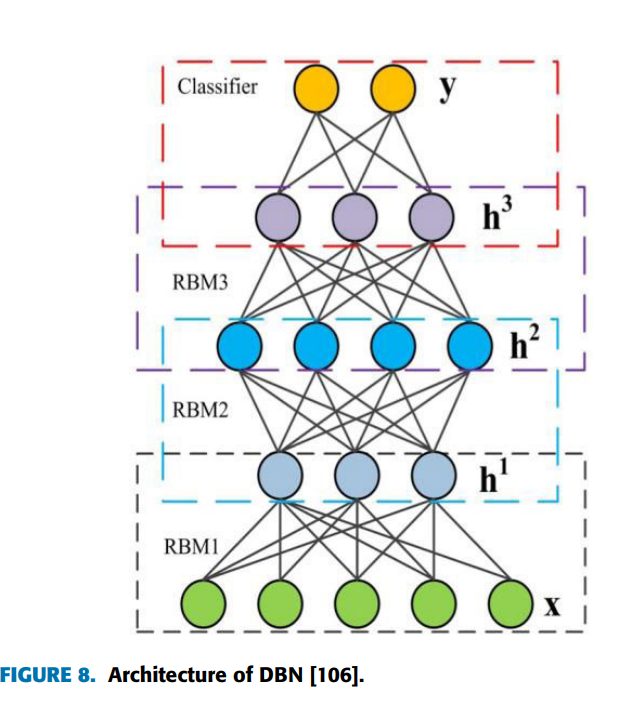
深度信念网络(Deep Belief Networks, DBN)最初由Hinton等人于2006年提出[100],是一种由多层受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)组成的网络架构。在DBN中,每一层RBM与相邻层进行交互,但层内神经元无连接。与传统神经网络不同,DBN通过逐层贪婪训练策略解决多层感知机(MLP)易陷入局部最优的问题,其分层结构能够捕捉输入数据的高阶非线性特征。DBN的最后一层通常用于分类任务,而中间层则通过无监督学习自动提取数据的抽象特征。
关键研究案例
-
自适应DBN与双树复小波包变换(DTCWPT)结合[101]
该研究提出一种改进的自适应DBN,通过堆叠多层自适应RBM提升模型收敛速度和诊断精度。原始振动信号首先经过DTCWPT预处理以增强故障特征,随后从分解后的频带信号中提取9个时域特征参数(如峰度、能量等),并输入自适应DBN进行分类。实验表明:- 在72-400-250-100-16的DBN架构下,测试准确率达94.37%。
- 相较于传统方法(如EEMD和BP神经网络),自适应DBN在特征学习能力和鲁棒性方面表现更优。
-
多传感器信息融合与D-S证据理论[102]
该研究设计了一种结合DBN与Dempster-Shafer(D-S)证据理论的多传感器融合诊断方法:- 分别在驱动端(DE)和风扇端(FE)布置传感器,通过DBN提取各传感器信号的特征。
- 使用SoftMax分类器进行初步分类后,利用D-S理论融合两传感器的决策结果。
- 实验结果显示,该方法在4种轴承健康状态下的诊断准确率达100%,且在负载变化时无需重新训练模型。
- 在噪声环境下(如SNR=0 dB),模型仍保持98.5%的准确率,验证其强抗干扰能力。
其他重要研究
-
希尔伯特包络谱与DBN结合[109]
通过希尔伯特变换获取振动信号的包络谱,直接作为DBN的输入特征向量。实验表明,当隐藏层神经元数量增至100时,分类准确率提升至99.55%,证实深层网络对复杂非线性关系的建模优势。 -
优化DBN结构[110]
采用粒子群优化(PSO)算法确定DBN最优结构(18-57-38-25-10),在CWRU数据集上平均准确率达89.2%。研究强调时域特征需分阶段提取,以平衡数据长度与统计特性。 -
分层深度网络(HDN)[113]
构建两层DBN网络:第一层识别故障类型,第二层评估故障严重程度。结合小波包能量特征,模型在三层RBM训练后达到99.03%的准确率,验证分层诊断的有效性。
技术优势与挑战
- 优势:
- 无需手工特征工程,自动学习数据的高阶抽象表示。
- 通过无监督预训练缓解梯度消失问题,提升模型泛化能力。
- 挑战:
- 训练时间较长,尤其在处理高维特征时计算成本较高。
- 对输入数据的平稳性敏感,需结合预处理方法(如DTCWPT)提升特征质量。
总结
