






注:题目的题号都是LeetCode的,包括剑指的题号也是LeetCode上的剑指Offer专题里的。标★的题相对来说是最高频的,需要重点掌握,时间有限也可以先刷这些题。
另:图床我是随便找的免费图床,初次打开图片可能要加载很久,也可能有些会加载不出来,可以手动复制图片地址查看。
算法基础
几点要求
- 做到给别人讲懂;
- 会自己写测试用例;
- 要能自己实现ArrayList,栈,队列,堆等基础的数据结构;能手写快排,堆排,归并排序。
数据结构与算法基础
-
Array和List的相互转换:
Array转List:使用java.util.Arrays工具类中的asList()方法。
String[] arrays = new String[]{“a”, “b”, “c”};
List listStrings = Arrays.asList(arrays);
List转Array:使用List中的toArray()方法。
String[] sss = listStrings.toArray(new String[listStrings.size()]);
-
二叉搜索树的中序遍历为递增序列。
-
String的compareTo()方法:
compareTo() 方法用于两种方式的比较:
- 字符串与对象进行比较。
- 按字典顺序比较两个字符串。
语法:int compareTo(Object o) 或 int compareTo(String anotherString)。
返回值:返回值是整型,它是先比较对应字符的大小(ASCII码顺序),如果第一个字符和参数的第一个字符不等,结束比较,返回他们之间的差值,如果第一个字符和参数的第一个字符相等,则以第二个字符和参数的第二个字符做比较,以此类推,直至比较的字符或被比较的字符有一方结束。
- 如果参数字符串等于此字符串,则返回值 0;
- 如果此字符串小于字符串参数,则返回一个小于 0 的值;
- 如果此字符串大于字符串参数,则返回一个大于 0 的值。
-
substring包左不包右。
-
位运算:

正常右移是正数右移,高位用0补,负数右移,高位用1补,对于无符号右移 >>> ,当负数使用无符号右移时,用0进行补位(自然而然的,就由负数变成了正数了) 。
- Java 获取长度方法:
- java中的length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了length这个属性;
- java中的length()方法是针对字符串String说的,如果想看这个字符串的长度则用到length()这个方法;
- java中的size()方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看。
-
数学操作:
pop operation:
pop = x % 10;
x /= 10;
push operation:
temp = rev * 10 + pop;
rev = temp;
-
快速排序和归并排序的区别:
- 快排是先整体后局部,归排是先局部后整体;
- 快排是不稳定的,归排是稳定的;
- 快排平均时间复杂度为O(NlogN),最坏能达到O(N^2),归排最好最坏都为O(NlogN);
- 快排空间复杂度为O(1),归排在使用数组时空间复杂度为O(N)(链表上为O(1))。
-
堆的初始化:
new PriorityQueue<>((v1, v2) -> v1.val - v2.val) 实现最小堆;
new PriorityQueue<>((v1, v2) -> v2.val - v1.val) 实现最大堆。
相当于 Queue queue = new PriorityQueue<>(new Comparator() {
@Override
public int compare(ListNode o1, ListNode o2) {
return o1.val - o2.val;
}
});
Java默认为小顶堆。
-
LinkedList 的 remove() 方法和 add() 方法都是默认对尾部进行操作,等同于 addLast() 和 removeLast()。
-
copyOf() 方法:
函数原型:copyOf(oringinal, int newlength);
oringinal:原数组,newlength:复制数组的长度;
这个方法是从原数组的起始位置开始复制,复制的长度是newlength。相比较于前一种,这种相当于特殊的情况,只能从原数组的起始位置开始复制。
copyOfRange()方法:
函数原型:copyOfRange(oringinal,int from, int to);
该方法是从original数组的下标from开始复制,到下标to结束。
注意:copyOfRange() 方法包左不包右!
数组
Sorted Array
★ 88.合并两个有序数组
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。
说明:
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。
你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。

思路:
如果我们从头往后进行比较,需要额外空间,这是由于在从头改变 nums1 的值时,需要把 nums1 中的元素存放在其他位置。所以我们可以从后往前比较,先添加较大的数。
复杂度分析:
时间复杂度 O(m+n);
空间复杂度 O(1)。
代码:
class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
int i = m - 1, j = n - 1;
int index = m + n - 1;
while(i >= 0 && j >= 0) {
if(nums1[i] > nums2[j]) nums1[index--] = nums1[i--];
else nums1[index--] = nums2[j--];
}
while(i >= 0) {
nums1[index--] = nums1[i--];
}
while(j >= 0) {
nums1[index--] = nums2[j--];
}
}
}
4.寻找两个正序数组的中位数
给定两个大小为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。
请你找出这两个正序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。
你可以假设 nums1 和 nums2 不会同时为空。

思路:
要求的时间复杂度为 O(log(m + n)),很自然的想到二分法。虽然不能直接应用,但我们仍然可以使用这种思想。

可以看到,比较 A[k/2−1] 和 B[k/2−1] 之后,可以排除 k/2 个不可能是第 k 小的数,查找范围缩小了一半。同时,我们将在排除后的新数组上继续进行二分查找,并且根据我们排除数的个数,减少 k 的值,这是因为我们排除的数都不大于第 k 小的数。
有以下三种情况需要特殊处理:
- 如果 A[k/2−1] 或者 B[k/2−1] 越界,那么我们可以选取对应数组中的最后一个元素。在这种情况下,我们必须根据排除数的个数减少 k 的值,而不能直接将 k 减去 k/2。
- 如果一个数组为空,说明该数组中的所有元素都被排除,我们可以直接返回另一个数组中第 k 小的元素。
- 如果 k=1,我们只要返回两个数组首元素的最小值即可。
复杂度分析:
时间复杂度:O(log(m+n)),其中 m 和 n 分别是数组 nums1 和 nums2 的长度。初始时有 k=(m+n)/2 或 k=(m+n)/2+1,每一轮循环可以将查找范围减少一半,因此时间复杂度是 O(log(m+n))。
空间复杂度:O(1)。
代码:
class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int len = nums1.length + nums2.length;
if(len % 2 == 1) { //和为奇数
return findKth(nums1, 0, nums2, 0, len / 2 + 1);
} else { //和为偶数
return (findKth(nums1, 0, nums2, 0, len / 2) +
findKth(nums1, 0, nums2, 0, len / 2 + 1)) / 2.0;
}
}
private int findKth(int[] nums1, int start1, int[] nums2, int start2, int k) {
//nums1空了
if(start1 >= nums1.length) {
return nums2[start2 + k - 1];
}
//nums2空了
if(start2 >= nums2.length) {
return nums1[start1 + k - 1];
}
//k无法再分
//k = 1时,表示要在两个sorted arrays找第一个数,即所有数中的最小的那个数
if(k == 1) {
return Math.min(nums1[start1], nums2[start2]);
}
//nums1的第k/2个数
//同时判断是否越界
int value1 = start1 + k / 2 - 1 < nums1.length ? nums1[start1 + k / 2 - 1] :
Integer.MAX_VALUE;
//nums2的第k/2个数
int value2 = start2 + k / 2 - 1 < nums2.length ? nums2[start2 + k / 2 - 1] :
Integer.MAX_VALUE;
//扔掉较小的一部分
//start1 = start1 + k / 2可以直接扔掉前k/2个数,记得更新k = k - k / 2
if(value1 < value2) {
return findKth(nums1, start1 + k / 2, nums2, start2, k - k / 2);
} else {
return findKth(nums1, start1, nums2, start2 + k / 2, k - k / 2);
}
}
}
Two Pointers
★ 15.三数之和
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。

思路:
- 首先对数组进行排序,排序后固定一个数 nums[i],再使用左右指针指向 nums[i] 后面的两端,数字分别为 nums[L] 和 nums[R],计算三个数的和 sum 判断是否满足为 0,满足则添加进结果集;
- 如果 nums[i]大于 0,则三数之和必然无法等于 0,结束循环;
- 如果 nums[i] == nums[i-1],则说明该数字重复,会导致结果重复,所以应该跳过;
- 当 sum == 0 时,nums[L] == nums[L+1] 则会导致结果重复,应该跳过,L++;
- 当 sum == 0 时,nums[R] == nums[R-1] 则会导致结果重复,应该跳过,R−−。
复杂度分析:
时间复杂度:O(N^2),其中 N 是数组 nums 的长度。
代码:
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
if(nums == null || nums.length < 3) return res;
Arrays.sort(nums); //排序
for(int i = 0; i < nums.length; i++) {
if(nums[i] > 0) break; // 如果当前数字大于0,则三数之和一定大于0,所以结束循环
//如果这个数等于上一个数,去重
//注意与下面两个去重的区别,这里使用了 if...continue;
if(i > 0 && nums[i] == nums[i - 1]) continue;
int l = i + 1, r = nums.length - 1;
while(l < r) {
int sum = nums[i] + nums[l] + nums[r];
if(sum == 0) {
res.add(Arrays.asList(nums[i], nums[l], nums[r]));
while(l < r && nums[l] == nums[l + 1]) l++; //去重
while(l < r && nums[r] == nums[r - 1]) r--; //去重
l++;
r--;
} else if(sum < 0) {
l++;
} else {
r--;
}
}
}
return res;
}
}
剑指21. 调整数组顺序使奇数位于偶数前面
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。
思路:双指针法。
考虑定义双指针 i , j 分列数组左右两端,循环执行:
- 指针 i 从左向右寻找偶数;
- 指针 j 从右向左寻找奇数;
- 将偶数 nums[i] 和 奇数 nums[j] 交换。
可始终保证: 指针 i 左边都是奇数,指针 j 右边都是偶数 。

算法流程:
![计算机生成了可选文字: 1.初始化:0j双指针,分别指向数组nums左右两端; 2.循环交换:当一j时跳出; 1.指针遇到奇数则执行=+1跳过,直到找到偶数; 2.指针j遇到偶数则执行j _1跳过,直到找到奇数; 3.交换nums[引和nums》]值; 3.返回值:返回已修改的nums数组。](https://i.loli.net/2020/11/05/yNUjagR2HisremL.png)
复杂度分析:
时间复杂度 O(N) :N 为数组 nums 长度,双指针 i, j 共同遍历整个数组。
空间复杂度 O(1) :双指针 i, j 使用常数大小的额外空间。
代码:
class Solution {
public int[] exchange(int[] nums) {
int i = 0, j = nums.length - 1, tmp;
//当 i = j 时跳出
while(i < j) {
//外层的循环无法控制内层的循环,内层也要判断i < j
//指针 i 遇到奇数则执行 i = i + 1 跳过,直到找到偶数;
while(i < j && (nums[i] % 2) == 1) i++;
//指针 j 遇到偶数则执行 j = j - 1 跳过,直到找到奇数;
while(i < j && (nums[j] % 2) == 0) j--;
//交换nums[i]和nums[j]的值;
tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
return nums;
}
}
剑指57. 和为s的两个数字
输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得它们的和正好是s。如果有多对数字的和等于s,则输出任意一对即可。

思路:
双指针法。
算法流程:
-
初始化: 双指针 i, j 分别指向数组 nums 的左右两端(俗称对撞双指针)。
-
循环搜索当双指针相遇时跳出;
-
- 计算和 s = nums[i] + nums[j] ;
- 若 s > targets,则指针 j 向左移动,即执行 j = j - 1 ;
- 若 s < targets,则指针 i 向右移动,即执行 i = i + 1 ;
- 若 s = targets,立即返回数组 [nums[i], nums[j]] ;
-
返回空数组,代表无和为 target 的数字组合。
复杂度分析:
时间复杂度 O(N):N 为数组 nums 的长度;双指针共同线性遍历整个数组。
空间复杂度 O(1):变量 i, j 使用常数大小的额外空间。
代码:
class Solution {
public int[] twoSum(int[] nums, int target) {
int i = 0, j = nums.length - 1;
while(i < j) {
int s = nums[i] + nums[j];
if(s < target) i++;
else if(s > target) j--;
else return new int[]{nums[i], nums[j]};
}
return new int[0];
}
}
剑指57 - II. 和为s的连续正数序列
输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。

思路:
注意与上道题的区别,上道题是数组下标,这道题直接是数字值。
这道题应该用滑动窗口来做。
- 当窗口的和小于 target 的时候,窗口的和需要增加,所以要扩大窗口,窗口的右边界向右移动
- 当窗口的和大于 target 的时候,窗口的和需要减少,所以要缩小窗口,窗口的左边界向右移动
- 当窗口的和恰好等于 target 的时候,我们需要记录此时的结果。设此时的窗口为 [i, j),那么我们已经找到了一个 i 开头的序列,也是唯一一个 i 开头的序列,接下来需要找 i+1 开头的序列,所以窗口的左边界要向右移动
注意:
- 为了编程的方便,滑动窗口一般表示成一个左闭右开区间;
- 滑动窗口的题要注意右边界的位置,如果是在窗口的下一个位置,则窗口长度为 j - i ;
- 窗口的左边界和右边界永远只能向右移动,而不能向左移动。这是为了保证滑动窗口的时间复杂度是 O(n)。
代码:
class Solution {
public int[][] findContinuousSequence(int target) {
int i = 1, j = 1, sum = 0; //滑动窗口初始化
List<int[]> res = new ArrayList<>();
while(i <= target / 2) {
if(sum < target) {
//右边界向右移动
sum += j;
j++;
} else if(sum > target) {
//左边界向右移动
sum -= i;
i++;
} else {
//记录结果
int[] cur = new int[j - i];
for(int k = i; k < j; k++) {
cur[k - i] = k;
}
res.add(cur);
//左边界继续向右移动,记录下一组数
sum -= i;
i++;
}
}
return res.toArray(new int[res.size()][]); //动态申请二维数组
}
}
Subarray
碰到 Subarray 相关的问题,一定要想到前缀和 Prefix Sum。
★ 121.买卖股票的最佳时机(同剑指63. 股票的最大利润)
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润。
注意:你不能在买入股票前卖出股票。
![计算机生成了可选文字: 示例1: 输入: [7丿1丿5丿3丿6丿4] 输出: 5 解释:在第2天(股票价格=1)的时候买入,在第5天(股票价 示例2: 输入: 输出: 格=6)的时候卖出,最大利氵闰 5 主意利氵闰不能是7一1=6丿因为卖出价格需要大于买入价格; 同时,你不能在买入前卖出股票 [7丿6丿4丿3丿1] 9 解释:在这种情况下丿没有交易完成丿所以最大利氵闰为9。](https://i.loli.net/2020/11/05/ICGaU1A9yfWr6mX.png)
代码:
class Solution {
public int maxProfit(int[] prices) {
int cost = Integer.MAX_VALUE, profit = 0;
for(int price : prices) {
cost = Math.min(cost, price);
profit = Math.max(profit, price - cost);
}
return profit;
}
}
★ 122.买卖股票的最佳时机 II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
![计算机生成了可选文字: 示例1: 输入:[7丿1丿5丿3丿6丿4] 输出:7 解释:在第2天(股票价格=1)的时候买入,在第3天(股票价 格=5)的时候卖出丿这笔交易所能获得利氵闰=5一1=4 随后,在第4天(股票价格=3)的时候买入,在第5天 (股票价格=6)的时候卖出丿这笔交易所能获得利润=6一3 3 示例2: 输入: [1丿2丿3丿‰5] 输出: 4 解释:在第1天(股票价格=1)的时候买入,在第5天(股票 价格=5)的时候卖出丿这笔交易所能获得利润= 5一1=4 注意你不能在第1天和第2天接连购买股票,之后再将它们 卖出。 因为这样属于同时参与了多笔交易,你必须在再次购买前出售 掉之前的股票](https://i.loli.net/2020/11/05/k5NUpXDLVEtzWsd.png)
思路:

算法流程:

时间复杂度 O(N) : 只需遍历一次price;
空间复杂度 O(1) : 变量使用常数额外空间。
代码:
class Solution {
public int maxProfit(int[] prices) {
int profit = 0;
for(int i = 1; i < prices.length; i++) {
int tmp = prices[i] - prices[i - 1];
if(tmp > 0) profit += tmp;
}
return profit;
}
}
★ 560.和为K的子数组
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
![示 例 1 输 入 : nums [ 1, 1 , 1 J, k : 2 输 出 : 2 。 [ 1 , 1 ] 与 [ 1j1 ] 为 两 种 不 同 的 情 况 。](https://i.loli.net/2020/11/05/krn6qH9pv48LKQw.png)
思路:
前缀和 + 哈希表优化。我们定义 pre[i] 为 [0…i] 里所有数的和,则 pre[i] 可以由 pre[i−1] 递推而来,即:
pre[i]=pre[i−1]+nums[i]
那么「[j…i] 这个子数组和为 k 」这个条件我们可以转化为
pre[i]−pre[j−1]==k
简单移项可得符合条件的下标 j 需要满足
pre[j−1]==pre[i]−k
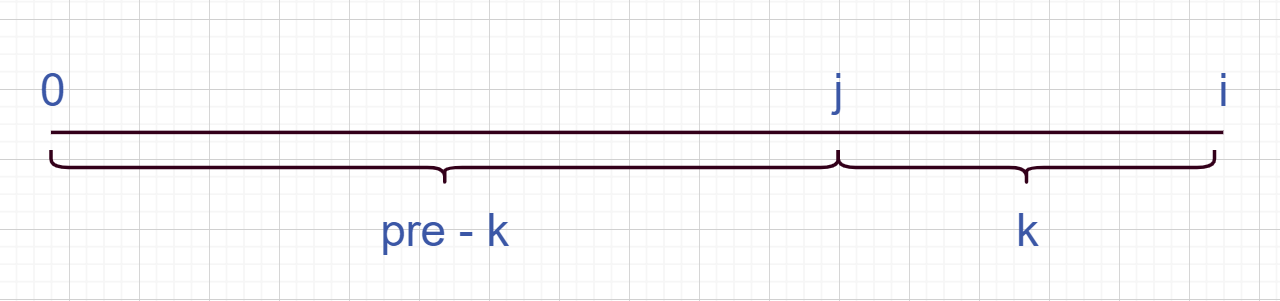
所以我们考虑以 i 结尾的和为 k 的连续子数组个数时只要统计有多少个前缀和为 pre[i]−k 的 pre[j] 即可。我们建立哈希表 mp,以和为键,出现次数为对应的值,记录 pre[i] 出现的次数,从左往右边更新 mp 边计算答案,那么以 i 结尾的答案 mp[pre[i]−k] 即可在 O(1) 时间内得到。最后的答案即为所有下标结尾的和为 k 的子数组个数之和。
需要注意的是,从左往右边更新边计算的时候已经保证了 mp[pre[i]−k] 里记录的 pre[j] 的下标范围是 0≤j≤i 。同时,由于 pre[i] 的计算只与前一项的答案有关,因此我们可以不用建立 pre 数组,直接用 pre 变量来记录 pre[i−1] 的答案即可。
复杂度分析:
时间复杂度:O(n),其中 n 为数组的长度。我们遍历数组的时间复杂度为 O(n),中间利用哈希表查询删除的复杂度均为 O(1),因此总时间复杂度为 O(n)。
空间复杂度:O(n),其中 n 为数组的长度。哈希表在最坏情况下可能有 n 个不同的键值,因此需要 O(n) 的空间复杂度。
代码:
class Solution {
public int subarraySum(int[] nums, int k) {
int count = 0; // 记录符合条件的连续字符串数量
int pre = 0; // 记录前面数字相加之和
// map记录前几个数字之和为K出现相同和的次数为value
HashMap<Integer, Integer> map = new HashMap<>();
// 初始化,刚开始前面没有数字所以为0,次数为1
map.put(0, 1);
for(int i = 0; i < nums.length; i++) {
pre += nums[i];
if(map.containsKey(pre - k)) {
count += map.get(pre - k);
}
map.put(pre, map.getOrDefault(pre, 0) + 1);
}
return count;
}
}
注:Map.getOrDefault(key, defaultValue) 方法,意思就是当 Map 集合中有这个 key 时,就使用这个 key 值,如果没有就使用默认值defaultValue 。
★ 53.最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
![计算机生成了可选文字: 示例: 输入:[一乙1厂3丿‰一1丿乙1丿一5丿4] 输出:6 解释:连续子数组[4厂1丿2丿1]的和最大,为6。](https://i.loli.net/2020/11/05/AtfNperygbnH3ho.png)
思路:
前缀和。
复杂度分析:
时间复杂度:O(N)。
代码:
class Solution {
public int maxSubArray(int[] nums) {
if(nums == null || nums.length == 0) {
return 0;
}
int sum = 0, minSum = 0, max = Integer.MIN_VALUE;
for(int i = 0; i < nums.length; i++) {
sum += nums[i];
max = Math.max(max, sum - minSum);
minSum = Math.min(minSum, sum);
}
return max;
}
}
排序问题
★ 剑指40. 最小的k个数
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
![计算机生成了可选文字: 示例1: 输入: [3丿2丿1],k arr 输出:[1丿2]或者[乙1] 示例2: 输入: 输出:[明 2 arr [1丿乙1], k 1](https://i.loli.net/2020/11/05/gp3Pt9fBwevj7iC.png)
思路:
对于经典TopK问题,有 4 种通用解决方案:
- 快排;
- 堆;
- 二叉搜索树排序;
- 数据范围有限时可以直接计数排序。
方法一:
快排是最高效的。快速排序会递归地排序基准数字左右两侧的数组。而快速选择(quick select)算法的不同之处在于,接下来只需要递归地选择一侧的数组。快速选择算法相当于一个“不完全”的快速排序,因为我们只需要知道最小的 k 个数是哪些,并不需要知道它们的顺序。我们的目的是寻找最小的 k 个数。假设经过一次 partition 操作,枢纽元素位于下标 m,也就是说,左侧的数组有 m 个元素,是原数组中最小的 m 个数。那么:
- 若 k = m,我们就找到了最小的 k 个数,就是左侧的数组;
- 若 k < m ,则最小的 k 个数一定都在左侧数组中,我们只需要对左侧数组递归地 parition 即可;
- 若 k > m,则左侧数组中的 m 个数都属于最小的 k 个数,我们还需要在右侧数组中寻找最小的 k-m 个数,对右侧数组递归地 partition 即可。
复杂度分析:
空间复杂度 O(1),不需要额外空间。
时间复杂度的分析方法和快速排序类似。由于快速选择只需要递归一边的数组,时间复杂度小于快速排序,期望时间复杂度为 O(n),最坏情况下的时间复杂度为 O(n^2)。
代码:
class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
if(arr.length == 0 || k == 0) return new int[0];
// 最后一个参数表示我们要找的是下标为k-1的数
return quickSearch(arr, 0, arr.length - 1, k - 1);
}
private int[] quickSearch(int[] nums, int left, int right, int k) {
// 每快排切分1次,找到排序后下标为j的元素,如果j恰好等于k就返回j以及j左边所有的数
int j = partition(nums, left, right);
if(j == k) return Arrays.copyOf(nums, j + 1);
// 否则根据下标j与k的大小关系来决定继续切分左段还是右段(看哪段包含着k)
return j > k ? quickSearch(nums, left, j - 1, k) : quickSearch(nums, j + 1, right, k);
}
// 快排切分,返回下标j,使得比nums[j]小的数都在j的左边,比nums[j]大的数都在j的右边
private int partition(int[] nums, int left, int right) {
int i = left, j = right, base = nums[left];
while(i != j) {
if(i > j) break;
while(i < j && nums[j] >= base) j--;
while(i < j && nums[i] <= base) i++;
if(i < j) {
int t = nums[i];
nums[i] = nums[j];
nums[j] = t;
}
}
nums[left] = nums[i];
nums[i] = base;
return j;
}
}
方法二:
堆排。保持堆的大小为K,然后遍历数组中的数字,遍历的时候做如下判断:
-
若目前堆的大小小于K,将当前数字放入堆中。
-
否则判断当前数字与大根堆堆顶元素的大小关系,如果当前数字比大根堆堆顶还大,这个数就直接跳过;反之如果当前数字比大根堆堆顶小,先poll掉堆顶,再将该数字放入堆中。
复杂度分析:
由于使用了一个大小为 k 的堆,空间复杂度为 O(k);
入堆和出堆操作的时间复杂度均为 O(logk),每个元素都需要进行一次入堆操作,故算法的时间复杂度为 O(nlogk)。
代码:
class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
if(arr.length == 0 || k == 0) return new int[0];
// 默认是小根堆,实现大根堆需要重写一下比较器。
Queue<Integer> pq = new PriorityQueue<>((v1, v2) -> v2 - v1);
for(int num : arr) {
if(pq.size() < k) pq.offer(num);
else if(num < pq.peek()) {
pq.poll();
pq.offer(num);
}
}
// 返回堆中的元素
int[] res = new int[pq.size()];
int index = 0;
for(int num : pq) {
res[index++] = num;
}
return res;
}
}
两种方法的优劣性比较:
在面试中,另一个常常问的问题就是这两种方法有何优劣。看起来分治法的快速选择算法的时间、空间复杂度都优于使用堆的方法,但是要注意到快速选择算法的几点局限性:
第一,算法需要修改原数组,如果原数组不能修改的话,还需要拷贝一份数组,空间复杂度就上去了。
第二,算法需要保存所有的数据。如果把数据看成输入流的话,使用堆的方法是来一个处理一个,不需要保存数据,只需要保存 k 个元素的最大堆。而快速选择的方法需要先保存下来所有的数据,再运行算法。当数据量非常大的时候,甚至内存都放不下的时候,就麻烦了。所以当数据量大的时候还是用基于堆的方法比较好。
改:若求最大的k个数怎么做?
★ 215.数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
![计算机生成了可选文字: 示例1: 输入: 输出: 示例2: 输入: 输出: 说明: 你可以假设k总是有效的,且1k数组的长度。 [3丿2丿1丿5丿6丿4]和k 5 2 [3丿20丿1丿2丿‰5丿5丿6]和k 4 4](https://i.loli.net/2020/11/05/KHXQBzxbyhscJ4S.png)
思路:与上题几乎完全相同。
方法一:快排。
复杂度分析:
时间复杂度:期望时间复杂度为 O(n),最坏情况下的时间复杂度为 O(n^2)。快速排序的性能和「划分」出的子数组的长度密切相关。直观地理解如果每次规模为 n 的问题我们都划分成 1 和 n - 1,每次递归的时候又向 n - 1 的集合中递归,这种情况是最坏的,时间代价是 O(n ^ 2)。
空间复杂度:O(logn),递归使用栈空间的空间代价的期望为 O(logn)。
代码:
class Solution {
public int findKthLargest(int[] nums, int k) {
return quickSearch(nums, 0, nums.length - 1, nums.length - k);
}
private int quickSearch(int[] nums, int left, int right, int index) {
int target = partition(nums, left, right);
if(target == index) return nums[index];
else if(target > index) return quickSearch(nums, left, target - 1, index);
else return quickSearch(nums, target + 1, right, index);
}
private int partition(int[] nums, int left, int right) {
if(left > right) return 0;
int i = left, j = right, base = nums[left];
while(i != j) {
while(i < j && nums[j] >= base) j--;
while(i < j && nums[i] <= base) i++;
if(i < j) {
int t = nums[i];
nums[i] = nums[j];
nums[j] = t;
}
}
nums[left] = nums[i];
nums[i] = base;
return i;
}
}
方法二:堆排。
复杂度分析:
由于使用了一个大小为 k 的堆,空间复杂度为 O(k);
入堆和出堆操作的时间复杂度均为 O(logk),每个元素都需要进行一次入堆操作,故算法的时间复杂度为 O(nlogk)。
代码:
class Solution {
public int findKthLargest(int[] nums, int k) {
Queue<Integer> pq = new PriorityQueue<>();
for(int num : nums) {
if(pq.size() < k) pq.offer(num);
else if(num > pq.peek()) {
pq.poll();
pq.offer(num);
}
}
return pq.peek();
}
}
剑指45. 把数组排成最小的数
较低频,待做。
剑指51. 数组中的逆序对
较低频,待做。
31.下一个排列
实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须原地修改,只允许使用额外常数空间。
以下是一些例子,输入位于左侧列,其相应输出位于右侧列。
1,2,3 → 1,3,2
3,2,1 → 1,2,3
1,1,5 → 1,5,1
思路:
要将一个数排列成下一个更大的数,改动高位数字,改变后的数一下就会变得很大,不是下一个更大的数。所以改动数字应该从低位开始。举几个例子:
- 一个数为1234。从低位开始,4是最低位,其右边没有数字与其交换。然后3,其右边有4比它大,二者交换就得到下一个更大的排列。
- 一个数为123654。从低位开始,4是最低位,其右边没有数字与其交换。然后5,其右边没有比它大的数,与4交换只会使得排列更小。然后考虑6,与5同理。然后考虑3,可以和后面的4交换得到下一个更大的排列。
从低位开始的意义就是:
- 从int i = nums.length - 2开始,如果nums[i] >= nums[i + 1],说明其前一个元素更大,不做任何处理。这样递推只要nums[i] >= nums[i + 1]成立,说明nums[i]是目前最大的数字,与其右边的数字交换得到的都是更小的排列。
- 当nums[i] < nums[i + 1]时,nums[i]右边的数字有比它大的了,但是为了保证找到下一个更大的排列而不是任意更大排列,还需要通过一个循环去找到其右边比nums[i]大的最小的那个数。从上一条中可以知道,nums[i]右边的元素是递减排列的,所以也只需要从右往左,找到第一个大于nums[i]的元素。
算法流程:
- 需要从后向前找到第一个升序对:如123465->123546中的123465,这样我们就可以确定4的位置i。
- 接下来从后向前找到第一个比4大的数的位置,如123465->123546中的123465,这样我们可以确定5的位置j。
- 再下来将i与j的数进行交换。
- 最后将i+1到最后的位置进行反转。
复杂度分析:
时间复杂度:O(n),在最坏的情况下,只需要对整个数组进行两次扫描。
空间复杂度:O(1),没有使用额外的空间,原地替换足以做到。
代码:
class Solution {
public void nextPermutation(int[] nums) {
int i = nums.length - 2;
//先找到第一个升序对,确定i
while(i >= 0 && nums[i + 1] <= nums[i]) i--;
//如果i没有越界,我们在进行下面的操作,如果越界了,就直接将整个数组反转
if(i >= 0) {
int j = nums.length - 1;
//找到第一个比nums[i]大的数,确定j
while(j >= 0 && nums[j] <= nums[i]) j--;
swap(nums, i, j);
}
reverse(nums, i + 1); //此时 i 已为 -1
}
//将i+1到最后的位置进行反转
private void reverse(int[] nums, int start) {
int i = start, j = nums.length - 1;
while(i < j) {
swap(nums, i, j);
i++;
j--;
}
}
//将i与j的数进行交换
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
矩阵
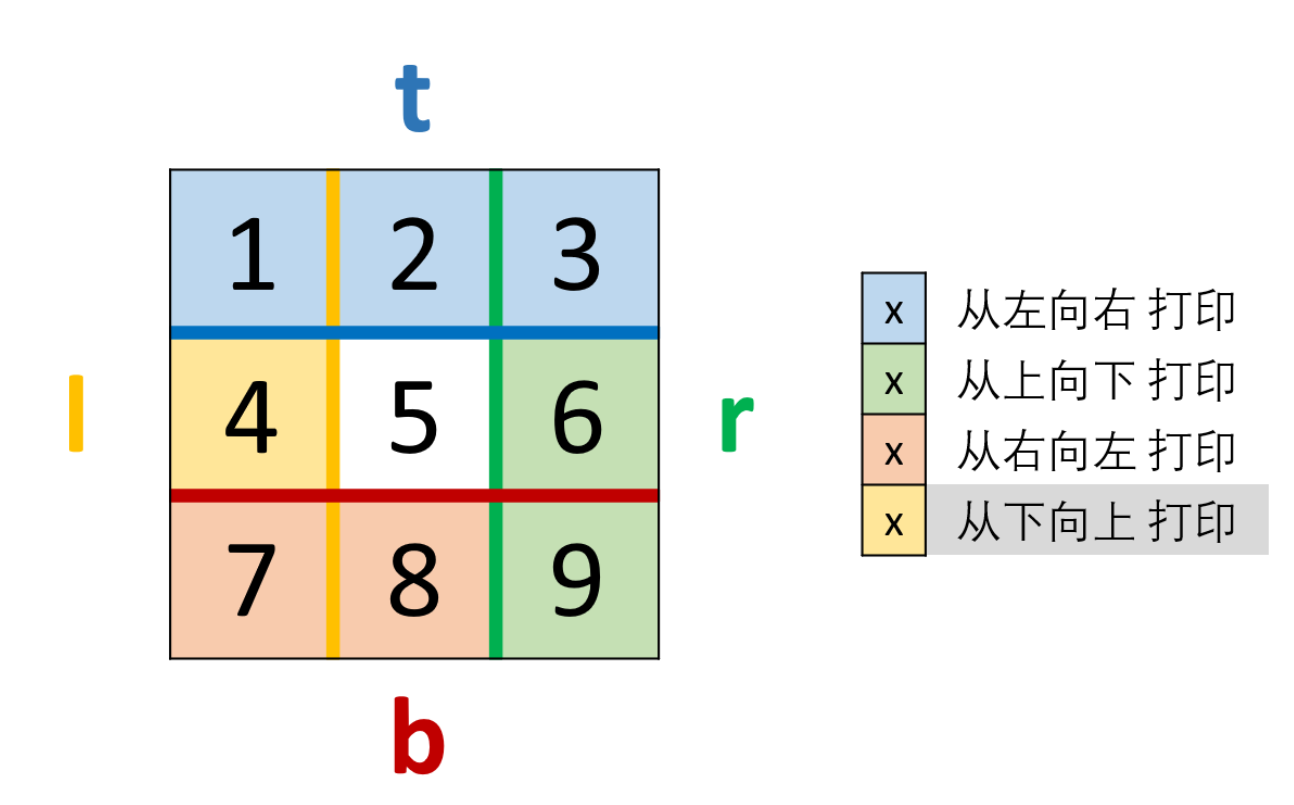
★ 54.螺旋矩阵(同剑指29. 顺时针打印矩阵)
给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。

