






 本文介绍了如何使用Linux Shell脚本进行系统管理,包括批量ping检查、用户创建、内存计算、文件操作、SSH配置、系统菜单、远程主机管理等。此外,还涉及到了交互式EXPECT脚本、并发处理、错误处理和系统信息收集。内容涵盖了网络、系统性能、进程监控等多个方面,是自动化运维的实用教程。
本文介绍了如何使用Linux Shell脚本进行系统管理,包括批量ping检查、用户创建、内存计算、文件操作、SSH配置、系统菜单、远程主机管理等。此外,还涉及到了交互式EXPECT脚本、并发处理、错误处理和系统信息收集。内容涵盖了网络、系统性能、进程监控等多个方面,是自动化运维的实用教程。
文章目录
- 目录
- ping文件中的ip地址
- while和let的使用
- 根据输入的用户来判断是否创建用户
- 计算内存的使用情况
- 根据输入的数字来创建文件或用户
- 用while来实现错误输入后重新输入
- 将内容写入文件
- case 的使用
- 删除指定用户
- 系统管理菜单
- jumpserver.sh
- 用for语句ping
- 批量创建用户
- 根据文件内容批量创建用户
- 远程批量修改密码
- 批量远程主机ssh配置
- while语句创建用户
- while 和 until
- 多进程,mkfifo
- expect交互式
- EXPECT 实现批量主机公钥推送
- 将文件中的数据导入数组
- 统计性别
- 统计解释器
- 计算阶乘
- 错误的函数返回值
- 数组传参
- 数组内部变量的使用
- break 的使用
- 打印九九乘法表
- shift的用法
- vim
- select 菜单
- 实战项目 收集系统信息
- 判断主机存活
- 判断主机存活 (函数)
- nginx 日志分析
- 定期删除目录下修改时间大于7天的文件
- mysql 多机部署
- 服务器系统配置初始化
目录
ping文件中的ip地址
[root@wzb practice]# cat ip_1.txt
www.baidu.com
www.360.cn
www.4399.cn
[root@wzb shell]# cat ping_iptxt.sh
#!/bin/bash
if [ -f $1 ];then
for ip in `cat $1`
do
ping -c1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo "$ip is up"
else
echo "$ip is down"
fi
done
elif [ ! -f $1 ];then
echo "not file"
exit 1
fi
while和let的使用
[root@wzb shell]# cat ping_while_let.sh
#!/bin/bash
ip=www.baidu.com
i=1
while [ $i -lt 4 ]
do
ping -c1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo "$ip up"
fi
let i++
done
根据输入的用户来判断是否创建用户
判断用户是否存在用 id 命令,根据返回值就可以判断
若是利用passwd来判断,会有比较麻烦的问题
[root@wzb shell]# cat useradd_01.sh
#!/bin/bash
#输入用户名,若该用户不存在就创建
read -p "输入一个用户名:" name
id $name &> /dev/null
if [ $? -eq 0 ];then
echo "The user already exists"
else
echo "用户${name}不存在,是否要创建该用户 N/Y?"
read -p "input y or n:" letter
if [ ${letter} == y ];then
echo "creating usear..."
elif [ ${letter} == n ];then
echo "dont create user , exit..."
exit
fi
fi
计算内存的使用情况
[root@wzb shell]# cat count_mem.sh
#!/bin/bash
mem_used=`free -m | awk 'NR==2{print $3}'`
mem_total=`free -m | awk 'NR==2{print $2}'`
#echo $mem_used
#echo $mem_total
let occupy=$mem_used*100/$mem_total
echo $occupy
内存使用过多,发送邮件

根据输入的数字来创建文件或用户
一开始用 {num…num}
发现行不通
[root@wzb shell]# cat useradd_02.sh
#!/bin/bash
read -p "input a number: " num
read -p "input prefix: " pre
for i in {1..${num}}
do
echo $i
done
这里用创建文件夹来代替创建用户
这里使用了 seq来遍历数字
[root@wzb shell]# cat useradd_02.sh
#!/bin/bash
read -p "input a number: " num
read -p "input prefix: " pre
for i in `seq $num`
do
echo $i
mkdir /home/wzb/tongzi/$pre$i
done
用来整体设置密码
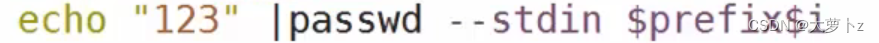
若输入的不是数字,来提示的几种方法
[root@wzb shell]# cat useradd_03.sh
#!/bin/bash
read -p "input a number: " num
read -p "input prefix: " pre
if [ -n "`echo $num | sed 's/[1-9]//g'`" ];then
echo "You entered characters other than numbers"
exit 1
fi
for i in `seq $num`
do
echo $i
mkdir /home/wzb/tongzi/$pre$i
done
[root@wzb shell]# cat useradd_04.sh
#!/bin/bash
read -p "input a number: " num
read -p "input prefix: " pre
if [ "${name} != ^[0-9]+$" ];then
echo "no"
exit 1
fi
for i in `seq $num`
do
echo $i
mkdir /home/wzb/tongzi/$pre$i
done
输入错误再次输入,用了递归,函数引用自己
其中 双中括号 支持正则[[]]
[root@wzb shell]# cat useradd_04.sh
#!/bin/bash
#read -p "input a number: " num
