






今天来做10分钟完成海量视频数据的采集,下图是需要采集的对象。

如何对数据进行采集呢,首先打开抓包工具进行分析。选择对应的元素图标点需要抓取的资源,可以看到索引到了对应的标签资源位置,可以看到对应的是img标签。
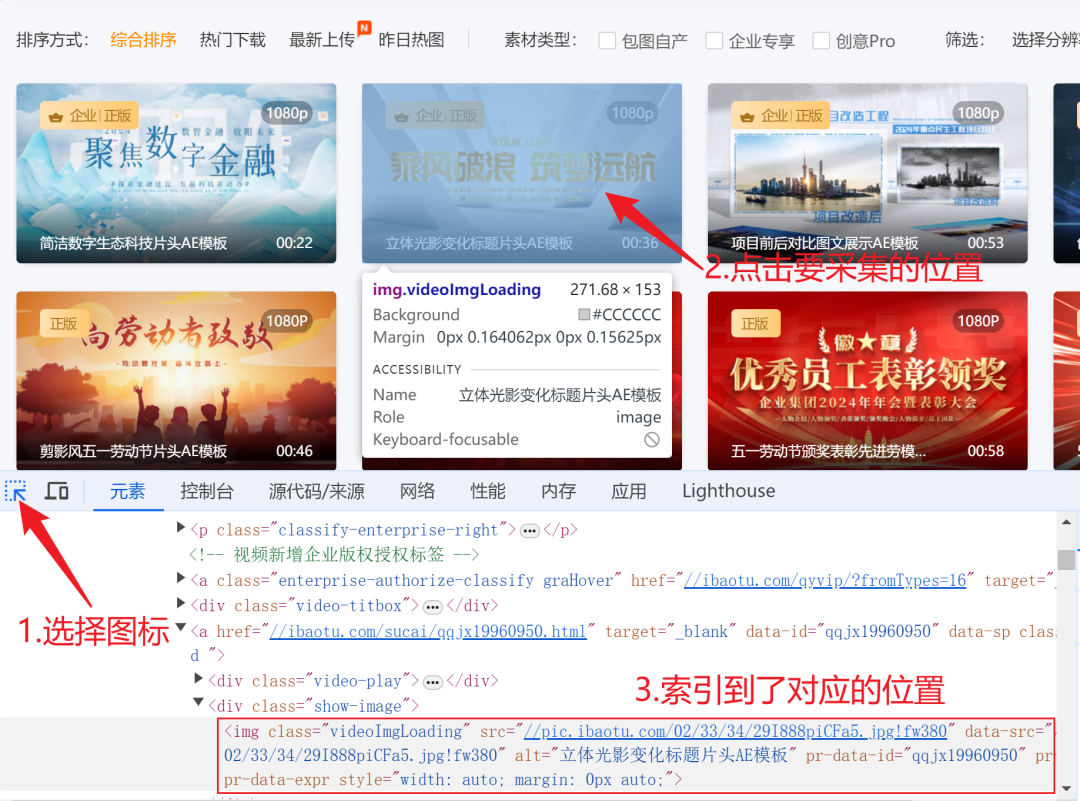
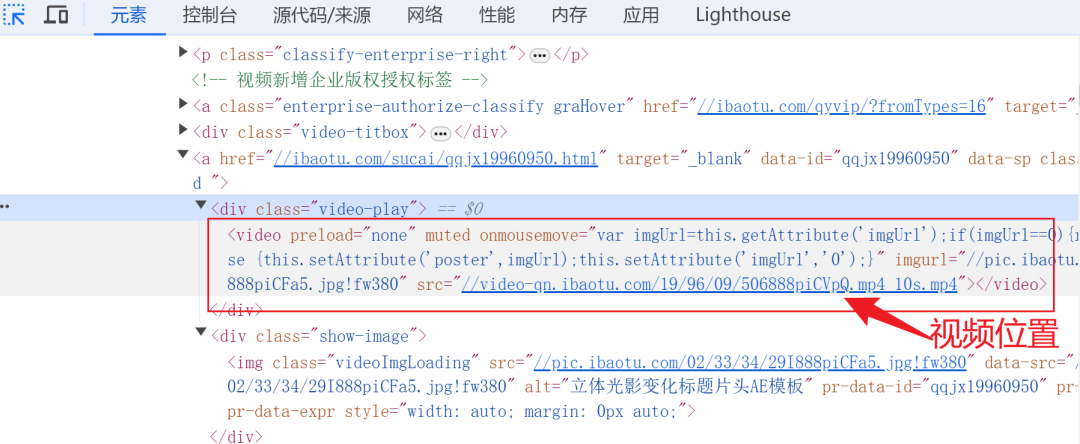
