







1、python深浅拷贝
- 浅拷贝,指的是重新分配一块内存,创建一个新的对象,但里面的元素是原对象中各个子对象的引用。
- 深拷贝,是指重新分配一块内存,创建一个新的对象,并且将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中。因此,新对象和原对象没有任何关联。
2、什么是作用域
- 作用域是在运行时代码中的某些特定部分中变量,函数和对象的可访问性。换句话说,作用域决定了代码区块中变量和其他资源的可见性。
- 作用域就是一个独立的地盘,让变量不会外泄、暴露出去。也就是说作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突。
3、闭包函数
- 闭包函数指有权访问另一个函数作用域中变量的函数。简单理解就是 ,一个作用域可以访问另外一个函数内部的局部变量。
- 作用:延伸变量的作用范围。
- 闭包有三个特性:
- 函数嵌套函数
- 函数内部可以引用外部的参数和变量
- 参数和变量不会被垃圾回收机制回收
闭包函数就是给函数体传参的一种方式,函数嵌套也就是在函数中定义另一个函数。
闭包函数的特点
闭:定义在函数内部的函数
包:就是内部函数引用了外部函数中的变量因为作用域的原因,在外层函数无法拿到内层函数中的变量和内部函数。所以当需要使用时,要将函数名作为
变量名返回。这是闭包最常用的方式。
4、接口测试开展的时间
-
后端开发写好了接口,但是前端开发没有写好页面的时候,我们提前介入接口测试,提前发现bug,减少功能测试阶段发现更多的bug。
-
接口测试的介入时间:需求评审澄清之后,前后端开发会对接接口文档,达成一致之后已经输出了接口文档。
-
接口测试的测试时间:后端开发把接口开发完成之后,并且达到提测的要求,就可以开始进行接口测试了。
-
接口测试的流程
一、需求评审,熟悉业务和需求
二、开发提供接口文档
三、编写接口测试用例
四、用例评审
五、提测后开始测试
六、提交测试报告
5、测试用例设计如何提高测试覆盖率
1、确保测试需求分析的全面性
2、引入测试设计技术
3、使用自动化测试用例工具
4、测试用例定期评审
5、建立有效测试管理流程
6、结合软件质量的八大特性进行思考
6、怎么保证测试没问题
什么是漏测?具体的说,什么是测试漏测?
测试漏测是指软件产品在测试结束后出现了在测试过程中没有被发现的bug。我们知道,漏测是每一个软件测试者最头疼的事,一旦出现漏测,
首先给客户带来了非常不好的影响,特别是严重的功能性bug被漏测;
其次增加bug修复的成本,包括人力物力财力上;
再者给自己的测试团队也带来了不利影响,容易被别人质疑能力不足,难以取得信任。
不漏侧这个很难避免的,微软的产品都天天打补丁呢,包括google, facebook都经常打补丁。测试人员是没有办法保证不漏侧的,但是尽可能少漏测,而且每次保证漏测的原因都是不一样的。
►如何避免漏测?
-
吃透业务需求
需求评审阶段,产品经理、开发、测试在开会之前,一般都会收到一份需求文档和原型图。在开会前,研读好需求文档后,做好理解不明确和产生歧义的地方,待产品经理组会来讲解需求时,针对不懂的地方进行提问,认真记录。 -
2.提高用例质量
提高用例覆盖率,结合业务设计有效业务场景,保证测试有效性。
-
做好用例评审
测试人员结合用例对需求进行反串讲,把对需求的理解讲一遍,列出所有的测试点和测试场景,产品和开发同事评审是否有遗漏场景,如果没有异议,这样就可以很大程度的避免漏测了。 -
增加交叉测试
一个人精力毕竟有限,如果条件和时间允许,可以把测试过的功能交给你的搭档,让他帮忙在测试一下,毕 竟 每个人的测试思路不一样,也许也有收获也不一定呢。
- 有效回归测试
梳理主流程用例,尤其随着版本迭代和功能的增加,回顾测试用例极为重要,毕竟每次发版时,要保证主流 程没问题吧,主流程都有问题,难道还敢上线?
-
bug仲裁
在上线前,查看还有哪些问题,是未解决的,与产品、开发、测试经理商量,哪些bug是允许带到线上的,如果三方达成一致,那么线上再出问题,也是已知的,就没什么问题了。 -
做好漏测复盘
对待漏测态度上必须要重视,分析为何会漏测,是哪个环节出了问题,是流程问题还是技术问题?
同样的坑别踩第二次,技术不足的学习补齐,流程不足的规范流程。
把它当做一次提高的机会,也正因为这次机会,让你印象越深刻,能够避免下次不会再犯同样的错误。
- 总结
不得不说一句的是,漏测是不可能绝对避免的,我们能做的只能是尽量减少漏测现象,漏测现象会随着工作经验增加而逐渐减少。
所以测试的时候,一定要仔细、细致、认真,毕竟一次漏测可能会影响很多人,所以万万马虎不得呀。
7、软件交付时间紧,赶着上线怎么办?
1、安排业务熟悉的人做这个紧急版本的测试
2、把版本的的修改点, 新增需求搞清楚,搞清楚这些变更是如何实现的
3、罗列主流程的测试用例(思维导图),优先保证主流程没有问题,然后再发散测试
4、在执行测试过程中,把测试过的点记录下来,这样方便事后检查自己哪些测试点还没有测试到
5、发现bug还是要提交bug,不能因为时间紧,而不提交bug,导致bug遗漏
8、Postman断言(postman获取断言时,任何响应都必须转为JsonData 对象。)
-
在 postman 中我们是在Tests标签中编写断言,同时右侧封装了常用的断言,当然 Tests 除了可以作为断言,还可以当做后置处理器来编写一些后置处理代码,经常应用于:
- 获取当前接口的响应,传递给下一个接口
- 控制多个接口间的执行顺序。
-
常见断言方法
- 1、状态码断言
判断接口响应的状态码:Status code: code is 200 pm.test("Status code is 200", function () { //Status code is 200是断言名称,可以自行修改 pm.response.to.have.status(200); //这里填写的200是预期结果,实际结果是请求返回结果 }); 判断接口响应码是否与预期集合中的某个值一致 pm.test("Successful POST request", function () { pm.expect(pm.response.code).to.be.oneOf([201,202]); //检查响应码是否为201或者202 }); 判断状态码名称(也就是状态码后面的描述)是否包含某个字符串:Status code:code name has string pm.test("Status code name has string", function () { pm.response.to.have.status("OK"); //断言响应状态消息包含OK });- 2、响应内容断言
断言响应体中包含XXX字符串:Response body:Contains string pm.test("Body matches string", function () { pm.expect(pm.response.text()).to.include("string_you_want_to_search"); //pm.response.text() }); 响应结果如果是json,断言响应体(json)中某个键名对应的值:Response body : JSON value check pm.test("Your test name", function () { var jsonData = pm.response.json(); //获取响应体,以json显示,赋值给jsonData .注意:该响应体必须返会是的json,否则会报错 pm.expect(jsonData.value).to.eql(100); //获取jsonData中键名为value的值,然后和100进行比较 }); 断言响应体等于XXX字符串:Response body : is equal to a string pm.test("Body is correct", function () { pm.response.to.have.body("response_body_string"); //获取响应体等于response_body_string });- 3、响应头断言
断言响应头包含:Response headers:Content-Type header check pm.test("Content-Type is present", function () { pm.response.to.have.header("Content-Type"); //断言响应头存在"Content-Type" });=- 4、响应速度断言
判断实际响应时间是否与低于预期时间:Response time is less than 200ms
pm.test("Response time is less than 200ms", function () { pm.expect(pm.response.responseTime).to.be.below(200); });
-
常用断言对应的脚本
--清除一个环境变量 postman.clearEnvironmentVariable("variable_key"); --断言响应数据中是否存在某个元素 tests["//断言返回的数据中是否存在__pid__这个元素"] = responseBody.has("pid"); --断言response等于预期内容 tests["Body is correct"] = responseBody === "response_body_string"; --断言json解析后的key的值等于预期内容 tests["Args key contains argument passed as url parameter"] = 'test' in responseJSON.args --检查response的header信息是否有被测字段 tests["Content-Type is present"] = postman.getResponseHeader("Content-Type"); --校验响应数据中,返回的数据类型 var jsonData = JSON.parse(responseBody);//第一步先转化为json字符串。其中变量(jsonData)可以自行定义...... tests["//data.category.name__valuse的值的类型是不是string"] = typeof(jsonData.data.category[0].name) == "string"; --响应时间判断 tests["Response time is less than 200ms"] = responseTime < 200; --设置环境变量 postman.setEnvironmentVariable("variable_key", "variable_value"); --断言状态码 tests["Status code is 200"] = responseCode.code != 400; --检查响应码name tests["Status code name has string"] = responseCode.name.has("Created"); --断言成功的post请求返回码 tests["Successful POST request"] = responseCode.code === 201 || responseCode.cod
