







python技术面试题
1、Python中的幂运算
在python中幂运算是由两个 **星号运算的,实例如下:
>>> a = 2 ** 2
>>> a
4
我们可以看到2的平方输出结果为4。
那么 ^指的是什么呢?我们用代码进行演示:
>>> 1 ^ 01
>>> 0 ^ 11
>>> 1 ^ 10
>>> 0 ^ 00
>>> 2 ^ 20
作为python的运算符时, ^表示bitwise XOR(按位操作符,按位异或)
a ^ b 对于每一个比特位,当两个操作数相应的比特位有且只有一个1时,结果为1,否则为0.
2、a=1,b=2,不用中间变量交换a和b的值?
答:
>>> a=1
>>> b=2
>>> a=a^b
>>> b=b^a
>>> a=a^b
>>> a2
>>> b1
注意这是一种比较巧的办法,当然本题的答案不唯一,最简单的答案
a,b=b,a
此处为了演示上面的异或,提供一种巧的办法:
用二进制表示为10,1用二进制表示为1。所以题中转换为二进制相当于a=1,b=10。如下:
a=01 b=10
首先a=a^b(按照相同取0,不同取1),注意两个二进制位上数值的变化规律:
a=01 b=10------a=11
然后进行b=b^a,结果如下:
b=10 a=11------b=01
最后进行a=a^b,结果如下:
a=11 b=01------a=10
最后的结果就是a=10,b=01。和最开始的a=1,b=10相比较,确实是交换了两个变量的值。
3、面试题之基础
1.代码中要修改不可变数据会出现什么问题?抛出什么异常?
答:代码不会正常运行,抛出TypeError异常。
2.print调用python中底层的什么方法?
答:print方法默认调用 sys.stdout.write方法,也就是往控制台打印字符串。
3.简述你对input()函数的理解?
答:
在python3中,input获取用户输入,不论用户输入什么,获取到的都是字符串类型。
在python2中,有rawinput()和input(),rawinput()和python3中的input作用是一样的,input有点区别,就是输入的是什么数据类型,获取到的就是什么数据类型的。
4.python2中range和xrange的区别?
答:
两者用法相同,不同的是range返回的结果是一个列表,而xrange的结果是一个生成器;range直接开辟一块内存空间来保存列表,xrange是一边循环一边使用,是有使用的时候才会开辟内存空间,所以当列表很长时,使用xrange性能要更好一点。
5.4G内存怎么读取一个5G的数据?
答:
可以通过生成器,分多次读取,每次读取数量相对少的的数据进行处理,处理结束后再读取后面的数据。
还可以通过Linux命令split切割成小文件,然后再对数据进行处理,此方法效率比较高,可以按照行数切割,可以按照文件大小切割。
6、dict
问:有这样一个需求,为字典添加一个键,如果已存在则不做任何操作;如果不存在,添加后需要设置默认值。请使用字典自带的一个方法完成此操作。
答:setdefault 方法可完成此操作。示例如下:
mydict = {"1":"小闫", "2":"小良"}
mydict.setdefault('1', 'xx')
print(mydict)
# 结果为 {'1': '小闫', '2': '小良'}
mydict.setdefault('3', 'xx')
print(mydict)
# 结果为 {'1': '小闫', '2': '小良', '3': 'xx'}
7、str
问:请问字符串的方法 join 与操作符 + ,哪一个效率高?
答:如果需要拼接大量的字符串,如几万个 ,那么 join 类型的效率要远高于操作符 +;如果仅仅是一两个字符串拼接的话,操作符会更加实用。
字符串底层是由 C 语言中 PyStringObject 对象所实现,此对象不可变,这就导致了如果要使用操作符 + ,就需要不断的重新申请地址空间去存放拼接后的字符串,在数量庞大的基础上,效率可想而知多么低。join 就不一样了,它是对列表等可迭代对象进行操作,因为操作对象是可变的,因此只需申请一次内存即可。所以结论就是 join 类型效率要高的多。
8、MVT
问:谈一谈你对 MVT 模式的了解?
答:首先介绍一下这三个字母所代表的的内容,M 是 Model 代表模型类,与数据库进行交互;V 是 View 代表视图,是对请求进行处理并与数据库模板等进行交互;T 是 Template 代表模板,是负责填充数据产生前端页面。其大体流程为:客户端发起一个请求,视图接收后,根据内容进行处理,过程中如果涉及到数据库,会进行查询保存等操作并将结果返回给视图,然后模板进行填充并返回给视图一个 html 页面,最后视图将页面返回给客户端进行渲染展示
4、文件读取的一些知识点
1.在文件读取的时候要考虑到指针的位置,如果文件没有关闭,那么我们第二次读取的时候将从第一次读取结束的位置开始。
2.控制文件指针的方法:
方法一:重新打开文件,每次执行只读方式的时候都是从文件开始进行读取的。
方法二:可以手动的将文件的指针移动到文件的开头:
file_name.seek(0.0)
file.seek(off, whence=0):从文件开始移动off个操作标记(文件指针),正数代表往结束方向移动,负数代表往开始方向移动。如果设定了whence参数,就以whence设定的起始位为准,0代表从头开始,1代表当前位置,2代表文件最末尾位置。
5、Linux命令split
该指令代表的是将大文件切割成较小的文件,在默认情况下按照每1000行切割成一个小文件。
语法:
split [--help][--version][-<行数>][-b <字节>][-C <字节>][-l <行数>][要切割的文件][输出文件名]
参数解释:
-<行数>: 指定每多少行切成一个小文件
-b<字节> : 指定每多少字节切成一个小文件
–help: 在线帮助–version: 显示版本信息
-C<字节> : 与参数"-b"相似,但是在切 割时将尽量维持每行的完整性[输出文件名]: 设置切割后文件的前置文件名, split会自动在前置文件名后再加上编号-a, --suffix-length=N 指定输出文件名的后缀,默认为2个-d, --numeric-suffixes 使用数字代替字母做后缀-l, --lines=NUMBER NUMBER 值为每一输出文档行数大小
使用:
split -l 2482 ../BLM/BLM.txt -d -a 4 BLM_
将 文件 BLM.txt 分成若干个小文件,每个文件2482行(-l 2482),文件前缀为BLM_ ,系数不是字母而是数字(-d),后缀系数为四位数(-a 4)
6、Linux命令wc
读取文件有多少行
wc -l <file_name>
7、Linux命令>>和>
代表覆盖文件内容。>>代表的是在文件后面追加内容。
8、描述用浏览器访问www.baidu.com的过程
1.首先由DNS服务器解析出baidu.com对应的IP地址。
2.要先使用ARP获取默认网关的mac地址。
3.组织数据发送给默认网关(IP还是DNS服务器的IP,但是mac地址是默认网关的mac地址),默认网关拥有转发数据的能力,把数据转发给路由器。
4.路由器根据自己的路由协议,来选择一个合适的较快的路径转发数据给目的网关。
5.目的网关(DNS服务器所在的网关),把数据转发给DNS服务器。
6.DNS服务器查询解析出baidu.com对应的ip地址,并原路返回请求这个域名的client。
7.得到了baidu.com对应的IP地址之后,会发送tcp的3次握手,进行连接。
8.使用HTTP协议发送请求数据给web服务器。
9.web服务器收到数据请求之后,通过查询自己的服务器得到的相应的结果,原路返回给浏览器。
10.浏览器接收到数据之后通过浏览器自己的渲染功能来显示这个网页。
11.浏览器关闭tcp连接,即4次挥手结束,完成整个访问过程。
9、过程中涉及到的知识点
9.1、OSI模型
OSI模型称为开放式系统互联通信参考模型,将计算机网络体系结构分为七层:
第一层:物理层(比特流传输),相当于邮局中一线的搬运工人。
第二层:数据链路层(提供介质访问,链路管理),相当于邮局中的装拆箱工人。MAC地址在这一层。
第三层:网络层(寻址和路由选择),相当于邮局中为邮件物品按地区分类排序的工人。IP地址在这一层。
第四层:传输层(提供终端到终端的可靠连接),相当于公司中给邮局去寄信件的职员。
第五层:会话层(建立维护和管理会话),相当于公司中负责收寄信,装信封拆信封的秘书之类的人员。
第六层:表示层(处理数据格式,数据加密等),相当于公司中替老板写信的助理。
第七层:应用层(提供应用程序间通信),相当于大老板。
9.2、TCP/IP模型
第一层:网络接口层(对应七层模型中的物理层和数据链路层)
第二层:网络层
第三层:传输层
第四层:应用层(对应会话层、表示层和应用层)
9.3ARP
ARP称为地址解析协议,是根据IP地址获取物理地址的一个TCP/IP协议。
主机将包含目标IP地址的ARP请求广播到网络上的所有主机,然后通过接收返回的消息来确定目标的物理地址。
10、Django创建项目的命令?
django-admin startproject 项目名称
11、Django创建项目以后,项目文件夹下的组成部分(对mvt的理解)?
manage.py:是项目运行的入口,指定配置文件路径。
init.py:是一个空文件,作用是这个目录可以被当做包使用,也可以在这个文件中做一些初始化的操作。
settings.py:是项目的整体配置文件。
urls.py:是项目的URL配置文件。
wsgi.py:是项目与WSGI兼容的web服务器。与项目同名的目录:包含项目的配置文件、子应用之类的。
12、3.对MVC,MVT的理解?
答:
下面先来谈一下MVC:
M:Model,模型,和数据库进行交互。
V:View,视图,负责产生HTML页面。
C:Controller,控制器,接收请求,进行处理,与M和V进行交互,返回应答。

我们可以以用户注册的一个案例来说明一下三者之间的关系,结合图片进行说明:
1.用户输入完注册信息之后,点击按钮,将信息提交给网站的服务器。
2.Controller控制器接收用户的注册信息,Controller会告诉Model层将用户的注册信息保存到数据库中。
3.Model层接收到指令之后,将用户的注册信息保存进数据库。
4.数据库返回保存的结果给Model模型。
5.Model层再将保存的结果的返回给Controller控制器。
6.Controller控制器收到保存的结果之后,告诉VIew视图,View视图产生一个html页面。
7.View将产生的html页面的内容交给Controller控制器。
8.Controller控制器将html页面内容返回给浏览器。
9.浏览器接收到服务器Controller返回的html页面之后进行解析展示。
下面再谈一下MVT模型:
M:Model,模型,和MVC中的M功能相同,和数据库进行交互。
V:View,视图,和MVC中的C功能相同,接收请求,进行处理,与M和T进行交互,返回应答。
T:Template,模板,和MVC中的V功能相同,产生html页面。

我们还是以同样的一个注册案例来对MVT模型进行一个简单的说明:
1.用户点击注册按钮,将要注册的内容发送给网站的服务器。
2.View视图,接收到用户发来的注册数据,View告诉Model将用户的注册信息保存进数据库。
3.Model层将用户的注册信息保存到数据库中。
4.数据库将保存的结果返回给Model。
5.Model将保存的结果再返回给View视图。
6.View视图告诉Template模板去产生一个html页面。
7.Template生成html内容返回给View视图。
8.View视图将html页面内容返回给浏览器。
9.浏览器拿到view返回的html页面内容进行解析,展示。
13.Django中models利用ORM对MySQL进行查表的语句(多个语句)?
1.增加:
# 1.save
people = EthanYan(name='小闫同学',age=18)
people.save()
# 2.create
EthanYan.objects.create(name='小闫同学',age=18)
2.基本查询:
# get,查询单一结果,如果不存在抛出`模型类.DoesNotExist异常
EthanYan.objects.get(id=3)
# all,查询多个结果
EthanYan.objects.all()
# count,查询结果数量
EthanYan.objects.count()
3.过滤查询:
# filter,过滤出多个结果
# exclude,排除掉符合条件剩下的结果
# get,过滤单一的结果
# 属性名称和比较运算符间使用两个下划线,所以属性名不能包括多个下划线
属性名称__比较运算符=值
# exact:表示判断
EthanYan.objects.filter(id__exact=1)
# contains:是否包含
EthanYan.objects.filter(name__contains='闫')
# startswith/endswith:以指定值开头或者结尾
EthanYan.objects.filter(name__startswith='小')
EtahnYan.objects.filter(name__endswith='记')
# isnull:是否为NULL
EthanYan.objects.filter(name__isnull=False)
# in:是否包含在范围内
EthanYan.objects.filter(id__in=[1,3,5])
# gt:大于
# gte:大于等于
# lt:小于
# lte:小于等于
EthanYan.objects.filter(id__gt=3)
# 不等于的运算符,使用exclude()过滤器
EthanYan.objects.exclude(id=3)
# 日期查询
# year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
XiaoYanBiJi.objects.filter(bpub_date__year=1980)
XiaoYanBiJi.objects.filter(bpub_date__gt=date(1980,1,1))
# F对象:用于类属性之间的比较条件
from django.db.models import F
# 查询小闫笔记中阅读量大于等于评论量的文章。
XiaoYanBiJi.objects.filter(bread__gte=F('bcomment'))
# Q对象:用于查询时的逻辑条件
# Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或。
# Q(属性名__运算符=值)
from django.db.models import Q
# 查询阅读量大于20,或编号小于3的文章,只能使用Q对象实现
XiaoYanBiJi.objects.filter(Q(bread_gt=20)|Q(id__lt=3))
# 查询编号不等于3的文章
XiaoYanBiJi.objects.filter(~Q(pk=3))
# 聚合函数
# Avg平均、Count数量、Max最大,Min最小、Sum求和
# from django.db.models import Sum
XiaoYanBiJi.objects.aggregate(Sum('bread'))
# aggregate的返回值是一个字典类型
{'属性名__聚合类小写':值}
# count一般不使用aggregate()过滤器
XiaoYanBiJi.objects.count()
# 排序
XiaoYanBiJi.objects.all().order_by('bread')
XiaoYanBiJi.objects.all().order_by('-bread')
# 关联查询
# 由一到多的访问语法:
people = EthanYan.objects.get(id=1)
一对应的模型类对象.多对应的模型类名小写_set
prople.note_set.all()
# 由多到一的访问方法
note = XiaoYanBiJi.objects.get(id=1)
# 多对应的模型类对象.关联类属性_id
note.xiaoyanbiji_id
# 由多模型类条件查询一模型类数据
关联模型类名小写__属性名__条件运算符=值 # 如果没有“__运算符”部分,表示等于
# 查询文章,要求文章的作者为小闫同学
XiaoYanBiJi.objects.filter(ethan__name='小闫同学')
# 查询文章,要求文章中的作者描述包含“闫”
XiaoYanBiJi.objects.filter(ethanyan__hcomment__contains='闫')
# 由一模型类条件查询多模型类数据
一模型类关联属性名__一模型类属性名__条件运算符=值
# 如果没有"__运算符"部分,表示等于
# 查询文章名为“Django”的所有作者
EthanYan.objects.filter(xiaoyanbiji_btitle='Django')
# 查询文章阅读量大于30的所有作者
EthanYan.objects.filter(xiaoyanbiji_bread__gt=30)
# 修改
# save
ethanyan = EthanYan.objects.get(ename='小闫同学')
ethanyan.save()
# update
EthanYan.objects.filter(ename='小闫同学1').update(ename='小闫同学')
# 删除
ethanyan = EthanYan.objects.get(id=3)
ethanyan.delete()
EthanYan.objects.filter(id=14).delete()
14、redis持久化
众所周知,redis是内存型的存储数据库。效率高的同时,也有一个弊端不可忽视,那就是数据安全问题。此处安全指的是数据丢失,并非其他。我们将数据都存储在内存中,如果发生宕机等意外情况导致redis重启,那么内存中的数据会全部丢失,多么可怕的一件事。那么我们怎么解决呢?答案就是数据的持久化。
数据的持久化有两种方式:RDB和AOF两种方式。一开始你会觉得两个名字很难记,其实了解过你就会发现其实这两种方式都是以相关数据存储文件的后缀名命名的。
1.1RDB
首先说一下RDB方式。RDB是将内存中所有的数据都持久化到硬盘中,这个过程还有一个名词,那就是『快照』。Redis默认将我们的数据保存在当前进程目录的 dump.rdb文件中,看一下后缀名,再看一下这个方式名,是不是发现了什么呢?了解完之后,要关注的就是怎么实现的问题的了。
redis启动的时候是会自动读取RDB快照文件的,这也 就是为什么RDB可以解决数据的持久化。
方式一:SAVE和BGSAVE命令
这种方式是让我们手动的进行快照操作。他俩的区别就是SAVE命令快照,会阻塞后来客户端的请求;而BGSAVE命令则是异步的方式进行快照的。区别显而易见,SAVE命令会打断正在进行的操作,如果数据超多,这是一种损失,所以必须减少其使用,如果必须使用,那么可以选在访问量极少的时间段。BGSAVE则可以一边接受客户端请求,一边快照,不会对网站造成什么损失。
方式二:自己配置快照条件
# 900的单位是s,1是被更改的键的个数。这句命令的意思就是,900s内被更改的键的个数大于1的时候,自动进行快照操作。
save 900 1
# 指定快照文件的文件名,这个就不要写其他的了
dbfilename dump.rdb
# 指定快照文件存储路径
dir ./
配置文件在redis.conf这个文件中。
方式三:执行flushall命令
这个命令进行快照操作有一个前提,那就是我们像方式二中配置了快照的设置。当我们使用了 flushall这个命令,Redis会清除数据库中所有的数据,而且会执行一次快照操作。
如果没有设置save,是不会进行快照操作的!!!!
1.1.1快照过程
在redis执行快照的时候,其实先使用了 fork函数。这个函数执行的时候有个特点,就是我们我们备份数据的时候,如果又有数据写入,后面的数据是不会备份的。意思就是我们执行快照的时候,其实保存的是执行 fork函数那一刻的所有数据。然后父进程继续处理客户端的相关请求,子进程将要保存的数据写入硬盘的临时文件,只有在子进程将所有的数据写完之后,才会将这个文件替换旧的RDB文件。这样就完成了一次快照操作。
1.2AOF
简单的说一下AOF方式,它不会像RDB方式全量的将数据持久化至硬盘,而是只保存执行过的命令。下次启动的时候,其实就是将所有的命令再执行一遍。下面仍然是最关心的如何实现的问题。
我们需要在配置文件中将 appendonly设置为 yes 。开启之后Redis每执行一条写操作(注意是写入的命令),就会将这个命令记录到 appendonly.aof文件中,看这个名字,是不是同样很熟悉,像不像本小节的标题呢?
在AOF中有一个概念,叫做文件重写。当我们多次设置同一个value的时候,redis中只会有最后一次的设置结果,那么前几次的操作,就完全没有必要记录下来再次执行了,会严重影响效率,所以就涉及到了AOF重写。重写就是将没用的命令删除的一个过程。
我们可以让Redis自动进行重写操作,那就是现在配置文件中进行如下设置:
# 目前的AOF文件的大小超过上一次重写时的AOF文件的百分之多少时再次进行重写,如果之前没有重写过,则以启动时AOF文件大小为依据。auto-aof-rewrite-percentage 100# 当AOF文件的大小大于64MB时才进行重写,因为如果AOF文件本来就很小时,有几个无效的命令也是无伤大雅的事情。auto-aof-rewrite-min-size 64mb
所有的东西都介绍完了,我们当然要讲一下如何将数据同步到硬盘中。
AOF文件我们可以设置同步到硬盘的时间,以减少数据的丢失。
# 实时的写入硬盘appendfsync always# 每秒写入一次appendfsync everysec# 不主动写入appendfsync no
1.3重要
重启服务的时候一定要加上配置参数:
redis-server <redis.conf文件的路径>
15、
1.HTTP/HTTPS协议
HTTP协议是超文本传输协议,是web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用。它属于应用层。HTTP连接最显著的特点就是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。HTTP是用来在网络上传输HTML文本的协议,用于浏览器和服务器的通信。有一点需要注意,它是明文传输,为了安全可以使用HTTPS协议。
HTTPS协议其实就是HTTP套了一层SSL/TLS外壳。这也是它最大的特点,安全。HTTP协议是应用层直接将数据给到TCP进行传输,HTTPS则是改成应用层将数据给到SSL/TLS,将数据加密之后再给TCP进行传输。
HTTP的端口是80;HTTPS的端口是443。SSL是一个加密套件,证书,TLS是SSL的升级版。
HTTP请求报文格式:
1、请求行:请求方法、资源路径、HTTP协议版本
GET / HTTP/1.1\r\n
2、请求头:有好多,而且不一,只说一下格式:
头名称:头对应的值\r\n
3、空行和请求体
HTTP响应报文格式
状态行:协议的版本、状态码、状态说明
HTTP/1.1 200 OK\r\n
响应头:
头名称:头对应的值\r\n
空行和响应体
2.TCP/IP协议
TCP称作传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。通过三次握手建立连接,通讯完成时四次挥手终止通讯。它的优点就是在数据传递时,有发送应答机制、超时重传机制、错误校验机制、阻塞管理机制等,能保证数据的正确性,可靠。缺点就是相对于UDP来说速度慢一点,要求系统资源也多一点。
TCP/IP协议是传输层协议,主要解决数据如何自网络中传输。HTTP是应用层协议,主要解决如何包装数据。IP协议处于网络层。
2.1 三次握手

**文邹邹晦涩版答案:**客户端将标志位SYN置为1,随机产生一个值seq(假装是J吧),然后将该数据包发送给服务器。服务器收到数据包之后将标志位SYN和ACK都置为1,ack=J+1。随机产生一个值seq(假装是K吧),然后将该数据包发送给客户端,确认连接请求。客户端收到确认后,看一下ack是不是J+1,看看ACK是不是1,确认无误之后就将标志位ACK置为1,ack=K+1,然后将数据包发送给服务器。服务器检查一下ack和ACK的值是不是K+1和1,正确了就连接成功。
SYN: 表示连接请求 ACK: 表示确认 FIN: 表示关闭连接 seq:表示报文序号 ack: 表示确认序号
**生动举例版:**A:“喂,老哥,在不?”B:“在呢,咋地啦?”A:“嗯,和你说件事…”巴拉巴拉的开始唠嗑…
2.2 四次挥手

**文邹邹晦涩版答案:**客户端和服务器都可以主动关闭,我们以客户端主动关闭连接为例。
第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送。
第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1。
第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送。
第四次挥手:Client收到FIN后,接着发送一个ACK给Server,确认序号为收到序号+1。
**生动举例版:**因为连接时双向通信的,必须双方都同意关闭才算关闭。就好像谈恋爱,俩人都同意分手,才分得彻底,要不然还是藕断丝连。
2.3说一下什么是tcp的2MSL?
