







文献信息:[2010.14794] Seen and Unseen emotional style transfer for voice conversion with a new emotional speech dataset 该文提出了DeepEST用于语音情感转换的模型,并且制作并开源了一个中英双语的情感语音数据集ESD,可用于语音情感转换,情感语音TTS等多项任务。
摘要
**情感语音转换(Emotional voice conversion)**的目的是在保留语言内容和说话人音色的同时,对言语中的情感韵律进行转换。
本文基于变分自编码器和生成对抗网络(VAW-GAN)的框架上提出了一个新模型框架DeepEST,该框架利用预训练的**语音情感识别(SER)**模型在训练和运行时推理过程中转移情感风格。通过这种方式,网络能够将可见的和不可见的情感风格转移到新的话语中。
所提出的框架通过持续优于基线框架而取得了显著的性能。本文还标志着用于语音转换的**情感语音数据集(ESD)**的发布,该数据集具有多个speaker和语言。
情感特征分析
情感的特征分析一直是SER的研究重点,比如将语音离散化为包含了情感信息的特征数据上。
我们感兴趣的是使用深度情感特征进行语音转换,在连续空间中描述情感韵律。其思路是利用参考语音的深层情感特征,将其情感风格转移到输出目标语音中。为了激发这一想法,我们使用t-SNE算法在二维平面上可视化了4名说话者(2男2女)的深层情感特征,如图所示。可以观察到,深层情绪特征在特征分布上形成了清晰的情绪组。