9、MySQL索引
什么是索引?请简述常用的索引有哪些种类?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则在表中搜索所有的行相比,索引有助于更快地获取信息
通俗的讲,索引就是数据的目录,就像看书一样,假如我想看第三章第四节的内容,如果有目录,我直接翻目录,找到第三章第四节的页码即可。如果没有目录,我就需要将从书的开头开始,一页一页翻,直到翻到第三章第四节的内容。
InnoDB:支持 B-tree,Full-text 等索引,不支持 Hash 索引;
MyISAM:支持 B-tree,Full-text 等索引,不支持 Hash 索引;
Memory:支持 B-tree,Hash 等索引,不支持 Full-text 索引;
NDB:支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive:不支持 B-tree、Hash、Full-text 等索引;
10、postman接口关联(提取数据—验证—放入数据----执行 )
-
方法一:使用json提取器实现接口关联
-
方法二:使用正则表达式提取器实现接口关联
-
方法三:使用cookie提取器实现接口关联(通过cookie来取值)
11、OSI七层协议各层详解
OSI七层协议(Open System Interconnection reference model)是一个由国际标准化组织(ISO)提出的标准通信协议体系结构,该体系结构把计算机网络体系结构的各个方面分割成了七个不同的抽象层,每一层都有各自的通信功能。OSI七层协议由上往下依次为:
1.物理层(Physical Layer)
物理层是位于通信系统底层的协议层,主要负责把比特流转化为可以在物理介质上传输的物理信号。物理层主要涉及数据传输的物理介质、机械电气特性、接口标准、传输速率和数据传输距离等问题。
2.数据链路层(Data-Link layer)
数据链路层主要建立在物理层之上,是建立与当地网络协议所规定的接口进行通信的实体层。它定义了如何让类似的网络接口通信,并指定当网络层出现错误时,如何进行检测和纠正。数据链路层一般包括两个子层:逻辑链路控制(LLC)和介质访问控制(MAC)。
3.网络层(Network Layer)
网络层主要用于在不同网络之间进行数据传送和路由选择,通过网络地址来实现通信。主要协议有IP(Internet Protocol)协议、ICMP(Internet Control Message Protocol)协议、IGMP(Internet Group Management Protocol)协议、OSPF(Open Shortest Path First)协议等。
4.传输层(Transport Layer)
传输层负责对网络通信质量进行管理,可以为应用程序提供良好的数据传输服务。主要协议有TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)。
5.会话层(Session Layer)
会话层主要负责建立、管理和终止会话连接,提供端到端的数据传输流控制和同步服务。主要协议有RPC(Remote Procedure Call)协议、NCP(NetWare Core Protocol)协议等。
6.表示层(Presentation Layer)
表示层用于处理交换数据的表示方式,例如数据压缩、加密、解密等操作。主要协议有ASCII、EBCDIC、JPEG、GIF等。
7.应用层(Application Layer)
应用层主要用于提供给用户的网络服务。例如:FTP(File Transfer Protocol)协议、HTTP(Hyper Text Transfer Protocol)协议、SMTP(Simple Mail Transfer Protocol)协议、SSH(Secure Shell Protocol)协议以及DNS(Domain Name System)协议等。
计算机网络七层协议的功能:
计算机网络的七层协议是一个分层的通讯协议体系结构,每一层都定义了不同的功能,便于开发和实现网络通讯的标准化和互操作性。各层的主要功能如下:
1.物理层(Physical Layer):传输比特流,定义能传输的电气和物理特性。
2.数据链路层(Data Link Layer):传输帧,定义帧的格式、检测和控制差错,以及媒体访问控制。
3.网络层(Network Layer):地理位置传输,实现不同网络间的路由选择和数据传输。
4.传输层(Transport Layer):端到端传输,提供可靠的传输服务,例如 TCP 协议。
5.会话层(Session Layer):建立、管理和终止会话连接,提供端到端的数据传输流控制和同步服务。
6.表示层(Presentation Layer):处理交换数据的表示方式,例如数据压缩、加密、解密等操作。
7.应用层(Application Layer):提供特定的应用服务,例如文件传输、电子邮件、Web浏览等。
12、测试用例模板

13、怎么测试一个接口
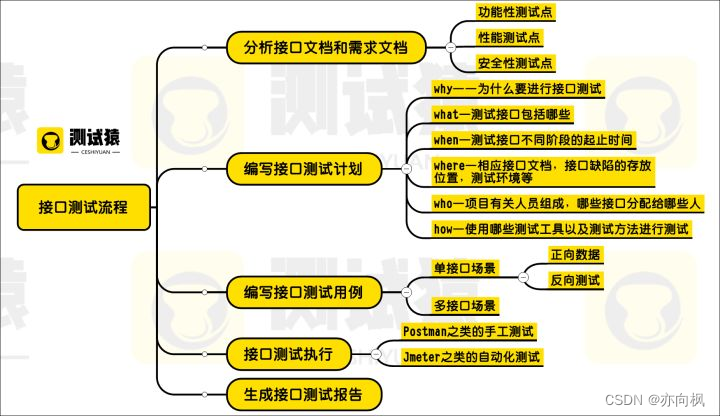
1、分析接口文档和需求文档
分析接口文档或者需求文档一般会去找测试点,那么接口测试的测试点我们一般从几种方向去找
· 功能性测试点
· 性能测试点
· 安全性测试点
2、编写接口测试计划
测试计划就是功能测试计划基本一样就是知名的5w1h了
- why——为什么要进行接口测试;
- what—测试接口包括哪些;
- when—测试接口不同阶段的起止时间;
- where—相应接口文档,接口缺陷的存放位置,测试环境等;
- who—项目有关人员组成,哪些接口分配给哪些人;
- how—使用哪些测试工具以及测试方法进行测试。
3、编写接口测试用例
测试用例就是根据具体的哪个接口来编写,一般会分为单接口和多接口两种场景来编写测试用例
- 单接口场景的测试
正向数据:也就是能正常发送请求,正常获取响应的数据,一般我们从三个方面去组织:
所有必填参数
全部参数(必填参数+选填参数)
参数组合(必填参数+某些选填参数)
反向测试:用不属于规定范围的数据区发送请求检查服务器能否正常处理
异常数据:数据为空,长度过多或者过少(边界值外),类型不符(需要数字类型传递str类型),错误的数据
异常的参数:不传参数,少传参数,多传参数,传递错误的参数
异常的业务数据:结合业务功能考虑输出的各种异常返回情况
2) 多接口场景的测试
业务场景功能测试(站在用户角度考虑常用的使用场景)
多业务场景功能测试主要是测试接口之间数据依赖
4、接口测试执行
根据设计的测试用例就可以执行测试用例当然执行的方式有几种
-
使用postman之类的工具,一个一个进行测试,这种方式我们叫做手工测试
-
使用jmeter之类的有自动化功能方式进行测试,这种叫做工具自动化测试
-
我们可以自己编写测试脚本,使用测试脚本自动加载测试,这种就是自动化测试了
5、生成接口测试报告。
测试完成了以后就可以生成测试报告了
14、GET和POST请求的区别
(1)post更安全(不会作为url的一部分,不会被缓存、保存在服务器日志、以及浏览器浏览记录中)
(2)post发送的数据更大(get有url长度限制)
(3)post能发送更多的数据类型(get只能发送ASCII字符)
(4)post比get慢
(5)post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作(淘宝,支付宝的搜索查询都是get提交),目的是资源的获取,读取数据.
总结:GET把参数包含在URL中,POST通过request body传递参数,所以Post更加安全一些;Get的效率比Post高一些,但是Get请求发送的参数是有限的,而Post请求是没有限制的(理论上来讲)。
15、jmeter的使用
- 添加线程组
- 添加HTTP请求
- 添加查看结果树
- 看查看结果树的返回
16、测试方法
-
常用的黑盒测试方法有:等价类划分法;边界值分析法;因果图法;场景法;正交实验设计法;判定表驱动分析法;错误推测法;功能图分析法。
-
常用白盒测试方法:
静态测试:不用运行程序的测试,包括代码检查、静态结构分析、代码质量度量、文档测试等等。它可以由人工进行,充分发挥人的逻辑思维优势,也可以借助软件工具(Fxcop)自动进行。
动态测试:需要执行代码,通过运行程序找到问题,包括功能确认与接口测试、覆盖率分析、性能分析、内存分析等。
白盒测试中的逻辑覆盖包括语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖和路径覆盖。六种覆盖标准发现错误的能力呈由弱到强的变化:
1.语句覆盖:每条语句至少执行一次。
2.判定覆盖:每个判定的每个分支至少执行一次。
3.条件覆盖:每个判定的每个条件应取到各种可能的值。
4.判定/条件覆盖:同时满足判定覆盖和条件覆盖。
5.条件组合覆盖:每个判定中各条件的每一种组合至少出现一次。
6.路径覆盖:使程序中每一条可能的路径至少执行一次。
17、B/S,C/S架构的优缺点
1、B/S架构的优点:
①、具有分布性特点,可以随时随地进行查询,浏览等业务处理;
②、业务扩展简单方便,通过增加网页即可增加服务器功能;
③、维护简单方便,只需要改变网页,即可实现所有用户的同步更新;
④、开发简单,共享性强。
2、B/S架构的缺点:
①、在跨浏览器上B/S架构不尽如人意;
②、表现要达到C/S程序的程度要花费不少的精力;
③、在速度和安全性上需要花费巨大的设计成本,这是B/S架构的最大问题;
④、客户端服务端的交互是请求-响应模式,需要刷新页面;
3、C/S架构的优点:
①、C/S架构的界面和操作可以很丰富;
②、安全性能可以很容易保证,实现多层认证也不难;
③、由于只有一层交互,因此响应速度较快;
4、C/S架构的缺点:
①、适用面窄,通常用于局域网中。
②、用户群固定。由于程序需要安装才可使用,因此不适合面向一些不可知的用户。
③、维护成本高,发生一次升级,则所有客户端的程序都需要改变。
简单的说:b/s:分布性强、开发简单、共享性强、维护方便;c/s:速度快、体验佳、处理能力强
18、jmeter中的事务
- 事务是用户自定义的一个标识,是一个或多个操作完成一个业务所花费的时间,事务时间反映的是一个操作过程的响应时间
19、jmeter怎么参数化批量操作
-
1、用户定义的变量(User Defined Variables)
用于存放不需要随迭代发生改变的参数(只取一次值的参数),比如host、端口号、url
-
2、CSV Data Set Config
同一个变量有多组值时,可以使用这种方式,比如验证多个用户登录。
-
函数助手
测试过程中,需要生成一些随机变量,比如订单号不能重复,可以用函数助手常用的几个函数来生成。引用的时候直接引用函数的表达式即可
__Random随机数,填写最小值和最大值,点击生成即可生成函数表达式
__time获取当前时间
-
4、用户参数(User Parameters)
这个方式和CSV Data Set Config有着异曲同工之妙
-
5、正则表达式提取器
测试过程中,会遇到token动态变化/需要从上个接口的返回取值的情况
-
6、json提取器
20、什么时候开始性能测试?
