







【Hadoop-Distcp】通过Distcp的方式迁移Hive中的数据至存储对象
1)了解 Distcp
1.1.Distcp 的应用场景
Distcp是Hadoop自带的分布式复制程序,该程序可以从Hadoop文件系统间复制大量数据,也可以将大量的数据复制到Hadoop中。
一般情况下Distcp在企业中的应用场景:
-
Distcp 的典型应用场景是在两个HDFS集群之间传输数据(如果两个集群运行相同版本的 Hadoop,就非常适合使用 HDFS 方案)
-
Distcp还可以将HDFS中的数据和存储对象中的数据进行相互迁移
1.2.Distcp 的底层原理
Distcp是作为一个MapReduce作业来实现的,该复制作业是通过集群中并行运行的 map 来完成,此过程中没有 reduce。
map的数量如何确定:
-
常规情况下,每个 map 至少复制256MB数据(除非输入的总数据量较少,否则一个 map 就可以完成所有的复制)
例如:
将 1GB 大小的文件分给4个map任务。
-
如果数据非常大则有必要限制 map 的数量进而限制带宽和集群的使用(默认情况下,每个集群节点最多分配20个map任务)
例如:
将 1000GB 的文件复制到一个由 100 个节点组成的集群,一共分配 2000 个 map 任务(每个节点 20 个 map 任务)所以每个map任务平均复制 512MB 数据。
-
通过对 distcp 指定 -m 参数,可以减少分配的map任务数。
例如:
-m 1000 将分配 1000 个 map 任务,每个平均复制 1GB 数据
2)使用 Distcp
(1)获取Hive数据在HDFS中对应的location路径