主动发送 fin 关闭的一方,在 4 次挥手最后一次要等待一段时间我们称这段时间为 2MSL。
2.4为什么客户端在 TIME-WAIT 状态必须等待 2MSL 的时间?
就好像分手一样,客户端主动关闭的,你得为这件事负责吧?客户端为了确保服务器收到最后一次挥手的报文。如果最后一次丢包了,服务器没有收到第四次挥手的报文,还以为客户端不想分手,就会再重发一次第三次挥手的报文,看看客户端是不是后悔了,不想分手了。这个等待时间就是为了接收超时重传的报文。
假如客户端发完就断开了链接,然后服务器一直等不到回应,重传了报文还是没有得到回应,服务器不死心啊,服务器就关闭不了链接。客户端这时就是典型的渣男角色,分手你别让别人还抱有幻想是不是?说多了,回归正题。
tcp最大的特点就是数据不会丢失啊,客户端渣渣的建立了新连接,然后发现有一个旧的数据包,然后让客户端的新连接也不好了,这就叫自食其果。所以有了这个等待时间,既保证了双方都正常关闭,又保证了所有报文段消失,不会在新连接中出现旧的请求报文段。
3.WSGI
先回忆一下后端服务器,它其实分为了web服务器和web框架。web服务器负责解析请求报文,调用框架程序处理请求;组织响应报文,返回内容给客户端。web框架则是负责路由分发(根据url找到对应的处理函数);处理函数中进行业务的处理。
WSGI其实就是为python语言定义的web服务器和web框架之间的一个接口。用来描述web服务器如何与web框架通信的规范。
WSGI协议中,重中之重就是一个接口函数:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return [b'<h1>Hello, web!</h1>']
第一个参数是字典类型的请求地址、请求方式等。第二个参数是一个回调函数,用来传递响应状态结果。返回值是响应体。
实现的过程很是巧妙,帮大家简单的回忆一下:
1.在服务器中调用application函数。
2.在服务器中定义用来储存返回的响应头信息的回调函数,函数有两个参数,一个是状态,一个是其它信息,以字典形式传入。
3.在服务器中以字典传入请求地址名,传入回调的函数名。
4.在框架中定义application函数,当处理完数据后,调用传入的函数并返回数据。
5.服务器收到返回的信息后进行响应信息的拼接处理。
通过WSGI接口,可以实现服务器和框架的功能分离。便于服务器的迁移和维护。
4.多任务相关知识
1.并行:基于多个CPU同一时间点执行的多任务方式。
2.并发:基于时间片轮转的方式执行多任务的方式。
3.谈谈你对多进程,多线程,以及协程的理解,项目是否用?
答:一个运行的程序就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所有进程间的数据不共享,开销大。进程之间通信使用Queue。线程是调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在。一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大的提高了程序的运行效率。但是cpython中是伪多线程。由于GIL的存在,python程序中同一时刻有且只有一个线程会执行,无法有效利用多核CPU。协程,又称微线程,纤程,也称为用户级线程,在不开辟线程的基础上完成多任务,也就是在单线程的情况下完成多任务,多个任务按照一定顺序交替执行 通俗理解只要在def里面只看到一个yield关键字表示就是协程。
4.协程Gevent实现多任务,为了让Gevent框架识别耗时操作时自动切换执行对应的任务,可以使用猴子补丁:
from gevent import monkey
monkey.patch_all()
5.生成器和迭代器
1.使用自定义迭代器输出斐波那契数列的前10项。
class Fibonacci(object):
def __init__(self,num):
self.num = num
self.a = 0
self.b = 1
self.current_index = 0
def __next__(self):
if self.current_index < self.num:
result = self.a
self.a,self.b = self.b,self.a+self.b
self.current_index += 1
return result
else:
raise StopIteration
def __iter__(self):
return self
if __name__ == '__main__':
fib = Fibonacci(10)
for value in fib:
print(value,end=' ')
2.使用生成器输出斐波那契数列前10项。
def fibonacci(num):
a = 0
b = 1
current_index = 0
while current_index < num:
result = a
a,b = b,a+b
current_index += 1
yield result
if __name__ == '__main__':
fibonacci = fibonacci(10)
for value in fibonacci:
print(value,end=' ')
6.QQ第三方登录开发流程
第一步:浏览器向服务器请求获取QQ登录网址。
第二步:服务器向客户端返回QQ登录网址和参数。
给客户端返回的数据:
{
"login_url": "https://graph.qq.com/oauth2.0/show?which=Login&display=pc&response_type=code&client_id=101474184&redirect_uri=http%3A%2F%2Fwww.ethan.site%3A8080%2Foauth_callback.html&state=%2F&scope=get_user_info"
}
第三步:客户端根据上面返回的QQ登录网址向QQ服务器发起请求。
第四步:QQ服务器向客户端返回QQ授权登录的页面。
第五步:用户开始在授权页面进行操作,登录QQ。
第六步:授权成功之后,QQ服务器让浏览器重定向访问回调网址,,并在网址后面携带code和原始的state参数,此处的参数是去QQ服务器提供的。
| 参数 | 说明 |
|---|---|
| code | QQ返回的授权凭证,根据code可以获取access_token |
| status | client端的状态值。用于第三方应用防止CSRF攻击,成功授权后回调时会原样带回。请务必严格按照流程检查用户与state参数状态的绑定。重定向到我们指定的页面,如果用户没有进行绑定,会跳转绑定的页面,这个时候在查询字符串中有两个参数,一个是code,一个是status |
第七步:客户端访问回调网址,携带QQ提供的code参数给服务器。然后获取QQ登录用户的openid并处理。
| 参数 | 说明 |
|---|---|
| openid | OpenID是此网站上或应用中唯一对应用户身份的标识,网站或应用可将此ID进行存储,便于用户下次登录时辨识其身份,或将其与用户在网站上或应用中的原有账号进行绑定。 |
第八步:服务器根据code请求QQ服务器获取 access_token。
| 参数 | 说明 |
|---|---|
| access_token | 用户是第一次使用QQ登录时返回,其中包含openid,用于绑定身份使用,注意这个是我们自己生成的。 |
第九步:QQ服务器向服务器返回所需要的 access_token。第十步:服务器凭借 access_token请求QQ服务器获取openid。
第十一步:QQ服务器返回openid给服务器。
第十二步:服务器接下来根据openid判断是否绑定过本网站用户。后端接口根据openid到数据库查询 tb_oatu_qq表(该表中记录了openid和User_id的绑定情况)
第十三步:如果绑定过,直接签发jwt token并返回给客户端,让客户端保存这个token。
第十四步:如果没有绑定过,将openid加密并返回给客户端。进行下面的步骤:
第十五步:前端也会做相应的判断,如果绑定过,直接就返回到首页登录网址,如果没有绑定过,则会在浏览器显示绑定页面,要求用户填写表单进行绑定。
第十六步:用户在填写完上面的表单,点击保存按钮的时候,客户端向服务器发起请求绑定QQ登录用户,服务器将表单信息保存到数据库中。
第十七步:服务器签发jwt token并返回给客户端。
16、数据库的优化
1.优化索引、SQL语句、分析慢查询。
2.设计表的时候严格根据数据库的设计范式来设计数据库。
三大范式:
1.表字段的原子性(不可拆分);
2.满足第一范式的基础上,有主键依赖;
3.满足第一二范式的基础上,非主属性之间没有依赖关系。
3.使用缓存,把经常访问到的数据而且不需要经常变化的数据放在缓存中,能节约磁盘IO。
4.优化硬件;采用SSD,使用磁盘队列技术等。
5.采用MySQL内部自带的表分区技术,把数据分成不同的文件,能够提高磁盘的读取效率。
6.垂直分表;把一些不经常读的数据放在一张表里,节约磁盘IO。
7.主从分离读写;采用主从复制把数据库的读操作和写入操作分离开来;
8.分库分表机器(数据量特别大),主要的原理就是数据路由。
9.选择合适的表引擎,参数上的优化。
10.进行架构级别的缓存,静态化和分布式。
11.不采用全文索引。
12.采用更快的存储方式,例如NoSQL存储经常访问的数据。
17、SQL语句
我们后面查询用到的表:
mysql> select * from t_score;
+------+--------------+-----------+--------+
| c_id | c_student_id | c_english | c_math |
+------+--------------+-----------+--------+
| 1 | 1 | 60.5 | 99 |
| 2 | 2 | 65.5 | 60 |
| 3 | 3 | 70.5 | 88 |
| 4 | 4 | 60.5 | 77 |
| 5 | 5 | 60.5 | 89 |
| 6 | 6 | 90 | 93 |
| 7 | 7 | 80 | 99 |
| 8 | 8 | 88 | 99 |
| 9 | 9 | 77 | 60 |
| 10 | 10 | 75 | 86 |
| 11 | 11 | 60 | 60 |
| 12 | 12 | 88 | 99 |
| 13 | 13 | 77 | 59 |
| 14 | 14 | NULL | 59 |
| 15 | 15 | 60 | NULL |
+------+--------------+-----------+--------+
1.单表查询
1.1mysql中的分页查询。
语法:
select * from 表名 limit (page-1)*count,count;
page指的是页码,count指的是每页显示的条数。
# 每页3条数据,查询第三页的数据,(3-1)*3=6.
mysql> select * from t_score limit 6,3;
+------+--------------+-----------+--------+
| c_id | c_student_id | c_english | c_math |
+------+--------------+-----------+--------+
| 7 | 7 | 80 | 99 |
| 8 | 8 | 88 | 99 |
| 9 | 9 | 77 | 60 |
+------+--------------+-----------+--------+
1.2.求和:
# 求数学学科的总成绩
mysql> select sum(c_math) from t_score;
+-------------+
| sum(c_math) |
+-------------+
| 1127 |
+-------------+
1.3.求平均:
# 求数学学科的平均成绩
mysql> select avg(c_math) from t_score;
+-------------+
| avg(c_math) |
+-------------+
| 80.5 |
+-------------+
1.4.求最大最小值:
# 找到数学最高分
mysql> select max(c_math) from t_score;
+-------------+
| max(c_math) |
+-------------+
| 99 |
+-------------+
# 找到数学最低分
mysql> select min(c_math) from t_score;
+-------------+
| min(c_math) |
+-------------+
| 59 |
+-------------+
1.5.统计记录总数:
# 统计参加数学考试的人有多少
mysql> select count(*) from t_score;
+----------+
| count(*) |
+----------+
| 15 |
+----------+
1.6.分组:
group_by后面的字段名要和select后面的字段名相同,否则会报错。
# 从成绩表中取出数学成绩进行分组
mysql> select c_math from t_score group by c_math;
+--------+
| c_math |
+--------+
| NULL |
| 59 |
| 60 |
| 77 |
| 86 |
| 88 |
| 89 |
| 93 |
| 99 |
+--------+
1.7.根据分组结果,使用group_concat()来获取分组中指定字段的集合
# 根据数据成绩进行分组,获取每个分数中学生的编号
mysql> select c_math,group_concat(c_student_id) from t_score group by c_math;
+--------+----------------------------+
| c_math | group_concat(c_student_id) |
+--------+----------------------------+
| NULL | 15 |
| 59 | 13,14 |
| 60 | 2,9,11 |
| 77 | 4 |
| 86 | 10 |
| 88 | 3 |
| 89 | 5 |
| 93 | 6 |
| 99 | 1,7,8,12 |
+--------+----------------------------+
1.8.分组和聚合函数的使用
# 根据性别进行分组,求出每组同学的最大年龄、最小年龄、年龄总和、平均年龄、人数
mysql> select c_gender,max(c_age),min(c_age),sum(c_age),avg(c_age),count(*) from t_student group by c_gender;
+----------+------------+------------+------------+------------+----------+
| c_gender | max(c_age) | min(c_age) | sum(c_age) | avg(c_age) | count(*) |
+----------+------------+------------+------------+------------+----------+
| 男 | 99 | 15 | 1084 | 47.1304 | 26 |
| 女 | 88 | 11 | 239 | 39.8333 | 7 |
+----------+------------+------------+------------+------------+----------+
1.9.having条件语句的使用。
# 从学生表中以性别进行分组,然后选出女生分组,并展示小组中所有的名字
mysql> select c_gender,group_concat(c_name) from t_student group by c_gender having c_gender='女';
+----------+-----------------------------------------------------------+
| c_gender | group_concat(c_name)
|
+----------+-----------------------------------------------------------+
| 女 | 小龙女,白骨精,扈三娘,孙二娘,赵敏,嫦娥,孙 |
+----------+-----------------------------------------------------------+
2.多表查询
# 学生表中保存了学生的信息和所在班级的ID,班级表中保存了班级的信息。 查询学生姓名和对应的班级
mysql> select t_student.c_name,t_class.c_name from t_student,t_class where t_student.c_class_id=t_class.c_id;
+-----------+-------------------------------------+
| c_name | c_name
+-----------+-------------------------------------+
| 孙德龙 | 软件工程18级一班 |
| 塔大 | 软件工程18级二班 |
| 宋江 | 计算机科学与技术18级一班 |
| 武松 | 计算机科学与技术18级二班 |
| 孙二娘 | 网络工程18级一班 |
| 扈三娘 | 网络工程18级二班 |
| 鲁智深 | 软件工程18级一班 |
| 林冲 | 软件工程18级二班 |
| 阮小七 | 计算机科学与技术18级一班 |
| 阮小五 | 计算机科学与技术18级二班 |
| 阮小二 | 网络工程18级一班 |
| 白骨精 | 网络工程18级二班 |
| 孙悟空 | 软件工程18级一班 |
| 猪八戒 | 软件工程18级二班 |
| 沙和尚 | 计算机科学与技术18级一班 |
| 唐三奘 | 计算机科学与技术18级二班 |
| 哪吒 | 网络工程18级一班 |
| 嫦娥 | 网络工程18级二班 |
| 杨过 | 软件工程18级一班 |
| 郭靖 | 软件工程18级二班 |
| 洪七公 | 计算机科学与技术18级一班 |
| 欧阳锋 | 计算机科学与技术18级二班 |
| 黄药师 | 网络工程18级一班 |
| 小龙女 | 网络工程18级二班 |
| 孙% | 软件工程18级一班 |
| 张无忌 | 软件工程18级二班 |
| 张翠山 | 计算机科学与技术18级一班 |
| 张三丰 | 计算机科学与技术18级二班 |
| 宋青书 | 网络工程18级一班 |
| 赵敏 | 网络工程18级二班 |
| 孙 | 计算机科学与技术18级一班 |
| 孙子 | 计算机科学与技术18级一班 |
| 孙 | 网络工程18级一班 |
+-----------+-------------------------------------+
2.1.内连接查询
语法:
select * from 表1 inner join 表2 on 表1.列 运算符 表2.列
连接时必须指定连接条件,用on指定。如果无条件,那么会出现笛卡尔积。
# 查询学生姓名和对应的班级
mysql> select ts.c_name,tc.c_name from t_student as ts inner join t_class tc on ts.c_class_id=tc.c_id;
.....结果同上一个结果.......
上面的as代表的是为表起别名,也可以不写空格隔开。
2.2.左连接查询
语法:
select * from 表1 left join 表2 on 表1.列 运算符 表2.列
查询的结果为根据左表中的数据进行连接,如果右表中没有满足条件的记录,则连接空值。
mysql> select ts.c_name,tc.c_name from t_student as ts left join t_class tc on ts.c_class_id=tc.c_id;
+--------------+-------------------------------------+
| c_name | c_name
|
+--------------+-------------------------------------+
| 孙德龙 | 软件工程18级一班 |
| 塔大 | 软件工程18级二班 |
| 宋江 | 计算机科学与技术18级一班 |
| 武松 | 计算机科学与技术18级二班 |
| 孙二娘 | 网络工程18级一班 |
| 扈三娘 | 网络工程18级二班 |
| 鲁智深 | 软件工程18级一班 |
| 林冲 | 软件工程18级二班 |
| 阮小七 | 计算机科学与技术18级一班 |
| 阮小五 | 计算机科学与技术18级二班 |
| 阮小二 | 网络工程18级一班 |
| 白骨精 | 网络工程18级二班 |
| 孙悟空 | 软件工程18级一班 |
| 猪八戒 | 软件工程18级二班 |
| 沙和尚 | 计算机科学与技术18级一班 |
| 唐三奘 | 计算机科学与技术18级二班 |
| 哪吒 | 网络工程18级一班 |
| 嫦娥 | 网络工程18级二班 |
| 杨过 | 软件工程18级一班 |
| 郭靖 | 软件工程18级二班 |
| 洪七公 | 计算机科学与技术18级一班 |
| 欧阳锋 | 计算机科学与技术18级二班 |
| 黄药师 | 网络工程18级一班 |
| 小龙女 | 网络工程18级二班 |
| 孙% | 软件工程18级一班 |
| 张无忌 | 软件工程18级二班 |
| 张翠山 | 计算机科学与技术18级一班 |
| 张三丰 | 计算机科学与技术18级二班 |
| 宋青书 | 网络工程18级一班 |
| 赵敏 | 网络工程18级二班 |
| 孙 | 计算机科学与技术18级一班 |
| 孙子 | 计算机科学与技术18级一班 |
| 孙 | 网络工程18级一班 |
| 亦向枫 | NULL |
+--------------+-------------------------------------+
2.3.子查询
语法:
select * from 表1 where 条件 运算符 (select查询)
子查询是单独可以执行的一条SQL语句,它作为主查询的条件或者数据源嵌套在主查询中。
2.3.1标量子查询(子查询返回的结果是一个数据(一行一列))
# 查询班级中年龄大于平均年龄的学生信息
mysql> select * from t_student where c_age > (select avg(c_age) from t_student);
# 因为数据太多,为了展示效果,我们查询指定的一些字段
mysql> select c_id,c_name,c_gender,c_address from t_student where c_age > (select avg(c_age) from t_student);
+------+-----------+----------+-----------------------------+
| c_id | c_name | c_gender | c_address |
+------+-----------+----------+-----------------------------+
| 7 | 鲁智深 | 男 | 北京市西城区西直门 |
| 15 | 沙和尚 | 男 | 北京市西城区西直门 |
| 16 | 唐三奘 | 男 | 北京市西城区西直门 |
| 18 | 嫦娥 | 女 | 北京市昌平霍营 |
| 19 | 杨过 | 男 | 北京市西城区西直门 |
| 20 | 郭靖 | 男 | 北京市西城区西直门 |
| 21 | 洪七公 | 男 | 北京市西城区西直门 |
| 22 | 欧阳锋 | 男 | 北京市西城区西直门 |
| 25 | 孙% | 男 | 北京市西城区西直门 |
| 29 | 宋青书 | 男 | 北京市西城区西直门 |
| 30 | 赵敏 | 女 | 北京市昌平霍营 |
+------+-----------+----------+-----------------------------+
2.3.2列级子查询(子查询返回的结果是一列(一列多行))
# 主查询 where 条件 in (列子查询)
# 查询出所有学生所在班级的班级名称
mysql> select c_name from t_class where c_id in (select c_class_id from t_student);
+-------------------------------------+
| c_name
|
+-------------------------------------+
| 软件工程18级一班 |
| 软件工程18级二班 |
| 计算机科学与技术18级一班 |
| 计算机科学与技术18级二班 |
| 网络工程18级一班 |
| 网络工程18级二班 |
+-------------------------------------+
2.3.3行级子查询(子查询返回的结果是一行(一行多列))
# 主查询 where (字段1,2,...) = (行子查询)
# 查询班级年龄最大,所在班号最小的学生
mysql> select c_id,c_name,c_gender,c_address from t_student where(c_age,c_class_id) = (select max(c_age),min(c_class_id) from t_student);
+------+-----------+----------+-----------------------------+
| c_id | c_name | c_gender | c_address |
+------+-----------+----------+-----------------------------+
| 7 | 鲁智深 | 男 | 北京市西城区西直门 |
| 25 | 孙% | 男 | 北京市西城区西直门 |
+------+-----------+----------+-----------------------------+
2.3.4.自连接查询
18、笔试题
1.python中is和==的区别?
答:is是同一性运算符,是判断两个对象的id地址是否相同,是否指向同一块区域;==是比较操作符,用来判断两个对象的数据类型和值是否相同。
2.Django里QuerySet的get和filter方法的区别?
答:filter返回的是一个对象列表,如果查不到,返回一个空列表。get得到的是一个具体的对象,如果查不到,会报错。
3.列出至少4种HTTP请求返回状态码,并解释其意思。
- 通过状态码告诉客户端服务器的执行状态,以判断下一步该执行什么操作。常见的状态机器码有:
- 100-199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200-299:表示服务器成功接收请求并已完成处理过程,常用 200(OK 请求成功)。
- 300-399:为完成请求,客户需要进一步细化请求。302(所有请求页面已经临时转移到新的 url)。304、307(使用缓存资源)。
- 400-499:客户端请求有错误,常用 404(服务器无法找到被请求页面),403(服务器拒绝访问, 权限不够)。
- 500-599:服务器端出现错误,常用 500(请求未完成,服务器遇到不可预知的情况)。
只列出一些特殊的,常见的大家都知道了,此处不做列出。
| 状态码 | 解释说明 |
|---|---|
| 302 | 跳转,新的url在响应的location头中给出 |
| 303 | 浏览器对于POST的响应进行重定向 |
| 307 | 浏览器对于POST的响应进行重定向 |
| 503 | 服务器维护或者负载过重未应答 |
4.多线程和多进程的区别?
进程是资源分配的单位,线程是操作系统调度的单位。进程切换需要的资源最大,效率低;线程切换需要的资源一般,效率一般(不考虑GIL的情况)。多进程和多线程根据CPU核数不一样可能是并行的。线程是基于进程存在的。
5.Flask中请求钩子的理解和应用?
