







需要在开头提前说明,本篇文章仅仅用于在学习初等数论或者离散数学时候对算术基本定理的理解,实际应用的时候把结论告诉大家,想求最大公约数就用欧几里得算法是最简单的,在本篇不再赘述,有机会我会在其他文章中说明欧几里得算法(辗转相除法)的我的理解,求最小公倍数用两个数相乘再除以它们的最大公约数的算法是最简单的!(这么干的“元”理,我在文章的最后会道出我的理解,大道至简!对代码不感兴趣的朋友也可以看过我给出的定理之后浏览代码各个函数的注释而后看我的运行结果看我最后由算术基本定理对这个lcm=m*n/gcd最简算法求lcm的理解,再回头来理解我的代码细节。有类似经验的朋友可以直接对代码算法的优化提出宝贵的意见)应用的时候应该用这两种算法。本来想着能不能在csdn上找到素因子分解法求gcd和lcm的代码来让我理解一下m*n/gcd=lcm到底是一个什么过程的,但没有一篇文章让我看得通透甚至代码不够清晰,走弯路,甚至有的代码中还有错误。本篇的代码中我也同样给到了欧几里得算法和最简算法的对比,以下用质因子分解的算法仅供4字节以内表示的无符号数范围内求它们的gcd和lcm,只是为了告诉大家”可以用素数之积表示所有大于1的正整数“。以前上小学的时候就一直不懂我们为什么要研究素数,合数,最大公约数,最小公倍数,直到离散数学课上讲解了算术基本定理,才知道原来素数是大于1的正整数的“元”!确实,大道至简,这是一个非常令人兴奋的点,在这一块就将素数、最大公约数、最小公倍数有机联系了起来,凭借这一个兴趣让我非常兴奋的希望可以用代码实现这一基本定理。
算术基本定理(唯一分解定理):任何一个大于1的自然数 N,如果N不为质数,那么N可以唯一分解成有限个质数的乘积N=,这里P1<P2<P3......<Pn均为质数,其中指数ai是正整数。这样的分解称为 N 的标准分解式。最早证明是由欧几里得给出的,由陈述证明。此定理可推广至更一般的交换代数和代数数论。
注:以下“素因子”、“素因数”、“质因子”、质因数“同义。
gcd(Greatest Commom Divisor)、lcm(Lowest Common Multiple)的质因子分解法原理:
对于上述原理的说明:看最下面一段最简洁的代码后面紧跟着就是我对这个定理给出的解释。
C语言实现过程当中需要注意的小细节:
①用target1先存放交集数组求完gcd后再将它不重复地存放两素数的所有素因子。
②两质因数的分解的算法Pf,得到的质因数放到数组factor_of_m、factor_of_n中,要注意显示的时候用posm和posn屏蔽掉无效的0。
(//求两质因数数组的交集的时候也要注意屏蔽0,看我在set_Intersection函数中是如何实现的,注意这里的set_Intersection和C++<algorithm>库函数中的set_intersection的i是大写的I,实现的细节也不一样,侧重于当前的问题。)//这个算法在最后可以简化,不需要用,但求交集有它的合理性。
④用质因数分解法求gcd之后,将数组target1重新整理,我们是为了得到两个数的不重复质因子集合。这里我们采用的方式是先将交集数组清零,将得到的两个素因数数组全放入target1中,而后去重。
⑤去除target1中重复元素的算法delesameelem需要注意的一点是要在数组覆盖一轮完成之后不仅对(*pos1)--,对循环变量j也要进行位置的j--,非常重要,不然会出问题。
⑥用循环,依据分解定理将target1中的元素相乘即可用分解质因数的方法得到最小公倍数lcm。
⑦关于记录各个素因子出现的次数的算法,我的思想是,用循环,先用i定位target1[i]的元素输入到count函数中给他赋值给flag进行定位而后依次与两质因子数组中的其中一个进行一个一个的比较,相同的就count++,在这一i轮循环结束之前就给初值为1的lcm乘上count次target[i],如此往复就可顺利计算得到lcm!
由算术基本定理的内容在编写第一段代码回头看,最后我们发现,也执行与⑦同样的操作即也可以求gcd!