深度信念网络通过分层特征学习和自适应优化机制,在轴承故障诊断中展现出强大的模式识别能力。结合信号预处理技术与多传感器融合策略,DBN能够有效应对复杂工况下的诊断挑战,为工业设备智能运维提供了可靠解决方案。
表6. 采用深度信念网络(DBN)的机械故障检测与诊断研究
| 文献 | 类别数 | 方法 | 超参数 | 结果 | 备注 |
|---|---|---|---|---|---|
| [109] | 10 | ● 基于希尔伯特包络谱和DBN的故障诊断方法: 1. 对振动信号进行重采样,提取其希尔伯特包络谱作为特征向量; 2. 构建DBN分类器模型识别轴承故障类型。 | Sigmoid激活函数 | 隐藏单元数为100时,准确率=99.55% | ● 隐藏单元数越多,模型对故障类型与特征间非线性关系的表征能力越强。 |
| [110] | 10 | ● 优化DBN架构: 1. 使用随机梯度下降(SGD)微调受限玻尔兹曼机(RBM)权重; 2. 粒子群优化(PSO)确定DBN最优结构(18-57-38-25-10)。 | 学习率=0.23 动量=0.86 | 数据集A平均准确率=89.2%,数据集B=90.7% | ● 需分阶段提取时域特征,平衡数据长度与统计特性。 |
| [111] | 4 | ● 基于DBN的编码器: 1. 通过堆叠RBM构建DBN,最小化输入与重构输出的能量差; 2. 对比DBN与HHT、FFT、小波变换的计算效率。 | Sigmoid激活函数 | 准确率=96.67% | ● DBN计算时间短于HHT和FFT,但长于小波变换。 |
| [112] | 10 | ● 改进集成方法: 1. 构建多组超参数不同的DBN,通过对比散度(CD-k)算法训练; 2. 利用权重矩阵融合分类结果。 | DBN1-5:Sigmoid DBN6-10:ReLU | 准确率=84.2% | ● 无预处理,直接对原始振动数据归一化。 |
| [113] | 10 | ● 分层深度网络(HDN): 1. 第一层识别故障类型,第二层评估故障严重程度; 2. 结合小波包能量特征优化分类器。 | Sigmoid激活函数 | 准确率=99.03% | ● 包含3层RBM,训练时采用小批量数据划分。 |
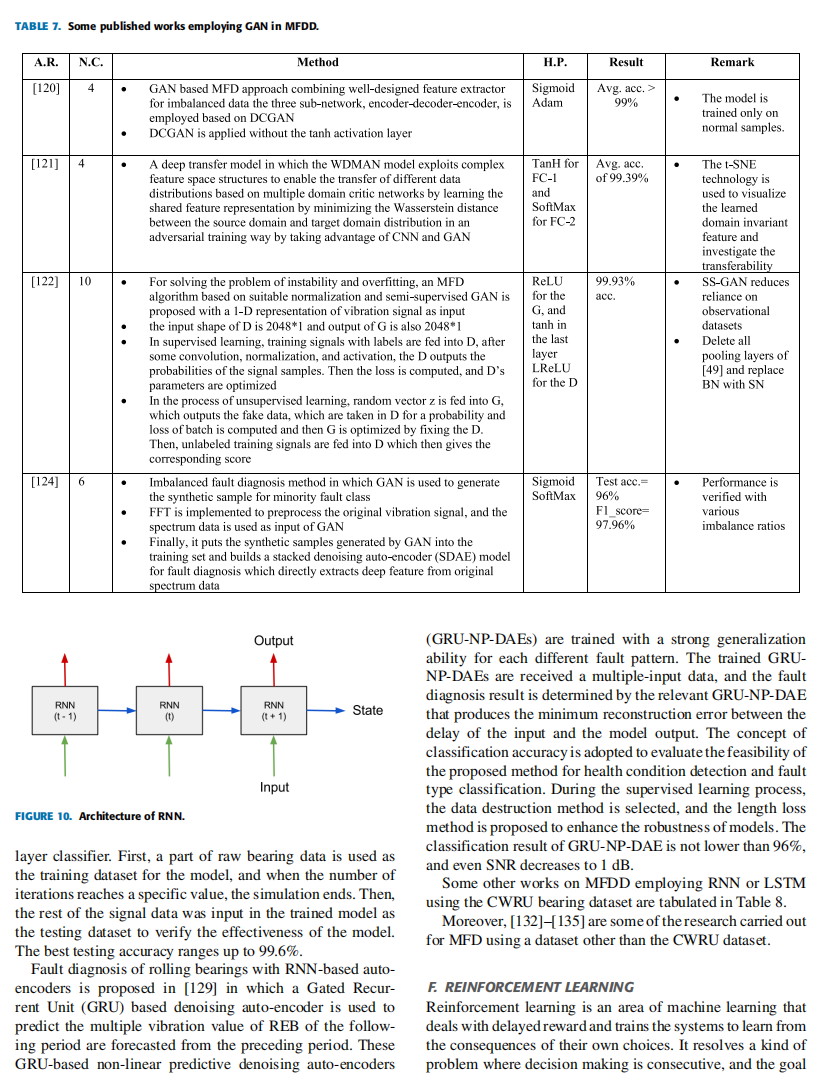
D. 生成对抗网络
生成对抗网络(GANs)是一种由两个相互竞争的神经网络组成的深度神经网络结构,属于生成模型的一种,能够生成新内容。它们通常以随机噪声为输入并生成输出样本。GANs最初由Ian Goodfellow等研究者在2014年提出[114],其核心是生成器(G)和判别器(D)通过以下极小极大博弈进行对抗训练,目标函数为:
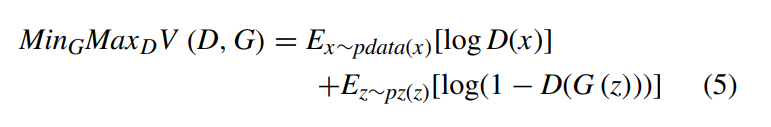
生成器(G) 的目标是生成与真实数据分布尽可能接近的样本,使得判别器无法区分真实样本与生成样本。判别器(D) 则是一个二元分类器,负责判断输入是来自真实数据还是生成器。通过对抗训练,生成器的生成能力和判别器的鉴别能力逐步提升,最终达到纳什均衡(Nash equilibrium),即判别器无法区分两类样本(D(x)=1/2)。
