







【Kafka-3.x-教程】专栏:
【Kafka-3.x-教程】-【一】Kafka 概述、Kafka 快速入门
【Kafka-3.x-教程】-【二】Kafka-生产者-Producer
【Kafka-3.x-教程】-【三】Kafka-Broker、Kafka-Kraft
【Kafka-3.x-教程】-【四】Kafka-消费者-Consumer
【Kafka-3.x-教程】-【五】Kafka-监控-Eagle
【Kafka-3.x-教程】-【六】Kafka 外部系统集成 【Flume、Flink、SpringBoot、Spark】
【Kafka-3.x-教程】-【七】Kafka 生产调优、Kafka 压力测试
【Kafka-3.x-教程】-【二】Kafka-生产者-Producer
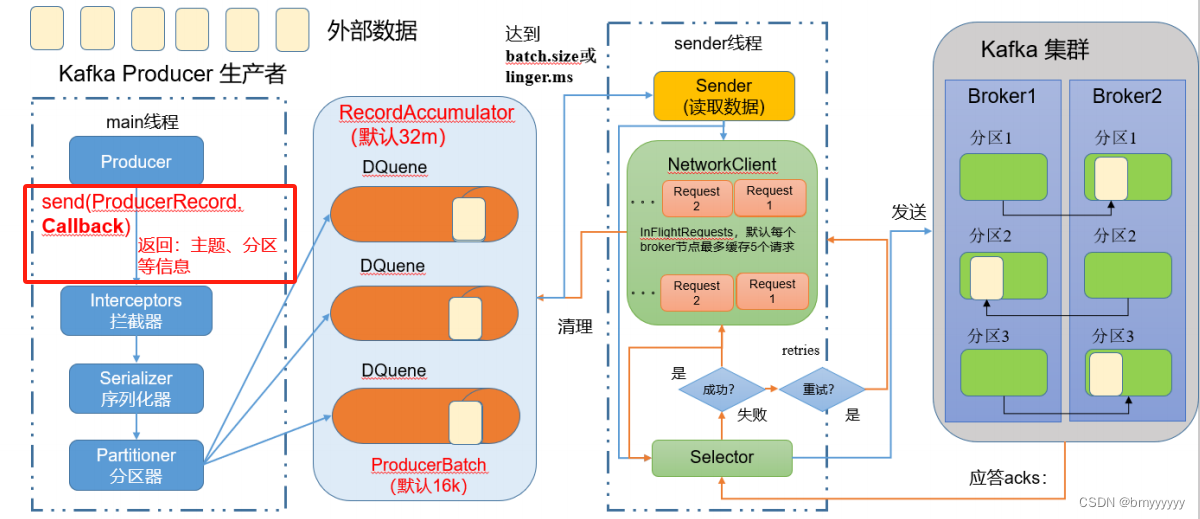
1)生产者消息发送流程
1.1.🚀发送原理
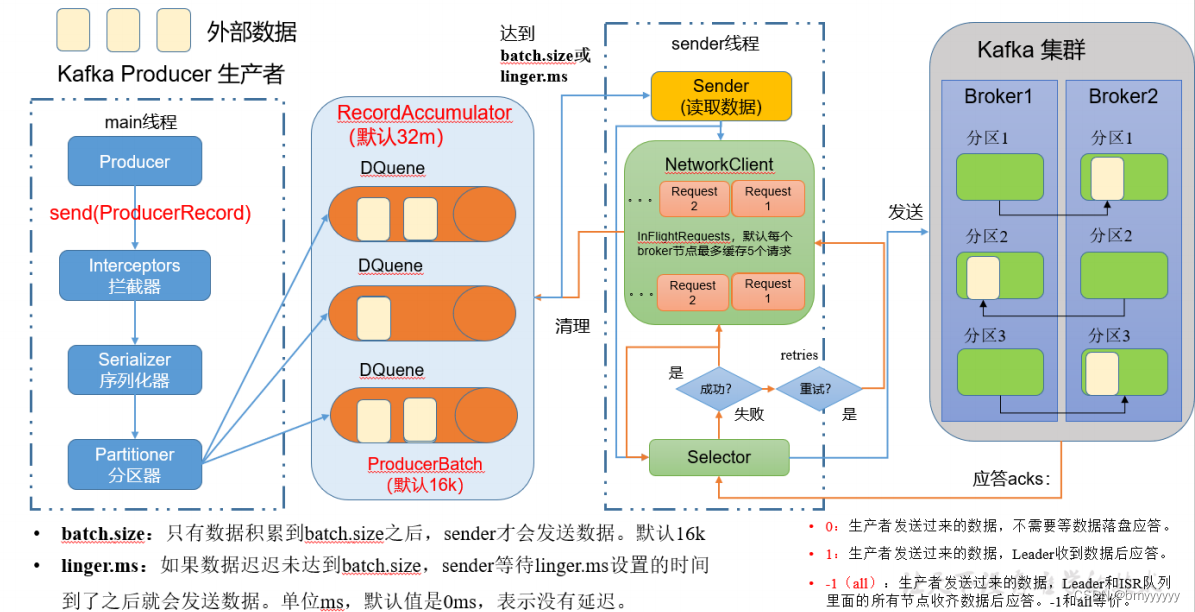
在消息发送的过程中,涉及到了两个线程 — — main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
1、外部数据通过 Producer 生产者中的 main 线程,调用 send 方法后,会经历三个阶段,分别是 Interceptors(拦截器)、Serializer(序列化器)、Partitioner(分区器)
(1)Interceptors 是做拦截过滤操作的,但是生产中一般不适用 Kafka 做拦截处理,一般都是使用 Flume 在上游做拦截处理.