找到img上一层级的同级别div标签进行展开,可以看到里面嵌套了video标签,这个标签的src属性里面有对应的视频资源。视频资源少了https:这样的协议头,只需要在这个字符串前面拼接这个https:协议头就可以进行视频的访问。
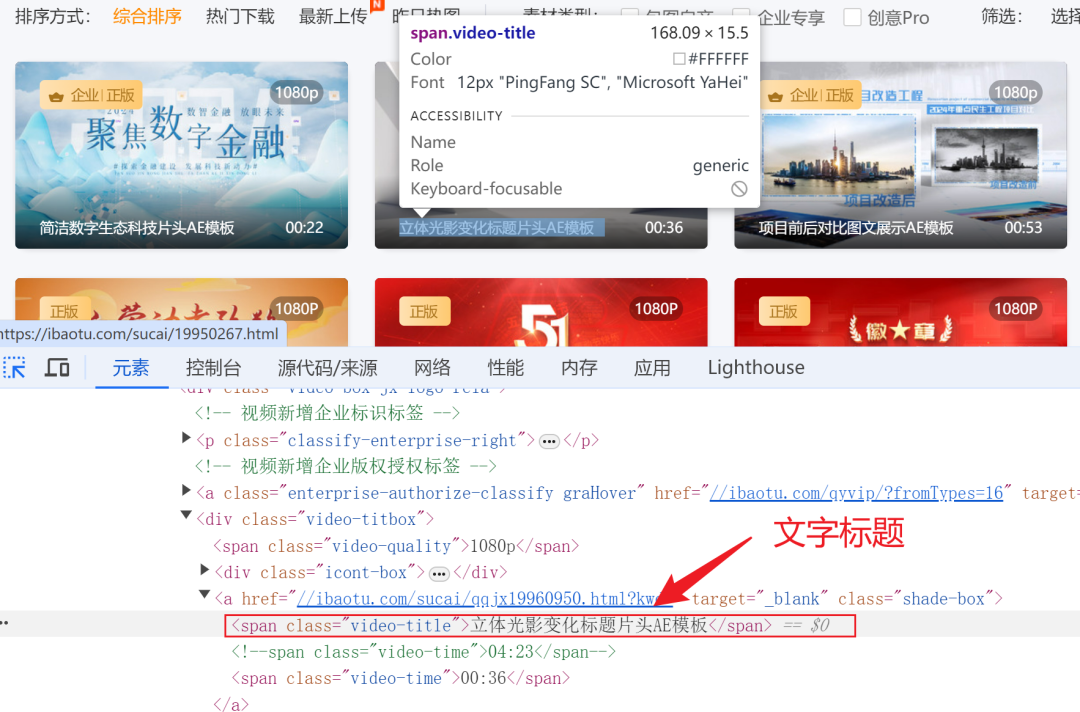
通过同样的方式,也可以找到视频对应的文字位置。后续采集到了视频,顺便可以使用对应的文字标题进行命名。其它的视频,也可以使用这样的方式进行查看。