在客户端和服务器交互的过程中,有些准备工作或扫尾工作需要处理的时候,为了让每个视图函数避免编写重复的代码,Flask提供了通用设施的功能,这就是请求钩子。
我们的项目中,在完善CSRFToken逻辑和拦截普通用户进入管理员页面的时候,用到了请求钩子。
请求钩子是通过装饰器的形式实现的,有4种:
1.before_first_request:在处理第一个请求前执行
2.before_request:在每次请求前执行,在该装饰函数中,一旦return,视图函数不再执行
a.接受一个参数:视图函数作出的响应
b.在此函数中可以对响应值,在返回之前做最后一步处理,再返回
3.after_request:如果没有抛出错误,在每次请求后执行
4.teardown_request:在每次请求后执行
a.接受一个参数:用来接收错误信息
但是我们常用的只有2和3两种,在项目中具体的代码展示一下,方便大家进行回忆:
1 #使用请求钩子拦截所有的请求,通过的在cookie中设置csrf_token
2 @app.after_request
3 def after_request(resp):
4 #调用系统方法,获取csrf_token
5 csrf_token = generate_csrf()
6
7 #将csrf_token设置到cookie中
8 resp.set_cookie("csrf_token",csrf_token)
9
10 #返回响应
11 return resp
1# 使用请求钩子,拦截用户的请求,只有访问了admin_blue,所装饰的视图函数需要拦截
2# 1.拦截的是访问了非登录页面
3# 2.拦截的是普通的用户
4@admin_blue.before_request
5def before_request():
6 if not request.url.endswith("/admin/login"):
7 if not session.get("is_admin"):
8 return redirect("/")
19、intern机制
Python3的解释器中实现了小数字和字符串缓存的机制,小数字的缓存范围是[-5 ~ 256],字符串的缓存位数默认是20位。
字符串缓存机制实验:
>>> a = 'xx' * 20
>>> b = 'xx' * 20
>>> a is b
False
>>> a = 'x' * 3
>>> b = 'x' * 3
>>> a is b
True
可以看出字符串长度没有超过20,两个id是一致的,因为小于20,提前缓存好了,我们赋值操作其实是一个引用,两个都指向同一块内存空间。如果长度超过20,没有缓存,会新开辟内存,所以他们的id地址不一样。
小数字的缓存机制实验:
>>> a = -6
>>> b = -6
>>> a is b
False
>>> a = -5
>>> b = -5
>>> a is b
True
可以看出如果是-5的话,两个变量的id是一样的,因为提前缓存好了,他们只是一个引用,指向同一块空间地址。如果是-6的话就相当于重新开辟内存空间。
还有一种情况,就是如果两个字符串中含有除数字、字母下划线的任意一个符号,那么会触发intern机制,他们的内存地址也是不一样的。不论你的字符串多短。
20、gc模块
一.垃圾回收机制
Python中的垃圾回收是以引用计数为主,分代收集为辅。
1、导致引用计数+1的情况
对象被创建,例如a=23
对象被引用,例如b=a
对象被作为参数,传入到一个函数中,例如func(a)
对象作为一个元素,存储在容器中,例如list1=[a,a]
2、导致引用计数-1的情况
对象的别名被显式销毁,例如del a
对象的别名被赋予新的对象,例如a=24
一个对象离开它的作用域,例如f函数执行完毕时,func函数中的局部变量(全局变量不会)
对象所在的容器被销毁,或从容器中删除对象
3、查看一个对象的引用计数
import sys
a = "hello world"
sys.getrefcount(a)
可以查看a对象的引用计数,但是比正常计数大1,因为调用函数的时候传入a,这会让a的引用计数+1
二.循环引用导致内存泄露
内存泄漏
申请了某些内存,但是忘记了释放,那么这就造成了内存的浪费,久而久之内存就不够用了
- 让程序产生内存泄漏
import gc
class ClassA():
def __init__(self):
print('object born,id:%s'%str(id(self)))
def f2():
while True:
c1 = ClassA()
c2 = ClassA()
c1.t = c2
c2.t = c1
del c1
del c2
#python默认是开启垃圾回收的,可以通过下面代码来将其关闭
gc.disable()
f2()
执行f2(),进程占用的内存会不断增大。
创建了c1,c2后这两块内存的引用计数都是1,执行 c1.t=c2和 c2.t=c1后,这两块内存的引用计数变成2.
在del c1后,引用计数变为1,由于不是为0,所以c1对象不会被销毁;同理,c2对象的引用数也是1。
python默认是开启垃圾回收功能的,但是由于以上程序已经将其关闭,因此导致垃圾回收器都不会回收它们,所以就会导致内存泄露。
三.垃圾回收
class ClassA():
def __init__(self):
print('object born,id:%s'%str(id(self)))
def f2():
while True:
c1 = ClassA()
c2 = ClassA()
c1.t = c2
c2.t = c1
del c1
del c2
gc.collect()#手动调用垃圾回收功能,这样在自动垃圾回收被关闭的情况下,也会进行回收
#python默认是开启垃圾回收的,可以通过下面代码来将其关闭
gc.disable()
f2()
有三种情况会触发垃圾回收:
1、当gc模块的计数器达到阀值的时候,自动回收垃圾
2、调用gc.collect(),手动回收垃圾
3、程序退出的时候,python解释器来回收垃圾
四. gc模块的自动垃圾回收触发机制
在Python中,采用分代收集的方法。把对象分为三代,一开始,对象在创建的时候,放在一代中,如果在一次一代的垃圾检查中,该对象存活下来,就会被放到二代中,同理在一次二代的垃圾检查中,该对象存活下来,就会被放到三代中。
gc模块里面会有一个长度为3的列表的计数器,可以通过gc.get_count()获取。
例如(488,3,0),其中488是指距离上一次一代垃圾检查,Python分配内存的数目减去释放内存的数目,注意是内存分配,而不是引用计数的增加。例如:
print gc.get_count() # (590, 8, 0)
a = ClassA()
print gc.get_count() # (591, 8, 0)
del a
print gc.get_count() # (590, 8, 0)
3是指距离上一次二代垃圾检查,一代垃圾检查的次数,同理,0是指距离上一次三代垃圾检查,二代垃圾检查的次数。
gc模快有一个自动垃圾回收的 阀值,即通过gc.get_threshold函数获取到的长度为3的元组,例如(700,10,10) 每一次计数器的增加,gc模块就会检查增加后的计数是否达到阀值的数目,如果是,就会执行对应的代数的垃圾检查,然后重置计数器
例如,假设阀值是(700,10,10):
当计数器从(699,3,0)增加到(700,3,0),gc模块就会执行gc.collect(0),即检查一代对象的垃圾,并重置计数器为(0,4,0)
当计数器从(699,9,0)增加到(700,9,0),gc模块就会执行gc.collect(1),即检查一、二代对象的垃圾,并重置计数器为(0,0,1)
当计数器从(699,9,9)增加到(700,9,9),gc模块就会执行gc.collect(2),即检查一、二、三代对象的垃圾,并重置计数器为(0,0,0)
21谈谈你对Nginx中负载均衡的理解。
答:负载均衡简单的来说就是将任务分摊到不同的服务器中,从而使业务处理更加的高效。Nginx中负载均衡策略有轮询,当然这也是默认的方式,就是按顺序向后端的服务器进行任务分发;还有权重,通过设置权重使得一些硬件条件较好的服务器处理的业务多一点; ip_hash则是基于客户端IP分配业务,确保了相同的客户端的请求一直发送到相同的服务器,以上就是一些常见的负载均衡策略。
22、数据库优化的措施,你们项目开发中做过哪些优化?
答:数据库的优化措施有很多,常见的有优化索引、SQL语句;设计表的时候严格根据数据库的设计范式来设计数据库;使用缓存,将经常访问且不需要经常变化的数据放到缓存中,节约磁盘IO;优化硬件,采用固态等;垂直分表,就是将不经常读取的数据放到一张表中,节约磁盘IO;主从分离,读写分离;选择合适的引擎;不采用全文索引等措施。
我们在项目开发过程中尽量少的使用外键,因为外键约束会影响插入和删除性能;使用缓存,减少对数据库的访问;需要多次连接数据库的一个页面,将需要的数据一次性的取出,减少对数据库的查询次数。在我们查询操作中尽量避免全表扫描,避免使用游标,因为游标的效率很差,还避免大事务操作,提高并发能力。
23、redis五种数据类型底层实现?
redis中有五种数据类型:字符串、列表、哈希、集合以及有序集合。
redis底层有简单字符串、链表、字典、跳跃表、整数集合、压缩列表等数据结构,但是,不是直接使用他们构建键值对的,而是基于这些数据结构创建了一个对象系统,这些对象系统就是咱们的五种数据类型。通过这五种不同类型的对象,Redis可以在执行命令之前,根据对象的类型判断一个对象是否可以执行给定的命令,而且可以针对不同的场景,为对象设置多种不同的数据结构,从而优化对象在不同场景下的使用效率。
在Redis中,键总是一个字符串对象,而值可以是字符串、列表、集合等对象,所以我们通常说的键为字符串键,表示的是这个键对应的值为字符串对象,我们说一个键为集合键时,表示的是这个键对应的值为集合对象。
首先是字符串对象,它的编码可以是int,raw或者embstr。其中int 编码是用来保存整数值,raw编码是用来保存长字符串,而embstr是用来保存短字符串。其中的长短字符串以44个字节为界限进行区分,当然这是redis3.2之后的版本才改的。编码的转化中,值得注意的几点是redis中对于浮点数类型作为字符串进行保存,需要的时候再将它转换成浮点数类型;int编码保存的值不是整数或大小超过了long类型(int就是可以用long类型表示的整数)的范围时,自动转化为raw。redis中embstr由于考虑到内存分配时的缺陷,只能用于读。所以修改embstr对象时,会先转化为raw在进行修改。
列表对象编码可以是压缩列表,也可以是双端链表。当列表保存元素个数小于512个且每个元素长度小于64个字节时,采用压缩列表编码;除此之外的所有情况使用双端链表编码。
双端链表:首先解释一下什么是链表,就是存储数据的时候,每一个节点中保存着下一个节点的指针,存储十分灵活,任意添加数据时,节约内存开销。双端链表就是链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。
压缩列表:由一系列特殊编码的连续内存块组成的顺序性数据结构。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。
简单的理解:去电影院买票看电影,压缩列表要的是连号的座位,双端链表只要有座位就行,管它连号不连号。
哈希对象,底层是压缩列表和hashtable实现的。而hashtable 编码的哈希表对象底层使用字典数据结构,哈希对象中的每个键值对都使用一个字典键值对。同样,当列表保存元素个数小于512个且每个元素长度小于64个字节时,采用压缩列表编码;除此之外的所有情况使用hashtable 编码。
集合对象的编码可以是 intset 或者 hashtable。intset 编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。hashtable 编码的集合对象使用 字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值则全部设置为 null。当集合对象中所有元素都是整数,且所有元素数量不超过512时,采用intset编码。除此之外使用hashtable编码。
有序集合的编码可以是 ziplist 或者 skiplist。ziplist 编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。skiplist 编码的有序集合对象使用 zset 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表。字典的键保存元素的值,字典的值则保存元素的分值;跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。压缩列表的使用条件同上,除此之外使用跳跃表。
其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。
24、MySQL引擎有哪些了解,用过什么?
答:主流的引擎有两个,分别是InnoDB和MyISAM。其中InnoDB支持事务,支持外键约束,它还支持行锁(比如select…for update语句,会触发行锁,但是锁定的是索引不是记录)。MyISAM不支持事务,不支持外键,它是数据库默认的引擎。InnoDB保存表的行数,如果看这个表有多少行的时候,InnoDB扫描整张表,MyISAM则是直接读取保存的行数即可。删除表的时候InnoDB是一行一行的删,而MyISAM则是重建表。InnoDB适合频繁修改以及安全性要求较高的应用,MyISAM适合查询为主的应用。在我们的项目中使用的是InnoDB。
25、缓存穿透、缓存击穿、缓存雪崩?
答:
缓存穿透指的是缓存和数据库中该数据没有,但是用户不断的发起请求(如发起id为-1或者id特别大不存在该数据的请求),从而使得数据库压力过大。这样就要考虑是不是受到了攻击。解决方法就是接口层增加校验,对id进行校验,过滤非法请求;如果对方执着于同一个ID暴力攻击,那么我们可以在缓存中将key-value写成key-null,缓存有效时间设置的短一点。
缓存击穿指的是缓存中没有,但是数据库中有(一般就是缓存时间到期了)的数据,这时并发用户特别多,缓存读不到,同时去数据库读数据,造成数据库压力瞬间增大的现象。解决的方法就是热点数据永远不过期;另一种方法就是牺牲一点用户体验保护数据库,加互斥锁。
缓存雪崩指的是缓存中数据大规模的到期,而查询数据量巨大,引发数据库压力过大。你也许会想,这不是缓存击穿吗?不是的,缓存击穿是用户查询同一条数据,而缓存雪崩则是用户查询不同的数据。解决方案就是缓存数据的时间设置为随机,防止同一时间大量数据过期;如果缓存数据采用分布式部署,那么热点数据给其他缓存数据库中也分点,雨露均沾嘛;还可以将热点数据设置为永不过期。
26、异步任务除了celery还涉及到哪些?为什么选择celery?
异步任务可以使用threading模块实现多线程,进而实现多任务。还可以使用asyncio包实现异步任务,它本质是采用了协程。还有基于redis的异步任务队列RQ等等。但是兼顾性能、功能、实用性、降低耦合以及可扩展等等综合因素采用了celery。
celery是生产者消费者模型,它拥有三个至关重要的模块,一个任务发出者,一个中间人,一个执行者。任务发出者发出任务,放到中间人的消息队列中(项目中使用redis数据库),然后执行者一监听到任务就立马执行。
27、Django中中间件是如何使用的?
1.首先需要定义一个中间件的工厂函数,然后返回一个可以被调用的中间件。其中中间件工厂函数需要接收一个可以调用的 get_response对象,返回的中间件也是一个可以被调用的对象,并且像视图一样接收一个request对象参数,返回一个Response对象。下面是一个实例:
def simple_middleware(get_response): # 此处编写的代码仅在Django第一次配置和初始化的时候执行一次。
def middleware(request): # 此处编写的代码会在每个请求处理视图前被调用。
response = get_response(request) # 此处编写的代码会在每个请求处理视图之后被调用。
return response
return middleware
2.定义好中间件之后,需要在settings.py文件中添加注册中间件。
MIDDLEWARE = [ ... 'users.middleware.simple_middleware', # 添加中间件]
28、项目上线后,服务器有没有什么容灾措施?
可以将数据异地备份;将项目部署到不同平台的服务器上等等,防止数据丢失。
29、如何提高并发性能?
答:可以使用动态页面的静态化;增加缓存;垂直分表;数据库的主从分离读写;分库分表;异步读取;异步编程等。数据库的优化其实也是在提高并发性能。
30、利用代码实现一个简单的TCP服务器?
import socket
# 创建套接字
tcp_server_socket = socket(socket.AF_INET,socket.SOCK_STREAM)
# 本地的信息
address = ('', 8888)
# 绑定地址
tcp_server_socket.bind(address)
# 设置监听
# 使用socket创建的套接字默认是属性是主动的,使用listen将其变为被动的,这样就可以接收到别人的连接了# 最大等待连接数我么设置为128,这是一个经验值,前人趟的坑,我们就不要在进去了
tcp_server_socket.listen(128)
# 如果有新的客户端来连接服务器,那么就产生一个新的套接字专门为这个客户端服务
# client_socket用来为这个客户端服务
# tcp_server_socket就可以省下来专门等待其他新客户端的连接
client_socket,clientAddr = tcp_server_socket.accept()
# 接收对方发送过来的数据
recv_data = client_socket.recv(1024)
print('接收到的数据为:',recv_data.decode('gbk'))
# 发送一些数据到客户端
client_socket.send('welcome to 小闫笔记'.encode('gbk'))
# 关闭为这个客户端服务的套接字,只要关闭了,就意味着不能再为这个客户端服务了,如果还需服务,只能再次进行重新连接。
client_socket.close()
31、在Linux如何查看程序的端口号,需要用什么命令?
netstat -tnulp
------------------------
[ethanyan@localhost ~]$ netstat -tnulp
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN
tcp6 0 0 :::111 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 ::1:631 :::* LISTEN
tcp6 0 0 ::1:25 :::* LISTEN
tcp6 0 0 :::3306 :::* LISTEN
udp 0 0 0.0.0.0:53814 0.0.0.0:*
udp 0 0 0.0.0.0:5353 0.0.0.0:*
udp 0 0 192.168.122.1:53 0.0.0.0:*
udp 0 0 0.0.0.0:67 0.0.0.0:*
udp 0 0 127.0.0.1:323 0.0.0.0:*
udp6 0 0 ::1:323 :::*
-t:显示tcp端口。
-u:显示udp端口。
-l:仅显示套接字。
-p:显示进程标识符和程序名称。
-n:不进行DNS轮询,显示IP
32、Python 如何实现单例模式?请写出至少两种实现方法?
单例模式(Singleton Pattern) 是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息。如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪费内存资源,尤其是在配置文件内容很多的情况下。
事实上,类似 AppConfig 这样的类,我们希望在程序运行期间只存在一个实例对象。
在 Python 中,我们可以用多种方法来实现单例模式:
1.使用模块; 2. 使 用 new ; 3.使用装饰器; 4. 使用元类(metaclass)。
(1)使用模块:
其实,Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成.pyc 文件,当第二次导入时,就会直接加载.pyc 文件,而不会再次执行模块代码。因此我们只需把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。
1.# mysingle.py
2.class MySingle:
3.def foo(self):
4.pass
5.
6. sinleton = MySingle()
7.
8.将上面的代码保存在文件 mysingle.py 中,然后这样使用:
9.from mysingle import sinleton
10.singleton.foo()
(2)使用 new :
为了使类只能出现一个实例,我们可以使用 new 来控制实例的创建过程,
class Singleton(object):
def new (cls):
# 关键在于这,每一次实例化的时候,我们都只会返回这同一个 instance 对象
if not hasattr(cls, 'instance'):
cls.instance = super(Singleton, cls). new (cls)
return cls.instance
obj1 = Singleton()
obj2 = Singleton()
obj1.attr1 = 'value1'
print obj1 is obj2
输出结果:
value1 value1
(3)使用装饰器:
装饰器可以动态的修改一个类或函数的功能。这里,我们也可以使用装饰器来装饰某个类,使其只能生成一个实例
def singleton(cls):
instances = {}
def getinstance(*args,**kwargs):
if cls not in instances:
instances[cls] = cls(*args,**kwargs)
return instances[cls]
return getinstance
@singleton
class MyClass:
a = 1
c1 = MyClass()
c2 = MyClass()
print(c1 == c2) # True
在上面,我们定义了一个装饰器 singleton,它返回了一个内部函数 getinstance,
该函数会判断某个类是否在字典 instances 中,如果不存在,则会将 cls 作为 key,cls(*args, **kw) 作为 value 存到instances 中 ,否则,直接返回 instances[cls]。
(4)使用 metaclass(元类):
元类可以控制类的创建过程,它主要做三件事:
- 拦截类的创建
- 修改类的定义
- 返回修改后的类
class Singleton2(type):
def init (self, *args, **kwargs):
self. instance = None
super(Singleton2,self). init (*args, **kwargs)
def call (self, *args, **kwargs):
if self. instance is None:
self. instance = super(Singleton2,self). call (*args, **kwargs)
return self. instance
class Foo(object):
__metaclass = Singleton2 #在代码执行到这里的时候,元类中的 new 方法和 init 方法其实已经被执行了,而不是在 Foo 实例化的时候执行。且仅会执行一次。
foo1 = Foo()
foo2 = Foo()
print (Foo. dict ) #_Singleton instance': < main .Foo object at 0x100c52f10> 存在一个私有属性来保存属性, 而不会污染 Foo 类(其实还是会污染,只是无法直接通过 instance 属性访问)
print (foo1 is foo2) # True
单例模式优缺点
优点:
-
实例控制:单例模式会阻止其他对象实例化其自己的单例对象的副本,从而确保所有对象都访问唯一实例。
-
灵活性:因为类控制了实例化过程,所以类可以灵活更改实例化过程。
缺点:
-
开销:虽然数量很少,但如果每次对象请求引用时都要检查是否存在类的实例,将仍然需要一些开销。可以通过使用静态初始化解决此问题。
-
可能的开发混淆:使用单例对象(尤其在类库中定义的对象)时,开发人员必须记住自己不能使用 new 关键字实例化对象。因为可能无法访问库源代码,因此应用程序开发人员可能会意外发现自己无法直接实例化此类。
-
对象生成期:不能解决删除单个对象的问题。在提供内存管理的语言中(例如基于 .NET Framework 的语言),只有单例类能够导致单例类中出现悬浮引用。
33、实现一个简单的装饰器。
def setFunc(func):
def wrapper(*args,**kwargs):
print('wrapper context')
return func(*arg,**kwargs)
return wrapper
34、Restful接口设计风格?
答:域名尽量部署在专用域名下(如https://api.ethanyan.com),如果api很简单,而且不会有进一步的扩展,那么可以考虑放在主域名下(https://www.ethanyan.com/api/)。API版本号应该放入URL,但是也有放在HTTP请求头中的。资源路径,使用名词表示,而且要用其复数形式,一般都是和数据库的表名进行对应。请求方式使用GET表示获取资源;使用POST表示新建资源;PUT表示更新资源;DELETE表示删除资源。使用准确的状态码,比如201表示新建数据成功;204表示删除数据成功;403表示请求错误被限制等等常见状态码。要进行错误处理,比如状态码是4xx的,我们应该返回错误信息,并且以error为键名出错信息作为键值进行返回。返回结果也要有规范,如GET请求返回单个对象或者资源对象的列表,POST返回新建的资源对象,PUT返回完整的资源对象,DELETE返回一个空文档。使用超媒体,返回结果中要提供链接,连向其他API的方法,使得用户不查文档也能知道下一步做什么。返回的数据格式,尽量使用JSON。
35、列举一些常用的一些默认端口?