1.功能测试已完成,系统能够正常运行;
2.已经了解了性能测试的基本指标(磁盘,内存,cpu,io);
3.了解所测系统的接口文档;
4.确保压力测试在测试环境下进行;


性能测试有关术语是什么意思?
(1)负载:模拟业务操作对服务器造成压力的过程,比如模拟100个用户进行发帖。
(2)性能测试(Performance Testing):模拟用户负载来测试系统在负载情况下,系统的响应时间、吞吐量等指标是否满足性能要求。
(3)负载测试(Load Testing):在一定软硬件环境下,通过不断加大负载(不同虚拟用户数)来确定在满足性能指标情况下能够承受的最大用户数。简单说,可以帮我们对系统进行定容定量,找出系统性能的拐点,给予生产环境规划建议。这里的性能指标包括TPS(每秒事务数)、RT (事务平均响应时间)、CPUUsing (CPU利用率)、 Mem Using(内存使用情况)等软硬件指标。从操作层面上来说,负载测试也是一种性能测试手段,比如下面的配置测试就需要变换不同的负载来进行测试。
(4)配置测试(Configuration Testing):为了合理地调配资源,提高系统运行效率,通过测试手段来获取、验证、调整配置信息的过程。通过这个过程我们可以收集到不同配置反映出来的不同性能,从而为设备选择、设备配置提供参考。
(5)压力度测试(Stress Testing):在一定软硬件环境下,通过高负载的手段来使服务器资源(强调服务器资源,硬件资源)处于极限状态,测试系统在极限状态下长时间运行是否稳定,确定是否稳定的指示包括TPS、RT、CPU Using、Mem Using等。
(6)稳定性测试(Endurance Testing):在一定软硬件环境下,长时间运行一定负载,确定系统在满足性能指标的前提下是否运行稳定。与上面的压力度测试区别在于负载并不强调是在极限状态下(很多测试人员会持保守观念,在测试时会验证极限状态下的稳定性),着重的是满足性能要求的情况下,系统的稳定性、比如响应时间是否稳定、TPS是否稳定。一般我们会在满足性能要求的负载情况加大1.5到2倍的负载量进行测试。
(7)TPS:每秒完成的事务数,通常指每少成功的事务数,性能测试中重要的综合性性能指标。一个事务是一个业务度量单位,有时一个事务会包括多个子操作,但为了方便统计,我们会把这多个子操作计为一个事务。比如笔电子支付操作,在后台系统中可能会经历会员系统、账务系统、支付系统、会计系统、银行网关等,但对于用户来说只想知道整笔支付花费了多长时间。
(8) RT/ART (Response Timelavernge Response
Time):响应时间平均响应时间,指一个事务花费多长时间完成(多长时间响应客户请求),为了使这个响应时间更具代表性,会统计更多的响应时间然后取平均值,即得到了事务平均响应时间(ART),为了方便大家通常会直接用RT来代替ART, ART 与RT是代表同一个意思。
(9) PV (Page View):每秒用户访问页面的次数,此参数用来分析平均每秒有多少用户访问页面。(10) Vuser 虚拟用户(Virtual user):模拟真实业务逻辑步骤的虚拟用户,虚拟用户模拟的操作步骤都被记录在虚拟用户脚本里。Vuser脚本用于描述Vuser在场景中执行的操作。
(11)Concurreney并发,并发分为狭义和广义两类。狭义的并发,即所有的用户在同具时刻做同一一件事情或操作,这种操作一般针对同一类型的业务,或者所有用户进行完全一样的操作,目的是测试数据库和程序对并发操作的处理。广义的并发,即多个用户对系统发出了请求或者进行了操作,但是这些请求或操作可以是不同的。对整个系统而言,仍然有很多用户同时进行操作。狭义并发强调对系统的请求操作是完全相同的,多适用于性能测试、负载测试、压力测试、稳定性测试场景;广义并发不限制对系统的请求操作,多适用于混合场景、稳定性测试场景。
(12)场景(Scenario):性能测试过程中为了模拟真实用户的业务处理过程,在LoadRunner中构建的基于事务、脚本、虚拟用户、运行设置、运行计划、监控、分析等的一系列动作的集合,称之为性能测试场景。场景中包含了待执行脚本、脚本组、并发用户数、负载生成器、测试目标、测试执行时的配置条件等。
(13) 思考时间(Think Time):模拟正式用户在实际操作时的停顿间隔时间。从业务的角度来讲,思考时间指的是用户在进行操作时,每个请求之间的间隔时间。在测试脚本中,思考时间体现为脚本中两个请求语句之间的间隔时间。
(14)标准差(Std. Deviation):该标准差根据数理统计的概念得来,标准差越小,说明波动越小,系统越稳定,反之,标准差越大,说明波动越大,系统越不稳定。包括响应时间标准差、TPS标准差、Running、Vuser 标准差、Load 标准差、CPU资源利用率标准差、WebResources 标准差等。举例响应时间标准差。
21、Redis支持哪几种数据类型?
答:Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
还有一些数据结构如HyperLogLog、Geo、Pub/Sub等,我们也最好知道,另外像Redis Module,像BloomFilter,RedisSearch,Redis-ML等,能有个印象,哪怕知其然不知其所以然也比听都没听过好点。
22、数据库的存储过程