思路:
根据题目示例 matrix = [[1,2,3],[4,5,6],[7,8,9]] 的对应输出 [1,2,3,6,9,8,7,4,5] 可以发现,顺时针打印矩阵的顺序是 “从左向右、从上向下、从右向左、从下向上” 循环。因此,考虑设定矩阵的“左、上、右、下”四个边界,模拟以上矩阵遍历顺序。
算法流程:
-
空值处理:当 matrix 为空时,直接返回空列表 [] 即可。
-
初始化:矩阵 左、右、上、下 四个边界 l , r , t , b ,用于打印的结果列表 res 。
-
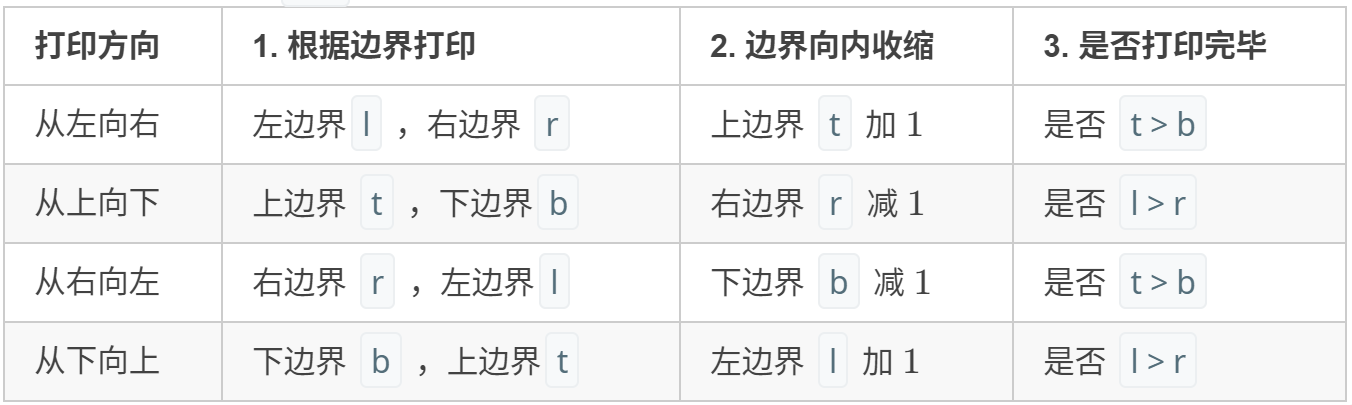
循环打印: “从左向右、从上向下、从右向左、从下向上” 四个方向循环,每个方向打印中做以下三件事 (各方向的具体信息见下表);
-
- 根据边界打印,即将元素按顺序添加至列表 res 尾部;
- 边界向内收缩 1(代表已被打印);(哪个变量何时自增何时自减很重要)
- 判断是否打印完毕(边界是否相遇),若打印完毕则跳出。
-
返回值: 返回 res 即可。
复杂度分析:
时间复杂度 O(MN) : M, N 分别为矩阵行数和列数。
空间复杂度 O(1) : 四个边界 l , r , t , b 使用常数大小的额外空间( res 为必须使用的空间)。
代码:
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> res = new ArrayList<>();
if(matrix == null || matrix.length == 0 || matrix[0].length == 0) return res;
//注意r是列,b是行,不要写反了!
int l = 0, r = matrix[0].length - 1, t = 0, b = matrix.length - 1;
while(true) {
for(int i = l; i <= r; i++) res.add(matrix[t][i]);
if(++t > b) break;
for(int i = t; i <= b; i++) res.add(matrix[i][r]);
if(--r < l) break;
for(int i = r; i >= l; i--) res.add(matrix[b][i]);
if(--b < t) break;
for(int i = b; i >= t; i--) res.add(matrix[i][l]);
if(++l > r) break;
}
return res;
}
}
注:
剑指 29 与本题返回值不同,稍复杂一些。
★ 200.岛屿数量
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。

方法一:DFS。
目标是找到矩阵中 “岛屿的数量” ,上下左右相连的 1 都被认为是连续岛屿。
dfs方法:设目前指针指向一个岛屿中的某一点 (i, j),寻找包括此点的岛屿边界。
-
从 (i, j) 向此点的上下左右 (i+1,j),(i-1,j),(i,j+1),(i,j-1) 做深度搜索。
-
终止条件:
-
- (i, j) 越过矩阵边界;
- grid[i][j] == 0,代表此分支已越过岛屿边界。
-
搜索岛屿的同时,执行 grid[i][j] = ‘0’,即将岛屿所有节点删除,以免之后重复搜索相同岛屿。
主循环:
- 遍历整个矩阵,当遇到 grid[i][j] == ‘1’ 时,从此点开始做深度优先搜索 dfs,岛屿数 count + 1 且在深度优先搜索中删除此岛屿。
最终返回岛屿数 count 即可。
代码:
class Solution {
public int numIslands(char[][] grid) {
int count = 0;
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == '1') {
dfs(grid, i, j);
count++;
}
}
}
return count;
}
private void dfs(char[][] grid, int i, int j) {
//注意是 >=
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length ||
grid[i][j] == '0') return;
grid[i][j] = '0';
dfs(grid, i + 1, j);
dfs(grid, i - 1, j);
dfs(grid, i, j + 1);
dfs(grid, i, j - 1);
}
}
★ 695.岛屿的最大面积
给定一个包含了一些 0 和 1 的非空二维数组 grid 。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)

思路同上题。
代码:
class Solution {
public int maxAreaOfIsland(int[][] grid) {
int res = 0;
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == 1) {
res = Math.max(res, dfs(grid, i, j));
}
}
}
return res;
}
private int dfs(int[][] grid, int i, int j) {
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length ||
grid[i][j] == 0) return 0;
grid[i][j] = 0;
int num = 1; //默认num应为1
num += dfs(grid, i + 1, j);
num += dfs(grid, i - 1, j);
num += dfs(grid, i, j + 1);
num += dfs(grid, i, j - 1);
return num;
}
}
剑指04. 二维数组中的查找
在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。

思路:
若使用暴力法遍历矩阵 matrix ,则时间复杂度为 O(N*M) 。暴力法未利用矩阵 “从上到下递增、从左到右递增” 的特点,显然不是最优解法。
本题解利用矩阵特点引入标志数,并通过标志数性质降低算法时间复杂度。
- 标志数引入:此类矩阵中左下角和右上角元素有特殊性,称为标志数。
左下角元素:为所在列最大元素,所在行最小元素。
右上角元素:为所在行最大元素,所在列最小元素。
- 标志数性质: 将 matrix 中的左下角元素(标志数)记作 flag ,则有:
若 flag > target ,则 target 一定在 flag 所在行的上方,即 flag 所在行可被消去。
若 flag < target ,则 target 一定在 flag 所在列的右方,即 flag 所在列可被消去。
算法流程: 根据以上性质,设计算法在每轮对比时消去一行(列)元素,以降低时间复杂度。
-
从矩阵 matrix 左下角元素(索引设为 (i, j) )开始遍历,并与目标值对比:
-
- 当 matrix[i][j] > target 时:行索引向上移动一格(即 i–),即消去矩阵第 i 行元素;
- 当 matrix[i][j] < target 时:列索引向右移动一格(即 j++),即消去矩阵第 j 列元素;
- 当 matrix[i][j] == target 时:返回 true 。
-
若行索引或列索引越界,则代表矩阵中无目标值,返回 false 。
复杂度分析:
时间复杂度 O(M+N) :其中,N 和 M 分别为矩阵行数和列数,此算法最多循环 M+N 次。
空间复杂度 O(1) : i, j 指针使用常数大小额外空间。
代码:
class Solution {
public boolean findNumberIn2DArray(int[][] matrix, int target) {
//从左下角开始
//二维数组行数为matrix.length,列数为matrix[0].length
int i = matrix.length - 1, j = 0;
while(i >= 0 && j < matrix[0].length) {
if(matrix[i][j] > target) i--; //行索引向上移动一格
else if(matrix[i][j] < target) j++; //列索引向右移动一格
else return true;
}
return false;
}
}
其他
★ 56.合并区间
给出一个区间的集合,请合并所有重叠的区间。

思路:
先根据区间的起始位置排序,再进行 n -1 次 两两合并。
复杂度分析:
时间复杂度:O(nlogn),其中 n 为区间的数量。除去排序的开销,我们只需要一次线性扫描,所以主要的时间开销是排序的 O(nlogn)。
空间复杂度:O(logn),其中 n 为区间的数量。这里计算的是存储答案之外,使用的额外空间。O(logn) 即为排序所需要的空间复杂度。
代码:
class Solution {
public int[][] merge(int[][] intervals) {
//先按照区间起始位置排序
Arrays.sort(intervals, (v1, v2) -> v1[0] - v2[0]);
int[][] res = new int[intervals.length][2];
int idx = -1;
for(int[] interval : intervals) {
//如果集合是空的,或者当前区间的起始位置 > 结果数组中最后区间的终止位置,
//则不合并,直接将当前区间加入结果数组。
if(idx == -1 || interval[0] > res[idx][1]) {
res[++idx] = interval;
} else {
//反之将当前区间合并至结果数组的最后区间(将两区间的右端进行比较取较大者)
res[idx][1] = Math.max(res[idx][1], interval[1]);
}
}
//res数组长度是intervals.length,最后copy才能削掉多的空余位置([0,0])
return Arrays.copyOf(res, idx + 1);
}
}
189.旋转数组
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。

我们可以用一个额外的数组来将每个元素放到正确的位置上,也就是原本数组里下标为 i 的我们把它放到 (i + k) % 数组长度 的位置。然后把新的数组拷贝到原数组中。
复杂度分析:
时间复杂度:O(n)。将数字放到新的数组中需要一遍遍历,另一边来把新数组的元素拷贝回原数组。
空间复杂度:O(n)。另一个数组需要原数组长度的空间。
代码:
class Solution {
public void rotate(int[] nums, int k) {
int len = nums.length;
int[] a = new int[len];
for(int i = 0; i < len; i++) {
a[(i + k) % len] = nums[i];
}
for(int i = 0; i < len; i++) {
nums[i] = a[i];
}
}
}
方法二:反转
这个方法基于这个事实:当我们旋转数组 k 次, k % n 个尾部元素会被移动到头部,剩下的元素会被向后移动。
在这个方法中,我们首先将所有元素反转。然后反转前 k 个元素,再反转后面 n − k 个元素,就能得到想要的结果。
例:假设 n = 7,k = 3 。
原始数组: 1 2 3 4 5 6 7
反转所有数字后: 7 6 5 4 3 2 1
反转前 k 个数字后: 5 6 7 4 3 2 1
反转后 n-k 个数字后: 5 6 7 1 2 3 4 --> 结果
复杂度分析:
时间复杂度:O(n)。n 个元素被反转了总共 3 次。
空间复杂度:O(1)。没有使用额外的空间。
代码:
class Solution {
public void rotate(int[] nums, int k) {
int len = nums.length;
k %= len;
reverse(nums, 0, len - 1);
reverse(nums, 0, k - 1); //注意下标,反转前 k 个数为 0 到 k - 1
reverse(nums, k, len - 1);
}
//反转头尾两个数
private void reverse(int[] nums, int start, int end) {
while(start < end) {
int tmp = nums[start];
nums[start] = nums[end];
nums[end] = tmp;
start++;
end--;
}
}
}
41.缺失的第一个正数
给你一个未排序的整数数组,请你找出其中没有出现的最小的正整数。
![计算机生成了可选文字: 示例1: 输入: [1丿2丿明 输出. 3 示例2: 输入: [3丿‰一11] 输出. 2 示例3: 输入: [7丿8丿9丿11丿12] 输出. 1](https://i.loli.net/2020/11/05/AzZ1dWS5YJaPMHk.png)
思路:
- 由于题目要求我们「只能使用常数级别的空间」,而要找的数一定在 [1, N + 1] 左闭右闭(这里 N 是数组的长度)这个区间里。因此,我们可以就把原始的数组当做哈希表来使用。事实上,哈希表其实本身也是一个数组;
- 我们要找的数就在 [1, N + 1] 里,最后 N + 1 这个元素我们不用找。因为在前面的 N 个元素都找不到的情况下,我们才返回 N + 1;
- 那么,我们可以采取这样的思路:就把 1 这个数放到下标为 0 的位置, 2 这个数放到下标为 1 的位置,按照这种思路整理一遍数组。然后我们再遍历一次数组,第 1 个遇到的它的值不等于下标的那个数,就是我们要找的缺失的第一个正数。
- 这个思想就相当于我们自己编写哈希函数,这个哈希函数的规则特别简单,那就是数值为 i 的数映射到下标为 i - 1 的位置。

复杂度分析:
时间复杂度:O(N),这里 N 是数组的长度。
说明:while 循环不会每一次都把数组里面的所有元素都看一遍。如果有一些元素在这一次的循环中被交换到了它们应该在的位置,那么在后续的遍历中,由于它们已经在正确的位置上了,代码再执行到它们的时候,就会被跳过。
最极端的一种情况是,在第 1 个位置经过这个 while 就把所有的元素都看了一遍,这个所有的元素都被放置在它们应该在的位置,那么 for 循环后面的部分的 while 的循环体都不会被执行。
平均下来,每个数只需要看一次就可以了,while 循环体被执行很多次的情况不会每次都发生。这样的复杂度分析的方法叫做均摊复杂度分析。
最后再遍历了一次数组,最坏情况下要把数组里的所有的数都看一遍,因此时间复杂度是 O(N)。
空间复杂度:O(1)。
代码:
class Solution {
public int firstMissingPositive(int[] nums) {
int len = nums.length;
for(int i = 0; i < len; i++) {
while(nums[i] > 0 && nums[i] <= len && nums[nums[i] - 1] != nums[i]) {
swap(nums, nums[i] - 1, i);
}
}
for(int i = 0; i < len; i++) {
if(nums[i] != i + 1) {
return i + 1;
}
}
return len + 1;
}
void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}
链表
链表基本操作
增删改
剑指18. 删除链表的节点
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。返回删除后的链表的头节点。
思路:
双指针法。需要额外考虑一个边界条件:当要删除的节点为头节点时,直接返回头节点的下一个节点。
代码:
class Solution {
public ListNode deleteNode(ListNode head, int val) {
if(head.val == val) return head.next;
ListNode pre = null;
ListNode cur = head;
while(cur != null) {
if(cur.val == val) {
pre.next = cur.next;
}
pre = cur;
cur = cur.next;
}
return head;
}
}
83. 删除排序链表中的重复元素
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
思路:
- 指定 cur 指针指向头部 head;
- 当 cur 和 cur.next 的存在为循环结束条件,当二者有一个不存在时说明链表没有去重复的必要了;
- 当 cur.val 和 cur.next.val 相等时说明需要去重,则将 cur 的下一个指针指向下一个的下一个,这样就能达到去重复的效果;
- 如果不相等则 cur 移动到下一个位置继续循环;
- 时间复杂度:O(n)。
代码:
class Solution {
public ListNode deleteDuplicates(ListNode head) {
ListNode cur = head;
while(cur != null && cur.next != null) {
if(cur.val == cur.next.val) {
cur.next = cur.next.next;
} else {
cur = cur.next;
}
}
return head;
}
}
反转
★ 206.反转链表(同剑指24. 反转链表)
反转一个单链表。

代码:
迭代:
class Solution {
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while(cur != null) {
ListNode tmp = cur.next; //暂存指针
cur.next = pre; //将指针反转
pre = cur;
cur = tmp; //继续向后遍历
}
return pre; //最后的头节点为pre
}
}
递归:
class Solution {
public ListNode reverseList(ListNode head) {
//递归终止条件,只有一个节点时无需反转
if(head == null || head.next == null) return head;
ListNode tmp = head.next;
head.next = null;
ListNode newHead = reverseList(tmp);
tmp.next = head;
return newHead;
}
}
两者时间复杂度均为O(N),但迭代空间复杂度为O(1),递归空间复杂度为O(N)。
找中点
★ 876.链表的中间结点
给定一个带有头结点 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
![示 例 1 : 输 入 : [ 1 , 乙 4 师 ] 糴 出 : 此 列 表 中 的 结 点 3 ( 序 列 化 形 式 : [ 3 , ‰ 5 ] ) 返 回 的 结 点 值 为 3 。 ( 测 评 系 统 对 该 结 点 序 列 化 表 述 是 [ 3J4J5 ] ) 。 注 , 我 们 返 回 了 一 个 ListN0de 类 型 的 对 象 ans , 这 样 ' ans.val 3, ans.next.val = 4, ans.next.next.val 及 ans.next.next.next = NULL. 示 例 2 : 输 入 : [ 1 , 2 , 3 , 4J5 詎 ] 输 出 : 此 列 表 中 的 结 点 4 ( 序 列 化 形 式 : [ ‰ 习 6]) 由 于 该 列 表 有 两 个 中 间 结 点 , 值 分 别 为 3 和 4 , 我 们 返 回 第 二 个 结 点 。](https://i.loli.net/2020/11/05/FTCtyPqvJOZsjwN.png)
思路:
关于链表找中点,若有两个中间节点,要想偏左,则应设 fast = head.next ;若想偏右,则应设 fast = head 。
代码:
class Solution {
public ListNode middleNode(ListNode head) {
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
}
找交点
★ 剑指52. 两个链表的第一个公共节点
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
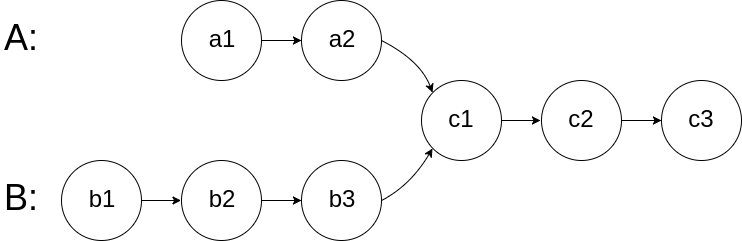
在节点 c1 开始相交。
思路:
两个链表的节点和相同,可以利用这条性质。
我们使用两个指针 a,b 分别指向两个链表 headA,headB 的头结点,然后同时分别逐结点遍历,当 a 到达链表 headA 的末尾时,重新定位到链表 headB 的头结点;当 b 到达链表 headB 的末尾时,重新定位到链表 headA 的头结点。这样,当它们相遇时,所指向的结点就是第一个公共结点。
代码:
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode a = headA;
ListNode b = headB;
while(a != b) {
if(a == null) a = headB;
else a = a.next;
if(b == null) b = headA;
else b = b.next;
}
return a;
}
}
归并
148.排序链表
在 O(nlogn) 时间复杂度和常数级空间复杂度下,对链表进行排序。
思路:

代码:
class Solution {
public ListNode sortList(ListNode head) {
if(head == null || head.next == null) return head; //返回head,不是null!
ListNode mid = findMid(head);
ListNode right = sortList(mid.next); //对右半链表进行排序
mid.next = null; //断开右半链表(mid分到了左边)
ListNode left = sortList(head); //对左半链表进行排序
return merge(left, right);
}
//找链表的中点
private ListNode findMid(ListNode head) {
ListNode slow = head, fast = head.next; //fast一定要写成head.next,这样mid偏左
while(fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
}
return slow;
}
//归并排序
private ListNode merge(ListNode node1, ListNode node2) {
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while(node1 != null && node2 != null) {
if(node1.val < node2.val) {
tail.next = node1;
node1 = node1.next;
} else {
tail.next = node2;
node2 = node2.next;
}
tail = tail.next;
}
if(node1 != null) {
tail.next = node1;
} else {
tail.next = node2;
}
return dummy.next;
}
}
Dummy Node
凡是链表结构发生变化的(也就是当需要返回的链表的头不确定的时候),都需要 Dummy Node。
82.删除排序链表中的重复元素 II
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。
思路:
本题与 83. 删除排序链表中的重复元素 的不同之处在于要删掉重复元素的所有节点,所以要用 dummy 来进行处理。
代码:
class Solution {
public ListNode deleteDuplicates(ListNode head) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode pre = dummy;
ListNode cur = head;
while(cur != null) {
//发现下个节点的值与本节点相同
if(cur.next != null && cur.val == cur.next.val) {
int val = cur.val; //记录本节点的值
//若节点的值相同,则一直往后遍历
while(cur != null && cur.val == val) {
cur = cur.next;
}
//直到走完链表或出现不同值的节点,删除之前所有节点
pre.next = cur;
} else {
//pre 和 cur 继续遍历
pre = cur;
cur = cur.next;
}
}
return dummy.next;
}
}
★ 92.反转链表 II
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
说明:
1 ≤ m ≤ n ≤ 链表长度。

