






1.4.3 存储引擎
openGauss存储引擎支持多个存储引擎来满足不同场景的业务诉求,目前支持行存储引擎、列存储引擎和内存引擎。
早期计算机程序通过文件系统管理数据,到了20世纪60年代这种方式就开始不能满足数据管理要求了,用户逐渐对数据并发写入的完整性、高效检索提出更高的要求。由于机械磁盘的随机读写性能问题,从20世纪80年代开始,大多数数据库一直在围绕着减少随机读写磁盘进行设计。主要思路是把对数据页面的随机写盘转换为对WAL(write ahead log,预写式日志)的顺序写盘,WAL持久化完成,事务就算提交成功,数据页面异步刷盘。但是随着内存容量变大、保电内存、非易失性内存的发展,以及SSD技术逐渐地成熟,I/O性能极大提高,经历了几十年发展的存储引擎需要调整架构来发挥SSD的性能和充分利用大内存计算的优势。随着互联网、移动互联网的发展,数据量剧增,业务场景多样化,一套固定不变的存储引擎不可能满足所有应用场景的诉求。因此现在的DBMS(database management system,数据库管理系统)需要设计支持多种存储引擎,根据业务场景来选择合适的存储模型。
1. 数据库存储引擎要解决的问题
(1) 存储的数据必须要保证ACID:原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability)。
(2) 高并发读写,高性能。
(3) 数据高效存储和检索能力。
2. openGauss存储引擎概述
openGauss整个系统设计支持多个存储引擎来满足不同场景的业务诉求。当前openGauss存储引擎有以下3种:
(1) 行存储引擎。主要面向OLTP(online transaction processing,在线交易处理)场景设计,例如订货发货,银行交易系统。
(2) 列存储引擎。主要面向OLAP场景设计,例如数据统计报表分析。
(3) 内存引擎。主要面向极致性能场景设计,例如银行风控场景。
创建表的时候可以指定行存储引擎表、列存储引擎表、内存引擎表,支持一个事务里包含对3种引擎表的DML(Data Manipulation Language,数据操作语言)操作,可以保证事务ACID。
1) storage源码组织
storage源码目录为:/src/gausskernel/storage。storage源码文件如表1-9所示。
表1-9 storage源码文件
| 模块 | 源码文件 | 功能 |
| storage | access | 基础行存储引擎方法 |
| cbtree | ||
| hash | ||
| heap | ||
| index | ||
| ... | ||
| buffer | 缓冲区 | |
| freespace | 空闲空间管理 | |
| ipc | 进程内交互 | |
| large_object | 大对象处理 | |
| remote | 远程读 | |
| replication | 复制备份 | |
| smgr | 存储管理 | |
| cmgr | 公共缓存方法 | |
| cstore | 列存储引擎 | |
| dfs | 分布式文件系统 | |
| file | 文件类 | |
| lmgr | 锁管理 | |
| mot | 内存引擎 | |
| page | 数据页 |
2) storage主流程
storage主流程代码如下:
/* smgr/smgr.cpp, 存储管理 */
...
