







 本文详细解释了Redis中的ZSet数据结构如何结合SkipList、HT和ZipList来满足排序和存储需求。当元素数量和内存限制发生变化时,ZSet会自动选择最合适的底层实现,包括ZipList的排序逻辑和向跳表的过渡机制。
本文详细解释了Redis中的ZSet数据结构如何结合SkipList、HT和ZipList来满足排序和存储需求。当元素数量和内存限制发生变化时,ZSet会自动选择最合适的底层实现,包括ZipList的排序逻辑和向跳表的过渡机制。
Redis Zset的底层原理
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值:
- 可以根据score值排序后
- member必须唯一
- 可以根据member查询分数

因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
- SkipList:可以排序,并且可以同时存储score和ele值(member)
- HT(Dict):可以键值存储,并且可以根据key找value
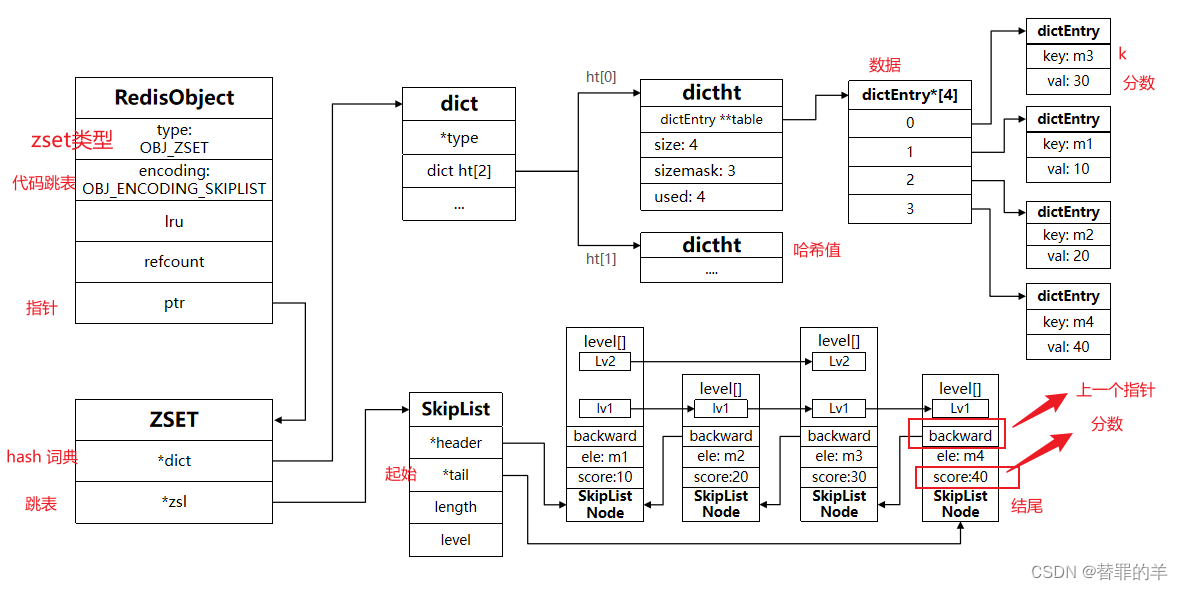