read -p "input prefix: " pre
re-en(){
read -p "please re-enter:" num
if [[ ! ${num} =~ ^[0-9]+$ ]];then
#if [ $? -eq 1 ];then
echo "no"
re-en
fi
}
re-en
for i in `seq $num`
do
echo $i
mkdir /home/wzb/tongzi/$pre$i
done
修改
添加了若输入是0的情况
有点不懂 ! 是全都管还是就管前面一句
[root@wzb shell]# cat useradd_04.sh
#!/bin/bash
#read -p "input a number: " num
read -p "input prefix: " pre
re-en(){
read -p "please re-enter:" num
if [[ ! ${num} =~ ^[0-9]+$ || ${num} =~ ^0*$ ]];then
#if [ $? -eq 1 ];then
echo "no"
re-en
fi
}
re-en
for i in `seq $num`
do
echo $i
mkdir /home/wzb/tongzi/$pre$i
done
试了之后发现 !是全管的
再次修改
[root@wzb shell]# cat useradd_04.sh
#!/bin/bash
#read -p "input a number: " num
read -p "input prefix: " pre
re-en(){
read -p "please re-enter:" num
if [[ ! ${num} =~ ^[1-9][1-9]+$ ]];then
#if [ $? -eq 1 ];then
echo "no"
re-en
fi
}
re-en
for i in `seq $num`
do
echo $i
mkdir /home/wzb/tongzi/$pre$i
done
完整版,包含了前缀和数量的错误输入,也修正了之前的错误
基本功能已实现
[root@wzb shell]# cat useradd_04.sh
#!/bin/bash
#read -p "input a number: " num
#read -p "input prefix: " pre
re-pre(){
read -p "input a prefix:" pre
if [ -z ${pre} ];then #判断是否为空,若空则返回真,与-n相反
echo "the prefix is empty!"
re-pre
fi
}
re-num(){
read -p "please input a num:" num
if [[ ${num} =~ ^[1-9][0-9]+$ || -n ${num} || ${num} =~ [1-9] ]];then
sleep 0.01s##有点问题的
else
echo "wrong input,please re-enter a num!"
re-num
fi
}
re-num
re-pre
for i in `seq $num`
do
echo "touching $pre$i ..."
mkdir /home/wzb/tongzi/$pre$i
done
用while来实现错误输入后重新输入
这是在if语句外套了一个while
因为if用不了break
[root@wzb shell]# cat re-enter
#!/bin/bash
read -p "input :" num
while true
do
if [[ "${num}" =~ ^[0-9]+$ ]];then
echo "shi"
break
else
echo "error"
read -p "reinput:" num
fi
done

将内容写入文件
文件不存在就会自动创建
[root@wzb tom]# cat t1.sh
#!/bin/bash
cat >/home/tom/r1.txt <<-EOF
123
123
info=123
EOF
case 的使用
case似乎不能用来“比较大小”
[root@wzb shell]# cat case.sh
#!/bin/bash
read -p "input a num:" num
case "$num" in
1)
echo "1"
;;
2)
echo "2"
;;
*)
echo "ever"
esac
删除指定用户
[root@wzb shell]# cat user_del.sh
#!/bin/bash
read -p "input a username: " uname
id ${uname} &>/dev/null
if [ $? -ne 0 ];then
echo "the user dont exists"
exit 1
fi
read -p "Are you sure?[y/n]: " action
if [ ${action} == y ];then
userdel -r ${uname}
echo "${uname} is deleted"
elif [ ${action} == "n" ];then
echo "ok cancle..."
else
echo "please input y or n"
exit 1
fi
若用户输入y/Y/yes/yes
可以看出非常冗杂,很不直观
[root@wzb shell]# cat user_del.sh
#!/bin/bash
read -p "input a username: " uname
id ${uname} &>/dev/null
if [ $? -ne 0 ];then
echo "the user dont exists"
exit 1
fi
read -p "Are you sure?[y/n]: " action
if [ ${action} == "y" -o ${action} == "yes" -o ${action} == "Y" -o ${action} == "YES" ];then
userdel -r ${uname}
echo "${uname} is deleted"
elif [ ${action} == "n" ];then
echo "ok cancle..."
else
echo "please input y or n"
exit 1
fi
使用case改进,更直观
[root@wzb shell]# cat user_del.sh
#!/bin/bash
read -p "input a username: " uname
id ${uname} &>/dev/null
if [ $? -ne 0 ];then
echo "the user dont exists"
exit 1
fi
read -p "Are you sure?[y/n]: " action
case "${action}" in
y|Y|yes|YES) #变得很直观!
userdel -r ${uname}
echo "${uname} is deleted!"