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define size_m 100
#define size_n 100
int gcd(int m,int n)//greatest common divisor欧几里得算法求gcd
{
int r;
while(n!=0)
{
r=m%n;
m=n;
n=r;
}
return m;
}
void Pf(int n,int c[],int *pos1)//质因数分解Prime factorization
{
for(int i=2;i<n;i++)
{
while(n!=i)
{
if(n%i==0)
{
c[*pos1]=i;
(*pos1)++;
n/=i;
}
else break;
}
}
c[*pos1]=n;
(*pos1)++;
}
void print_the_two_Pf(int m[],int n[],int pos1,int pos2)//打印两个质因子数组
{
int posm=pos1;
int posn=pos2;
//段落测试,打印输出两个质因数数组
for(int i=0;i<posm;i++)
{
printf("%d ",m[i]);
}
printf("\n");
for(int i=0;i<posn;i++)
{
printf("%d ",n[i]);
}
printf("\n");
}
int min(int a,int b)
{
if(a>b) return b;
else return a;
}
int max(int a,int b)
{
if(a>b) return a;
else return b;
}
void set_Intersection(int m[],int n[],int target1[],int *pos1,int posm,int posn)//求两质因子数组的交集
{
for(int i = 0; i < posm;i++)
{
int j=0;
for(;j < posn;j++) if(m[i]==n[j]) break;
if(i!=0&&m[i]==m[i-1])continue;//某个数组中连续的两个数若一样则跳过
if(m[i]!=0&&n[j]!=0&&m[i]==n[j])//排除0元素放入target1数组
{
target1[*pos1]=m[i];
(*pos1)++;
}
}
}
int count(int mn[],int target[],int pos,int pos1)//记录m和n中每个重复的质因数的个数
{
int count=0;
int flag=target[pos1];
for(int i=0;i<pos;i++)
{
if(mn[i]==flag) count++;
}
return count;
}
void printTarget(int target[],int *pos)//打印target1数组中实际的元素
{
for(int i=0;i<(*pos);i++)
{
printf("%d ",target[i]);
}
printf("\n");
}
void delesameelem(int target1[],int *pos1)//去除数组中重复的数
{
for(int i=0;i<(*pos1)-1;i++)
{
for(int j=i+1;j<(*pos1);++j)
if(target1[i]==target1[j])
{
for(int k=j;k<(*pos1)-1;++k) //从num[j]开始,所有数字前移一位
target1[k]=target1[k+1];
--(*pos1); //数组长度-1
--j; //非常重要,因为有++j,所以这里先减一下,否则num[i]比较的是移动之后的下一位,会漏掉一个数
}
}
}
int main()
{
int m,n,r;
printf("请输入两个正整数:");
scanf("%d %d",&m,&n);
//用欧几里得算法求最大公约数
int Gcd=gcd(m,n);
//m和n,根据算术基本定理分解得到的质因子的数组
int *factor_of_m=(int *)malloc(size_m*sizeof(int));
int *factor_of_n=(int *)malloc(size_n*sizeof(int));
int posm=0;
int posn=0;//以上两个数组的下标标志
//求m和n的质因子,分别放入两数组中
Pf(m,factor_of_m,&posm);
Pf(n,factor_of_n,&posn);
//查看两分解质因子数组
printf("两质因子数组分别为:\n");
print_the_two_Pf(factor_of_m,factor_of_n,posm,posn);
//求两个质因子元素的交集并查看,用于用质因子分解法求gcd和lcm
int sizeof_target1=min(size_m,size_n);
int target1[sizeof_target1];//两质因子数组交集
int pos1=0;//交集数组标号
set_Intersection(factor_of_m,factor_of_n,target1,&pos1,posm,posn);
printf("两质因子数组的交集为:");
printTarget(target1,&pos1);
printf("由欧几里得算法求得的最大公约数为:%d\n",Gcd);
printf("用最简算法得到的最小公倍数为:%d\n",m*n/Gcd);
//将以上交集的各个元素相乘得到的就是m和n的最大公约数
int gcd_by_Pf=1;//用于存放质因子分解法的最大公约数
for(int i=0;i<pos1;i++)
{
gcd_by_Pf*=target1[i];
}
printf("用质因子分解法得到的最大公约数为:%d\n",gcd_by_Pf);
int num;//用于存放两个质因数数组中相同的元素的个数的最大值
int Lcm=1;//用于存放质因数分解法的最小公倍数
//改变交集,让这个集合包含两个集合所有的质因子
pos1=0;
for(int i=0;i<posm;i++) target1[pos1++]=factor_of_m[i];
for(int i=0;i<posn;i++) target1[pos1++]=factor_of_n[i];
delesameelem(target1,&pos1);//去除数组中重复的数
printf("所有质因数集合(不重复)为:");
for(int i=0;i<pos1;i++)
{
printf("%d ",target1[i]);
}
printf("\n");
for(int i=0;i<pos1;i++)//对target1单个的元素循环,用i确定位置
{
int countelem_in_m=count(factor_of_m,target1,posm,i);//定位target中的元素输入到计数函数中得到m中与之相同的数的个数