答:MySQL默认对口是3306,HTTP默认端口是80,HTTPS默认端口是443,Redis的默认端口是6379,MongoDB默认端口是27017。
36、什么是SQL注入,如何防止,ORM中如何防止?
答:SQL注入就是利用正常的SQL语句,获取到了非法的数据。防御措施大体有以下几点:对用户的输入进行校验,可以通过正则表达式或限制长度;对单引号和 --等特殊字符进行转义;不要动态的拼接SQL语句,使用参数化的SQL(下面的例子就是使用参数化解决SQL注入)查询数据库;永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的连接数据库;不要把机密的信息直接存放,而是经过hash加盐加密等措施保护敏感数据;应用的异常信息应该尽可能的少提示,最好使用自定义的错误信息对原始错误信息进行包装。(永远不要信任用户的任何输入,很有可能对面是一个想要攻击你的黑客!!!!)ORM底层其实是使用了参数化的形式执行SQL语句,而且ORM接口是属于内部封装机制,对外无接口,理论上很安全了,但是凡事没有绝对
举例说明SQL注入
我们在书写查询语句的时候,有可能涉及到占位符进行数据替换,后面接入用户输入的用户名和密码之类的数据:
select * from user where username = '%s' and password = '%s';
如果用户输入了一些特殊的字符,那么会产生一些严重的后果(拖库,直接获取到所有的数据)。比如用户的用户名输入了 root’ or 1 --,然后将其拼接到上述的SQL语句中,会出现下面的现象:
select * from user where username = 'root' or 1 -- ' and password = '%s';
– 代表注释的意思
上述查询条件where为 username='root’或者是 1,后面的密码因为 --的出现变成了注释,不会执行,因此只对用户名进行校验。username无论对与错,因为是逻辑运算符 或,后面 1代表真,判断条件永远成立,那么直接返回查询结果。
就问你可怕不可怕,当然上面只是利用简单的一个例子进行说明。你肯定会问,那么就不能防止SQL注入吗?答案是可以的。那就是参数化,问题又来了,什么是参数化呢?就是我们在python数据库编程的时候,将 SQL 语句的所有数据参数存在一个元组(或者列表、字典)中传递给 execute 函数的第二个参数。下面演示效果:
from pymysql import *
# 创建数据库连接
db_connect = Connect(host='localhost',port=3306,database='test_db',user='root',password='123123',charset='utf8')
# 获取游标
cur = db_connect.cursor()
# 请输入一个查询的ID
query_id = input('please input ID:')
# 使用参数化来解决SQL注入
# 以字符串形式书写SQL语句,因为SQL语句中也会出现字符串,避免单引号或者双引号的错误,我们直接使用三引号进行书写
sql_str = ''' select * from students where id = %s '''
# 在准备SQL字符串时,不能再直接拼接参数
# 而是将参数做成一个元组,列表,字典,传入到 execute 方法中
# 下面执行SQL语句,并传入元组形式的参数
cur.execute(sql_str, (query_id,))
# 获取所有的数据
result = cur.fetchall()
# 遍历出所有的结果
for t in result:
print(t)
# 关闭游标
cur.close()
# 关闭数据库
db_connect.close()
37、部署相关知识
部署方面最重要的知识分为两块,一块是Nginx,一块是Docker,下面就这两块内容,进行阐述。
1、Nginx
Nginx是一款基于异步框架的轻量级服务器,它支持高并发量,能高效的处理相关业务。平时我们用来做web服务器、缓存服务器以及反向代理服务器,当然它还能做邮件服务器。那么它除了支持高并发,还有什么优点吗?内存消耗少,配置简单还稳定,扔到远程服务器上基本就不用管了。如果公司想用有限的资源解决更多的问题,那么它是首选,因为它便宜啊,还支持多系统。最最重要的一点,就是它善于处理静态文件,因此我们常常将静态文件放到Nginx上,减少后端服务器的压力。
1.1相关命令
查看Nginx状态(active或者dead):
systemctl status nginx
启动|停止|重启|重新加载Nginx服务器:
systemctl start|stop|restart|reload nginx
其实上面的命令用来开启关闭还是太麻烦,那么可以使用下面的命令替换:
nginx 启动nginx -s stop|reload 停止|重载
检查配置文件是否符合语法要求(超级重要,在工作中只要配置文件发生改变,马上要执行的命令就是这个,检查完之后再重新启动。否则最后出错,难以排查问题):
nginx -t
查看当前系统下开启服务所占用端口的信息:
netstat -tnulp
配置文件目录:
/etc/nginx/conf.d
文件的结构要明白:
全局配置段
http配置段
server配置段 # 项目或者应用的网站
location配置段 # 网站里面的文件url
1.2 Nginx访问原理
浏览器拆分URL地址获取相关的请求。分为地址、端口和路径关键字。其中每个请求的目的是根据地址找服务器,根据端口找服务器上的应用,路径关键字用于location匹配。
url:
协议:// 网站地址:端口 (/)路径地址 ? 参数
server配置段:
server { listen 端口; server_name 主机名; ...}
location配置:
location optional_modifier location_match {...}
optional_modifier:匹配条件;location_match是匹配的样式;{…}:要执行的操作。
另外补充一点:location常见的动作中,alias 相当于 u r i 直接去 a l i a s 指定的目录下请求就可以了,是绝对路径。而 r o o t 则是到 r o o t 指定的目录下的 uri 直接去alias指定的目录下请求就可以了,是绝对路径。而root 则是到root指定的目录下的 uri直接去alias指定的目录下请求就可以了,是绝对路径。而root则是到root指定的目录下的uri/ 去找,是相对路径。
1.3正向代理&反向代理
从安全性来讲,正向代理可以保护客户端的身份,而反向代理则是保护服务器的身份。
我们翻阅天朝的墙时,使用的VPN就是正向代理。当我们爬取数据,采用高匿IP时,也是正向代理,毕竟要保护爬虫工程师的人生安全嘛。那么什么是反向代理呢?我们采用的Nginx就是反向代理啊?忘记了吗?
1.4Nginx代理模块
关键参数就是 proxy_pass,设定的是请求跳转后的地址,也就是被代理服务器的地址和被映射的URI。
server{ listen 99; location / { proxy_pass http://192.168.33.24:888/ethanyan/; }}
一定要注意 proxy_pass中的地址结尾处的 /。有没有结果大不相同。
1.5负载均衡(超级重要)
上面我们使用 proxy_pass的方式实现了Nginx反向代理,请求后端。当网站的访问量越来越多的时候,一台服务器就有点力不从心了,那么怎么办,就是采用负载均衡。简单的理解就是多准备几台服务器,就是这么简单粗暴。负载均衡就用到了我们Nginx中的 upstream模块。它定义了一个后端服务地址的集合列表,每个后端服务使用一个server命令指定。它还可以通过一系列的属性设置负载均衡中的主机情况。
down 当前主机故障时,直接进行隔离backup 后备主机,当线上主机故障或者访问量剧增服务器繁忙时,才开启max_fails 允许请求的最大失败数,默认是1,配合下一个参数使用fail_timeout 经历max_fails次失败后,暂停服务的时间,默认为10s。
最后说一个是常识,但是超级重要的命令:
curl [option] [url]如:curl http://www.ethanyan.com # 执行之后请求的页面内容就显示在屏幕上了,作为一个运维人员,或者一个后端服务器工程师,这个命令如果不晓得就说不过去了
1.6Nginx调度算法
内置策略:
轮询:默认算法,按服务器顺序依次转发相关请求。(要雨露均沾嘛)加权轮询:指定轮询权重,值越大,分配到的几率就越大,适合后端服务器性能不均衡的情况。ip_hash:按访问IP的哈希结果分配请求,让同一个IP访问固定一台服务器,有效的解决动态网页会话共享问题。
第三方算法:
fair:这个是按服务器的响应时间来分配请求的,当某一台服务器请求无延迟,直接就将请求交给他了。url_hash:按url的哈希结果来分配请求,使得同一个URL定向到同一台后端服务器,可提高后端缓存服务器的效率。
1.7日志
日志地址: /var/log/nginx
还可以定制日志,在下面的文件中进行配置:
/etc/nginx/nginx.conf
2、Docker
一提到Docker,你脑中蹦出来的词是什么呢?虚拟化、容器等等。如果是这些,那么说明你了解到了它的精髓。它没有固定的概念,曾有人这么描述:Docker是一种快速解决生产问题的技术手段。文绉绉,难以理解。
Docker其实就是将开发环境完整封装的一个容器,它解决了开发工程师和运维人员之间的甩锅操作,开发是什么样子,测试就是什么样子。还有部署项目的时候,怎么实现负载均衡,手动一台台配啊?那不得累死,直接将Docker搬过去啊,下载打开运行成功,立马搞定。
2.1相关操作
启动docker:
systemctl start docker
查看Docker的状态:
systemctl status docker
Docker服务命令:
docker start | stop | restart docker
删除命令:
你还真看啊,涉及到删除命令,哥劝你用的时候手动查一下,利用查询的时间思考一下
搜索镜像:
docker search [image_name]
先在本地仓库找,找不到去网络仓库找
获取镜像:
docker pull [image_name]
查看镜像:
docker images# 查看一个镜像docker images [image_name]
查看镜像历史信息:
docker history nginx
查看历史操作过的命令以及产生文件的大小
重命名,打标签:
docker tag [old_image]:[old_version] [new_image]:[new_version]
删除镜像:
docker rmi [IMAGE ID]或:docker rmi [image]:[image_version]
Docker的家目录:
/var/lib/docker
将Docker的镜像导出,进行备份:
docker save -o [包文件] [镜像]如:docker save -o nginx.tar ethanyan-nginx
导入镜像:
docker load < [image.tar_name]docker load --input [image.tar_name]
查看正在运行的容器:
docker ps
查看所有运行过的容器:
docker ps -a
启动容器;
docker run <参数,可选> [docker_image] [执行的命令]
# 让Docker容器在后台以守护形式运行docker run -d [docker_image]# 启动已经终止的容器docker start [container_id]
创建并进入到容器里面:
docker run --name [container_name] -it [docker_image] /bin/bash--name
给容器定义一个名字-i 让容器的标准输入保持打开-t 让docker分配一个伪终端,并绑定在容器的标准输入上
进入到容器里面:
docker exec -it <容器id> /bin/bash
关闭容器:
docker stop [container_id]
基于容器创建镜像:
docker commit -m <注释> -a <作者> [container_id] [new_image]:[new_version]
查看容器所有的详细信息:
docker inspect [container_name]
查看容器运行日志:
docker logs [container_id]
2.2私有仓库部署
1.下载registry镜像:
docker pull registry
2.启动容器:
docker run -d -p 5000:5000 --restart=always registry
–restart 代表的是什么时间重启
3.检查容器效果:
curl 127.0.0.1:5000/v2/_catelog
4.配置容器权限:
vim /etc/docker/daemon.json{"registry-mirrors":["http://74f21445.m.daocloud.io"], "insecureregistries":["192.168.8.14: 5000"]}
私有仓库ip地址是宿主机的ip,而且ip两侧要有双引号
5.重启docker服务:
systemctl restart dockersystemctl status docker
效果查看:
docker start <container_id>docker tag ubuntu-mini 192.168.33.24:5000/buntu-16.04-minidocker push 192.168.33.24:5000/ubuntu-16.04-minidocker pull 192.168.33.24:5000/ubuntu-16.04-mini
打标签时版本号如果不指定,默认是latest。
38、Celery底层原理
celery提供了一个task装饰器,对被修饰的函数添加delay 方法(将原任务方法名和参数保存到redis的list中)。
在celery的redis消息队列中,利用了redis的列表类型的 lpush和 brpop操作。任务发出者向列表中通过lpush加入任务。而任务执行者则是通过brpop操作按顺序异步执行任务。因为lpush可以形象的理解为从左向右推入元素,brpop则是从右侧取元素,保证了任务添加的顺序不会乱。Brpop命令:
brpop <list>.... <timeout>
Redis Brpop 命令移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
假如在指定时间内没有任何元素被弹出,则返回一个 nil 和等待时长。 反之,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的 key ,第二个元素是被弹出元素的值。
39、数据库事务
事务 Transaction 是指作为一个基本工作单元执行的一系列SQL语句的操作,要么完全地执行,要么完全地都不执行。事务的四大特性(ACID):原子性、一致性、隔离性、持久性。
一个简单的例子(三个步骤打包为一个事务,任何一个失败,则必须回滚所有):
1. 检查支票账户的余额高于或者等于200美元。
2. 从支票账户余额中减去200美元。
3. 在储蓄帐户余额中增加200美元。
1.原子性(Atomicity)
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
2.一致性(Consistency)
数据库总是从一个一致性的状态转换到另一个一致性的状态。(在前面的例子中,一致性确保了,即使在执行语句时系统崩溃,支票账户中也不会损失200美元,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。)
3.隔离性(Isolation)
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。(在前面的例子中,一个事务未完成,此时有另外的一个账户汇总程序开始运行,则其看到支票帐户的余额并没有被减去200美元。)
4.持久性(Durability)
一旦事务提交,则其所做的修改会永久保存到数据库。(此时即使系统崩溃,修改的数据也不会丢失。)
39.1、事务的操作
开启事务(开启事务后执行修改命令,变更会维护到本地缓存中,而不维护到物理表中):
begin;或:start transaction;
提交事务(将缓存中的数据变更维护到物理表中):
commit;
回滚事务(放弃缓存中变更的数据 表示事务执行失败 应该回到开始事务前的状态):
rollback;
40、MySQL数据库索引
数据库索引是什么大家应该都已经知道。为什么建立索引,大家应该张口就来。算了,我还是简简单单的说一下吧:
数据库索引可以理解为数据库中一种排序的数据结构。它的存在就是为了协助快速查询、更新数据库表中的数据。优化查询效率。(简直和废话一样,谁不知道索引就像新华字典前面的音节索引和部首检字表一样…)
那么索引的原理呢?什么时候创建索引呢?索引有哪些呢?这些你想过吗?不知道就对了,我也不知道(会不会被打死…)。
MySQL中的索引用到了B+树、哈希桶等索引数据结构,但是主流还是B+树。那么为什么B+树适合做数据库索引呢?
1.B+树使得IO读写次数变少。
+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对于B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2.B+树查询效率稳定。
搜索任何一个关键字,所走的路径长度是一样的,也就是说查每一个数据的效率相同。
3.B+树只需要遍历叶子节点(也就是最底层没有子节点的节点)就可以达到遍历整棵树的目的,这也解决了数据库的范围查询问题,而B数是不支持这样的操作的。
什么时候建立索引,什么时候少建或者不建索引呢?
1.表记录太少的话,不要建立索引了,因为建立索引表会增加查询的步骤,处理变慢;
2.经常插入、删除、修改的表尽量少的建立索引,因为索引表的维护也会降低性能;
3.对于那些数据都是重复且分布平均的字段,比如一个字段只有True和False两种数据,但是记录超多(假设100万行),这样建立索引是提高不了查询速度的;
4.不要将超多的字段建立在一个索引里,它会增加数据修改、插入和删除的时间的。
5.对于百万、千万级的数据库建立索引,相信我,它会有质的飞跃。
6.对于不会出现在where条件中的字段不要建立索引,不要再增加索引表的体积了。
40.1创建索引的语句
1.1 ALTER TABLE
1.创建普通的索引
alter table <table_name> add index <index_name> (`字段名`);
2.创建多个索引
alter table <table_name> add index <index_name> (`column`,`column1`,`column_N`.......);
3.创建主键索引
alter table <table_name> add primary key (`字段名`);
4.创建唯一索引
alter table <table_name> add unique (`字段名`);
5.创建全文的索引
alter table <table_name> add fulltext (`字段名`);
1.2 CREATE INDEX
1.增加普通索引
create index <index_name> on table_name (`字段名`)
2.增加UNIQUE索引
create unique index <index_name> on <table_name> (`字段名`)
CREATE INDEX中索引名必须指定,而且只能增加普通索引和UNIQUE索引,不能增加PRIMARY KEY索引。
40.2、删除索引
drop index <index_name> on <table_name>;
alter table <table_name> drop index <index_name>;
alter table <table_name> drop primary key;
41、算法
1、算法的五大特性
输入:算法具有0个或多个输入。
输出:算法至少有一个输出。
有穷性:算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成。
确定性:算法中的每一步都有确定的含义,不会出现二义性。
可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限次数完成。
2、冒泡排序的思想
冒泡排序的过程,就好像咱们喝汽水时,那些小气泡一点一点从下往上的冒,最后到了最顶部。这只是一种形象的类比,用实际的例子来说明一下。假如有一个列表,其中的数字是无序排列的,通过冒泡要实现的结果就是将列表中的数字从小到大排序。
那么怎么实现呢?我们可以将列表中左侧第一个和第二个数字先进行比较,将较小的排在左侧;然后再比较第二个和第三个数字,较小的排在左侧,再比较第三个和第四个…将列表中的数字第一轮比较完之后,最大的数,排在了列表的最尾端。然后重复上面的步骤,但是尾端最大的数不再参与比较,一轮一轮的比较完之后,实现将列表中的数字从小到大排序后的效果。这样是不是最小的数一点一点从后往前冒了呢?
冒泡的最优时间复杂度为O(n),最坏时间复杂度为O(n^2)。空间复杂度为O(1)。
那么下面使用代码实现一个冒泡排序:
def bubble_sort(alist):
for j in range(len(alist)-1,0,-1):
for i in range(j):
if alist[i] > alist[i+1]:
alist[i],alist[i+1] = alist[i+1],alist[i]
print(alist)
alist = [23,13,1,3,5,2,1,7]
bubble_sort(alist)
print(alist)
------结果--------
[1, 1, 2, 3, 5, 7, 13, 23]
其中 range(len(alist)-1,0,-1)大家可能不是很理解。我下面举例说明一下:
for i in range(3,0,-1):
print(i,end=',')
输出的结果为:
3,2,1,
结合上面的例子,我们可以看出 range(3,0,-1)其实是 [3,0)进行倒序,因为区间是左闭右开,所以0取不到,相当于对区间 (0,3]进行倒序。
3、快速排序的思想
快速排序的方法和冒泡排序类似,也属于交换排序。也就是通过不断的比较元素之间的大小,同时不断的交换元素的位置,实现排序的效果。那么它为什么叫快速排序呢?因为它快啊!(…很欠揍的样子)
我们简单的了解一下快速排序。快速排序就是先找到一个基准(一般来说拿列表中的第一个元素先做为基准),然后利用这个基准,将列表中的元素分为两部分。一部分(这部分中的元素每一个都要比基准大)放在基准的右侧;另一部分(这一部分中的元素都比基准小)放在基准左侧。第一轮划分完毕,第二轮会将左部分和右部分再次进行第一轮的步骤。然后不断的划分啊划分啊划分啊…直到最后列表中的元素变成了有序,就结束排序。
看到了上面的步骤是不是发现一个问题?这不就是我们的递归思想吗?对的,稍后我们就利用递归的方法实现一个快速排序。
快速排序的最优时间复杂度为O(nlogn),最坏时间复杂度为O(n^2),空间复杂度为O(logn)。它是不稳定的。
下面使用代码实现一个快速排序:
# ==============快速排序==================
def quick_sort(alist, start, end):
# 递归的退出条件
if start >= end:
return
# 设定起始元素为要寻找位置的基准元素
mid = alist[start]
# low为序列左边的,由左向右移动的游标
low = start
# high为序列右边的,由右向左移动的游标
high = end
while low < high:
# 如果low与high未重合,high指向的元素比基准元素大,则high向左移动
while low < high and alist[high] >= mid:
high -= 1
# 当high指向的元素比基准元素小了
# 将high指向的元素放到low的位置上
alist[low] = alist[high]
# 如果low与high未重合,low指向的元素比基准元素小,则low向右移动
while low < high and alist[low] < mid:
low += 1
# 当low指向的元素比基准元素大了
# 将low指向的元素放到high的位置上
alist[high] = alist[low]
# 退出循环后,low与high重合,此时所指位置为基准元素的正确位置
# 将基准元素放到该位置
alist[low] = mid
# 对基准元素左边的子序列进行快速排序
quick_sort(alist, start, low-1)
# 对基准元素右边的子序列进行快速排序
quick_sort(alist, low+1, end)
alist = [54,26,93,17,77,31,44,55,20]
quick_sort(alist,0,len(alist)-1)
print(alist)
python中没有指针的概念,上述代码中的游标就类似于指针的效果。
本次使用的方法和c语言中的“挖坑法”类似。当然还有其他的很多方法,大家可以查阅相关资料进行学习。
4、插入排序
插入排序是一种简单直观的排序方法,我想说一句废话(插入排序就是通过插入来实现排序),想了想还是忍住了。插入排序的思路是什么样的呢?下面且听我慢慢道来。
有一个无序列表,让我们将其中的元素从小到大进行排序。使用插入排序,首先将从左到右的第一个元素所在的区域叫做有序区,其他的元素在的区域叫做无序区。然后将无序区中的元素从左到右开始取,取出来一个元素就将其放在有序区的合适位置(比如无序区取了一个3,有序区有两个数字1和4,那么我们就将3放到1和4之间)。不断的从无序区取,向有序区合适位置插,直到最后无序区没有值了,列表也就变成了有序列表。
最优时间复杂度为O(n),最坏时间复杂度为O(n^2),具有稳定性。
那么用代码实现一个插入排序:
def insert_sort(alist):
# 从第二个位置,即下标为1的元素开始向前插入
for i in range(1, len(alist)):
# 从第i个元素开始向前比较,如果小于前一个元素,交换位置
for j in range(i, 0, -1):
if alist[j] < alist[j-1]:
alist[j], alist[j-1] = alist[j-1], alist[j]
5、选择排序
有了上面算法的基础,选择排序理解就没那么难了。
同样有一个无序列表,我们需要对其从小到大进行排序。使用选择排序的话,我们先从列表中挑选出一个最大值,然后将其和列表最尾端的值进行调换。最后一个元素就是最大值,毫无悬念,它找到了自己的最终归属,不需要再参与排序(它所在的区域叫做有序区,剩余元素处于无序区)。剩下的元素再挑选一个最大值,将其放到放到有序区的合适位置…不断的重复以上步骤,直到所有的元素放到有序区,得到了一个有序列表,完成我们的需求。
最优时间复杂度为O(n2),最坏时间复杂度为O(n2),不稳定。
代码实现:
def selection_sort(alist):
n = len(alist)
# 需要进行n-1次选择操作
for i in range(n-1):
# 记录最小位置
min_index = i
# 从i+1位置到末尾选择出最小数据
for j in range(i+1, n):
if alist[j] < alist[min_index]:
min_index = j
# 如果选择出的数据不在正确位置,进行交换
if min_index != i:
alist[i], alist[min_index] = alist[min_index], alist[i]
6、希尔排序
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因 DL.Shell于1959年提出而得名。 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
最优时间复杂度根据步长序列的不同而不同,最坏时间复杂度为O(n^2),不稳定。
看完后你心中肯定有一万头草泥马在奔腾了,一定想说『说人话!』好吧,还是用个例子说明一下希尔排序的思想吧…
希尔排序的基本思想是:将数组列在一个表中并对列分别进行插入排序,重复这过程,不过每次用更长的列(步长更长了,列数更少了)来进行。最后整个表就只有一列了。将数组转换成表是为了更好地理解这算法,算法本身还是使用数组进行排序。
例如,假设有这样一组数[ 13,14,94,33,82,25,59,94,65,23,45,27,73,25,39,10 ],如果我们以步长为5开始进行排序,我们可以通过将这些数放在有5列的表中来更好地描述算法,这样他们就像下面了:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
将上述四行数字,依序接在一起时我们得到:[ 10,14,73,25,23,13,27,94,33,39,25,59,94,65,82,45 ]。这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45
再次对列进行排序,变为下面这样:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94
然后将上面的6行数字在衔接在一起:[ 10,14,13,25,23,33,27,25,59,39,65,73,45,94,82,94 ]。然后我们以1为步长进行排序,此时就是简单的插入排序了。最后结果为:
[10, 13, 14, 23, 25, 25, 27, 33, 39, 45, 59, 65, 73, 82, 94, 94]
我们使用代码实现一个希尔排序:
def shell_sort(alist):
n = len(alist)
# 初始步长
gap = n // 2
while gap > 0:
# 按步长进行插入排序
for i in range(gap, n):
j = i
# 插入排序
while j>=gap and alist[j-gap] > alist[j]:
alist[j-gap], alist[j] = alist[j], alist[j-gap]
j -= gap
# 得到新的步长
gap = gap // 2
alist = [ 13,14,94,33,82,25,59,94,65,23,45,27,73,25,39,10 ]
shell_sort(alist)
print(alist)
7、桶排序
当列表中的数值取值范围太大,或者不是整数的时候,可以使用桶排序来解决问题。
桶排序基本思想就是将一个大区间划分成n个相同大小的子区间,称为桶。将n个记录分布到各个桶中。如果有多于一个记录被分到同一个桶中,需要进行桶内排序。最后依次把各个桶中的记录列出来就得到有序序列。
其实就是预先准备很多“桶”,然后把无序列表中的数,按照对应的区间放入桶中,桶里的数超过两个了,那么桶内再进行排序,然后将所有的数按照“桶”的顺序排列出来(一个桶内有多个数据的,按照桶内排好的顺序依次取出)。这是典型的以空间换时间,进行排序的数变少了,效率高了,时间就短了,但是占据了很多空间。
8、归并排序
归并排序采用了分而治之的思想,先递归分解无序列表,再合并列表。我们先来看一下两个有序的列表如何进行合并:
1.我们有两个列表:
list1 = [3,5,7,8]
list2 = [1,4,9,10]
2.为了合并,我们需要再建立一个空列表。
list = []
3.然后就是将两个有序列表list1和list2分别从左到右比较两个列表中哪一个值比较小,然后复制进新的列表中:
# 一开始新列表是空的
['3',5,7,8] ['1',4,9,10] []
# 然后两个指针分别指向第一个元素,进行比较,显然,1比3小,所以把1复制进新列表中:
['3',5,7,8] [1,'4',9,10] [1]
# list2的指针后移,再进行比较,这次是3比较小:
[3,'5',7,8] [1,'4',9,10] [1,3]
# 同理,我们一直比较到两个列表中有某一个先到末尾为止,在我们的例子中,list1先用完。
[3,5,7,8] [1,4,'9',10] [1,3,4,5,7,8]
# 最后把list2中剩余的元素复制进新列表即可。
[1,3,4,5,7,8,9,10]
为了突出比较的过程,我们将比较时的数字加了引号,其实它是int类型。由于前提是这两个列表都是有序的,所以整个过程是很快的。
上面就是归并排序中最主要的想法和实现了。接下来我们完整的对归并排序进行描述:
有一个列表,我们将其对半分,不断的重复这个过程,问题的规模就越来越小,直到分成了一个一个的数字(一个数字就相当于排好序了),接下来呢,就是类似于上面的过程了,两两合并,然后再两两合并,直到最后合并为一个有序的列表。正所谓天下之势,分久必合合久必分。现在有了一个了解了吧?
