







文献信息:[2106.07447] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units facebook提出的一个用于语音音频的特征提取的泛用模型,模型结构基于Bert,称为HuBert(Hidden-Unit BERT),使用的是自监督的方式。HuBert的出现具有很大的意义和实际价值,在很多优秀的语音识别ASR,语音生成TTS等实际应用项目中,都能看到HuBert的身影。
摘要
自监督的语音特征学习有三个难点:(1)每个句子中有多个声音单元(2)在预训练阶段没有输入声音单元的词典(3)声音单元具有可变长度,难以显式分割。
为了解决这些问题,作者提出了Hidden-unit BERT(HuBERT)。HuBERT使用聚类的方式为BERT中使用的loss提供标签,然后再通过类似BERT的mask式loss让模型在连续的语音数据中学习到数据中的声学和语言模型。
实验证明HuBERT取得了和目前最好的Wav2vec 2.0类似或是更好的效果。
HuBert
语音信号不同于文本和图像,因为它们是连续值序列。语音识别领域的自监督学习面临来自CV和NLP领域的独特挑战。每个输入话语中存在多个声音打破了许多CV预训练方法中使用的实例分类假设。其次,在预训练期间,没有可用的离散声音单元的先验词典,如在使用单词或词条的NLP应用中,这阻碍了预测损失的使用。最后,声音单元之间的边界未知,这使得掩码预测预训练复杂化。
在本文中,引入了Hidden-unit BERT(HuBERT),它受益于离线聚类步骤,为BERT的每次训练生成噪声标签。具体地说,BERT模型使用掩码的连续语音特征来预测预定的聚类分配。预测损失仅应用于掩码区域,迫使模型学习未掩码输入的良好高层表示,以正确推断掩码输入的目标
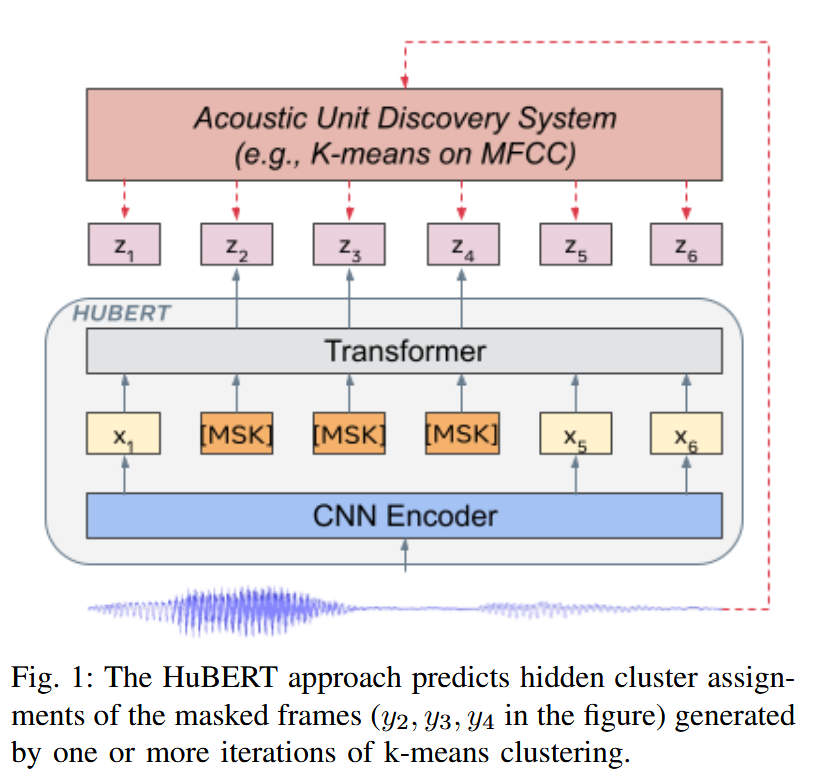
其大致的计算流程为,原始wav通过CNN提取特征,mask之后送入transformer。然后同时wav利用Acoustic unit discovery system得到自监督的label标签。transformer从mask之后的输入x中得到特征表示z,然后计算label和预测z之间的交叉熵损失(只计算mask部分的损失),进行反向传播。