思路:
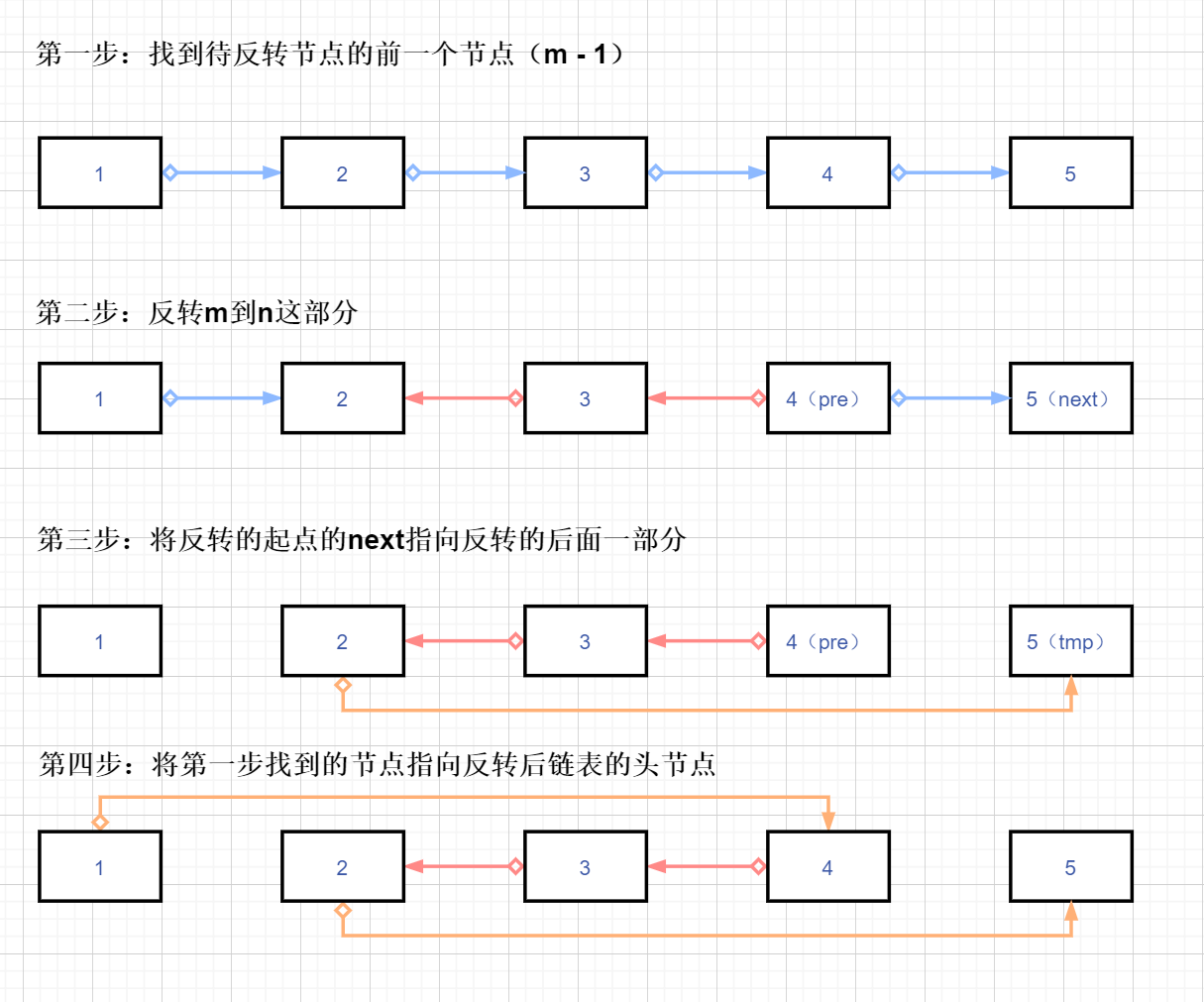
代码:
class Solution {
public ListNode reverseBetween(ListNode head, int m, int n) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode node = dummy;
for(int i = 1; i < m; i++) { //注意 i 从 1 开始
node = node.next; //向后遍历,直到 m - 1
}
ListNode cur = node.next; // m 处的节点
ListNode pre = null;
ListNode tmp = null;
for(int i = m; i <= n; i++) { //等于 n 的情况也要包括
tmp = cur.next;
cur.next = pre;
pre = cur;
cur = tmp;
}
//下面两步不能写反!
//连接 m -> n + 1,此时 m 为node.next, n + 1 为暂存着 n.next 的tmp
node.next.next = tmp;
//连接 m - 1 -> n,此时 m - 1 为 node,n 为反转链表的头节点即 pre
node.next = pre;
return dummy.next;
}
}
★ 2.两数相加
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。您可以假设除了数字 0 之外,这两个数都不会以 0 开头。

思路:
本题与 415. 字符串相加 做法完全相同。
将两个链表看成是相同长度的进行遍历,如果一个链表较短则在前面补 0,比如 987 + 23 = 987 + 023 = 1010;
每一位计算的同时需要考虑上一位的进位问题,而当前位计算结束后同样需要更新进位值;
如果两个链表全部遍历完毕后,进位值为 1,则在新链表最前方添加节点 1。
复杂度分析:
时间复杂度:O(max(m,n)),假设 m 和 n 分别表示 l1 和 l2 的长度,上面的算法最多重复 max(m,n) 次。
空间复杂度:O(max(m,n)), 新列表的长度最多为 max(m,n)+1。
代码:
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(0);
ListNode cur = dummy;
int carry = 0;
while(l1 != null || l2 != null) {
int n1 = l1 == null ? 0 : l1.val;
int n2 = l2 == null ? 0 : l2.val;
int sum = n1 + n2 + carry;
carry = sum / 10;
sum = sum % 10; //这两步千万不能写反了!
cur.next = new ListNode(sum);
cur = cur.next;
if(l1 != null) l1 = l1.next;
if(l2 != null) l2 = l2.next;
}
if(carry == 1) cur.next = new ListNode(1);
return dummy.next;
}
}
★ 19.删除链表的倒数第N个节点
给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
思路:
- 整体思路是让 cur 指针先移动 n 步,之后两个指针共同移动直到 cur 到尾部为止;
- 设预先指针 dummy的下一个节点指向 head,设前指针为 pre,后指针为 cur,二者都等于 dummy;
- cur 先向后移动 n 步;
- 之后 pre 和 cur 共同向前移动,二者的距离始终为 n,当 cur 到尾部时,pre 的位置恰好为倒数第 n 个节点;
- 因为要删除该节点,所以 pre 要移动到该节点的前一个才能删除,所以循环结束条件为 cur.next != null;
- 删除后返回 dummy.next,为什么不直接返回 head 呢,因为 head 有可能是被删掉的点;
- 时间复杂度:O(n)。
代码:
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode pre = dummy;
ListNode cur = dummy;
for(int i = 1; i <= n; i++) {
cur = cur.next;
}
while(cur.next != null) {
pre = pre.next;
cur = cur.next;
}
pre.next = pre.next.next;
return dummy.next;
}
}
快慢指针
★ 141.环形链表
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
![示 例 1 、 输 入 : 输 出 : 3 [3,2,e,-4], POS : 1 解 释 : 链 表 中 有 一 个 环 , 其 尾 部 连 接 到 第 二 个 节 点 。 head 2 0 . 4](https://i.loli.net/2020/11/05/CSlYX4Zp1Hw5q6c.png)
代码:
public class Solution {
public boolean hasCycle(ListNode head) {
if(head == null || head.next == null) return false;
ListNode slow = head, fast = head.next;
while(fast != slow) {
if(fast == null || fast.next == null) return false;
fast = fast.next.next;
slow = slow.next;
}
return true;
}
}
142.环形链表 II
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
![计算机生成了可选文字: 示例1: 输入: 输出: 3 [3丿2丿9丿一4],pos 1 tonodeindex1 解释:链表中有一个环,其尾部连接到第二个节占 head tailC0nneCtS 2 0 .4](https://i.loli.net/2020/11/05/1DkTmbJG8EBhcFs.png)
代码:
public class Solution {
public ListNode detectCycle(ListNode head) {
if(head == null || head.next == null) return head;
ListNode slow = head, fast = head.next;
while(slow != fast) {
if(fast == null || fast.next == null) return null;
fast = fast.next.next;
slow = slow.next;
}
while(head != slow.next) {
head = head.next;
slow = slow.next;
}
return head;
}
}
“K个”问题
★ 23.合并K个排序链表
合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。

方法一:优先队列。
维护当前每个链表没有被合并的元素的最前面一个,k 个链表就最多有 k 个满足这样条件的元素,每次在这些元素里面选取 val 属性最小的元素合并到答案中。在选取最小元素的时候,我们可以用优先队列来优化这个过程。
复杂度分析:
时间复杂度:考虑优先队列中的元素不超过 k 个,那么插入和删除的时间代价为 O(logk),这里最多有 kn 个点,对于每个点都被插入删除各一次,故总的时间代价即渐进时间复杂度为 O(kn × logk)。
空间复杂度:这里用了优先队列,优先队列中的元素不超过 k 个,故渐进空间复杂度为 O(k)。
代码:
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
//这里的lambda表达式要记得写,因为比较的是值,节点不能直接比较
Queue<ListNode> heap = new PriorityQueue<>((v1, v2) -> v1.val - v2.val);
for(ListNode list : lists) {
if(list != null) {
heap.offer(list); //其实只是加入了头节点
}
}
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while(!heap.isEmpty()) {
ListNode head = heap.poll();
tail.next = head;
tail = head;
if(head.next != null) heap.offer(head.next);
}
return dummy.next;
}
}
方法二:分治法。(两两合并)
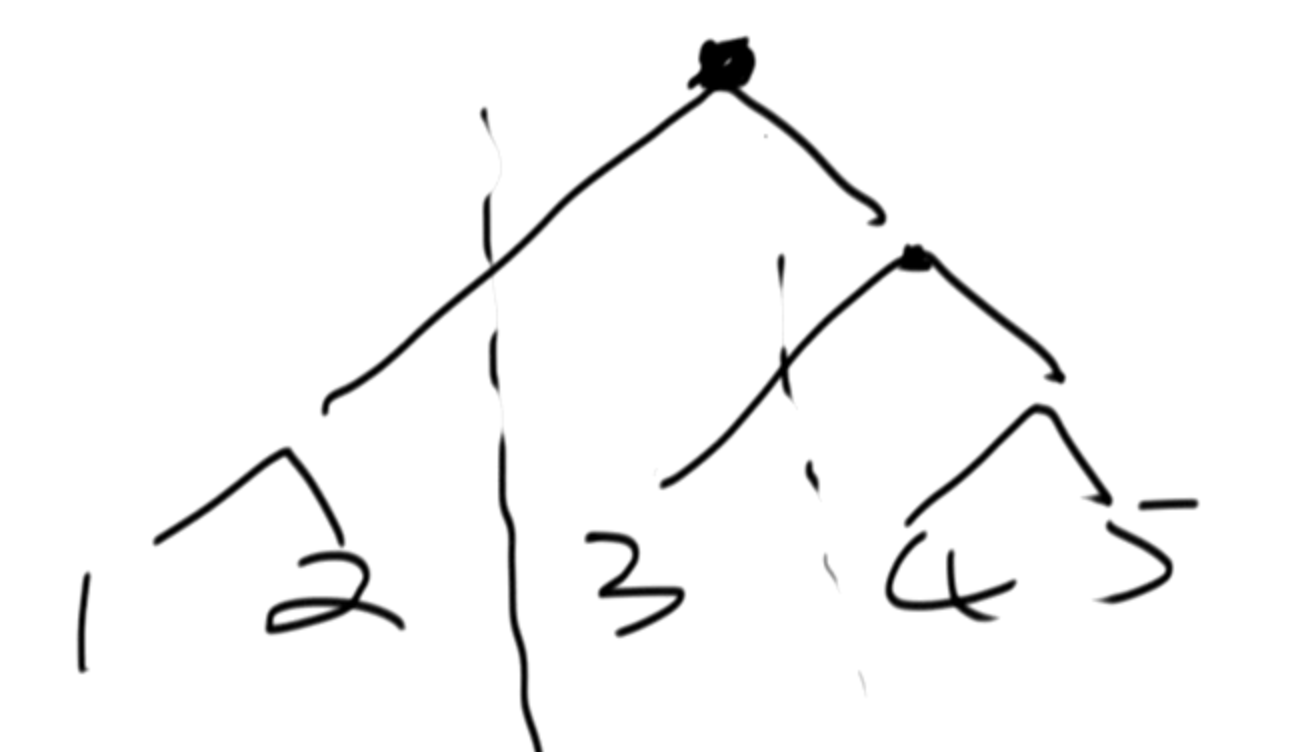
如果我们逐一合并的话,一条链表要经过 k 次合并,总结点数为 n ,则时间复杂度为 O(nk)。而用上图的方式进行合并的话,每条链表只需要经过 logk 次合并(logk层),则时间复杂度为 O(nlogk)。
代码:
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
return mergeHelper(lists, 0, lists.length - 1);
}
private ListNode mergeHelper(ListNode[] lists, int start, int end) {
if(lists == null || lists.length == 0) return null;
if(start == end) return lists[start]; //这个边界条件一定要考虑到!
int mid = start + (end - start) / 2;
ListNode left = mergeHelper(lists, start, mid);
ListNode right = mergeHelper(lists, mid + 1, end);
return merge2Lists(left, right);
}
private ListNode merge2Lists(ListNode head1, ListNode head2) {
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while(head1 != null && head2 != null) {
if(head1.val < head2.val) {
tail.next = head1;
head1 = head1.next;
} else {
tail.next = head2;
head2 = head2.next;
}
tail = tail.next;
}
if(head1 != null) tail.next = head1;
else tail.next = head2;
return dummy.next;
}
}
★ 25.K 个一组翻转链表
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
示例:
给你这个链表:1->2->3->4->5
当 k = 2 时,应当返回: 2->1->4->3->5
当 k = 3 时,应当返回: 3->2->1->4->5
方法一:递归。
- 先反转以 head 开头的 k 个元素。
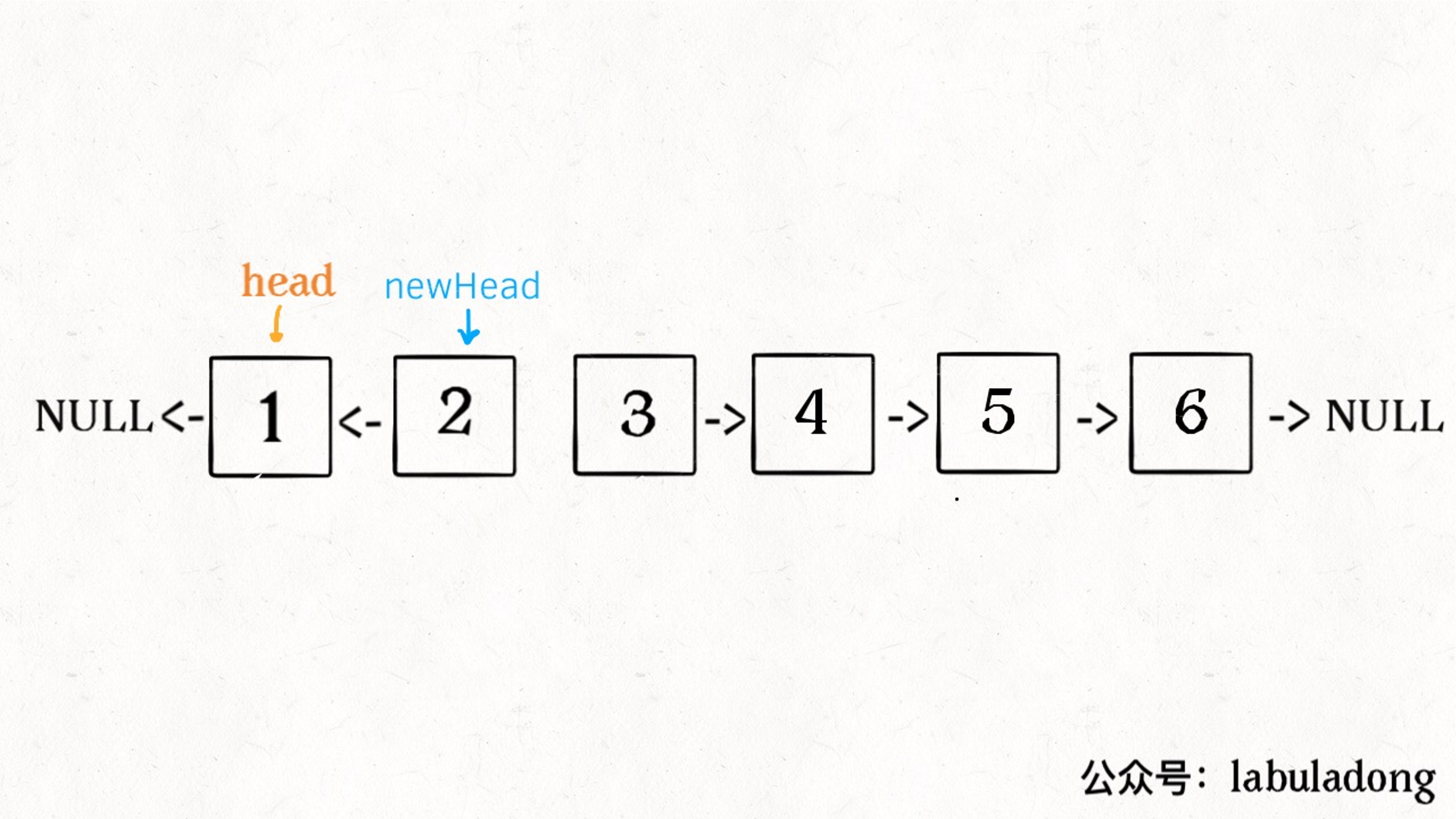
- 将第 k + 1 个元素作为 head 递归调用 reverseKGroup 函数。
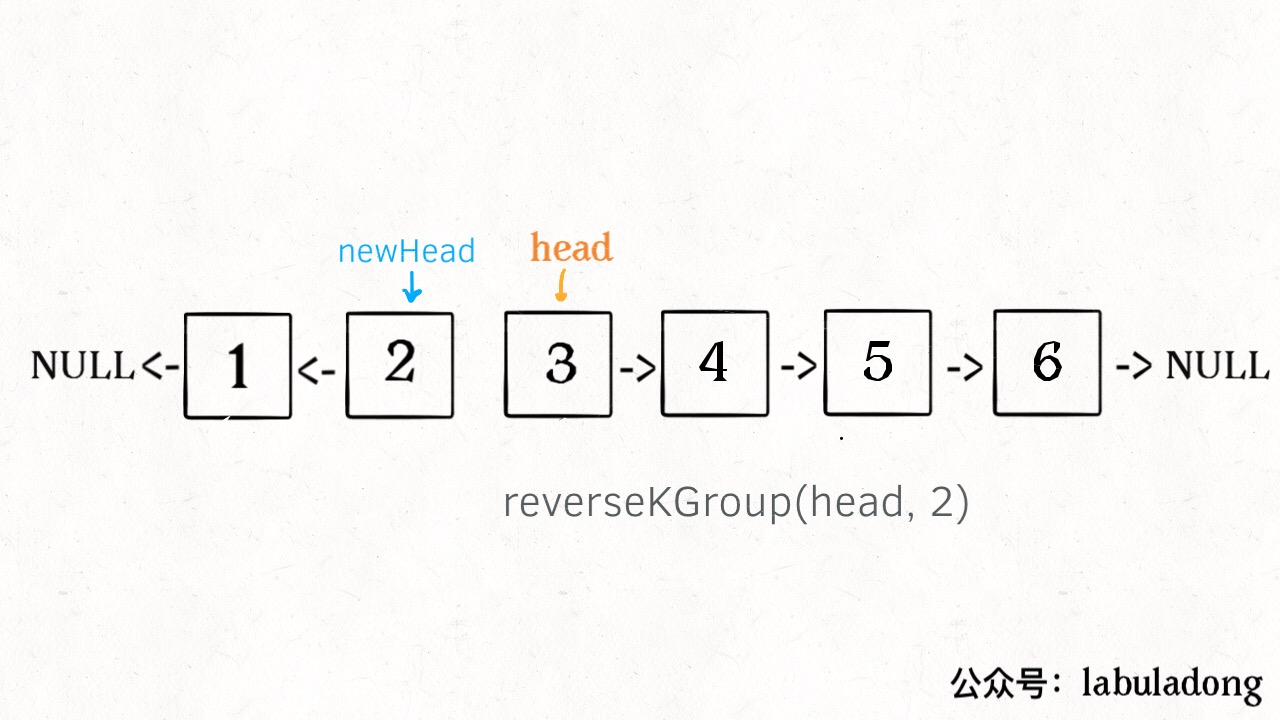
- 将上述两个过程的结果连接起来。

base case 是如果最后的元素不足 k 个,就保持不变。
复杂度分析:
时间复杂度O(N);
空间复杂度O(N)。
代码:
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
if(head == null) return null;
// 区间 [a, b) 包含 k 个待反转元素
ListNode a, b;
a = b = head;
for(int i = 0; i < k; i++) {
// 不足 k 个,不需要反转,base case
if(b == null) return head;
b = b.next;
}
// 反转前 k 个元素
ListNode newHead = reverse(a, b);
// 递归反转后续链表并连接起来
// 此时 b 所在的位置为后续链表的头节点
a.next = reverseKGroup(b, k);
return newHead;
}
/** 反转区间 [a, b) 的元素,注意是左闭右开 */
ListNode reverse(ListNode a, ListNode b) {
ListNode pre = null, cur = a, tmp = a;
// while 终止的条件改一下就行了
while(cur != b) {
tmp = cur.next;
cur.next = pre;
pre = cur;
cur = tmp;
}
return pre;
}
}
328.奇偶链表
未做。
234.回文链表
未做。
树
Traverse in Binary Tree
Preorder:
★ 144.二叉树的前序遍历
给定一个二叉树,返回它的 前序 遍历。
分治法:
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if(root == null) return result;
//divide
List<Integer> left = preorderTraversal(root.left);
List<Integer> right = preorderTraversal(root.right);
//conquer
result.add(root.val);
result.addAll(left);
result.addAll(right);
return result;
}
}
非递归:
前序遍历的输出是根左右,即 Top->Bottom ->->-> Left->Right 。所以从根节点开始,每次迭代弹出当前栈顶元素,并将其孩子节点压入栈中,先压右孩子再压左孩子。
代码:
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
List<Integer> res = new ArrayList<>();
if(root == null) return res;
stack.push(root);
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
res.add(node.val);
//一定要先压右孩子,这样输出时才会是left->right
if(node.right != null) stack.push(node.right);
if(node.left != null) stack.push(node.left);
}
return res;
}
}
Inorder:
★ 94.二叉树的中序遍历
给定一个二叉树,返回它的中序 遍历。
非递归:
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while(cur != null || !stack.isEmpty()) {
//不断往左子树方向走,每走一次就将当前节点保存到栈中
while(cur != null) {
stack.push(cur);
cur = cur.left;
}
//当前节点为空,说明左边走到头了,从栈中弹出节点并保存
//然后转向右边节点,继续上面整个过程
cur = stack.pop();
res.add(cur.val);
cur = cur.right;
}
return res;
}
}
Postorder:
★ 145.二叉树的后序遍历
给定一个二叉树,返回它的 后序 遍历。
非递归:
后序遍历等于原二叉树的镜像树的前序遍历(前序遍历为 根 - 左 - 右),我们用栈后进先出的特点把原二叉树变成镜像二叉树;先把左节点压入栈,再把右节点压入栈(根 - 右 - 左),所以逆序输出是(左 - 右 -根),即后序遍历。
代码:
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
if(root == null) return res;
stack.push(root);
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
res.add(0, node.val); //逆序输出
if(node.left != null) stack.push(node.left);
if(node.right != null) stack.push(node.right);
}
return res;
}
}
DFS in Binary Tree
Traverse vs Divide Conquer
- They are both Recursion Algorithm
- Result in parameter vs Result in return value
- Top down vs Bottom up
★ 104.二叉树的最大深度(同剑指55 - I. 二叉树的深度)
给定一个二叉树,找出其最大深度。二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
![计算机生成了可选文字: 示例: 给定一 一叉树[3,9,20,n引l,nu比15,7], 929 15 返回它的最大深度3。](https://i.loli.net/2020/11/05/GflLaAp5NhUTbsz.png)
遍历法:
class Solution {
int max;
public int maxDepth(TreeNode root) {
max = 0;
helper(root, 1); //当前深度为 1
return max;
}
void helper(TreeNode root, int depth) {
if(root == null) return;
max = Math.max(max, depth);
helper(root.left, depth + 1); //去向下一层
helper(root.right, depth + 1);
}
}
分治法:
class Solution {
public int maxDepth(TreeNode root) {
if(root == null) return 0;
//divide
int leftDepth = maxDepth(root.left);
int rightDepth = maxDepth(root.right);
//整棵树在该问题上的结果 和左右儿子在该问题上的结果之间的联系
return Math.max(leftDepth, rightDepth) + 1;
}
}
110.平衡二叉树(同剑指55 - II. 平衡二叉树)
给定一个二叉树,判断它是否是高度平衡的二叉树。本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
![计算机生成了可选文字: 示例1: 给定二叉树[3,9,20,n引l,nu|L15,7] 3 929 7](https://i.loli.net/2020/11/05/jn1Yv5Vw6P3SroX.png)
代码:
class Solution {
public boolean isBalanced(TreeNode root) {
return maxDepth(root) != -1;
}
int maxDepth(TreeNode root) {
if(root == null) return 0;
int left = maxDepth(root.left);
int right = maxDepth(root.right);
if(left == -1 || right == -1 || Math.abs(left - right) > 1) return -1;
return Math.max(left, right) + 1;
}
}
★ 236. 二叉树的最近公共祖先(同剑指68 - II. 二叉树的最近公共祖先)
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]。
![计算机生成了可选文字: 示例1: 输入: 输出: 示例2: 输入: 输出: [3丿5丿1丿6丿2丿9丿8丿nulnull丿7丿4], root 3 解释:节点5和节点1的最近公共祖先是节点3。 [3丿5丿1丿6丿2丿9丿8丿null丿null丿7丿4], root 5 解释:节点5和节点4的最近公共祖先是节点5。因为根据定义最 P P 1 近公共祖先节点可以为节点本身](https://i.loli.net/2020/11/05/vdDxawtrq9zb7lR.png)
代码:
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//最近公共祖先节点可以为节点本身,只有其中一个时就返回它
if(root == null || root == p || root == q) return root;
//divide
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
//左右各一个节点
if(left != null && right != null) return root;
//都在右边
if(left == null) return right;
//都在左边
if(right == null) return left;
return null;
}
}
★ 124.二叉树中的最大路径和
给定一个非空二叉树,返回其最大路径和。
本题中,路径被定义为一条从树中任意节点出发,达到任意节点的序列。该路径至少包含一个节点,且不一定经过根节点。
![计算机生成了可选文字: 示例1: 输入: 输出: 示例2: 输入: [1丿2丿3] 1 2 6 3 [一10丿9丿29丿nullnull157] 一19 9 输出: 29 7 42](https://i.loli.net/2020/11/05/geI35iRNEwBH6d7.png)
分析:
这道题有 4 种情况:
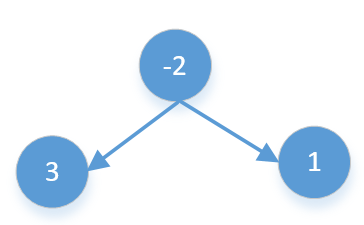
- 单个数字最大值,比如下面的3
- 当前值加左子树的值是最大值,比如下面的2,3
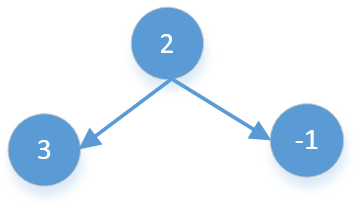
- 当前值加右子树的值是最大值,比如下面的2,4
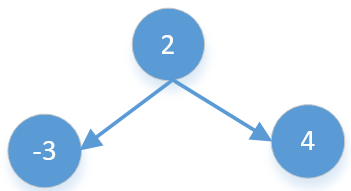
- 当前值加左右子树的值是最大值,比如下面的2,3,4
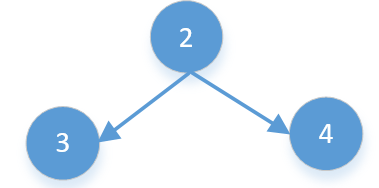
上面的 1,2,3 这几种情况都可以作为树的一个子树再计算,但第 4 种是不能作为一个子树再计算的。
代码:
class Solution {
int maxValue = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
dfs(root);
return maxValue;
}
int dfs(TreeNode root) {
if(root == null) return 0;
//Divide
int left = dfs(root.left);
int right = dfs(root.right);
//Conquer
//第4种情况
int cur = root.val + Math.max(0, left) + Math.max(0, right);
//第1,2,3种情况
int res = root.val + Math.max(0, Math.max(left, right));
//记录最大value值
maxValue = Math.max(maxValue, Math.max(cur, res));
//第1,2,3种情况还可以再计算,所以返回的是res
return res;
}
}
124 变形. 二叉树中的最大路径和 II
给一棵二叉树,找出从根节点出发的路径中,和最大的一条。
这条路径可以在任何二叉树中的节点结束,但是必须包含至少一个点(也就是根了)。
代码:
class Solution {
public int maxPathSum2(TreeNode root) {
if(root == null) return 0;
int left = maxPathSum2(root.left);
int right = maxPathSum2(root.right);
return Math.max(Math.max(left, right), 0) + root.val;
}
}
两题之间的区别是:上题是 anynode -> anynode,这题是 root -> anynode。
★ 543.二叉树的直径
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
![例 定 返 回 3 , 它 的 长 度 是 路 径 [ 4 , 2 , 1 , 3 ] 或 者 [ 5 , 2 , 1 , 3 ] 。](https://i.loli.net/2020/11/05/nUupY7qTNyQaEDM.png)
思路:
任意一条路径均可以被看作由某个节点为起点,从其左儿子和右儿子向下遍历的路径拼接得到。
假设我们知道对于该节点的左儿子向下遍历经过最多的节点数 L (即以左儿子为根的子树的深度) 和其右儿子向下遍历经过最多的节点数 R (即以右儿子为根的子树的深度),那么以该节点为起点的路径经过节点数的最大值即为 L+R+1 。
最后的算法流程为:我们定义一个递归函数 depth(node) 计算返回该节点为根的子树的深度。先递归调用左儿子和右儿子求得它们为根的子树的深度 L 和 R ,则该节点为根的子树的深度即为 max(L,R)+1。
复杂度分析:
时间复杂度:O(N),其中 N 为二叉树的节点数,即遍历一棵二叉树的时间复杂度,每个结点只被访问一次。
空间复杂度:O(Height),其中 Height 为二叉树的高度。
代码:
class Solution {
int res;
public int diameterOfBinaryTree(TreeNode root) {
res = 1;
depth(root);
return res - 1;
}
int depth(TreeNode root) {
if(root == null) return 0;
int left = depth(root.left);
int right = depth(root.right);
res = Math.max(res, left + right + 1);
return Math.max(left, right) + 1;
}
}
572.另一个树的子树
给定两个非空二叉树 s 和 t,检验 s 中是否包含和 t 具有相同结构和节点值的子树。s 的一个子树包括 s 的一个节点和这个节点的所有子孙。s 也可以看做它自身的一棵子树。

