模型结构
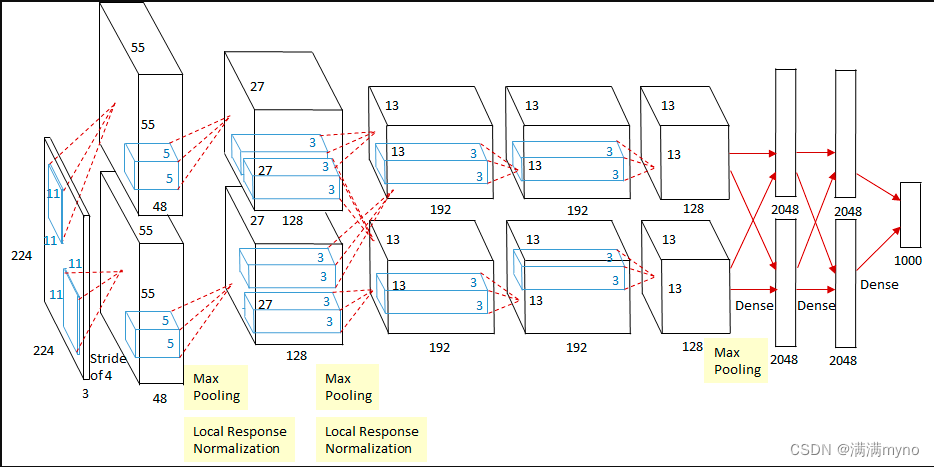
模型解读
conv1 阶段 DFD(data flow diagram):
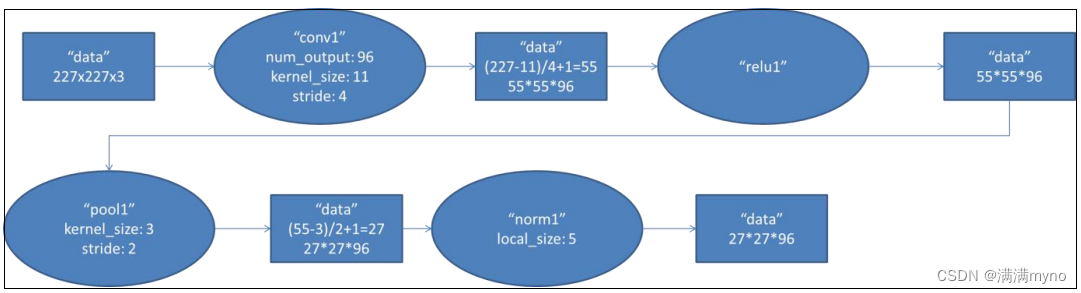
第一层输入数据为原始的 227*227*3 的图像,这个图像被 11*11*3 的卷积核进行卷积运算,卷积核对原始图像的每次卷积都生成一个新的像素。卷积核沿原始图像的 x 轴方向和 y 轴方向两个方向移动,移动的步长是 4 个像素。因此,卷积核在移动的过程中会生成(227-11)/4+1=55个像素(227 个像素减去 11,正好是 54,即生成 54 个像素,再加上被减去的 11 也对应生成一个像素),行和列的 55*55 个像素形成对原始图像卷积之后的像素层。共有 96 个卷积核,会生成 55*55*96 个卷积后的像素层。96 个卷积核分成 2 组,每组 48 个卷积核。对应生成 2 组55*55*48 的卷积后的像素层数据。这些像素层经过 relu1 单元的处理,生成激活像素层,尺寸仍为 2 组 55*55*48 的像素层数据。 这些像素层经过 pool 运算(池化运算)的处理,池化运算的尺度为 3*3,运算的步长为 2,则池化后图像的尺寸为(55-3)/2+1=27。 即池化后像素的规模为 27*27*96;然后经过归一化处理,归一化运算的尺度为 5*5;第一卷积层运算结束后形成的像素层的规模为 27*27*96。分别对应 96 个卷积核所运算形成。这 96 层像素层分为 2 组,每组 48 个像素层,每组在一个独立的 GPU 上进行运算。 反向传播时,每个卷积核对应一个偏差值。即第一层的 96 个卷积核对应上层输入的 96 个偏差值。
conv2 阶段 DFD(data flow diagram):
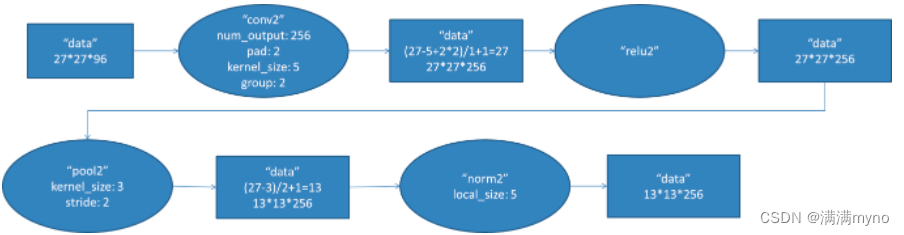
第二层输入数据为第一层输出的 27*27*96 的像素层,为便于后续处理,每幅像素层的左右两边和上下两边都要填充 2 个像素;27*27*96 的像素数据分成 27*27*48 的两组像素数据,两组数据分别再两个不同的 GPU 中进行运算。每组像素数据被 5*5*48 的卷积核进行卷积运算,卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿原始图像的 x 轴方向和 y 轴方向两个方向移动, 移动的步长是1个像素 。因此 ,卷积核在移 动 的 过 程 中 会 生 成 (27-5+2*2)/1+1=27 个像素。27 个像素减去 5,正好是 22,在加上上下、左右各填充的 2 个像素,即生成 26 个像素,再加上被减去的 5 也对应生成一个像素),行和列的 27*27 个像素形成对原始图像卷积之后的像素层。共有 256 个 5*5*48 卷积核;这 256 个卷积核分成两组,每组针对一个 GPU 中的 27*27*48 的像素进行卷积运算。会生成两组 27*27*128 个卷积后的像素层。这些像素层经过 relu2 单元的处理,生成激活像素层,尺寸仍为两组 27*27*128 的像素层。
这些像素层经过 pool 运算(池化运算)的处理,池化运算的尺度为 3*3,运算的步长为 2,则池化后图像的尺寸为(57-3)/2+1=13。 即池化后像素的规模为 2 组 13*13*128 的像素层;然后经过归一化处理,归一化运算的尺度为 5*5;第二卷积层运算结束后形成的像素层的规模为2 组 13*13*128 的像素层。分别对应 2 组 128 个卷积核所运算形成。每组在一个 GPU 上进行运算。即共 256 个卷积核,共 2 个 GPU 进行运算。
