








我在代码处打有注释,请耐心观看,不懂得请留言或私信,若有好办法也请留言私信,在最后附上一个实验图和文件的截图
'''
功能:词频统计
作者:Sherry
时间:2021.12.4
'''
def regroup_word():
word = 0 #这个可以不用管 只是为了下面的word有一个底色
f = open('D:\Python_Datebase\lesson11_date\\词频统计.txt') #使用绝对路径打开文件
for i in f: #让 i 等于 文件 f 里的所有值
word = i.split(' ') #让每个以 ' ' 相隔的元素组成列表
f.close() #关闭文档
return word #函数u返回值 word
#计算次数
def count_time():
word = regroup_word() #调用函数值
only_word = list(set(word)) #先用 集合 set 来让元素值唯一,再组成列表遍历
only_word.sort() #排序 这只是为了结果好看
for i in range(len(only_word)): #计算有多少个唯一单词
count = 0 #先定义 数量的 初始值
for j in range(len(word)): #和每个值做对照
if only_word[i] == word[j]: #因为我们 j 是 0开始 所以我们上面定义的是 count = 0
count += 1 #计数 加一
print('{}出现了{}次'.format(only_word[i], count)) #输出
#若要调用就写一个 函数名就好
下面是实验图:
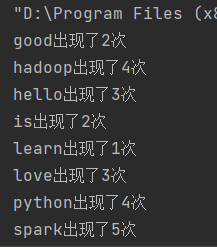
下面是文件的截图:

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











