






今天又来分享下我的爬虫实战案例了。

很多人看到这种网站就怂了,觉得这种网站爬不了,但其实这种网站的数据是公开大众可见的,并没有个人隐私数据,爬一爬也是没问题的,那么该怎么爬呢?

可以看到,这个数据已进行加密,我们先了解清楚是哪里加密了。我们可以通过XHR断点的形式去进行查找。
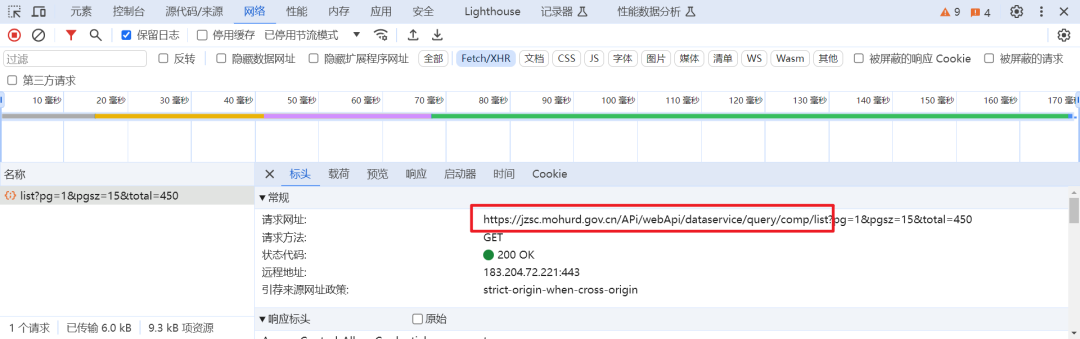
在这个红色框住的地方可以随便复制一段
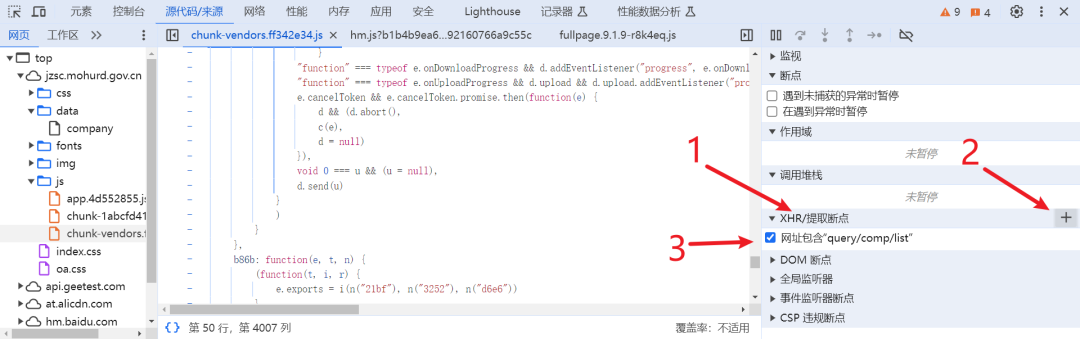
把复制的内容粘贴上去,找到它加密的位置
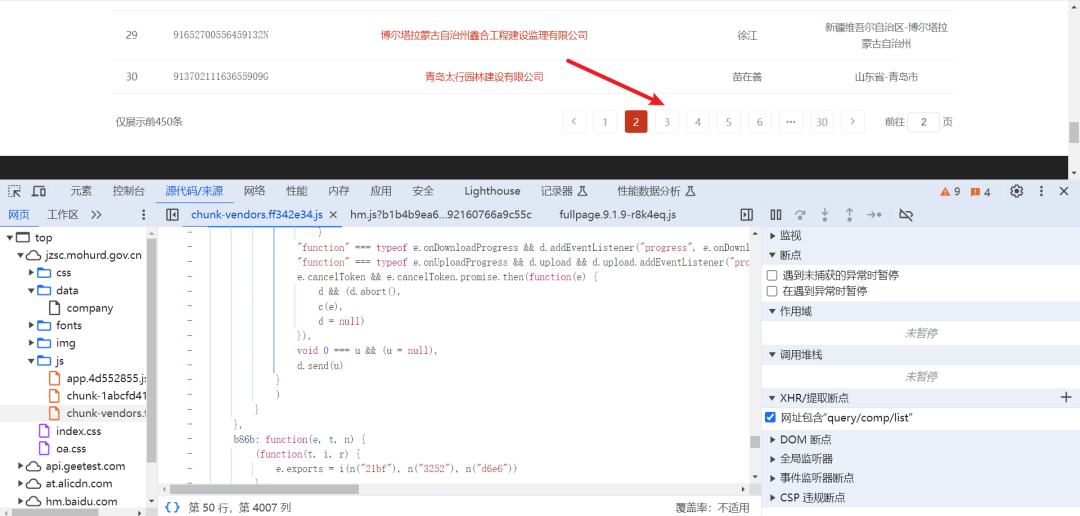