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于zset_max_ziplist_entries,默认值128(可以通过配置文件、命令修改默认值,如果元素数量==0,代表禁用ZipList)
- 每个元素都小于zset_max_ziplist_value字节,默认值64
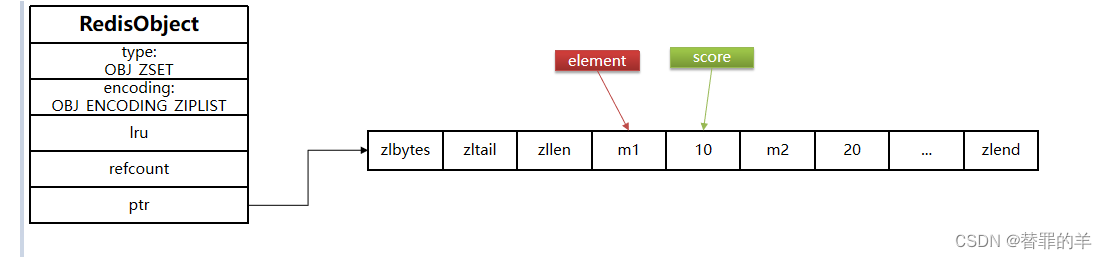
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
ZipList图
Zset底层原理白话
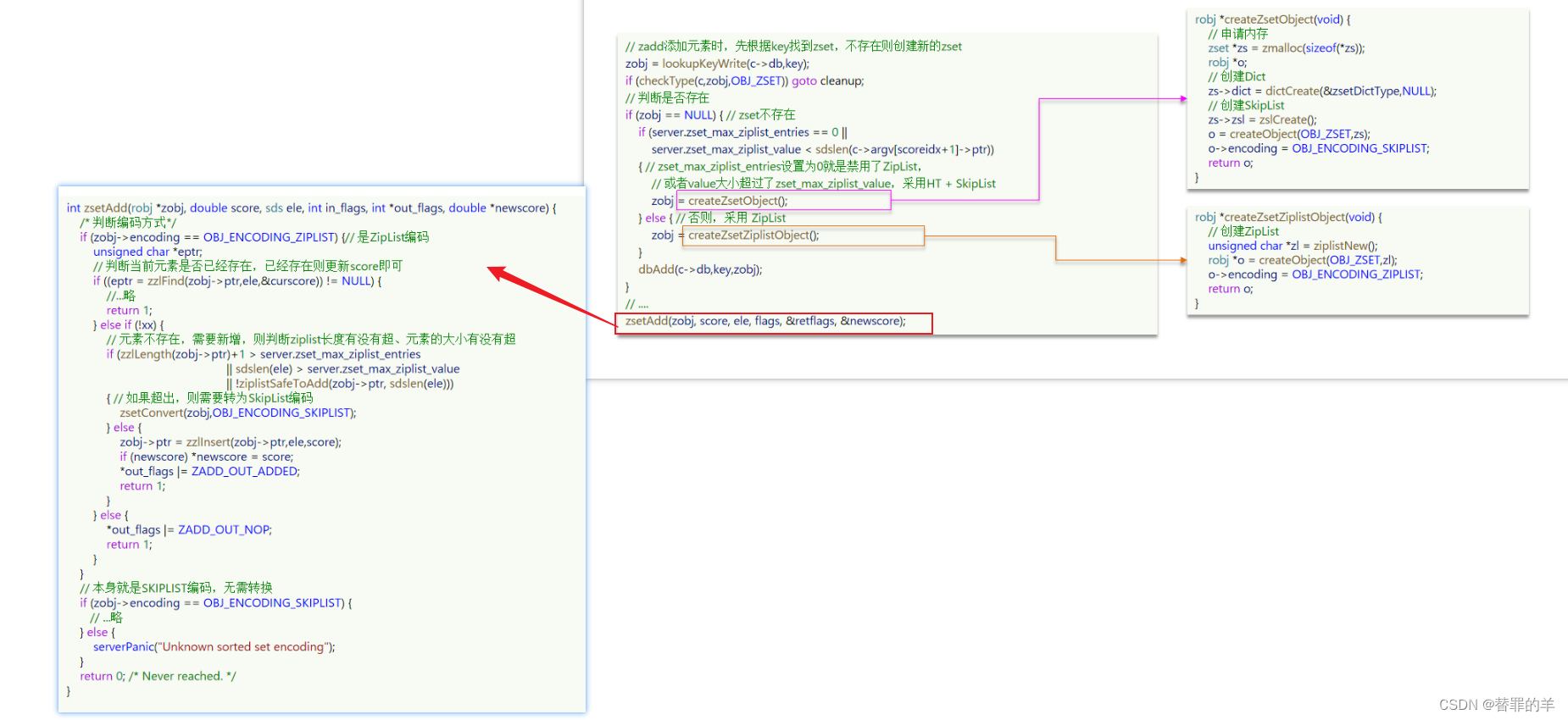
元素数量大于最大entries,或每个元素都大于value字节,就采用哈希表+跳表的结果,否则采用ZipList;
当采用的是ZipList,慢慢添加元素,会往跳表转化,在zsetadd方法中做判断,具体逻辑是这样的,判断编码是不是ZipList,是的话判断当前元素是否存在,如果存在更新score分数;如果元素不存在,需要判断ZipList的长度、元素大小有没有超,如果超了,转为跳表















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









