







目录
1、回顾SQL查询语句
基本语法:
mysql> select */字段列表 from 数据表名称 where 查询条件;
2、SQL查询子句
基本语法:
mysql> select */字段列表 from 数据表名称 where 子句 group by 子句 order by 子句 limit 子句;
① where子句
② group by子句
③ order by子句
④ limit子句
特别注意:子句的顺序是固定的,不能颠倒。
3、WHERE子句
案例:like模糊查询语句,查询姓"关"的同学信息(name字段对应值应该以"关"开头)
准备测试数据
mysql> create database db_sanguo;
mysql> use db_sanguo;
mysql> create table tb_student(
id mediumint not null auto_increment,
name varchar(20),
age tinyint default 0,
gender enum('男','女'),
address varchar(255),
primary key(id)
) default charset=utf8;
//mediumint not null auto_increment 自增
//primary key 在数据库中的意思是主键,用来确保记录的唯一性
插入测试数据
mysql> insert into tb_student values (null,'刘备',33,'男','湖北省武汉市');
mysql> insert into tb_student values (null,'貂蝉',18,'女','湖南省长沙市');
mysql> insert into tb_student values (null,'关羽',32,'男','湖北省荆州市');
mysql> insert into tb_student values (null,'大乔',20,'女','河南省漯河市');
mysql> insert into tb_student values (null,'赵云',25,'男','河北省石家庄市');
mysql> insert into tb_student values (null,'小乔',18,'女','湖北省荆州市');
使用like模糊查询,获取姓"关"的同学信息
mysql> select * from tb_student where name like '关%';
like模糊查询,有点类似于管道命令的中的数据检索。有两个关键字:%百分号与_下划线,%百分号代表任意个任意字符,_下划线代表任意的某个字符(只能匹配1个)
案例:like模糊查询语句,查询名字中带"蝉"字的同学信息
mysql> select * from tb_student where name like '%蝉%';
案例:like模糊查询语句,查询云字结尾且名字为两个字的同学信息
mysql> select * from tb_student where name like '_云';
案例:获取学生表中,id编号为3的同学信息
mysql> select * from tb_student where id=3;
案例:获取年龄大于25周岁的同学信息
mysql> select * from tb_student where age>25;
案例:获取学生表中,性别不为男的同学信息(获取女同学的信息)
mysql> select * from tb_student where gender<>'男';
案例:获取班级中年龄大于30岁的男同学信息
select * from tb_student where age>30 && gender='男';
案例:获取id值为1、3、5的同学信息
mysql> select * from tb_student where id=1 or id=3 or id=5;
案例:获取年龄在18周岁~25周岁之间的同学信息
mysql> select * from tb_student where age>=18 and age<=25;
或
mysql> select * from tb_student where age between 18 and 25;
案例:获取id值为2、4、6的同学信息
mysql> select * from tb_student where id in (2,4,6);
4、DISTINCT数据去重
案例:获取tb_student学生表学员年龄的分布情况。
mysql> select distinct age from tb_student;
5、GROUP BY子句
group by子句的作用:对数据进行分组操作,为什么要进行分组呢?分组的目标就是进行分组统计。
