







 文章介绍了一种新的wildNeRF模型,通过自监督学习,能在几分钟内处理动态和静态场景的视图合成,区分静态和动态像素,从稀疏图像中生成高质量表示。实验结果表明,该方法在NVIDIA动态场景和复杂手术数据集上表现出色,提升了神经辐射技术的效率和适用性。
文章介绍了一种新的wildNeRF模型,通过自监督学习,能在几分钟内处理动态和静态场景的视图合成,区分静态和动态像素,从稀疏图像中生成高质量表示。实验结果表明,该方法在NVIDIA动态场景和复杂手术数据集上表现出色,提升了神经辐射技术的效率和适用性。
wildNeRF: Complete view synthesis of in-the-wild dynamic scenes captured using sparse monocular data( 使用稀疏单目数据捕获的野外动态场景的完整视图合成)
Abstract
提出了一种新的神经辐射模型,该模型可以用自监督的方式进行训练,用于动态非结构化场景的新视角合成。我们的端到端可训练算法学习高度复杂,真实世界的静态场景在几秒钟内和动态场景与刚性和非刚性运动在几分钟内。通过区分静态像素和以运动为中心的像素,我们从稀疏的图像集合中创建高质量的表示。我们对现有的基准进行了广泛的定性和定量评估,并在具有挑战性的 NVIDIA 动态场景数据集上设置了最先进的性能测量方法。此外,我们评估我们的模型在具有挑战性的现实世界数据集,如胆固醇80和手术行动160的性能。
3.Method
我们介绍了 WildNERF,一个计算效率高的神经渲染器,用于新的视图和时间合成任务。从使用单目摄像机源捕获的稀疏输入中提出的渲染器重建复杂的场景。我们建立在先前基于流的和基于变形的方法的基础上,使用计算有效的网格嵌入对动态场景进行建模。这些方法通过模拟场景中物体几何形状随时间的变化来扩展传统的神经辐射表示。这可以产生具有不同几何形状和复杂动态的复杂场景的高保真重建。我们举例说明,变形技术和基于流的技术相结合,能够在新视角和新时间合成任务的不失一般性下,以整体的方式捕捉场景。我们利用现成的预先训练的模型来产生流量和深度先验 ,以限制规范的重建空间,导致高质量的重建。我们还利用有效的网格编码在现有模型的一小部分时间内产生结果。
3.1. Datasets