int countelem_in_n=count(factor_of_n,target1,posn,i);//定位target中的元素输入到计数函数中得到n中与之相同的数的个数
// printf("%d %d\n",countelem_in_m,countelem_in_n);//测试代码
num=max(countelem_in_m,countelem_in_n);//用该代码得到两个质因数数组中相同的元素的个数的最大值
// printf("%d %d %d\n",num,target1[i],Lcm);//测试代码
//
for(int j=0;j<num;j++)
{
Lcm*=target1[i];//由质因数分解法求得的最小公倍数
}
}
printf("用质因子分解法得到的最小公倍数为:%d\n",Lcm);
free(factor_of_m);
free(factor_of_n);
return 0;
}读到这里和上面公式定理截图一对比,估计技巧比较熟练的朋友就发现了,其实我在用分解素因子求最大公因数的时候使用先求交集再将target1中对应的数它们在两个质因子数组中用count函数读出数目再将这个个数分别输入到min函数中求出以target1中各个因此出现的个数作为循环次数相乘的结果作为gcd。我一开始没有顺利求出lcm的时候,从网上搜到的操作就是先求交集这么做的(求交集也有它的道理,因为min(count_elem_in_m,count_elem_in_n)在不是交集的数上指数为0,相当于在公式中在后面该质因数的地方乘上1),但其实再回顾定理发现到根本不用这么麻烦,我已经在代码中取出了它们俩无重复的所有质因数的数组target1,那么我就不取交集,我用target1中的数组重复上述的操作,即以target1中的元素为准,求min(count_elem_in_m,count_elem_in_n),分别作为target1中无重复两数所有素因子的指数来计算gcd!下面给出优化后的代码:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define size_m 100
#define size_n 100
int gcd(int m,int n)//greatest common divisor欧几里得算法求gcd
{
int r;
while(n!=0)
{
r=m%n;
m=n;
n=r;
}
return m;
}
void Pf(int n,int c[],int *pos1)//质因数分解Prime factorization
{
for(int i=2;i<n;i++)
{
while(n!=i)
{
if(n%i==0)
{
c[*pos1]=i;
(*pos1)++;
n/=i;
}
else break;
}
}
c[*pos1]=n;
(*pos1)++;
}
void print_the_two_Pf(int m[],int n[],int pos1,int pos2)//打印两个质因子数组
{
int posm=pos1;
int posn=pos2;
//段落测试,打印输出两个质因数数组
for(int i=0;i<posm;i++)
{
printf("%d ",m[i]);
}
printf("\n");
for(int i=0;i<posn;i++)
{
printf("%d ",n[i]);
}
printf("\n");
}
int min(int a,int b)
{
if(a>b) return b;
else return a;
}
int max(int a,int b)
{
if(a>b) return a;
else return b;
}
//void set_Intersection(int m[],int n[],int target1[],int *pos1,int posm,int posn)//求两质因子数组的交集
//{
// for(int i = 0; i < posm;i++)
// {
// int j=0;
// for(;j < posn;j++) if(m[i]==n[j]) break;
// if(i!=0&&m[i]==m[i-1])continue;//某个数组中连续的两个数若一样则跳过
// if(m[i]!=0&&n[j]!=0&&m[i]==n[j])//排除0元素放入target1数组
// {
// target1[*pos1]=m[i];
// (*pos1)++;
// }
// }
//}
int count(int mn[],int target[],int pos,int pos1)//记录m和n中每个重复的质因数的个数
{
int count=0;
int flag=target[pos1];
for(int i=0;i<pos;i++)
{
if(mn[i]==flag) count++;
}
return count;
}
void printTarget(int target[],int *pos)//打印target1数组中实际的元素
{
for(int i=0;i<(*pos);i++)
{
printf("%d ",target[i]);
}
printf("\n");
}
void delesameelem(int target1[],int *pos1)//去除数组中重复元素
{
for(int i=0;i<(*pos1)-1;i++)
{
for(int j=i+1;j<(*pos1);++j)
if(target1[i]==target1[j])
{
for(int k=j;k<(*pos1)-1;++k) //从num[j]开始,所有数字前移一位
target1[k]=target1[k+1];
--(*pos1); //数组长度-1
--j; //非常重要,因为有++j,所以这里先减一下,否则num[i]比较的是移动之后的下一位,会漏掉一个数
}
}
}
int main()
{
int m,n,r;
printf("请输入两个正整数:");
scanf("%d %d",&m,&n);
//用欧几里得算法求最大公约数
int Gcd=gcd(m,n);
//m和n,根据算术基本定理分解得到的质因子的数组
int *factor_of_m=(int *)malloc(size_m*sizeof(int));
int *factor_of_n=(int *)malloc(size_n*sizeof(int));
int posm=0;
int posn=0;//以上两个数组的下标标志
//求m和n的质因子,分别放入两数组中
Pf(m,factor_of_m,&posm);
Pf(n,factor_of_n,&posn);
//查看两分解质因子数组
printf("两质因子数组分别为:\n");
print_the_two_Pf(factor_of_m,factor_of_n,posm,posn);
printf("由欧几里得算法求得的最大公约数为:%d\n",Gcd);