根据给定==数据列==的查询结果进行分组统计,最终得到一个==分组汇总表==
注:一般情况下group by需与==统计函数==一起使用才有意义
5.1、统计函数
| 常见统计函数 | 说明 |
| max | 求最大值 |
| min | 求最小值 |
| sum | 求和 |
| avg | 求平均值 |
| count | 求总行数 |
案例:求tb_student表中一共有多少个记录
mysql> select count(*) from tb_student;
案例:针对id字段求和
mysql> select sum(id) from tb_student;
案例:求学员表中年龄的平均值
mysql> select avg(age) from tb_student;
5.2、GROUP BY分组
案例:求tb_student表中,男同学的总数量与女同学的总数量
mysql> select gender,count(*) from tb_student group by gender;
在MySQL5.7以后版本中,分组字段必须出现在select后面的查询字段中
案例:求tb_student表中,男同学年龄的最大值与女同学年龄的最大值
mysql> select gender,max(age) from tb_student group by gender;
6、ORDER BY子句
主要作用的就是对数据进行排序(升序、降序)
升序:从小到大,1,2,3,4,5
mysql> select * from 数据表名称 ... order by 字段名称 asc;
降序:从大到小,5,4,3,2,1
mysql> select * from 数据表名称 ... order by 字段名称 desc;
案例:按年龄进行排序(由大到小)
mysql> select * from tb_student order by age desc;
7、LIMIT子句
mysql> select * from 数据表名称 ... limit number; 查询满足条件的number条数据
或
mysql> select * from 数据表名称 ... limit offset,number; 从偏移量为offset开始查询,查询number条记录
offset的值从0开始
offset偏移量:
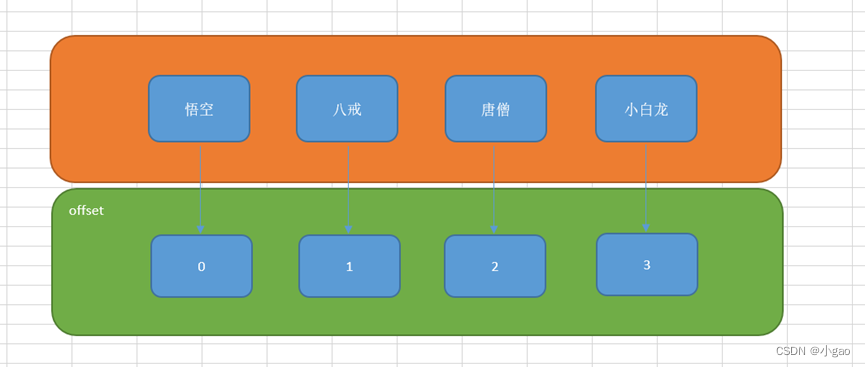
案例:获取学生表中,年龄最大的学员信息
mysql> select * from tb_student order by age desc limit 1;
案例:从偏移量为1的元素开始查询,查询2条记录
mysql> select * from tb_student limit 1,2;
LIMIT子句在开发项目中,主要应用于数据分页。
案例:实现数据分页(参考上图)
第一页:
mysql> select * from tb_student limit 0,2;
第二页:
mysql> select * from tb_student limit 2,2;
8、 SQL多表查询
8.1、 什么是多表查询
我们刚才学习的SQL子句都主要是针对单表情况,我们在实际工作中,也可能会接触到一些复杂的多表查询。
8.2、 UNION联合查询
UNION联合查询的作用:把多个表中的数据联合在一起进行显示。应用场景:分库分表
第一步:创建两个结构相同的学生表tb_student1与tb_student2
mysql> create table tb_student1(
id mediumint not null auto_increment,
name varchar(20),
age tinyint unsigned default 0,
gender enum('男','女'),
subject enum('ui','java','yunwei','python'),
primary key(id)
) engine=innodb default charset=utf8;
mysql> insert into tb_student1 values (1,'悟空',255,'男','ui');
mysql> create table tb_student2(
id mediumint not null auto_increment,
name varchar(20),
age tinyint unsigned default 0,
gender enum('男','女'),
subject enum('ui','java','yunwei','python'),
primary key(id)
) engine=innodb default charset=utf8;