反向传播时,每个卷积核对应一个偏差值。即第一层的 96 个卷积核对应上层输入的 256个偏差值。
conv3 阶段 DFD(data flow diagram):

第三层输入数据为第二层输出的
2
组
13*13*128
的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充 1
个像素;
2
组像素层数据都被送至
2
个不同的
GPU
中进行运算。每个 GPU
中都有
192
个卷积核,每个卷积核的尺寸是
3*3*256
。因此,每个
GPU
中的卷积核都能对 2
组
13*13*128
的像素层的所有数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿像素层数据的 x
轴方向和
y
轴方向两个方向移动,移动的步长是
1个像素。因此,运算后的卷积核的尺寸为(13-3+1*2)/1+1=13
(
13
个像素减去
3
,正好是
10
,在加上上下、左右各填充的 1
个像素,即生成
12
个像素,再加上被减去的
3
也对应生成一个像素),每个 GPU
中共
13*13*192
个卷积核。
2
个
GPU
中共
13*13*384
个卷积后的像素层。这些像素层经过 relu3
单元的处理,生成激活像素层,尺寸仍为
2
组
13*13*192
像素层,共13*13*384 个像素层。
conv4 阶段 DFD(data flow diagram):

第四层输入数据为第三层输出的
2
组
13*13*192
的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充 1
个像素;
2
组像素层数据都被送至
2
个不同的
GPU
中进行运算。每个 GPU
中都有
192
个卷积核,每个卷积核的尺寸是
3*3*192
。因此,每个
GPU
中的卷积核能对 1
组
13*13*192
的像素层的数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿像素层数据的 x
轴方向和
y
轴方向两个方向移动,移动的步长是
1
个像素。因此,运算后的卷积核的尺寸为(13-3+1*2)/1+1=13
(
13
个像素减去
3
,正好是
10
,在加上上下、左右各填充的 1
个像素,即生成
12
个像素,再加上被减去的
3
也对应生成一个像素),每个 GPU
中共
13*13*192
个卷积核。
2
个
GPU
中共
13*13*384
个卷积后的像素层。这些像素层经过 relu4
单元的处理,生成激活像素层,尺寸仍为
2
组
13*13*192
像素层,共
13*13*384
个像素层。
conv5 阶段 DFD(data flow diagram):
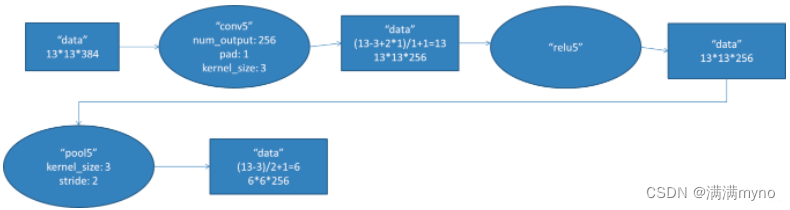