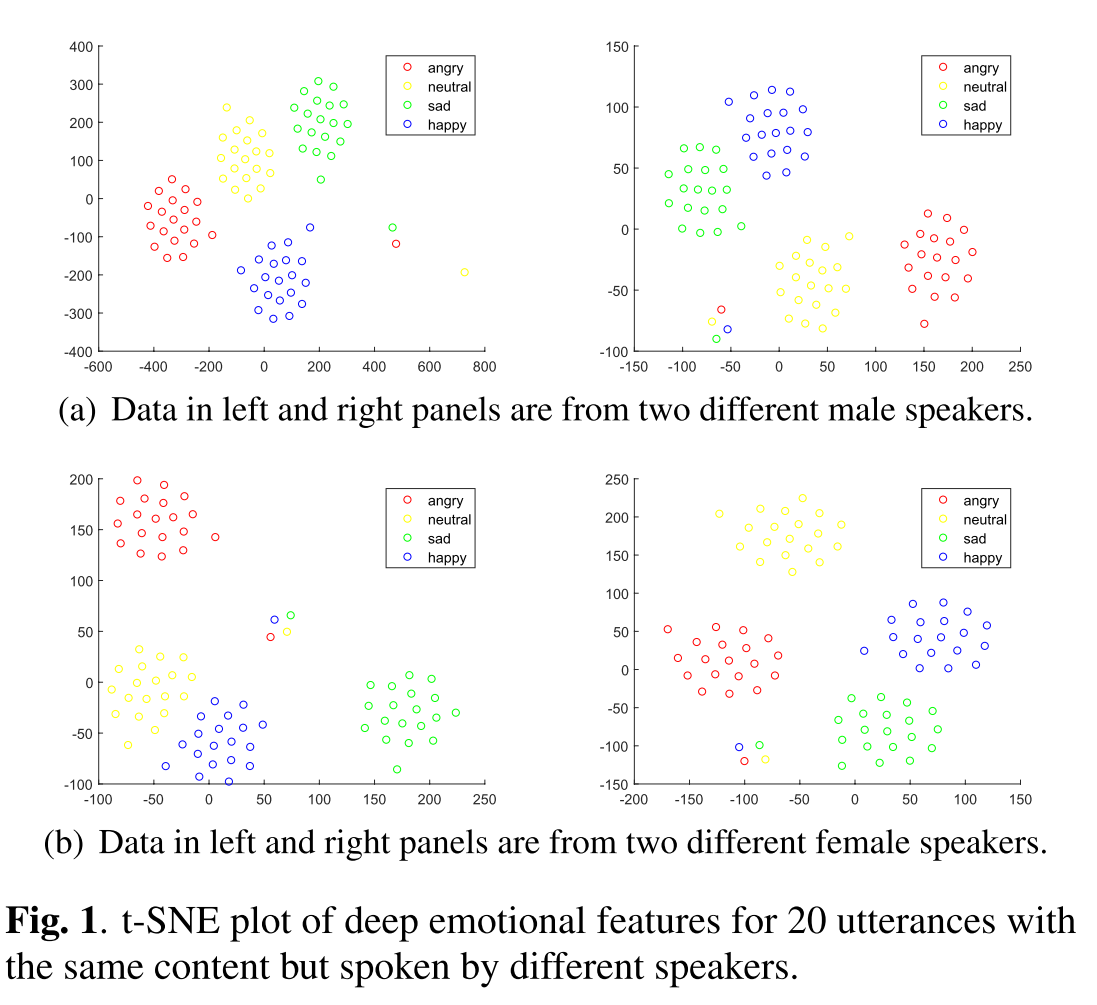
我们可以使用情感特征作为一种风格嵌入来编码一个情感类。在这一结果的驱动下,我们通过深度情感特征提出了一个一对多的情感风格迁移框架。
在语音SER的推动下,本文提出了一种基于VAW-GAN的一对多情感风格迁移框架模型,该模型利用了深层情感特征的条件解码器。被称为deepEST。
deepEST
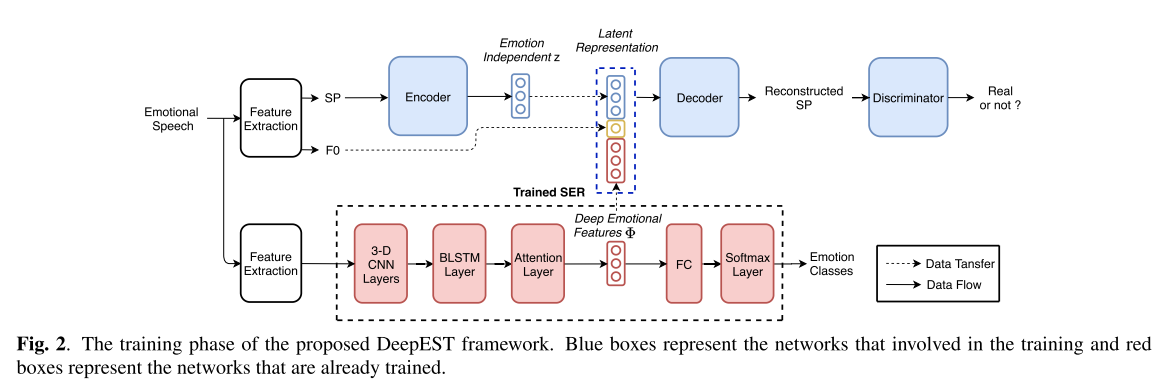
情感描述模块
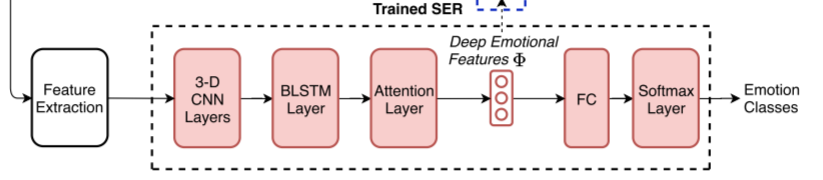
议使用SER模型作为情感描述D,功能是从输入话语X提取深层情感特征Φ,即Φ= D(X)。
SER架构,包括:
- 1)一个三维(3-D) CNN层;
- 2)BLSTM层;
- 3)注意层;
- 4)全连接(FC)层.
3-D CNN首先将具有delta和delta-delta特征的输入Mel-spectrum投影成固定大小的潜在表示,在保留有效情感信息的同时减少情感无关因素的影响。然后,为了进行情感预测,下面的BLSTM和注意力层总结前一层的时间信息,并产生区分的句子级特征Φ。
这个SER模块就是对输入的句子进行情感分类,同时在中间提取出句子级的向量表示。
VAW-GAN
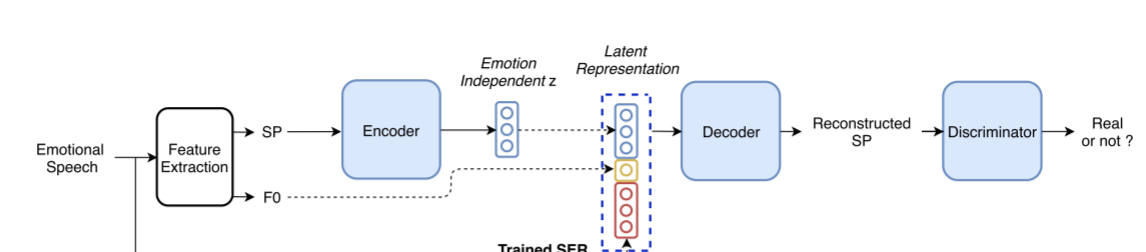
与传统的VAW-GAN流程不同,deepEST提出了一种编码器-解码器训练过程.