最优时间复杂度为O(nlogn),最坏时间复杂度为O(nlogn),稳定。
代码实现:
def merge_sort(alist):
if len(alist) <= 1:
return alist
# 二分分解
num = len(alist)//2
left = merge_sort(alist[:num])
right = merge_sort(alist[num:])
# 合并
return merge(left,right)
def merge(left, right):
'''合并操作,将两个有序数组left[]和right[]合并成一个大的有序数组'''
#left与right的下标指针
l, r = 0, 0
result = []
while l<len(left) and r<len(right):
if left[l] < right[r]:
result.append(left[l])
l += 1
else:
result.append(right[r])
r += 1
result += left[l:]
result += right[r:]
return result
alist = [54,26,93,17,77,31,44,55,20]
sorted_alist = merge_sort(alist)
print(sorted_alist)
---------------------------
[17, 20, 26, 31, 44, 54, 55, 77, 93]
9、计数排序
对于那些数值取值范围不是很大的整数构成的列表怎么进行排序呢?那就是计数排序了,它的性能甚至会超过那些O(nlogn)的排序。神奇吧?
它是通过列表的下标来确定元素的正确位置。假如有一个列表,它由20个随机整数构成,且每个元素的取值范围从0到10。利用计数排序,我们可以建立一个长度为11的新列表,新列表下标从0到10上的元素初始值都为0。然后遍历无序的列表,每一个整数按照其值在新列表中进行对号入座,新列表中对应下标的元素进行加1操作(比如整数2,那么新列表中下标为2的元素由原来的0加1后变为了1;如果再有个整数2,那么下标为2的元素由原来的1加1变为了2。类似这样的操作,直到无序列表中所有的整数遍历完)。
新列表中每一个下标位置的值,代表的是无序列表中该整数出现的次数(下标的值与无序列表中对应的整数相等)。最后将新列表进行遍历,注意输出的是下标值,下标对应的元素是几,该下标就输出几次,遍历完成,无序列表变为了有序。
不适用于计数排序的情况:
1.当列表中最大值和最小值差距过大时;
2.当列表中元素不是整数时;
如果原始列表的规模是N,最大值和最小值的差是M的话,计数排序的时间复杂度和空间复杂度是多少呢?
答:时间复杂度为O(N+M),空间复杂度如果只考虑统计列表大小的话,为O(M)。
42、数据结构与算法
1.链表
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是不像顺序表一样连续存储数据,而是在每一个节点(数据存储单元)里存放下一个节点的位置信息(即地址)。
顺序表:将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由它们的存储顺序自然表示。
举个栗子:4个小伙伴(B是A的朋友,C是B的朋友,D是C的朋友。是挺尴尬哈…)去电影院买票,正好有四个连座,他们很开心,然后很自然的A挨着B,B挨着C…就这么坐了,愉快的看了场『霸王别姬』。这就是顺序表。
第二天,又想看电影了,但是很不凑巧,只剩下几个散座了,他们商量了一下,还是买了吧,毕竟『飞驰人生』挺好看的,然后他们就拿着票分开坐了。由于前面提到的尴尬关系,A手机里有B的联系方式,B手机里有C的联系方式…虽然没挨着,但是他们都有朋友的联系方式,知道朋友在哪里坐着。这就是链表。
链表呢,又分为了单向链表、双向链表、单向循环链表。我们下面看看它们分别是什么样子的。
1.1单向链表
单向链表也叫单链表,是链表中最简单的一种形式,它的每个节点包含两个域,一个信息域(元素域)和一个链接域。这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值。就像我们上面的那个甜栗子,4个尴尬的朋友分开坐的那种情况,如果A手机里有B的手机号,但是B手机里没有A的,B手机里有C的手机号,但是C没有B的…也就是只有从A开始,他们才能找到所有人,这就是单向链表。
表元素域elem用来存放具体的数据。
链接域next用来存放下一个节点的位置(python中的标识)。也就是例子中存放他们的联系方式的手机。
变量p指向链表的头节点(首节点)的位置,从p出发能找到表中的任意节点。
1.1.1单向链表的操作
is_empty() 链表是否为空
length() 链表长度
travel() 遍历整个链表
add(item) 链表头部添加元素
append(item) 链表尾部添加元素
insert(pos, item) 指定位置添加元素
remove(item) 删除节点
search(item) 查找节点是否存在
1.1.2链表和顺序表的对比
链表的优点就是,四个小伙伴即使没有连座了,也能看上电影,对于存储空间的使用相对灵活。但是缺点也显而易见,那就是他们想联系别人,需要用手机存朋友的手机号,而保存手机号浪费了手机的内存(16G的手机伤不起啊)。链表增加了结点的指针域,空间开销大一丢丢。而且,如果他们连着坐,想找谁直接就找到了,而分开坐的话,不能随机找,只能从A开始一个接一个的找。链表失去了顺序表随机读取的优点。
1.2双向链表
一种更复杂的链表是“双向链表”或“双面链表”。每个节点有两个链接:一个指向前一个节点,当此节点为第一个节点时,指向空值;而另一个指向下一个节点,当此节点为最后一个节点时,指向空值。
看到单向链表例子的时候,你一定心里想:这四个傻缺,A手机存B的手机号,B怎么就不存A的?也许听到了你骂他们吧。现在B也存了A的手机号,C也存了B的手机号,D也存了C的手机号。
咱们现在屡屡哈,有点乱。现在那四个小伙伴是这么个状态:A和B互为盆友,B和C互为盆友,C和D互为盆友,盆友之间彼此都存了对方的手机号(A、B、C、D是4个人,没错…)。他们又没买到连座的票,然后就分开坐了,现在他们的状态就是双向链表。
1.2.1双向链表的操作
is_empty() 链表是否为空
length() 链表长度
travel() 遍历链表
add(item) 链表头部添加
append(item) 链表尾部添加
insert(pos, item) 指定位置添加
remove(item) 删除节点
search(item) 查找节点是否存在
1.3单向循环链表
单链表的一个变形是单向循环链表,链表中最后一个节点的next域不再为None,而是指向链表的头节点。
还是那4个小伙伴,都是『表面兄弟』。B删了A的手机号(B心里想:浪费我16G华为手机的内存,你能联系到我不就好了吗?);C也这么想,删除了B的手机号;巧了,D也把C的手机号删了。回到了单向链表的状态(A有B的联系方式,B有C的联系方式,C有D的联系方式)。都看了这么多场电影了,D看上了A(是个甜甜的妹子),然后D要了A的手机号,保存了下来,哈哈哈哈,活该B单身,还删小姑娘的手机号(笑出了猪一般可爱的声音…)。
现在他们的状态就是单向循环链表了。
2.二叉树
二叉树大家一定都不陌生,就是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。下面的这样子就是二叉树。

二叉树的性质
性质1:在二叉树的第i层上至多有2^(i-1)个结点(i>0)
性质2:深度为k的二叉树至多有2^k - 1个结点(k>0)
性质3:对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
性质4:具有n个结点的完全二叉树的深度必为 log2(n+1)
性质5:对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根,除外)
(1)完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
2.1 广度、深度的计算
import queue
class Node:
def __init__(self,value=None,left=None,right=None):
self.value=value
self.left=left
self.right=right
def treeDepth(tree):
if tree==None:
return 0
leftDepth=treeDepth(tree.left)
rightDepth=treeDepth(tree.right)
if leftDepth>rightDepth:
return leftDepth+1
if rightDepth>=leftDepth:
return rightDepth+1
def treeWidth(tree):
curwidth=1
maxwidth=0
q=queue.Queue()
q.put(tree)
while not q.empty():
n=curwidth
for i in range(n):
tmp=q.get()
curwidth-=1
if tmp.left:
q.put(tmp.left)
curwidth+=1
if tmp.right:
q.put(tmp.right)
curwidth+=1
if curwidth>maxwidth:
maxwidth=curwidth
return maxwidth
if __name__=='__main__':
root=Node('D',Node('B',Node('A'),Node('C')),Node('E',right=Node('G',Node('F'))))
depth=treeDepth(root)
width=treeWidth(root)
print('depth:',depth)
print('width:',width)
2.2 二叉树的遍历
树的遍历是树的一种重要的运算。所谓遍历是指对树中所有结点的信息的访问,即依次对树中每个结点访问一次且仅访问一次,我们把这种对所有节点的访问称为遍历(traversal)。那么树的两种重要的遍历模式是深度优先遍历和广度优先遍历,深度优先一般用递归,广度优先一般用队列。一般情况下能用递归实现的算法大部分也能用堆栈来实现。
2.2.1深度优先遍历
对于一颗二叉树,深度优先搜索(Depth First Search)是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
那么深度遍历有重要的三种方法。这三种方式常被用于访问树的节点,它们之间的不同在于访问每个节点的次序不同。这三种遍历分别叫做先序遍历(preorder),中序遍历(inorder)和后序遍历(postorder)。我们来给出它们的详细定义,然后举例看看它们的应用。
先序遍历 :在先序遍历中,我们先访问根节点,然后递归使用先序遍历访问左子树,再递归使用先序遍历访问右子树。
根节点->左子树->右子树
def preorder(self, root):
"""递归实现先序遍历"""
if root == None:
return
print root.elem
self.preorder(root.lchild)
self.preorder(root.rchild)
中序遍历 :在中序遍历中,我们递归使用中序遍历访问左子树,然后访问根节点,最后再递归使用中序遍历访问右子树。
左子树->根节点->右子树
def inorder(self, root):
"""递归实现中序遍历"""
if root == None:
return
self.inorder(root.lchild)
print root.elem
self.inorder(root.rchild)
后序遍历: 在后序遍历中,我们先递归使用后序遍历访问左子树和右子树,最后访问根节点。
左子树->右子树->根节点
def postorder(self, root):
"""递归实现后续遍历"""
if root == None:
return
self.postorder(root.lchild)
self.postorder(root.rchild)
print root.elem
2.2.2广度优先遍历
从树的root开始,从上到下从从左到右遍历整个树的节点
def breadth_travel(self):
"""利用队列实现树的层次遍历"""
if root == None:
return
queue = []
queue.append(root)
while queue:
node = queue.pop(0)
print node.elem,
if node.lchild != None:
queue.append(node.lchild)
if node.rchild != None:
queue.append(node.rchild)
3.栈
栈(stack),有些地方称为堆栈,是一种容器,可存入数据元素、访问元素、删除元素,它的特点在于只能允许在容器的一端(称为栈顶端指标,英语:top)进行加入数据(英语:push)和输出数据(英语:pop)的运算。没有了位置概念,保证任何时候可以访问、删除的元素都是此前最后存入的那个元素,确定了一种默认的访问顺序。就好像咱们在Redis中的列表, lpush操作放进去元素,最后 lrange取的时候变成了倒序。忘了?没关系,给你讲小故事啊。
如果是在北京,一定体验过早晚高峰,挤地铁的痛苦吧?那个酸爽。有时,好不容易到站了,要下车,硬生生又被挤上了车!!!!告诉你们个秘密,我上地铁,从来都是靠着门口侧边的栏杆,因为我怕下不去车,哈哈哈哈哈。跑偏了,这不是介绍生活小妙招,是要讲栈。
举一个不严谨的例子,地铁的一节车厢每到一站只开一个门,这就是栈。大家都挤上去了,下车的时候一定是最后上的那个先下(不管你到没到站)。
3.1栈的操作
Stack() 创建一个新的空栈
push(item) 添加一个新的元素item到栈顶
pop() 弹出栈顶元素
peek() 返回栈顶元素
is_empty() 判断栈是否为空
size() 返回栈的元素个数
43、@classmethod和@staticmethod?
@classmethod用来标识类方法,对于类方法,第一个参数必须是类对象,一般用 cls作为第一个参数。 cls参数用来调用类的属性,类的方法等等。类方法可以通过实例对象和类对象去访问。类方法还可以对类属性进行修改。@staticmethod修饰的方法为静态方法,该方法不强制要求传递参数,可以通过对象和类来访问。在静态方法中引用类属性的话,必须通过类来引用。
44、谈一谈python中的元类
答:一般来说,我们都是在代码里定义类,用定义的类来创建实例。而使用元类,步骤有些不同,定义元类,用元类创建类,再使用创建出来的类来创建实例。元类的主要目的就是当创建类时能够自动地改变类。
45、with open执行原理
答:使用了with上下文管理器。上下文管理器的工作机制便是使用了python的方法: __enter__和 __exit__两个方法。
上下文管理器简单的理解就是一个操作环境。在文件操作时,需要打开、关闭文件,而在文件进行读写操作时,就处于文件操作的上下文中,也就是文件操作环境中。
__enter__方法会在执行 with 后面的语句时执行,一般用来处理操作前的内容。比如一些创建对象,初始化等。在with open的时候就是打开文件的操作。__exit__方法会在 with 内的代码执行完毕后执行,一般用来处理一些善后收尾工作,比如文件的关闭,数据库的关闭等。在with open的时候就是关闭文件的操作。
自定义一个上下文管理器,模拟文件打开过程:
class MyOpen(object):
def __init__(self,file,mode):
self.__file = file
self.__mode = mode
def __enter__(self):
print('__enter__run... open the file')
self.__handle = open(self.__file,self.__mode)
return self.__handle
def __exit__(self,exc_type,exc_val,exc_tb):
print('__exit__.run... close the file')
self.__handle.close()
with MyOpen('test','w') as f:
f.write('欢迎来到 <亦向枫的博客>')
print('over')
46、状态码中301和302的区别?
答:301是永久重定向,302是临时重定向。
47、python中的列表底层实现原理
python中的列表底层采用了顺序表。那么什么是顺序表呢?顺序表是线性表存储的一种方式。那么什么是线性表呢?(怎么问题这么多…)线性表就是存储着一些元素的集合(不光有元素,还有元素的顺序关系)。
为了了解底层实现原理,首先来了解顺序表吧。假如班主任在统计班级同学信息,统计完之后在教室前面贴了一张表,表上写的是班级能容纳学生的数量以及现有同学的数量,教室和这张表就构成了顺序表。
一个顺序表的完整信息包括两部分,一部分是表中的元素集合,另一部分是为实现正确操作而需记录的信息,即有关表的整体情况的信息,这部分信息主要包括元素存储区的容量和当前表中已有的元素个数两项。
了解完顺序表之后,我们了解一下顺序表的实现方式。顺序表实现方式有两种,分别是一体式结构和分离式结构。

一体式就是教室前面的那张表被用胶水粘死了,他和教室融为了一体,在教室前面。
一体式结构,存储表信息的单元与元素存储区以连续的方式安排在一块存储区里,两部分数据的整体形成一个完整的顺序表对象。
分离式就是表在班主任办公桌上,教室在…(不管你爱还是不爱,教室就在那里…),万一换教室了,班主任改一下表上的信息就好了。如果是一体式,哈哈哈,再做一张表吧,总不能为了看班级的信息,天天跑去改为了2班的教室吧…
上面涉及到了元素存储区的一个替换。就是假如我们想更换数据区,也就是教室要从南校区搬迁到北校区了。那张表十分珍贵,被班主任糊涂的写在了乾隆年间的一张草纸上,世界上再无第二张,但是又被死死粘在了墙上,怎么办,教室和那张纸一起搬走(有点暴力哈,不要和我说为什么不把墙皮弄下来…我任性,我就要整体搬迁,谁让是我写的故事呢…哼),这就是一体式结构的元素存储区替换。分离式呢?教室搬迁到了北校区,但是老师的办公室在南校区,这张表还在老师的办公桌上,老师只需要小手一挥,将南校区1班改为北校区1班即可。
一体式结构由于顺序表信息区与数据区连续存储在一起,所以若想更换数据区,则只能整体搬迁,即整个顺序表对象(指存储顺序表的结构信息的区域)改变了。
分离式结构若想更换数据区,只需将表信息区中的数据区链接地址更新即可,而该顺序表对象不变。
python中的列表就是采取了分离式技术实现的动态顺序表。之所以你可以根据下标随意的访问和更新数据,时间复杂度为O(1),特别快,是因为顺序表中的元素保存在一块连续的存储区中。为了可以任意加入元素,而且在不断加入元素过程中,表对象的id不变,那就只能采用分离式实现。也就是班主任的表就在班主任办公桌上,不变。当班级里的学生太多了需要换教室,随便换,不需要暴力的将整个房子搬走了。
48、给定一个列表,使用sort对其进行去重操作,从最后一个元素开始
ids = [1,4,3,3,4,2,3,4,5,6,1]
ids.reverse()
news_ids = list(set(ids))
news_ids.sort(key=ids.index)
print(news_ids)
----------------
[1, 6, 5, 4, 3, 2]
sort()函数
语法:
list.sort(self,key=None,reverse=False)
用于对原列表进行排序。
key — 指定可迭代对象中的一个元素来进行排序。像上面的代码一样,指定了列表的索引排序,所以顺序就是题目要求的顺序。
reverse — True代表降序,False代表升序。
49、判断一个字符串是不是回文
先来讲解一下什么是回文字符串,可以简单的理解为对称的字符串。下面的这些都是回文字符串:
'a’由一个元素组成的字符串; abccba偶数个元素的字符串左右对称; abcdcba奇数个元素的字符串中间元素两边对称。
def is_palindrom(s):
"""判断回文数,递归法"""
if len(s) < 2:
return True
if s[0] == s[-1]:
return is_palindrom(s[1:-1])
else:
return False
50、python中map和reduce?
map()是python内置的高阶函数,它接收一个函数f和一个list,并通过把函数f依次作用在list的每个元素上,得到一个新的list并返回。(python3中返回的迭代器)2. reduce()函数接收的参数和 map()类似,一个函数f和一个list,但行为和 map()不同, reduce()传入的函数f必须接收两个参数, reduce()对list的每个元素反复调用函数f,并返回最终结果的值。python3使用 reduce需要导入,在 functools中。
51、多态
答:定义时的类型和运行时的类型不一样,此时就是多态。python中,多态就是弱化类型,重点在于对象参数是否有指定的属性和方法,如果有,就认定合适,而不关心对象的类型是否正确。
52事务隔离级别。
MySQL数据库事务隔离级别主要有四种:
Serializable (串行化),一个事务一个事务的执行。
Repeatable read (可重复读),无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务影响。
Read committed (读取已提交),其他事务提交了对数据的修改后,本事务就能读取到修改后的数据值。
Read uncommitted (读取为提交),其他事务只要修改了数据,即使未提交,本事务也能看到修改后的数据值。
MySQL数据库默认使用可重复读( Repeatable read)。
53、Django中ORM如何使用?
