






目录
AI大模型事先训练时用的数据集里缺少最新动态信息、个人或企业私有数据等,有时会一本正经地“胡说八道”,而通过外挂即时数据库、私有知识库、参考文档等可以有效缓解。基于此,大模型的RAG(Retrieval-Augmented Generation,检索增强生成)技术迅速崛起,成为有效破解这一难题的主流解决方案。
所以RAG相当于告诉大模型一些额外的知识,让他更好的理解这个问题,大模型的能力并没有提升,但是了解到东西更多了。
标准的 RAG 流程简介:将文本分块,然后使用一些 Transformer Encoder 模型将这些块嵌入到向量中,将所有向量放入索引中,最后创建一个 LLM 提示,告诉模型根据搜索步骤中找到的上下文回答用户的查询。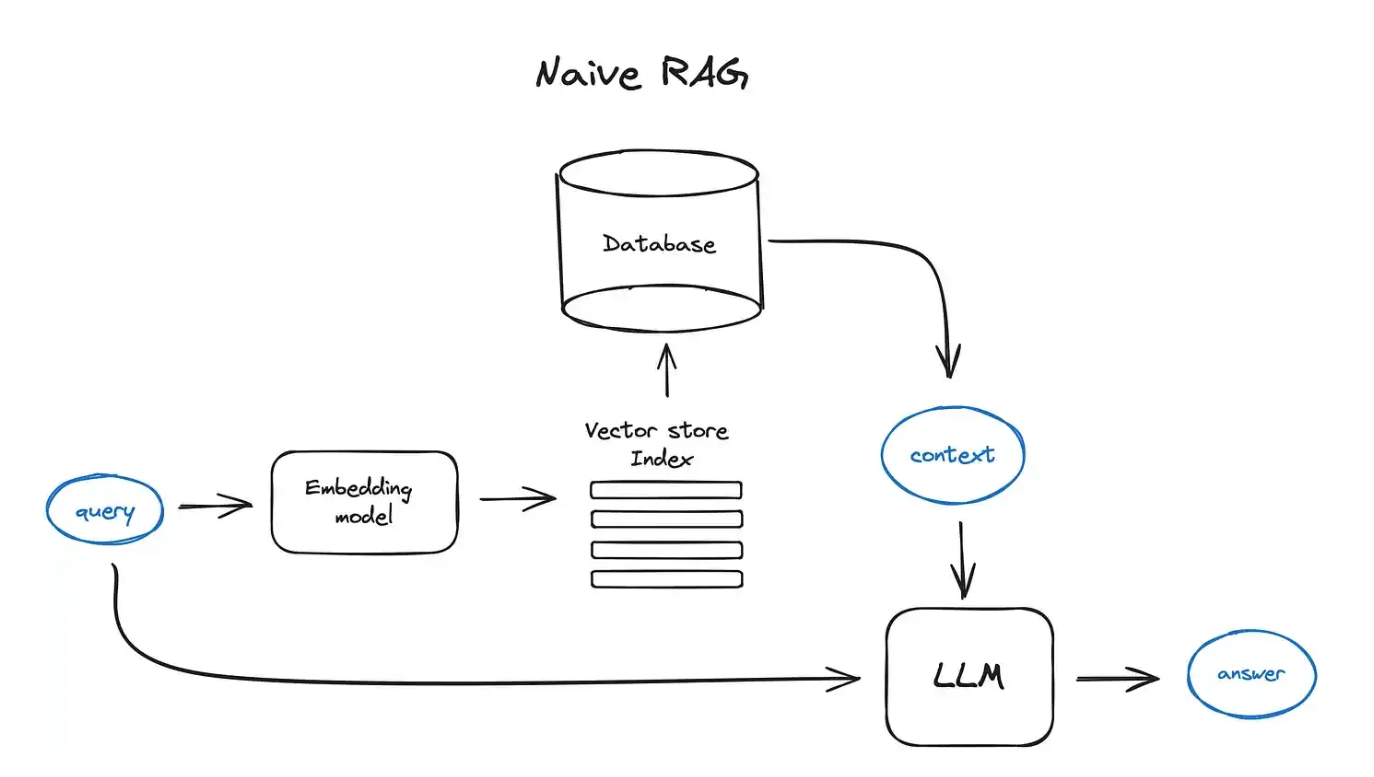
在运行时,通过使用同一编码器模型对用户的查询进行向量化,然后搜索该查询向量的索引,找到 top-k 个结果,从数据库中检索相应的文本块,并将它们作为上下文输入到 LLM 提示中。
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。我这里并没有引入向量数据库,只使用了比较简单的一些文本数据。
分享一些相关的资料
使用 Gemini Pro 构建一个利用多模态 RAG 的问答应用
——谷歌的大模型应用
luhengshiwo/LLMForEverybody: 每个人都能看懂的大模型知识分享,LLMs春/秋招大模型面试前必看,让你和面试官侃侃而谈
——大模型知识
——ModelScope模型库,里面有多种嵌入模型
使用LlamaIndex构建百炼RAG应用_大模型服务平台百炼(Model Studio)-阿里云帮助中心
————阿里云官网给的调用百炼平台的代码,较简单RAG,不需要手写很多方法
1、文本段落分割
首先对于原始pdf文本进行切割,利用pdfminer库工具,提取每一页内部的文本:
from pdfminer.layout import LTTextContainer #pdf页面上的一个文本容器
from pdfminer.high_level import extract_pages #pdf文档提取页面信息的工具
#1、切割文本——需要恰当的切割文本
#定义一个从pdf中提取文本的函数
def extract_text_from_pdf(filename,page_numbers=None,min_line_length=0):
"""filename:PDF 文件的路径。
page_numbers:要提取的页码列表(比如 [0,2,5]),如果是 None,就处理所有页面。
min_line_length:行的最小长度,太短的行(比如长度为 0 的空行)可以过滤掉。"""
paragraphs = []
buffer='' #用于临时拼接同一段落的多行内容。
full_text = '' #保存整页(或多页)PDF中提取出的原始文本
#提取全部文本
for i,page_layout in enumerate(extract_pages(filename)): #i页码,page_layout(页面结构)
if page_numbers is not None and i not in page_numbers: #如果指定了页码,且当前页码不在指定的页码列表中,则跳过该页
continue
#layout是一个LTPage对象,其中包含了这个page解析出的各种对象,如LTTextBox、LTFigure、LTImage和LTTextBoxHorizontal等。
for element in page_layout:
if isinstance(element, LTTextContainer): #isinstance用于判断一个对象是否是一个已知的类型
full_text += element.get_text()+'\n' #从每一页的element提取文本,加上换行,添加到full_text中
#按照空行分割,将文本重新组织成为段落
lines= full_text.split('\n') #每一行分出来,变成一个列表
for text in lines: #遍历lines列表
if len(text) > min_line_length: #该行的字符长度 大于 这一行的最小长度
buffer += (' '+text) if not text.endswith('-') else text.strip('-') #如果每一行末尾不是-,在这一行前面加一个空格;如果是-,就去掉-,并将这一行添加到buffer中
elif buffer: #如果buffer不是空并且当前行长度小于最小长度
paragraphs.append(buffer) #将buffer加到段落里面
buffer = '' #清空buffer,准备下一个段落
if buffer:
paragraphs.append(buffer) #如果buffer不为空,说明还有一段没有添加到段落里面
return paragraphs
paragraph = extract_text_from_pdf('/home/zqy/A_DDUP/Rag/day1/RAG-Embeddings/llama2_page8.pdf',min_line_length=10)
for para in paragraph[:4]: #前四段输出
print(para+"\n")2、定义环境,调用大模型的API
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv(), verbose=True) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY或者直接使用api-key导入,这里使用的是通义千问turbo免费的apikey,注册可以申请:
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
# api_key=os.getenv("DASHSCOPE_API_KEY"),
api_key="你注册得到的apikey",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)导入了 python-dotenv 这个库里的两个方法:
-
find_dotenv():去查找项目目录下的.env文件(通常是存放环境变量的文件,比如 API key、数据库密码等)。 -
load_dotenv():把.env文件里的内容加载到环境变量中(也就是os.environ里)。
#2、调用大模型embedding和提示词
from openai import OpenAI
import os
client = OpenAI() #创建一个 连接到OpenAI服务器的对象
def get_completion(prompt, model="gpt-4o"): #输入:提示词、模型选择
'''封装 openai 接口'''
messages = [{"role": "user", "content": prompt}] #信息用 字典 表示:作用(使用者),内容(提示词,也就是输入的问题)
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content如果使用openai的api key:
client.chat.completions.create(...)是调用 OpenAI聊天接口,让模型根据你的prompt生成回答。
详细分解一下:
-
client.chat:表示访问 聊天接口(Chat Completions API)。 -
client.chat.completions:更精确一点,是 聊天补全("completion")——让模型接着你的提示词(prompt)继续说下去。 -
.create(...):创建一次新的聊天请求,向OpenAI服务器发送**“我要让模型生成一段内容”**的请求。
3、建立提示词模板
#3、提示词模板
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
inputs = {}
for k, v in kwargs.items():
if isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n\n'.join(v)
else:
val = v
inputs[k] = val
return prompt_template.format(**inputs)
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
已知信息:
{context} # 检索出来的原始文档
用户问:
{query} # 用户的提问
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""-
遍历传进来的参数;
-
如果是字符串列表,就合成一段大的文本;
-
最后用
.format()方法把整理好的值一键填到 prompt 模板里; -
返回最终可以直接发给大模型的完整 prompt 字符串
其中:
**kwargs 是用来接收不定数量的“键=值”参数的。
👉 它把多出来的命名参数打包成一个**字典(dict)**传给你。
.items() 是字典(dict)的方法。
👉 它把字典里的每一对 键(key) 和 值(value) 拿出来。
👉 返回一个可遍历的对象(叫 dict_items,其实可以直接 for 循环用)。
.join(v) 是字符串(string)的方法。
👉 它用当前这个字符串,把 v 里面的每个元素连接起来。
👉 v 必须是一个可迭代对象(比如列表、元组),而且里面的每个元素都要是字符串。
要整理好每个参数,准备一键 .format() 填充模板。
4、计算余弦相似度、欧氏距离
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧氏距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)
def list2dic(paragraphs):
dict={}
dict["source_sentence"]=paragraphs
return dict
def get_embeddings(inputs):
'''封装 ModelScope 的 Embedding 模型接口'''
# 当输入包含“soure_sentence”与“sentences_to_compare”时,会输出source_sentence中首个句子与sentences_to_compare中每个句子的向量表示,以及source_sentence中首个句子与sentences_to_compare中每个句子的相似度。
result = pipeline_se(input=inputs)
embeddings = result['text_embedding']
return embeddings
get_embeddings 表示你想用的是Embedding接口(不是聊天接口,也不是图像接口,是专门做向量生成的接口!)。
这里使用modelscope网站的一个嵌入模型。将一段文本转化为一个1024维度的向量。