/* 存储管理函数列表,包含磁盘初始化、开关、同步等操作函数 */
static const f_smgr g_smgrsw[] = {
/* 磁盘*/
{mdinit,
NULL,
mdclose,
mdcreate,
mdexists,
mdunlink,
mdextend,
mdprefetch,
mdread,
mdwrite,
mdwriteback,
mdnblocks,
mdtruncate,
mdimmedsync,
mdpreckpt,
mdsync,
mdpostckpt,
mdasyncread,
mdasyncwrite}};
/*
* 存储管理初始化
* 当服务器后端启动时调用
*/
void smgrinit(void)
{
int i;
/* 初始化所有存储相关管理器 */
for (i = 0; i < SMGRSW_LENGTH; i++) {
if (g_smgrsw[i].smgr_init) {
(*(g_smgrsw[i].smgr_init))();
}
}
/* 登记存储管理终止程序 */
if (!IS_THREAD_POOL_SESSION) {
on_proc_exit(smgrshutdown, 0);
}
}
/*
* 当后端服务关闭时,执行存储管理关闭代码
*/
static void smgrshutdown(int code, Datum arg)
{
int i;
/* 关闭所有存储关联服务 */
for (i = 0; i < SMGRSW_LENGTH; i++) {
if (g_smgrsw[i].smgr_shutdown) {
(*(g_smgrsw[i].smgr_shutdown))();
}
}
}3. 行存储引擎
openGauss的行存储引擎设计上支持MVCC(multi-version concurrency control,多版本并发控制),采用集中式垃圾版本回收机制,可以提供OLTP业务系统的高并发读写要求。架构如图1-6所示。
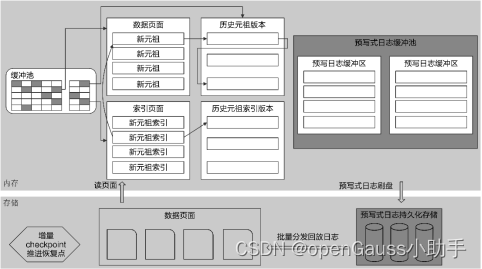
图1-6 行存储架构
行存储引擎的关键技术有:
(1) 基于CSN(commit sequence number,待提交事务的序列号,它是一个64位递增无符号数)的MVCC并发控制机制,进行集中式垃圾数据清理。
(2) 并行刷新日志,并行恢复。传统数据库一般都采用串行刷日志的设计,因为日志有顺序依赖关系,例如一个由事务产生的redo/undo log是有前后依赖关系的。openGauss的日志系统采用多个logwriter线程并行写的机制,充分发挥SSD的多通道I/O能力。
(3) 基于大内存设计的缓冲管理器。
行存储缓冲区主流程代码如下:
/* buffer/bufmgr.cpp, 基础行存储管理 */
...
/* 查找或创建一个缓冲区 */
Buffer ReadBufferExtended(
Relation reln, ForkNumber fork_num, BlockNumber block_num, ReadBufferMode mode, BufferAccessStrategy strategy)
{
bool hit = false;
Buffer buf;
if (block_num == P_NEW) {
STORAGE_SPACE_OPERATION(reln, BLCKSZ);
}
/* 以smgr(存储管理器)级别打开一个缓冲区 */
RelationOpenSmgr(reln);
/* 拒绝读取非局部临时关系的请求,因为可能会获得监控不到的错误数据 */
if (RELATION_IS_OTHER_TEMP(reln) && fork_num <= INIT_FORKNUM)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED), errmsg("cannot access temporary tables of other sessions")));
/* 读取缓冲区,更新统计信息数量反馈缓存命中与否情况 */
pgstat_count_buffer_read(reln);
pgstatCountBlocksFetched4SessionLevel();
buf = ReadBuffer_common(reln->rd_smgr, reln->rd_rel->relpersistence, fork_num, block_num, mode, strategy, &hit);
if (hit) {
pgstat_count_buffer_hit(reln);
}
return buf;
}
/* 释放一个缓冲区 */
void ReleaseBuffer(Buffer buffer)
{
BufferDesc* buf_desc = NULL;
PrivateRefCountEntry* ref = NULL;
/* 错误释放处理 */
if (!BufferIsValid(buffer)) {
ereport(ERROR, (errcode(ERRCODE_INVALID_BUFFER), (errmsg("bad buffer ID: %d", buffer))));
}
ResourceOwnerForgetBuffer(t_thrd.utils_cxt.CurrentResourceOwner, buffer);
if (BufferIsLocal(buffer)) {
Assert(u_sess->storage_cxt.LocalRefCount[-buffer - 1] > 0);
u_sess->storage_cxt.LocalRefCount[-buffer - 1]--;
return;
}
/* 释放当前缓冲区 */
buf_desc = GetBufferDescriptor(buffer - 1);