在本文中,我们展示了 NVIDIA 动态场景数据集的定量和定性结果,以及复杂手术数据集 Cholec80和 SugicalActions160的定性结果(由于缺乏地面真相深度数据) ,这些数据处理摄像机和场景中的物体之间显着的非结构化运动。
NVIDIA Dynamic Scenes Dataset:
这个数据集由8个场景组成,每个场景用12个同步摄像机来模拟运动。在每种情况下,从数据集中拿出24帧用于训练,12帧用于测试
Cholec80:
该数据集包含80个捕捉胆囊切除术过程的全长手术视频。现有的神经辐射场方法的范围是有限的,因为它们只能模拟由一小组帧组成的非常受限的场景。因此,我们将重点放在从较长视频中提取的短片上,以评估这些方法在极端自由环境中的效果。
SurgicalActions160:
这个数据集包括总共160个短剪辑(something 5秒) ,其中外科医生执行关键行动,如缝合,解剖和打结。
3.2. Scene registration
为了完全了解一个场景,我们需要相对摄像机的姿势信息沿着图像坐标作为输入。从一组稀疏的图像中提取这些信息称为“Scene registration(场景配准)”,场景中的特征结构被用来生成组成图像的相对姿态特征,这是计算机视觉和视知觉中一个被广泛研究的问题,称为“运动中的结构(structure-from-motion.)”。为此,我们使用 COLMAP ,一个开源的动态结构库。
3.3. Volume rendering
3.4. Pixel pruning(像素修剪)
传统的方法使用策略性地设计的粗和精细的附加光线采样时间表来计算彩色像素值。我们的方法受到基于体素模型的有效训练方法的最新进展的启发,其中我们在空间中系统地关闭点,这些关闭点在固定数量的迭代中不会对我们的场景做出贡献。在这样做时,我们大大减少了下游计算中所需的矩阵操作的数量。在 N = 5000次迭代之后,我们继续优化图像中最有代表性的像素。我们在图4中说明了我们的方法
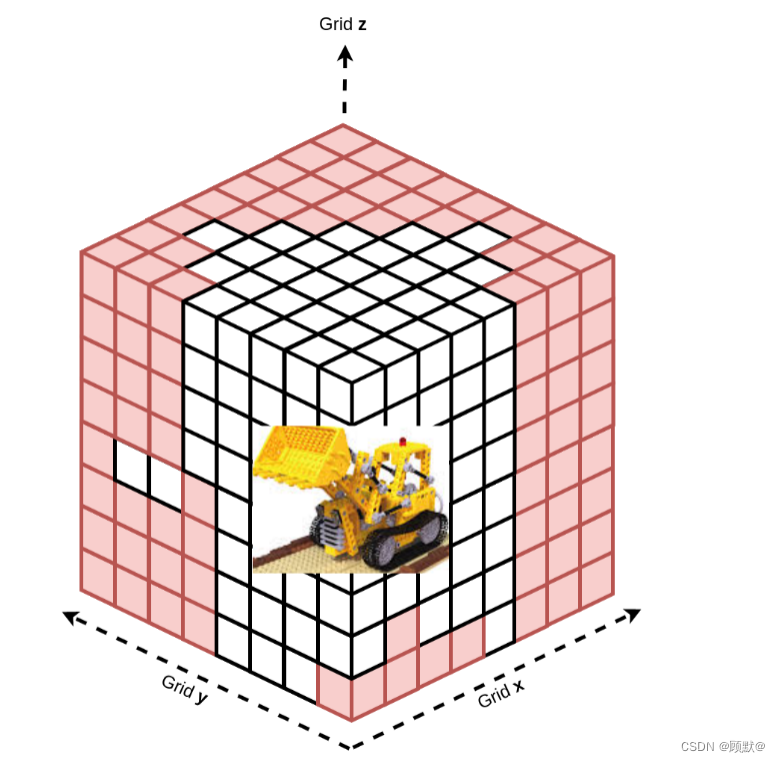
图4:像素修剪过程说明。在模型的最初几次迭代中,我们网格上的任何红色像素都被排除在分析之外。
3.5. Model architecture(模型架构)