第五层输入数据为第四层输出的2组13*13*192的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有128个卷积核,每个卷积核的尺寸是3*3*192。因此,每个GPU中的卷积核能对1组13*13*192的像素层的数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿像素层数据的x轴方向和y轴方向两个方向移动,移动的步长是1个像素。因此,运算后的卷积核的尺寸为(13-3+1*2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU中共13*13*128个卷积核。2个GPU中共13*13*256个卷积后的像素层。这些像素层经过relu5单元的处理,生成激活像素层,尺寸仍为2组13*13*128像素层,共13*13*256个像素层。
2组13*13*128像素层分别在2个不同GPU中进行池化(pool)运算处理。池化运算的尺度为3*3,运算的步长为2,则池化后图像的尺寸为(13-3)/2+1=6。 即池化后像素的规模为两组6*6*128的像素层数据,共6*6*256规模的像素层数据。
fc6 阶段 DFD(data flow diagram):
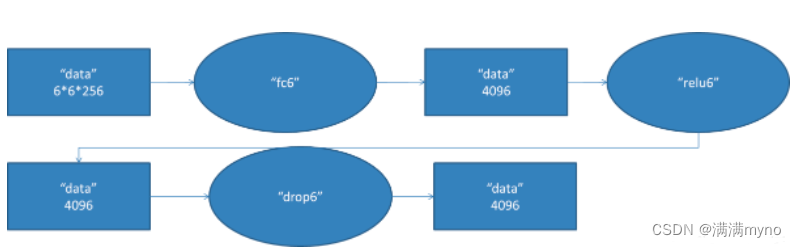
第六层输入数据的尺寸是6*6*256,采用6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算;每个6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6*6*256尺寸的滤波器对输入数据进行卷积运算,通过4096个神经元输出运算结果;这4096个运算结果通过relu激活函数生成4096个值;并通过drop运算后输出4096个本层的输出结果值。
由于第六层的运算过程中,采用的滤波器的尺寸(6*6*256)与待处理的feature map的尺寸(6*6*256)相同,即滤波器中的每个系数只与feature map中的一个像素值相乘;而其它卷积层中,每个滤波器的系数都会与多个feature map中像素值相乘;因此,将第六层称为全连接层。
第五层输出的6*6*256规模的像素层数据与第六层的4096个神经元进行全连接,然后经由relu6进行处理后生成4096个数据,再经过dropout6处理后输出4096个数据。
fc7 阶段 DFD(data flow diagram):
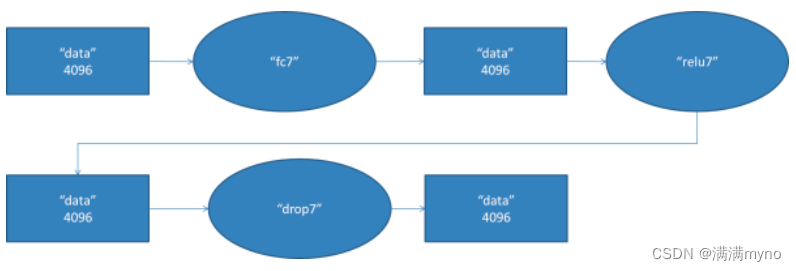
第六层输出的
4096
个数据与第七层的
4096
个神经元进行全连接,然后经由
relu7
进行处理后生成 4096
个数据,再经过
dropout7
处理后输出
4096
个数据。
fc8 阶段 DFD(data flow diagram):

第七层输出的
4096
个数据与第八层的
1000
个神经元进行全连接,经过训练后输出被训练的数值。
模型特性
使用
ReLU
作为非线性
使用
dropout
技术选择性地忽略训练中的单个神经元,避免模型的过拟合
重叠最大池化(overlapping max pooling),避免平均池化(average pooling)的平均效应
使用
NVIDIA GTX 580 GPU
减少训练时间
当时,
GPU
比
CPU
提供了更多的核心,可以将训练速度提升
10
倍,从而允许使用更大的数据集和更大的图像。
























 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