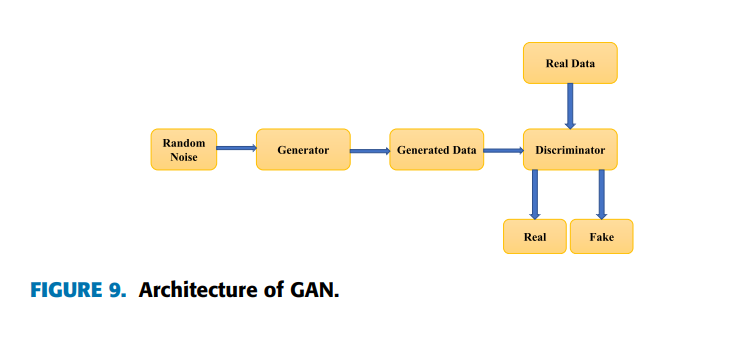
GANs在轴承故障诊断中的应用
以下研究展示了GANs在基于CWRU数据集的轴承故障检测中的应用:
-
基于Wasserstein距离的深度迁移学习(WD-DTL)[13]
- 方法:提出一种结合Wasserstein距离的深度迁移学习模型,通过对抗训练最小化源域(source domain)和目标域(target domain)的分布差异。使用CNN作为特征提取器,并采用频域预处理(FFT)处理振动信号。
- 结果:在三种迁移场景(速度迁移、传感器位置迁移)中,模型平均准确率达到95.75%。
- 备注:通过对抗训练实现域不变特征提取,适用于不同工况下的迁移任务。
-
分类对抗自编码器(CatAAE)[118]
- 方法:设计一种结合自编码器和对抗训练的模型(CatAAE),在潜在空间引入分类器进行无监督聚类。提取时频域特征(如FFT和统计特征)以提高鲁棒性。
- 结果:在原始信号和噪声(0 dB SNR)条件下,聚类指标分别为98.36和94.35;跨负载条件下平均指标为90.15。
- 备注:依赖时频域特征,但对噪声和负载变化具有较强适应性。
-
全局优化GAN(GO-GAN)[119]
- 方法:针对数据不平衡问题,设计生成器生成故障特征而非原始数据,判别器结合两级分类(真实性与故障类别)。通过交替优化生成器和判别器实现全局优化。
- 结果:在10:1不平衡比例下,内圈、滚珠、外圈故障的诊断准确率分别为94.58%、96.85%、93.28%,显著优于传统SAE模型。
- 备注:生成器优化以提升故障诊断效果,适用于小样本不平衡场景。
其他研究案例
-
深度卷积GAN(DCGAN)[120]
使用三子网络(编码器-解码器-编码器)结构,生成器基于DCGAN框架,仅用正常样本训练,实现高精度异常检测(平均准确率>99%)。 -
多域对抗网络(WDMAN)[121]
通过多域判别网络最小化Wasserstein距离,结合CNN和对抗训练,实现跨域特征对齐,平均准确率达99.39%。 -
半监督GAN(SS-GAN)[122]
将1D振动信号直接输入GAN,结合谱归一化(SN)和批量归一化(BN),减少对标记数据的依赖,测试准确率达99.93%。
关键挑战
- 纳什均衡的稳定性:GAN训练中需平衡生成器与判别器的能力,避免模式崩溃(mode collapse)。
- 数据质量与不平衡:实际故障数据稀缺且不平衡,需结合迁移学习或数据增强(如过采样、合成样本生成)提升模型鲁棒性。
总结
GANs通过对抗机制生成逼真样本或提取域不变特征,在轴承故障诊断中展现出处理不平衡数据、跨域迁移和噪声鲁棒性的潜力。结合频域预处理(如FFT)和深度架构(如CNN),能够有效提升故障分类精度,适用于工业场景中的复杂工况。