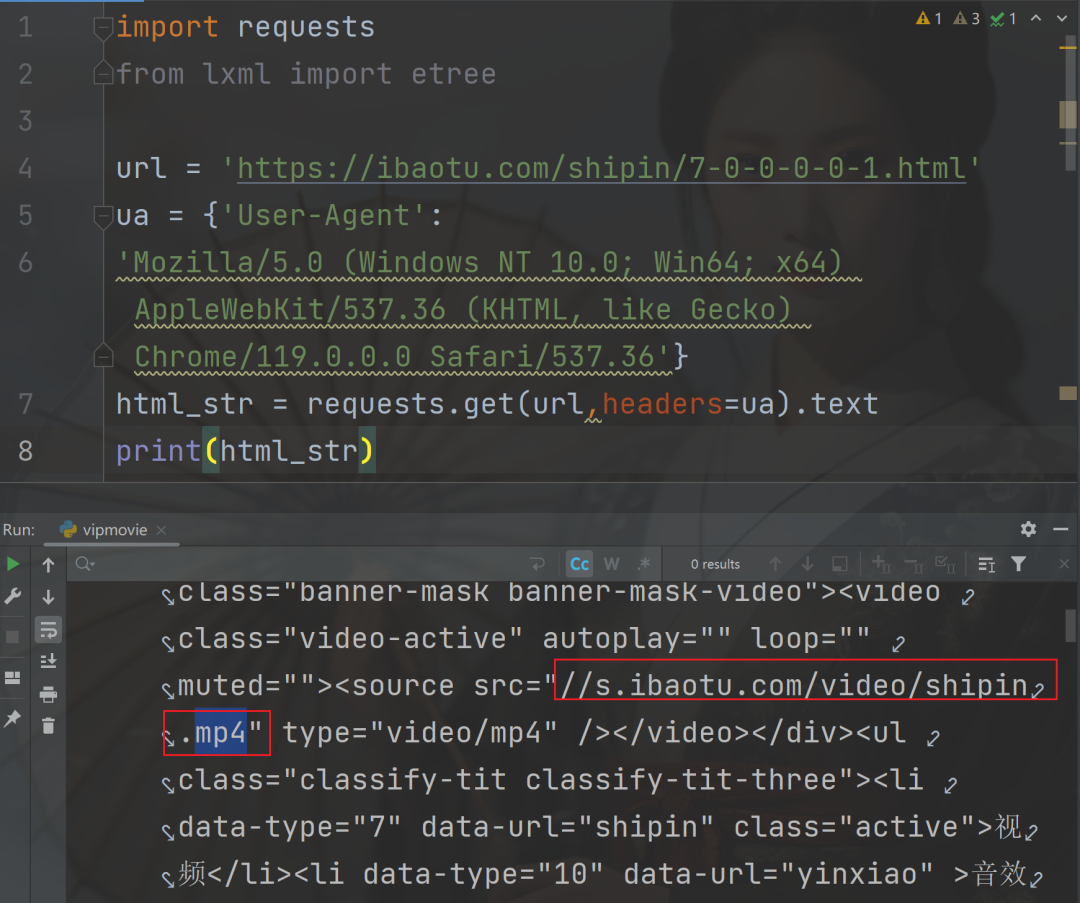
Html里面的数据就有我们想要的结果,所以只需要对当前网页页面的网址发起网络请求就可以。拿到数据结果之后,筛选数据,进行保存就可以得到最终的结果。
在发起请求的时候,可以看到有视频数据的结果,后面就是数据删选的操作。
使用xpath语法可以筛选出数据,这是xpath语法筛选出来的结果。