;;
n)
echo "fine,cancel..."
exit 0
;;
esac
系统管理菜单
用case来实现
[root@wzb shell]# cat system_manage01.sh
#!/bin/bash
menu(){
cat <<-EOF
#################################
# h. help
# f. disk partition
# d. filesystem mount
# u. system load
# q exit
#################################
EOF
}
menu
while true
do
read -p "please input a num to chose what you want to do:" num
case ${num} in
h)
help;menu;;
f)
fdisk -l;;
d)
df -Th;menu;;
m)
free -m;menu;;
u)
uptime;;
q)
break;;
"") #这段语句要在 *)的前面,否则若输入空值,也会输出"error"
;;
*)
echo "error";;
esac
done
echo "finish..."
jumpserver.sh
实现跳板机的作用
用 ssh 登陆 alice 用户,自动执行相应命令
在本地shell登陆到跳板机的alice用户
ssh alice@192.168.92.5
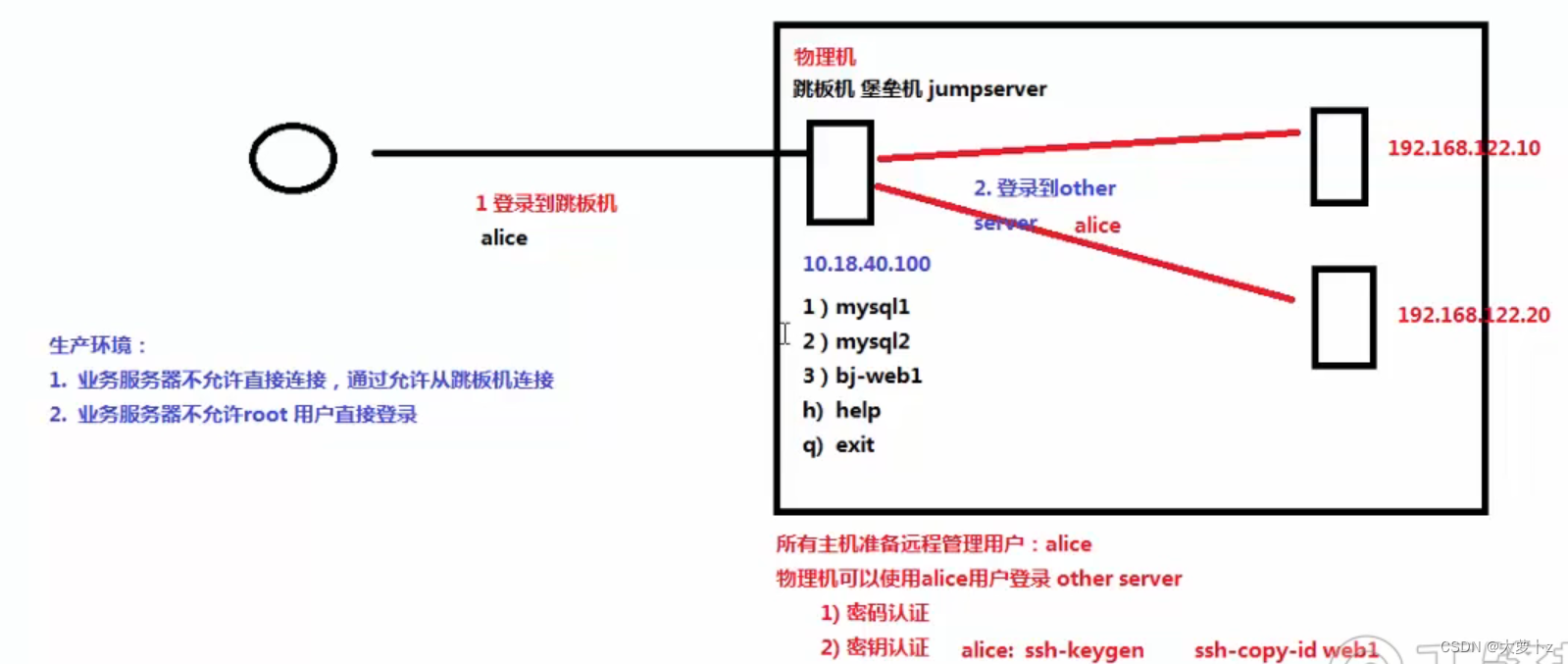
[root@wzb alice]# cat jumpserver.sh
#!/bin/bash
trap "" HUP INT OUIT TSTP #信号,可以阻止用户通过 ctrl + c 退出脚本
server1=192.168.92.16
server2=192.168.92.132
clear
while :
do
cat <<-EOF
1. server1
2. server2
3. lo
EOF
read -p "input a num:" num
case ${num} in
1)
ssh alice@${server1};;
2)
ssh alice@${server2};;
"")
;;
*)
echo "error"
esac
done
用for语句ping
[root@wzb shell]# cat ping_for.sh
#!/bin/bash
for i in {125..130}
do
ip=${i}.0.0.1
ping -c1 -W1 $ip &>/dev/null #W1似乎是延时1秒,若1秒钟ping不通则不pingl
if [ $? -eq 0 ];then
echo "${ip}" | tee -a ip1.txt #将结果写入,与重定向比较了一下,发现这个可以在终端显示结果,重定向不显示,直接写入
fi
done
改进
修改了之后脚本跑的很快
[root@wzb shell]# cat ping_for.sh
#!/bin/bash
>ip1.txt #将文件清空,重定向
for i in {1..130}
do
{
ip=${i}.0.0.1
ping -c1 -W1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo "${ip}" | tee -a ip1.txt
fi
}& #使代码在后台运行
done
wait #等待在这之前的在后台运行的代码运行完毕
echo "finish"
批量创建用户
这里不用cat是因为cat似乎无法读取变量,就用了printf
其中 判断 $action是一个比较简便的判断用户输入
输入y就打断while循环,执行后面的代码,n则为重新执行while
与之前的差不多,没有实现用户错误输入的情况
[root@localhost shell]# cat user_create.sh
#!/bin/bash
while :
do