存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集。经编译后存储在数据库中。存储过程是数据库中的一个重要对象,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是由流控制和 SQL语句书写的过程,这个过程经编译和优化后存储在数据库服务器中。存储过程可由应用程序通过一个调用来执行,而且允许用户声明变量。同时,存储过程可以接收和输出参数、返回执行存储过程的状态值,也可以嵌套调用。
23、常用状态码
一、1开头的状态码(信息类)
100,接受的请求正在处理,信息类状态码
二、2开头的状态码(成功类)
2xx(成功)表示成功处理了请求的状态码
200(成功)服务器已成功处理了请求。
三、3开头的状态码(重定向)
3xx(重定向)表示要完成请求,需要进一步操作。通常这些状态代码用来重定向。
301,永久性重定向,表示资源已被分配了新的 URL
302,临时性重定向,表示资源临时被分配了新的 URL
303,表示资源存在另一个URL,用GET方法获取资源
304,(未修改)自从上次请求后,请求网页未修改过。服务器返回此响应时,不会返回网页内容
四、4开头的状态码(客户端错误)
4xx(请求错误)这些状态码表示请求可能出错,妨碍了服务器的处理
400(错误请求)服务器不理解请求的语法
401表示发送的请求需要有通过HTTP认证的认证信息
403(禁止)服务器拒绝请求
404(未找到)服务器找不到请求网页
五、5开头的状态码(服务器错误)
5xx(服务器错误)这些状态码表示服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求的错误
500,(服务器内部错误)服务器遇到错误,无法完成请求
503,表示服务器处于停机维护或超负载,无法处理请求
24、ll和ls的区别
"ls"是列出文件和目录的基本命令,而"ll"是"ls -l"的缩写,用于以长格式列出文件和目录的详细属性信息。
25、接口测试用例模板

26、web测试和app测试的差异
1.性能方面:
web页面可能更关注响应时间,而app更关注流量、电量、QPS。
2.系统架构方面:
web项目,一般都是b/s架构,基于浏览器的,而app则是c/s的,必须要有客户端。在系统测试的时候就会产生区别了。首从系统架构来看的话,web测试只要更新了服务器端,客户端就会同步会更新。而且客户端是可以保证每一个用户的客户端完全一致的。但是app端是不能够保证完全一致的,除非用户更新客户端。如果是app下修改了服务端,意味着客户端用户所使用的核心版本都需要进行回归测试一遍。
3.兼容性方面:
web是基于浏览器的,所以更倾向于浏览器和电脑硬件,电脑系统的方向的兼容,不过一般还是以浏览器的为主。而浏览器的兼容则是一般是选择不同的浏览器内核进行测试(IE、chrome、Firefox)。app的测试不仅要看分辨率,屏幕尺寸,还要看设备系统。系统总的来说也就分为Android和iOS。
4.相比较web测试,app更是多了一些专项测试:
一些异常场景的考虑以及弱网络测试。这里的异常场景就是中断,来电,短信,关机,重启等。而弱网测试是app测试中必须执行的一项测试。包含弱网和网络切换测试。需要测试弱网所造成的用户体验,重点要考虑回退和刷新是否会造成二次提交。需要测试丢包,延时的处理机制。避免用户的流失
5.安装、卸载、更新:
web测试是基于浏览器的所以不必考虑这些。而app是客户端的,则必须测试安装、更新、卸载。除了常规的安装、更新、卸载还要考虑到异常场景。包括安装时的中断、弱网、安装后删除安装文件,更新的强制更新与非强制更新、增量包更新、断点续传、弱网,卸载后删除app相关的文件等等。
6.界面操作:
app产品的用户都是使用的触摸屏手机,所以测试的时候还要注意手势,横竖屏切换,多点触控,事件触发区域等测试。
27、python的数据类型有哪几种
Python中的数据类型主要有:Number(数字)、Boolean(布尔)、String(字符串)、List(列表)、Tuple(元组)、Dictionary(字典)、Set(集合)。
其中又分为可变数据类型和不可变数据类型,可变数据类型是指可以随着函数的执行发生变化,而不可变数据类型不可以改变
不可变数据类型(3个):Number(数字)、Boolean(布尔)、String(字符串)、Tuple(元组)
可变数据类型(4个):List(列表)、Dictionary(字典)、Set(集合)
28、功能测试流程
1、研读需求文档
2、编写测试计划
3,设计与编写测试用例
4,测试用例评审
5,搭建测试环境、执行测试用例
6,提交缺陷报告、回归测试
7,测试总结报告输出
29、bug定位方式
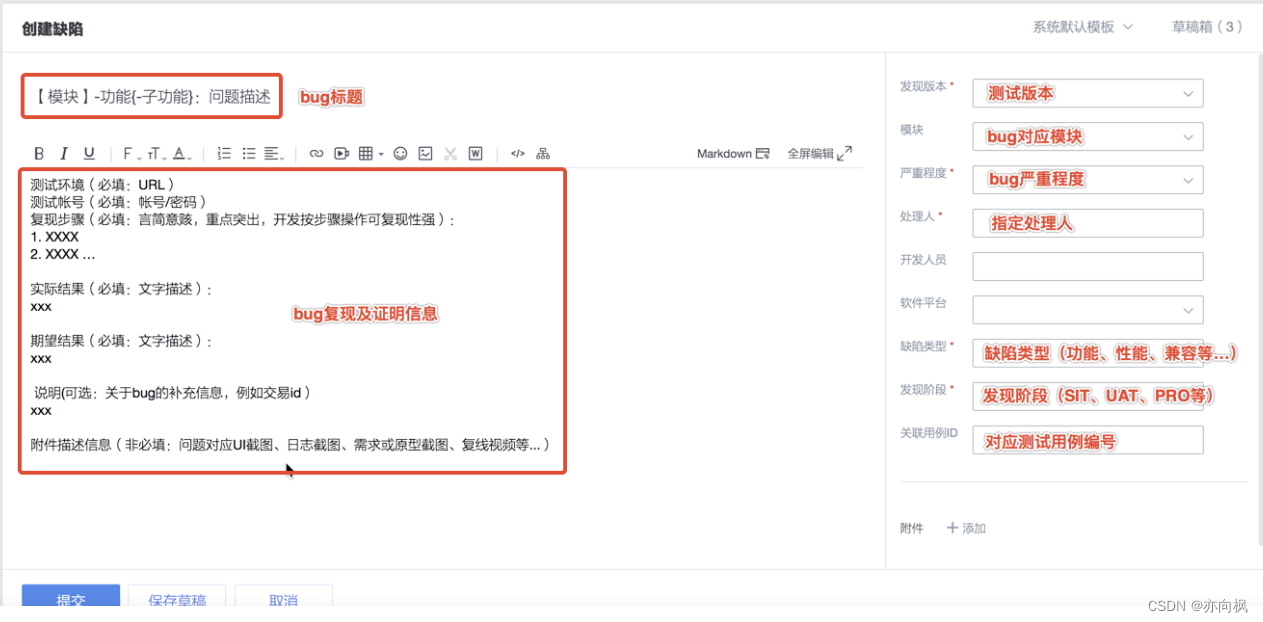
当系统出现bug时,一定要将bug现象进行录制保留,保留现象是为了证明这个bug出现过,如果bug是固定重现还好说,如果该bug无法重现,那么保存的截图都是你直接证据,要养成良好的保存现场的习惯
提BUG这块,还是要体现出测试的专业性,标题简洁、问题环境标识清楚、问题详细描述清楚、系统错误表象贴图、接口传参返参贴图、必要时贴服务器日志,总结来说不该少的bug标签一个不要少
一、小型产品,前后端一人统筹
一些小型程序,例如前后端都用node、php语言开发的,整个系统前后端是同一个开发的时候,那么作者可以自信的给你说,系统出现问题时,bug大胆的提,往猝死的提,责任人错不了!