思路:
要判断一个树 t 是不是树 s 的子树,那么可以判断 t 是否和树 s 的任意子树相等。那么就转化成 100. Same Tree。
即,这个题的做法就是在 s 的每个子节点上,判断该子节点是否和 t 相等。
判断两个树是否相等的三个条件是与的关系,即:
- 当前两个树的根节点值相等;
- 并且,s 的左子树和 t 的左子树相等;
- 并且,s 的右子树和 t 的右子树相等。
而判断 t 是否为 s 的子树的三个条件是或的关系,即:
- 当前两棵树相等;
- 或者,t 是 s 的左子树;
- 或者,t 是 s 的右子树。
复杂度分析:

代码:
class Solution {
public boolean isSubtree(TreeNode s, TreeNode t) {
if(s == null) return false;
if(t == null) return true;
return isSubtree(s.left, t) || isSubtree(s.right, t) || isSameTree(s, t);
}
boolean isSameTree(TreeNode s, TreeNode t) {
if(s == null && t == null) return true;
if(s == null || t == null) return false;
if(s.val != t.val) return false;
return isSameTree(s.left, t.left) && isSameTree(s.right, t.right);
}
}
★ 105.从前序与中序遍历序列构造二叉树(同剑指07:重建二叉树)
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
![计算机生成了可选文字: 例如,给出 前序遍历preorder 中序遍历inorder 返回如下的二叉树: 3 929 [3,9,29J157] [9J3JISJ29)7] 15 7](https://i.loli.net/2020/11/05/7A3fer6dMJLzONR.png)
思路:
由前序遍历和中序遍历的特点可总结出以下规律:
前序遍历的首个元素即为根节点 root 的值;
在中序遍历中搜索根节点 root 的索引 ,可将中序遍历划分为 [ 左子树 | 根节点 | 右子树 ] 。
根据中序遍历中的左(右)子树的节点数量,可将前序遍历划分为 [ 根节点 | 左子树 | 右子树 ] 。
算法流程:
建立根节点root;
搜索根节点root在中序遍历的索引index;
构建根节点root的左子树和右子树;
设置递归出口;
返回值: 返回 root,含义是当前递归层级建立的根节点 root 为上一递归层级的根节点的左或右子节点。

复杂度分析:
时间复杂度:O(n)。对于每个节点都有创建过程以及根据左右子树重建过程。
空间复杂度:O(n)。存储整棵树的开销。
代码:
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
// 递归出口
if (preorder == null || preorder.length == 0)
return null;
// 获取根节点
TreeNode root = new TreeNode(preorder[0]);
// 根节点在中序遍历数组中的索引值
int index = findIndex(preorder, inorder);
// 构建左子树,构建右子树
// root.left = buildTree(左子树的前序,左子树的中序)
root.left = buildTree(Arrays.copyOfRange(preorder, 1, index + 1),
Arrays.copyOfRange(inorder, 0, index));
// 需要特别注意的是,Arrays.copyOfRange是左闭右开的, 所以右边需要多写一个位置到index+ 1, 才能包含到index这个位置。
// root.right = buildTree(右子树的前序,右子树的中序)
root.right = buildTree(Arrays.copyOfRange(preorder, index + 1, preorder.length),
Arrays.copyOfRange(inorder, index + 1, inorder.length));
return root;
}
public int findIndex(int[] preorder, int[] inorder) {
for(int i = 0; i <inorder.length; i++) {
if(inorder[i] == preorder[0]) return i;
}
return 0; //异常情况
}
}
剑指27. 二叉树的镜像
操作给定的二叉树,将其变换为源二叉树的镜像。
思路:递归法。
递归解析:
-
终止条件:当节点 root 为空时(即越过叶节点),则返回 null ;
-
递推工作:
-
- 初始化节点 tmp,用于暂存 root 的左子节点;
- 开启递归 右子节点 mirrorTree(root.right) ,并将返回值作为 root 的 左子节点 。
- 开启递归 左子节点 mirrorTree(tmp),并将返回值作为 root 的 右子节点 。
-
返回值: 返回当前节点 root ;
Q: 为何需要暂存 root 的左子节点?
A: 在递归右子节点 “root.left = mirrorTree(root.right);” 执行完毕后, root.left 的值已经发生改变,此时递归左子节点 mirrorTree(root.left) 则会出问题。
复杂度分析:
时间复杂度 O(N) :其中 N 为二叉树的节点数量,建立二叉树镜像需要遍历树的所有节点,占用 O(N) 时间。
空间复杂度 O(N) :最差情况下(当二叉树退化为链表),递归时系统需使用 O(N) 大小的栈空间。
代码:
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if (root == null) return root;
TreeNode t = root.left;
root.left = mirrorTree(root.right);
root.right = mirrorTree(t);
return root;
}
}
剑指33. 二叉搜索树的后序遍历序列
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。

方法一:递归分治
思路:
根据二叉搜索树的定义,可以通过递归,判断所有子树的正确性(即其后序遍历是否满足二叉搜索树的定义),若所有子树都正确,则此序列为二叉搜索树的后序遍历。
算法流程:

复杂度分析:

代码:
class Solution {
public boolean verifyPostorder(int[] postorder) {
return recur(postorder, 0, postorder.length - 1);
}
boolean recur(int[] postorder, int i, int j) {
//当 i >= j ,说明此子树节点数量 ≤ 1 ,无需判别正确性
if(i >= j) return true;
int p = i; //i, j为固定的,需要一个游标
while(postorder[p] < postorder[j]) p++;
int m = p; //m为第一个大于根节点的节点索引
while(postorder[p] > postorder[j]) p++;
//p == j说明[m,j)之间的元素都大于postorder[j](即上面的条件一直成立,p++每次都执行了)
return p == j && recur(postorder, i, m - 1) &&
recur(postorder, m, j - 1); //记得是 j - 1!
}
}
剑指28. 对称的二叉树
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
思路:
对称二叉树定义: 对于树中 任意两个对称节点 L 和 R ,一定有:
L.val = R.val :即此两对称节点值相等。
L.left.val = R.right.val:即 L 的 左子节点 和 R 的 右子节点 对称;
L.right.val = R.left.val:即 L 的 右子节点 和 R 的 左子节点 对称。
根据以上规律,考虑从顶至底递归,判断每对节点是否对称,从而判断树是否为对称二叉树。
算法流程:
isSymmetric(root) :
特例处理: 若根节点 root 为空,则直接返回 true 。
返回值: 即 recur(root.left, root.right) ;
recur(L, R) :
终止条件:
当 L 和 R 同时越过叶节点:此树从顶至底的节点都对称,因此返回 true ;
当 L 或 R 中只有一个越过叶节点:此树不对称,因此返回 false ;
当节点 L 值 ≠ 节点 R 值:此树不对称,因此返回 false ;
递推工作:
判断两节点 L.left 和 R.right 是否对称,即 recur(L.left, R.right) ;
判断两节点 L.right 和 R.left 是否对称,即 recur(L.right, R.left) ;
返回值: 两对节点都对称时,才是对称树,因此用与逻辑符 && 连接。
复杂度分析:
时间复杂度 O(N) : 其中 N 为二叉树的节点数量,每次执行 recur() 可以判断一对节点是否对称,因此最多调用 N/2 次 recur() 方法。
空间复杂度 O(N) : 最差情况下,二叉树退化为链表,系统使用 O(N) 大小的栈空间。
代码:
class Solution {
public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
return recur(root.left, root.right);
}
public boolean recur(TreeNode L, TreeNode R) {
if (L == null && R == null) return true;
if (L == null || R == null || L.val != R.val) return false;
return recur(L.left, R.right) && recur(L.right, R.left);
}
}
112.路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
代码:
class Solution {
public boolean hasPathSum(TreeNode root, int sum) {
if(root == null) return false;
//一定要同时判断节点的左右子树同时为空才算走到了头
if(root.left == null && root.right == null) {
return root.val == sum;
}
return hasPathSum(root.left, sum - root.val) ||
hasPathSum(root.right, sum - root.val);
}
}
Binary Search Tree
基本性质:
从定义出发:
左子树都比根节点小 ;
右子树都比根节点大 。
如果存在重复元素,可以自行选择放到左子树还是右子树。
从效果出发:
中序遍历 in-order traversal 是升序序列。
★ 98.验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
![计算机生成了可选文字: 示例1: 输入: 2 1 输出: 示例2: 输入: 3 5 3 6 输出:fa1se 解释:输入为:[5丿1丿4丿null丿null丿3丿6]。 根节点的值为5,但是其右子节点值为4](https://i.loli.net/2020/11/05/RkioSOcl5hALXMV.png)
递归法:
class Solution {
public boolean isValidBST(TreeNode root) {
//先将上下界设为最大,最小值
//这道题要用long,否则测试用例过不了
return helper(root, Long.MIN_VALUE, Long.MAX_VALUE);
}
boolean helper(TreeNode root, Long lower, Long upper) {
if(root == null) return true;
//对root进行处理
long val = root.val;
if(val <= lower) return false;
if(val >= upper) return false;
//对root的左右子树进行递归处理,同时改变上下界的值
if(!helper(root.left, lower, val)) return false;
if(!helper(root.right, val, upper)) return false;
return true;
}
}
中序遍历法:(非典型,通常用栈来实现)
class Solution {
long pre = Long.MIN_VALUE;
public boolean isValidBST(TreeNode root) {
if(root == null) return true;
//访问左子树
if(!isValidBST(root.left)) return false;
//访问当前节点:如果当前节点小于等于中序遍历的前一个节点,说明不满足BST,返回 false;否则继续遍历。
if(root.val <= pre) return false;
pre = root.val;
return isValidBST(root.right);
}
}
108.将有序数组转换为二叉搜索树
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
![示 例 : 结 定 有 序 数 组 : [ . 19 , . 3 , 9], 一 个 可 能 的 答 案 是 : [ 0 疒 3J9 厂 1 null,5 ] , 它 可 以 示 下 面 这 个 高 度 平 衡 二 叉 搜 索 树 : 0](https://i.loli.net/2020/11/05/kFcLRjfwK1InEZN.png)
思路:
BST的中序遍历是升序的,因此本题等同于根据中序遍历的序列恢复二叉搜索树。因此我们可以以升序序列中的任一个元素作为根节点,以该元素左边的升序序列构建左子树,以该元素右边的升序序列构建右子树,这样得到的树就是一棵二叉搜索树。又因为本题要求高度平衡,因此我们需要选择升序序列的中间元素作为根节点,这样分给左右子树的数字个数相同或只相差 1,可以使得树保持平衡。
复杂度分析:
时间复杂度:O(n),其中 n 是数组的长度。每个数字只访问一次。
空间复杂度:O(logn),其中 n 是数组的长度。空间复杂度不考虑返回值,因此空间复杂度主要取决于递归栈的深度,递归栈的深度是 O(logn)。
代码:
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return dfs(nums, 0, nums.length - 1);
}
TreeNode dfs(int[] nums, int lo, int hi) {
if(lo > hi) return null;
int mid = lo + (hi - lo) / 2;
TreeNode root = new TreeNode(nums[mid]); //是 nums[mid] !
root.left = dfs(nums, lo, mid - 1);
root.right = dfs(nums, mid + 1, hi);
return root;
}
}
★ 剑指36. 二叉搜索树与双向链表
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
思路:
本文解法基于性质:二叉搜索树的中序遍历为 递增序列 。
将 二叉搜索树 转换成一个 “排序的循环双向链表” ,其中包含三个要素:
- 排序链表:节点应从小到大排序,因此应使用 中序遍历 “从小到大”访问树的节点;
- 双向链表:在构建相邻节点(设前驱节点 pre ,当前节点 cur )关系时,不仅应 pre.right = cur ,也应 cur.left = pre 。
- 循环链表: 设链表头节点 head 和尾节点 tail ,则应构建 head.left = tail 和 tail.right = head 。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lGx9Y8fW-1639998765316)(https://i.loli.net/2020/11/05/yfcIDtLmGblMxKr.png)]
根据以上分析,考虑使用中序遍历访问树的各节点 cur ;并在访问每个节点时构建cur 和前驱节点 pre 的引用指向;中序遍历完成后,最后构建头节点和尾节点的引用指向即可。核心就是在访问下个节点前,记录当前节点。
复杂度分析:
时间复杂度 O(N) :N 为二叉树的节点数,中序遍历需要访问所有节点。
空间复杂度 O(N) :最差情况下,即树退化为链表时,递归深度达到 N,系统使用 O(N) 栈空间。
代码:
class Solution {
Node pre, head;
public Node treeToDoublyList(Node root) {
if(root == null) return null;
treeToDoublyList(root.left);
if(pre == null) head = root;
else pre.right = root;
root.left = pre;
pre = root;
treeToDoublyList(root.right);
pre.right = head;
head.left = pre;
return head;
}
}
剑指54. 二叉搜索树的第k大节点
给定一棵二叉搜索树,请找出其中第k大的节点。
![计算机生成了可选文字: 示例1: 输入: 3 2 输出: r00t 4 [3JIJ4null,2], k 1](https://i.loli.net/2020/11/05/U2xFOLkPRy9EdvK.png)
思路:
本文解法基于此性质:二叉搜索树的中序遍历为递增序列。根据以上性质,易得二叉搜索树的中序遍历倒序为递减序列 。
因此,求 “二叉搜索树第 k 大的节点” 可转化为求 “此树的中序遍历倒序的第 k 个节点。
算法流程:
-
终止条件:当节点 root 为空(越过叶节点),则直接返回;
-
递归右子树: 即 dfs(root.right);
-
三项工作:
-
- 提前返回:若 k = 0,代表已找到目标节点,无需继续遍历,因此直接返回;
- 统计序号:执行 k = k - 1(即从 k 减至 0 );
- 记录结果:若 k = 0,代表当前节点为第 k 大的节点,因此记录 res = root.val;
-
递归左子树:即 dfs(root.left);
复杂度分析:
时间复杂度 O(N) :当树退化为链表时(全部为右子节点),无论 k 的值大小,递归深度都为 N ,占用 O(N) 时间。
空间复杂度 O(N) :当树退化为链表时(全部为右子节点),系统使用 O(N) 大小的栈空间。
代码:
class Solution {
int k, res;
public int kthLargest(TreeNode root, int k) {
this.k = k;
dfs(root);
return res;
}
void dfs(TreeNode root) {
if(root == null) return;
dfs(root.right); //中序遍历的倒序为 “右、根、左” 顺序
//若 k = 0,代表已找到目标节点,无需继续遍历,因此直接返回
if(k == 0) return;
//执行 k = k - 1(即从 k 减至 0 ), k = 0,代表当前节点为第 k 大的节点,因此记录 res = root.val
if(--k == 0) res = root.val;
dfs(root.left);
}
}
BFS in Binary Tree
★ 剑指32 - I. 从上到下打印二叉树
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
![计算机生成了可选文字: 例如: 给定二叉树: 3 [3,9,20,nu比nu比15,7], 7 929 15 返回: [3,9,29J157]](https://i.loli.net/2020/11/05/4LifSRMIYbwtVcd.png)
思路:
- 题目要求的二叉树的 从上至下 打印(即按层打印),又称为二叉树的 广度优先搜索(BFS)。
- BFS 通常借助 队列 的先入先出特性来实现。
算法流程:
-
特例处理:当树的根节点为空,则直接返回空列表 [] ;
-
初始化:打印结果列表 res = [],包含根节点的队列 queue = [root] ;
-
BFS 循环:当队列 queue 为空时跳出;
-
- 出队:队首元素出队,记为 node;
- 打印:将 node.val 添加至列表 tmp 尾部;
- 添加子节点:若 node 的左(右)子节点不为空,则将左(右)子节点加入队列 queue ;
-
返回值:返回打印结果列表 res 即可。
复杂度分析:
时间复杂度 O(N): N 为二叉树的节点数量,即 BFS 需循环 N 次。
空间复杂度 O(N) :最差情况下,即当树为平衡二叉树时,最多有 N/2 个树节点同时在 queue 中,使用 O(N) 大小的额外空间。
代码:
class Solution {
public int[] levelOrder(TreeNode root) {
if (root == null) return new int[0];
Queue<TreeNode> queue = new LinkedList<>(); //用来排序(先入先出)
ArrayList<Integer> list = new ArrayList<>(); //用来接收
//核心思想:queue中取出一个元素,再将其左右孩子加入queue
queue.add(root);
while(!queue.isEmpty()) {
TreeNode node = queue.remove(); //queue中取出一个节点
list.add(node.val); //将其值加入list
//左右孩子不空则加入queue
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
//把ArrayList类型转为int数组
int[] res = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
res[i] = list.get(i);
}
return res;
}
}
★ 102.二叉树的层序遍历(同剑指32 - II. 从上到下打印二叉树 II)
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
![计算机生成了可选文字: 示例: 二叉树:[3,9,20,nl,nu比15,7], 3 929 7 返回其层次遍历结果: [9丿29L [15丿7]](https://i.loli.net/2020/11/05/jDvJpCw6hL5xQzF.png)
代码:
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> resultList = new ArrayList<>();
if(root == null) return resultList;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
List<Integer> currentList = new ArrayList<>();
int size = queue.size();
for(int i = 0; i < size; i++) {
TreeNode head = queue.poll();
currentList.add(head.val);
if(head.left != null)
queue.offer(head.left);
if(head.right != null)
queue.offer(head.right);
}
resultList.add(currentList);
}
return resultList;
}
}
★ 103.二叉树的锯齿形层次遍历(同剑指32 - III. 从上到下打印二叉树 III)
给定一个二叉树,返回其节点值的锯齿形层次遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
![计算机生成了可选文字: 例如· 给定一 一叉树[3,9,20,n引l,nu比15,7], 3 929 7 返回锯齿形层次遍历如下: [29], [15丿7]](https://i.loli.net/2020/11/05/fAvejPZoSb5ziIE.png)
代码:
class Solution {
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
if(root == null) return res;
boolean flag = true; //首先为奇数层
queue.offer(root);
while(!queue.isEmpty()) {
List<Integer> cur = new LinkedList<>();
int size = queue.size();
for(int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if(flag == true) cur.add(node.val); //奇数层加至尾部
else cur.add(0, node.val); //偶数层加至头部
if(node.left != null) queue.offer(node.left);
if(node.right != null) queue.offer(node.right);
}
flag = !flag; //一次循环结束后要变号
res.add(cur);
}
return res;
}
}
★ 199.二叉树的右视图
给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。

思路:
思路:利用 BFS 进行层次遍历,记录下每层的最后一个元素。
复杂度分析:
时间复杂度:O(N),每个节点都入队出队了 1 次。
空间复杂度:O(N),使用了额外的队列空间。
代码:
class Solution {
public List<Integer> rightSideView(TreeNode root) {
List<Integer> res = new ArrayList<>();
if(root == null) return res;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
int size = queue.size();
for(int i = 0; i < size; i++) {
TreeNode node = queue.poll();
//将当前层的最后一个节点放入结果列表
if(i == size - 1) res.add(node.val);
if(node.left != null) queue.offer(node.left);
if(node.right != null) queue.offer(node.right);
}
}
return res;
}
}
数据结构
栈
20.有效的括号
给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 注意空字符串可被认为是有效字符串。

思路:
利用一个辅助栈来判断括号是否一一对应。
复杂度分析:
时间复杂度:O(N)。遍历字符数组。
空间复杂度:O(N)。使用了一个辅助栈。
代码:
class Solution {
public boolean isValid(String s) {
if(s == null || s.length() == 0) return true;
Stack<Character> stack = new Stack<>();
for(char c : s.toCharArray()) {
if(c == '(') stack.push(')');
else if(c == '{') stack.push('}');
else if(c == '[') stack.push(']');
//栈为空,没有相对应的括号,返回false
//当不为左括号时候,说明c是右括号,stack.pop弹出栈元素中存储的右括号元素,比较这两个右括号是否相等
else if(stack.isEmpty() || c != stack.pop()) return false;
}
//全部出栈完毕栈为空,说明括号一一匹配,返回true
return stack.isEmpty();
}
}
★ 32.最长有效括号
给定一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长的包含有效括号的子串的长度。

思路:
我们始终保持栈底元素为当前已经遍历过的元素中「最后一个没有被匹配的右括号的下标」,这样的做法主要是考虑了边界条件的处理,栈里其他元素维护左括号的下标:
-
对于遇到的每个 ‘(’,我们将它的下标放入栈中;
-
对于遇到的每个 ‘)’,我们先弹出栈顶元素表示匹配了当前右括号:
-
- 如果栈为空,说明当前的右括号为没有被匹配的右括号,我们将其下标放入栈中来更新我们之前提到的「最后一个没有被匹配的右括号的下标」;
- 如果栈不为空,当前右括号的下标减去栈顶元素即为「以该右括号为结尾的最长有效括号的长度」。
我们从前往后遍历字符串并更新答案即可。
需要注意的是,如果一开始栈为空,第一个字符为左括号的时候我们会将其放入栈中,这样就不满足提及的「最后一个没有被匹配的右括号的下标」,为了保持统一,我们在一开始的时候往栈中放入一个值为 -1 的元素。
<动图链接:https://leetcode-cn.com/problems/longest-valid-parentheses/solution/zui-chang-you-xiao-gua-hao-by-leetcode-solution/>
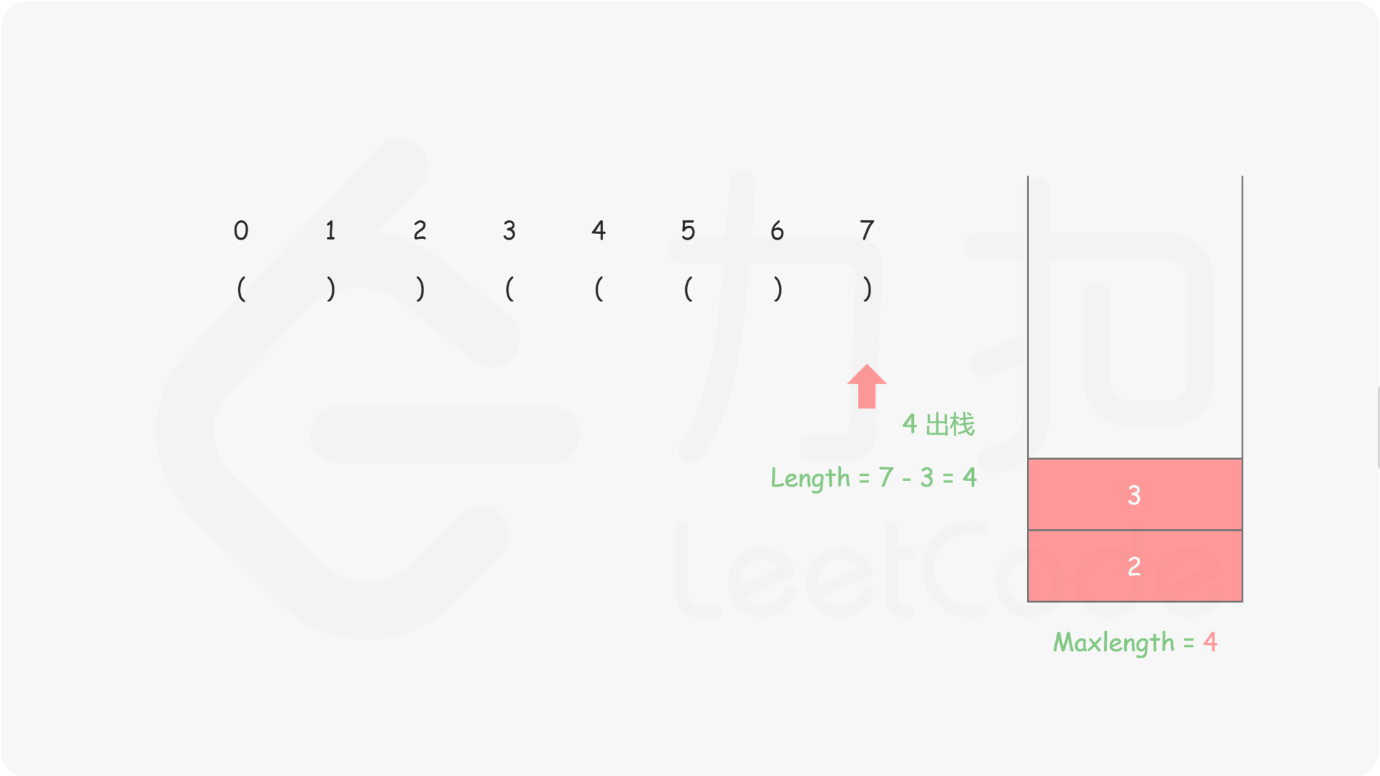
复杂度分析:
时间复杂度:O(n),n 是给定字符串的长度。我们只需要遍历字符串一次即可。
空间复杂度:O(n)。栈的大小在最坏情况下会达到 n,因此空间复杂度为 O(n) 。
代码:
class Solution {
public int longestValidParentheses(String s) {
int max = 0;
Stack<Integer> stack = new Stack<>();
stack.push(-1); //最后一个没有被匹配的右括号的下标,设置一个初值
//除了栈底的右括号下标,栈中其他元素均为左括号下标
for(int i = 0; i < s.length(); i++) {
if(s.charAt(i) == '(') {
stack.push(i);
} else { //当前为右括号
stack.pop();
if(stack.isEmpty()) {
stack.push(i); //更新栈底右括号下标
} else {
max = Math.max(max, i - stack.peek());
}
}
}
return max;
}
}
42.接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。