(2)Serializer 将数据进行序列化操作,但是注意这里的序列化器并不是用的 java 自带的序列化(java 的序列化太重量了),Kafka 有自己的序列化器,相对于 java 更加轻量好用。
(3)Partitioner 将数据进行分区操作,Kafka 有几种不同的分区策略,根据不同的分区策略将数据发送到不同的分区上,点击此处跳转至 Kafka 分区策略详解。
2、Producer 将数据经过以上三个阶段处理后,会将数据发送到一个双端队列 RecordAccumulator 中,这个双端队列中的过程是基于内存完成的(默认 32M),在 RecordAccumulator 中,会根据分区数量创建好对应的 DQuene(队列)数量(一个分区一个 DQuene),然后按照对应的分区策略将数据发送到对应的 DQuene 中,发送到 DQuene 中的数据每一批次(ProducerBatch)大小默认是 16 KB。
扩展:双端队列 RecordAccumulator 中存在一个内存池,Producer 将数据经过以上三个阶段处理后向 RecordAccumulator 中的 DQuene 发送数据时,会直接从内存池中获取内存资源,后续数据完成写入后将资源重新释放回内存池当中。
3、Sender 现成将 RecordAccumulator 缓冲区中的数据读取出来后,将数据发送到 Kafka 集群(Broker)。
(1)batch.size(ProducerBatch) 达到阈值,或 linger.ms 达到设置的时间(默认 0ms,也就是说来一条发送一条),Sender 线程就会去 RecordAccumulator 拉取数据。
- 可以理解为大巴车,人满了就会发车,如果人没有坐满但是发车时间到了也要发车。
- 如果 linger.ms 设置为 0,那么 batch.size 的参数无论设置为多少都没有作用了。
(2)Sender 拉取到数据后,按照节点地址(Broker)作为 key,Request(请求)作为 value,这里的 Request(请求)中并不只包含一条或一批数据,可能是多条数据或多批数据,将数据发送给 Broker。
(3)如果 Request1 拉取到 DQuene 中的数据后发送到 Broker1 中,如果 Broker1 没有及时的应答,那么允许发送第二个请求吗?答案是允许的,最多有五个请求都没有收到应答,那么就不再发送请求了。
(4)Selector 可以理解为一条高速公里,数据可以理解为高速公路上行驶的骑车;左侧的 RecordAccumulator 缓冲区看做输入流,右侧的 Broker 看做输出流。
4、数据发送到 Kafka 集群中(也就是 Broker 中),会有一个副本同步机制进行副本同步。
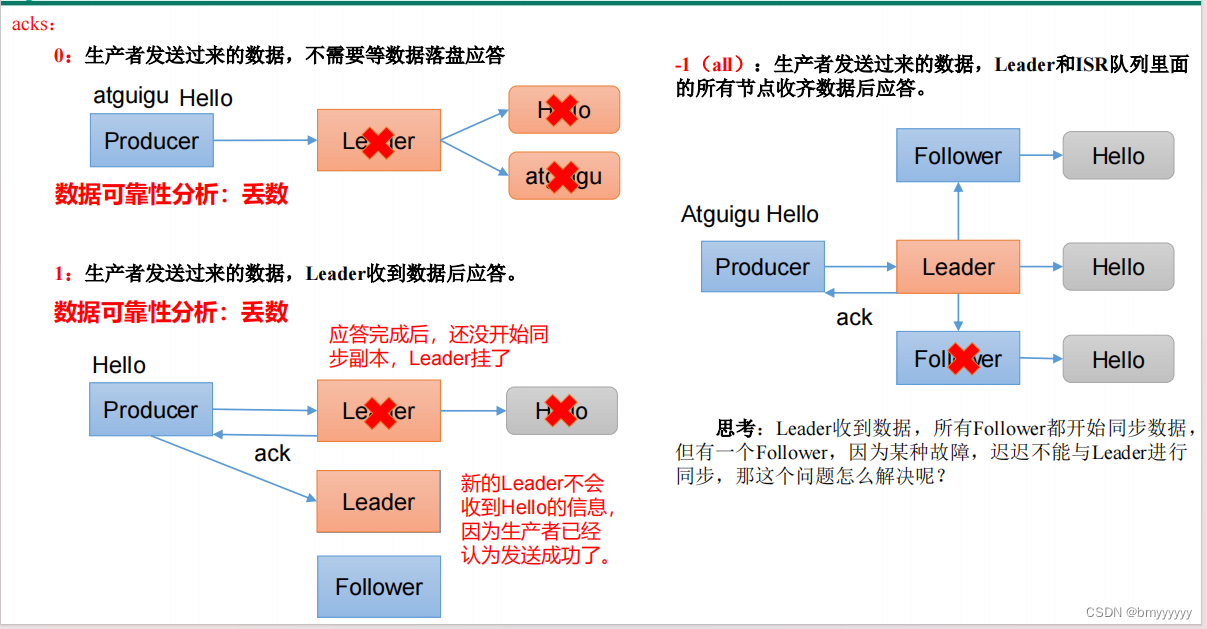
(1)Kafka 集群收到数据后会有一个应答机制(ack),表明是否收到数据,ack 的级别有一下几种。