E. 循环神经网络(RNENT NEURAL NETWORKS)
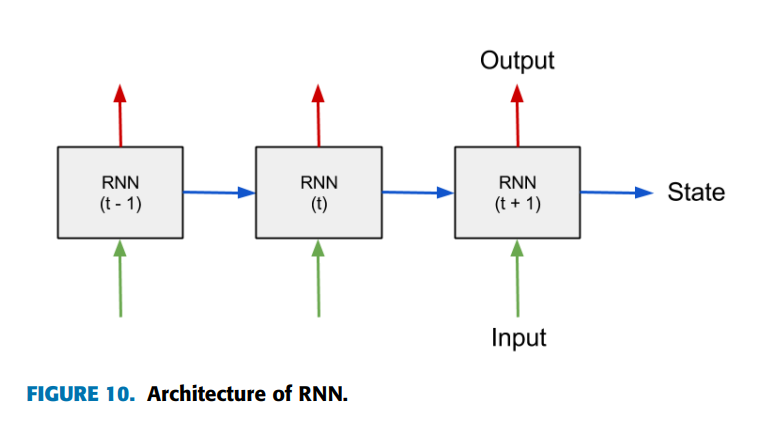
循环神经网络(RNNs)是一类允许先前输出作为输入处理的神经网络,同时具有隐藏状态。它们能够记忆过去信息,其决策受先前学习状态的影响。由于RNN存在典型的梯度消失或爆炸问题,长短期记忆网络(LSTM)应运而生。LSTM(Long Short-Term Memory)是当前广泛应用的网络结构,其单元从前一状态和当前状态接收输入。不仅在自然语言处理、文本识别或语音识别领域,RNN在机械故障检测与诊断中也得到了广泛应用。图10展示了LSTM网络的基本架构。
在文献[128]中,作者提出了一种结合一维CNN和LSTM的统一结构改进方法,直接以原始采样信号作为输入,无需任何预处理或传统特征提取。该架构由一维卷积层、最大池化层、LSTM层和SoftMax分类层组成。首先使用部分原始轴承数据训练模型,当迭代次数达到特定值后,将剩余信号数据输入训练好的模型进行测试验证,最高测试准确率达到99.6%。
文献[129]提出了一种基于GRU(Gated Recurrent Unit)去噪自编码器的滚动轴承故障诊断方法。通过GRU非线性预测去噪自编码器(GRU-NP-DAEs)预测后续时间段的振动值,每个故障模式对应一个GRU-NP-DAE模型。分类结果由重构误差最小的模型确定。在监督学习过程中,采用数据破坏法和长度损失法增强模型鲁棒性。即使在1 dB信噪比下,分类准确率仍不低于96%。
表8总结了其他采用RNN/LSTM的CWRU轴承故障诊断研究:
| 文献 | 类别数 | 方法 | 超参数 | 结果 | 备注 |
|---|---|---|---|---|---|
| [130] | 12 | • 改进的深度循环神经网络(DRNN)采用堆叠循环隐藏层和LSTM单元 •MSE损失函数和SGD优化器 • 采用自适应学习率提升训练性能 | SGD | 平均测试准确率96.53% | • 使用频谱序列作为输入以减少数据维度 |
| [131] | 10 | • 结合空洞卷积、LSTM输入门结构和ResNet的堆叠残差空洞CNN(SRDCNN) • 空洞卷积扩大感受野,ResNet缓解梯度消失问题 | SoftMax | 99.7% | • 残差空洞卷积层使样本长度减半 • 空洞卷积处理长样本冗余信息 |
其他相关研究(使用非CWRU数据集)包括[132]-[135]。
F. 强化学习(REINFORCEMENT LEARNING)
强化学习(RL)通过延迟奖励机制训练系统从决策结果中学习,适用于序列决策问题。其框架包含控制器和子模型:控制器生成网络架构参数,子模型性能作为奖励反馈优化控制器参数。文献[138]提出基于强化学习的神经网络架构自动搜索方法,使用CWRU 12kHz数据验证,12类故障状态下获得98.47%准确率。表9详述了该方法的关键信息:
| 文献 | 类别数 | 方法 | 分类器 | 结果 | 备注 |
