






什么时候需要分片上传?
如果将大文件一次性上传,耗时会非常长,甚至可能传输失败,那么我们怎么解决这个问题呢?既然大文件上传不适合一次性上传,那么我们可以尝试将文件分片散上传。
这样的技术就叫做分片上传。分片上传就是将大文件分成一个个小文件(切片),将切片进行上传,等到后端接收到所有切片,再将切片合并成大文件。通过将大文件拆分成多个小文件进行上传,确实就是解决了大文件上传的问题。因为请求时可以并发执行的,这样的话每个请求时间就会缩短,如果某个请求发送失败,也不需要全部重新发送。
分片上传流程
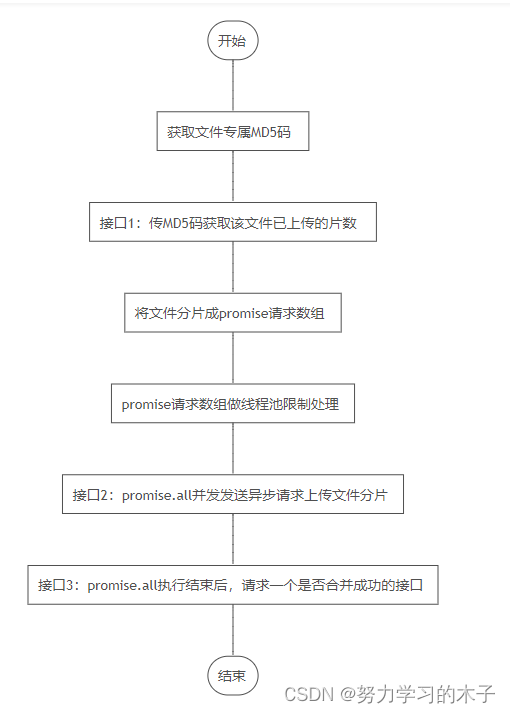
获取文件专属MD5码
import sparkMD5 from 'spark-md5' // 安装下spark-md5包
// 定义hash函数,接受一个名为chunks的数组作为参数
hash = (chunks) => {
// 返回一个Promise,这样调用者可以使用.then()或async/await来处理结果
return new Promise((resolve) => {
// 创建一个新的sparkMD5实例,用于计算MD5哈希值
const spark = new sparkMD5();
// 定义一个递归函数_read,用于逐个处理chunks数组中的blob
function _read(i) {
// 如果索引i大于等于chunks数组的长度,说明所有blob都已经处理完毕
if (i >= chunks.length) {
// 调用sparkMD5实例的end方法,并传入resolve回调,以返回最终的哈希值
resolve(spark.end());
return; // 读取完成,退出函数
}
// 获取当前索引i对应的blob
const blob = chunks[i];
// 创建一个新的FileReader实例,用于读取blob的内容
const reader = new FileReader();
// 设置FileReader的onload事件处理函数,当blob内容读取完成后调用
reader.onload = e => {
// 从事件对象e中获取读取到的字节数组
const bytes = e.target.result;
// 将字节数组添加到sparkMD5实例中,用于计算哈希值
spark.append(bytes);
// 递归调用_read函数,处理下一个blob
_read(i + 1);
};
// 以ArrayBuffer格式异步读取当前blob的内容
reader.readAsArrayBuffer(blob); // 这里是读取操作开始的地方
}
// 从索引0开始,调用_read函数,处理chunks数组中的第一个blob
_read(0);
});
};
解析:
在这个函数中,_read 函数是一个递归函数,它会逐个处理 chunks 数组中的每个 blob。对于每个 blob,它使用 FileReader 的 readAsArrayBuffer 方法异步读取内容,并在内容读取完成后通过 onload 事件处理函数将读取到的字节数组添加到 sparkMD5 实例中。当所有 blob 都处理完毕后,sparkMD5 实例的 end 方法被调用,并返回最终的哈希值,这个值随后通过Promise的 resolve 方法传递给调用者。
在这个函数中,当用户选择一个文件后,readAsArrayBuffer开始异步读取文件内容。一旦文件内容被读取并转换为ArrayBuffer,onload事件处理程序就会被调用,你可以在这个事件处理程序中访问到ArrayBuffer对象,并对其进行处理。ArrayBuffer对象代表原始的二进制数据
接口1:传MD5码获取该文件已上传的片数
调用上面的方法hash()
const md5Str = await this.hash(chunksList);
/* 这里写发送md5Str【接口1】 的方法,获取已上传片数 */
接口2:将文件分片成promise请求数组
1.文件分片
chunkFile = (file, chunksize) => {
const chunks = Math.ceil(file.size / chunksize);
const chunksList = [];
let currentChunk = 0;
while (currentChunk < chunks) {
const start = currentChunk * chunksize;
const end = Math.min(file.size, start + chunksize);
const chunk = file.slice(start, end);
chunksList.push(chunk);
currentChunk++;
}
return chunksList;
};
2.封装成promise请求
chunkPromise = data => { //每个分片的请求
return new Promise((resolve, reject) => {
/* 这里写上传的 【接口2】,传data过去*/
}).catch(err => {
message.error(err.msg);
reject();
})
}
const promiseList = []
const chunkList = chunkFile(file, size)
chunkList.map(item => {
const formData = new FormData();
formData.append('file', item)
// limit是线程池组件 后面会写
promiseList.push(limit(() => this.chunkPromise(formData, chunks)))
})
promise请求数组做线程池限制处理 p-limit
p-limit npm 包是一个实用工具,它允许你限制同时运行的 Promise 数量。当你拥有可以在并行中运行的操作,但由于资源限制想要限制这些操作的数量时,这个工具就很有用,有助于控制并发性。
p-limit npm地址
官方案例:
const pLimit = require('p-limit');
const limit = pLimit(2);
const input = [
limit(() => fetchSomething('foo')),
limit(() => fetchSomething('bar')),
limit(() => doSomethingElse()),
];
// Only two promises will run at once, the rest will be queued
Promise.all(input).then(results => {
console.log(results);
});
接口3:promise.all执行结束后,请求一个是否合并成功的接口
Promise.all(promiseList).then(res =>{
// 这里写接口3 问后端是否合并成功了
}).catch(err => {
message.error(err.msg);
})完整主函数
分片大小建议不超过最大不超过5M
const md5Str = await this.hash(chunksList);
/* 这里写发送md5Str【接口1】 的方法,获取已上传片数 */
const promiseList = []
const chunkList = this.chunkFile(file, size)
chunkList.map(item => {
const formData = new FormData();
formData.append('file', item)
promiseList.push(limit(() => this.chunkPromise(formData, chunks))) // 【接口2 在this.chunkPromise里】
}
Promise.all(promiseList).then(res =>{
// 这里写【接口3】 问后端是否合并成功了
}).catch(err => {
message.error(err.msg);
})
待优化的地方: 使用Web Workers进行分片上传
Web Workers在后台线程中运行,它们不会阻塞主线程,这意味着主线程可以继续响应用户的操作,如界面渲染和交互。在分片上传过程中,每个文件块可以在单独的Worker中处理,从而实现并行处理,大大提高了上传速度。同时,由于Worker不会与主线程共享内存,因此可以避免内存竞争和阻塞,进一步提升了性能。















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