0:生产者发送过来的数据,不需要等数据落盘应答。1:生产者发送过来的数据,Leader 收到数据后应答。-1/all:生产者发送过来的数据,Leader 和 ISR 队列(ISR 队列中包含 Leader 和所有跟得上 Leader 进行数据同步的 Follower 的集合)里面的所有节点收齐数据后应答。-1 和 all 等价。
(2)如果 Selector 接收到 ack 返回的成功信号,那么首先要把 NetWorkClient 中对应的的 Request1 清理掉,同时清理掉 RecordAccumulator 缓冲区内对应的分区数据;如果 Selector 接收到 ack 返回的失败信号,那么可以进行 retries(重试),retries 默认次数为 int 的最大值,一般情况下我们是进行重新配置的。
以上为 Produer 发送数据到 Kafka 集群的流程原理
1.2.生产者重要参数列表

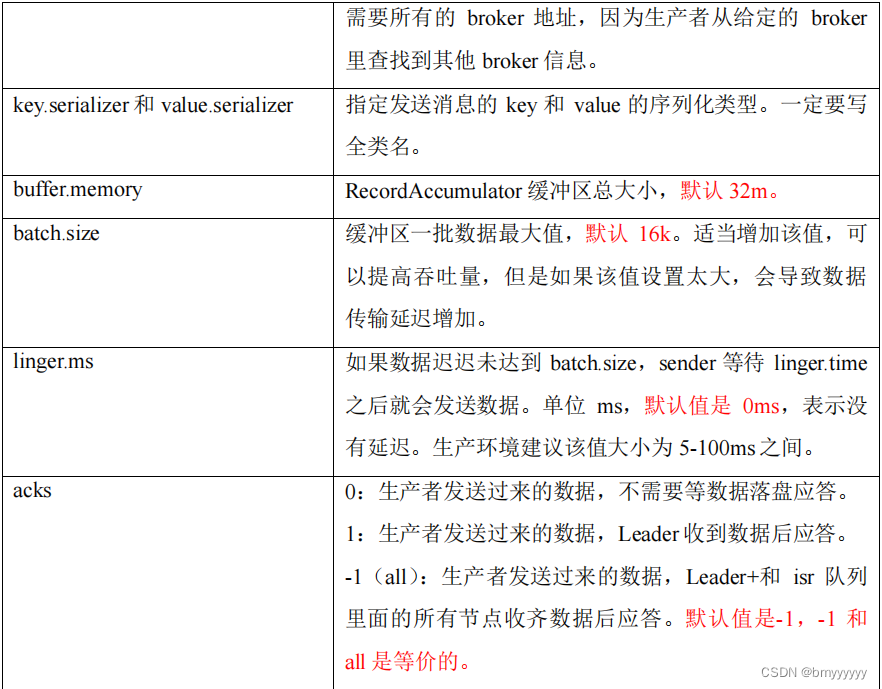
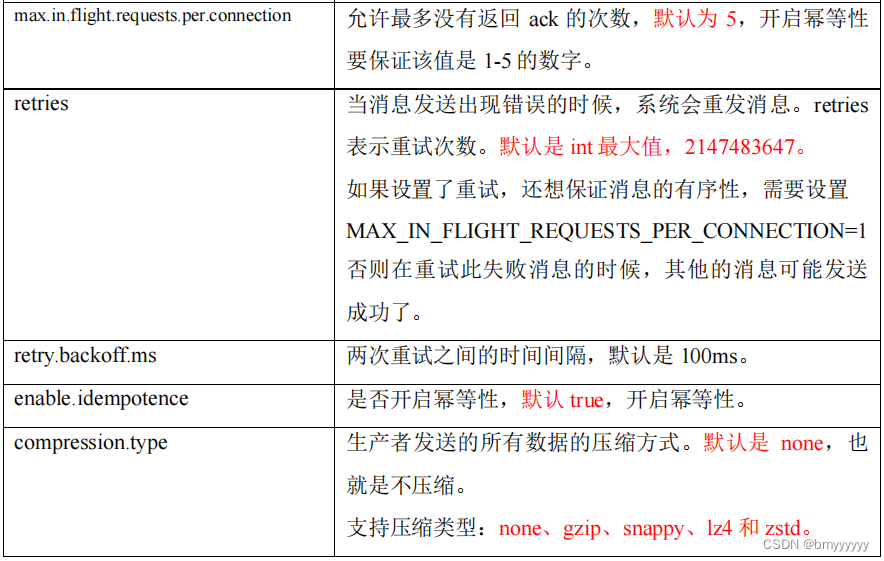
2)异步发送
2.1.普通异步发送
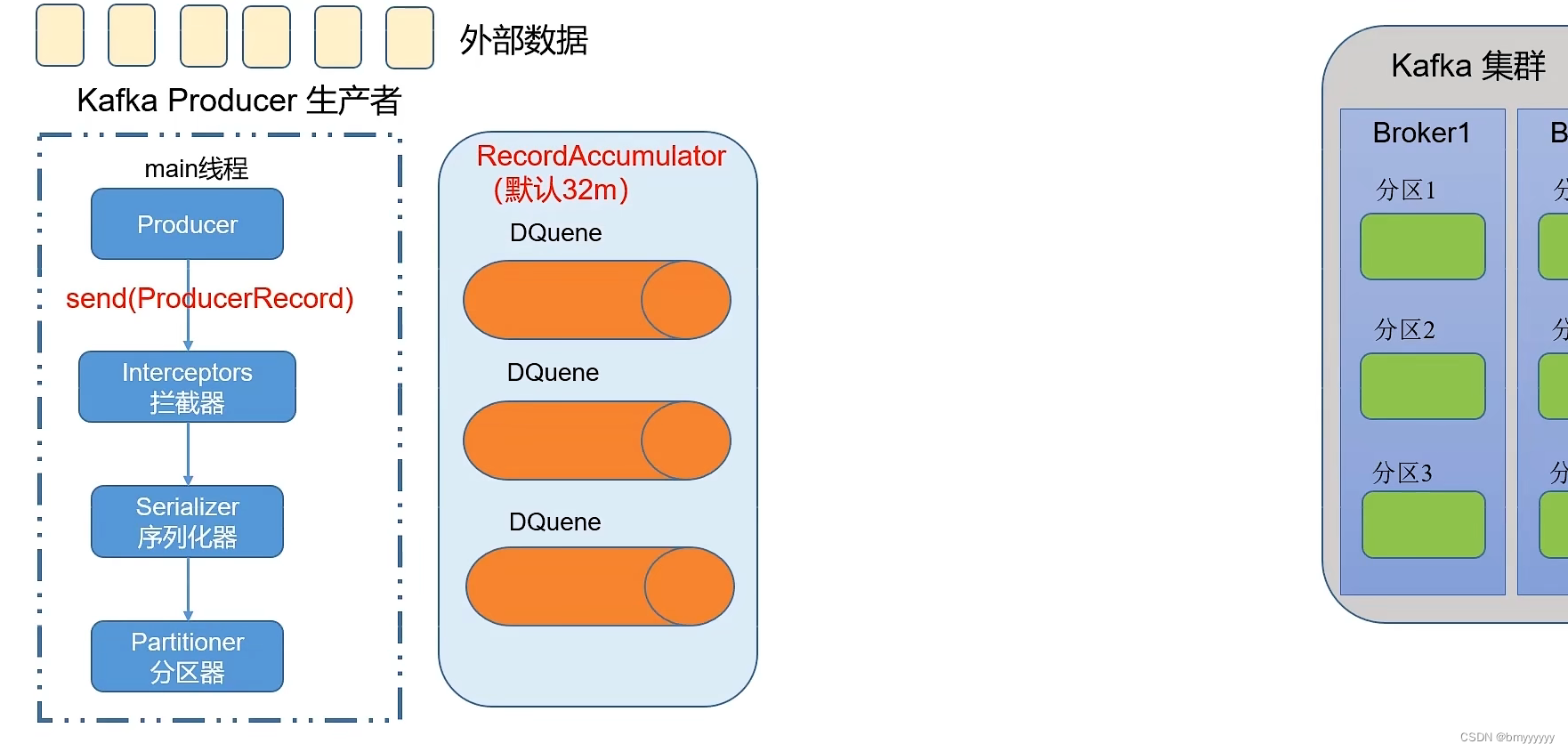
在企业中一般采用异步发送策略,异步发送是指,在外部数据经过 main 线程后进入到双端队列 RecordAccumulator 中后,不用等待数据写入 Kafka 集群,直接继续发送数据到 RecordAccumulator 中。
1、导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
2、代码编写
public class CustomProducer {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first","count"+i));
}
// 3 关闭资源
kafkaProducer.close();
}
}
2.2.带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
代码编写:
public class CustomProducerCallback {
public static void main(String[] args) throws InterruptedException {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 500; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "count" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println("主题: "+metadata.topic() + " 分区: "+ metadata.partition());