点击翻页,进行触发
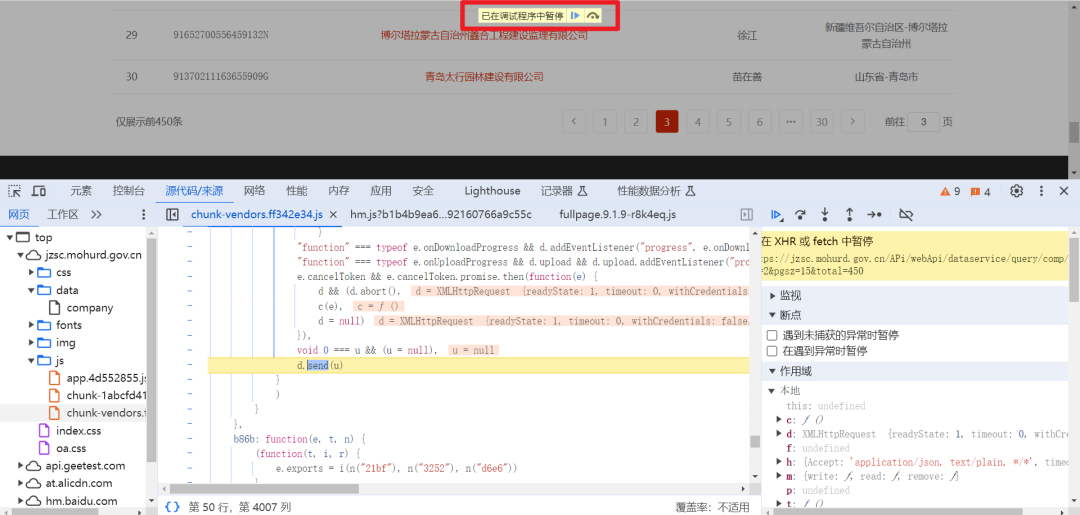
成功断住
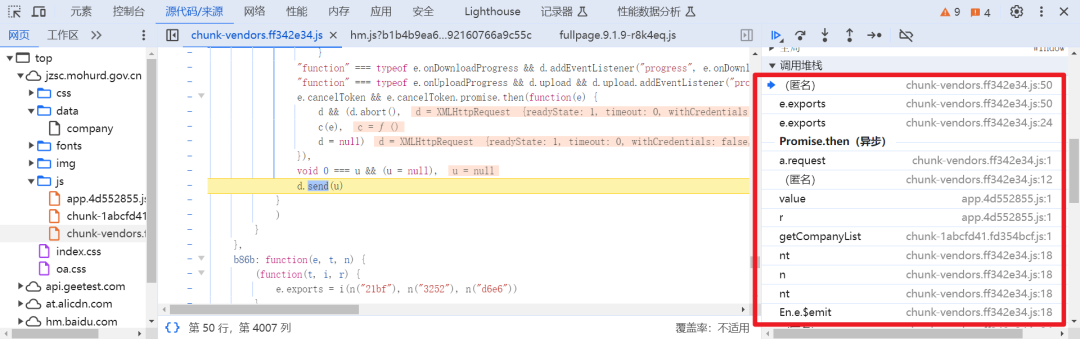
再通过调用堆栈去一个一个查找加密位置,这个时候就得细心了,得慢慢找,感兴趣的小伙伴可以自行去查找,我们直接来看代码
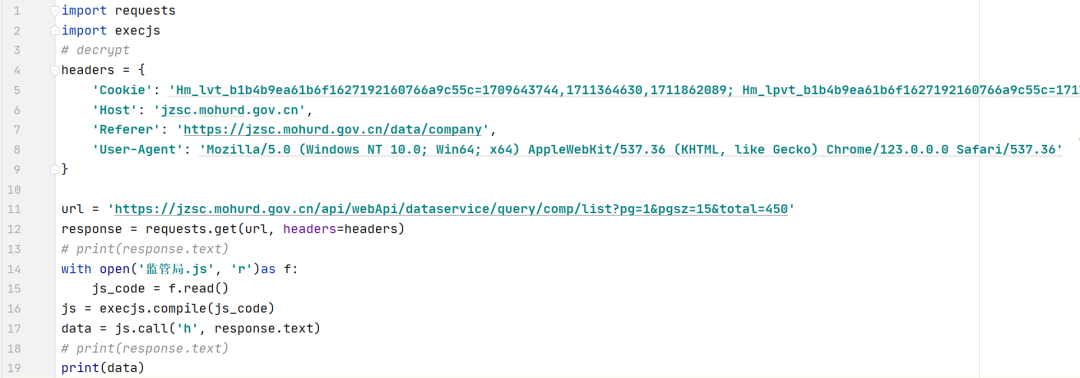
这里是Python代码,还是一样的操作,添加请求头、Host、防盗链、Cookie,加上之后正常对网址发送请求,从第14行开始就是来读取我们所写的js文件,接下来,我们看看js文件是怎么操作的。