Acoustic unit discovery system
Acoustic unit discovery system这个自监督模块是HuBert的亮点,正是这个自监督模块很好的从wav中提取label标签,才能使transformer的自监督训练可以进行。
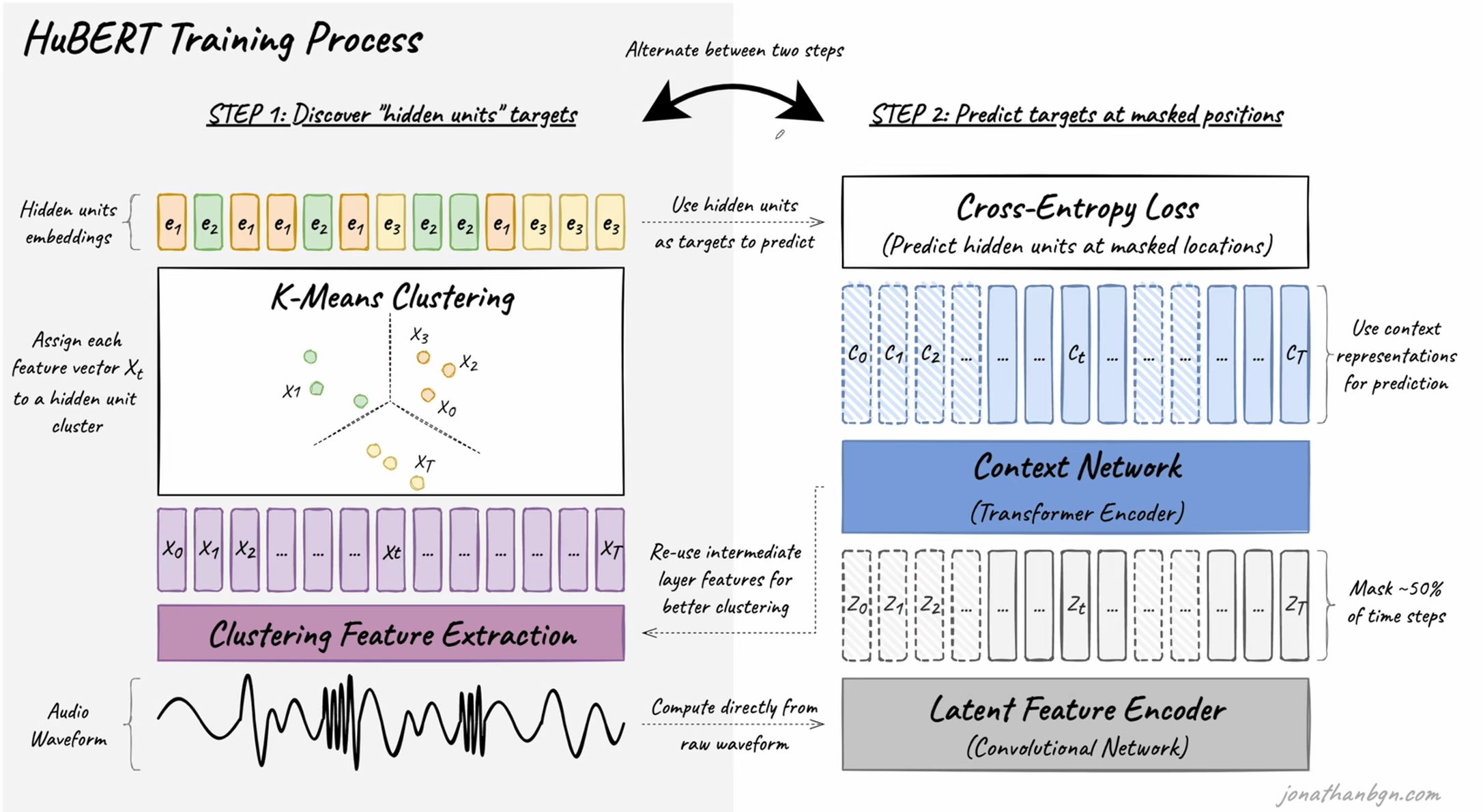
第一次迭代
为了在开始训练之前得到好的标签,文中使用了MFCC(Mel Frequency Cepstral Coefficient)方法。具体是,直接对wav帧进行MFCC得到MFCC特征x,MFCC特征是一种倒谱图,是用来提取语音的音色(timbre)的,音色是区分说话人最有力的特征。因此特征x包含了很多的音色特征。
对特征x进行k-means聚类,这样对于每一个x我们都能赋予其一个聚类中心e,这个e就是第一次迭代使用的自监督标签。
之后的迭代
但是基于MFCC的标签过于粗糙,在学习到一定程度之后,不使用MFCC方式,而是从transformer的中间层(文中说是第9层)中抽取特征向量,替代原先的MFCC特征x。
对x使用k-means聚类,从而学习更好的聚类表示,也就是聚类中心e。
transformer预测和训练
有了足够好的label之后,transformer的训练就很简单了,通过CNN提取wav帧特征之后,mask掉50%的时间步,送入transformer中做上下文预测,预测并重建隐藏单特征c,只对被mask的区域,进行与Acoustic unit discovery system自监督模块得到的label做交叉熵损失,反向传播并训练。
mask掩码策略:论文采用了SpanBERT和wav2vec 2.0中用于掩码生成的相同策略,其中 p% 的时间步长被随机选择为起始索引, l l l个步长的跨度被掩码。
假设M⊂[T]表示要mask的区域, X ~ \tilde X X~表示被mask之后的输入,将在掩码和非掩码时间步长上计算的交叉熵损失分别表示为$ L_m $和 $L_u $。我们定义在mask区域上的cross-entropy loss L m L_m Lm为:
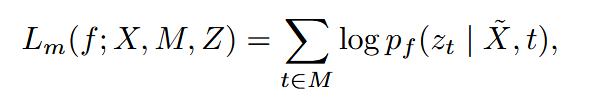