Django中内嵌了ORM框架,不需要直接面向数据库编程,而是定义模型类,通过模型类和对象完成数据表的增删改查操作。
使用Django进行数据库开发的步骤如下:
1.配置数据库连接信息。
2.在 models.py中定义模型类。
3.迁移。
4.通过类和对象完成数据增删改查操作。
定义模型类时,我们继承了 models.Model,这个模块在 django.db中。我们在查询操作时,需要导入模型类,通过类和对象完成数据增删改查。
54、多继承写法以及继承顺序问题。
答:在多继承时,我们的书写方式:
class Son(Master, Father):
pass
python中多采用新式类,多继承的时候按照上面的方式进行书写。
多继承会继承所有父类的属性和方法。如果多个父类中有同名的属性和方法,则默认使用第一个父类的属性和方法。我们可以根据 mro(是一个魔法方法,称为方法解析顺序,用来获取当前类的方法继承顺序)来查看继承顺序。
55、析构函数
答:析构函数就是当对象结束其生命周期,比如对象所在的函数已经调用完毕,程序结束时,系统自动执行析构函数。在python中,当一个对象的引用计数为0的时候, __del__会被自动调用。 __del__就是一个析构函数。
56、继承,在执行析构函数时,先执行父类的,还是先执行子类的?
答:析构时,会先调用子类的析构函数,再调用父类的。
初始化子类时,会先自动调用父类的构造函数,然后调用子类的构造函数。
57、继承时,所有的方法都会被继承吗?
答:不会,比如构造函数和析构函数,它们不能被继承。
58、range(0,20)[2:-2]执行结果?
python3中range返回的是一个可迭代对象,python2中则是返回一个列表。
结果:range(0,20)[2:-2]range(2, 18)
59、写出下面代码执行结果
[1,2,3,5,6,7,8][2:-2]
结果为:
[3,5,6]
60、将一个列表去重,并按原始顺序排序
alist = [2,5,6,3,2,6,3,2,8]
new_list = list(set(alist))new_list.sort(key=alist.index)
print(new_list)
>>>[2, 5, 6, 3, 8]
61、简单谈谈ACID,并解释每一个特性。
答:ACID是事务的四大特性。分别为原子性,一致性,隔离性和持久性。原子性(Atomicity)指的是一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚。一致性(Consistency)指的是数据库总是从一个一致性的状态转换到另一个一致性的状态,如果事务没有提交,中间某一步执行失败,那么事务中所做的修改并不会保存到数据库中。隔离性(Isolation)指的是一个事务所做的修改在最终提交以前,对其他事务是不可见的。持久性(Durability)指的是一旦事务提交,则其所做的修改会永久保存到数据库
62、MySQL的两个主流引擎,并介绍它们的区别。
答:主流的引擎有两个,分别是 InnoDB和 MyISAM。其中 InnoDB支持事务,支持外键约束,它还支持行锁(比如select…for update语句,会触发行锁,但是锁定的是索引不是记录)。 MyISAM不支持事务,不支持外键,它是数据库默认的引擎。 InnoDB保存表的行数,如果看这个表有多少行的时候, InnoDB扫描整张表, MyISAM则是直接读取保存的行数即可。删除表的时候 InnoDB是一行一行的删,而 MyISAM则是重建表。 InnoDB适合频繁修改以及安全性要求较高的应用, MyISAM适合查询为主的应用。在我们的项目中使用的是 InnoDB。
63、如果将一个列表传入函数中,在函数中修改后,全局的列表会被修改吗?
答:会被修改,作为参数传入函数内部,内部修改相当于修改外部的列表。
a = [1,2,3]
def fuc(a):
a.append(1)
print(a)fuc(a)
结果为:
[1, 2, 3, 1]
64、像快排、冒泡之类的必须会手写!!!不光腾讯,每个公司都问!!!
65、笔试题
1.1 哈希树
哈希树是专门优化查询效率的一种数据结构,这棵树查询效率极高,单论查询,要比二叉排序树快。
哈希树是通过质数分辨算法建立的,所以我们首先来看一下质数分辨算法。
质数是只能被1和它本身整除的数,所以2是最小的质数。在一篇论文中曾描述过质数分辨定理『n个不同的质数可以“分辨”的连续整数个数和他们的乘积相等。“分辨”就是指这些连续的整数不可能有完全相同的余数序列』。
人们发现int类型最大能表示21亿个数,10个连续的质数能分辨的整数个数为 23571113171923*29=6464693230这个数超过了21亿,也就是说任何数经过10次以内计算肯定能找到。这就是为什么它查询快了。
看完是不是一脸蒙蔽,我还是用一个小栗子来说一下这棵树吧。
一个数除以2,余数有几种?0和1,所以哈希树的第2层有两个叉。查询就是根据余数判别走哪条路,一个数先除以2,根据余数找到分叉,用商除以3,根据余数找到分叉,再用商除以5。。。。不断的除下去,直到根据余数找到对应的数,或者跟本找不到为空。这就是哈希树。
1.2链表和顺序表的区别
顺序表中元素存储位置是相邻连续的,是可以快速访问到任何元素的一种数据结构。一个顺序表在使用前必须指定好存储空间大小,一旦分配内存就不可轻易更改。优点就是查询快速,缺点是插入非尾端数据或删除非尾端数据麻烦。顺序表由两部分组成,一部分是元素集合,一部分是有关表整体情况的信息(主要包括元素存储区的容量和元素的个数)。实现的方式为一体式和分离式,顾名思义,以顺序表两部分的情况区分。python中的list就是利用分离式顺序表实现的。
顺序表的构建需要预先知道数据大小来申请连续的存储空间,而进行扩充的时候,又不得不进行数据的搬迁,使用起来不是很灵活。为了充分利用计算机的内存空间,实现灵活的内存动态管理,我们就用到了链表。链表作为一种基础的数据结构,与顺序表不同,它是通过指针来描述元素关系的一种数据结构。它保存元素的时候,内存空间可以是不连续的,每个节点保存元素和下一个元素的指针即可。优点显而易见,但是缺点也很明显,就是查找元素必须重头开始查找。
1.3用代码实现一个死锁
假如一个线程在未释放锁的情况下发生了意外终止响应,其他线程获取不到锁而一直等待,这就是造成了死锁。下面我们利用简单的几行代码来模拟一个死锁的情况:
import threading
import time
# 创建互斥锁
lock = threading.Lock()
# 根据下标去取值, 保证同一时刻只能有一个线程去取值
def get_value(index):
# 上锁
lock.acquire()
print(threading.current_thread())
my_list = [3,6,8,1]
# 判断下标释放越界
if index >= len(my_list):
print("下标越界:", index)
return
value = my_list[index]
print(value)
time.sleep(0.2)
# 释放锁
lock.release()
if __name__ == '__main__':
# 模拟大量线程去执行取值操作
for i in range(30):
sub_thread = threading.Thread(target=get_value, args=(i,))
sub_thread.start()
死锁产生后,程序会发生停止响应,空耗资源。为了避免此种情况,我们需要在合适的地方释放锁。
66、排序二叉树如何查找两个叶节点的最近公共祖先
排序二叉树有一个特点,就是左子树的节点都比父节点小,位于右子树的节点都比父节点大。抓住这个特点,我们从根节点开始进行比较查找。如果当前节点的值比两个节点的值都大,那么最低的公共祖先节点一定在该节点的左子树中,下一步就开始遍历当前节点的左子树。如果当前节点的值比两个节点的值都小,那么最低的公共祖先节点一定在该节点的右子树中,下一步就是遍历当前节点的右子树。这样从上到下找到第一个在两个输入节点的值之间的节点。
了解完之后,我们利用python代码实现一下:
class TreeNode(object):
def __init__(self,item):
self.item = item
self.lchild = None
self.rchild = None
def getCommonAncestor(root,node1,node2):
while root:
if root.item > node1.item and root.item > node2.item:
root = root.lchild
elif root.item < node1.item and root.item < node2.item:
root = root.rchild
else:
return root
return None
67、查找linux当前目录下的所有python文件。
答:linux中我们使用 find命令查找文件。众所周知,python文件是以 .py结尾,因此我们可以按照下面命令进行查找。
find ./ -name "*.py"
68、装饰器
答:装饰器就是在不更改原函数代码前提下给函数增加新的功能。下面我们实现一个万能装饰器。
def decorator(func):
def wrapper(*args, **kwargs):
print('wrapper context')
return func(*args, **kwargs)
return wrapper
69、生成器
答:生成器是一种特殊的迭代器,它不用自己写 iter()方法和 next()方法就可以使用next函数和for循环来取值,使用起来更加的方便。创建生成器有两种常用的方法,一种是将列表生成式中的 []改为 ()。
my_generator = (i * 2 for i in range(5))
我们打印发现提示是一个生成器对象:
<generator object <genexpr> at 0x7f8971f48a40>
另一种方式是使用 yield关键字,我们以著名的fibonacci数列为例:
def fibonacci(num):
a = 0
b = 1
current_index = 0
print("--11---")
while current_index < num:
result = a
a, b = b, a + b
current_index += 1
print("--22---")
yield result
print("--33---")
70、实现一个单向链表
先实现一个节点:
class SingleNode(object):
"""单链表的结点"""
def __init__(self, item):
# item 存放数据元素
self.item = item
# next 是下一个节点的标识
self.next = None
然后实现单链表:
class SingleLinkList(object):
"""单链表"""
def __init__(self):
self.__head = None
def is_empty(self):
"""判断链表是否为空"""
return self.__head == None
def length(self):
"""链表长度"""
# cur初始时指向头节点
cur = self.__head
count = 0
# 尾节点指向None,当未到达尾部时
while cur != None:
count += 1
# 将cur后移一个节点
cur = cur.next
return count
def travel(self):
"""遍历链表"""
cur = self.__head
while cur != None:
print(cur.item, end=" ")
cur = cur.next
print("")
头部添加元素:
def add(self, item):
"""头部添加元素"""
# 先创建一个保存item值的节点
node = SingleNode(item)
# 将新节点的链接域next指向头节点,即_head指向的位置
node.next = self.__head
# 将链表的头_head指向新节点
self.__head = node
尾部添加元素:
def append(self, item):
"""尾部添加元素"""
node = SingleNode(item)
# 先判断链表是否为空,若是空链表,则将_head指向新节点
if self.is_empty():
self.__head = node
# 若不为空,则找到尾部,将尾节点的next指向新节点
else:
cur = self.__head
while cur.next != None:
cur = cur.next
cur.next = node
指定位置添加元素:
def insert(self, pos, item):
"""指定位置添加元素"""
# 若指定位置pos为第一个元素之前,则执行头部插入
if pos <= 0:
self.add(item)
# 若指定位置超过链表尾部,则执行尾部插入
elif pos > (self.length()-1):
self.append(item)
# 找到指定位置
else:
node = SingleNode(item)
count = 0
# pre用来指向指定位置pos的前一个位置pos-1,初始从头节点开始移动到指定位置
pre = self.__head
while count < (pos-1):
count += 1
pre = pre.next
# 先将新节点node的next指向插入位置的节点
node.next = pre.next
# 将插入位置的前一个节点的next指向新节点
pre.next = node
删除节点:
def remove(self, item):
"""删除节点"""
cur = self.__head
pre = None
while cur != None:
# 找到了指定元素
if cur.item == item:
# 如果第一个就是删除的节点
if not pre:
# 将头指针指向头节点的后一个节点
self.__head = cur.next
else:
# 将删除位置前一个节点的next指向删除位置的后一个节点
pre.next = cur.next
break
else:
# 继续按链表后移节点
pre = cur
cur = cur.next
查找节点是否存在:
def search(self, item):
"""链表查找节点是否存在,并返回True或者False"""
cur = self.__head
while cur != None:
if cur.item == item:
return True
cur = cur.next
return False
71、堆和栈的定义以及实现
答:栈是一种可以实现“先进后出”(或者称为“后进先出”)的存储结构。堆则是一种经过排序的树形数据结构,常用来实现优先队列等。
可以简单的理解,堆是一种特殊的完全二叉树。其中,节点是从左到右填满的,并且最后一层的树叶都在最左边(即如果一个节点没有左儿子,那么它一定没有右儿子);每个节点的值都小于(或者都大于)其子节点的值。
72、什么是2msl?为什么要这样做?
2MSL即两倍的MSL,TCP的TIME_WAIT状态也称为2MSL等待状态,当TCP的一端发起主动关闭,在发出最后一个ACK包后,即第3次握 手完成后发送了第四次握手的ACK包后就进入了TIME_WAIT状态,必须在此状态上停留两倍的MSL时间,等待2MSL时间主要目的是怕最后一个 ACK包对方没收到,那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的FIN包后可以再发一个ACK应答包。在TIME_WAIT状态 时两端的端口不能使用,要等到2MSL时间结束才可继续使用。当连接处于2MSL等待阶段时任何迟到的报文段都将被丢弃。不过在实际应用中可以通过设置 SO_REUSEADDR选项达到不必等待2MSL时间结束再使用此端口。
73、大数据的文件读取:
①利用生成器generator;
②迭代器进行迭代遍历:for line in file;
74、迭代器和生成器的区别:
答:
(1)迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个StopIteration异常
(2)生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出StopIteration异常
装饰器是Python中一种特殊的语法,用于为函数或类添加额外的功能,而无需修改被装饰对象的源代码。装饰器可以在不改变原函数或类的情况下,对其进行功能扩展、修饰或包装。
75、装饰器的作用和功能:
- 扩展函数或类的功能:通过装饰器,可以在不改变原函数或类的情况下,为其添加新的功能,如日志记录、性能分析、异常处理等。
- 代码复用:通过将通用的功能逻辑封装成装饰器,可以在多个函数或类中重复使用。这样可以避免代码重复,提高代码的可维护性。
- 修改函数或类的行为:装饰器可以修改函数或类的输入、输出、执行流程等行为,使其满足特定的需求,例如参数验证、缓存数据、权限检查等。
- AOP编程:装饰器可以将横切关注点(如日志、事务管理)与核心业务逻辑分离,实现面向切面编程(AOP),提高代码的可读性和可维护性。
- 代码注入:某些装饰器可以动态地在被装饰函数或类中注入额外的代码,实现一些特定的需求,如单例模式、注册函数等。
76、谈谈你对同步异步阻塞非阻塞的理解:
同步:一个线程只监听一个套接字,可以用于udp
异步:使用io模型中的一种,如select ,event,一个线程监听多套接字
阻塞:套接字的send recv 等操作再执行完成以前会阻塞
非阻塞:操作不会阻塞,所以函数的返回值也不再准确
77、简单谈下GIL:
Global Interpreter Lock(全局解释器锁)
Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在多线程环境中,Python 虚拟机按以下方式执行:
-
设置GIL
-
切换到一个线程去运行
-
运行:指定数量的字节码指令,或者线程主动让出控制(可以调用time.sleep(0))
-
把线程设置为睡眠状态
-
解锁GIL
-
再次重复以上所有步骤
在调用外部代码(如C/C++扩展函数)的时候,GIL 将会被锁定,直到这个函数结束为止(由于在这期间没有Python 的字节码被运行,所以不会做线程切换)
78、简单谈下python2和python3的区别:
1 Py3默认使用utf-8编码,python2使用ascill码
2 去除了<>,全部改用!=
3 整型除法返回浮点数,要得到整型结果,请使用//
4 去除print语句,加入print()函数实现相同的功能。同样的还有 exec语句,已经改为exec()函数
5 改变了顺序操作符的行为,例如x<y,当x和y类型不匹配时抛出TypeError而不是返回随即的 bool值
6 输入函数改变了,删除了raw_input,用input代替
7 去除元组参数解包。不能def(a, (b, c)):pass这样定义函数了『Pythonnote』
8 Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
9 新增了bytes类型,对应于2.X版本的八位串
10 迭代器的next()方法改名为__next__(),并增加内置函数next(),用以调用迭代器的__next__()方法『Pythonnote』小闫同学
11 增加了@abstractmethod和 @abstractproperty两个 decorator,编写抽象方法(属性)更加方便。
12 所以异常都从 BaseException继承,并删除了StardardError
13 去除了异常类的序列行为和.message属性
14 用 raise Exception(args)代替 raise Exception, args语法小闫同学
15 移除了cPickle模块,可以使用pickle模块代替。最终我们将会有一个透明高效的模块。
16 移除了imageop模块
17 移除了 audiodev, Bastion, bsddb185, exceptions, linuxaudiodev, md5, MimeWriter, mimify, popen2,
rexec, sets, sha, stringold, strop, sunaudiodev, timing和xmllib模块
18 移除了bsddb模块(单独发布,可以从 获取)
19 移除了new模块
20 xrange() 改名为range()
79、find和grep?:
grep命令是一种强大的文本搜索工具,grep搜索内容串可以是正则表达式,允许对文本文件进行模式查找。如果找到匹配模式,grep打印包含模式的所有行。
find通常用来再特定的目录下搜索符合条件的文件,也可以用来搜索特定用户属主的文件。
80、线上服务可能因为种种原因导致挂掉怎么办?
linux下的后台进程管理利器 supervisor
每次文件修改后再linux执行 service supervisord restart
81、如何提高python的运行效率:
- 使用合适的数据结构和算法:选择适当的数据结构和算法可以显著提高程序效率。了解不同数据结构和算法的性能特点,并选择最适合问题的解决方案。
- 减少循环和迭代次数:避免不必要的循环和迭代,尽量使用内置函数和库函数来处理集合操作、列表推导等,以提高效率。
- 使用生成器和迭代器:使用生成器(Generator)和迭代器(Iterator)可以在处理大量数据时降低内存占用,并提高程序效率。
- 利用并发和并行:对于需要处理大量独立任务的情况,可以使用并发和并行编程技术,如多线程、多进程或异步编程,以提高程序的并发性和效率。
- 缓存计算结果:将重复计算的结果缓存起来,避免重复计算,提高程序运行效率。
- 使用内置函数和库函数:Python 有许多高效的内置函数和库函数,熟悉并充分利用这些函数可以提高程序效率。
- 使用适当的数据类型:选择适当的数据类型可以减少内存占用和提高运算效率。例如,对于数值计算,可以使用 NumPy 库提供的数组(ndarray)类型。
- 避免过多的对象复制:Python 中的对象复制操作比较昂贵,尽量避免不必要的对象复制来提高程序效率。
- 使用 C 扩展或 JIT 编译:对于对性能要求较高的关键部分,可以使用 C 扩展模块或使用 JIT (即时编译)技术,如 Numba、PyPy 等,以提高运行速度。
- 编写优化的代码:注意编写简洁、高效的代码,减少不必要的操作、函数调用和内存分配。
82、python 中 yield 的用法?
答:yield简单说来就是一个生成器,这样函数它记住上次返 回时在函数体中的位置。对生成器第 二次(或n 次)调用跳转至该函 次)调用跳转至该函 数。
83、python是如何进行内存管理的?
一、垃圾回收:python不像C++,Java等语言一样,他们可以不用事先声明变量类型而直接对变量进行赋值。对Python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称Pyt
二、引用计数:Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数。当变量被绑定在一个对象上的时候,该变量的引用计数就是1,(还有另外一些情况也会导致变量引用计数的增加),系统会自动维护这些标签,并定时扫描,当某标签的引用计数变为0的时候,该对就会被回收。
三、内存池机制Python的内存机制以金字塔型,-1,-2层主要有操作系统进行操作,
第0层是C中的malloc,free等内存分配和释放函数进行操作;
第1层和第2层是内存池,有Python的接口函数PyMem_Malloc函数实现,当对象小于256K时有该层直接分配内存;
第3层是最上层,也就是我们对Python对象的直接操作;
在 C 中如果频繁的调用 malloc 与 free 时,是会产生性能问题的.再加上频繁的分配与释放小块的内存会产生内存碎片. Python 在这里主要干的工作有:
如果请求分配的内存在1~256字节之间就使用自己的内存管理系统,否则直接使用 malloc.
这里还是会调用 malloc 分配内存,但每次会分配一块大小为256k的大块内存.
经由内存池登记的内存到最后还是会回收到内存池,并不会调用 C 的 free 释放掉.以便下次使用.对于简单的Python对象,例如数值、字符串,元组(tuple不允许被更改)采用的是复制的方式(深拷贝?),也就是说当将另一个变量B赋值给变量A时,虽然A和B的内存空间仍然相同,但当A的值发生变化时,会重新给A分配空间,A和B的地址变得不再相同
84、描述数组、链表、队列、堆栈的区别?
数组与链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据;
队列和堆栈是描述数据存取方式的概念,队列是先进先出,而堆栈是后进先出;队列和堆栈可以用数组来实现,也可以用链表实现。
85、django 中当一个用户登录 A 应用服务器(进入登录状态),然后下次请求被 nginx 代理到 B 应用服务器会出现什么影响?