如图所示,其中编码器(E)学习从输入特征中去除情感元素,并生成一个潜在表征z。假设得到的表征z包含语音和说话人信息,但与情感无关。然后,解码器/生成器(G)学习用与情绪无关的表示z和其他可控的情绪相关属性(从情感描述模块得到)重建输入特征。
训练
使用WORLD声码器从波形中提取频谱特征(SP)和基频(F0)。编码器(Eθ)暴露于具有不同情绪类型的输入梅尔频谱帧x中,并学习一个与情绪无关的表示z: z =Eθ(x)。由于从源频谱中提取的潜在表示z仍然包含源F0信息,并且转换性能可能会受到这个缺陷的影响。因此,参数集为ψ的解码器/生成器(Gψ)取与情绪无关的表示z和与情绪相关的特征:反映阶段I输入话语X的全局情感方差的深层情感特征Φ和对应的包含源音高信息的F0,以重新组合频谱的情感元素。
重构特征x可表示为
x
‾
=
G
ψ
(
z
,
Φ
t
,
F
^
0
)
=
G
ψ
(
E
θ
(
x
)
,
D
(
X
)
,
F
0
)
\overline x = G_ψ(z, Φ_t, \hat F_0) = G_ψ(E_θ(x),D(X), F_0)
x=Gψ(z,Φt,F^0)=Gψ(Eθ(x),D(X),F0)
然后,通过对抗性训练训练频谱的生成模型:参数集µ的鉴别器(Yµ)试图最大化真实特征x和重构特征x之间的损失,而生成器(Gψ)试图最小化它。参数集θ、ψ和µ通过这个最小-最大博弈(min-max
game)得到优化,这使我们能够生成高质量的语音样本。
推理时转换
任务:在运行时转换期间,我们有一个以中性情绪表达的源话语,我们希望将其转换为遵循参考话语中的参考情绪风格的目标情感。
假设我们有一组属于某个情绪类别的参考话语
X
t
X_t
Xt。我们首先使用预训练的SER生成所有参考话语的深层情感特征
Φ
t
=
m
e
a
n
(
D
(
X
t
)
)
Φ_t=mean(D(X_t))
Φt=mean(D(Xt)),即我们数据集中具有相同参考情感的所有话语。然后,我们将Φt与转换后的
F
0
(
F
^
0
)
F_0(\hat F_0)
F0(F^0)和来自源话语的与情绪无关的z连接起来,构成目标话语梅尔谱(SP)的潜在表示。转换后的SP可以表示为:
x
^
=
G
ψ
(
z
,
Φ
t
,
F
^
0
)
=
G
ψ
(
E
θ
(
x
)
,
m
e
a
n
(
D
(
X
t
)
)
,
F
^
0
)
\hat x = G_ψ(z, Φ_t, \hat F_0) = G_ψ(E_θ(x), mean(D(X_t)), \hat F_0)
x^=Gψ(z,Φt,F^0)=Gψ(Eθ(x),mean(D(Xt)),F^0)
结果
实验使用来自ESD数据集的四名英语人士(2男2女)。对于每个说话者,我们进行了从中性到快乐
(N2H:中性到快乐)和从中性到悲伤(N2S:中性到悲伤)的情绪转换。我们选择愤怒作为看不见的情绪,并进行从中性到愤怒(N2A:中性到愤怒)的实验,以评估我们提出的看不见的情绪风格转移模型的性能。

语音数据集(ESD)
在本文中,还引入并公开发布了一个新的多语言、多说话人的情感语音数据集,可用于各种语音合成和语音转换任务。
该数据集由350个平行的话语组成,平均持续时间为2.9秒,由10个母语为英语的人和10个母语为普通话的人。对于每种语言,数据集由5名男性和5名男性组成女性说话者的五种情绪总结如下:1)快乐,2)悲伤,3)中性,4)愤怒,5)惊喜。语音数据以16khz采样,保存为16位。
据文中所知,这是第一个在多语言和多说话人设置中提供情感标签的并行语音转换数据集。作为未来的工作,作者将报告对该数据集进行跨语言和单语言情感语音转换应用的深入调查。
总结
该文提出了一种新的VAW-GAN模型,并引入了语音情感识别过程,能做到一对多的将原语音转换并生成指定情感的语音。同时发布了一个高质量的情感语音数据集,目前像这样的数据集依然稀缺,这对于情感语音TTS任务来说是相当重要的一个数据集,并且能很好的推动情感语音相关研究的发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