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Query与自己的余弦距离: {:.2f}".format(cos_sim(query_vec, query_vec)))
print("Query与Documents的余弦距离:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print()
print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec)))
print("Query与Documents的欧氏距离:")
for vec in doc_vecs:
print(l2(query_vec, vec))
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": final_prompt},
],
# Qwen3模型通过enable_thinking参数控制思考过程(开源版默认True,商业版默认False)
# 使用Qwen3开源版模型时,若未启用流式输出,请将下行取消注释,否则会报错
# extra_body={"enable_thinking": False},
)
output=completion.model_dump_json()
# 解析 JSON 字符串为 Python 字典
data_dict = json.loads(output)
#取出你想要的回答内容
answer = data_dict['choices'][0]['message']['content']
print("回答内容:", answer)5、主函数如下所示
# from google import genai
from openai import OpenAI
from pdfminer.layout import LTTextContainer #pdf页面上的一个文本容器
from pdfminer.high_level import extract_pages #pdf文档提取页面信息的工具
from tool_cutting import extract_text_from_pdf,list2dic,get_embeddings,cos_sim,build_prompt
import json
#1、切割文本——需要恰当的切割文本
#定义一个从pdf中提取文本的函数
paragraph = extract_text_from_pdf('llama2.pdf',min_line_length=10)
paragraph_dict=list2dic(paragraph)
print(paragraph)
#2、转为embedding
out_embed=get_embeddings(paragraph_dict)
user_query = {"source_sentence":["llama2 参数是什么?"]}
query_embed=get_embeddings(user_query)
#3、余弦相似度计算 高相似度 的文本
cos_high_sim=[]
index=0
for i in out_embed:
cos=cos_sim(query_embed,i)
if cos>0.6:
cos_high_sim.append(paragraph[index])
index+=1
#4、把高相似度文本加到提示词模板
#提示词模板
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
已知信息:
{context}
用户问:
{query}
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""
final_prompt = build_prompt(
prompt_template,
context=cos_high_sim,
query="llama2 参数是什么?"
)
print(final_prompt)
#5、加载api key,连接到大模型输入问题
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
# api_key=os.getenv("DASHSCOPE_API_KEY"),
api_key="你的apikey",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": final_prompt},
],
# Qwen3模型通过enable_thinking参数控制思考过程(开源版默认True,商业版默认False)
# 使用Qwen3开源版模型时,若未启用流式输出,请将下行取消注释,否则会报错
# extra_body={"enable_thinking": False},
)
output=completion.model_dump_json()
# 解析 JSON 字符串为 Python 字典
data_dict = json.loads(output)
#取出你想要的回答内容
answer = data_dict['choices'][0]['message']['content']
print("回答内容:", answer)
思考:写代码之前想好分为哪几个步骤,最好能够写下来,再一步步实现,其中还要知道每一阶段输出的数据类型是什么,应该用什么方式对它进行处理,过程中还要查找不了解的相关函数的知识。一定不能乱糟糟地看。一些论文图要看明白,不可囫囵吞枣~
——小狗照亮每一天
20250430



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