上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 感谢 Marcos 贡献此图。
![З: [е,1,а,2,1,а,1,з,2,1,2,1]](https://i.loli.net/2020/11/05/RlqG4PTgXB2LoAI.png)
思路:
这道题目可以用单调栈来做。单调栈就是比普通的栈多一个性质,即维护一个栈内元素单调。
比如当前某个单调递减的栈的元素从栈底到栈顶分别是:[10, 9, 8, 3, 2],如果要入栈元素5,需要把栈顶元素pop出去,直到满足单调递减为止,即先变成[10, 9, 8],再入栈5,就是[10, 9, 8, 5]。
<演示图:https://leetcode-cn.com/problems/trapping-rain-water/solution/dan-diao-zhan-jie-jue-jie-yu-shui-wen-ti-by-sweeti/>
复杂度分析:
时间复杂度:O(n)。单次遍历 O(n) ,每个条形块最多访问两次(由于栈的弹入和弹出),并且弹入和弹出栈都是 O(1) 的。
空间复杂度:O(n)。 栈最多在阶梯型或平坦型条形块结构中占用 O(n) 的空间。
代码:
class Solution {
public int trap(int[] height) {
if(height == null || height.length < 3) { //至少要三个柱体才能形成容器
return 0;
}
Stack<Integer> stack = new Stack<>();
int res = 0;
for(int i = 0; i < height.length; i++) {
while(!stack.isEmpty() && height[stack.peek()] < height[i]) { //栈不单调
int curIdx = stack.pop();
// 如果栈顶元素一直相等,那么全都pop出去,只留第一个。
while(!stack.isEmpty() && height[stack.peek()] == height[curIdx]) {
stack.pop();
}
if(!stack.isEmpty()) {
//栈顶元素现在所在的位置即此次接住的雨水的左边界的位置。右边界是当前的柱体,即i。
// Math.min(height[stackTop], height[i]) 是左右柱子高度的min,
//减去height[curIdx]就是雨水的高度。
// i - stackTop - 1 是雨水的宽度。
int left = stack.peek();
res += (Math.min(height[left], height[i]) - height[curIdx]) * (i - left - 1);
//注意这里是 i - left - 1 而不是 + 1,因为不包括左右两个柱体
}
}
stack.add(i);
}
return res;
}
}
★ 496.下一个更大元素 I
给定两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。找到 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
![示 例 1 . 输 少 、 : 输 出 . 解 释 : 对 于 numl 中 的 数 字 4 , 第 二 个 数 组 中 没 有 下 一 个 更 大 的 数 numsl [ . 1J3 疒 1 ] nums2 [ 1J3 丿 ‰ 2 ] , 对 于 numi 中 的 数 字 4 , 你 无 氵 去 在 第 二 个 数 组 中 找 到 下 一 个 更 大 的 数 字 , 因 此 输 出 一 1 。 对 于 numi 中 的 数 字 1 , 第 二 个 数 组 中 数 曱 1 右 边 的 下 一 个 较 大 数 字 对 于 numi 中 的 数 字 2 , 第 二 个 数 组 中 没 有 下 一 个 更 大 的 数 字 , 因 此 输 出 过 。 示 例 2 : 车 龕 少 、 : 解 释 : numsl 输 出 : [ 3 厂 1 ] 字 , 因 此 输 出 . 1 [ 1J2J3 , 4 ] . 对 于 numi 中 的 数 字 2 , 第 二 个 数 组 中 的 下 一 个 较 大 数 字 是 3 nums2](https://i.loli.net/2020/11/05/GFOuAqXoeQPmrj9.png)
思路:
下一个更大元素 这类题都是用单调栈来做。
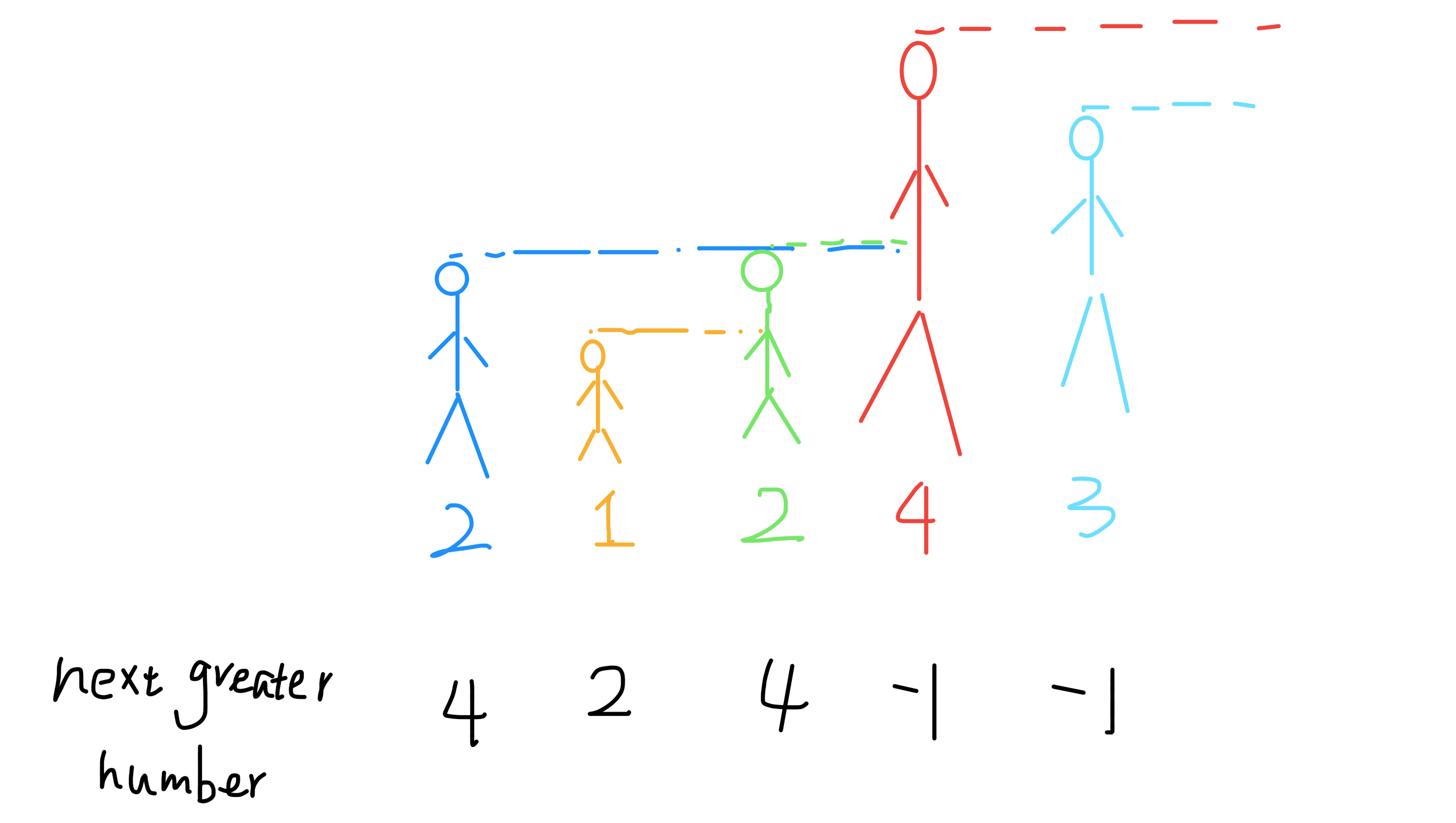
- 如图所示,把数组的元素想象成并列站立的人,元素大小想象成人的身高。这些人面对你站成一列,如何求元素「2」的 Next Greater Number 呢?很简单,如果能够看到元素「2」,那么他后面可见的第一个人就是「2」的 Next Greater Number,因为比「2」小的元素身高不够,都被「2」挡住了,第一个露出来的就是答案。
- 那我们用 for 循环从后往前扫描元素,因为我们借助的是栈的结构,倒着入栈,其实是正着出栈。while 循环是把两个“高个”元素之间的元素排除,因为他们的存在没有意义,前面挡着个“更高”的元素,所以他们不可能被作为后续进来的元素的 Next Great Number 了。
- 实际上这个算法的复杂度只有 O(n)。分析它的时间复杂度,要从整体来看:总共有 n 个元素,每个元素都被 push 入栈了一次,而最多会被 pop 一次,没有任何冗余操作。所以总的计算规模是和元素规模 n 成正比的,也就是 O(n) 的复杂度。
复杂度分析:
时间复杂度:O(M+N),其中 M 和 N 分别是数组 nums1 和 nums2 的长度。
空间复杂度:O(N)。我们在遍历 nums2 时,需要使用栈,以及哈希映射用来临时存储答案。
代码:
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
//需要一个map来存储 nums2中的数 和 其下一个更大元素 的对应关系
HashMap<Integer, Integer> map = new HashMap<>();
Stack<Integer> stack = new Stack<>();
for(int i = nums2.length - 1; i >= 0; i--) { //倒着往栈里放
while(!stack.isEmpty() && nums2[i] >= stack.peek()) {
stack.pop(); //小的直接pop掉,因为会被挡住
}
//这个元素右边的第一个高个
map.put(nums2[i], stack.isEmpty() ? -1 : stack.peek());
stack.push(nums2[i]); //每个元素都要入栈
}
int[] res = new int[nums1.length];
for(int i = 0; i < nums1.length; i++) {
//去map中找该数在nums2中 对应位置的 右边的第一个比 x 大的元素
res[i] = map.get(nums1[i]);
}
return res;
}
}
503.下一个更大元素 II
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
![示 例 1 : 输 入 : [ 1 , 2 , 1 ] 输 出 : [ 2 厂 1J2 ] 解 释 : 第 一 个 1 的 下 一 个 更 大 的 数 是 2 ; 数 字 2 找 不 到 下 一 个 更 大 的 数 ; 第 二 个 1 的 下 一 个 最 大 的 数 需 要 循 环 搜 索 , 结 果 也 是 2 。](https://i.loli.net/2020/11/05/YlfNcoHvDZqrXnO.png)
思路:
实际上计算机的内存都是线性的,没有真正意义上的环形数组,但是我们可以模拟出环形数组的效果,一般是通过 % 运算符求模(余数),获得环形特效。增加了环形属性后,问题的难点在于:这个 Next 的意义不仅仅是当前元素的右边了,有可能出现在当前元素的左边。那我们可以考虑这样的思路:将原始数组“翻倍”,就是在后面再接一个原始数组,这样的话,按照之前“比身高”的流程,每个元素不仅可以比较自己右边的元素,而且也可以和左边的元素比较了。
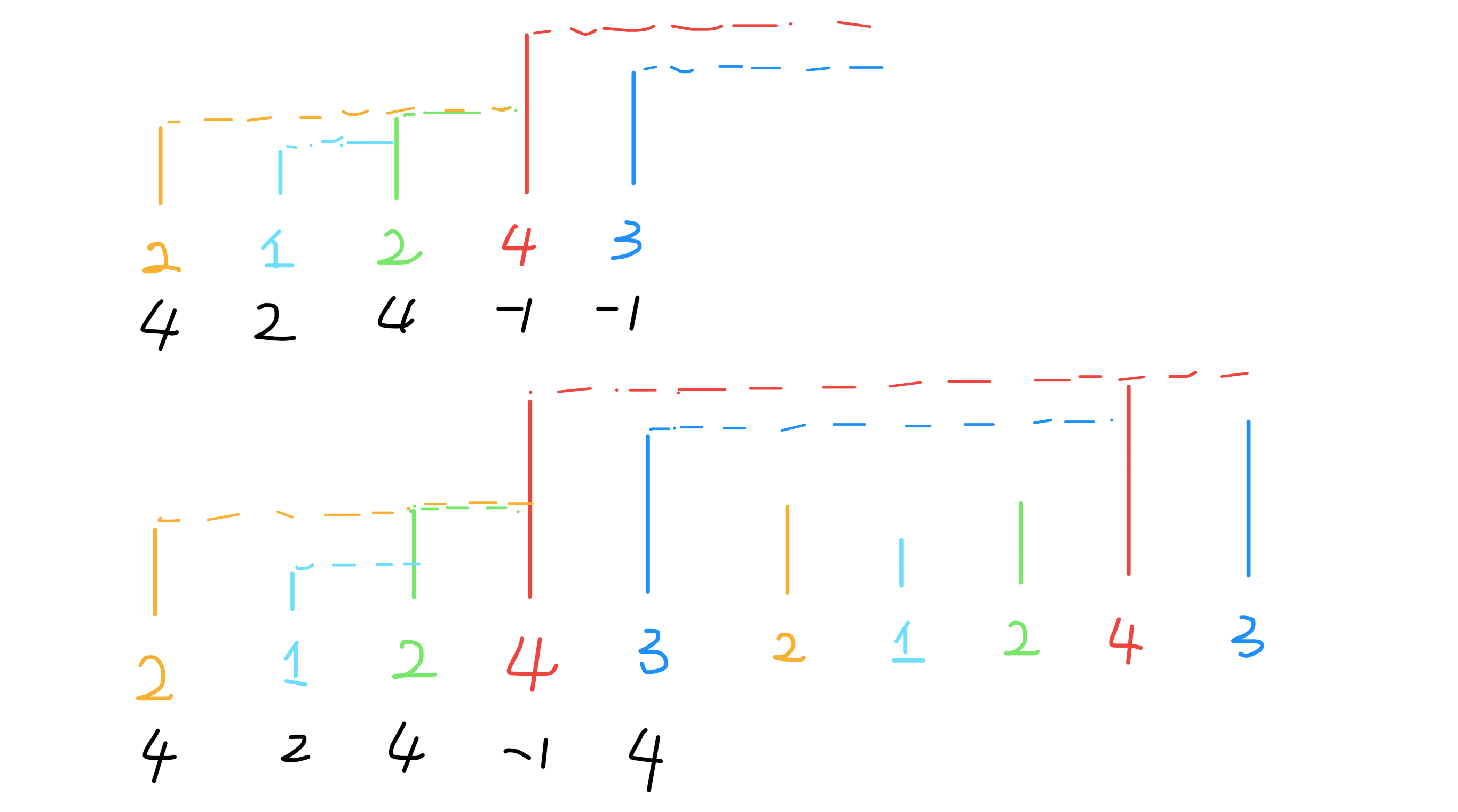
我们可以不用构造新数组,而是利用循环数组的技巧来模拟。
复杂度分析:
时间复杂度:O(N)。注意每个元素会入栈两次。
空间复杂度:O(N)。
代码:
class Solution {
public int[] nextGreaterElements(int[] nums) {
int n = nums.length;
int[] res = new int[n];
Stack<Integer> stack = new Stack<>();
//可以理解为这个数组长度翻倍了
for(int i = 2 * n - 1; i >= 0; i--) {
//不严格的单调递增是为了解决会出现重复元素的情况。
//比如存在数组: 1, 1, 2,
//假如是严格单调递增的话,后出栈的1的右边最大值(-1)会覆盖掉先出栈的1的右边的最大值(2)。
while(!stack.isEmpty() && nums[i % n] >= stack.peek()) {
stack.pop();
}
res[i % n] = stack.isEmpty() ? -1 : stack.peek();
stack.push(nums[i % n]);
}
return res;
}
}
剑指06. 从尾到头打印链表
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
![计算机生成了可选文字: 示例1: 输入:head [1J3J2] 输出:[2J3J1]](https://i.loli.net/2020/11/05/fUlFGvb5IjeVnJw.png)
思路:
链表特点: 只能从前至后访问每个节点。
题目要求: 倒序输出节点值。
这种 先入后出 的需求可以借助 栈 来实现。
算法流程:
入栈: 遍历链表,将各节点值 push 入栈。(Python 使用 append() 方法,Java借助 LinkedList 的addLast()方法)。
出栈: 将各节点值 pop 出栈,存储于数组并返回。(Python 直接返回 stack 的倒序列表,Java 新建一个数组,通过 popLast() 方法将各元素存入数组,实现倒序输出)。
复杂度分析:
时间复杂度 O(N):入栈和出栈共使用 O(N) 时间。
空间复杂度 O(N):辅助栈 stack 和数组 res 共使用 O(N) 的额外空间。
代码:
class Solution {
public int[] reversePrint(ListNode head) {
Stack<Integer> stack = new Stack<>();
while(head != null) {
stack.push(head.val);
head = head.next;
}
int[] res = new int[stack.size()];
for(int i = 0; i < res.length; i++) {
res[i] = stack.pop();
}
return res;
}
}
哈希表
128.最长连续序列
给定一个未排序的整数数组,找出最长连续序列的长度。
要求算法的时间复杂度为 O(n)。
![示 例 : 输 入 : [ 1 羽 , 4 , 2 羽 。 1 , 3, 2 ] 输 出 : 4 解 释 : 最 长 迓 续 序 列 是 [ 1 , 乙 4 ] 。 它 的 长 度 为 4 。](https://i.loli.net/2020/11/05/4ArDtoRPZK3gSpI.png)
思路:
- 本题难点在于要求的时间复杂度为 O(n)。
- 我们考虑枚举数组中的每个数 x,考虑以其为起点,不断尝试匹配 x+1, x+2, ⋯ 是否存在,假设最长匹配到了 x+y,那么以 x 为起点的最长连续序列即为 x, x+1, x+2, ⋯,x+y,其长度为 y+1,我们不断枚举并更新答案即可。
- 对于匹配的过程,暴力的方法是 O(n) 遍历数组去看是否存在这个数,但其实更高效的方法是用一个哈希表存储数组中的数,这样查看一个数是否存在即能优化至 O(1) 的时间复杂度。
- 我们会发现其中执行了很多不必要的枚举,如果已知有一个 x, x+1, x+2,⋯,x+y 的连续序列,而我们却重新从 x+1,x+2 或者是 x+y 处开始尝试匹配,那么得到的结果肯定不会优于枚举 x 为起点的答案,因此我们在外层循环的时候碰到这种情况跳过即可。
- 怎么判断是否跳过呢?由于我们要枚举的数 x 一定是在数组中不存在前驱数 x−1 的,不然按照上面的分析我们会从 x−1 开始尝试匹配,因此我们每次在哈希表中检查是否存在 x−1 即能判断是否需要跳过了。
复杂度分析:
-
时间复杂度:O(n),其中 n 为数组的长度。
外层循环需要 O(n) 的时间复杂度,只有当一个数是连续序列的第一个数的情况下才会进入内层循环,然后在内层循环中匹配连续序列中的数,因此数组中的每个数只会进入内层循环一次。根据上述分析可知,总时间复杂度为 O(n)。
-
空间复杂度:O(n)。哈希表存储数组中所有的数需要 O(n) 的空间。
代码:
class Solution {
public int longestConsecutive(int[] nums) {
HashSet<Integer> set = new HashSet<>();
int maxLen = 0;
for(int num : nums) {
set.add(num); //去重
}
for(int num : set) {
if(!set.contains(num - 1)) {
int curNum = num; //一个连续序列从这个数开始
int len = 1;
while(set.contains(curNum + 1)) {
curNum += 1;
len += 1;
}
maxLen = Math.max(maxLen, len);
}
}
return maxLen;
}
}
★ 1.两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
![ififlJ: nums - [2, 7, 11, 15], target - 9 nums[e] + nums[l] - -2+7=9](https://i.loli.net/2020/11/05/hPjTbOcByLwVCqz.png)
思路:
由于哈希查找的时间复杂度为 O(1),所以可以利用哈希容器 map 降低时间复杂度;
遍历数组 nums,i 为当前下标,每个值都判断map中是否存在 target-nums[i] 的 key 值;
如果存在则找到了两个值,如果不存在则将当前的 (nums[i],i) 存入 map 中,继续遍历直到找到为止;
如果最终都没有结果则抛出异常;
时间复杂度:O(n)。
代码:
class Solution {
public int[] twoSum(int[] nums, int target) {
//map的key为值,value为下标
HashMap<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < nums.length; i++) {
if(map.containsKey(target - nums[i])) {
return new int[] {map.get(target - nums[i]), i};
}
map.put(nums[i], i);
}
return new int[] {-1, -1};
}
}
剑指03.数组中重复的数字
找出数组中重复的数字。在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
![计算机生成了可选文字: 示例1: 输入: [2,3,1,9,2,5,3] 输出:2或3](https://i.loli.net/2020/11/05/wsLIBKS2VN3AFjT.png)
代码:
class Solution {
public int findRepeatNumber(int[] nums) {
HashSet<Integer> set = new HashSet<>();
for(int i = 0; i < nums.length; i++) {
if(set.contains(nums[i])) {
return nums[i];
}
set.add(nums[i]);
}
return -1;
}
}
138.复制带随机指针的链表(同剑指35. 复杂链表的复制)
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
要求返回这个链表的 深拷贝。
我们用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
![fif51J 1 : fif51J 2: . head - [17, null], . head -](https://i.loli.net/2020/11/05/LMQotzy8WmwcEYT.png)
思路:
- 创建一个hashmap,键与值分别为原链表节点和新链表节点。
- 第一遍遍历复制节点值。
- 第二遍遍历复制指向。
复杂度分析:
时间复杂度为O(N),空间复杂度为O(N)。
代码:
class Solution {
public Node copyRandomList(Node head) {
HashMap<Node, Node> map = new HashMap<>();
Node cur = head;
//第一遍复制值
while(cur != null) {
map.put(cur, new Node(cur.val));
cur = cur.next;
}
cur = head; //重置为头节点
//第二遍复制引用
while(cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
}
队列
剑指59 - I.滑动窗口的最大值
给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
示例:

思路:
![设 窗 囗 区 间 为 [i,j) , 最 大 值 为 与 。 当 窗 囗 向 前 移 动 一 格 , 则 区 间 变 为 0 + 1 , j 十 1 ] , 即 添 加 了 nums[j + 1 ] , 删 除 了 nums[i] 。 若 只 向 窗 口 [i,j] 右 边 添 加 数 字 nums[j + 1 ] , 则 新 窗 囗 最 大 值 可 以 通 过 一 次 对 比 使 用 00 ) 时 间 得 到 , 即 : xj+l : max(æj,nums[j + 1]) 而 由 于 删 除 的 nums[t] 可 能 恰 好 是 窗 囗 内 唯 一 的 最 大 值 与 , 因 此 不 能 通 过 以 上 方 氵 去 计 算 , 必 须 使 用 00 一 刁 时 间 , 遍 历 整 个 0 口 区 间 获 取 最 大 值 , 即 : 'Tj+l 一 max(nums(i + 1 ) , , num(j + 1 月](https://img-blog.csdnimg.cn/img_convert/2b6d16d6832079e49f7b1770b96d53fe.png)
本题难点: 如何在每次窗口滑动后,将 “获取窗口内最大值” 的时间复杂度从 O(k) 降低至 O(1) 。
“窗口滑动” 删除的是 “列表首部元素” ,本题使用 单调队列 即可解决以上问题。遍历数组时,每轮保证单调队列 deque :
- deque 内 仅包含窗口内的元素 ⇒ 每轮窗口滑动移除了元素 nums[i - 1] ,需将 deque 内的对应元素一起删除。
- deque 内的元素 非严格递减 ⇒ 每轮窗口滑动添加了元素 nums[j + 1] ,需将 deque 内所有 < nums[j + 1] 的元素删除。
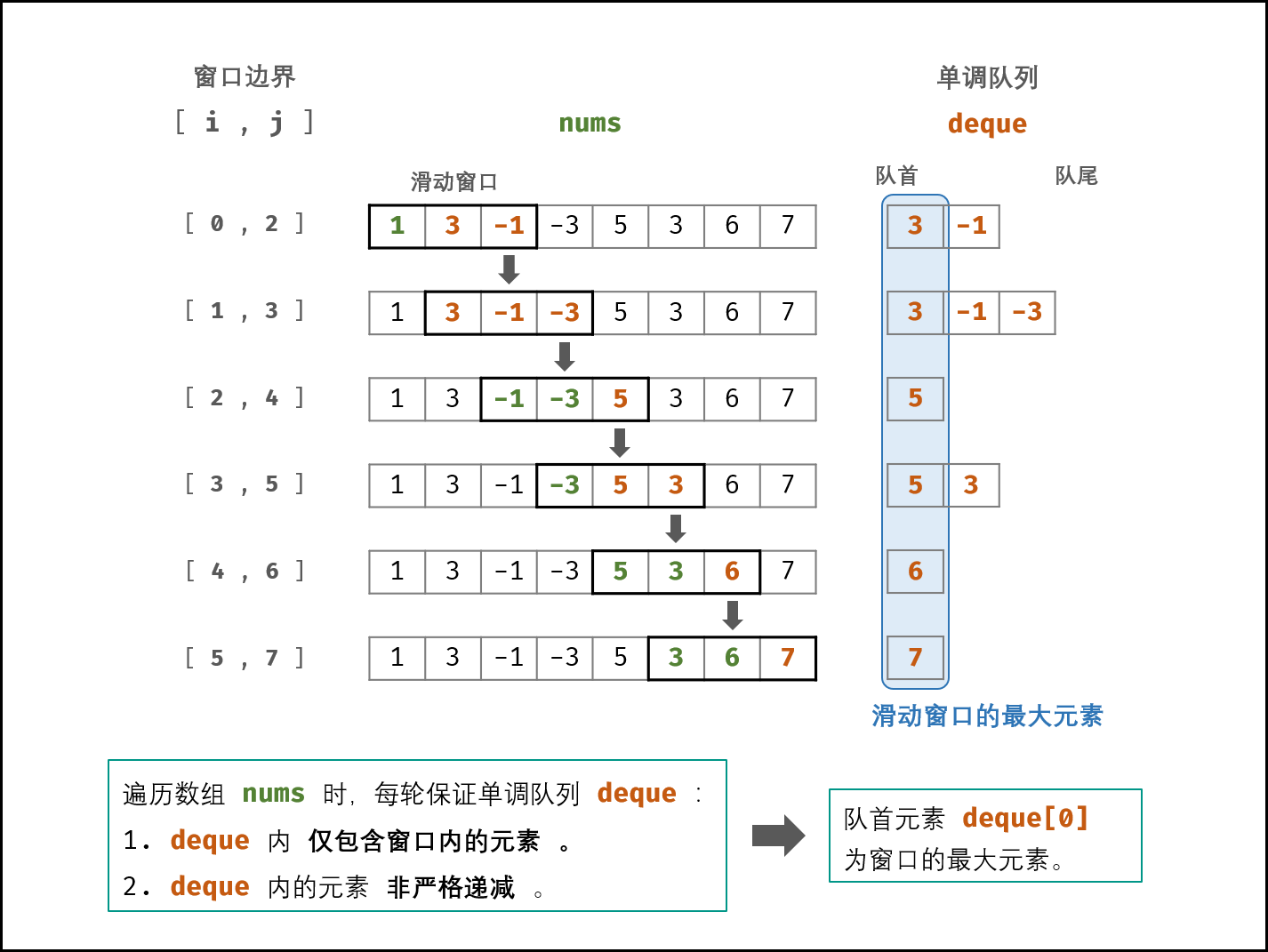
算法流程:
![1 . 初 始 化 : 双 端 队 列 deque , 结 果 列 表 “ 5 , 数 组 长 度 “ , 2 . 滑 动 窗 口 : 左 边 界 范 围 € [ 1 一 丛 “ + 1 一 胡 , 右 边 界 范 围 je [ 0 , 一 1 ] 1. 若 i > 0 且 队 首 元 素 que[0 ] : 被 删 除 元 素 nums[i 一 1 ] : 则 队 首 元 素 出 队 ; 2 . 删 除 deque 内 所 有 < nums[j] 的 元 素 , 以 保 持 deque 递 减 ; 3 . 将 numsj) 添 加 至 deque 尾 部 ; 4 . 若 已 形 成 窗 囗 〈 即 i 0 ) : 将 窗 囗 最 大 值 ( 即 队 首 元 素 que[O ] ) 添 加 至 列 表 res 。 3 . 返 回 值 : 返 回 结 果 列 表 “ 5 。
复杂度分析:
- 时间复杂度 O(n) : 其中 n 为数组 nums 长度;线性遍历 nums 占用 O(N) ;每个元素最多仅入队和出队一次,因此单调队列 deque 占用 O(2N) 。
- 空间复杂度 O(k) : 双端队列 deque 中最多同时存储 k 个元素(即窗口大小)。
代码:
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums.length == 0 || nums == null) return new int[0];
Deque<Integer> deque = new LinkedList<>();
int[] res = new int[nums.length - k + 1];
for(int i = 0; i < k; i++) { //未形成窗口
//删除 deque 内所有 < nums[j] 的元素,以保持 deque 递减
while(!deque.isEmpty() && deque.peekLast() < nums[i]) deque.removeLast();
deque.addLast(nums[i]); //将 nums[j] 添加至 deque 尾部
}
res[0] = deque.peekFirst(); //不能忘记这一步!
for(int i = k; i < nums.length; i++) { //形成窗口后
//nums[i-k] 就是对应此轮窗口滑动时,左边滑动出去的元素,若此元素是最大元素,则需要弹出
if(deque.peekFirst() == nums[i - k]) deque.removeFirst();
while(!deque.isEmpty() && deque.peekLast() < nums[i]) deque.removeLast();
deque.addLast(nums[i]);
res[i - k + 1] = deque.peekFirst();
}
return res;
}
}
字符串
修改字符串
使用一个StringBuilder 来接受新的字符串。
★ 151.翻转字符串里的单词(同58 - I. 翻转单词顺序)
给定一个字符串,逐个翻转字符串中的每个单词。