二、常规系统,多人开发协同
前置:测试之前该测试人员对系统、业务、环境部署、开发人员等较为熟悉
在测试之前打开对应浏览器的F12直接开个新页签,或者使用抓包工具等,系统呈现出问题时,查看对应的请求、日志信息等我们才能去全面的定位是前端还是后端人员的问题,具体给大家介绍以下几个常用方法
1.分析问题场景进行预判
先查看页面表象,根据问题表像判断问题可能出现的原因,进行缩小范围,并且准备好录制工具,录制问题
系统页面无法正常访问的提示5开头的找后端,4开头的先检查请求地址或者对应的权限,进入系统页面正常打开,提示异常代码错误的直接找后端
进入系统页面展示异常图片视频相关提示Flash等相关信息进行安装Flash如若还不行找前端,界面UI展示兼容性错误找前端
如若系统访问正常,进入操作页面,功能性报错信息,就进入下面环节,抓包查看对应请求体,看日志等
2.关注请求体的状态码
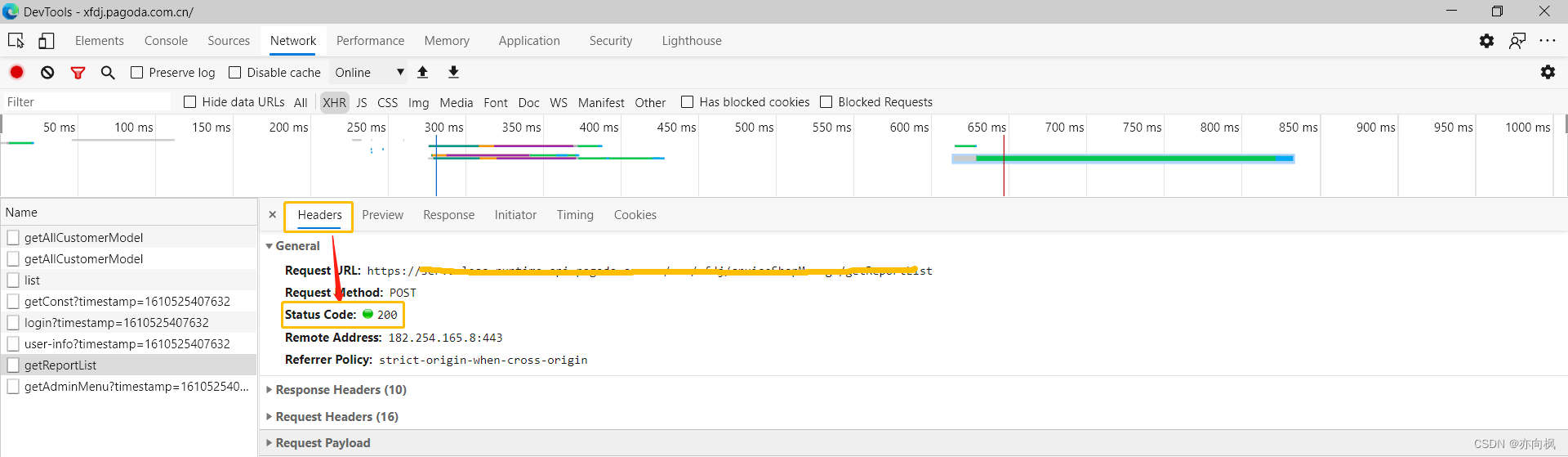
4**开头的状态码一般都是客户端(前端)的问题;例如常见的404确认下是否是请求的地址有错,403确认是否有权限访问,具体可百度
5**开头的状态码一般都是服务端(后端)问题,例如常见的500,则表示是服务器内部错误,503网络过载导致服务端延时,502服务器崩溃等,具体可百度
3.关注请求的入参与响应数据
通过访问报错的页面,加载错误请求时我们通过F12进行分析请求包,查看对应的入参以及响应数据
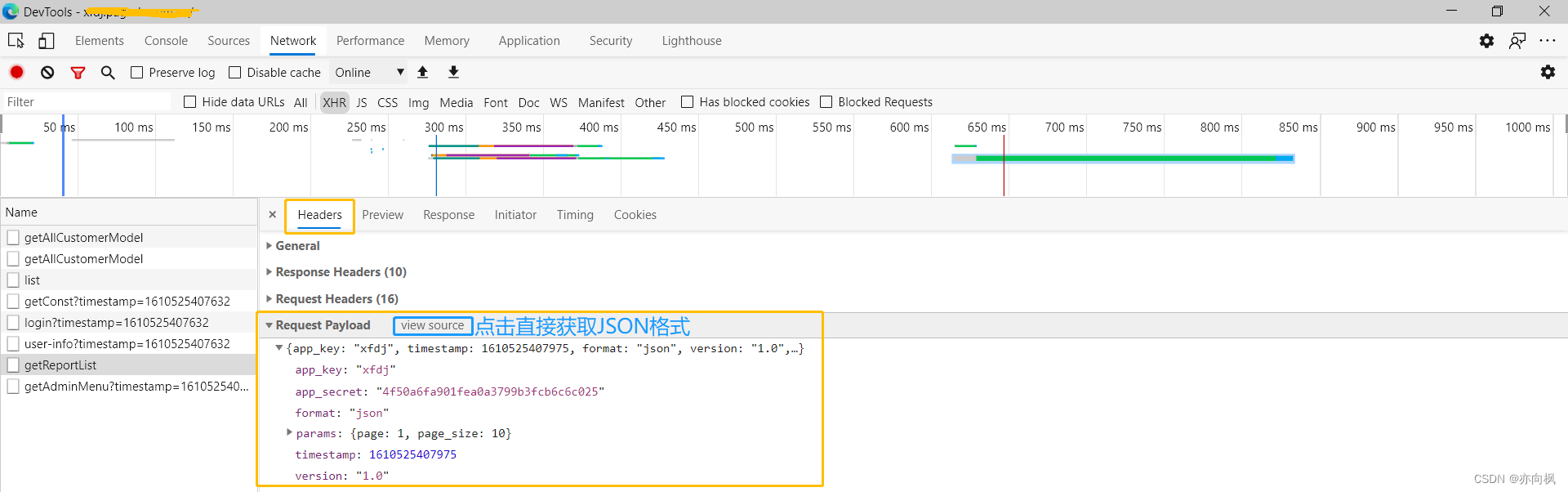
例如:请求入参错误,那么该bug属于前端的错误;入参标准可以根据前端页面的输入的内容或者选择的内容,进行核验,入参格式以及是否必填等可以对应接口文档去进行分析或跟开发确认
例如:请求未响应或者响应数据错误,那么该bug就属于后端的错误;一般是数据库查看报错,例如删了某个表查询报错误空指针等
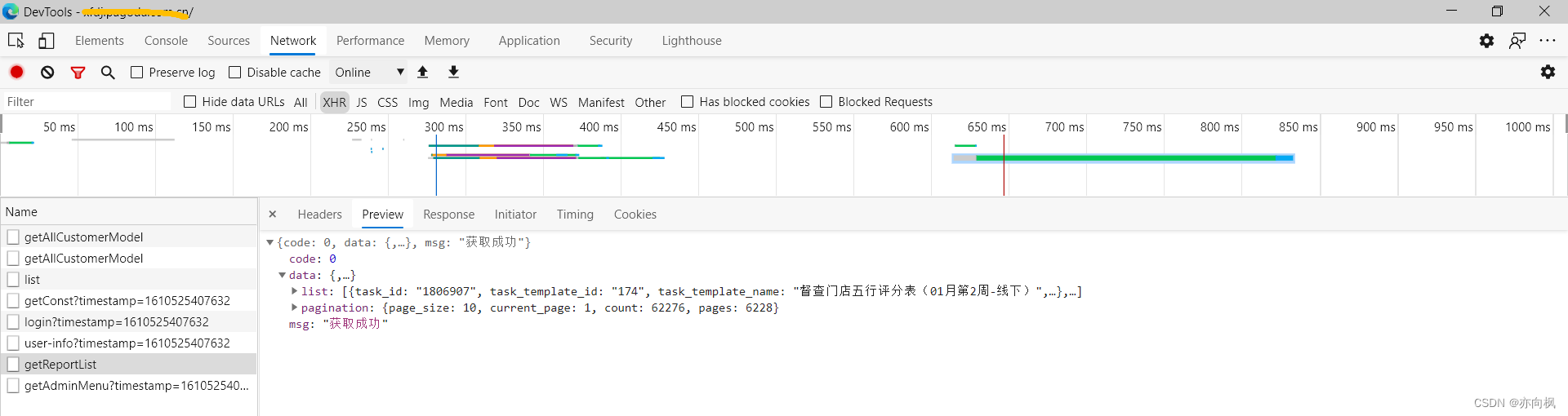
如果请求的入参或者响应数据都没问题,可以跟开发反馈是不是浏览器解析的问题,可以换个浏览器测试
4.查看日志
针对服务端类型的报错,我们可以进行登录日志平台或者服务器对应Log目录下查看打印出的日志
常用查看日志命令tail ,/error进行快速检索关键词接口名等相关内容
拿到对应的日志,将日志文件贴进bug单,指派给后端,提高专业性,测试人员也要养成看日志的习惯,看着看着就懂了
5.经验法则
在系统前端页面当碰见服务器配置相关报错的信息例如Nginx或者代码以及SQL相关的提示报错信息直接找后端处理,例如JAVA* 、.PHP、SQL等异常报错
前端字符校验、格式校验、等,浏览器界面UI兼容性以及插件,或者APP、小程序类调用手机相关功能拍照、语音无法正常调用直接找前端
30、JMeter基本组成部分
-
线程组
-
断言
-
监听器
-
前置处理器
-
配置元件
-
后置处理器
-
控制器
-
定时器
-
取样器
31、性能测试,负载测试,压力测试以及容量测试有什么联系与区别
1、性能测试(Performance Test):通常收集所有和测试有关的所有性能,通常被不同人在不同场合下进行使用。
关注点:how much和how fast
2、负载测试(Load Test):负载测试是一种性能测试,指数据在超负荷环境中运行,程序是否能够承担。 关注点:how much
3、压力测试(Stress Test): 压力测试(又叫强度测试)也是一种性能测试,它在系统资源特别低的情况下软件系统运行情况,目的是找到系统在哪里失效以及如何失效的地方。包括
Spike testing:短时间的极端负载测试
Extreme testing:在过量用户下的负载测试
Hammer testing:连续执行所有能做的操作
4、容量测试(Volume Test):确定系统可处理同时在线的最大用户数 关注点:how much(而不是how fast) 容量测试,通常和数据库有关,容量和负载的区别在于:容量关注的是大容量,而不需要关注使用中的实际表现。
5、极限测试 Extreme testing:在过量用户下的负载测试 Hammer testing:连续执行所有能做的操作
负载测试是测试软件本身最大所能承受的性能测试;
压力测试就是一种破坏性的性能测试;
32、selenuim弹窗怎么处理
1、在Selenium中如果只是简单的对弹窗进行定位的话,是定位不到的
2、因为这种弹窗是不属于HTML的元素的,它是属于浏览器自带的弹窗(是由JavaScript生成的),所以用定位元素的方法是定位不了的
⑴这类元素在使用F12选择元素时,是选择不到的
3、Selenium中的WebDriver对象提供了**switch_to_alert()**方法定位(捕获)到各种弹窗(alert、confirm、prompt)
4、WebDriver对象在处理弹框时主要有以下几种方法:
⑴**switch_to_alert():**定位弹出的对话框
⑵**text:**获取对话框文本值
⑶**accept():**相当于点击"确认"
⑷**dismiss():**相当于点击"取消"
⑸**send_keys():**输入值,该方法只能在prompt类弹框中使用
5、基本思路:先利用方法switch_to_alert()定位到alert等弹出框,再进行相应的处理(确认、取消、输入值)
33、一条sql执行过长的时间,你如何优化,从哪些方面?