L u L_u Lu和其形式相同,只是它在非mask区域 t∉M 上求和,最终损失计算为两项的加权和
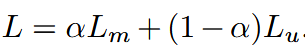
在极端情况下,当 α=0 时,在未掩码的时间步长上计算损失,这类似于混合语音识别系统中的声学建模。在论文的设置中,这将学习过程限制为模仿聚类模型。
在 α=1 的另一个极端情况下,仅在掩码时间步长上计算损失,其中模型必须根据上下文预测与未看到帧对应的目标,类似于语言模型。它迫使模型学习未掩码段的声学表示和语音数据的长程时间结构。论文假设, α=1 的设置对集群目标的质量更具弹性,这在论文的实验中得到了证明。
也就是说设置α=1,只计算mask区域的损失,是会让效果更好的。
结果
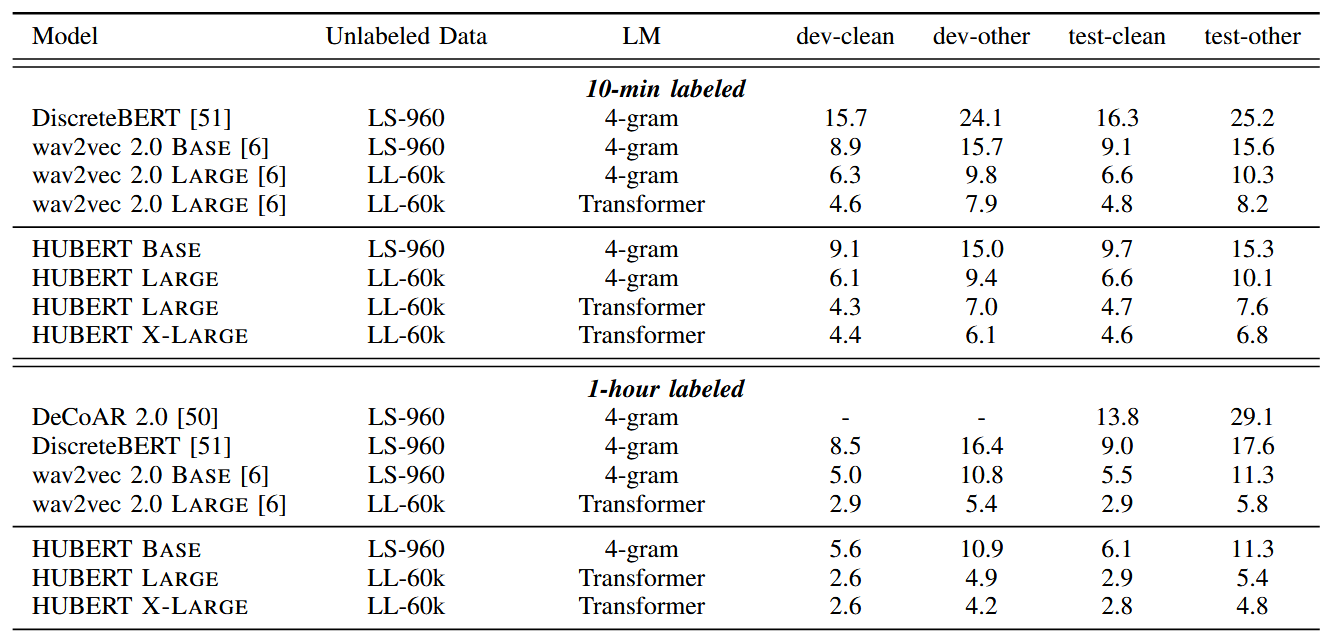
可以看到HuBERT LARGE的表现超过了wav2vec 2.0 LARGE的表现,X-LARGE则进一步提高了表现。
实验
huggingface上HuBert的官方示例
from transformers import AutoProcessor, HubertModel
from datasets import load_dataset
import soundfile as sf
processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
model = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
input_values = processor(ds["speech"][0], return_tensors="pt").input_values # Batch size 1
hidden_states = model(input_values).last_hidden_state
这样就将音频转化为高质量的语音嵌入(768维),包含了说话人的音色特征。这样的语音嵌入对于TTS任务将相当有用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