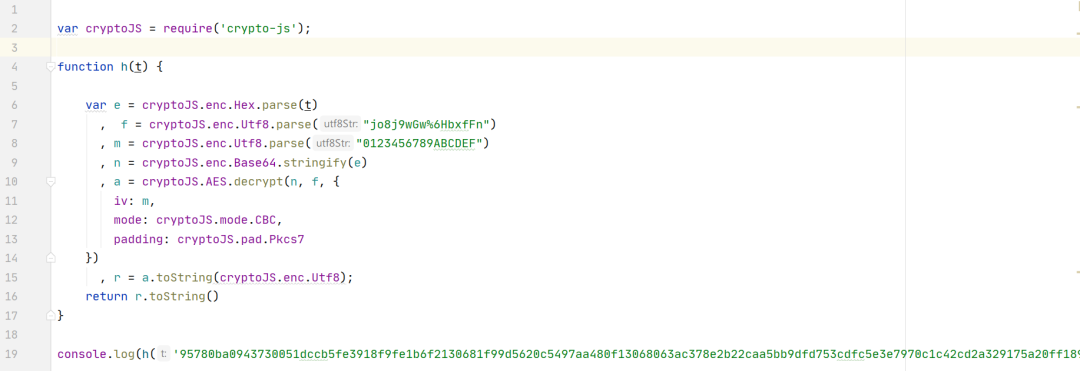
Js文件其实就是把它加密的位置全都复制粘贴下来,复制粘贴下来之后进行打印输出
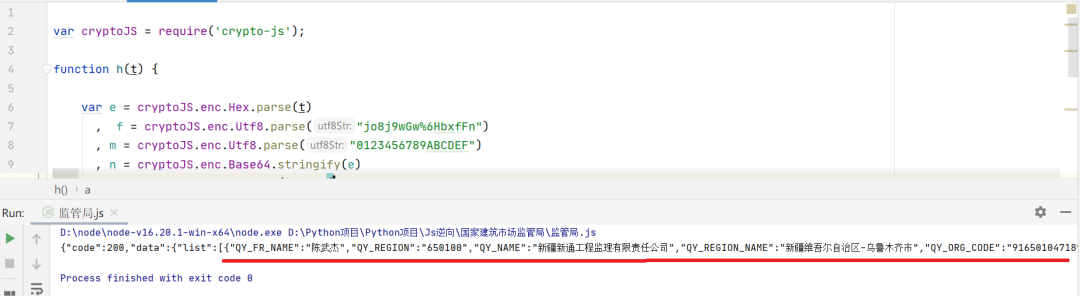
数据已经出来啦,只需要写入Python文件中就能获取到我们想要的数据了。
需要注意一点的是:
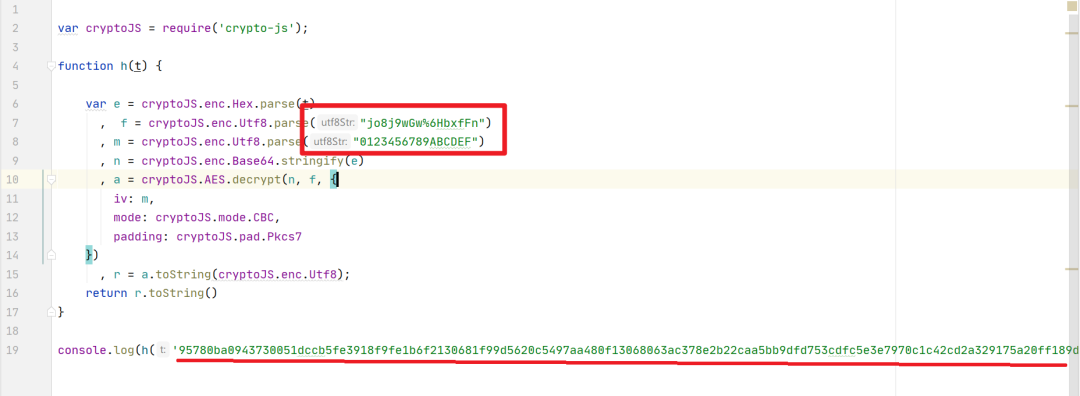
框住的地方,这个网站会进行更改,所以还是建议大家自己去实操一遍哦。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