1、查看 sql 是否涉及多表的联表或者子查询,如果有,看是否能进行业务拆分,相关字段冗余或者合并成临时表(业务和算法的优化)。
2、涉及链表的查询,是否能进行分表查询,单表查询之后的结果进行字段整合。
3、如果以上两种都不能操作,非要链表查询,那么考虑对相对应的查询条件做索引。加快查询速度。
4、针对数量大的表进行历史表分离(如交易流水表)。
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,mysql 有自带的 binlog 实现主从同步。
6、explain 分析 sql 语句,查看执行计划,分析索引是否用上,分析扫描行数等等。
7、查看 mysql 执行日志,看看是否有其他方面的问题。
上面我将 explain 关键字加粗显示,就是很多面试官他并不直接问你 sql 优化,他会问你知道什么是 mysql 的执行计划吗?其实就是想考你知不知道 explain 关键字,所以乡亲们对 explain 这个不了解的,还需要自己线下去网上查看学习一下哦。
34、数据库的优化
1.优化索引、SQL语句、分析慢查询。
2.设计表的时候严格根据数据库的设计范式来设计数据库。
三大范式:
1.表字段的原子性(不可拆分);
2.满足第一范式的基础上,有主键依赖;
3.满足第一二范式的基础上,非主属性之间没有依赖关系。
3.使用缓存,把经常访问到的数据而且不需要经常变化的数据放在缓存中,能节约磁盘IO。
4.优化硬件;采用SSD,使用磁盘队列技术等。
5.采用MySQL内部自带的表分区技术,把数据分成不同的文件,能够提高磁盘的读取效率。
6.垂直分表;把一些不经常读的数据放在一张表里,节约磁盘IO。
7.主从分离读写;采用主从复制把数据库的读操作和写入操作分离开来;
8.分库分表机器(数据量特别大),主要的原理就是数据路由。
9.选择合适的表引擎,参数上的优化。
10.进行架构级别的缓存,静态化和分布式。
11.不采用全文索引。
12.采用更快的存储方式,例如NoSQL存储经常访问的数据。
35、如何实现加密接口的处理
(1)写个函数或者方法,把要加密的参数使用这个函数过滤一遍,等于就是说把数据丢进去,加密了之后,再通过这个加密好的数据传输过去就可以。
(2)至于用什么加密算法,这个要根据产品和自己的业务场景和需求不管是AES或者公钥私钥也好看自己的选择。
(3)也可能是编码的问题,就直接用base64码把需要传输加密的东西通过base64返回base64码,然后再放进去,然后再进行传输。
(4)这是编码不是加密,真的要加密的话,首先把要用的参数加好密之后再被传输出去,传输的过程中把传输的数据进行一次加密和封装之后再发送过去。
(5)用jmeter做接口测试用post-processor加beanshell进行加密解密,再从日志中查找参数,然后具体的加密算法要看需求。
(6)每个测试工具提供的加密算法是不一样的,工具不一样加密算法也是不一样的。
36、同步和异步的区别
同步,可以理解为在执行完一个函数或方法之后,一直等待系统返回值或消息,这时程序是出于阻塞的,只有接收到返回的值或消息后才往下执行其他的命令。
异步,执行完函数或方法后,不必阻塞性地等待返回值或消息,只需要向系统委托一个异步过程,那么当系统接收到返回值或消息时,系统会自动触发委托的异步过程,从而完成一个完整的流程。
同步,就是实时处理(如打电话),比如服务器一接收客户端请求,马上响应,这样客户端可以在最短的时间内得到结果,但是如果多个客户端,或者一个客户端发出的请求很频繁,服务器无法同步处理,就会造成涌塞。
同步如打电话,通信双方不能断(我们是同时进行,同步),你一句我一句,这样的好处是,对方想表达的信息我马上能收到,但是,我在打着电话,我无法做别的事情。
异步,就是分时处理(如收发短信),服务器接收到客户端请求后并不是立即处理,而是等待服务器比较空闲的时候加以处理,可以避免涌塞。
异步如收发收短信,对比打电话,打电话我一定要在电话的旁边听着,保证双方都在线,而收发短信,对方不用保证此刻我一定在手机旁,同时,我也不用时刻留意手机有没有来短信。这样的话,我看着视频,然后来了短信,我就处理短信(也可以不处理),接着再看视频。
对于写程序,同步往往会阻塞,没有数据过来,我就等着,异步则不会阻塞,没数据来我干别的事,有数据来去处理这些数据。
同步在一定程度上可以看做是单线程,这个线程请求一个方法后就待这个方法给他回复,否则他不往下执行(死心眼)。
异步在一定程度上可以看做是多线程的(废话,一个线程怎么叫异步),请求一个方法后,就不管了,继续执行其他的方法
37、SQL中事务的特性
-
原子性(Atomicity):事务应该被视为一个原子操作,即要么全部成功,要么全部失败。如果任何单个操作失败,整个事务将回滚并且不会对数据库产生任何影响。
-
一致性(Consistency):事务执行后,数据库应该保持一个一致性状态。一致性状态是由事务操作所指定的约束条件定义的,也就是说,事务所做的任何更改都必须遵守其定义的约束条件。
-
隔离性(Isolation):事务应该与其他并发执行的事务隔离开来,以确保事务间不会相互干扰。通过各种技术,如锁定机制和多版本并发控制(MVCC),可以实现高度的隔离性。
-
持久性(Durability):一旦事务提交,其更改就应该永久保存在数据库中,即使系统发生故障或电源被关闭也是如此。这通常通过将更改写入磁盘或其他非易失性存储介质来实现。
38、fiddler对手机进行抓包(接口测试)
①配置fiddler,允许监听到htttps(因为fiddler默认监http)
②配置fiddler允许远程连接
③准备手机端数据
查询ip,确保和手机再同一个局域网 ipconfig
fiddler监听端口为8888,所在fiddler的option中查看
手机端配置:
①手机和电脑在同一网络,打开浏览器,输入http://ip:8888,页面跳转点击fiddler certificate下载证书
②下载之后,给证书取名,其他不需要设置
③更改手机无线网的代理
手机系统设置→无线网→选中连接的wifi→修改网络→勾选高级代理→选择手动、主机名:电脑ip、服务器端口号:8888
恢复设置
①停止fiddler对手机的网络监控
手机系统设置→无线网→选中wifi→修改网络→勾选高级→代理选择无
②删除手机中的证书
手机系统设置→安全和隐私→更多安全设置→用户凭证→点击证书删除
39、分页怎么测试
分析测试点
一、翻页
有无数据时控件的显示情况
在首页时,首页和上一页是否能点击
在尾页时,下一页和尾页是否能点击
在非首页和非尾页时,四个按钮功能是否正确
翻页后,列表中的记录是否仍按照指定的排序列进行了排序
二、总页数、当前页数
总页数是否等于总的记录数/指定每页条数
当前页数是否正确
三、指定跳转页
是否能正常跳转到指定的页数
输入的跳转页数非法时的处理
四、指定每页显示条数
是否有默认的指定每页显示条数
指定每页的条数后,列表显示的记录数,页数是否正确
输入的每页条数非法时的处理
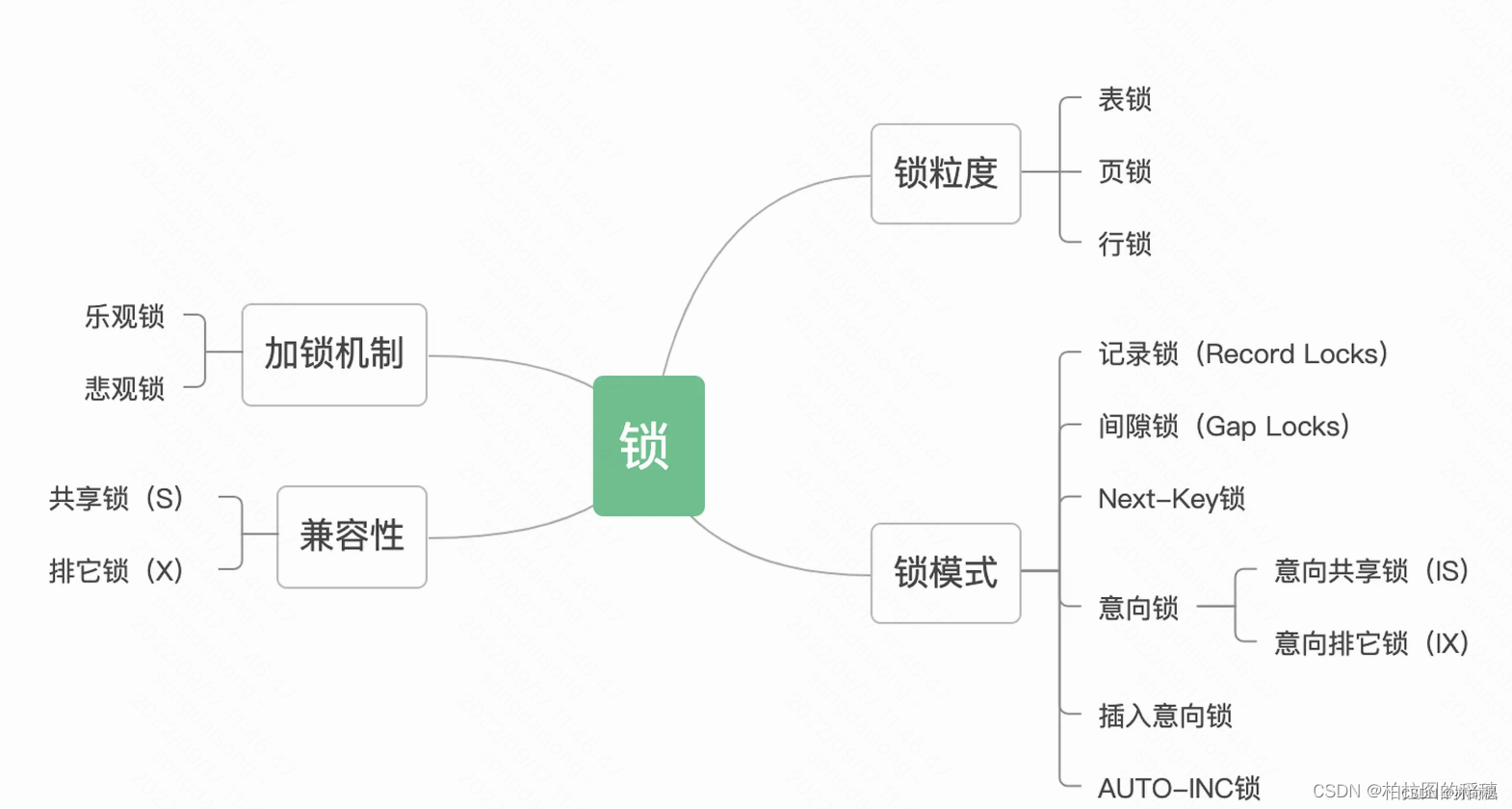
40、mysql锁的类型
41、游标的认识和作用
1.1 什么是游标?
- 游标Cursor是处理数据的一种方法,用来查看或者处理结果集中的数据,游标提供了在结果集中一次一行或者多行向前或向后浏览数据的能力;
- 游标相当于一个指针,它可以指定结果中的任何位置,允许用户对指定位置的数据进行处理;
- 游标可以被看作是一个临时文件,提供了在查询结果集中向前或向后浏览护具、处理结果集中数据的能力。
1.2 游标的作用是什么?