PrivateRefCountEntry *free_entry = NULL;
ref = GetPrivateRefCountEntryFast(buffer, free_entry);
if (ref == NULL) {
ref = GetPrivateRefCountEntrySlow(buffer, false, false, free_entry);}
Assert(ref != NULL);
Assert(ref->refcount > 0);
if (ref->refcount > 1) {
ref->refcount--;
} else {
UnpinBuffer(buf_desc, false);
}
}
/* 标记写脏缓冲区 */
void MarkBufferDirty(Buffer buffer)
{
BufferDesc* buf_desc = NULL;
uint32 buf_state;
uint32 old_buf_state;
if (!BufferIsValid(buffer)) {
ereport(ERROR, (errcode(ERRCODE_INVALID_BUFFER), (errmsg("bad buffer ID: %d", buffer))));}
if (BufferIsLocal(buffer)) {
MarkLocalBufferDirty(buffer);
return;
}
buf_desc = GetBufferDescriptor(buffer - 1);
Assert(BufferIsPinned(buffer));
Assert(LWLockHeldByMe(buf_desc->content_lock));
old_buf_state = LockBufHdr(buf_desc);
buf_state = old_buf_state | (BM_DIRTY | BM_JUST_DIRTIED);
/* 将未入队的脏页入队 */
if (g_instance.attr.attr_storage.enableIncrementalCheckpoint) {
for (;;) {
buf_state = old_buf_state | (BM_DIRTY | BM_JUST_DIRTIED);
if (!XLogRecPtrIsInvalid(pg_atomic_read_u64(&buf_desc->rec_lsn))) {
break;
}
if (!is_dirty_page_queue_full(buf_desc) && push_pending_flush_queue(buffer)) {
break;
}
UnlockBufHdr(buf_desc, old_buf_state);
pg_usleep(TEN_MICROSECOND);
old_buf_state = LockBufHdr(buf_desc);
}
}
UnlockBufHdr(buf_desc, buf_state);
/* 如果缓冲区不是“脏”状态,则更新相关计数 */
if (!(old_buf_state & BM_DIRTY)) {
t_thrd.vacuum_cxt.VacuumPageDirty++;
u_sess->instr_cxt.pg_buffer_usage->shared_blks_dirtied++;
pgstatCountSharedBlocksDirtied4SessionLevel();
if (t_thrd.vacuum_cxt.VacuumCostActive) {
t_thrd.vacuum_cxt.VacuumCostBalance += u_sess->attr.attr_storage.VacuumCostPageDirty;
}
}
}4. 列存储引擎
传统行存储数据压缩率低,必须按行读取,即使读取一列也必须读取整行。openGauss创建表的时候,可以指定行存储还是列存储。列存储表也支持DML操作和MVCC。列存储架构如图1-7所示。
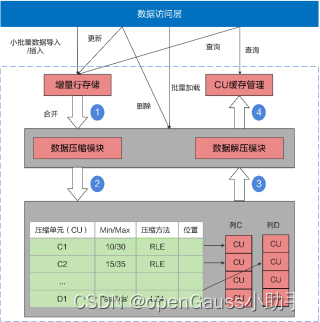
图1-7 列存储架构
列存储引擎有以下优势:
(1) 列的数据特征比较相似,适合压缩,压缩比很高。
(2) 当表列的个数比较多,但是访问的列个数比较少时,列存储可以按需读取列数据,大大减少不必要的读I/O开支,提高查询性能。
(3) 基于列批量数据Vector(向量)的运算,CPU的缓存命中率比较高,性能比较好。列存储引擎更适合OLAP大数据统计分析的场景。
1) 列存储源码组织
列存储源码目录为:/src/gausskernel/storage/cstore。列存储源码文件如表1-10所示。
表1-10 列存储源码文件
| 模块 | 源码文件 | 功能 |
| cstore | compression | 数据压缩与解压 |
| cstore_allocspace | 空间分配 | |
| cstore_am | 列存储公共API(application programming interface,应用编程接口) | |
| cstore_***_func | 支持函数 | |
| cstore_psort | 列内排序 | |
| cu | 数据压缩单元 | |
| cucache_mgr | 缓存管理器 | |
| custorage | 持久化存储 | |
| cstore_delete | 删除方法 | |
| cstore_update | 更新方法 | |
| cstore_vector | 缓冲区实现 | |
| cstore_rewrite | SQL重写 | |
| cstore_insert | 插入方法 | |
| cstore_mem_alloc | 内存分配 |
2) 列存储主要API
列存储主要API代码如下:
/* cstore_am.cpp */
...