方法一:双指针法。
思路:
- 倒序遍历字符串 s ,记录单词左右索引边界 i, j ;
- 每确定一个单词的边界,则将其添加至单词列表 res ;
- 最终,将单词列表拼接为字符串,并返回即可。
复杂度分析:
时间复杂度 O(N) :其中 N 为字符串 s 的长度,线性遍历字符串。
空间复杂度 O(N) :新建的 StringBuilder(Java) 中的字符串总长度 ≤N ,占用 O(N) 大小的额外空间。
代码:
class Solution {
public String reverseWords(String s) {
s = s.trim();
int j = s.length() - 1, i = j;
StringBuilder res = new StringBuilder();
while(i >= 0) {
//下面的i >= 0不加这个条件的话返回值里面会缺失第一个单词
while(i >= 0 && s.charAt(i) != ' ') i--; //直到遇到第一个空格
res.append(s.substring(i + 1, j + 1) + " "); //添加单词
while(i >= 0 && s.charAt(i) == ' ') i--; //跳过所有的空格
j = i; //j 指向下个单词的尾字符
}
return res.toString().trim();
}
}
剑指05.替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
思路:
在 Python 和 Java 等语言中,字符串都被设计成不可变的类型,即无法直接修改字符串的某一位字符,需要新建一个字符串实现。
算法流程:
-
初始化一个 StringBuilder ,记为 res ;
-
遍历字符串 s 中的每个字符 c :
-
- 当 c 为空格时:向 res 后添加字符串 “%20”;
- 当 c 不为空格时:向 res 后添加字符 c ;
-
将 res 转化为 String 类型并返回。
复杂度分析:
时间复杂度 O(N) :遍历使用 O(N) ,每轮添加(修改)字符操作使用 O(1) ;
空间复杂度 O(N) :Java 新建的 StringBuilder 都使用了线性大小的额外空间。
代码:
class Solution {
public String replaceSpace(String s) {
StringBuilder res = new StringBuilder();
for(char c : s.toCharArray()) {
if(c == ' ') res.append("%20");
else res.append(c);
}
return res.toString();
}
}
剑指58 - II. 左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
方法一:切片法。
思路:
获取字符串 s[n:]s[n:] 切片和 s[:n]s[:n] 切片,使用 “++” 运算符拼接并返回即可。
复杂度分析:
时间复杂度 O(N): 其中 N 为字符串 s 的长度,字符串切片函数为线性时间复杂度;
空间复杂度 O(N): 两个字符串切片的总长度为 N 。
代码:
class Solution {
public String reverseLeftWords(String s, int n) {
return s.substring(n, s.length()) + s.substring(0, n);
}
}
方法二:列表遍历拼接
思路:
- 新建一个 StringBuilder(Java) ,记为 res ;
- 先向 res 添加 “第 n + 1 位至末位的字符” ;
- 再向 res 添加 “首位至第 n 位的字符” ;
- 将 res 转化为字符串并返回。
复杂度分析:
时间复杂度 O(N) :线性遍历 s 并添加,使用线性时间;
空间复杂度 O(N) :新建的辅助 res 使用 O(N) 大小的额外空间。
代码:
class Solution {
public String reverseLeftWords(String s, int n) {
StringBuilder res = new StringBuilder();
for(int i = n; i < s.length(); i++)
res.append(s.charAt(i));
for(int i = 0; i < n; i++)
res.append(s.charAt(i));
return res.toString();
}
}
★ 415.字符串相加(大数相加通常指此题)
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和。
提示:
num1 和num2 的长度都小于 5100;
num1 和num2 都只包含数字 0-9;
num1 和num2 都不包含任何前导零;
你不能使用任何內建 BigInteger 库, 也不能直接将输入的字符串转换为整数形式。
思路:
本题与 2. 两数相加 做法完全相同。

复杂度分析:

代码:
class Solution {
public String addStrings(String num1, String num2) {
StringBuilder res = new StringBuilder();
int i = num1.length() - 1, j = num2.length() - 1;
int carry = 0;
while(i >= 0 || j >= 0) {
int n1 = i >= 0 ? num1.charAt(i) - '0' : 0;
int n2 = j >= 0 ? num2.charAt(j) - '0' : 0;
int tmp = n1 + n2 + carry;
carry = tmp / 10;
res.append(tmp % 10);
i--;
j--;
}
if(carry == 1) res.append(1);
return res.reverse().toString();
}
}
其他
★ 3.无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
代码:
class Solution {
public int lengthOfLongestSubstring(String s) {
if(s.length() == 0) return 0;
HashMap<Character, Integer> map = new HashMap<>();
int left = 0, max = 0; //left为滑动窗口左下标,i相当于滑动窗口右下标
for(int i = 0; i < s.length(); i++) {
if(map.containsKey(s.charAt(i))) {
//map.get():返回字符所对应的索引,当发现重复元素时,窗口左指针右移
//如"abca",map中已有key为a的元素,则left更新为这个a的下一个元素b,即map.get(s.charAt(i) + 1)
//用Math.max而不直接更新left为map.get(s.charAt(i)) + 1是因为map得到的索引下标不一定在滑动窗口内
left = Math.max(left, map.get(s.charAt(i)) + 1);
}
map.put(s.charAt(i), i); //再更新map中a映射的下标
max = Math.max(max, i - left + 1); //比较两个参数的大小
}
return max;
}
}
拓展:将题目改动一下,返回该最长无重复子串。
代码:
class Solution {
public String lengthOfLongestSubstring(String s) {
if(s.length() == 0) return s;
HashMap<Character, Integer> map = new HashMap<>();
int left = 0, max = 0;
int start = 0, end = 0;
for(int i = 0; i < s.length(); i++) {
if(map.containsKey(s.charAt(i))) {
left = Math.max(left, map.get(s.charAt(i)) + 1);
}
map.put(s.charAt(i), i);
if(max < i - left + 1){
start = left;
end = i;
max = i - left + 1;
}
}
return s.substring(start, end + 1);
}
}
★ 8.字符串转换整数 (atoi)(同剑指67. 把字符串转换成整数)
写一个函数 StrToInt,实现把字符串转换成整数这个功能。不能使用 atoi 或者其他类似的库函数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。
当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该整数的正负号;假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。
在任何情况下,若函数不能进行有效的转换时,请返回 0。
说明:
假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 [−231, 231 − 1]。如果数值超过这个范围,请返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。

思路:

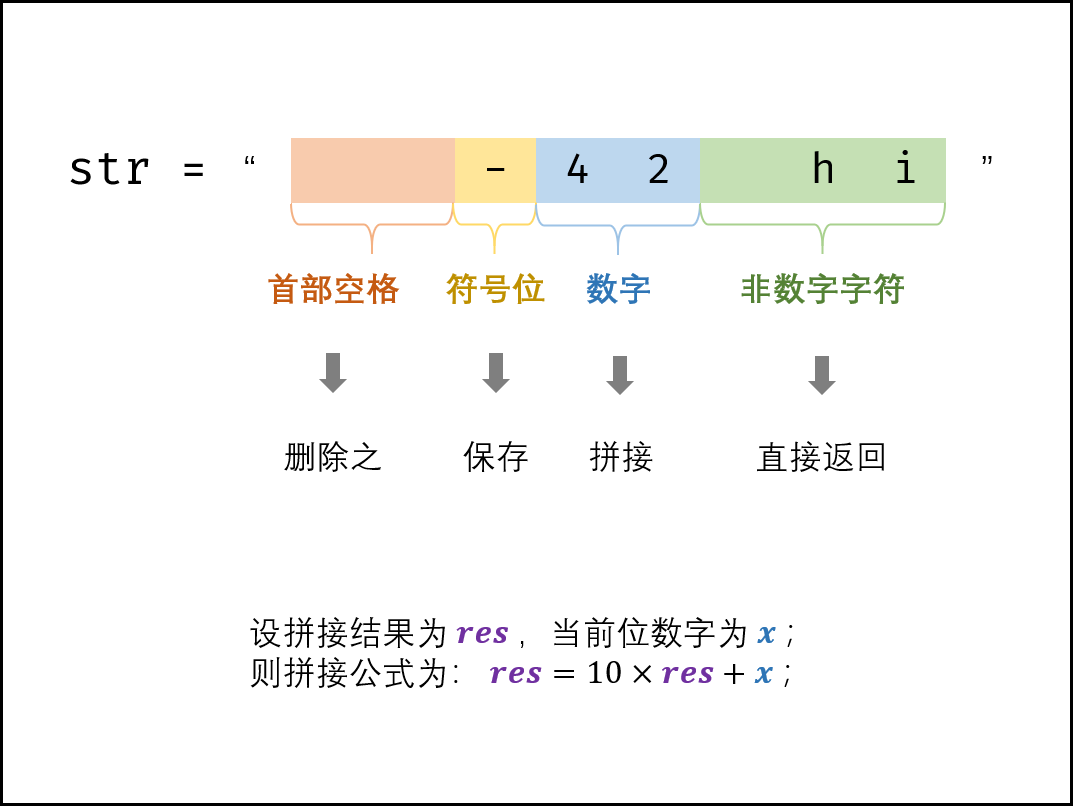
数字越界处理:
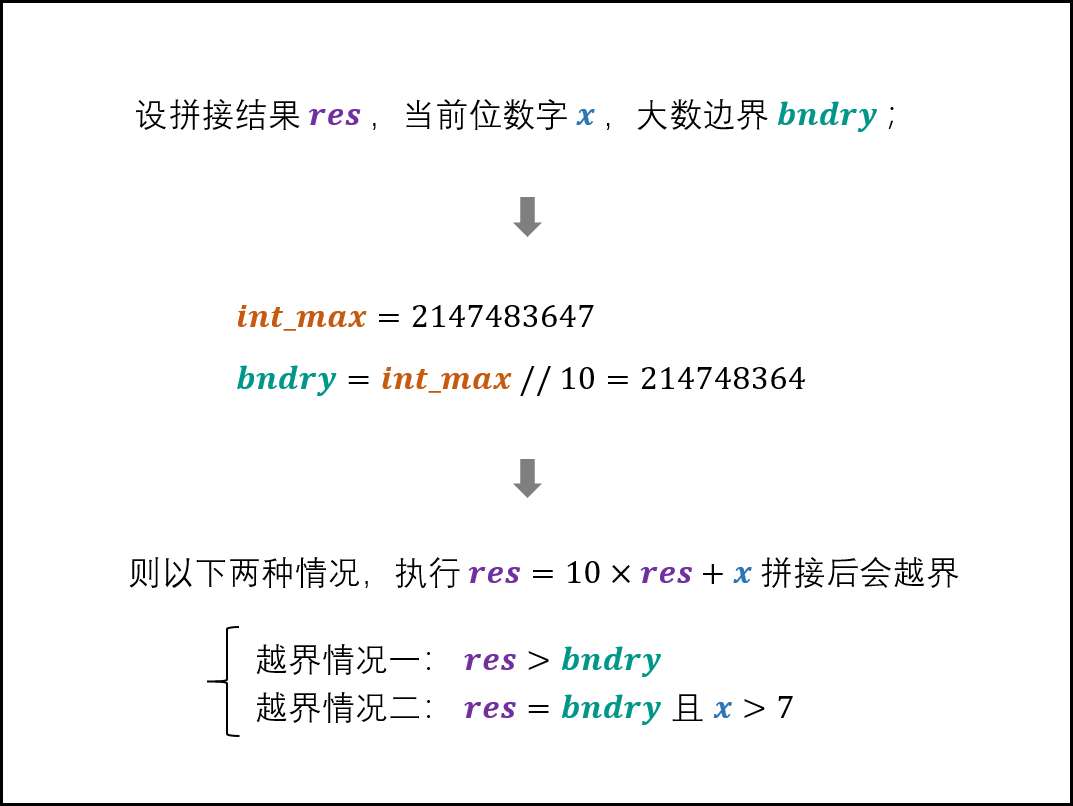
复杂度分析:
时间复杂度与空间复杂度均为O(N)。
代码:
class Solution {
public int strToInt(String str) {
char[] c = str.trim().toCharArray();
if(c.length == 0) return 0;
int res = 0, boundary = Integer.MAX_VALUE / 10;
int i = 1, sign = 1;
if(c[0] == '-') sign = -1;
else if(c[0] != '+') i = 0;
for(int j = i; j < c.length; j++) {
if(c[j] < '0' || c[j] > '9') break;
if(res > boundary || res == boundary && c[j] > '7')
return sign == 1 ? Integer.MAX_VALUE : Integer.MIN_VALUE;
res = res * 10 + (c[j] - '0');
}
return sign * res;
}
}
14.最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 “”。
思路:
- 当字符串数组长度为 0 时则公共前缀为空,直接返回;
- 令最长公共前缀 ans 的值为第一个字符串,进行初始化;
- 遍历后面的字符串,依次将其与 ans 进行比较,两两找出公共前缀,最终结果即为最长公共前缀;
- 如果查找过程中出现了 ans 为空的情况,则公共前缀不存在直接返回;
- 时间复杂度:O(s),s 为所有字符串的长度之和。
代码:
class Solution {
public String longestCommonPrefix(String[] strs) {
if(strs.length == 0) return "";
String res = strs[0];
for(int i = 1; i < strs.length; i++) {
int j = 0;
for(; j < res.length() && j < strs[i].length(); j++) {
if(res.charAt(j) != strs[i].charAt(j)) {
break;
}
}
res = res.substring(0, j);
if(res.equals("")) return "";
}
return res;
}
}
二分法
时间复杂度
二分法是通过 O(1) 的时间将一个规模为 n 的问题降为了 n/2,即 T(n) = T(n/2) + O(1) 。再往下计算为:
T(n) = T(n/2) + O(1) = T(n/4) + 2 * O(1) = T(n/8) + 3 * O(1) = T(1) + log(n) * O(1) = O(logN) 。
二分法模板
public int binarySearch(int[] nums, int target) {
if(nums == null || nums.length == 0) {
return -1;
}
int start = 0, end = nums.length - 1;
while(start + 1 < end) {
int mid = start + (end - start) / 2;
if(nums[mid] == target) {
end = mid; //或start = mid
} else if (nums[mid] < target) {
start = mid;
} else {
end = mid;
}
}
if(nums[start] == target) {
return start;
}
if(nums[end] == target) {
return end;
}
return -1;
}
几个需要注意的点:
- start + 1 < end
- start + (end - start) / 2
- A[mid] ==, <, >
- A[start] A[end] ? target
题目
162.寻找峰值
峰值元素是指其值大于左右相邻值的元素。
给定一个输入数组 nums,其中 nums[i] ≠ nums[i+1],找到峰值元素并返回其索引。
数组可能包含多个峰值,在这种情况下,返回任何一个峰值所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞。
![计算机生成了可选文字: 示例1: 输入: [1丿2丿3丿1] numS 输出: 2 解释:3是峰值元素,你的函数应该返回其紊引2。 示例2: 输入: [1丿2丿1丿3丿5丿6丿4] numS 输出:1或5 解释:你的函数可以返回紊引1,其峰值元素为2; 或者返回紊引5,其峰值元素为6。](https://i.loli.net/2020/11/05/HLyX6AJ8I3MZuTS.png)
代码:
class Solution {
public int findPeakElement(int[] nums) {
int start = 0, end = nums.length - 1;
while(start + 1 < end) {
int mid = start + (end - start) / 2;
if(nums[mid] < nums[mid + 1]) { //上升序列,峰值在其右边
start = mid;
} else if(nums[mid] < nums[mid - 1]) { //下降序列,峰值在其左边
end = mid;
}
}
if(nums[start] < nums[end]) { //最后剩下两个数,较大的为峰值
return end;
} else {
return start;
}
}
}
★ 33.搜索旋转排序数组
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
你可以假设数组中不存在重复的元素。
你的算法时间复杂度必须是 O(log n) 级别。
![计算机生成了可选文字: 示例1: 输入: 输出: 示例2: 输入: 输出· numS 4 numS 一1 [4丿5丿6丿7丿9丿1丿2], [4丿5丿6丿7丿9丿1丿2], target target 3](https://i.loli.net/2020/11/05/TdQLgqbH4FaXhc3.png)
思路:
可以自己手写几个旋转数组,经过实验可以发现,将待搜索区间从中间一分为二,mid 一定会落在其中一个有序区间里。比如 1 2 3 4 5 6 7 可以大致分为两类,
-
第一类 2 3 4 5 6 7 1 这种,也就是 nums[start] < nums[mid]。此例子中就是 2 < 5。
这种情况下,前半部分有序。因此如果 nums[start] <=target<nums[mid],则在前半部分找,target 落在其中,能且只能等于其中的一个元素,当然包括头尾。否则就是上一个情况的反面,这种情况用 else 表示即可,去后半部分找。
-
第二类 6 7 1 2 3 4 5 这种,也就是 nums[start] >= nums[mid]。此例子中就是 6 >= 2。
这种情况下,后半部分有序。因此如果 nums[mid] <target<=nums[end],则在后半部分找,否则去前半部分找。
时间复杂度:O(logn),其中 n 为nums[] 数组的大小。
代码:
class Solution {
public int search(int[] nums, int target) {
if(nums == null || nums.length == 0) return -1;
int start = 0, end = nums.length - 1;
while(start + 1 < end) {
int mid = start + (end - start) / 2;
if(nums[mid] == target) return mid;
// 先根据 nums[mid] 与 nums[start] 的关系判断 mid 是在左段还是右段
if(nums[start] < nums[mid]) {
// 再判断 target 是在 mid 的左边还是右边,从而调整左右边界 start 和 end
if(nums[start] <= target && nums[mid] >= target) {
end = mid;
} else {
start = mid;
}
} else {
if(nums[end] >= target && nums[mid] <= target) {
start = mid;
} else {
end = mid;
}
}
}
if(nums[start] == target) return start;
if(nums[end] == target) return end;
return -1;
}
}
★ 34.在排序数组中查找元素的第一个和最后一个位置
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
你的算法时间复杂度必须是 O(log n) 级别。
如果数组中不存在目标值,返回 [-1, -1]。
![fif51J 2: nums [3,4] nums [-1,-1] target = 8 target = 6](https://i.loli.net/2020/11/05/1Juxophicz5BC2a.png)
思路:
两次二分法。查找元素的第一个位置和平常的做法一样;而查找最后一个位置有两处改动:一是 nums[mid] == target 时的情况不同;二是出了循环以后一定要先写 nums[end] == target,这样才能保证先返回后面的位置。另外还有一个边界条件很重要,要提前处理,即 nums[start] != target && nums[end] != target 时返回 [-1, -1],说明该数不存在。
代码:
class Solution {
public int[] searchRange(int[] nums, int target) {
if(nums == null || nums.length == 0) {
return new int[] {-1, -1};
}
int[] res = new int[2];
int start = 0, end = nums.length - 1;
while(start + 1 < end) {
int mid = start + (end - start) / 2;
if(nums[mid] >= target) { //此时nums[mid]应一直往左收缩,直到左边界
end = mid;
} else {
start = mid;
}
}
if(nums[start] != target && nums[end] != target) { //该数不存在
return new int[]{-1, -1};
}
if(nums[start] == target) res[0] = start;
else if(nums[end] == target) res[0] = end;
start = 0; end = nums.length - 1;
while(start + 1 < end) {
int mid = start + (end - start) / 2;
if(nums[mid] <= target) { //此时nums[mid]应一直往右收缩,直到右边界
start = mid;
} else {
end = mid;
}
}
if(nums[end] == target) res[1] = end;
else if(nums[start] == target) res[1] = start;
return res;
}
}
69.x 的平方根
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。

思路:
由于 x 平方根的整数部分 ans 是满足 k^2 ≤x 的最大 k 值,因此我们可以对 k 进行二分查找,从而得到答案。
二分查找的下界为 0,上界可以粗略地设定为 x。在二分查找的每一步中,我们只需要比较中间元素 mid 的平方与 x 的大小关系,并通过比较的结果调整上下界的范围。
时间复杂度 O(logx),即为二分查找需要的次数。
代码:
class Solution {
public int mySqrt(int x) {
long X = (long) x;
long l = 0, r = X;
while (l + 1 < r) {
long mid = l + (r - l) / 2;
if (mid * mid == X) {
return (int) mid;
} else if (mid * mid < X) {
l = mid;
} else {
r = mid;
}
}
if (r * r == X) return (int) r; //r * r只可能 >= X,不可能 < X
return (int) l;
}
}
153.寻找旋转排序数组中的最小值(同剑指11. 旋转数组的最小数字)
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
你可以假设数组中不存在重复元素。
![示 例 1 : 输 入 : 输 出 , 示 例 2 : 输 入 : 输 出 , [ ‰ 习 1J2 ] 1 [ 4J5 , 6J7J9JIJ2 ]](https://i.loli.net/2020/11/05/6YFoE9aSW3N1Mxv.png)
思路:
用二分法查找,需要始终将目标值(这里是最小值)套住,并不断收缩左边界或右边界。
左、中、右三个位置的值相比较,有以下几种情况:
- 左值 < 中值, 中值 < 右值 :没有旋转,最小值在最左边,可以收缩右边界,如 1234567;
- 左值 > 中值, 中值 < 右值 :有旋转,最小值在左半边,可以收缩右边界,如 6712345;
- 左值 < 中值, 中值 > 右值 :有旋转,最小值在右半边,可以收缩左边界,如 4567123。
分析前面三种可能的情况,会发现情况1、2是一类,情况3是另一类。
- 如果中值 < 右值,则最小值在左半边,可以收缩右边界。
- 如果中值 > 右值,则最小值在右半边,可以收缩左边界。
通过比较中值与右值,可以确定最小值的位置范围,从而决定边界收缩的方向。
Q:那么能不能通过比较mid与left来解决问题?
A:能,转换思路,不直接找最小值,而是先找最大值,最大值偏右,可以通过比较mid与left来找到最大值,最大值向右移动一位就是最小值了(需要考虑最大值在最右边的情况,右移一位后对数组长度取余)。
代码:
class Solution {
public int findMin(int[] nums) {
int start = 0, end = nums.length - 1;
while(start + 1 < end) {
int mid = start + (end - start) / 2;
if(nums[end] > nums[mid]) {
end = mid;
} else {
start = mid;
}
}
return Math.min(nums[start], nums[end]);
}
}
不要太拘泥于模板,以下两题用上面的模板很难实现。用 i <= j 作为跳出条件,这样跳出时 i 在 j 的右边,在 剑指53 - I 里正好为右边界,在 剑指53 - II 里可以解决数字无缺失的情况,如 [0,1,2],则缺失的数字为3,这正好是 i 当前所在的位置。
剑指53 - I. 在排序数组中查找数字 I
统计一个数字在排序数组中出现的次数。
思路:
本题与 LC34. 在排序数组中查找元素的第一个和最后一个位置 相同,仅返回值不同。
排序数组中的搜索问题,首先想到 二分法 解决。
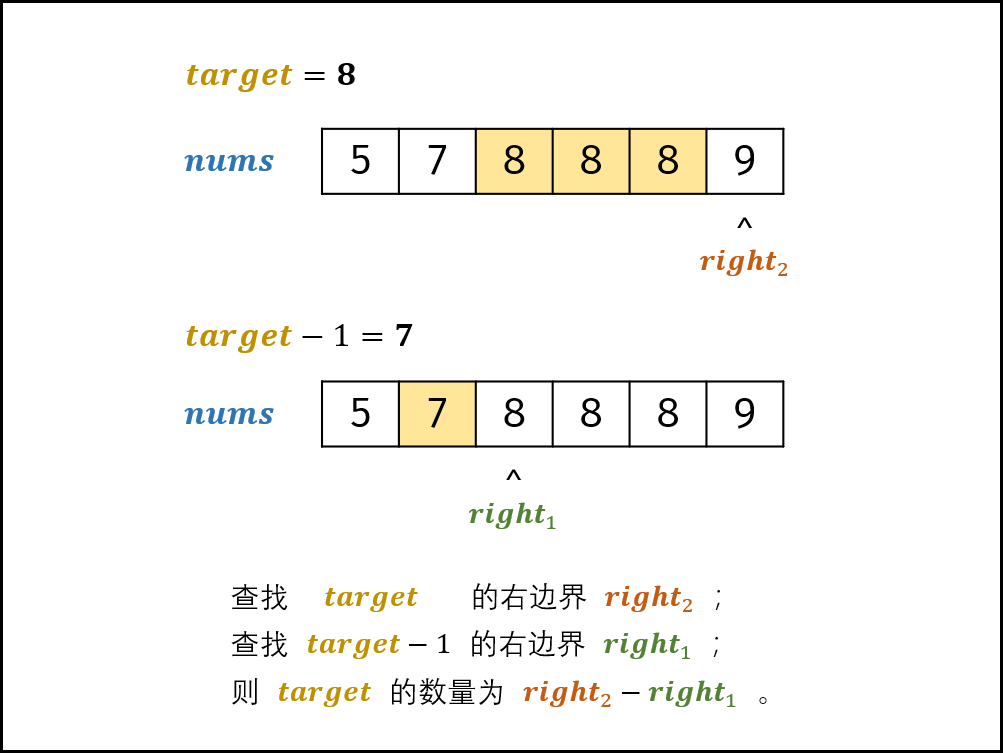
如上图所示,由于数组 nums 中元素都为整数,因此可以分别二分查找 target 和 target - 1 的右边界,将两结果相减并返回即可。
本质上看,helper() 函数旨在查找数字 tar 在数组 nums 中的 插入点 ,且若数组中存在值相同的元素,则插入到这些元素的右边。
复杂度分析:
时间复杂度 O(log N):二分法为对数级别复杂度。
空间复杂度 O(1):几个变量使用常数大小的额外空间。
代码:
class Solution {
public int search(int[] nums, int target) {
return helper(nums, target) - helper(nums, target - 1);
}
public int helper(int[] nums, int target) {
int i = 0, j = nums.length - 1;
//当i > j时跳出循环,并记录右边界right=i
while(i <= j) {
int m = (i + j) / 2;
if(target >= nums[m]) i = m + 1;
else j = m - 1;
}
return i;
}
}
剑指53 - II. 0~n-1中缺失的数字
一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围 0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
![计算机生成了可选文字: 示例1: 输入: 输出: 示例2: 输入: 输出: [1J3] 2 [9)1,2,3,4,5)6)7,9] 8](https://i.loli.net/2020/11/05/xZFgQqbMo7eR39Y.png)
思路:
仍然使用二分查找。根据题意,数组可以按照以下规则划分为两部分。
- 左子数组:nums[i] = i ;
- 右子数组:nums[i] ≠i;
缺失的数字等于 “右子数组的首位元素” 对应的索引;因此考虑使用二分法查找 “右子数组的首位元素” 。
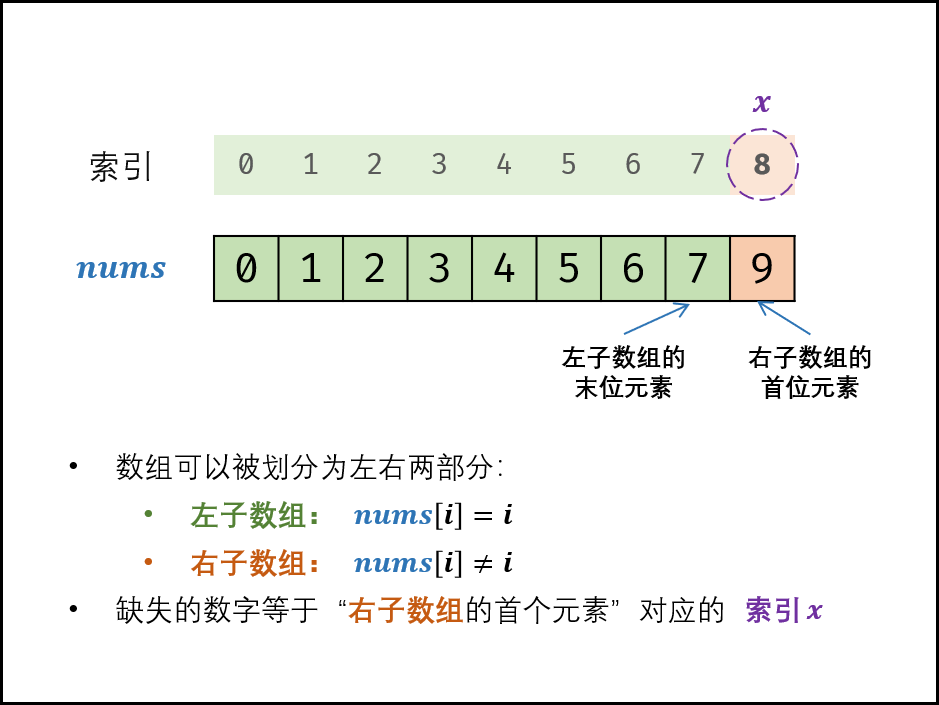
算法流程:

复杂度分析:
时间复杂度 O(log N): 二分法为对数级别复杂度。
空间复杂度 O(1): 几个变量使用常数大小的额外空间。
代码:
class Solution {
public int missingNumber(int[] nums) {
int i = 0, j = nums.length - 1;
while(i <= j) {
int m = (i + j) / 2;
if(nums[m] == m) i = m + 1;
else j = m - 1;
}
return i;
}
}
回溯
22.括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。

思路:
dfs + 剪枝。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vjRHeQal-1639998765373)(https://i.loli.net/2020/11/05/pvirmudgYjIhwMU.png)]
如图所示,我们规定:
- 当前左右括号都有大于 0 个可以使用的时候,才产生分支;
- 产生左分支的时候,只看当前是否还有左括号可以使用;
- 产生右分支的时候,还受到左分支的限制,右边剩余可以使用的括号数量一定得在严格大于左边剩余的数量的时候,才可以产生分支;
- 在左边和右边剩余的括号数都等于 0 的时候结算。
复杂度分析:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-slEW7JB6-1639998765376)(https://i.loli.net/2020/11/05/QGmSMVAFpkKz6Pu.png)]
代码:
class Solution {
List<String> res = new ArrayList<>(); //结果
StringBuilder path = new StringBuilder(); //路径
public List<String> generateParenthesis(int n) {
if(n == 0) return res;
dfs(path, n, n);
return res;
}
private void dfs(StringBuilder path, int left, int right) {
//终结条件,加入res,返回
if(left == 0 && right == 0) {
res.add(path.toString()); // path.toString() 生成了一个新的字符串,相当于做了一次拷贝
return;
}
//剪枝,提前返回
if(left > right) return;
//1.add 2.开启下一层dfs 3.remove最后一个值
if(left > 0) {
path.append('(');
dfs(path, left - 1, right);
path.deleteCharAt(path.length() - 1);
}
if(right > 0) {
path.append(')');
dfs(path, left, right - 1);
path.deleteCharAt(path.length() - 1);
}
}
}
93.复原IP地址
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
有效的 IP 地址正好由四个整数(每个整数位于 0 到 255 之间组成),整数之间用 ‘.’ 分隔。
![fif51J: "25525511135" ["255.255.11.135", "255.255.111.35"]](https://i.loli.net/2020/11/05/FS4VnbIMAEL18fu.png)
思路:(图要学会自己画!)
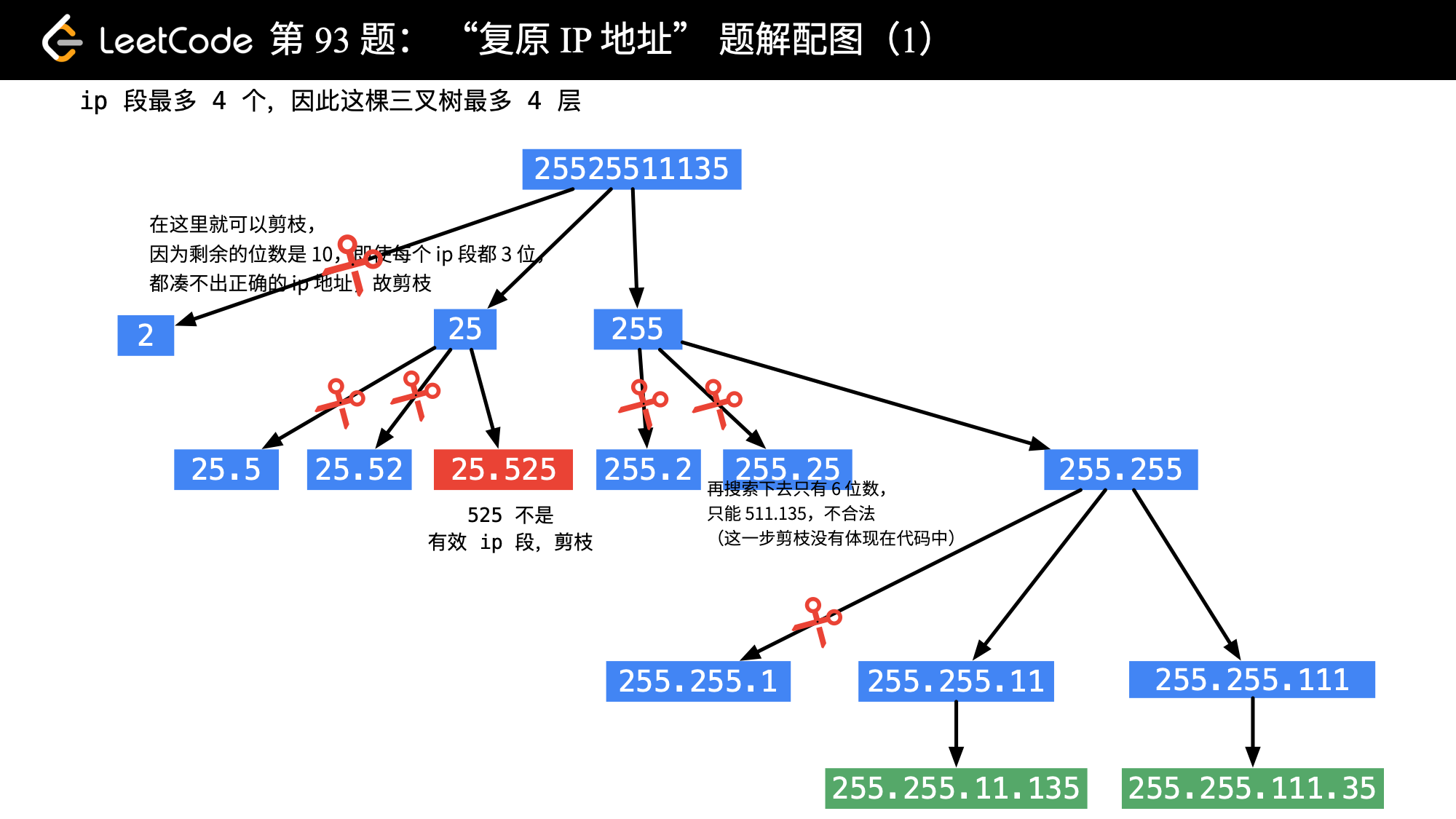
如图所示,可能的剪枝条件有:
- 一开始,字符串的长度小于 4 或者大于 12 ,一定不能拼凑出合法的 ip 地址(这一点可以化到中间结点的判断中,以产生剪枝行为);
- 每一个结点可以选择截取的方法只有 3 种:截 1 位、截 2 位、截 3 位,因此每一个结点可以生长出的分支最多只有 3 条分支;
- 根据截取出来的字符串判断是否是合理的 ip 段,如是否小于 255,子段大于 1 位的时候,不能以 0 开头;
- 由于 ip 段最多就 4 个段,因此这棵三叉树最多 4 层,这个条件作为递归终止条件。
时间复杂度:
难以分析。。。
代码:
class Solution {
List<String> res = new ArrayList<>();
StringBuilder path = new StringBuilder();
public List<String> restoreIpAddresses(String s) {
if(s.length() < 4 || s.length() > 12) return res;
dfs(s, 0, 0);
return res;
}
// depth控制递归深度
private void dfs(String s, int index, int depth) {
int len = path.length();
// 如果字符串都取完了,可以加入结果集
if(depth == 4 && index == s.length()) {
path.deleteCharAt(len - 1); // 移除掉最后的"."
res.add(path.toString());
return;
}
// 每组ip地址的长度,最大为3
for(int i = 1; i <= 3; i++) {
if(index + i > s.length()) break; //索引超出字符串长度
String subIp = s.substring(index, index + i); //以.分隔开的子段
int num = Integer.valueOf(subIp); //Integer.valueOf会remove掉数字开头的0
if(num > 255) break; // 注意ip数字的合法性,不能大于255
// 不能存在01.001.01.01(子段大于1位的时候,不能以0开头)
if(String.valueOf(num).length() != i) break;
path.append(subIp + ".");
dfs(s, index + i, depth + 1);
path.setLength(len);
}
}
}
★ 113.路径总和 II(同剑指34. 二叉树中和为某一值的路径)
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
说明: 叶子节点是指没有子节点的节点。
![示 例 : 给 定 如 下 二 叉 树 , 11 返 回 : 以 及 目 标 和 su m = 22 , 13 4 [ 5 , 4J11J2L [ 5 , 8J4 师 ]](https://i.loli.net/2020/11/05/KyCPBs2pjzR3Iwn.png)
复杂度分析:
时间复杂度 O(N) :N 为二叉树的节点数,先序遍历需要遍历所有节点。
空间复杂度 O(N) :最差情况下,即树退化为链表时,path 存储所有树节点,使用 O(N) 额外空间。
代码:
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> path = new LinkedList<>(); //需要定义具体实现
public List<List<Integer>> pathSum(TreeNode root, int sum) {
dfs(root, sum);
return res;
}
void dfs(TreeNode root, int sum) {
//终结条件
//本题无需剪枝,无需提前返回
if(root == null) return;
path.add(root.val);
sum -= root.val;
//这道题有点特殊,一般这里是终结条件,要返回,但这里并未终结,只加入结果集,不返回
if(sum == 0 && root.left == null && root.right == null) {
res.add(new LinkedList(path)); //需要拷贝一份
}
dfs(root.left, sum);
dfs(root.right, sum);
path.removeLast();
}
}
求一个数组的所有子集
代码:
public class SubArrays {
public static List<List<Integer>> getSubArrays(int[] arr) {
List<List<Integer>> res = new ArrayList<>();
List<Integer> list = new ArrayList<>();
backtrack(arr, res, list, 0);
return res;
}
private static void backtrack(int[] arr, List<List<Integer>> res, List<Integer> list, int i) {
//从数组第一位数开始,获取该数与后面数组合的所有可能。第一位组合完到第二位...直到最后一位
res.add(new ArrayList(list));
for(int j = i; j < arr.length; j++) {
list.add(arr[j]);
backtrack(arr, res, list, j + 1);
list.remove(list.size() - 1);
}
}
}
动态规划
★ 509.斐波那契数
斐波那契数,通常用 F(n) 表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
给定 N,计算 F(N)。

代码:
class Solution {
public int fib(int N) {
if(N == 1 || N == 2) return 1;
int pre = 1, cur = 1, sum = 0;
for(int i = 3; i <= N; i++) {
sum = pre + cur;
pre = cur;
cur = sum;
}
return sum;
}
}
★ 70.爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
注意:给定 n 是一个正整数。
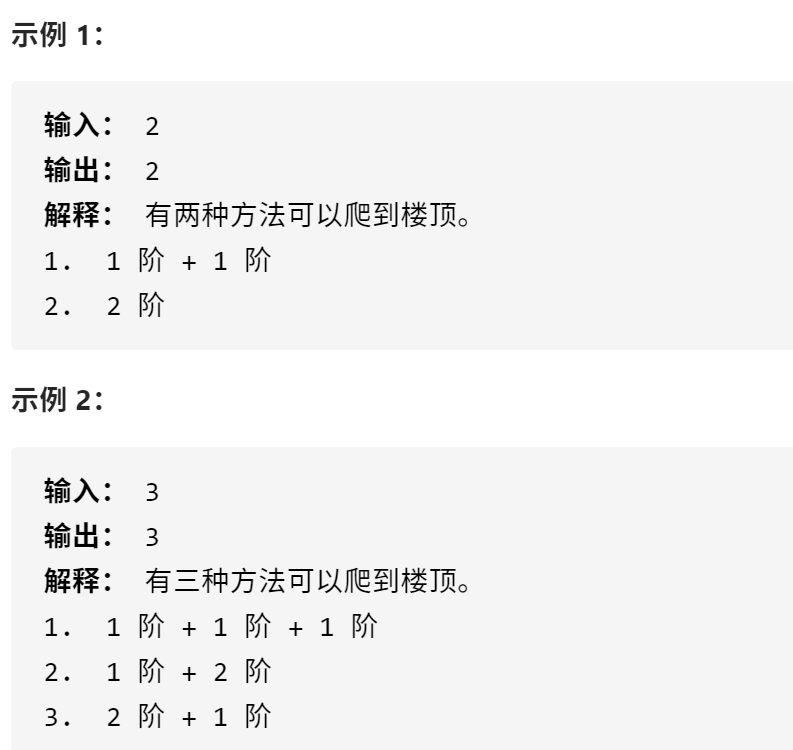
思路:
本问题其实常规解法可以分成多个子问题,爬第n阶楼梯的方法数量,等于2部分之和:
- 爬上 n-1 阶楼梯的方法数量。因为再爬1阶就能到第n阶
- 爬上 n-2 阶楼梯的方法数量,因为再爬2阶就能到第n阶
所以我们得到公式 dp[n] = dp[n-1] + dp[n-2],同时需要初始化 dp[0]=1 和 dp[1]=1。
时间复杂度:O(n)。
代码:
class Solution {
public int climbStairs(int n) {
int[] dp = new int[n + 1];
dp[0] = 1; dp[1] = 1;
for(int i = 2; i < dp.length; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}
状态压缩:
class Solution {
public int climbStairs(int n) {
int pre = 1, cur = 1, sum = 1; //sum的初始值相当于dp[0],此处应为1
for(int i = 2; i <= n; i++) {
sum = pre + cur;
pre = cur;
cur = sum;
}
return sum;
}
}
198.打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
![示 例 1 : 输 出 . 3 ) 。 输 入 : [ 的 乙 3 , 1 ] 解 释 : 偷 窃 1 号 房 屋 〈 金 额 = 1 ) , 然 后 偷 窃 3 号 房 屋 ( 金 额 = 俺 窃 到 的 最 高 金 额 = 1 + 3 = 4](https://i.loli.net/2020/11/05/CTzoWBpkm72VycG.png)
代码:
class Solution {
public int rob(int[] nums) {
int pre = 0, cur = 0;
for(int num : nums) {
int tmp = cur;
cur = Math.max(cur, pre + num);
pre = tmp;
}
return cur;
}
}
★ 322.零钱兑换
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
![计算机生成了可选文字: 示例1: 输入: 输出: 解释: 示例2: 输入: 输出: [1丿2丿5], CO工nS 3 11 5+5+1 amount 3 11 CO工nS 一1 amount](https://i.loli.net/2020/11/05/vBSZdQaRW5JI9PK.png)
思路:
对于这道题,以coins = [1, 2, 5], amount = 11为例
我们要求组成11的最少硬币数,可以考虑组合中的最后一个硬币分别是1,2,5的情况,比如
- 最后一个硬币是1的话,最少硬币数应该为【组成10的最少硬币数】+ 1枚(1块硬币)
- 最后一个硬币是2的话,最少硬币数应该为【组成9的最少硬币数】+ 1枚(2块硬币)
- 最后一个硬币是5的话,最少硬币数应该为【组成6的最少硬币数】+ 1枚(5块硬币)
在这3种情况中硬币数最少的那个就是结果
按同样的道理,我们也可以分别再求出组成10的最少硬币数,组成9的最少硬币数,组成6的最少硬币数。。。
这种当前状态的问题可以转化成之前状态问题的,一般就是动态规划的套路
所以我们自底向上依次求组成1,2…一直到11的最少硬币数。
对每一个数,依次比较最后一个硬币是不同面额的情况,从中选出最小值。
⚠️注意:这里有两个小技巧:
预设一个0位方便后续计算,组成0的最少硬币数是0,所以dp[0] = 0;
给每一个数预设一个最小值amount+1,因为硬币面额最小为整数1,所以只要有解,最小硬币数必然小于amount+1。其实设为 Integer.MAX_VALUE 也可以。
dp的最后一项就是答案。判断dp的最后一项是否大于amount,大于则说明没有任何一种硬币组合能组成总金额,返回 -1。
复杂度分析:
时间复杂度:O(Sn),其中 S 是金额,n 是面额数。我们一共需要计算 O(S) 个状态,S 为题目所给的总金额。对于每个状态,每次需要枚举 n 个面额来转移状态,所以一共需要 O(Sn) 的时间复杂度。
空间复杂度:O(S)。DP 数组需要开长度为总金额 S 的空间。
代码:
class Solution {
public int coinChange(int[] coins, int amount) {
//dp[i]表示总金额为i时,凑成i所需的最少的硬币个数
int[] dp = new int[amount + 1];
dp[0] = 0;
for(int i = 1; i < dp.length; i++) {
dp[i] = amount + 1;
for(int coin : coins) {
if(i - coin >= 0) {
//dp[i - coin]表示前一个状态所需最少硬币数
dp[i] = Math.min(dp[i], dp[i - coin] + 1);
}
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
}
1143.最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,“ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。

思路:
dp[i][j]表示text1的前i个字符和text2的前j个字符的最长公共子序列。
现在对比的这两个字符不相同的,那么我们要取它的「要么是text1往前退一格,要么是text2往前退一格,两个的最大值」,即
dp[i + 1][j + 1] = Math.max(dp[i+1][j], dp[i][j+1]);
对比的两个字符相同,去找它们前面各退一格的值加1即可:dp[i+1][j+1] = dp[i][j] + 1。
int[][] dp = new int[m+1][n+1]。
这里为什么要加1,原因是你可以不加1,但是不加1你就会用其它限制条件来确保这个index是有效的,而当你加1之后你就不需要去判断只是让索引为0的行和列表示空串。
代码:
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int m = text1.length(), n = text2.length();
int[][] dp = new int[m + 1][n + 1];
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
char c1 = text1.charAt(i), c2 = text2.charAt(j);
if(c1 == c2) {
dp[i + 1][j + 1] = dp[i][j] + 1;
} else {
dp[i + 1][j + 1] = Math.max(dp[i + 1][j], dp[i][j + 1]);
}
}
}
return dp[m][n];
}
}
牛客 最长公共子串
给定两个字符串str1和str2,输出两个字符串的最长公共子串,如果最长公共子串为空,输出-1。
代码:
public class Solution {
public String LCS (String str1, String str2) {
int m=str1.length(),n=str2.length();
int[][] dp=new int[m+1][n+1];
int max=0,index=0;
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(str1.charAt(i)==str2.charAt(j)){
//dp[i][j]代表 str1[0~i-1]和str2[0~j-1] 的最长公共子串的长度
dp[i+1][j+1]=dp[i][j]+1;
if(max<dp[i+1][j+1]){
max=dp[i+1][j+1]; //记录下最长公共子串的长度
index=i+1; //记录下出现“最长公共子串”时的末尾字符的位置的下一个位置
}
}
}
}
return str1.substring(index-max,index);
}
}
64.最小路径和
给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
![[ 1, 3 , 1 J, [ ‰ 2 1 ] 输 出 : 7 解 释 : 因 为 路 径 恤 恤 1 的 总 和 最 小 。](https://i.loli.net/2020/11/05/Lm94Ppy2Th8MSzD.png)
思路:
动态规划。
状态定义:
设 dp 为大小 m×n 矩阵,其中 dp[i][j] 的值代表直到走到 (i,j) 的最小路径和。
转移方程:
题目要求,只能向右或向下走,换句话说,当前单元格 (i,j) 只能从左方单元格 (i-1,j) 或上方单元格 (i,j-1) 走到,因此只需要考虑矩阵左边界和上边界。

返回值:
返回 dp 矩阵右下角值,即走到终点的最小路径和。
复杂度分析:
时间复杂度 O(M×N) : 遍历整个 grid 矩阵元素。
空间复杂度 O(1) : 直接修改原矩阵,不使用额外空间。
代码:
class Solution {
public int minPathSum(int[][] grid) {
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(i == 0 && j == 0) continue;
else if(i == 0) grid[i][j] = grid[i][j - 1] + grid[i][j];
else if(j == 0) grid[i][j] = grid[i - 1][j] + grid[i][j];
else grid[i][j] = Math.min(grid[i][j - 1], grid[i - 1][j]) + grid[i][j];
}
}
return grid[grid.length - 1][grid[0].length - 1];
}
}
221.最大正方形
在一个由 0 和 1 组成的二维矩阵内,找到只包含 1 的最大正方形,并返回其面积。

思路:
dp[i + 1][j + 1] 表示 「以第 i 行、第 j 列为右下角的正方形的最大边长」。对于任何一个正方形,我们都「依赖」当前格 左、上、左上三个方格的情况,三者取最小 。
复杂度分析:
时间复杂度 O(height * width)O(height∗width);
空间复杂度 O(height * width)O(height∗width)。
代码:
class Solution {
public int maximalSquare(char[][] matrix) {
if(matrix == null || matrix.length < 1 || matrix[0].length < 1) return 0;
int width = matrix[0].length, height = matrix.length;
int[][] dp = new int[height + 1][width + 1];
int maxSide = 0;
for(int i = 0; i < height; i++) {
for(int j = 0; j < width; j++) {
if(matrix[i][j] == '1') {
dp[i + 1][j + 1] = Math.min(dp[i][j], Math.min(dp[i + 1][j], dp[i][j + 1])) + 1;
maxSide = Math.max(maxSide, dp[i + 1][j + 1]);
}
}
}
return maxSide * maxSide;
}
}
85.最大矩形
给定一个仅包含 0 和 1 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。

代码:
class Solution {
public int maximalRectangle(char[][] matrix) {
if(matrix.length == 0) return 0;
int m = matrix.length;
int n = matrix[0].length;
int[] left = new int[n]; // initialize left as the leftmost boundary possible
int[] right = new int[n];
int[] height = new int[n];
Arrays.fill(right, n); // initialize right as the rightmost boundary possible
int maxarea = 0;
for(int i = 0; i < m; i++) {
int cur_left = 0, cur_right = n;
// update height
for(int j = 0; j < n; j++) {
if(matrix[i][j] == '1') height[j]++;
else height[j] = 0;
}
// update left
for(int j=0; j<n; j++) {
if(matrix[i][j]=='1') left[j]=Math.max(left[j],cur_left);
else {left[j]=0; cur_left=j+1;}
}
// update right
for(int j = n - 1; j >= 0; j--) {
if(matrix[i][j] == '1') right[j] = Math.min(right[j], cur_right);
else {right[j] = n; cur_right = j;}
}
// update area
for(int j = 0; j < n; j++) {
maxarea = Math.max(maxarea, (right[j] - left[j]) * height[j]);
}
return maxarea;
}
}
5.最长回文子串
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。

方法一:
动态规划。

所以如果我们想知道 P(i, j) 的情况,不需要调用判断回文串的函数了,只需要知道 P(i+1, j-1) 的情况就可以了,这样时间复杂度就少了O(n)。因此我们可以用动态规划的方法,空间换时间,把已经求出的 P(i, j) 存储起来。如果 S[i+1, j-1] 是回文串,那么只要S[i] == S[j] ,就可以确定 S[i,j] 也是回文串了。
求 长度为 1 和长度为 2 的 P(i,j) 时不能用上边的公式,因为我们代入公式后会遇到 P[i][j] 中 i > j 的情况,比如求 P[1][2] 的话,我们需要知道 P[1+1][2-1]=P[2][1],而 P[2][1] 代表着 S[2,1] 是不是回文串,显然是不对的,所以我们需要单独判断。
复杂度分析:
时间复杂度:两层循环 O(n²)。
空间复杂度:用二维数组 P 保存每个子串的情况 O(n²)。
代码:
class Solution {
public String longestPalindrome(String s) {
int len = s.length();
boolean[][] dp = new boolean[len][len];
int maxLen = 0;
String maxString = "";
for(int l = 1; l <= len; l++) { //遍历所有的长度
for(int i = 0; i < len; i++) {
int j = l + i - 1;
if(j >= len) break; //下标已经越界,结束本次循环
//长度为 1 和 2 的单独判断下
dp[i][j] = (l == 1 || l == 2 || dp[i + 1][j - 1]) &&
s.charAt(i) == s.charAt(j);
if(dp[i][j] && l > maxLen) {
maxString = s.substring(i, j + 1);
maxLen = l; //记得更新maxLen
}
}
}
return maxString;
}
}
方法二:
中心扩展法。遍历每一个索引,以这个索引为中心,利用“回文串”中心对称的特点,往两边扩散,看最多能扩散多远。
由于存在奇数的字符串和偶数的字符串,所以我们需要从一个字符开始扩展(奇数),或者从两个字符之间开始扩展(偶数),所以总共有 n+n-1 个中心。
复杂度分析:
时间复杂度:枚举“中心位置”时间复杂度为 O(N),从“中心位置”扩散得到“回文子串”的时间复杂度为 O(N),因此时间复杂度为 O(N^2)。
空间复杂度:O(1)。
代码:
public String longestPalindrome(String s) {
if(null == s || s.length() <= 1) {
return s;
}
int start = 0;
int end = 0;
//遍历整个字符串,将每个字符都从中心开始拓展
for(int i=0;i<s.length();i++) {
//因为回文可能有两种情况,奇数回文和偶数回文
//这个就代表它是一个奇数回文,最小的长度肯定是1,就是它自己,中心就是i
int lenOdd = expandCenter(s,i,i);
//这个就代表它是一个偶数回文,最小长度可能是0,中心介于i和i+1之间,可以想象成一条虚线
int lenEven = expandCenter(s, i, i+1);
//比较奇数回文和偶数回文的长度大小
Int len = Math.max(lenOdd, lenEven);
//如果长度比原本记录的长度大了,说明有更长的回文出现了,所以要记录一下回文的下标
if(len > end-start) {
//这里为什么要i-1?,这里说明一下,因为for循环是从0开始的,
//如果是奇数回文,假设有个回文是3个,那么len=3,此时中心i是下标1(从0开始),那么(len-1)/2和len/2的结果都是1,因为整型会向下取整
//但是如果是偶数回文,假设有个回文是4个,那么len=4,此时的中心是一条虚线,但是i的位置却在1,(因为S是从左向右遍历的,如果从右向左,
//i的位置就会在2.)这时候,(len-1)/2=1,len/2=2.很明显为了保证下标正确,我们需要的是(len-1)/2.原因其实是i在中心线的左边一位,
//所以要少减个1.
start = i - (len-1)/2;
end = i+len/2;
}
}
return s.substring(start,end+1);
}
public int expandCenter(String s,int left,int right) {
//left>=0 && right<s.length()是为了保证数组下标不越界
while(left>=0 && right<s.length() && s.charAt(left) == s.charAt(right)) {
left--;
right++;
}
//这里其实是right-left+1-2,意思就是right-left+1是本来的长度,但是由于上面最后一次判断肯定false,所以最后一次left--和right++
//其实不属于回文的一部分,所以要减去2
return right - left -1;
}
设计
297.二叉树的序列化与反序列化(同剑指37. 序列化二叉树)
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
![计算机生成了可选文字: 示例: 你可以将以下二叉树: 1 2 3 序列化为 "[1丿2丿3丿null丿nu11丿4丿5]"](https://i.loli.net/2020/11/05/gJdiNSMp71WLuPt.png)
思路:
观察题目示例,序列化的字符串实际上是二叉树的 “层序遍历”(BFS)结果,本文也采用层序遍历。序列化实际上就是从上到下打印二叉树,反序列化就是根据字符串重建二叉树。
代码流程:

![计算机生成了可选文字: 反序列化deserialize· 基于本文一开始分析的“node,“巳left,“巳7、匆,在序列化列表中的位置关系,可实现反序列化。 利用队列按层构建二叉树,借助一个指针指向节点“0的左、右子节点,每构建一个node的左、右子节点,指 针就向右移动1位。 算法流程: 1.特例处理:若忉为空,直接返回襯; 2.初始化:序列化列表vals(先去掉首尾中括号,再用逗号隔开),指针=1,根节点“(值为省s[0] ),队列queue(包含“)· 3.按层构建:当queue为空时跳出; 1.节点出队,记为“0; 2.构建“0的左子节点:node.left的值为vals[i],并将“0入队; 3.执行+=1; 4.构建“0的右子节点:node.left的值为vals[i],并将“0入队; 5.执行+=1; 4.返回值:返回根节点ro即可。 复杂度分析: ·时间复杂度O(N):N为二叉树的节点数,按层构建二叉树需要遍历整个省s,其长度最大为2N+1。 ·空间复杂度O(N): 最差情况下,队列queue同时存储个节,因此使用O(N)额外空间。](https://img-blog.csdnimg.cn/img_convert/73ac333dcbcac525b55fa31a315d38eb.png)
代码:
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if(root == null) return "[]";
StringBuilder res = new StringBuilder("[");
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
TreeNode node = queue.poll();
if(node != null) {
res.append(node.val + ",");
queue.offer(node.left);
queue.offer(node.right);
} else {
res.append("null,");
}
}
res.deleteCharAt(res.length() - 1);
res.append("]");
return res.toString();
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
if(data.equals("[]")) return null;
String[] vals = data.substring(1, data.length() - 1).split(",");
TreeNode root = new TreeNode(Integer.parseInt(vals[0]));
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int i = 1;
while(!queue.isEmpty()) {
TreeNode node = queue.poll();
if(!vals[i].equals("null")) {
node.left = new TreeNode(Integer.parseInt(vals[i]));
queue.offer(node.left);
}
i++;
if(!vals[i].equals("null")) {
node.right = new TreeNode(Integer.parseInt(vals[i]));
queue.offer(node.right);
}
i++;
}
return root;
}
}
★ 155.最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
- push(x) —— 将元素 x 推入栈中。
- pop() —— 删除栈顶的元素。
- top() —— 获取栈顶元素。
- getMin() —— 检索栈中的最小元素。
思路:

函数设计:

复杂度分析:

代码:
class MinStack {
Stack<Integer> A, B;
/** initialize your data structure here. */
public MinStack() {
A = new Stack<>();
B = new Stack<>();
}
public void push(int x) {
A.push(x);
if(B.isEmpty() || x <= B.peek()) {
B.push(x);
}
}
public void pop() {
int y = A.pop();
if(y == B.peek()) {
B.pop();
}
}
public int top() {
return A.peek();
}
public int getMin() {
return B.peek();
}
}
716.最大栈
设计一个最大栈,支持 push、pop、top、peekMax 和 popMax 操作。
- push(x) – 将元素 x 压入栈中。
- pop() – 移除栈顶元素并返回这个值。
- top() – 返回栈顶元素。
- peekMax() – 返回栈中最大元素。
- popMax() – 返回栈中最大的元素,并将其删除。如果有多个最大元素,只要删除最靠近栈顶的那个。
思路:
前四个方法和最小栈完全相同,A为原栈,B为最大栈。对于 popMax() 方法,先将 B 的栈顶元素保存到一个变量 max 中,然后我们要在 A 中删除这个元素,由于栈无法直接定位元素,所以我们用一个临时栈 buffer,将 A 的出栈元素保存到临时栈 buffer 中,当 A 的栈顶元素和 B 的栈顶元素相同时退出 while 循环,此时我们在 A 中找到了 B 的栈顶元素,分别将 A 和 B 的栈顶元素移除,然后要做的是将临时栈 buffer 中的元素加回 A 中,注意此时容易犯的一个错误是,没有同时更新 B,所以我们直接调用 push() 函数即可。
复杂度分析:
时间复杂度:O(n)。由于前四个操作的时间复杂度都是 O(1),而 popMax() 操作在最坏情况下需要将栈中的所有元素全部出栈再入栈,时间复杂度为 O(n)。因此总的时间复杂度为 O(n)。
空间复杂度:O(n)。
代码:
class MaxStack {
Stack<Integer> A, B;
/** initialize your data structure here. */
public MaxStack() {
A = new Stack<>();
B = new Stack<>();
}
public void push(int x) {
A.push(x);
if(B.isEmpty() || x >= B.peek()) {
B.push(x);
}
}
public int pop() {
int y = A.pop();
if(y == B.peek()) {
B.pop();
}
return y;
}
public int top() {
return A.peek();
}
public int peekMax() {
return B.peek();
}
public int popMax() {
int max = peekMax(); //保存最大值
Stack<Integer> buffer = new Stack(); //用来保存A的出栈元素
//将A出栈的元素加入buffer保存,直到A,B栈顶元素相同时退出循环
while (top() != max) buffer.push(pop());
pop(); //将A,B的栈顶元素移除
//将buffer中的元素放回到A中,同上更新B
while (!buffer.isEmpty()) push(buffer.pop());
return max;
}
}
★ 剑指09.用两个栈实现队列
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
思路:
- 栈无法实现队列功能:栈底元素(对应队首元素)无法直接删除,需要将上方所有元素出栈。
- 双栈可实现列表倒序:设有含三个元素的栈 A = [1,2,3] 和空栈 B = []。若循环执行 A 元素出栈并添加入栈 B ,直到栈 A 为空,则 A = [] , B = [3,2,1] ,即 栈 B 元素实现栈 A 元素倒序 。
- 利用栈 B 删除队首元素:倒序后,B 执行出栈则相当于删除了 A 的栈底元素,即对应队首元素。
函数设计:

复杂度分析:
由于问题特殊,以下分析仅满足添加 N 个元素并删除 N 个元素,即栈初始和结束状态下都为空的情况。
时间复杂度: 对于插入和删除操作,时间复杂度均为 O(1)。插入不多说,对于删除操作,虽然看起来是 O(n) 的时间复杂度,但是仔细考虑下每个元素只会「至多被插入和弹出 B 一次」,因此均摊下来每个元素被删除的时间复杂度仍为 O(1)。
空间复杂度 O(N) : 最差情况下,栈 A 和 B 共保存 N 个元素。
代码:
class CQueue {
LinkedList<Integer> A, B;
public CQueue() {
A = new LinkedList<>();
B = new LinkedList<>();
}
public void appendTail(int value) {
A.addLast(value);
}
public int deleteHead() {
if(!B.isEmpty()) return B.removeLast();
if(A.isEmpty()) return -1;
while(!A.isEmpty()) B.addLast(A.removeLast());
return B.removeLast();
}
}
★ 146.LRU缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。

思路:
LRU 缓存算法的核心数据结构就是哈希链表。哈希表赋予了链表快速查找的特性:可以快速查找某个 key 是否存在缓存(链表)中,同时可以快速删除、添加节点。
该链表为双向链表,这是因为我们不知道单向链表的前驱节点,如果要删除某个节点,只能遍历链表,或者一直维护一个指针指向前驱节点。而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。
伪代码:
// key 映射到 Node(key, val)
HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
DoubleList cache;
int get(int key) {
if (key 不存在) {
return -1;
} else {
将数据 (key, val) 提到开头;
return val;
}
}
void put(int key, int val) {
Node x = new Node(key, val);
if (key 已存在) {
把旧的数据删除;
将新节点 x 插入到开头;
} else {
if (cache 已满) {
删除链表的最后一个数据腾位置;
删除 map 中映射到该数据的键;
}
将新节点 x 插入到开头;
map 中新建 key 对新节点 x 的映射;
}
}
代码:
class LRUCache {
class Node {
public int key, value;
public Node next, prev;
public Node(int k, int v) {
this.key = k;
this.value = v;
}
}
class DoubleList {
private Node head, tail; //头尾虚结点
private int size; //链表元素数
public DoubleList() {
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0; //别忘了size
}
public void addFirst(Node x) { //先连后断
x.next = head.next; //连接后面的
x.prev = head; //连接前面的
head.next.prev = x; //断开后面的
head.next = x; //断开前面的
size++; //记得size++
}
public void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
size--; //记得size--
}
public Node removeLast() {
if(tail.prev == head) return null; //记得边界条件判断
Node last = tail.prev;
remove(last);
return last;
}
public int size() {
return size;
}
}
private HashMap<Integer, Node> map;
private DoubleList cache;
private int cap;
public LRUCache(int capacity) {
map = new HashMap<>();
cache = new DoubleList();
this.cap = capacity;
}
public int get(int key) {
if(!map.containsKey(key)) return -1;
int val = map.get(key).value;
//利用 put 方法把该数据提前
put(key, val);
return val;
}
//记得对双向链表进行操作后,map也要进行更新
public void put(int key, int value) {
//先把新节点 x 做出来
Node x = new Node(key, value);
if(map.containsKey(key)) {
//删除旧的节点,新的插到头部
cache.remove(map.get(key));
cache.addFirst(x);
//更新 map 中对应的数据
map.put(key, x);
} else {
if(cap == cache.size()) { //缓存满了
//删除链表最后一个数据
Node last = cache.removeLast();
map.remove(last.key);
}
//直接添加到头部
cache.addFirst(x);
map.put(key, x);
}
}
}
数学
★ 7.整数反转
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。

思路:
弹出和推入数字 & 溢出前进行检查。我们不断“弹出” x 的最后一位数字,并将它“推入”到 res 的后面。最后,res 将与 x 相反。
pop 操作:
pop = x % 10;
x /= 10;
push 操作:
res = res * 10 + pop;
复杂度分析:
代码:
class Solution {
public int reverse(int x) {
int res = 0;
while(x != 0) {
下面的 res = res * 10 + pop 可能越界,此处预先判断加以避免
if(res != (res * 10) / 10) {
return 0;
}
//pop
int pop = x % 10;
x /= 10;
//push
res = res * 10 + pop;
}
return res;
}
}
9.回文数
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
思路:
取出后半段数字进行翻转。这里需要注意的一个点就是由于回文数的位数可奇可偶,所以当它的长度是偶数时,它对折过来应该是相等的;当它的长度是奇数时,那么它对折过来后,有一个的长度需要去掉一位数(除以 10 并取整)。
具体做法如下:
每次进行取余操作 ( %10),取出最低的数字:y = x % 10
将最低的数字加到取出数的末尾:revertNum = revertNum * 10 + y
每取一个最低位数字,x 都要自除以 10
判断 x 是不是小于 revertNum ,当它小于的时候,说明数字已经对半或者过半了
最后,判断奇偶数情况:如果是偶数的话,revertNum 和 x 相等;如果是奇数的话,最中间的数字就在revertNum 的最低位上,将它除以 10 以后应该和 x 相等。
复杂度分析:
时间复杂度:O(logn),对于每次迭代,我们会将输入除以 10,因此时间复杂度为 O(logn)。
空间复杂度:O(1)。我们只需要常数空间存放若干变量。
代码:
class Solution {
public boolean isPalindrome(int x) {
//x % 10 == 0直接返回false,如100,10等
if(x < 0 || x != 0 && x % 10 == 0) return false;
int halfNumber = 0;
while(x > halfNumber) {
halfNumber = halfNumber * 10 + x % 10;
x /= 10;
}
return x == halfNumber || x == halfNumber / 10;
}
}
118.杨辉三角
给定一个非负整数 numRows,生成杨辉三角的前 numRows 行。
在杨辉三角中,每个数是它左上方和右上方的数的和。

代码:
class Solution {
public List<List<Integer>> generate(int numRows) {
List<List<Integer>> res = new ArrayList<>();
for(int i = 0; i < numRows; i++) {
List<Integer> list = new ArrayList<>();
for(int j = 0; j <= i; j++) {
if(j == 0 || j == i) {
list.add(1);
} else {
list.add(res.get(i - 1).get(j - 1) + res.get(i - 1).get(j));
}
}
res.add(list);
}
return res;
}
}
470.用 Rand7() 实现 Rand10()
未做。
位运算
★ 136.只出现一次的数字
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?

思路:
异或是机器码运算,相同为0不同为1,不管数字先后,只要两个数字相同对应的二进制都会被异或为00000000,最后剩下的就是所要找的值。
异或有交换律定理,相当于将相同的数字先异或,这样两两异或就只剩0了,然后0再和最后的一个数字异或得到最终值。
代码:
class Solution {
public int singleNumber(int[] nums) {
int cur = 0;
for(int num : nums) {
cur ^= num;
}
return cur;
}
}
★ 137.只出现一次的数字 II
在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
![计算机生成了可选文字: 示例1: 输入: 输出: 示例2. 输入: 输出: numS 4 numS 1 [3丿‰3丿3] [9丿1丿7丿9丿7丿9丿7]](https://i.loli.net/2020/11/05/PuXpFLnHohEke8T.png)
思路:
![计算机生成了可选文字: 使用与运算,可获取二进制数字num的最右一位: 1:=7&動 配合无符号右移操作,可获取num所有位的值(即砌~“32) m=77丑m>>>1 建立一个长度为32的数组counts,通过以上方法可记录所有数字的各二进制位的1的出现次数。 int[]counts=newint32 for(inti=0;i<nums」ength;i十十){ for(intj=0 <32 counts[j]十=nums[i]&1;//更新第j位 =1//第j位一一>第j十1位 nu.lms[i]>>>

代码:
class Solution {
public int singleNumber(int[] nums) {
int[] counts = new int[32]; //记录所有数字的各二进制位的 1 的出现次数
for(int num : nums) {
for(int j = 0; j < 32; j++) {
counts[j] += num & 1; //获取二进制数字 num 的最右一位
num >>>= 1; //配合无符号右移操作 ,可获取 num 所有位的值
}
}
//将 counts 数组中各二进位的值恢复到数字 res 上
int res = 0, m = 3;
for(int i = 0; i < 32; i++) {
res <<= 1;
res |= counts[31 - i] % m;
}
return res;
}
}
实际上,只需要修改求余数值 m ,即可实现解决 除了一个数字以外,其余数字都出现 m 次 的通用问题。
★ 260.只出现一次的数字 III(同剑指56 - I. 数组中数字出现的次数)
给定一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。要求时间复杂度是O(n),空间复杂度是O(1)。
![计算机生成了可选文字: 示例1: 输入: [4丿1丿‰6] numS 输出:[1丿6]或[6丿1] 示例2. 输入: [1丿2丿19丿4丿1丿4丿3丿3] numS 输出:[2丿1明或[12]](https://i.loli.net/2020/11/05/I6Apcmy8jz9LgfN.png)
思路:
由于数组中存在着两个数字不重复的情况,我们将所有的数字异或操作起来,最终得到的结果是这两个数字的异或结果:(相同的两个数字相互异或,值为0)) 最后结果一定不为0,因为有两个数字不重复。我们可以把数组分为两组进行异或,那么就可以知道是哪两个数字不同了。
我们可以想一下如何分组:重复的数字进行分组,很简单,只需要有一个统一的规则,就可以把相同的数字分到同一组了。例如:奇偶分组。因为重复的数字,数值都是一样的,所以一定会分到同一组。此时的难点在于,对两个不同数字的分组。
此时我们要找到一个操作,让两个数字进行这个操作后,分为两组。我们最容易想到的就是 & 1 操作, 当我们对奇偶分组时,容易地想到 & 1,即用于判断最后一位二进制是否为 1 来辨别奇偶。两个不同的数字至少也有一位不同,那么我们只需要找出那位不同的数字mask,即可完成分组( & mask )操作。
由于两个数异或的结果就是两个数数位不同结果的直观表现,所以我们可以通过异或后的结果去找 mask。所有的可行 mask 个数,都与异或后1的位数有关。为了操作方便,我们只去找最低位的mask。
代码:
class Solution {
public int[] singleNumbers(int[] nums) {
//把所有的数异或起来
int k = 0;
for(int num : nums) {
k ^= num;
}
//从最低位开始,与k的每一位进行比较,直到发现为1的最低一位,为1说明两数在此位上不同
int mask = 1;
while((k & mask) == 0) {
mask <<= 1;
}
//通过与mask进行与运算,就能将a,b分到不同的两组
//其他相同的数相互异或结果为0,最终只剩a,b
int a = 0, b = 0;
for(int num : nums) {
if((num & mask) == 0) a^= num; //重复的数字会分到同一组,异或消除
else b^= num;
}
return new int[]{a, b};
}
}
排序
归并排序
public class MergeSort {
public static void mergeSort(int[] arr) {
sort(arr, 0, arr.length - 1);
}
public static void sort(int[] arr, int lo, int hi) {
if(lo >= hi) {
return;
}
int mid = (lo + hi) / 2;
sort(arr, lo, mid);
sort(arr, mid + 1, hi);
merge(arr, lo, mid, hi);
}
public static void merge(int[] arr, int lo, int mid, int hi) {
int[] temp = new int[arr.length];
int i = lo, j = mid + 1, k = 0;
while(i <= mid && j <= hi) {
if(arr[i] < arr[j]) {
temp[k++] = arr[i++];
} else {
temp[k++] = arr[j++];
}
}
while(i <= mid) {
temp[k++] = arr[i++];
}
while(j <= hi) {
temp[k++] = arr[j++];
}
for (int l = 0; l < k; l++) {
arr[l + lo] = temp[l];
}
}
public static void main(String[] args) {
int[] arr = new int[] {1, 6, 4, 5, 2, 9, 7, 23, 56, 43, 99};
mergeSort(arr);
for(int num : arr) {
System.out.println(num);
}
}
}
快速排序
递归:
public class QuickSort {
public static void sort(int[] a, int left, int right) {
if(left > right) return;
int i = left, j = right, base = a[left];
while(i != j) {
while(i < j && a[j] >= base) j--;
while(i < j && a[i] <= base) i++;
if(i < j) {
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
}
a[left] = a[i];
a[i] = base;
sort(a, left, i - 1);
sort(a, i + 1, right);
}
public static void main(String[] args) {
int[] a = new int[] {-1, 2, 3, 78, 34, 22, 90, -7};
sort(a, 0, a.length - 1);
}
}
非递归:
import java.util.Stack;
/**
\* 这是一个用快速排序的非递归形式,用俩个移动下标l和r来分别比较基准数,
\* 下标分别存放在栈里面,在用一个方法来调用排序得出一个中下标之后,进行分左右区间,
\* 判断是否符合分区的最小个数,成功把下标存放在栈里面。
*
\* 1.用栈集合存放左右下标
\* 2.用一个方法来得出中下标位置
\* 3.判断中下标的左右区间
\* 4.回到步骤1循环这几步操作,知道栈为空,则排序完成。
*/
public class QuickSort2 {
public static int[] sort2(int[] nums) {
int start = 0;
int end = nums.length-1;
Stack<Integer> stack = new Stack<>();
if(start < end)
{
stack.push(end);
stack.push(start);
while(!stack.isEmpty())
{
int l = stack.pop();
int r = stack.pop();
int index = partition(nums,l,r);
if(l < index-1)
{
stack.push(index-1);
stack.push(l);
}
if(r > index+1)
{
stack.push(r);
stack.push(index+1);
}
}
}
return nums;
}
private static int partition(int[] nums, int left, int right) {
if(left > right) return 0;
int i = left, j = right, base = nums[left];
while(i != j) {
while(i < j && nums[j] >= base) j--;
while(i < j && nums[i] <= base) i++;
if(i < j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}
nums[left] = nums[i];
nums[i] = base;
return i;
}
public static void main(String[] args) {
int[] a = new int[] {-1, 2, 3, 78, 34, 22, 90, -7};
sort2(a);
for(int aa : a) {
System.out.println(aa);
}
}
}
堆排序
升序大顶堆 降序小顶堆
public class HeapSort {
public static void main(String[] args) {
int[] array = { 19, 38, 7, 36, 5, 5, 3, 2, 1, 0, 56 };
System.out.println("排序前:");
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + ",");
}
System.out.println();
System.out.println("分割线---------------");
heapSort(array);
System.out.println("排序后:");
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + ",");
}
}
public static void heapSort(int[] array) {
if (array == null || array.length == 1)
return;
buildMaxHeap(array); // 第一次排序,构建最大堆,只保证了堆顶元素是数组里最大的
for (int i = array.length - 1; i >= 1; i--) {
// 这个是什么意思呢?,经过上面的一些列操作,目前array[0]是当前数组里最大的元素,需要和末尾的元素交换
// 然后,拿出最大的元素
swap(array, 0, i);
// 交换完后,下次遍历的时候,就应该跳过最后一个元素,也就是最大的那个值,然后开始重新构建最大堆
// 堆的大小就减去1,然后从0的位置开始最大堆
maxHeap(array, i, 0);
//minHeap(array, i, 0);
}
}
// 构建堆
public static void buildMaxHeap(int[] array) {
if (array == null || array.length == 1)
return;
// 堆的公式就是 int root = 2*i, int left = 2*i+1, int right = 2*i+2;
int cursor = array.length / 2;
for (int i = cursor; i >= 0; i--) { // 这样for循环下,就可以第一次排序完成
maxHeap(array, array.length, i);
//minHeap(array, array.length, i);
}
}
// 最大堆
public static void maxHeap(int[] array, int heapSieze, int index) {
int left = index * 2 + 1; // 左子节点
int right = index * 2 + 2; // 右子节点
int maxValue = index; // 暂时定在Index的位置就是最大值
// 如果左子节点的值,比当前最大的值大,就把最大值的位置换成左子节点的位置
if (left < heapSieze && array[left] > array[maxValue]) {
maxValue = left;
}
// 如果右子节点的值,比当前最大的值大,就把最大值的位置换成右子节点的位置
if (right < heapSieze && array[right] > array[maxValue]) {
maxValue = right;
}
// 如果不相等,说明啊,这个子节点的值有比自己大的,位置发生了交换了位置
if (maxValue != index) {
swap(array, index, maxValue); // 就要交换位置元素
// 交换完位置后还需要判断子节点是否打破了最大堆的性质。最大堆性质:两个子节点都比父节点小。
maxHeap(array, heapSieze, maxValue);
}
}
// 最小堆
public static void minHeap(int[] array, int heapSieze, int index) {
int left = index * 2 + 1; // 左子节点
int right = index * 2 + 2; // 右子节点
int maxValue = index; // 暂时定在Index的位置就是最小值
// 如果左子节点的值,比当前最小的值小,就把最小值的位置换成左子节点的位置
if (left < heapSieze && array[left] < array[maxValue]) {
maxValue = left;
}
// 如果右子节点的值,比当前最小的值小,就把最小值的位置换成左子节点的位置
if (right < heapSieze && array[right] < array[maxValue]) {
maxValue = right;
}
// 如果不相等,说明啊,这个子节点的值有比自己小的,位置发生了交换了位置
if (maxValue != index) {
swap(array, index, maxValue); // 就要交换位置元素
// 交换完位置后还需要判断子节点是否打破了最小堆的性质。最小性质:两个子节点都比父节点大。
minHeap(array, heapSieze, maxValue);
}
}
// 数组元素交换
public static void swap(int[] array, int index1, int index2) {
int temp = array[index1];
array[index1] = array[index2];
array[index2] = temp;
}
}
设计模式
单例模式
DCL+volatile
public class Singleton {
private volatile Singleton singleton;
// 构造函数是private,防止外部实例化
private Singleton() {}
public static Singleton getInstance() {
if (singleton == null) { // 第一次检查
synchronized (Singleton.class) {
if (singleton == null) { // 第二次检查,"double check"的由来
singleton = new Singleton();
}
}
}
return singleton;
}
}
DCL方法中做了两次singleton == null的判断,那么这里为什么需要做两次检查呢? 首先我们看一下这个方法的过程:
- 检查singleton实例是否为空,如果不为空直接返回。
- 对Singleton的class加synchronized锁,锁住整个类。如果没有获取锁则阻塞等待。
- 判断singleton实例是否为空,如果为空则进行初始化。
设想一下,在最开始,如果N个线程同时并发来获取实例,除了获取锁的线程之外其他的线程都阻塞在第2步,等待第一个线程初始化实例完成后。后面的N - 1线程会穿行执行synchronized代码块,如果代码块中没有判断singleton是否为null,则还是会再"new" N - 1个实例出来,无法达到单例的目的。 因此这里的DCL机制是必须的。
上面的方案看起来很完美,但是在更严苛的意义上还是有问题的,假设线程1获取锁之后在执行singleton = new Singleton();这一行,这里是new一个Singleton实例,Java中新建一个对象分为三个步骤:
- 在内存中开辟一块地址
- 对象初始化
- 将指针指向这块内存地址
Java中如果我们在一个线程中观察代码,代码都是顺序穿行执行的,但是如果我们在一个线程中观察其他线程,其他线程中的执行都是乱序的。这句话说的是Java中的指令重排序现象。如果在新建Singleton对象的时候第2步和第3步发生了重排序,线程1将singleton指针指向了内存中的地址,但是此时我们的对象还没有初始化。这个时候线程2进来,看到singleton不是null,于是直接返回。这个时候错误就发生了:线程2拿到了一个没有经过初始化的对象。
解决这个问题的思路也很简单:防止指令重排序,Java中可以通过volatile关键字来防止指令重排序。
静态内部类
public class MySingleton1 {
private MySingleton1() {}
public static MySingleton1 getInstance() {
return Inner.singleton;
}
private static class Inner {
private static MySingleton1 singleton = new MySingleton1();
}
}
生产者消费者
public class ProducerConsumer {
public static void main(String[] args) {
Data data = new Data();
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try{
data.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"添加线程").start();
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
data.decrement();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"减少线程").start();
}
}
class Data {
private int number = 0;
public synchronized void increment() throws InterruptedException {
if(number != 0) {
this.wait();
}
number++;
System.out.println(Thread.currentThread().getName() + "->" + number);
notify();
}
public synchronized void decrement() throws InterruptedException {
if(number == 0) {
this.wait();
}
number--;
System.out.println(Thread.currentThread().getName() + "->" + number);
notify();
}
}














 102
102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










![j) 添 加 至 deque 尾 部 ; 4 . 若 已 形 成 窗 囗 〈 即 i 0 ) : 将 窗 囗 最 大 值 ( 即 队 首 元 素 que[O ] ) 添 加 至 列 表 res 。 3 . 返 回 值 : 返 回 结 果 列 表 “ 5 。](https://img-blog.csdnimg.cn/img_convert/2fd47c709bf019a124d2758a19c9d61d.png){kind=link}
![32 for(inti=0;i<nums」ength;i十十){ for(intj=0 <32 counts[j]十=nums[i]&1;//更新第j位 =1//第j位一一>第j十1位 nu.lms[i]>>>](https://img-blog.csdnimg.cn/img_convert/2188c630fec33b423716323c2eb0458f.png){kind=link}