- 游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录进行处理的机制。
- 用户可以访问结果集中任意一行数据,在将游标放置到某行之后可以在该行或从该位置的行块上执行操作。
- 其实就是用于存放查询出来的多条记录的一个临时变量,我们可以从这个变量中取出我们需要的信息字段。
2.游标的优点和缺点
2.1 游标的优点
- sql的游标是一种临时的数据库对象,即可以用来存放在数据库表中的数据行副本,也可以指向存储在数据库中的数据行的指针。
- 游标提供了在逐行的基础上操作表中数据的方法;
- 游标的常见用途就是保存查询结果,以便之后的使用;
- 创建一次游标结果集而重复使用若干次,比重复查询数据库要快很多。
2.2 游标的缺点
- 当我们做的数据量大,而且系统上跑的不止我们一个业务时,尽量避免使用游标,游标使用时会对行加锁,可能会影响其他业务的正常进行;
- 当数据量大时其效率比较低效;
- 游标其实是相当于把磁盘整体放入了内存中,如果游标数据量大则会造成内存不足,所以在数据量小时才使用游标。
- 尽管游标能遍历结果中的所有行,但他一次只指向一行。
游标的使用步骤:
-
定义游标:declare cursor 游标名称 for select查询语句 [for {readonly|update}]
-
打开游标:open cursor
-
从游标中操作数据:fetch… … current of cursor
-
关闭游标:close cursor
游标的遍历:两种方式
1.loop…end loop;
2.使用for遍历
注意:
- 使用for循环遍历游标的好处:1.不用声明额外的变量,2.不用打开和关闭游标,3.写法简单。
- 使用游标时,一定要记得关闭游标;
- 在定义变量时需要注意定义的类型必须要和表中的字段类型一致,否则会出错
42、支付功能的测试点
一、梳理支付的业务流程如下**:**
点击支付—> 选择支付方式 —> 确认金额—> 输入密码 —> 成功支付
完成这个流程测试,也就是完成了项目的冒烟测试!然后需要测试针对流程中的每个阶段和步骤,具体分析可能导致异常的测试点,所以我们按阶段和输入项来进行划分如下:
1)点击支付,提交订单但是取消了,检查可以取消成功
2)选择支付方式:
正常:可以支持的支付方式有:信用卡,储蓄卡,网银支付,余额,第三方支付(微信,支付宝,京东、百度、聚合支付、组合支付),找人代付,验证是否支持并且可以正常选择并支付;
异常: 没有绑定任何的支付方式时,支付报错。
**功能交互:**支付时结合优惠券/折扣券/促销价抵扣进行相关的抵扣,验证规则正确,并且可以正常抵扣和支付。
3)确认支付金额:这个步骤可以用到等价类和边界值的用例设计方法
正常:正常金额里用边界值法去测试点:
最大支付金额(单日最大,单笔最大,余额最大)
最小支付金额
异常:同样也用边界值方法提取测试点:
超过支付方式单日最大消费金额/单笔最大/余额最大
异常金额支付:非数字、负数、0,小数点超过 2 位等
4)支付密码:
正常:可以支持的支付密码类型有:指纹,人脸识别,账号密码,动态获取验证码,手势,信用卡和支付码,小额免密等,确认自己的产品所支持的密码类型,确认可以验证并支付成功;
异常:输入错误的密码,检查有无提示信息且正确;超过密码错误上限,检查是否冻结等。
5)其他场景测试点:
a、多笔订单合并支付,是否可以成功;
b、重复点击支付按钮,是否会出现多次购买,并同步检查数据库的数据帐账目正确;
c、支付中断:
主动中断:可以继续支付并成功
被动中断:比如电话、低电量、闹钟,断网、切换后台、耳机插拔等,验证可以继续支付;
d、网络测试:
验证各种网络类型:2G、3G, 4G,5G,wifi 下都可以正常支付;
进行网络切换,支付功能正常;
弱网测试下支付功能正常:不会重复支付多次,APP 不会闪退 崩溃,而且页面提示友好;
e、使用 fiddler 等抓包篡改价格:不允许抓包或者数据加密,篡改不成功
二、退款流程
**正常:**验证正常的退款流程,也就是退款的冒烟测试:
1、点击退款可以退款成功,并且检查交易状态是退款,退款金额可以到账;
2、结合优惠券等抵扣,可以退款实际支付金额;
3、同步检查数据库的数据和账目是正确的;
异常:提交错误退款(退款订单号不对),或者退款金额错误,都能够退款失败(此处一般会借助工具进行测试,比如进行接口测试);
三、测试方法
那么以上的测试点在具体公司项目中要怎么进行测试呢?我们有不同的一些测试方法:
1) 小额支付:
需要让开发修改代码,不管支付多少钱,实际支付都是 1 分钱;不顾这种方法只能测试小额支付,就有可能会出现产品小额支付没问题,但是大额支付就错误的漏测情况;
2)申请测试金额:
这种方式一般会作为小额支付的一种补充,比如测试完小额支付后,再测试一些大额支付,这就需要跟公司申请测试基金,走报销流程;
3)沙箱支付:
沙箱支付是一种虚拟的支付,不是真实的金额;这种方法可以验证小额和大额的支付流程;不过目前只有支付宝沙箱比较成熟可用,其他的支付方法不可用。
四、非功能测试点
测试完以上的功能测试点之后,我们还需要验证一些非功能测试点,主要包括以下几个方面:
1)界面
验证界面的美观,排版和错别字等。
2)兼容性
**BS:**如果是 BS 架构的产品,需要测试跟浏览器的兼容性;所以就需要根据浏览器的内核,选择一些主流的浏览器进行测试;
CS:如果 CS 架构的产品,测试手机移动端的兼容,比如手机型号,系统版本和屏幕大小及分辨率等。
3)易用性
测试站在用户的角度考虑用户体验,使用是否方便等。
4)性能
比如考虑多用户支付,长时间运行等,关注产品的响应时间等,一般需要借助工具或者代码进行测试。
5)安全
验证敏感信息是否加密,是否可以篡改;通过一些工具进行安全扫描,检查是否有安全漏洞;或者采用一些其他的手段进行专门的安全测试。
43、JMeter常用的几种断言方法
-
响应断言
-
JSON Assertion
-
Size Assertion
-
JSR223 Assertion
-
XPath Assertion
-
Compare Assertion
-
断言持续时间
-
HTML Assertion
-
MD5Hex断言
-
SMIME Assertion
-
XML断言
-
XML Schema Assertion
-
BeanShell断言
44、tcp和udp的区别
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
45、接口自动化的优缺点
1、自动化测试的优点
(1)对程序的回归测试更方便。 由于回归测试的动作和用例是完全设计好的,测试期望的结果也是完全可以预料的,将回归测试自动运行,可以极大提高测试效率,缩短回归测试时间。
(2)可以运行更加繁琐的测试 自动化测试的一个明显好处就是可以在很短的时间内运行更多的测试。
(3)可以执行一些手工测试困难或者不可执行的测试,例如模拟大量用户场景的压力测试
(4)更好的利用资源 将繁琐的任务自动化,可以提高准确性和测试人员的积极性,将测试技术人员解脱出来投入更多精力设计更好的测试用例。有些测试不适合于自动测试,仅适合于手工测试,将可自动测试的测试自动化后,可以让测试人员专注于手工测试部分,提高手工测试的效率。
(5)测试具有一致性和可重复性。由于测试是自动执行的,每次测试的结果和执行的内容的一致性是可以得到保障的,从而达到测试的可重复的效果。
(6)测试的复用性 由于自动测试通常采用脚本技术,这样就有可能只需要做少量的甚至不做修改,实现在不同的测试过程中使用相同的用例。
(7)增加软件的信任度 由于测试是自动执行的,所以不存在执行过程中的疏忽和错误,完全取决于测试的设计质量,一旦软件测试通过强有力的自动测试后,软件的信任度自然增加。
2、自动化测试的缺点
(1)自动化测试不能取代手工测试
(2)手工测试比自动化测试发现的缺陷更多
(3)对测试质量的依赖性极大
(4)测试自动化不能提高有效性
(5)测试自动化可能制约软件开发,自动化测试比手工测试更脆弱,所以维护会受到限制,从而制约软件的开发
(6)各种工具良莠不齐
46、常见的性能问题归类
一、响应时间慢:
1、连接数不足导致连接排队,线程池连接数不走,jdbc连接数,DB连接数不足;
2、慢sql; (联合索引效率比单字段的索引效果好)
3、外部接口调用慢; - 是否能使用redis
4、GC停顿时间长:(代码不合理、jvm配置不合理:教大的对象,或对象在年轻代中满进入老年代,进行full GC 频繁
5、锁竞争
6、IO消耗高 – 一般为磁盘性能较差,打印大量日志
二、CPU消耗高:
1、死循环;
2、info日志打印代码行号,jvm触发爬栈,爬栈对cpu消耗较高;
3、序列化与反序列化;
4、大量的正则匹配;
5、业务查询数据使用同步锁
三、内存:
1、内存泄漏 jvm OutofMemory
2、从db中单次读取较大的数据
四、线程
1、线程泄漏:new线程时,要规定线程的大小,默认较大。推荐使用线程池管理线程;
2、线程上下切换频繁;
五、磁盘IO高
1、日志输出频繁,日志数据量较大
47、提交bug的模板
48、没有接口测试文档怎么测试
1、与开发人员沟通,以便明确测试的重点和要测试的功能点。
2、使用浏览器开发者工具或抓包工具,捕获网络请求和响应信息,了解应用程序中的请求类型、参数和响应数据。
3、如果能看到程序源码,可以尝试查找API相关的代码段。一些框架和库可能会有内置的路由器和控制器,可以帮助你了解API的端点和参数。
4、查看程序日志,采集接口请求与响应相关的日志信息。
5、使用第三方工具,或者编写脚本对相关接口编写测试用例并执行测试。
49、自动化测试之八大元素定位方式
1、id定位元素
id是当前整个HTML页面中唯一的,所以可以通过id属性来唯一定位一个元素,是首选的元素定位方式。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过id定位元素的方式
# .send_keys()发送关键词
driver.find_element(By.ID, "kw").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
2、name元素定位
根据元素的name来定位属性,但name并不是唯一的。
name方式:1、元素中必须要有name的属性 2、name的属性在页面中如果是唯一的,那么可以准确的定位到元素(不是唯一的,默认返回的是第一个元素)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过name定位元素的方式