|---|---|---|---|---|---|
| [138] | 12 | • 控制器生成CNN架构参数,子模型准确率作为奖励优化控制器 • 基于策略梯度法更新参数 | SoftMax | 98.47% | • 搜索空间广阔,易陷局部最优解 |
文献[139]则采用基于峭度的RL指标进行故障诊断(使用非CWRU数据集)。
关键要点总结:
- 架构创新:LSTM与1D CNN结合可直接处理原始振动信号,无需手工特征提取。
- 抗噪能力:GRU-NP-DAEs在低信噪比(1dB)下仍保持高准确率,凸显模型鲁棒性。
- 自动化设计:强化学习实现了网络架构的自动优化,但需解决搜索空间过大导致的局部最优问题。
- 计算效率:SRDCNN通过空洞卷积和残差结构平衡了长序列处理与计算效率。
这些进展表明,循环神经网络及其变体在轴承故障诊断中展现出强大的时序建模能力,特别是在处理非平稳信号和复杂工况适应方面具有显著优势。未来的研究可进一步探索网络结构的轻量化设计,以及多模态传感器数据的融合策略。


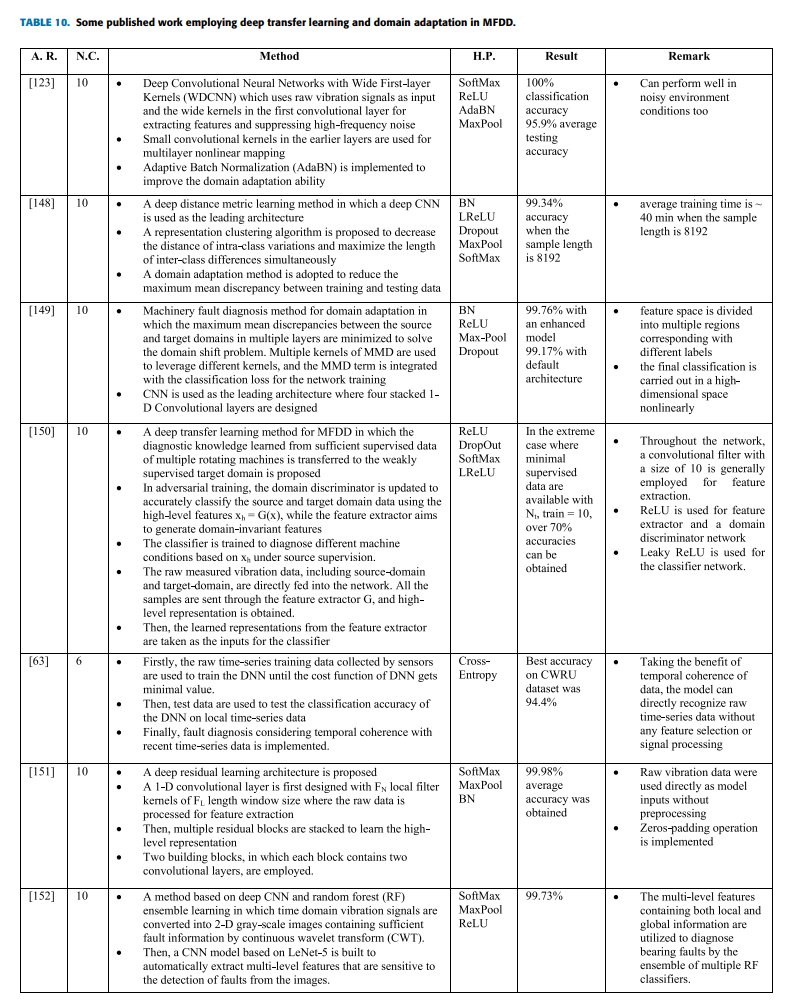


IV. 深度迁移学习与领域自适应方法
传统的机器学习与深度学习算法在数据充足时表现优异,但在实际工业场景中往往面临训练数据不足的挑战。为此,迁移学习技术应运而生,其核心思想是将从源领域(如实验室环境)学习到的诊断知识迁移至目标领域(如实际工况),以解决目标领域标记数据稀缺的问题。其中,领域自适应(Domain Adaptation)作为迁移学习的代表性方法,致力于通过最小化与目标域之间的分布差异(如最大均值差异MMD),在共享特征空间中实现跨域知识迁移。图12展示了迁移学习的核心框架。
代表性方法解析
-
深度对抗迁移诊断(文献[141])
基于深度生成对抗网络(GAN)构建两阶段模型:- 阶段一:通过特征提取器获取频域振动信号的高阶表征,利用多生成器架构生成目标域故障样本,并通过主分类器确保特征判别性。
- 阶段二:固定特征提取器参数,利用跨域分类器融合源域监督与目标域生成数据,最终实现无监督域适应。实验表明,该方法在CWRU类故障诊断中达到95.9%平均准确率,显著优于传统迁移方法。
-
小样本学习与宽核CNN(文献[123,148])
- WDCNN架构:采用宽首层卷积核(一维64×1)直接处理原始振动信号,抑制高频噪声;后续层使用小卷积核进行深层非线性映射,结合自适应批量归一化(AdaBN)提升跨域泛化能力。
- 结果:在CWRU数据集上实现100%同工况分类精度,跨传感器迁移(DE→FE)时仍保持95%以上的准确率,验证了模型对分布偏移的鲁棒性。
-
残差迁移网络(文献[151])
构建深度残差网络处理原始振动信号:- 使用一维卷积层提取局部特征,堆叠残差块学习高级表征。
- 零填充(Zero-padding)保持特征图维度,避免信息丢失。
- 在CWRU数据集10类故障中取得99.98%平均准确率,较传统CNN提升约3%,证明残差连接有效缓解了深层网络退化问题。