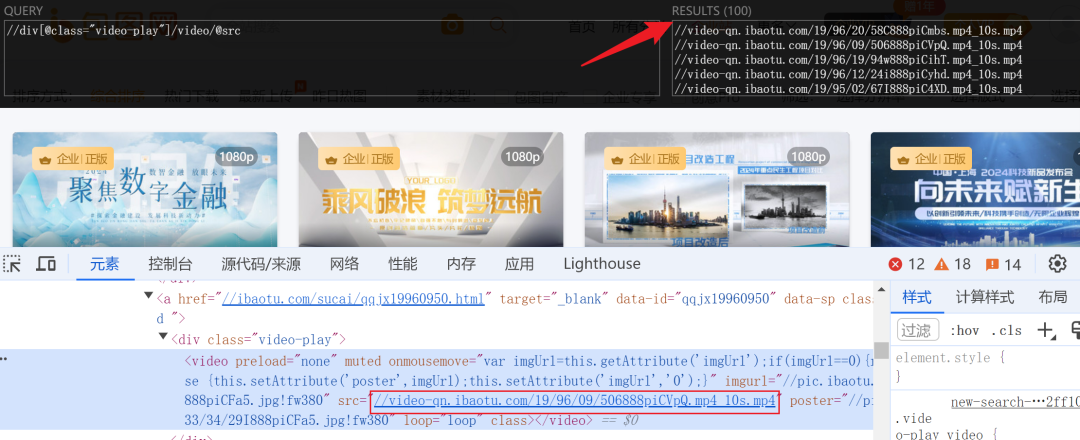
数据筛选出来之后,直接进行保存就行。
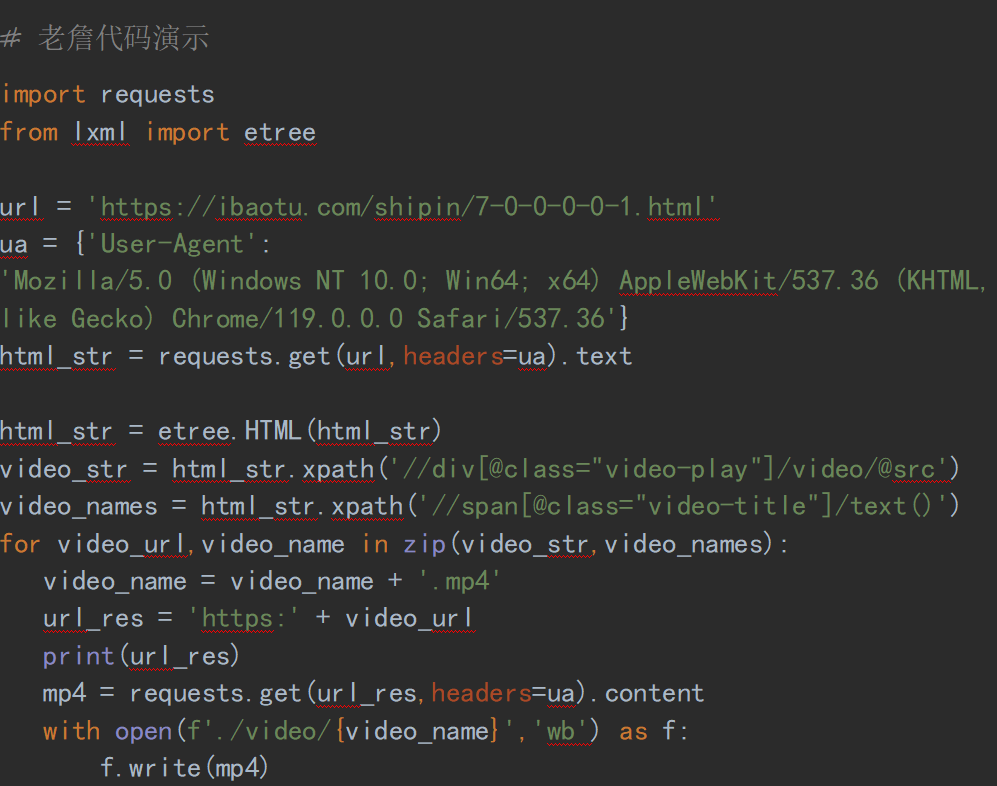
以下是示例代码:















 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