}
}
});
Thread.sleep(2);
}
// 3 关闭资源
kafkaProducer.close();
}
}
3)同步发送 API
只需在异步发送的基础上,再调用一下 get()方法即可。
代码编写:
public class CustomProducerSync {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first","count"+i)).get();
}
// 3 关闭资源
kafkaProducer.close();
}
}
4)生产者分区
4.1.分区好处
(1)便于合理使用存储资源,每个 Partition 在一个 Broker 上存储,可以把海量的数据按照分区切割一块一块数据存储在多台 Broker 上。合理控制分区的任务,可以实现负载均衡的效果。
(2)提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
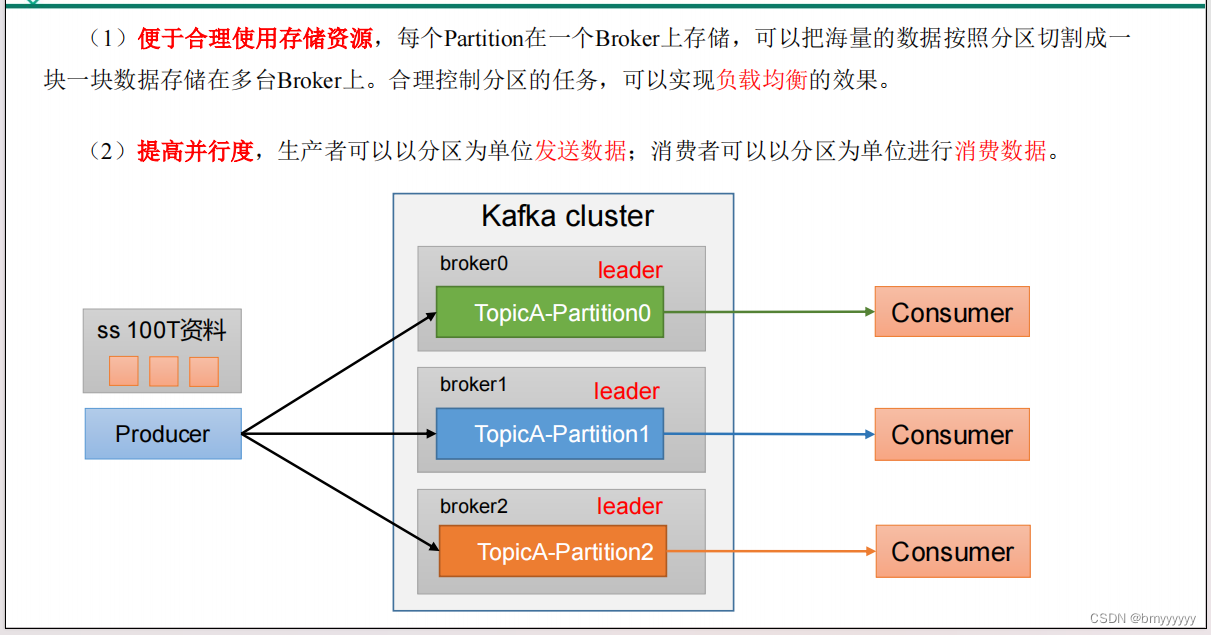
4.2.生产者发送消息的分区策略
4.2.1.默认的分区器 DefaultPartitioner
在 IDEA 中 ctrl +n,全局查找 DefaultPartitioner。
/**
* The default partitioning strategy:
* <ul>
* <li>If a partition is specified in the record, use it
* <li>If no partition is specified but a key is present choose a
partition based on a hash of the key
* <li>If no partition or key is present choose the sticky
partition that changes when the batch is full.
*
* See KIP-480 for details about sticky partitioning.
*/
public class DefaultPartitioner implements Partitioner {
… …
}

1、将数据发往指定 partition 的情况下,例如,将所有数据发往分区 1 中。
public class CustomProducerCallbackPartitions {
public static void main(String[] args) throws InterruptedException {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", 1,"","hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println("主题: "+metadata.topic() + " 分区: "+ metadata.partition());