如果用户在A应用服务器登陆的session数据没有共享到B应用服务器,那么之前的登录状态就没有了。
86、跨域请求问题django怎么解决的(原理)
启用中间件
post请求
验证码
表单中添加{%csrf_token%}标签
87、请解释或描述一下Django的架构
对于Django框架遵循MVC设计,并且有一个专有名词:MVT
M全拼为Model,与MVC中的M功能相同,负责数据处理,内嵌了ORM框架
V全拼为View,与MVC中的C功能相同,接收HttpRequest,业务处理,返回HttpResponse
T全拼为Template,与MVC中的V功能相同,负责封装构造要返回的html,内嵌了模板引擎
88、django对数据查询结果排序怎么做,降序怎么做,查询大于某个字段怎么做
排序使用order_by()
降序需要在排序字段名前加-
查询字段大于某个值:使用filter(字段名_gt=值)
89、说一下Django,MIDDLEWARES中间件的作用?
答:中间件是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出。
90、你对Django的认识?
Django是走大而全的方向,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。
Django内置的ORM跟框架内的其他模块耦合程度高。应用程序必须使用Django内置的ORM,否则就不能享受到框架内提供的种种基于其ORM的便利;理论上可以切换掉其ORM模块,但这就相当于要把装修完毕的房子拆除重新装修,倒不如一开始就去毛胚房做全新的装修。请关注公众号『Pythonnote』或者『全栈技术精选』
Django的卖点是超高的开发效率,其性能扩展有限;采用Django的项目,在流量达到一定规模后,都需要对其进行重构,才能满足性能的要求。
Django适用的是中小型的网站,或者是作为大型网站快速实现产品雏形的工具。
Django模板的设计哲学是彻底的将代码、样式分离;Django从根本上杜绝在模板中进行编码、处理数据的可能。
91、Django重定向你是如何实现的?用的什么状态码?
使用HttpResponseRedirect
redirect和reverse
状态码:302,301
92、ngnix的正向代理与反向代理?
答:正向代理 是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
反向代理正好相反,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容原本就是它自己的一样。
93、Tornado 的核是什么?
Tornado 的核心是 ioloop 和 iostream 这两个模块,前者提供了一个高效的 I/O 事件循环,后者则封装了 一个无阻塞的 socket 。通过向 ioloop 中添加网络 I/O 事件,利用无阻塞的 socket ,再搭配相应的回调 函数,便可达到梦寐以求的高效异步执行。
94、Django 本身提供了 runserver,为什么不能用来部署?
runserver 方法是调试 Django 时经常用到的运行方式,它使用 Django 自带的WSGI Server 运行,主要在测试和开发中使用,并且 runserver 开启的方式也是单进程 。
uWSGI 是一个 Web 服务器,它实现了 WSGI 协议、uwsgi、http 等协议。注意 uwsgi 是一种通信协议,而 uWSGI 是实现 uwsgi 协议和 WSGI 协议的 Web 服务器。uWSGI 具有超快的性能、低内存占用和多 app 管理等优点,并且搭配着 Nginx请关注公众号『Pythonnote』或者『全栈技术精选』就是一个生产环境了,能够将用户访问请求与应用 app 隔离开,实现真正的部署 。相比来讲,支持的并发量更高,方便管理多进程,发挥多核的优势,提升性能。
95、 GET请求和POST到底有什么区别?
-
GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCII 字符 ,而且浏览器会对 URL 的长度有限制(HTTP协议本身对 URL长度并没有做任何规定)。比如,你打开我的文章,浏览器就会发送 GET 请求给服务器,服务器就会返回文章的所有文字及资源。
-
POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST 请求携带数据的位置一般是写在报文 body 中,body 中的数据可以是任意格式的数据,只要客户端与服务端协商好即可,而且浏览器不会对 body 大小做限制。比如,你在我文章底部,敲入了留言后点击「提交」,浏览器就会执行一次 POST 请求,把你的留言文字放进了报文 body 里,然后拼接好 POST 请求头,通过 TCP 协议发送给服务器。
-
GET 请求,请求的数据会附加在 URL 之后,以?分割 URL 和传输数据,多个参数用&连接。URL 的编码格式采用的是 ASCII 编码,而不是 uniclde,即是说所有的非 ASCII 字符都要编码之后再传输。
-
POST 请求:POST 请求会把请求的数据放置在 HTTP 请求包的包体中。上面的 item=bandsaw 就是实际的传输数据。
因此,GET 请求的数据会暴露在地址栏中,而 POST 请求则不会。 -
在 HTTP 规范中,没有对 URL 的长度和传输的数据大小进行限制。但是在实际开发过程中,对于 GET,特定的浏览器和服务器对 URL 的长度有限制。因此,在使用 GET 请求时,传输数据会受到 URL 长度的限制。
-
对于 POST,由于不是 URL 传值,理论上是不会受限制的,但是实际上各个服务器会规定对 POST提交数据大小进行限制,Apache、IIS 都有各自的配置。
-
POST 的安全性比 GET 的高。这里的安全是指真正的安全,而不同于上面 GET 提到的安全方法中的安全,上面提到的安全仅仅是不修改服务器的数据。比如,在进行登录操作,通过 GET 请求, 用户名和密码都会暴露再 URL 上,因为登录页面有可能被浏览器缓存以及其他人查看浏览器的历史记录的原因,此时的用户名和密码就很容易被他人拿到了。除此之外,GET 请求提交的数据还可能会造成 Cross-site request frogery 攻击。
-
GET 比 POST 效率高。
POST 请求的过程:
- 1.浏览器请求 tcp 连接(第一次握手)
- 2.服务器答应进行 tcp 连接(第二次握手)
- 3.浏览器确认,并发送 post 请求头(第三次握手,这个报文比较小,所以 http 会在此时进行第一次数据发送)
- 4.服务器返回 100 continue 响应
- 5.浏览器开始发送数据
- 6.服务器返回 200 ok 响应
GET 请求的过程:
- 1.浏览器请求 tcp 连接(第一次握手)
- 2.服务器答应进行 tcp 连接(第二次握手)
- 3.浏览器确认,并发送 get 请求头和数据(第三次握手,这个报文比较小,所以 http 会在此时进行第一次数据发送)
- 4.服务器返回 200 OK 响应
96、聊聊什么是GIL锁
1. GIL的定义
GIL(Global Interpreter Lock)(全局解释器锁)是CPython解释器中的一种机制,用于确保同一时间只有一个线程可以执行Python字节码。GIL通过在解释器级别上进行互斥锁来实现,这意味着在任何给定的时间点上,只有一个线程可以执行Python字节码和操作Python对象。
Python的GIL是一种特殊的锁,它不是操作系统提供的锁,而是Python解释器提供的锁。当Python解释器创建一个线程时,会自动创建一个与之关联的GIL。当多个线程同时运行时,只有一个线程能够获取GIL,从而执行Python字节码。其它线程则必须等待GIL的释放才能执行。这个机制在保证线程安全的同时,也导致了Python多线程程序的性能问题。
需要注意的是,GIL只影响解释器级别的线程(也称为“内部线程”),而不影响操作系统级别的线程(也称为“外部线程”)。也就是说,在Python程序中使用多个操作系统级别的线程时,这些线程可以并行执行,不受GIL的影响。但是,在同一个解释器中创建的内部线程都受到GIL的限制,只有一个线程能够运行Python代码。
需要注意的是,虽然GIL是Python多线程程序的性能问题之一,但是它并不意味着Python不能使用多线程。对于I/O密集型的任务,Python的多线程模型可以带来性能上的提升。但对于CPU密集型的任务,使用多线程并不能提升性能,反而可能会导致性能下降。此时可以考虑使用多进程或者异步编程等方式来提升性能。
2. GIL的作用机制
GIL的引入是为了解决CPython解释器的线程安全问题。由于CPython的内存管理并不是线程安全的,如果多个线程同时执行Python字节码,可能会导致数据竞争和内存错误。为了解决这个问题,GIL被引入,并确保了同一时间只有一个线程可以执行Python字节码,从而消除了竞争条件。
具体来说,GIL通过在执行Python字节码之前获取并锁定全局解释器锁,从而阻止其他线程执行Python字节码。一旦某个线程获取了GIL,它将独占解释器,并在执行完一定数量的字节码或者时间片后,将GIL释放,使其他线程有机会获取GIL并执行字节码。这个过程在多个线程之间不断重复,以实现多线程的执行。
3. GIL对多线程编程的影响
3.1 CPU密集型任务不会获得真正的并行加速
由于同一时间只有一个线程可以执行Python字节码,对于CPU密集型任务,多线程并不能真正实现并行加速。即使使用多个线程,只有一个线程能够执行字节码,其余线程被GIL阻塞,不能充分利用多核CPU的计算能力。
import threading
def count_up():
count = 0
for _ in range(100000000):
count += 1
t1 = threading.Thread(target=count_up)
t2 = threading.Thread(target=count_up)
t1.start()
t2.start()
t1.join()
t2.join()
上述代码中,t1和t2分别执行count_up函数,该函数进行一亿次的自增操作。然而,在CPython解释器中,由于GIL的存在,实际上只有一个线程能够执行自增操作,因此多线程并不能加速该任务的执行时间。
3.2 I/O密集型任务可以获得一定的并发优势
对于I/O密集型任务,由于线程在等待I/O操作完成时会释放GIL,因此多线程能够发挥一定的并发优势。在等待I/O的过程中,其他线程可以获取GIL并执行Python字节码,从而提高整体程序的执行效率。
import threading
import requests
def fetch_url(url):
response = requests.get(url)
print(response.status_code)
urls = [
'https://www.example1.com',
'https://www.example2.com',
'https://www.example3.com',
]
threads = [threading.Thread(target=fetch_url, args=(url,)) for url in urls]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
上述代码中,多个线程并发地发起HTTP请求,等待请求完成时会释放GIL,因此可以充分利用CPU资源,并发执行多个网络请求。
3.3 线程间数据共享需要注意同步
由于GIL的存在,多线程在同时访问共享数据时需要注意同步机制,以避免数据竞争和不一致性。
import threading
count = 0
def increment():
global count
for _ in range(100000):
count += 1
t1 = threading.Thread(target=increment)
t2 = threading.Thread(target=increment)
t1.start()
t2.start()
t1.join()
t2.join()
print("Final count:", count)
在上述代码中,多个线程并发执行自增操作,由于涉及到共享变量count,可能会导致竞争条件。由于GIL的存在,实际上只有一个线程能够执行自增操作,从而可能导致最终的计数结果不正确。
为了避免这种竞争条件,可以使用线程锁(Lock)来进行同步:
import threading
count = 0
lock = threading.Lock()
def increment():
global count
for _ in range(100000):
lock.acquire()
count += 1
lock.release()
t1 = threading.Thread(target=increment)
t2 = threading.Thread(target=increment)
t1.start()
t2.start()
t1.join()
t2.join()
print("Final count:", count)
通过引入线程锁,确保每次只有一个线程可以访问和修改共享变量count,从而避免了竞争条件,最终获得正确的计数结果。
4、GIL的准则
1.当前执行线程必须持有GIL
2.当线程遇到 IO的时、时间片到时或遇到阻塞时, 会释放GIL(Python 3.x使用计时器----执行时间达到阈值后,当前线程释放GIL,或Python 2.x,tickets计数达到100。)
5、GIL的优缺点
优点:
线程是非独立的,所以同一进程里线程是数据共享,当各个线程访问数据资源时会出现“竞争”状态,即数据可能会同时被多个线程占用,造成数据混乱,这就是线程的不安全。所以引进了互斥锁,确保某段关键代码、共享数据只能由一个线程从头到尾完整地执行。
缺点:
单个进程下,开启多个线程,无法实现并行,只能实现并发,牺牲执行效率。由于GIL锁的限制,所以多线程不适合计算密集型任务,更适合IO密集型任务。常见IO密集型任务:网络IO(抓取网页数据)、磁盘操作(读写文件)、键盘输入
6、要避免Python的GIL锁带来的影响,可以考虑以下几种方法:
- 使用多进程。Python的多进程模型可以避免GIL的限制,多个进程之间可以并行执行Python代码。但是,多进程之间的通信和数据共享需要通过一些额外的手段来实现,如管道、共享内存、套接字等。
- 使用第三方扩展模块。一些第三方扩展模块,如NumPy、Pandas等,在执行计算密集型任务时会使用C语言编写的底层库,这些库不会受到GIL的限制。因此,使用这些扩展模块可以提高Python程序的性能。
- 使用异步编程。异步编程是一种非阻塞的编程模型,可以在单个线程中执行多个任务,从而避免GIL的限制。Python的异步编程框架有很多,如asyncio、Tornado、Twisted等。
- 使用多线程+进程池。多线程可以用来处理I/O密集型任务,而进程池可以用来处理计算密集型任务。将多个线程分配到不同的进程池中可以同时提高I/O密集型和计算密集型任务的处理速度。
需要注意的是,在使用上述方法时,要根据具体的情况来选择合适的方式。例如,在处理大量I/O操作时,使用多进程可能会导致性能下降,因为进程之间的切换开销较大。此时,使用异步编程可能是更好的选择。在处理计算密集型任务时,使用多进程可能是更好的选择,因为进程之间可以并行执行计算密集型任务。
97、简述 进程、线程、协程的区别 以及应用场景?
一、概念:
1、进程
- 进程:一个运行的程序或代码就是一个进程,一个没有运行的代码叫程序。进程是系统进行资源分配的最小单位,进程拥有自己的内存空间,所以进程间数据不共享,开销大。
- 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
- 进程拥有自己独立的堆和栈,堆和栈都不共享,进程由操作系统调度
2、线程
- 线程:调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程的存在而存在,一个进程至少有一个线程,叫主线程,多个线程共享内存(数据共享和全局变量),因此提升程序的运行效率。
- 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据
- 线程拥有自己独立的栈,但是堆却是共享的,标准的线程是由操作系统调度的
3、协程
- 协程:用户态的轻量级线程,调度有用户控制,拥有自己的寄存器上下文和栈,切换基本没有内核切换的开销,切换灵活。
- 协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
- 协程共享堆却不共享栈,协程是由程序员在协程的代码块里显示调度
二、区别:
1、进程多与线程比较
线程是指进程内的一个执行单元,也是进程内的可调度实体。线程与进程的区别:
- 地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间
- 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
- 线程是处理器调度的基本单位,但进程是资源分配的基本单位
- 二者均可并发执行
- 每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
2、协程多与线程进行比较
- 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
- 线程进程都是同步机制,而协程则是异步
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
三、进程和线程、协程在python中的使用
1、多进程一般使用multiprocessing库,来利用多核CPU,主要是用在CPU密集型的程序上,当然生产者消费者这种也可以使用。多进程的优势就是一个子进程崩溃并不会影响其他子进程和主进程的运行,但缺点就是不能一次性启动太多进程,会严重影响系统的资源调度,特别是CPU使用率和负载。
2、多线程一般是使用threading库,完成一些IO密集型并发操作。多线程的优势是切换快,资源消耗低,但一个线程挂掉则会影响到所有线程,所以不够稳定。
3、协程一般是使用gevent库,当然这个库用起来比较麻烦,所以使用的并不是很多。相反,协程在tornado的运用就多得多了,使用协程让tornado做到单线程异步,据说还能解决C10K的问题。所以协程使用的地方最多的是在web应用上。
注意:IO密集型一般使用多线程或者多进程,CPU密集型一般使用多进程,强调非阻塞异步并发的一般都是使用协程,当然有时候也是需要多进程线程池结合的,或者是其他组合方式。
98、git 合并文件有冲突,如何处理?
- git merge 冲突了,根据提示找到冲突的文件,解决冲突如果文件有冲突,那么会有类似的标记。
- 修改完之后,执行 git add 冲突文件名。
- git commit 注意:没有-m 选项 进去类似于 vim 的操作界面,把 conflict 相关的行删除掉直接 push就可以了,因为刚刚已经执行过相关 merge 操作了。
99、Python 生产者消费者模型
生产者消费者模型介绍
1、为什么要使用生产者消费者模型
生产者指的是生产数据的任务,消费者指的是处理数据的任务,在并发编程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
2、什么是生产者和消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
生产者消费者模型是一种并发编程模型,主要用于解决多线程或多进程中的资源共享和通信问题。使用生产者消费者模型可以带来以下好处:
- 解耦生产者和消费者:生产者和消费者之间的通信通过消息队列或缓冲区进行,彼此之间不需要直接交互。这样使得生产者和消费者可以独立演化和调试,提高了代码的灵活性和可维护性。
- 并发和流量控制:生产者和消费者可以并发执行,提高系统的吞吐量和资源利用率。同时,可以通过控制生产者和消费者的速度,实现流量控制,防止资源过载。
- 缓冲和异步处理:通过引入缓冲区可以平衡生产者和消费者之间的速度差异,从而提高系统性能。生产者可以将数据放入缓冲区中,而消费者可以从缓冲区中取出数据进行处理。这种机制可以实现异步处理和解耦合。
- 分布式计算:生产者消费者模型可用于构建分布式系统中的任务调度、消息传递等机制。不同节点的生产者和消费者之间可以通过消息队列或共享存储进行通信,实现分布式计算和协同处理。
总的来说,生产者消费者模型提供了一种优雅和可扩展的方式来处理资源共享和通信问题,提高了系统的并发性、响应性和可伸缩性,使得程序设计更灵活和可维护。
生产者消费者模型实现
1. 使用线程和锁实现生产者消费者模型:
import threading
import time
buffer = [] # 共享的缓冲区
lock = threading.Lock() # 锁对象
# 生产者函数
def producer():
for i in range(10):
item = f'商品{i}'
print(f'生产了{item}')
with lock:
buffer.append(item) # 加锁操作,向缓冲区添加商品
time.sleep(1)
# 消费者函数
def consumer():
while True:
with lock:
if buffer:
item = buffer.pop(0) # 加锁操作,从缓冲区取出商品
print(f'消费了{item}')
time.sleep(2)
# 创建生产者和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
# 启动线程
producer_thread.start()
consumer_thread.start()
# 等待线程结束
producer_thread.join()
consumer_thread.join()
在这个示例中,我们使用一个列表来作为共享的缓冲区,并使用一个锁对象来确保对缓冲区的访问是线程安全的。
在生产者函数中,我们使用with lock来加锁,然后向缓冲区添加商品。在消费者函数中,我们同样使用with lock来加锁,然后从缓冲区中取出商品进行消费。
通过使用线程和锁,我们实现了生产者消费者模式的功能。生产者线程负责生产商品并放入缓冲区,消费者线程负责从缓冲区中取出商品进行消费,而且保证了线程安全。
2. 使用队列实现生产者消费者模型:
import threading
import queue
import time
buffer = queue.Queue(5) # 共享的缓冲区
# 生产者函数
def producer():
for i in range(10):
item = f'商品{i}'
print(f'生产了{item}')
buffer.put(item) # 将商品放入缓冲区
time.sleep(1)
# 消费者函数
def consumer():
while True:
item = buffer.get() # 从缓冲区取出商品
print(f'消费了{item}')
time.sleep(2)
# 创建生产者和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
# 启动线程
producer_thread.start()
consumer_thread.start()
# 等待线程结束
producer_thread.join()
consumer_thread.join()