关键技术创新
-
多核最大均值差异(MK-MMD)(文献[149])
通过多核函数加权计算源域与目标域的距离,在CNN高层特征空间实现细粒度分布对齐。实验显示,该方法在跨(0hp→3hp)诊断中准确率达99.76%,较单核MMD提升2.3%。 -
对抗性领域混淆(文献[150])设计领域判别器与特征提取器对抗训练:特征提取器生成域不变特征,领域判别器无法区分特征来源。结合源域监督分类器,在CWRU极端小样本场景(目标域仅10个标记样本)下仍保持70%+准确率。
工业应用挑战与解决方案
-
数据异构性:实际工况中负载、转速的连续变化导致数据分布动态偏移。解决方案包括工况解耦特征学习(如文献[144]分离转速敏感/不敏感特征)和在线自适应微调(如文献[152]集成随机森林实现增量学习)。
-
零样本迁移:当目标域包含未知故障类别时,采用开集识别策略(如文献[142]构建孪生网络度量样本相似性),在CWRU数据集中成功识别3类未知故障,误报率低于5%。
性能对比与展望
表10. 部分采用深度迁移学习与领域自适应策略的机械故障诊断研究(基于CWRU数据集)
| 文献 | 类别数 | 方法 | 超参数 | 结果 | 备注 |
|---|---|---|---|---|---|
| [123] | 10 | 宽一维卷积核深度网络(WDCNN) • 直接以原始振动信号为输入,首层采用宽卷积核抑制高频噪声 • 浅层小卷积核实现多层非线性映射 • 集成自适应批归一化(AdaBN)提升领域适应能力 | SoftMax ReLU AdaBN 最大池化 | 100%分类准确率 平均测试准确率95.9% | • 在噪声环境下表现优异 |
| [148] | 10 | 深度距离度量学习 • 基于深度CNN框架 • 提出表示聚类算法压缩类内差异/扩大类间差异 • 采用领域自适应减少训练-测试数据的最大均值差异(MMD) | 批归一化(BN) Leaky ReLU Dropout 最大池化 | 样本长度8192时 准确率99.34% | • 平均训练时间约40分钟(样本长度8192时) |
| [149] | 10 | 多核MMD领域自适应 • 在多层网络最小化源域与目标域的MMD差异 • 融合分类损失与多核MMD约束项 • 四层一维卷积架构 | BN ReLU 最大池化 Dropout | 改进模型99.76% 默认架构99.17% | • 高维空间非线性分类 • 特征空间按标签分区 |
| [150] | 10 | 对抗迁移学习 • 特征提取器生成域不变特征 • 域判别器区分源/目标域数据 • 分类器基于源域监督训练 | ReLU(特征提取) Leaky ReLU(分类器) Dropout | 极端案例(Nt=10监督样本)>70%准确率 | • 全网络采用尺寸10的卷积核 • 适用于极小监督数据场景 |
| [63] | 6 | DNN时域相干性诊断 • 直接处理传感器原始时序数据 • 利用数据时域连贯性优化诊断 | 交叉熵损失 | CWRU数据集最佳准确率94.4% | • 无需特征选择/信号预处理 |