}
}
});
Thread.sleep(2);
}
// 3 关闭资源
kafkaProducer.close();
}
}
2、没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值。
public class CustomProducerCallback {
public static void main(String[] args) throws InterruptedException {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 500; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println("主题: "+metadata.topic() + " 分区: "+ metadata.partition());
}
}
});
Thread.sleep(2);
}
// 3 关闭资源
kafkaProducer.close();
}
}
4.2.2.自定义分区器
如果研发人员可以根据企业需求,自己重新实现分区器。
1、需求
例如我们实现一个分区器实现,发送过来的数据中如果包含 hello,就发往 0 号分区,不包含 hello,就发往 1 号分区。
2、实现步骤
(1)定义类实现 Partitioner 接口。
(2)重写 partition()方法。
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取数据 atguigu hello
String msgValues = value.toString();
int partition;
if (msgValues.contains("hello")){
partition = 0;
}else {
partition = 1;
}
return partition;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
(3)使用分区器的方法,在生产者的配置中添加分区器参数。
public class CustomProducerCallbackPartitions {
public static void main(String[] args) throws InterruptedException {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 关联自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atguigu.kafka.producer.MyPartitioner");
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", 1,"","hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println("主题: "+metadata.topic() + " 分区: "+ metadata.partition());
}
}
});
Thread.sleep(2);
}
// 3 关闭资源
kafkaProducer.close();
}
}
5)生产经验
5.1.生产者如何提高吞吐量

-
batch.size:批次大小,默认 16k -
linger.ms:等待时间,修改为 5-100ms -
compression.type:压缩 snappy -
RecordAccumulator:缓冲区大小,修改为 64m
代码编写:
public class CustomProducerParameters {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接kafka集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
// 批次大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
// linger.ms
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
// 1 创建生产者
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first","count"+i));
}
// 3 关闭资源
kafkaProducer.close();
}
}
5.2.数据可靠性(ack)
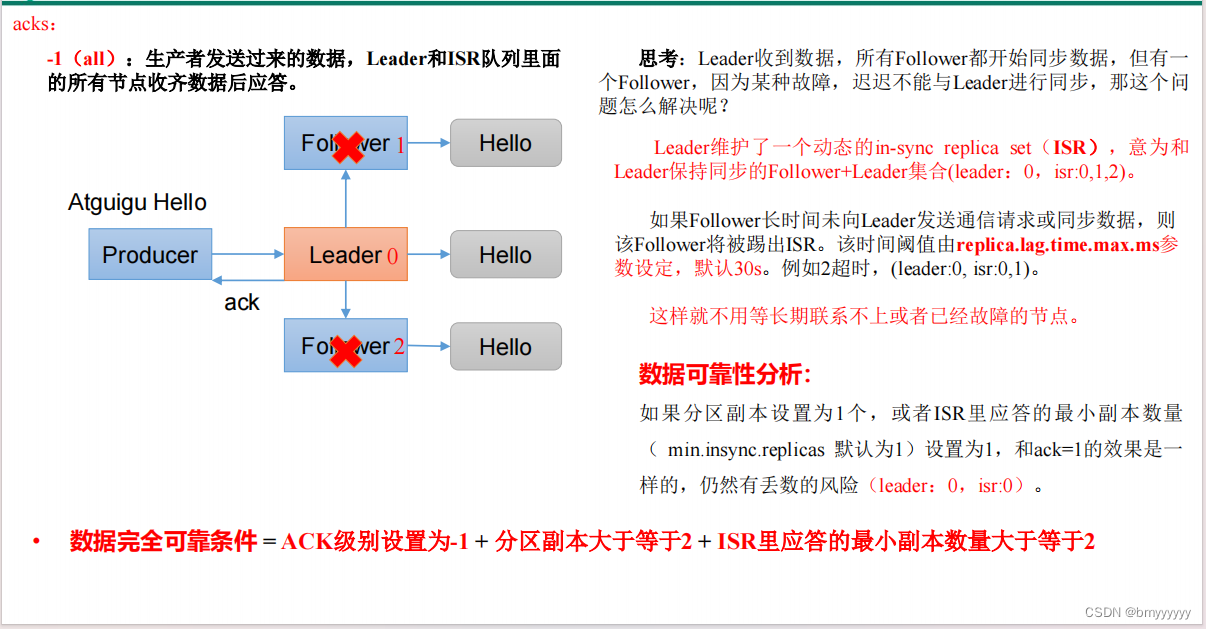
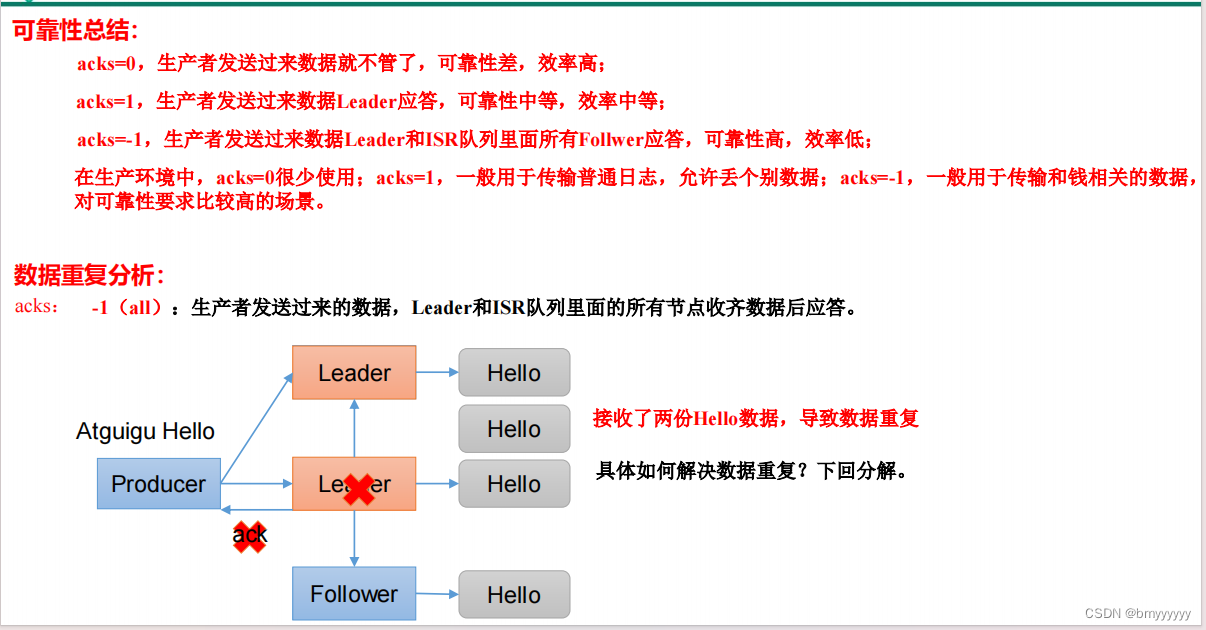
数据可靠性分析:
如果分区副本设置为 1 个,或者 ISR 里应答的最小副本数量( min.insync.replicas 默认为 1)设置为 1,和 ack = 1 的效果是一样的,仍然有丢数的风险(leader:0,isr:0)。
所以数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2。
代码编写:
public class CustomProducerAcks {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// acks
properties.put(ProducerConfig.ACKS_CONFIG,"all");
// 重试次数