printf("用最简算法得到的最小公倍数为:%d\n",m*n/Gcd);
int size_of_target1=min(size_m,size_n);
int target1[size_of_target1];
int pos1=0;
// set_Intersection(factor_of_m,factor_of_n,target1,&pos1,posm,posn);
// printf("两质因子数组的交集为:");
// printTarget(target1,&pos1);
// //将以上交集的各个元素相乘得到的就是m和n的最大公约数
int gcd_by_Pf=1;//用于存放质因子分解法的最大公约数
// for(int i=0;i<pos1;i++)
// {
// gcd_by_Pf*=target1[i];
// }
// printf("用质因子分解法得到的最大公约数为:%d\n",gcd_by_Pf);
int num;//用于存放两个质因数数组中相同的元素的个数的最大值
int Lcm=1;//用于存放质因数分解法的最小公倍数
//改变交集,让这个集合包含两个集合所有的质因子
pos1=0;
for(int i=0;i<posm;i++) target1[pos1++]=factor_of_m[i];
for(int i=0;i<posn;i++) target1[pos1++]=factor_of_n[i];
delesameelem(target1,&pos1);//去除数组中重复元素
printf("所有质因数集合(不重复)为:");
for(int i=0;i<pos1;i++)
{
printf("%d ",target1[i]);
}
printf("\n");
for(int i=0;i<pos1;i++)//对target1单个的元素分别与两素因数数组循环遍历,用i确定位置
{
int countelem_in_m=count(factor_of_m,target1,posm,i);//定位target中的元素输入到计数函数中得到m中与之相同的数的个数
int countelem_in_n=count(factor_of_n,target1,posn,i);//定位target中的元素输入到计数函数中得到n中与之相同的数的个数
// printf("%d %d\n",countelem_in_m,countelem_in_n);//测试代码
num=min(countelem_in_m,countelem_in_n);//用该代码得到两个质因数数组中相同的元素的个数的最小值
// printf("%d %d %d\n",num,target1[i],Lcm);//测试代码
//
for(int j=0;j<num;j++)
{
gcd_by_Pf*=target1[i];//由质因数分解法求得的最大公因数
}
}
printf("用质因子分解法得到的最大公因数为:%d\n",gcd_by_Pf);
for(int i=0;i<pos1;i++)//对target1单个的元素分别与两素因数数组循环遍历,用i确定位置
{
int countelem_in_m=count(factor_of_m,target1,posm,i);//定位target中的元素输入到计数函数中得到m中与之相同的数的个数
int countelem_in_n=count(factor_of_n,target1,posn,i);//定位target中的元素输入到计数函数中得到n中与之相同的数的个数
// printf("%d %d\n",countelem_in_m,countelem_in_n);//测试代码
num=max(countelem_in_m,countelem_in_n);//用该代码得到两个质因数数组中相同的元素的个数的最大值
// printf("%d %d %d\n",num,target1[i],Lcm);//测试代码
//
for(int j=0;j<num;j++)
{
Lcm*=target1[i];//由质因数分解法求得的最小公倍数
}
}
printf("用质因子分解法得到的最小公倍数为:%d\n",Lcm);
free(factor_of_m);
free(factor_of_n);
return 0;
}将求交集等冗余的代码清理而保留必要的注释让结构更清晰的展现:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define size_m 100
#define size_n 100
int gcd(int m,int n)//greatest common divisor欧几里得算法求gcd
{
int r;
while(n!=0)
{
r=m%n;
m=n;
n=r;
}
return m;
}
void Pf(int n,int c[],int *pos1)//质因数分解Prime factorization
{
for(int i=2;i<n;i++)
{
while(n!=i)
{
if(n%i==0)
{
c[*pos1]=i;
(*pos1)++;
n/=i;
}
else break;
}
}
c[*pos1]=n;
(*pos1)++;
}
void print_the_two_Pf(int m[],int n[],int pos1,int pos2)//打印两个质因子数组
{
int posm=pos1;
int posn=pos2;
//段落测试,打印输出两个质因数数组
for(int i=0;i<posm;i++)
{
printf("%d ",m[i]);
}
printf("\n");
for(int i=0;i<posn;i++)
{
printf("%d ",n[i]);
}
printf("\n");
}
int min(int a,int b)
{
if(a>b) return b;
else return a;
}
int max(int a,int b)
{
if(a>b) return a;
else return b;
}
int count(int mn[],int target[],int pos,int pos1)//记录m和n中每个重复的质因数的个数
{
int count=0;
int flag=target[pos1];
for(int i=0;i<pos;i++)
{
if(mn[i]==flag) count++;
}
return count;
}
void printTarget(int target[],int *pos)//打印target1数组中实际的元素
{
for(int i=0;i<(*pos);i++)
{
printf("%d ",target[i]);
}
printf("\n");
}
void delesameelem(int target1[],int *pos1)//去除数组中重复元素
{
for(int i=0;i<(*pos1)-1;i++)
{
for(int j=i+1;j<(*pos1);++j)