/* 扫描 APIs */
void InitScan(CStoreScanState *state, Snapshot snapshot = NULL);
void InitReScan();
void InitPartReScan(Relation rel);
bool IsEndScan() const;
/* 延迟读取APIs */
bool IsLateRead(int id) const;
void ResetLateRead();
/* 更新列存储扫描计时标记*/
void SetTiming(CStoreScanState *state);
/* 列存储扫描*/
void ScanByTids(_in_ CStoreIndexScanState *state, _in_ VectorBatch *idxOut, _out_ VectorBatch *vbout);
void CStoreScanWithCU(_in_ CStoreScanState *state, BatchCUData *tmpCUData, _in_ bool isVerify = false);
/* 加载数据压缩单元描述信息 */
bool LoadCUDesc(_in_ int col, __inout LoadCUDescCtl *loadInfoPtr, _in_ bool prefetch_control, _in_ Snapshot snapShot = NULL);
/* 从描述表中获取数据压缩单元描述*/
bool GetCUDesc(_in_ int col, _in_ uint32 cuid, _out_ CUDesc *cuDescPtr, _in_ Snapshot snapShot = NULL);
/* 获取元组删除信息*/
void GetCUDeleteMaskIfNeed(_in_ uint32 cuid, _in_ Snapshot snapShot);
bool GetCURowCount(_in_ int col, __inout LoadCUDescCtl *loadCUDescInfoPtr, _in_ Snapshot snapShot);
/* 获取实时行号。 */
int64 GetLivedRowNumbers(int64 *deadrows);
/* 获得数据压缩单元*/
CU *GetCUData(_in_ CUDesc *cuDescPtr, _in_ int colIdx, _in_ int valSize, _out_ int &slotId);
CU *GetUnCompressCUData(Relation rel, int col, uint32 cuid, _out_ int &slotId, ForkNumber forkNum = MAIN_FORKNUM,
bool enterCache = true) const;
/* 缓冲向量填充 APIs */
int FillVecBatch(_out_ VectorBatch *vecBatchOut);
/* 填充列向量*/
template <bool hasDeadRow, int attlen>
int FillVector(_in_ int colIdx, _in_ CUDesc *cu_desc_ptr, _out_ ScalarVector *vec);
template <int attlen>
void FillVectorByTids(_in_ int colIdx, _in_ ScalarVector *tids, _out_ ScalarVector *vec);
template <int attlen>
void FillVectorLateRead(_in_ int seq, _in_ ScalarVector *tids, _in_ CUDesc *cuDescPtr, _out_ ScalarVector *vec);
void FillVectorByIndex(_in_ int colIdx, _in_ ScalarVector *tids, _in_ ScalarVector *srcVec, _out_ ScalarVector *destVec);
/* 填充系统列*/
int FillSysColVector(_in_ int colIdx, _in_ CUDesc *cu_desc_ptr, _out_ ScalarVector *vec);
template <int sysColOid>
void FillSysVecByTid(_in_ ScalarVector *tids, _out_ ScalarVector *destVec);
template <bool hasDeadRow>
int FillTidForLateRead(_in_ CUDesc *cuDescPtr, _out_ ScalarVector *vec);
void FillScanBatchLateIfNeed(__inout VectorBatch *vecBatch);
/* 设置数据压缩单元范围以支持索引扫描 */
void SetScanRange();
/* 判断行是否可用*/
bool IsDeadRow(uint32 cuid, uint32 row) const;
void CUListPrefetch();
void CUPrefetch(CUDesc *cudesc, int col, AioDispatchCUDesc_t **dList, int &count, File *vfdList);
/* 扫描函数 */
typedef void (CStore::*ScanFuncPtr)(_in_ CStoreScanState *state, _out_ VectorBatch *vecBatchOut);
void RunScan(_in_ CStoreScanState *state, _out_ VectorBatch *vecBatchOut);
int GetLateReadCtid() const;
void IncLoadCuDescCursor();














 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