在这个示例中,我们使用了queue.Queue作为共享的缓冲区。
在生产者函数中,我们使用buffer.put(item)将商品放入缓冲区。在消费者函数中,我们使用buffer.get()从缓冲区中取出商品进行消费。
通过使用队列,我们不需要手动管理缓冲区的大小和同步,而是利用队列的线程安全性,生产者线程可以向队列中放入商品,而消费者线程可以从队列中取出商品,而不会造成冲突。
通过创建生产者和消费者线程并启动它们,我们实现了生产者消费者模式的功能。
3. 使用条件变量实现生产者消费者模型:
import threading
import time
buffer = [] # 共享的缓冲区
buffer_size = 5 # 缓冲区大小
# 条件变量
buffer_not_full = threading.Condition() # 缓冲区非满条件
buffer_not_empty = threading.Condition() # 缓冲区非空条件
# 生产者函数
def producer():
for i in range(10):
item = f'商品{i}'
with buffer_not_full:
while len(buffer) >= buffer_size:
buffer_not_full.wait() # 等待缓冲区非满
buffer.append(item) # 向缓冲区添加商品
print(f'生产了{item}')
buffer_not_empty.notify() # 唤醒等待的消费者线程
time.sleep(1)
# 消费者函数
def consumer():
while True:
with buffer_not_empty:
while len(buffer) == 0:
buffer_not_empty.wait() # 等待缓冲区非空
item = buffer.pop(0) # 从缓冲区取出商品
print(f'消费了{item}')
buffer_not_full.notify() # 唤醒等待的生产者线程
time.sleep(2)
# 创建生产者和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
# 启动线程
producer_thread.start()
consumer_thread.start()
# 等待线程结束
producer_thread.join()
consumer_thread.join()
在这个示例中,我们使用了两个条件变量buffer_not_full和buffer_not_empty来控制生产者和消费者线程的执行。
在生产者函数中,我们使用buffer_not_full.wait()来等待缓冲区非满,当缓冲区已满时,生产者线程会暂时挂起等待。当缓冲区非满时,生产者线程将商品添加到缓冲区,并使用buffer_not_empty.notify()唤醒等待的消费者线程。
在消费者函数中,我们使用buffer_not_empty.wait()来等待缓冲区非空,当缓冲区为空时,消费者线程会暂时挂起等待。当缓冲区非空时,消费者线程从缓冲区中取出商品,并使用buffer_not_full.notify()唤醒等待的生产者线程。
通过使用条件变量,我们可以精确控制生产者和消费者线程的执行,并在合适的时机进行等待和唤醒操作,以实现生产者消费者模式的功能。
4. 使用信号量实现生产者消费者模型:
import threading
import time
buffer = [] # 共享的缓冲区
max_size = 5 # 缓冲区最大容量
producer_sem = threading.Semaphore(max_size) # 生产者信号量
consumer_sem = threading.Semaphore(0) # 消费者信号量
# 生产者函数
def producer():
for i in range(10):
item = f'商品{i}'
producer_sem.acquire() # 获取生产者信号量
buffer.append(item) # 向缓冲区添加商品
print(f'生产了{item}')
consumer_sem.release() # 释放消费者信号量
time.sleep(1)
# 消费者函数
def consumer():
while True:
consumer_sem.acquire() # 获取消费者信号量
item = buffer.pop(0) # 从缓冲区取出商品
print(f'消费了{item}')
producer_sem.release() # 释放生产者信号量
time.sleep(2)
# 创建生产者和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
# 启动线程
producer_thread.start()
consumer_thread.start()
# 等待线程结束
producer_thread.join()
consumer_thread.join()
在这个示例中,我们使用了两个信号量producer_sem和consumer_sem来控制生产者和消费者线程的执行。
在生产者函数中,我们使用producer_sem.acquire()来获取生产者信号量,当缓冲区已满时,生产者线程会在此等待。当缓冲区有空位时,生产者线程将商品添加到缓冲区,并使用consumer_sem.release()释放消费者信号量,以唤醒一个等待的消费者线程。
在消费者函数中,我们使用consumer_sem.acquire()来获取消费者信号量,当缓冲区为空时,消费者线程会在此等待。当缓冲区有商品时,消费者线程从缓冲区中取出商品,并使用producer_sem.release()释放生产者信号量,以唤醒一个等待的生产者线程。
通过使用信号量,我们可以控制生产者和消费者线程的执行顺序和数量,以实现生产者消费者模式的功能。
5. 使用协程实现生产者消费者模型:
import asyncio
import time
buffer = [] # 共享的缓冲区
# 生产者协程
async def producer():
for i in range(10):
item = f'商品{i}'
print(f'生产了{item}')
buffer.append(item) # 向缓冲区添加商品
await asyncio.sleep(1)
# 消费者协程
async def consumer():
while True:
await asyncio.sleep(0) # 让出CPU时间片
if buffer:
item = buffer.pop(0) # 从缓冲区取出商品
print(f'消费了{item}')
await asyncio.sleep(2)
# 创建事件循环并运行协程
loop = asyncio.get_event_loop()
tasks = asyncio.gather(producer(), consumer())
loop.run_until_complete(tasks)
在这个示例中,我们使用了两个协程producer和consumer来完成生产者消费者的功能。
在生产者协程中,我们使用await asyncio.sleep(1)来模拟生产商品的延迟,然后将商品添加到缓冲区中。每次添加商品后,我们打印出生产的商品信息。
在消费者协程中,我们使用await asyncio.sleep(0)来让出CPU时间片,以便其他协程有机会执行。然后,我们检查缓冲区是否有商品可消费,如果有,则从缓冲区中取出商品并打印消费的商品信息。每次消费商品后,我们再次等待一段时间。
通过使用asyncio库,我们可以方便地创建和管理协程,并使用事件循环来调度协程的执行。这种方式可以实现高效的异步编程,适用于处理IO密集型任务。
6、函数yield 方式:
import time
# 生产者生成商品
def producer():
for i in range(10):
item = f'商品{i}'
print(f'生产了{item}')
yield item
time.sleep(1)
# 消费者消费商品
def consumer(products):
for product in products:
print(f'消费了{product}')
time.sleep(2)
# 创建生产者生成器
products = producer()
# 消费商品
consumer(products)
在这个示例中,producer函数是一个生成器函数,它通过yield语句生成商品并返回。生成器函数可以在每次调用yield时暂停执行,并返回生成的值。在这个示例中,producer函数每次生成一个商品并暂停,直到被消费者消费。
消费者函数consumer接受生成的商品作为参数,并逐个消费。在这个示例中,我们直接将生成器对象传递给消费者函数,消费者会依次迭代生成器并消费每个商品。
通过使用生成器函数,我们可以实现异步的生产者消费者模式。生产者可以在生产商品后暂停执行,而消费者可以根据需要消费商品,这种方式避免了缓冲区可能带来的额外复杂性。
100、OSI七层协议各层详解
OSI七层协议(Open System Interconnection reference model)是一个由国际标准化组织(ISO)提出的标准通信协议体系结构,该体系结构把计算机网络体系结构的各个方面分割成了七个不同的抽象层,每一层都有各自的通信功能。OSI七层协议由上往下依次为:
1.物理层(Physical Layer)
物理层是位于通信系统底层的协议层,主要负责把比特流转化为可以在物理介质上传输的物理信号。物理层主要涉及数据传输的物理介质、机械电气特性、接口标准、传输速率和数据传输距离等问题。
2.数据链路层(Data-Link layer)
数据链路层主要建立在物理层之上,是建立与当地网络协议所规定的接口进行通信的实体层。它定义了如何让类似的网络接口通信,并指定当网络层出现错误时,如何进行检测和纠正。数据链路层一般包括两个子层:逻辑链路控制(LLC)和介质访问控制(MAC)。
3.网络层(Network Layer)
网络层主要用于在不同网络之间进行数据传送和路由选择,通过网络地址来实现通信。主要协议有IP(Internet Protocol)协议、ICMP(Internet Control Message Protocol)协议、IGMP(Internet Group Management Protocol)协议、OSPF(Open Shortest Path First)协议等。
4.传输层(Transport Layer)
传输层负责对网络通信质量进行管理,可以为应用程序提供良好的数据传输服务。主要协议有TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)。
5.会话层(Session Layer)
会话层主要负责建立、管理和终止会话连接,提供端到端的数据传输流控制和同步服务。主要协议有RPC(Remote Procedure Call)协议、NCP(NetWare Core Protocol)协议等。
6.表示层(Presentation Layer)
表示层用于处理交换数据的表示方式,例如数据压缩、加密、解密等操作。主要协议有ASCII、EBCDIC、JPEG、GIF等。
7.应用层(Application Layer)
应用层主要用于提供给用户的网络服务。例如:FTP(File Transfer Protocol)协议、HTTP(Hyper Text Transfer Protocol)协议、SMTP(Simple Mail Transfer Protocol)协议、SSH(Secure Shell Protocol)协议以及DNS(Domain Name System)协议等。
计算机网络七层协议的功能:
计算机网络的七层协议是一个分层的通讯协议体系结构,每一层都定义了不同的功能,便于开发和实现网络通讯的标准化和互操作性。各层的主要功能如下:
1.物理层(Physical Layer):传输比特流,定义能传输的电气和物理特性。
2.数据链路层(Data Link Layer):传输帧,定义帧的格式、检测和控制差错,以及媒体访问控制。
3.网络层(Network Layer):地理位置传输,实现不同网络间的路由选择和数据传输。
4.传输层(Transport Layer):端到端传输,提供可靠的传输服务,例如 TCP 协议。
5.会话层(Session Layer):建立、管理和终止会话连接,提供端到端的数据传输流控制和同步服务。
6.表示层(Presentation Layer):处理交换数据的表示方式,例如数据压缩、加密、解密等操作。
7.应用层(Application Layer):提供特定的应用服务,例如文件传输、电子邮件、Web浏览等。
101、简述 TCP 和 UDP 的区别以及优缺点和使用场景?
一、TCP与UDP区别总结:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
3、UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
4.每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP对系统资源要求较多,UDP对系统资源要求较少。
二、TCP和UDP的优缺点
- TCP协议的优点:
可靠、稳定,TCP的可靠体现在TCP在传输数据之前,会有三次握手来建立连接,而且在数据传输之前,会有三次握手来建立连接,而且在数据传输时,有确认、窗口、重传、拥塞控制机制,在数据传完猴,还会断开连接用来节约系统资源。 - TCP缺点:
慢,效率低,占用系统资源高,易被攻击,TCP在传输数据之前,要先建立连接,这会消耗时间,而且在数据传递时,确认机制,重传机制,拥塞机制等都会消耗大量时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。而且,因为TCP有确认机制、三次握手机制,这些也导致了TCP容易被人利用,实现DOS,DDOS,CC等攻击。 - UDP的优点:
快速,比TCP稍安全,UDP没有TCP的握手,确认,窗口,重传,拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一点。 - UDP的缺点:
但是UDP也是无法避免攻击;不可靠,不稳定 因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就很容易丢失包。
什么时候应该使用TCP:
当对网络通信质量有要求的时候,比如: 整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,如QQ,游览器, HTTP,HTTPS,FTP等传输文件的协议,POP,SITP等邮件传输的协议。
什么时候应该使用UDP:
当对我拿过来通信质量要求不高的时候,要求网络通讯能尽量的快,这时就可以使用UDP,比如qq语音,qq视频FTFP
102、三次握手和四次挥手
三次握手过程:
专业版:
- 1首先客户端向服务端发送一个带有 SYN 标志,以及随机生成的序号 100(0 字节)的报文
- 2服务端收到报文后返回一个报文(SYN200(0 字节),ACK1001(字节+1))给客户端
- 3客户端再次发送带有 ACK 标志 201(字节+)序号的报文给服务端至此三次握手过程结束,客户端开始向服务端发送数据。
接地气版:
- 1客户端向服务端发起请求:我想给你通信,你准备好了么?
- 2服务端收到请求后回应客户端:I’ok,你准备好了么
- 3客户端礼貌地再次回一下客户端:准备就绪,咱们开始通信吧!
接电话版
整个过程跟打电话的过程一模一样:
- 1 喂,你在吗
- 2 在,我说的你听得到不
- 3 恩,听得到(接下来请开始你的表演)
补充:SYN:请求询问,ACK:回复,回应。
四次挥手过程:
由于 TCP 连接是可以双向通信的(全双工),因此每个方向都必须单独进行关闭(这句话才是精辟,后面四个挥手过程都是其具体实现的语言描述)
四次挥手过程,客户端和服务端都可以先开始断开连接
- 1客户端发送带有 fin 标识的报文给服务端,请求通信关闭
- 2服务端收到信息后,回复 ACK 答应关闭客户端通信(连接)请求
- 3服务端发送带有 fin 标识的报文给客户端,也请求关闭通信
- 4客户端回应 ACK 给服务端,答应关闭服务端的通信(连接)请求
103、Django请求的生命周期是指:
当用户在浏览器上输入URL到用户看到网页的这个时间段内,Django后台所发生的事情。
直白的来说就是当请求来的时候和请求走的阶段中,Django的执行轨迹。
一个完整的Django生命周期:
- 用户从客户端发出一条请求以后,首先会基于http协议去解析数据并封装,
- 然后来到Nginx处理(nginx监听公网ip的某个端口,接到请求后,如果是静态资源,nginx直接获取该资源并返回给用户,如果是动态资源,nginx就将请求转发到uWSGI,使用协议一般是uwsgi),
- uWSGI接收到请求以后,通过将http协议转化为WSGI协议,和Django之间进行通信,
- 此时,该条请求就真正的来到了后端之上,首先它会经过Django的第一道工序:中间件,(而所谓中间件,简单来说就是请求来和请求走的时候Django增加的一道工序,请求来和请求走的时候都要先经过中间件的处理,因此,也可以将中间件理解为Django提供的额外功能组件),
- 在经过中间件以后,来到Django的第二道工序:路由层(urls.py)去筛选匹配符合符合请求命令后缀的地址,
- 然后根据匹配到的地址去Django的第三道工序:视图层(views.py)找到对应的视图函数/视图类里的属性,
- 之后去到第四道工序:模型层(models.py)通过orm操作去数据库中获取数据,拿到数据以后回到视图层(views.py)里对数据进行处理(序列化和反序列化),
- 将处理后的数据返给Django的第五道工序:模板层(Templates),模板层接收到数据后,对数据进行渲染,之后再次经过视图层、路由层、中间件、uWSGI服务器、Nginx代理,
- 最后将渲染的数据返还给客户端进行展示。
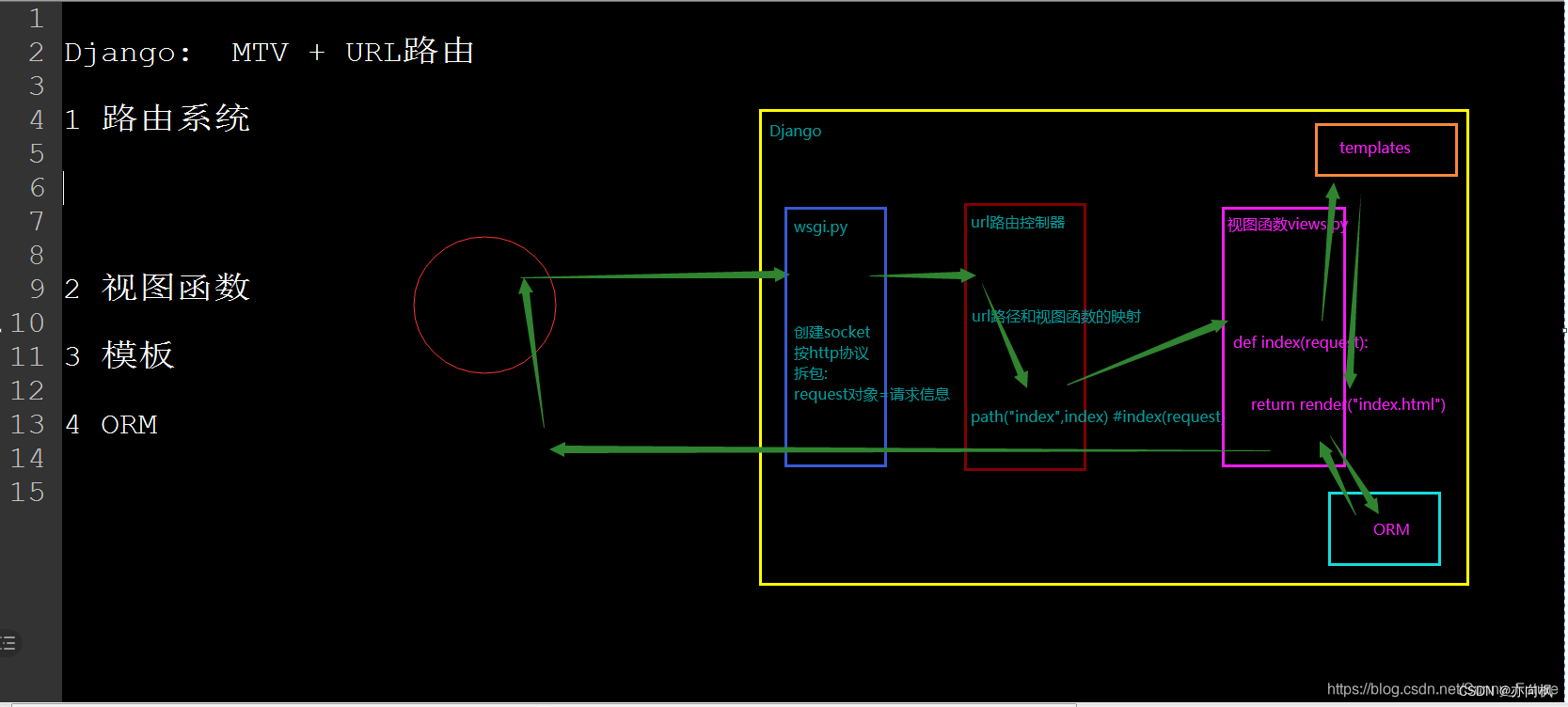
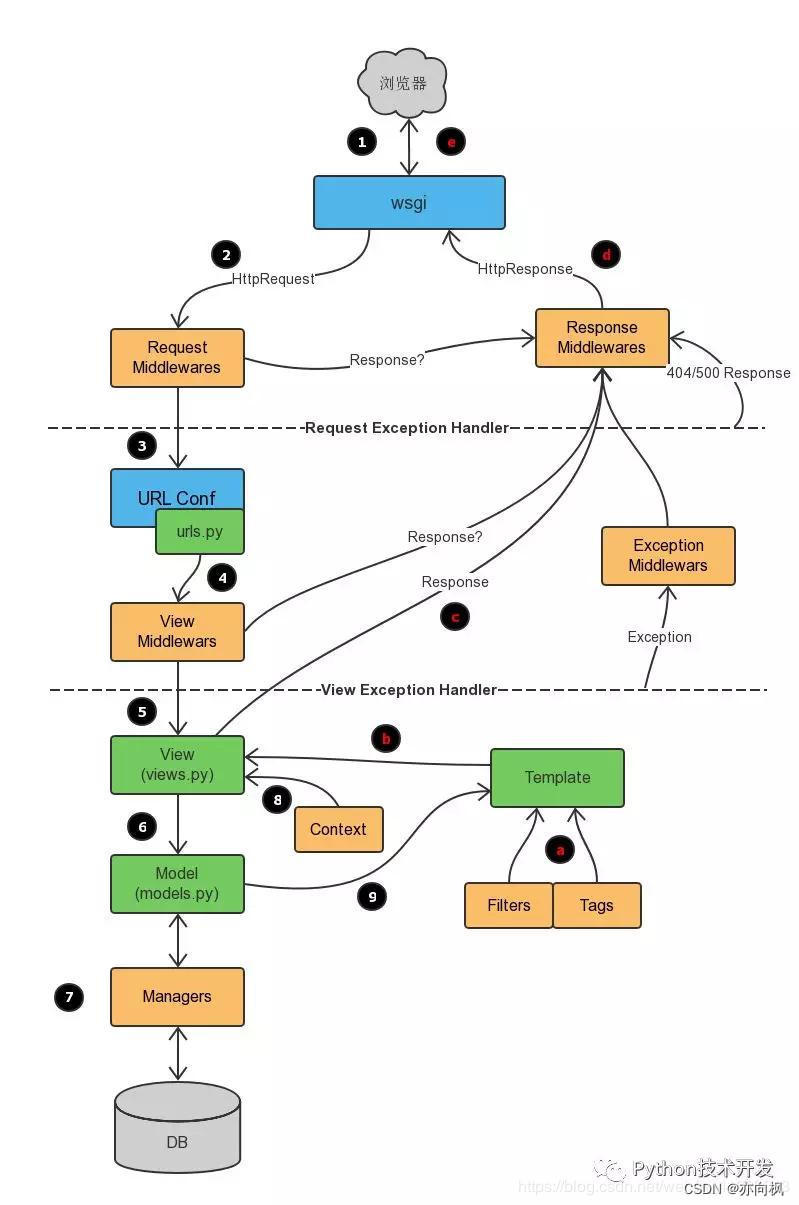


浏览器向django服务器发起请求
路由系统(url.py)
- 通过正则匹配url
- 交由视图系统(views.py),调用对应的方法处理数据
中间件
- 全局生效(所有方法均需要先由中间件处理)
视图系统(views.py)
- 是否需要根据post get请求, 区分处理方式
- 处理数据
- 返回结果
templates
- 直接返回页面
- 数据处理后返回页面
层层返回给浏览器
简单的说就是:django的生命周期是:前端请求—>nginx—>uwsgi.—>中间件—>url路由---->view视图—>orm---->拿到数据返回给view---->视图将数据渲染到模版中拿到字符串---->中间件—>uwsgi---->nginx---->前端渲染。
Django 请求的生命周期主要分为如下四个阶段:
- WSGI 应用的初始化
- URL 路由匹配
- Django View 函数的执行
- 返回响应
接着,我们将逐一对这四个阶段进行详细讲解。
当 WSGI 服务器启动 Django 应用程序时,将调用 Django 的自带 WSGI 应用程序处理器将应用程序加载到内存中,并在内存设定一些全局变量,如 settings,middleware 等。这些全局变量可以由 Django 应用程序和应用程序的中间件共同使用。
其中,settings 是 Django 应用程序中最重要的全局变量。它包含了除了 URL 路由跳转之外的所有应用程序配置信息,例如本地数据库 URL,模板引擎设置,调试开关等。middleware 则是一个提供额外功能的组件,可以对视图函数的请求和响应进行扩展。
以下是 WSGI 应用的初始化的代码段:
def get_wsgi_application():
django.setup(set_prefix=False)
return WSGIHandler()
get_wsgi_application() 函数用于实例化一个 WSGI 应用程序对象,并返回 WSGI 请求处理器对象。Django 在这里进行重要的初始化操作。
一旦 WSGI 应用程序在内存中设置好了,它将自动提供视图,即 URL 映射到相应的处理程序。在 Django 中,URLs 通过一个名为 urls.py 的文件进行定义和管理。当一个客户端请求到达 Django 时,它将映射到 urlpatterns 变量中的可调用视图函数上。
以下是一个 URL 映射器的示例:
from django.urls import path
from . import views
urlpatterns = [
path('about/', views.about),
path('contact/', views.contact),
]
在这里,URL “/about/” 和 “/contact/” 路径将使用 views.about 和 views.contact 函数来处理请求。
在匹配 URL 时,Django 会按顺序依次尝试匹配每个 URL 规则,并使用第一个匹配的 URL 规则。如果没有规则匹配请求的 URL 路径,则 Django 允许你定义一个捕获所有情况的通配符 URL 规则,即使用 path() 函数的 ‘path:’ 参数。
urlpatterns = [
path('about/', views.about),
path('contact/', views.contact),
path('<path:slug>/', views.page_not_found),
]
在这个示例中,Django 将试图匹配 “/about/” 和 “/contact/”,但无论它们能否成功匹配,最终都会跳转到 views.page_not_found 函数上。
如果 Django 能够正确地将请求 URL 映射到一个视图函数上,则该视图函数将被执行。视图函数是 Django MVC 模型中的控制器,它处理请求并返回响应。
以下是一个视图函数的示例:
from django.shortcuts import render
def index(request):
return render(request, 'index.html')
在这个示例中,index 视图函数将会渲染 index.html 模板,并将结果用 HTTP 响应的形式返回给客户端。
Django 将请求对象作为视图函数的第一个参数传递,并在对象中提供了用于访问请求数据和其他属性的方法和属性。视图函数还可以访问请求参数和其他内置对象(如 settings 和 middleware)。
当视图函数处理请求,并生成响应后,Django 将响应发送回客户端(通常是浏览器)。响应的内容都可以是可选的,Django 可以生成基于文本(HTML,JSON,XML 等)的响应,或者基于非文本(例如使用文件响应)的响应。
Django 提供了一组给用户访问的响应对象,并允许定制 HTTP 响应头。默认情况下,Django 使用 HttpResponse。HttpResponse 接受以下两类参数:
- content(必选项) - 由视图函数生成的一个字符串。
- content_type(可选项) - 此响应的内容类型,如 ‘text/html’ 或 ‘application/json’。

















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