| [151] | 10 | 深度残差学习架构 • 一维卷积层提取特征 • 堆叠残差块学习高层表示<br 零填充保持特征图维度 | SoftMax 最大池化 BN | 平均准确率99.98% | • 直接输入原始振动信号 • 包含双卷积层残差模块 |
| [152] | 10 | CNN-随机森林集成 • 连续小波变换(CWT)将信号转为二维灰度图 • 基于LeNet-5的CNN自动提取多级特征 • 多随机森林分类器集成诊断 | SoftMax 最大池化 ReLU | 99.73% | • 融合局部与全局特征信息 |
关键术语说明:
- WDCNN: 宽一维卷积核深度网络(Wide Deep Convolutional Neural Networks)
- AdaBN: 自适应批归一化(Adaptive Batch Normalization)
- MMD: 最大均值差异(Maximum Mean Discrepancy)
- Nt: 目标域监督样本量(Number of Target-domain labeled samples)
未来方向包括:1)融合物理模型约束提升小样本泛化能力;2)开发轻量化架构实现边缘设备部署;3)探索多模态数据(声发射、温度)的协同迁移机制。
V. CWRU轴承数据集的缺陷
CWRU轴承数据集具有数据量大、多样性和复杂性高的特点。每个数据文件包含不同长度的数据,这些长度并非2的整数倍。此外,许多记录显示出非经典故障识别特征;部分记录甚至无法被正确识别。数据集中的某些频率成分并不规律,某些频段会出现异常的大幅或小幅波动[143],这使得使用FFT或其他信号处理技术进行特征提取变得具有挑战性。主要难点在于特征选择——如何筛选有效特征并舍弃无效特征。
部分记录受到数据采集过程的严重影响,例如:
- 电气噪声干扰:某些记录被大范围的电气噪声污染
- 传感器数据同质化:驱动端(DE)和风扇端(FE)的测量数据除比例因子外完全相同
- 数据截断:部分记录存在数据截断现象
- 机械松动干扰:轴承测试台的装配松动问题在多个数据集中被发现,这种机械松动对检测结果的影响甚至超过了故障本身[23]
此外,CWRU数据集仅包含固定转速和负载下的运行数据。当同一轴承故障在不同负载或转速条件下运行时,其表现特征会出现显著差异,这使得数据集实际工况的多变性。
VI. 基于深度学习的机械故障检测与诊断模型面临的挑战
机械振动信号是理解轴承相关现象的重要信息来源。尽管深度学习算法在轴承故障检测中具有显著优势,但其应用仍面临诸多挑战。这些挑战主要涉及模型架构和训练过程,具体表现如下:
1. 数据需求量大
深度学习模型依赖海量数据进行高效训练,但在实际工业场景中,收集足够的故障数据(尤其是关键系统故障数据)极具挑战性。机械系统故障通常呈现缓慢退化过程,可能耗时数月甚至数年,导致相关数据集获取困难。
2. 计算资源要求高
复杂模型的训练需要高性能GPU支持,耗时长达数周。此外,深层网络需要大容量内存支持,这对硬件资源提出了较高要求。