if(target1[i]==target1[j])
{
for(int k=j;k<(*pos1)-1;++k) //从num[j]开始,所有数字前移一位
target1[k]=target1[k+1];
--(*pos1); //数组长度-1
--j; //非常重要,因为有++j,所以这里先减一下,否则num[i]比较的是移动之后的下一位,会漏掉一个数
}
}
}
int main()
{
int m,n,r;
printf("请输入两个正整数:");
scanf("%d %d",&m,&n);
//用欧几里得算法求最大公约数
int Gcd=gcd(m,n);
//m和n,根据算术基本定理分解得到的质因子的数组
int *factor_of_m=(int *)malloc(size_m*sizeof(int));
int *factor_of_n=(int *)malloc(size_n*sizeof(int));
int posm=0;
int posn=0;//以上两个数组的下标标志
//求m和n的质因子,分别放入两数组中
Pf(m,factor_of_m,&posm);
Pf(n,factor_of_n,&posn);
//查看两分解质因子数组
printf("两质因子数组分别为:\n");
print_the_two_Pf(factor_of_m,factor_of_n,posm,posn);
printf("由欧几里得算法求得的最大公约数为:%d\n",Gcd);
printf("用最简算法得到的最小公倍数为:%d\n",m*n/Gcd);
int size_of_target1=min(size_m,size_n);
int target1[size_of_target1];
int pos1=0;
int gcd_by_Pf=1;//用于存放质因子分解法的最大公约数
int num;//用于存放两个质因数数组中相同的元素的个数的最大值
int Lcm=1;//用于存放质因数分解法的最小公倍数
for(int i=0;i<posm;i++) target1[pos1++]=factor_of_m[i];
for(int i=0;i<posn;i++) target1[pos1++]=factor_of_n[i];
delesameelem(target1,&pos1);//去除数组中重复元素
printf("所有质因数集合(不重复)为:");
for(int i=0;i<pos1;i++)
{
printf("%d ",target1[i]);
}
printf("\n");
for(int i=0;i<pos1;i++)//对target1单个的元素分别与两素因数数组循环遍历,用i确定位置
{
int countelem_in_m=count(factor_of_m,target1,posm,i);//定位target中的元素输入到计数函数中得到m中与之相同的数的个数
int countelem_in_n=count(factor_of_n,target1,posn,i);//定位target中的元素输入到计数函数中得到n中与之相同的数的个数
// printf("%d %d\n",countelem_in_m,countelem_in_n);//测试代码
num=min(countelem_in_m,countelem_in_n);//用该代码得到两个质因数数组中相同的元素的个数的最小值
// printf("%d %d %d\n",num,target1[i],Lcm);//测试代码
//
for(int j=0;j<num;j++)
{
gcd_by_Pf*=target1[i];//由质因数分解法求得的最大公因数
}
}
printf("用质因子分解法得到的最大公因数为:%d\n",gcd_by_Pf);
for(int i=0;i<pos1;i++)//对target1单个的元素分别与两素因数数组循环遍历,用i确定位置
{
int countelem_in_m=count(factor_of_m,target1,posm,i);//定位target中的元素输入到计数函数中得到m中与之相同的数的个数
int countelem_in_n=count(factor_of_n,target1,posn,i);//定位target中的元素输入到计数函数中得到n中与之相同的数的个数
// printf("%d %d\n",countelem_in_m,countelem_in_n);//测试代码
num=max(countelem_in_m,countelem_in_n);//用该代码得到两个质因数数组中相同的元素的个数的最大值
// printf("%d %d %d\n",num,target1[i],Lcm);//测试代码
//
for(int j=0;j<num;j++)
{
Lcm*=target1[i];//由质因数分解法求得的最小公倍数
}
}
printf("用质因子分解法得到的最小公倍数为:%d\n",Lcm);
free(factor_of_m);
free(factor_of_n);
return 0;
}将用欧几里得算法和最简算法的冗余代码也去除的到的最终用仅仅质因数分解法得到gcd和lcm的结构最清晰的仅仅用质因数分解求gcd和lcm的代码:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define size_m 100
#define size_n 100
void Pf(int n,int c[],int *pos1)//质因数分解Prime factorization
{
for(int i=2;i<n;i++)
{
while(n!=i)
{
if(n%i==0)
{
c[*pos1]=i;
(*pos1)++;
n/=i;
}
else break;
}
}
c[*pos1]=n;
(*pos1)++;
}
void print_the_two_Pf(int m[],int n[],int pos1,int pos2)//打印两个质因子数组
{
int posm=pos1;
int posn=pos2;
//段落测试,打印输出两个质因数数组
for(int i=0;i<posm;i++)
{
printf("%d ",m[i]);
}
printf("\n");
for(int i=0;i<posn;i++)
{
printf("%d ",n[i]);
}
printf("\n");
}
int min(int a,int b)
{
if(a>b) return b;
else return a;
}
int max(int a,int b)
{
if(a>b) return a;
else return b;
}
int count(int mn[],int target[],int pos,int pos1)//记录m和n中每个重复的质因数的个数
{
int count=0;
int flag=target[pos1];
for(int i=0;i<pos;i++)