properties.put(ProducerConfig.RETRIES_CONFIG,3);
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first","hello"+i));
}
// 3 关闭资源
kafkaProducer.close();
}
}
5.3.数据去重(一致性语义、幂等性、生产者事务)
1、数据传递语义

2、幂等性
PID:ProducerId,Kafka 每次重启都会生成一个新的 PID。所以幂等性不能保证多会话时数据不重复,只能保证单会话时数据不重复,一旦 Kafka 重启产生新的会话那么就会造成数据重复。通过幂等性判断出来的重复数据不会落盘,直接在内存中将数据清理掉。
Partition:分区号。证明多个分区也可以有想同的数据。
SeqNumber:序列化 number,单调递增。
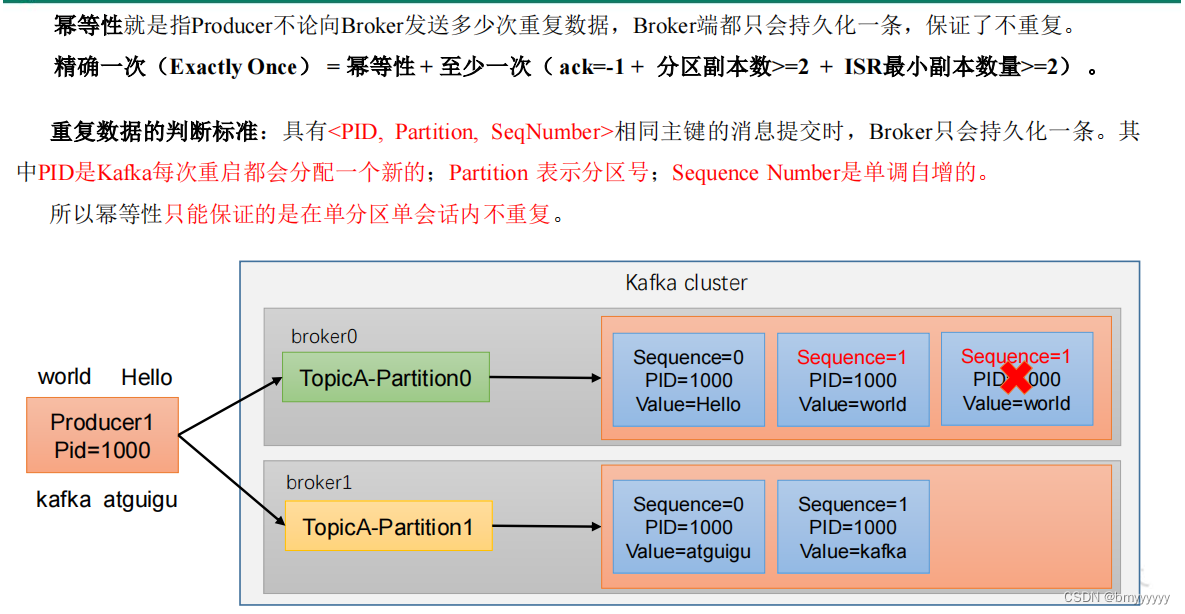
如何使用幂等性:开启参数 enable.idempotence 默认为 true,false 关闭。
3、Kafka 事务
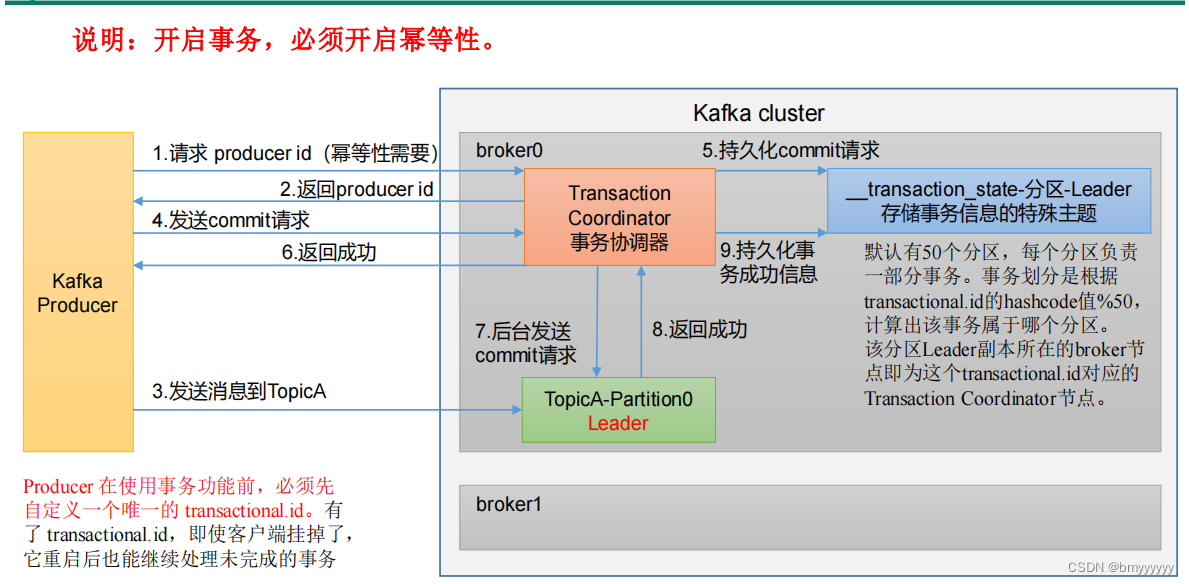
(1)Kafka 事务原理
开启事务,必须开启幂等性。
刚才上面说的幂等性不能保证 Kafka 重启时的数据重复问题,那么为了解决这一问题,衍生出了 Kafka 事务。
Transaction Coordinator(事务协调器):Kafka 事务的主要负责者。Kafka 事务开启后会存在一个存储事务信息的特殊主题(也就是说可以将事务信息持久化到磁盘中),这个主题默认有 50 个分区,每个分区负责一部分事务,事务的划分是根据 transactionnal.id(可以再代码中进行配置,唯一值)的 hashcode 值 % 50 计算出该事务属于哪个分区,该分区 Leader 副本所在的 Broker 节点即为这个 transactional.id 对应的 Transaction Coordinator 节点。
Kafka 事务流程:
① Producer 向协调器请求 PID(幂等性需要)。
② 返回 PID 给 Producer。
③ Producer 接收到 PID 后向 topic 发送消息。
④ Producer 同时向协调器发出 commit 请求
⑤ commit 请求持久化到存储事务信息的特殊主题。
⑥ 持久化成功后通知 Producer 已经持久化成功。
⑦ 协调器在后台向 topic 分区所在的节点发送一个 commit 请求,用来验证数据是否已经写入到对应的节点中。
⑧ topic 分区所在的节点返回数据成功写入的信息。
⑨ 将事务成功信息持久化到存储事务信息的特殊主题。
(2)Kafka 的事务一共有如下 5 个 API
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws
ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
(3)单个 Producer,使用事务保证消息的仅一次发送
public class CustomProducerTranactions {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 设置事务 id(必须),事务 id 任意起名
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "tranactional_id_01");
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 初始化事务
kafkaProducer.initTransactions();
// 开启事务
kafkaProducer.beginTransaction();
try {
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "atguigu" + i));
}
int i = 1 / 0;
// 提交事务
kafkaProducer.commitTransaction();
} catch (Exception e) {
// 终止事务
kafkaProducer.abortTransaction();
} finally {
// 3 关闭资源
kafkaProducer.close();
}
}
}
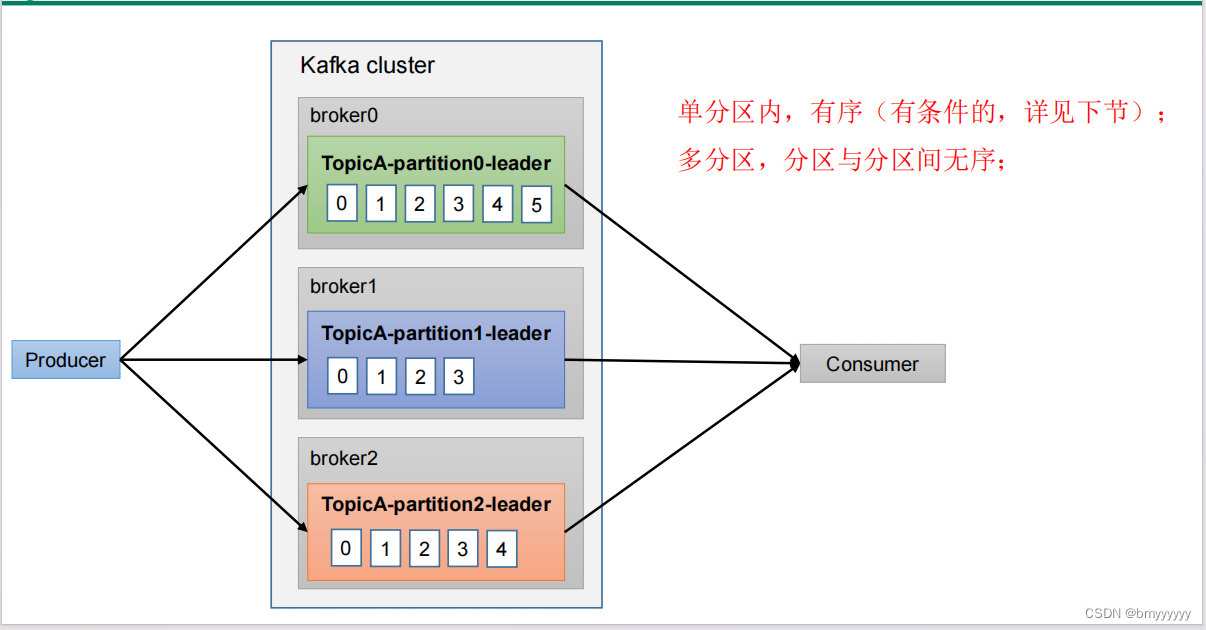
5.4.数据有序
单分区内数据有序
多分区、分区与分区间数据无需。
5.5.数据乱序
1、Kafka 在 1.x 版本之前保证数据单分区有序,条件如下(Request 每次只发送一个):
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。
2、kafka在1.x及以后版本保证数据单分区有序,条件如下:
(1)未开启幂等性
max.in.flight.requests.per.connection需要设置为 1。
(2)开启幂等性
max.in.flight.requests.per.connection 需要设置小于等于 5。如果配置为大于 5 就不一定能保证了,因为 Sender 中最多只保证 5 个 Request 的排序(最多缓存 5 个请求)。
原因说明:因为在 Kafka1.x 以后,启用幂等后,Kafka 服务端会缓存 Producer 发来的最近 5 个 Request 的元数据,故无论如何,都可以保证最近 5 个 Request 的数据都是有序的。
在缓存中根据幂等性中的序列号进行排序后进行落盘。















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