3. 数据不平衡问题
模型在类别不平衡数据中易偏向多数类样本。实际应用中,平衡的轴承数据集难以获取,如何有效处理数据不平衡成为重要挑战。
4. 动态工况适应性差
机械系统常在多变工况下运行,传统方法难以采集足够覆盖所有工况的标注数据。这对模型的泛化能力提出了更高要求。
5. 传感器成本与安装限制
高质量振动信号依赖昂贵的传感器设备,且需要专业人员严格安装。传感器松动或安装不当会导致数据质量下降,进而影响模型性能。
6. 模型架构的局限性
- 自编码器:依赖预训练阶段,初始层误差可能导致模型重建训练数据均值而非有效特征
- 卷积神经网络:需大量标注数据,深层网络需多层结构捕捉特征层级
- 深度信念网络:未考虑输入图像的二维结构,影响图像数据处理效果
生成对抗网络**:训练过程中难以达到纳什均衡 - 循环神经网络:存在梯度消失/爆炸问题
- 强化学习:需要持续监控环境,依赖对动作结果的预估能力
7. 网络深度优化难题
超深层网络面临梯度消失/爆炸和性能退化问题。当网络深度超过临界值时,准确率反而可能下降,如何优化网络深度成为技术难点。
8. 低质量数据学习困难
虽然深度学习对噪声数据具有一定鲁棒性,但从弱质量数据中有效学习特征仍存在挑战,影响故障诊断的可靠性。
9. 可解释性问题
现有文献虽大量涉及深度学习在故障检测系统中的应用,但模型架构设计需要先验知识支持。这种"黑箱"特性导致工业应用接受度较低。
这些挑战凸显了将深度学习应用于机械故障检测时需要综合考虑数据、算法和实际工程条件的复杂性。未来的研究需要针对这些瓶颈问题提出创新解决方案,以推动该领域的技术进步和实际应用落地。
VIII. 结论
在工业4.0时代,深度学习算法已逐渐成为机械故障检测与诊断系统的核心工具。近年来,基于深度学习的模型在机械故障检测领域展现出显著优势,并随着计算机技术的持续进步,其鲁棒性和适用性将不断增强。本文通过系统性综述使用CWRU数据集的轴承故障检测研究,尝试全面总结深度学习算法在该领域的最新应用进展。
本文的贡献体现在以下方面:
- 研究范围覆盖全面:详细概述了采用CWRU数据集驱动端缺陷轴承数据的相关文献,重点剖析了各类深度学习算法的应用细节。
- 技术挑战系统梳理:针对振动信号处理与深度学习模型应用中的关键难题(如数据需求、计算成本、不平衡数据集等)进行了深入探讨。
- 实用建议提出:为未来研究者提供了基于CWRU数据集的研究指导,包括数据增强、噪声鲁棒性优化、实际场景验证等方向。
未来研究方向建议:
- 开发更高效的跨域适应策略以应对多变工况
- 探索小样本学习在机械故障诊断中的潜力
- 构建可解释性更强的深度学习模型以提高工业接受度
- 研究多模态传感器数据融合技术提升诊断精度
致谢
本文感谢凯斯西储大学通过其官方网站公开共享轴承振动实验数据,为相关研究提供了重要基准数据集。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