{
if(mn[i]==flag) count++;
}
return count;
}
void printTarget(int target[],int *pos)//打印target1数组中实际的元素
{
for(int i=0;i<(*pos);i++)
{
printf("%d ",target[i]);
}
printf("\n");
}
void delesameelem(int target1[],int *pos1)//去除数组中重复元素
{
for(int i=0;i<(*pos1)-1;i++)
{
for(int j=i+1;j<(*pos1);++j)
if(target1[i]==target1[j])
{
for(int k=j;k<(*pos1)-1;++k) //从num[j]开始,所有数字前移一位
target1[k]=target1[k+1];
--(*pos1);
--j; //非常重要,因为有++j,所以这里先减一下,否则num[i]比较的是移动之后的下一位,会漏掉一个数
}
}
}
int main()
{
int m,n,r;
printf("请输入两个正整数:");
scanf("%d %d",&m,&n);
//m和n,根据算术基本定理分解得到的质因子的数组
int *factor_of_m=(int *)malloc(size_m*sizeof(int));
int *factor_of_n=(int *)malloc(size_n*sizeof(int));
int posm=0;
int posn=0;//以上两个数组的下标标志
//求m和n的质因子,分别放入两数组中
Pf(m,factor_of_m,&posm);
Pf(n,factor_of_n,&posn);
//查看两分解质因子数组
printf("两质因子数组分别为:\n");
print_the_two_Pf(factor_of_m,factor_of_n,posm,posn);
int size_of_target1=min(size_m,size_n);
int target1[size_of_target1];
int pos1=0;
int gcd_by_Pf=1;//用于存放质因子分解法的最大公约数
int num;//用于存放两个质因数数组中相同的元素的个数的最大值
int Lcm=1;//用于存放质因数分解法的最小公倍数
for(int i=0;i<posm;i++) target1[pos1++]=factor_of_m[i];
for(int i=0;i<posn;i++) target1[pos1++]=factor_of_n[i];
delesameelem(target1,&pos1);//去除数组中重复元素
printf("所有质因数集合(不重复)为:");
for(int i=0;i<pos1;i++)
{
printf("%d ",target1[i]);
}
printf("\n");
//按算术基本定理公式用循环来计算gcd最终结果
for(int i=0;i<pos1;i++)//对target1单个的元素分别与两素因数数组循环遍历,用i确定位置
{
int countelem_in_m=count(factor_of_m,target1,posm,i);//定位target中的元素输入到计数函数中得到m中与之相同的数的个数
int countelem_in_n=count(factor_of_n,target1,posn,i);//定位target中的元素输入到计数函数中得到n中与之相同的数的个数
// printf("%d %d\n",countelem_in_m,countelem_in_n);//测试代码
num=min(countelem_in_m,countelem_in_n);//用该代码得到两个质因数数组中相同的元素的个数的最小值
// printf("%d %d %d\n",num,target1[i],Lcm);//测试代码
//
for(int j=0;j<num;j++)
{
gcd_by_Pf*=target1[i];//由质因数分解法求得的最大公因数
}
}
printf("用质因子分解法得到的最大公因数为:%d\n",gcd_by_Pf);
//按算术基本定理公式用循环来计算lcm最终结果
for(int i=0;i<pos1;i++)//对target1单个的元素分别与两素因数数组循环遍历,用i确定位置
{
int countelem_in_m=count(factor_of_m,target1,posm,i);//定位target中的元素输入到计数函数中得到m中与之相同的数的个数
int countelem_in_n=count(factor_of_n,target1,posn,i);//定位target中的元素输入到计数函数中得到n中与之相同的数的个数
// printf("%d %d\n",countelem_in_m,countelem_in_n);//测试代码
num=max(countelem_in_m,countelem_in_n);//用该代码得到两个质因数数组中相同的元素的个数的最大值
// printf("%d %d %d\n",num,target1[i],Lcm);//测试代码
//
for(int j=0;j<num;j++)
{
Lcm*=target1[i];//由质因数分解法求得的最小公倍数
}
}
printf("用质因子分解法得到的最小公倍数为:%d\n",Lcm);
free(factor_of_m);
free(factor_of_n);
return 0;
}看到这里,那么我们来研究一下为什么m*n/gcd=lcm,谈谈我的理解。
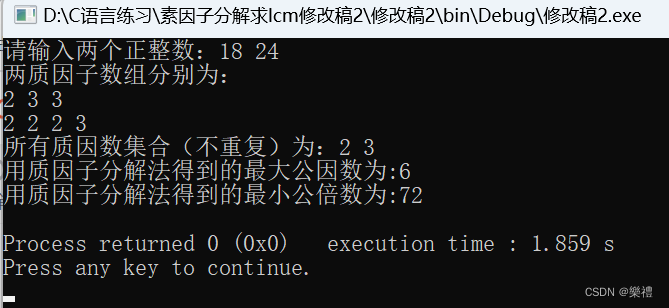
首先对于gcd,以上两数m*n=2*2*2*2*3*3*3,gcd=2*3(是用m中的数量最少的2和n中数量最少的3相乘,这是它们两个公共部分的“至少”的地方,否则它们将没有公共部分,这也是gcd公式中的次数为什么要对这两个数的素因数分解数每个数出现的次数取min的原因!这也是第一篇代码之前网上给出的解法的原理。)//这是从算术基本定理的角度来理解gcd的,我还有从“最大单位份数”的角度来理解gcd,可以点击超链接来查看我的其他文章。
我们再来看lcm,为什么m*n/gcd可以得到lcm?
考察用代码求lcm的过程,输入循环num=max(countelem_in_m,countelem_in_n);得到的表达式可以为
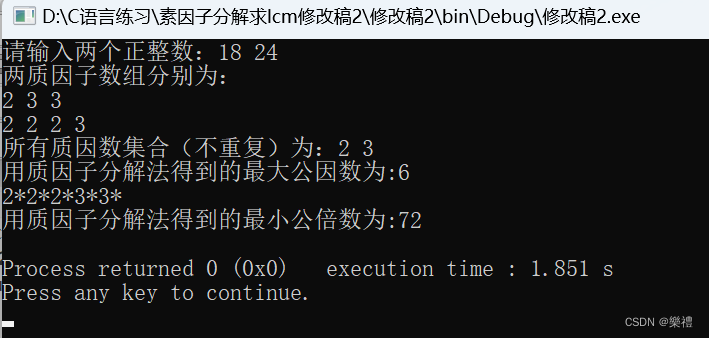

2*2*2*3*3,不就是对于2取n中2的个数(n中2比m中2多),对于3取m中3的个数(m中3比n中3多),这不就是公式m*n/gcd写成素因数分解写法为2*2*2*2*3*3*3/2*3=2*2*2*3*3吗!这也就是lcm公式中的次数为什么要对这两个数的素因数分解数每个数出现的次数取max的原因!这也就是最简算法直接输出lcm=m*m/gcd的原因!