# name方式:1、元素中必须要有name的属性 2、name的属性在页面中如果是唯一的,那么可以准确的定位到元素(不是唯一的,默认返回的是第一个元素)
driver.find_element(By.NAME, "wd").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
3、class_name元素定位
根据Class定位属性,主要是用来元素进行分组,并对这一级元素设置相同的样式。所以class属性在当前html页面当中,也是不能唯一定位到一个元素的。
class_name定位元素:1、在元素中需要有class的属性;2、class的属性值不是唯一的,那么不能唯一的定位到指定的元素。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过class定位元素的方式
# class_name定位元素:1、在元素中需要有class的属性;2、class的属性值不是唯一的,那么不能唯一的定位到指定的元素
driver.find_element(By.CLASS_NAME, "s_ipt").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
4、tag_name元素定位
tag_name是通过标签名称来定位的,如标签。
tag_name定位元素:标签名是会重复,默认返回的是第一个符合的元素。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.taobao.com/")
# 定位到百度搜索框通过tag_name定位元素的方式
# tag_name定位元素:1、标签名是会重复,默认返回的是第一个符合的元素
driver.find_element(By.TAG_NAME, "input").send_keys("三体")
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
5、link_text元素定位
link_text 只能使用精准的匹配(a标签的全部文本内容)。
link_text定位:必须根据链接上完整的文本内容去进行定位。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过link_text定位元素的方式
# link_text定位元素:1、必须根据链接上完整的文本内容去进行定位。
driver.find_element(By.LINK_TEXT, "新闻").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
6、partial_link_text元素定位
partial_link_text可以使用精准或模糊匹配,如果使用模糊匹配最好能使用可以唯一的关键字;如果有多个值,默认返回第一个值。
partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个值。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度输入框,搜索热点新闻
driver.find_element(By.ID, "kw").send_keys("热点新闻")
# 定位到百度一下按钮,并且点击
driver.find_element(By.ID, "su").click()
# 停留3秒,加载页面
sleep(3)
# 从返回的结果页面,通过模糊匹配定位到包含了“腾讯网”的超连接
# partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个
# .click()点击的操作
driver.find_element(By.PARTIAL_LINK_TEXT, "腾讯网").click()
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
7、xpath元素定位
1、使用xpath目的
在前面写的定位方式不能实现的时候使用。
id、name、class_name定位前提是要有这个属性,否则不能定位。
tag_name方式如果有很多相同的标签名,定位不方便。
link的定位方式只是针对超链接的。
2、xpath语法
xpath语法 表达式 说明 /aaa 选取根节点为aaa的元素 /aaa/bbb 选取aaa标签下的bbb标签 //aaa 选取所有aaa的标签元素 //aaa/bbb 选取所有父元素为aaa的bbb元素 . 选取当前节点 … 选取当前节点的父节点
xpath定位方式一(绝对路径)
语法:以单斜杠开头逐级开始编写,不能跳级。如:(“html/body/div/div/form/input”)。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到姓名输入框
# xpath定位方式一:绝对路径
driver.find_element(By.XPATH, "html/body/div/form/fieldset/table/tbody/tr/td/input").send_keys("admin")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
xpath定位方式二(相对路径)
相对路径是只给出元素路径的部分信息,在 html 的任意层次中寻找符合条件的元素。(元素名不知道,可用*)语法:以双斜杠开头,双斜杠后边跟元素名称。如://input。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到多行文本输入框(简介)
# xpath定位方式二:相对路径
driver.find_element(By.XPATH, "//textarea").send_keys("这是一个简介。")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
xpath定位方式三(路径结合属性)
语法://input[@id=‘id值’]。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到密码输入框
# xpath定位方式三:路径结合属性的形式(定位到密码输入框)
driver.find_element(By.XPATH, "//input[@id='Password1']").send_keys("123456789")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
xpath定位方式四(文本内容匹配)
语法://a[text()=“新闻”],标签为a文本信息为"新闻"。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get("https://www.hao123.com/")
# 延时3秒
sleep(3)
# xpath定位方式四:文本内容匹配(定位到hao123当中的京东链接)
driver.find_element(By.XPATH, "//a[text()='京东']").click()
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
xpath定位方式五(部分文本信息包含匹配)
语法://a[contains(text(),“新”)] 或者 //a[contains(text(),“闻”)]
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get("https://www.hao123.com/")
# 延时3秒
sleep(3)
# xpath定位方式五:部分文本内容进行匹配(定位到hao123当中的哔哩哔哩链接)
driver.find_element(By.XPATH, "//a[contains(text(), '哔哩')]").click()
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
xpath定位方式六(路径结合逻辑)
语法://标签名[@属性名=‘属性值’ and @属性名=‘属性值’]
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式六:通过多个属性定位到姓名2输入框
driver.find_element(By.XPATH, "//input[@name='Name' and @id='t2']").send_keys("第二个姓名")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
xpath定位方式七(通过父级定位子级元素)
语法://标签名(或*)[@父级属性名=‘父级属性值’]/input。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式七:通过父级定位子级元素
driver.find_element(By.XPATH, "//td[@id='id1']/input").send_keys("通过父级定位到子级")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
xpath定位方式八(直接复制法)
通过手动定位到的标签,点击右击复制xpath元素,直接复制到代码里。如下所示。
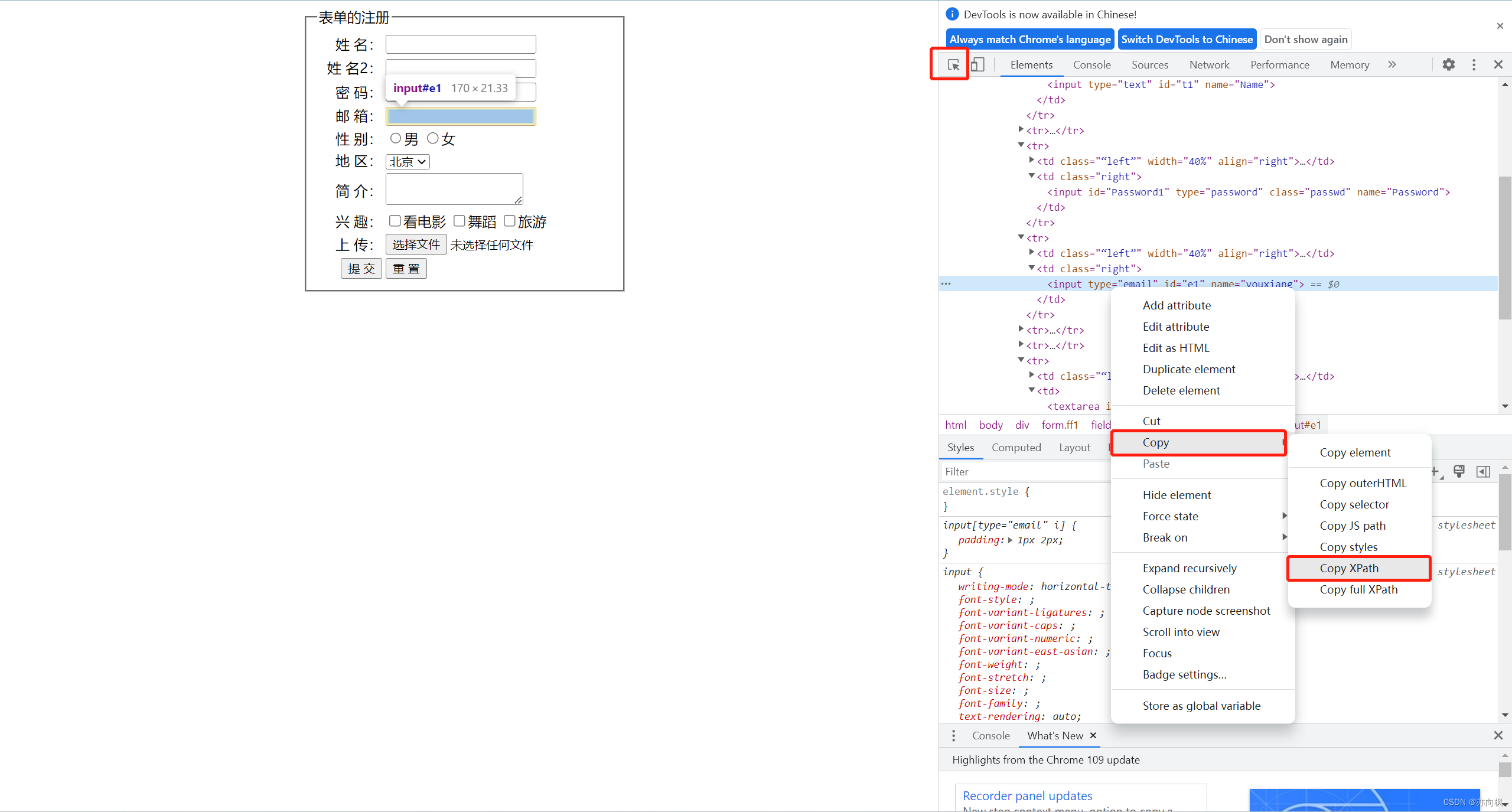
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式七:通过父级定位子级元素
driver.find_element(By.XPATH, "//*[@id='e1']").send_keys("直接复制定位到邮箱")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
8、CSS选择器定位















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