mysql> insert into tb_student2 values (2,'唐僧',30,'男','yunwei');
第二步:使用UNION进行联合查询
mysql> select * from tb_student1 union select * from tb_student2;
9、 SQL语句查询练习 (*重点)
下面以图书表 book 为例进行演示
9.1、 把book.sql上传到/root目录
9.2、 把课程中的book.sql导入MySQL
mysql -uroot -p123456 #先登陆数据库
create database book; #新建一个数据库
use book;
source /root/book.sql;#把book.sql 导入 名字为book的数据库
导入成功:
show tables; #显示所有的表
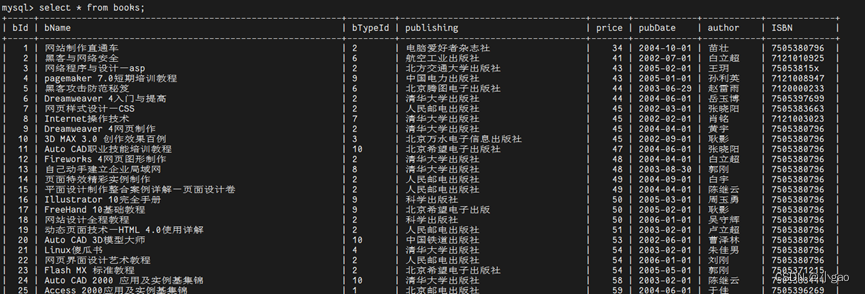
select * from books; #*通配符:表示所有字段 from 表名 指定是从那张表中查询
9.3、 练习:
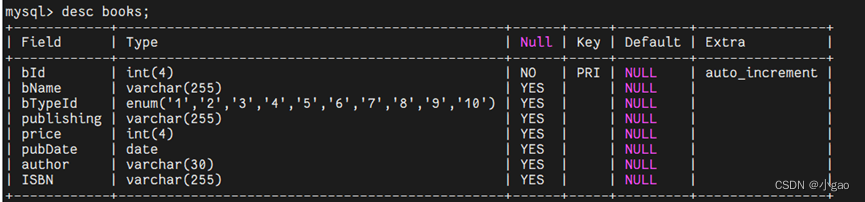
查看表的结构
desc books;
where 表达式 (按条件查询)
#查询bId为5的内容
select * from books where bId =5;
#查询publishing 出版社为清华大学出版社的内容
select * from books where publishing= "清华大学出版社"; #字符串要加引号
#查询价格小于50元的书
select * from books where price <50;
#查询 价格大于50 且 出版社为 人民邮电出版社
select * from books where price >50 and publishing= "人民邮电出版社";
#查询 价格大于50 且 出版社为 人民邮电出版社 并且 书名中 有CAD 内容
select * from books where price >50 and publishing= "人民邮电出版社" and bName like "%CAD%";
#查询出版社为清华大学 或者人民邮电的 书名和价格
select bName,price,publishing from books where publishing= "人民邮电出版社" or publishing= "清华大学出版社";
#查询所有图书价格按照从高到底排序
select * from books order by price desc ;
#查询所有图书价格按照从高到底排序
select * from books order by price asc ;
#查询所有图书价格按照从低到高排序,限制显示一条 也就是价格最低的一本书
select * from books order by price asc limit 0,1;
#查询所有图书价格按照从高到底排序,限制显示三条 也就是价格第二高到第四高的内容
select * from books order by price desc limit 1,3;
select * from books order by 1 ; #按照第一个字段排序
select * from books order by 3 ; #按照第三个字段排序
select * from books order by 9 ; #按照第九个字段排序
修改数据库内容
修改 表为book的 价格为50 当bId 为3的时候
update books set price=50 where bId=3;
修改表为book的 价格为50 当 书名为 黑客与网络安全
update books set price=50 where bName="黑客与网络安全";
修改表为book的 书名为《黑客与画家》 当 bId 为2
update books set bName="黑客与画家" where bId=2;
增加数据
insert into books values(45,"黑客攻防",3,"中国工业出版社",98,"2021-01-01","齐鹏",7121008947);
删除数据
delete from books where bName="黑客攻防";#删除名字为黑客攻防的内容
delete from books where price >100; #删除价格大于100 的内容
delete from books;#删除books所有数据 注意不等于 drop table books;
















 8005
8005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











