







1.1 事务的概述
1.1.1 什么是事务?
如果一个业务操作中多次访问了数据库,必须保证每条SQL语句都执行成功;如果其中由一条执行失败,那么所有已经执行过的代码必须回滚(撤销),回到没有执行前的状态,称为事务。简单来说,就是要么所有的SQL语句全部执行成功,要么全部失败。
1.1.2 事务的四大特性
| 事务特性 | 含义 |
| 原子性(Atomicity) | 事务是工作的最小单元,整个工作单元要么全部执行成功,要么全部执行失败 |
| 一致性(Consistency) | 事务执行前与执行后,数据库中数据应该保持相同的状态(数据总量不变) |
| 隔离性(Isolation) | 事务与事务之间不能互相影响,必须保持隔离性 |
| 持久性(Durability) | 如果事务执行成功,对数据库的操作是持久的 |
1.1.3 事务提交的方式
- 自动提交:MySQL 就是自动提交的 (一条 DML(增删改)语句会自动提交一次事务)
- 手动提交:需要先开启事务,再提交(Oracle 是默认手动提交的)
- 查看事务的默认提交方式:select @@autocommit; (1 代表自动提交,默认值,0 代表手动提交)
- 修改默认提交方式:set @@autocommit = 0;(1 代表自动提交,0 代表手动提交)
1.2 事务的应用场景说明
- 转账的操作
drop database if exists db04;
create database db04;
use db04;
-- 创建数据表
CREATE TABLE account (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10),
money DOUBLE
);
-- 添加数据
INSERT INTO account (name, money) VALUES ('a', 1000), ('b', 1000);- 转账需求:
模拟a给b转500元钱,一个转账的业务操作最少要执行下面的2条语句:
a账号-500
b账号+500
-- 转账操作
-- 有两条UPDATE的更新操作
-- a转500给b
update account set money=money-500 where name='a';
update account set money=money+500 where name='b';
-- 还原
update account set money=1000;假设当a账号上-500元,服务器崩溃了。b的账号并没有+500元,数据就出现问题了。我们需要保证其中一条SQL语句出现问题,整个转账就算失败。只有两条SQL都成功了转账才算成功。这个时候就需要用到事务。
1.3 手动提交事务
1.3.1 SQL语句
| 功能 | SQL语句 |
| 开启事务 | start transaction/begin |
| 提交事务 | commit |
| 回滚事务 | rollback |
1.3.2 使用过程
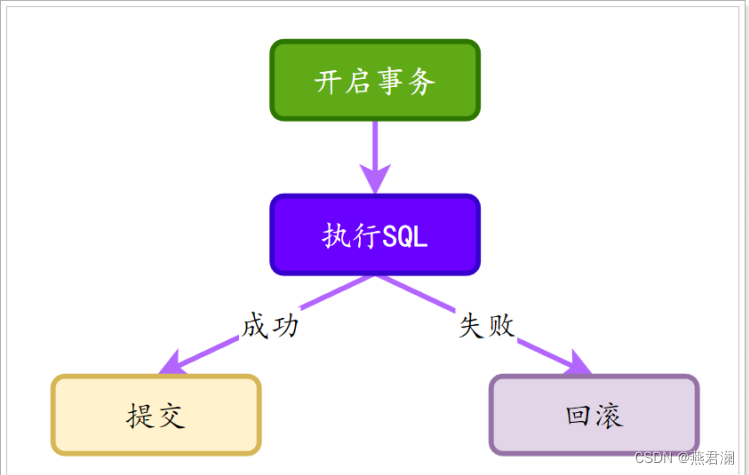
1.3.3 事务提交
模拟a给b转500元钱(成功) 目前数据库数据如下:

- 使用DOS控制台进入MySQL
- 执行以下SQL语句: 1.开启事务, 2.xiaodong账号-500, 3.xiaobiao账号+500
- 使用Navicat查看数据库:发现数据并没有改变
- 在控制台执行commit提交任务:
- 使用Navicat查看数据库:发现数据改变
mysql> use db04;
Database changed
mysql> select * from account;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+
2 rows in set (0.00 sec)
-- 执行具体操作
-- 开启事务
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- a账号-500元
mysql> update account set money = money-500 where name = 'a';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- b账号+500元
mysql> update account set money = money+500 where name = 'b';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 提交事务
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 500 |
| 2 | b | 1500 |
+----+------+-------+
2 rows in set (0.00 sec)1.3.4 事务回滚
首先还原数据:
mysql> update account set money = 1000;
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
mysql> select * from account;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+
2 rows in set (0.00 sec)模拟a给b转500元钱(失败):
- 在控制台执行以下SQL语句:1.开启事务, 2.a账号-500
- 使用Navicat查看数据库:发现数据并没有改变
- 在控制台执行rollback回滚事务:
- 使用Navicat查看数据库:发现数据没有改变
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set money = money-500 where name = 'a';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from account;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+
2 rows in set (0.00 sec)
-- 回滚事务
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
-- 再次查询数据发现数据回到事务开始之前的状态
mysql> select * from account;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+
2 rows in set (0.00 sec)- 如果事务中SQL语句没有问题,那就commit提交事务,会对数据库数据的数据进行改变
- 如果事务中SQL语句有问题,那就rollback回滚事务,会回退到开启事务时的状态
1.4 自动提交事务
MySQL默认每一条DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,执行完毕自动提交事务,MySQL默认开始自动提交事务。
1.4.1 案例演示
- 将金额重置为1000
- 更新其中某一个账户
- 使用Navicat查看数据库:发现数据已经改变
1.4.2 取消自动提交
- 查看MySQL是否开启自动提交事务
-- 1表示自动提交(默认值),0表示手动提交
select @@autocommit;- 取消自动提交事务
set @@autocommit = 0;1.5 事务原理
事务开启之后,所有的操作都会临时保存到事务日志中,事务日志只有在达到commit命令才会同步到数据表中,执行完commit或rollback都会清空事务日志(rollback,断开连接)。
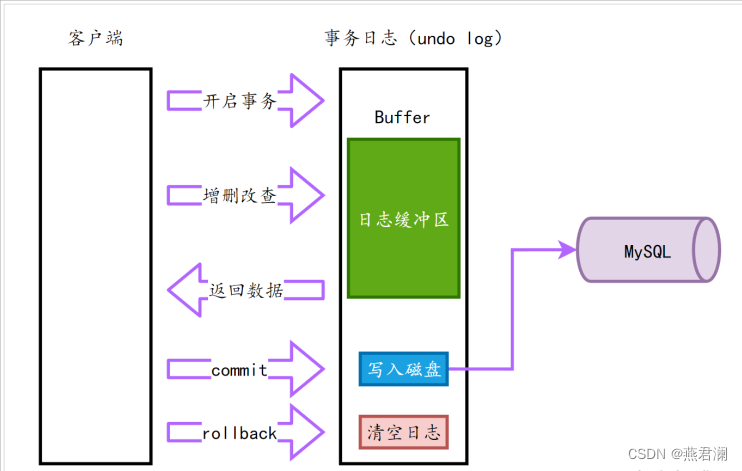
原理解释:
- 如果没有开启事务,用户不适用日志文件,而是直接写到数据库
- 如果查询,数据从表中查询出来以后,经过日志文件加工以后返回
- 如果回滚,清除日志文件,不会写到数据库中
1.6 回滚点
1.6.1 什么是回滚点?
在某些成功的操作完成之后,后续的操作有可能成功有可能失败,但是不管成功还是失败,前面操作都已经成功,可以在当前成功的位置设置一个回滚点,可以供后续失败操作返回到该位置,而不是返回所有操作,这个点称之为回滚点。
1.6.2 操作语句
| 回滚点的操作语句 | 语句 |
| 设置回滚点 | savepoint 名字 |
| 回到回滚点 | rollback to 名字 |
1.6.3 具体操作
- 将数据还原到1000
- 开启事务
- 让a账号减2次钱,每次10块
- 设置回滚点:savepoint p1;
- 让a账号减2次钱,每次10块
- 回到回滚点:rollback to p1;
- 分析执行过程
-- 开启事务
begin;
-- a账号-10元
update account set money=money-10 where name='a';
-- a账号-10元
update account set money=money-10 where name='a';
-- 设置保存点
savepoint p1;
-- 查询账号信息
select * from account;
-- a账号-10元
update account set money=money-10 where name='a';
-- a账号-10元
update account set money=money-10 where name='a';
-- 回滚到指定的保存点
rollback to p1;
-- 查询账号信息
select * from account;总结:设置回滚点可以让我们在失败的时候回到回滚点,而不是回到事务开启的时候。
1.7 事务的隔离级别
1.7.1 并发访问的三个问题
当同时有多个用户在访问同一张表中的记录,每个用户在访问的时候都市一个单独的事务。
事务在操作时的理想状态是:事务之间不应该相互影响,实际应用的时候会引发下面三种问题。应尽量避免这些问题的发生,通过数据库本身的功能去避免,设置不同的隔离级别。
- 脏读: 一个事务(用户)读取到了另一个事务没有提交的数据
- 不可重复读:一个事务多次读取同一条记录,出现读取数据不一致的情况。一般因为另一个事务更新了这条记录而引发的
- 幻读:在一次事务中,多次读取到的条数不一致
1.7.2 设置隔离级别
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 |
| 2 | 读已提交 | read committed | 否 | 是 | 是 |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是/否 |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
- 隔离级别越高,安全性就越高,性能越低
- 隔离级别越低,安全性就越低,性能越高
- 作用:
1)Read uncommitted (读未提交): 简称RU隔离级别,所有事务中的并发访问问题都会发生,可以读取到其他事务没有提交的数据
2)Read committed (读已提交):简称RC隔离级别,会引发不可重复读和幻读的问题,读取的永远是其他事务提交的数据
3)Repeatable read (可重复读):简称RR隔离级别,会引发幻读的问题,一次事务读取到的同一行数据,永远是一样
4)Serializable (串行化): 可以避免所有事务产生的并发访问的问题 效率及其低下
- 查询全局事务隔离级别
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)- 设置全局事务隔离级别
set global transaction isolation level 隔离级别; -- 服务器只要不关闭一直有效Tips:修改隔离级别后需要重启会话,因为@@表示全局
1.7.4 脏读
在并发情况下,一个事务读取到另一个事务没有提交的数据,这个数据称之为脏数据,此次读取也称之为脏读。
只有read uncommitted(读未提交)的隔离级别才会引发脏读。
- 将MySQL的事务隔离级别设置为read uncommitted
mysql> set global transaction isolation level read uncommitted;
Query OK, 0 rows affected (0.00 sec)- 将数据还原:

- 脏读演示:
| session-01 | session-02 |
| begin; | |
| begin; | |
| select * from account where name='a'; | |
| update account set money=money-200 where name='a'; | |
| select * from account where name='a'; | |
| rollback; |
观察变化:

- 解决脏读:将全局的隔离级别进行提升
1.7.5 不可重复读
- 概念:在同一个事务中的多次差应该出现相同的结果,两次读取不能出现不同的结果。
- 和脏读的区别:脏读是读取前一事务未提交的脏数据,不可重复读是从夫读取了前一事务已提交的数据,当两次读取的结果不同。
应用场景:比如银行程序需要将查询结果分别输出到电脑屏幕和写到文件中,结果在一个事务中针对输出的目的地,两次输出结果却不一致,导致文件和屏幕中的结果不同,银行工作人员就不知道以哪个为准了。
- 不可重复读演示
将数据进行恢复,并关闭窗口重新登录。
update account set money=1000;| session-01 | session-02 |
| begin; | |
| begin; | |
| select * from account where name='a'; | |
| update account set money=money-200 where name='a'; | |
| select * from account where name='a'; | |
| rollback; |
观察变化:

两次查询输出的结果不同,到底哪次是对的?
- 解决不可重复读:为了保证多次查询数据一致,必须使用repeatable read隔离级别
-- 设置隔离级别为repeatable read
set global transaction isolation level repeatable read;1.7.6 幻读
- 概念:一次事务多次读取到的条数不一致而引发的问题。
在InnoDB(暂时理解是MySQL)中幻读在很多地方都得到了解决,但在一些特殊的情况下,还是会引发幻读问题;
为什么有的情况下能解决,有的情况下解决不了?因为一次事务多次读取到的条数不一致会导致有很多情况发生!
- 幻读解决情况-1
还原数据:
update account set money=1000;
-- 设置隔离级别为repeatable read
set global transaction isolation level repeatable read;记得重启客户端
| session-01 | session-02 |
| begin; | |
| begin; | |
| select * from account; | |
| insert into account values(3,'c',1000); | |
| commit; | |
| select * from account; // 查询发现还是两条,幻读问题达到解决 |
观察变化:

查询发现还是两条,幻读问题达到解决。
- 幻读解决情况2
还原数据
| session-01 | session-02 |
| begin; | |
| begin; | |
| select sum(money) from account; // 查询表中的总金额,2000 | |
| insert into account values(3,'c',1000); | |
| commit; | |
| select sum(money) from account; // 再次查询总金额,仍是2000,幻读问题达到解决 |
观察变化:

再次查询总金额,仍是2000,幻读问题达到解决。
- 幻读问题出现情况-1
还原数据
| session-01 | session-02 |
| begin; | |
| begin; | |
| select * from account; | |
| insert into account values(3,'c',1000); | |
| commit; | |
| select * from account; // 查询发现还是两条 | |
| update account set money=0; // 发现修改记录为3条 | |
| select * from account; // 再次查询记录发现变为了3条,出现幻读 |
观察变化:

- 特殊情况
还原数据
| session-01 | session-02 |
| begin; | |
| begin; | |
| select * from account; | |
| select * from account; | |
| insert into account values(3,'c',1000); | |
| commit; | |
| select * from account; // 再次查询,依旧没有id为3的记录 | |
| insert into account values(3,'c',1000); // 查询不到,但又插入不进去 |
观察变化:

Tips:严格意义来说,上述案例是MySQL的快照机制导致的,不能算幻读;关于幻读我们理解概念就行,即:两次读取到的条数不一致!这就是幻读
1.7.7 串行化
- 概念:
想要彻底的解决幻读,那么我们必须再把隔离级别调高,数据库的最高隔离级别为串行化(serializable)。
串行化相当于锁表操作,即一个事务如果操作了某张表(增加、删除、修改),那么就不允许其他任何事务操作此表,也不允许查询,等第一个事务提交或者回滚之后才可以操作,这样做效率及其低下,因此一般不会采用serializable隔离级别。
- 串行化演示
-- 还原数据
truncate account;
insert into account(name, money) values('a', 1000), ('b', 1000);
set global transaction isolation level serializable; -- 设置隔离级别为串行化| session-01 | session-02 |
| begin; | |
| begin; | |
| update account set money=money-500 where name='a'; | |
| select * from account; // 查询记录发现卡住了 |


在串行化隔离级别中,相当于锁表的操作,在一个事务对表进行任何的insert/update/delete等操作时,其他事务均不可对其进行操作;在读写上是串行的,并发能力极差;














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