-
通过查看建表语句的方式
show create table tableName; -
通过查看表详细信息的方式
desc formatted tableName;
(2)通过distcp对获取到的location中的数据进行数据迁移(以S3为例)
参数说明:
- -D mapred.task.timeout:允许超时时间
- -D mapreduce.job.name:任务名称
- -Dfs.s3a.access.key:S3存储对象的accesskey
- -Dfs.s3a.secret.key:S3存储对象的secretkey
- -Dfs.s3a.endpoint:S3存储对象的endpoint
- -Dfs.s3a.connection.ssl.enabled:是否关闭ssl连接
- -Dfs.s3a.signing-algorithm:S3的操作算法,选择S3SignerType即可
- HDFS的location路径
- S3存储对象的路径
hadoop distcp \
-D mapred.task.timeout=60000000 \
-D mapreduce.job.name=%s \
-Dfs.s3a.access.key=B4840CE7567123456789 \
-Dfs.s3a.secret.key=123456789eYEh9+4h01ch123456789123456789 \
-Dfs.s3a.endpoint=192.168.1.1 \
-Dfs.s3a.connection.ssl.enabled=false \
-Dfs.s3a.signing-algorithm=S3SignerType \
hdfs://nameserver/warehouse/tablespace/external/hive/test.db/tableName \
s3a://s3-bucket-test/tableName
(3)登录S3可视化界面查看数据是否成功写入
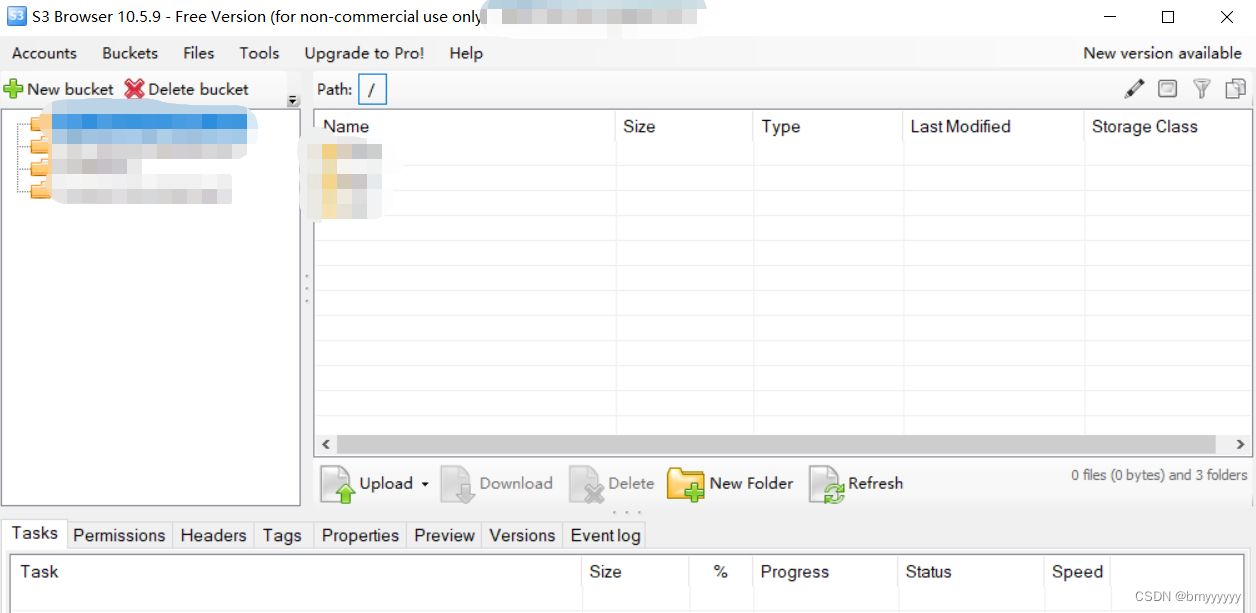
4)S3 可视化 App 下载
S3可视化App下载地址:https://s3browser.com/
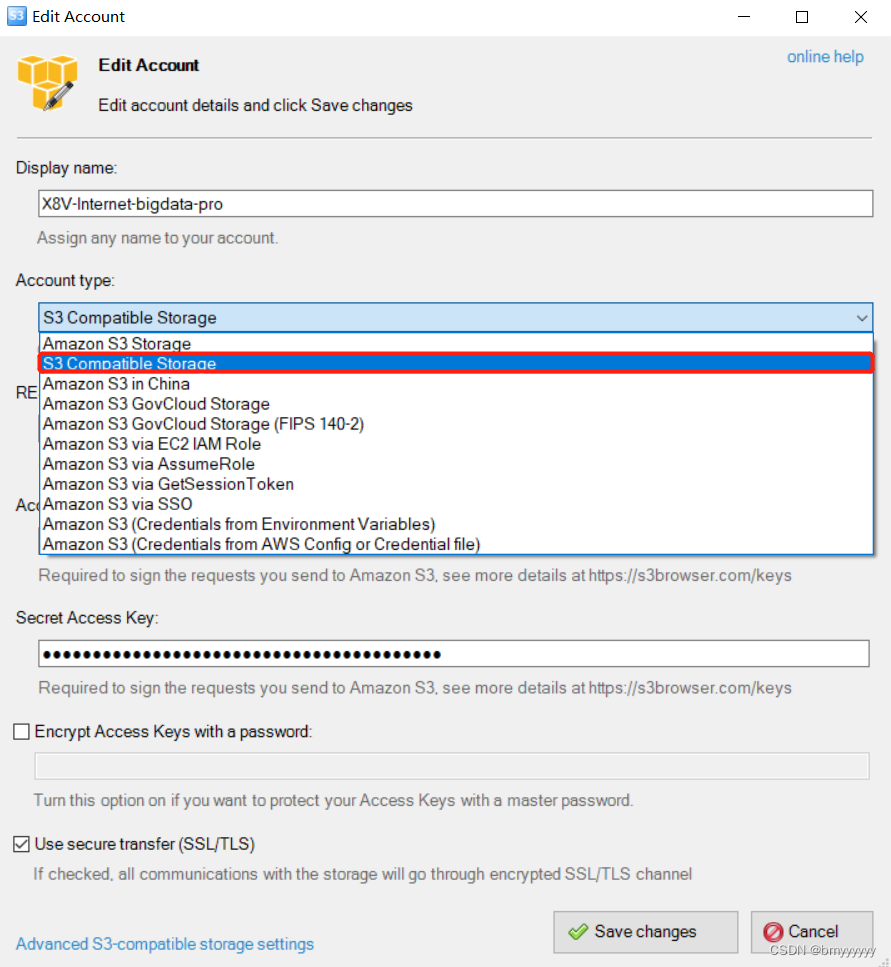
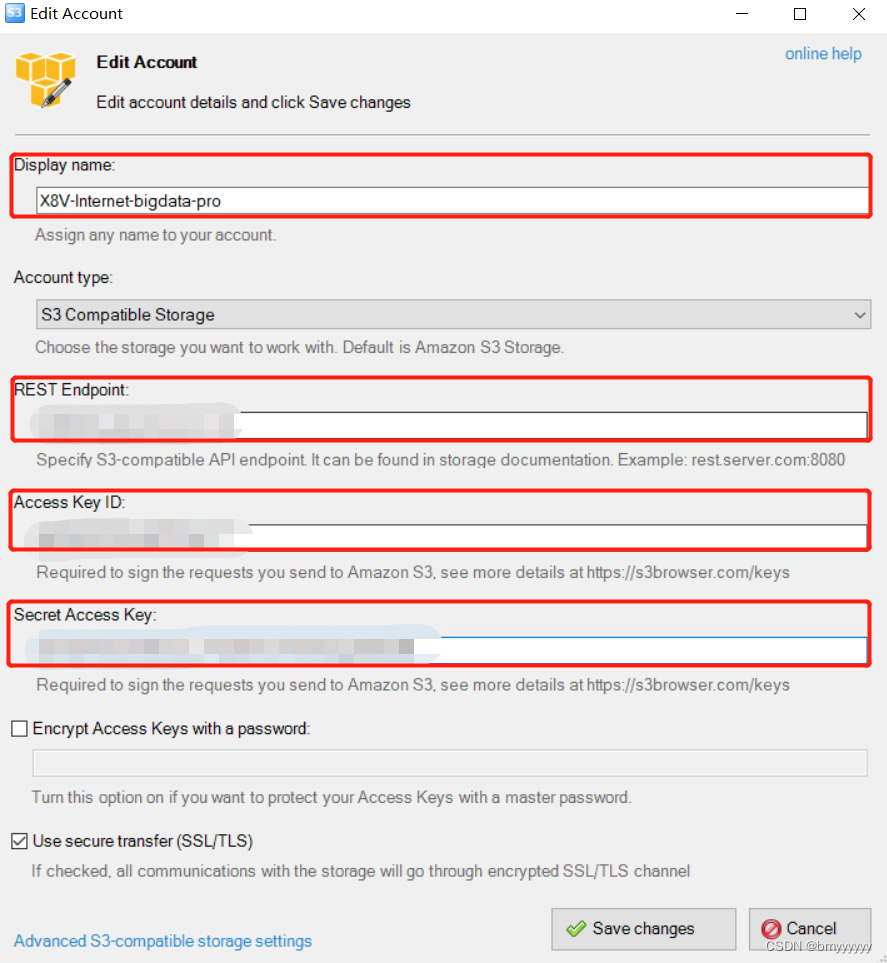
4)S3 可视化 App 使用
5)跨集群迁移 HDFS 数据
1、如果集群版本不同,不能用hdfs协议直接拷贝,需要用http协议。
即不能用:distcp hdfs://src:50070/foo /user
而要用:distcp hftp://src:50070/foo /user
最终的命令为:hadoop distcp hftp://192.168.57.73:50070/hive3/20171008 /hive3/
2、如果两个集群的版本相同,则可以使用hdfs协议,命令如下:
hadoop distcp hdfs://namenodeip:9000/foo hdfs://namenodeip:9000/foo















 5965
5965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