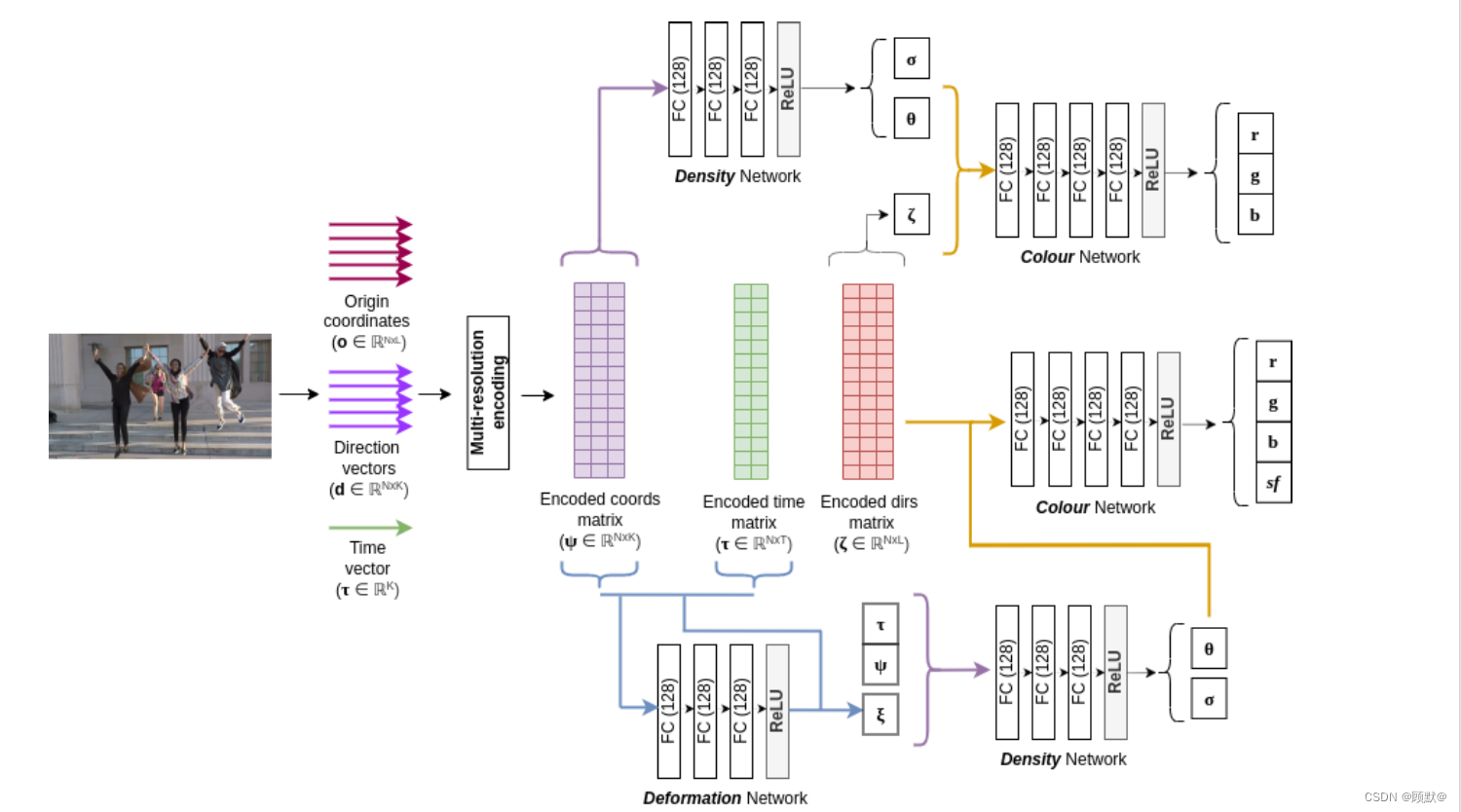
我们提出的渲染器包括3个核心轻量级完全连接的模型,一个预测场景流的流模型,一个模型从一个框架到下一个框架的非刚体动力学建模的变形模型,以及一个背景模型,是不可知的任何运动中心像素在场景中。我们在图3中演示了两个预测输出,以及如何使用它们以端到端的方式训练模型。
3.5.1 Background Network
我们使用传统的基于辐射度的隐式表示模型对场景中与刚体相关的像素进行建模。
3.5.2 Deformation network
我们通过定义一个变换,来建立跨框架的非刚体运动模型。这个变换可以应用于规范空间中不同时间点的运动。这种变形,φ,结合基于流动的刚体运动建模允许我们改进现有的最先进的结果在 NVIDIA 动态场景数据集。这种转换是通过最小化整个数据集的均方差来实现的。
3.5.3 Scene-flow network
当试图使用全光学函数来建立一个大型变量集时,场景变得越来越不受约束。我们通过利用光度约束来模拟场景中动态像素的刚体运动来解决这些异常现象。我们模型的流场非刚性运动跨越相邻框架在两个向前(tc = t + 1)和向后(tc = t-1)的方向(图5)。
图5。由场景流模型生成的跨帧预测流。这些预测,连同现成的刚体流估计,有助于约束我们极其欠受约束的场景。
3.5.4 Blending approach
我们的混合方法利用在预处理步骤中生成的现成的运动掩模,并根据掩模值分配像素级值。这种混合方法很简单,不需要额外的网络来建模背景像素。它还避免了在其他网络输出之外计算的混合参数。
5. Conclusion
提出了一种新的基于神经辐射的方法,通过对刚体和非刚体运动分别建模,从稀疏输入合成场景。这种方法加上多分辨率哈希编码网格,在 NVIDIA 动态场景数据集上产生最先进的结果,同时比现有方法快得多。我们也从理想化的环境和数据集中移开,展示了我们的方法在复杂的真实场景中的有效性,例如外科手术160和胆囊80数据集。我们希望我们的工作能够使基于神经辐射的技术得到广泛的应用,并使我们的源代码公开可用















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