工科的学生,在理解上不需要确确实实的证明,因为第一对于某些定理,证明的材料或者说前置知识你是有可能不知道的,如果你要确确实实的每一条都会,要通过证明性理解你才掌握,我说这不是我们工科的目的,本末倒置,而且你也没有时间,你对证明的理解需要花时间,你对证明的熟练度需要花时间,但主要矛盾集中于“理解性应用”,另外如果说你非要会证明,那么你要会证明的目的又是什么?是为了功利性的攀比吗?我想这个意义还不够大,不足以让你随时记得你的证明方法。
第二这是定理,是前人已经证明过的结论,你会证明没有什么厉害的,你说你算的快,计算机算的比你还快,我们工科的学生研究的突破点应该在工程应用的创新点,要对已有的定理应该做到的是“先相信”和工程实践,你想做出一些贡献你就必须先接受这一点,我知道这很难受,就包括我在高中阶段的时候我也很纳闷为什么考试不考定理的证明过程,考到我会啊,你那应用又不是永恒的东西,我那时候对唯应用主义的填鸭式教学是很不满的,但渐渐的也通过一些功利性的考试的备考也渐渐能够理解学习的规律和“先应用后推导”的必要性和实用性,我们工科的学生要做的应该是在工程中利用数学工具进行“多快好省”的创新,数学是留给数学专业的学生研究的,我们要做的事是与他们合作!而不是干他们的事!人生苦短,这里学过微分方程的解法的同志应该深有体会,那些求解得方法很少有老师会对它进行推导,但其实那些解法也有“元”,核心也在于可以对解的结构进行分解,有机会我也会在我的其他文章里谈谈我的理解,感兴趣的朋友也可以上网搜索自己总结,也有可能你会像现在我这个问题这样暂时先应用,找到它的元的那一刻可能也像今天找到小学就想搞清楚联系的最大公因数、最小公倍数、素数的联系这样在十几年甚至几十年以后的某一个“恰好”,那些解法的步骤都是工程性总结的“多快好省”的经验总结,能够快速应用于工程的求解过程,而这和我们十几年前在小学分散而没有联系地学素数、最大公因数和最小公倍数的感觉是一致的,可能你现在也仅仅是为了应用而已,也没有时间取深究这其中的数学原理,或许在十几年后的某一个机遇,“恰好”碰上了别人总结的某个定理,让你能够从“元”理层面上让这些既定的工程经验得到合理的解释,那时候再去趁热打铁对你人生的每个节点来说才都是高效的,我想这也是学习的规律。
第三,我们一定要考察我们的心态,我们工科的代码实现仅仅只是应用而已,这些方便的算法前人已经帮我们研究过了,我们只是应用而已,没有什么厉害的;而且也不要对“会证明”有什么不切实际的幻想,它也没有什么厉害的,企业要结果,从这个角度而言如果说你只会证明,不会实现一样没什么厉害的(既会证明又会实现,那当然很好,但也很有限,人是有限的,人只能在自己的研究方向能够有希望做到既会又会,但也很有限,什么时候要求你必须要确确实实的证明?就是在写论文雄辩的时候,那个时候花时间和精力是必要的。)。总之就是希望各位能够放平心态,没有什么,认识你自己才是我们一生的命题。
最后我也想再次强调和回应一些肯定会有的声音,也对这些声音谈谈我的看法,就是说我自己实现这一个案例花了几天的时间值得吗?考试又不考。我觉得从某一角度讲,值得,因为最大公约数、最小公倍数、素数我从小学的时候就非常不明白为什么要分开来(而不是联系起来)研究它们,感觉它们有联系但又不知道是什么联系,我现在“恰好”遇上了算术基本定理,也是我正在学习的离散数学课程,我觉得在这里我必须自己去理解,让十几年前的我的疑问得到有联系的解释,本源的解释,和至简的大道(大道至简是说大的道理有十分清晰的“元”,一定是简单的思想,而不能理解为可以一句话给它描述完整,有些元可以,那真的挺好,而有些元需要加一些严格的定义,否则“元”不够清晰,就比如有些人喜欢对人工智能上加上“导论”给人看,你不用“概论”或者“通论”(这三者从前到后内容逐渐细化),你一简化,失去了清晰的“元”别人就不懂“是什么”和“为什么”,“科学”是研究“是什么”、“为什么”,“技术”是研究“怎么做”,“工程”是研究如何“多块好省地做”)。这个定理恰好我有机会去联系让我原本可能永远都不会联系起来的事物,我觉得这一点上来说,值得。再从另一个角度来讲,如果这三者不能够串起来我们也就不能够真正明白求素数算法的意义何在,找本元!这个意义还不够厚重吗,它是很多后续算法的前提。
如果有人还是觉得我做的事是一件浪费浪费时间的事,不如直接记住来的快,确实是这样,我也这样认为,但我说,仅仅的应用其实并不是我们真正想要的,了解“元”理扪心自问其实是我们每个人的追求,所有的不确定一定都是为了走向确定,所有的怀疑一定都是为了走向坚信,就像我们所奢望的既会证明又会实现,那当然很好,其实很多牛人确确实实的做到了这一点。如果有人还是捍卫自己的观点,就认为我这做的没有意义,只有记忆快速应用才有意义,除了选择认同你的观点,我还希望可以和你探讨一下“意义”的话题。有人非要说学习数学不值得,那我觉得确实,没有兴趣的数学确实不值得,而且人生本质上也没有任何意义,所有的一切都是偶然,你可以考虑一下凭什么你的灵魂是“你”而不是其他东西,凭什么?小概率,但确实发生。这一切其实都是小概率事件,只不过幸存者偏差让你我觉得你我的生命不那么偶然,和世界上的牛人比不过是人间充数的,这就和概率的判定和样本空间的选取有关,而概率的实际数值尽管研究的是同一个问题,选取不同的样本空间得到的实际数值还是不一样,但这件事发生的概率在人们心里“是大还是小”的人们对它的看法是确定的。这一点的原理其实是“贝特朗奇论”:


明白了样本空间是什么,那么我就要接着来论述一些其他的事情,和解释上面我说的我们都是小概率事件了(关于概率的问题,也是一个让人兴奋的点,我有机会也会在后续的文章中谈论概率的话题)。首先来解释我们为什么都是小概率事件,很显然,因为从古至今的人很多,而“恰好”你是你,那么样本空间就是就是从古至今所有人的总和,你只有独一无二的一个。那么接下来我想谈论的是一些基于这一个事实给出的一些看法。我们知道活着是一个小概率事件,因为从古至今所有人做样本空间的话活着只是偶然,活着的人无论权力低位的高低,不一定是有着伟大观念的人,这也就是为什么苏格拉底在被众人的偏见诬陷被判处死刑后说“我去死,你们去生,孰好孰坏只有神知道。”的原因。
那既然我说人生没有意义为什么我还活着,我没有去死呢?提出这种问题的人其实你也没什么别的想法,就是单纯的坏,不过我也可以给出逻辑自洽的回答。首先是因为我活着没有意义,上面已经论述了,我死了很显然人人都知道更没有意义,那两者都是没有意义的事情,我死了对我自己没有任何好处,而对我的竞争对手来说他们巴不得我死,也就是说对我的竞争对手来说我的死对他们有好处,而这是我不愿看到的,所以我选择活着,这是我活着的原因之一,另外就是由于我的经历,我原本是要进入士官队伍的,但那不是我想要的生活,我在上这类学校的时候我的独立人格的发展就愈发强烈,因为我现在升学,我感觉我的时间都是“借”来的,如果我进去了,我在里面也必须要背诵条令条例,我的想法是,我把时间花在背这些仅仅只有这个一个用场景才用得到的东西,我倒不如把时间花在背英语单词上!花在研究我感兴趣的问题上!这也是我为什么对某些事情那么执着的原因,其实不是执着,就是“与其做不如做”的意思,有些东西我们逃不掉,就比如忍受非理解性背诵的痛苦,比如条令条例,现在换做背英语单词和背别人研究的经常用到的结论,再来看是不是更舒适了?我在那个学校的时候我感觉其他的一切其实都是奢侈的,我经常安慰自己“至少我还能呼吸”。再比如,你可以想一想,我们的一生中有95%的事儿都是我们不能决定的,我们能决定的只有5%,我们不能决定我们的出生,我们不能决定我们的智商,我们不能决定我们一生的贵人相助,我们能够决定的东西很少,而且我们既然活了,那么,活了就活了,我们没有必要花费力气就去为了死,既然要花力气那就不应该为了“对竞争对手好”而花力气,你想也是吧,如果要死,那么我觉得希望是意外决定我们或者生命的长度决定我们,而不是我们自己决定我们,如果到了根据经济学的意义由我们自己决定我们的时候,那将是生命最悲哀的时候,比如战争,再具体一点战败,沦为奴隶。其次我们现在所有活着的人嘴里说的意义其本质上都是经济学意义,都是效率的考量。放眼现在,我们为权力与地位去除人生有本质意义的观念后对它提出的合理解释是,我们观念里所有有价值的一切意义都只有经济学意义,所有的公平都是效率的考量,所有的活动都要考虑成本,从经济学成本与效率对于考试的角度而言,的确,我上面做的工作都是最笨的工作,那些“唯技术主义”“唯应用主义”的人说就应该直接背,不假思索的背,反正应用嘛,没差别,的确,但我想说,这仅仅是第一步,我们永远在路上,如果说你就在这一步永远的停住还孤芳自赏的话你就会进入“唯技术主义陷阱”从而进入“35岁定律”,你也知道我们最终的目标是用最低的成本创造最高的利润,而不是孤芳自赏,这就让我们必然要涉猎经济学领域,明白的不仅仅是我们研究学习的学科以内的知识,而社会的原理看上去比技术的精进是更重要的,所以我们不能进入“唯技术主义陷阱”,我们应当不断地接受新的认知,承认自己的无知乃是开启智慧的大门,有知识的人很多,而有知识仅仅停留在有知识的这一步,还孤芳自赏,那就永远无法拥有大智慧,就像苏格拉底所说“我唯一知道的就是我自己的无知”。我想对于一些让你兴奋的事又碰上了这样一种“恰好”,人只活一次,我们就是活着的过程就是见证一次次的“恰好”的过程,勇敢去追寻,勇敢也是我们人生的一大命题,勇敢去做,失败了就失败了,我去实现这一个案例也是会有可能失败的,中途当然经历一波三折,因为工程经验总结中不是用这个方法去实现的,正是因为人生本质上没有什么意义,所以失败并没有什么,人最大的痛苦莫过于跨越知道和做到的鸿沟,其实这时候趁热打铁是再好不过的,对于应用的确先不要忙深究底层,只有有兴趣,有“恰好”,你自然就会水到渠成的理顺应用背后的逻辑。
这个案例用素因数求lcm的结果没有任何意义,因为对于结果而言,我们在应用的时候肯定是以gcd和最简算法优先(上面已经阐释过原理),有意义的是这其中“确定素因式的过程”、“去除数组中重复元素的基础算法”、“整体干净整洁的仅仅用素因数分解算法的最终代码”,在解决这个案例的过程之中我加深了对求交集求并集求差集的理解(在中间过程中思考过,但每次都止步于我自己之前写的删除数组重复元素的算法,就是因为没有对循环变量j--,绕了好多弯路(比如用求交集算法),还考虑用得到素因数数组有顺序的性质去解决等等),但这些弯路对我学“去重”算法的时候就不仅仅是“记忆j--”这么简单了,而是我花费的时间和血的教训。
另外,因为学校课程比较紧迫,我以上的所有算法我暂时没有考虑时间和空间复杂度,如果有感兴趣而且有想法的朋友私信我,让我们共同精进我们的算法之路!
2022.10.31:更新质因子分解的优化算法
如有问题欢迎随时与我沟通。















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