read -p "enter prefix & pass & num : " prefix pass num
printf "user infomation:
----------------
prefix:${prefix}
password:${pass}
number:${num}
----------------
"
read -p "Are you sure?[y/n]" action
if [ ${action} == "y" ];then
break
fi
done
echo "ok"
for i in `seq ${num}`
do
uname=${prefix}${i}
useradd ${uname}
echo "${pass}" | passwd --stdin ${uname} &>/dev/null
if [ $? -eq 0 ];then
echo "${uname} is created..."
fi
done
根据文件内容批量创建用户
[root@wzb shell]# cat username.txt
zhang1
zhang2
wang1
wang2
liu1
liu2
liu3
wu1
wu001
文件中只有用户名
[root@wzb shell]# cat useradd_07.sh
#!/bin/bash
password=123456
if [ $# -eq 0 ];then
echo "$0"
exit 1
fi
if [ ! -f $1 ];then
echo "not file"
fi
for i in `cat $1`
do
#echo "${i}"
useradd ${i}
if [ $? -eq 0 ];then
echo ${password} | passwd --stdin ${i} &>/dev/null
fi
if [ $? -eq 0 ];then
echo "done"
fi
done
用户密码文件
zhang1 123445
zhang2 12311
wang1 zzsc
wang2 awdasd
liu1 awdsa
liu2 adzxc
liu3 12awsd
wu1 awdawd
wu001 asd123
文件中存在用户名和密码
for语句默认以空格为分隔符,所以使用IFS将分隔符改为回车
for语句会省略空行
试了之后发现是临时改变分隔符
[root@localhost shell]# cat useradd_08.sh
#!/bin/bash
IFS='
'
if [ $# -eq 0 ];then
echo "$0"
exit 1
fi
if [ ! -f $1 ];then
echo "not file"
exit 2
fi
for line in `cat $1`
do
name=`echo "${line}" | awk '{print $1}'`
pass1=`echo "${line}" | awk '{print $2}'`
useradd ${name}
if [ $? -eq 0 ];then
echo ${pass1} | passwd --stdin ${name} &>/dev/null
fi
if [ $? -eq 0 ];then
echo "done"
fi
done
远程批量修改密码
ssh这一行,不懂,这里必须要加引号,加分号会登陆相应主机,不加会修改当前主机的密码
第一个参数为文件,第二个为密码
[root@wzb shell]# cat pass_modify.sh
#!/bin/bash
>success.txt
for i in `cat $1`
do
{
ping -c1 -W1 ${i} &>/dev/null
if [ $? -eq 0 ];then
#echo ${i}
ssh ${i} "echo $2 | passwd --stdin final"
if [ $? -eq 0 ];then
echo ${i} >> ./success.txt
else
echo ${i} >> ./fail.txt
fi
else
echo "cant ping"
fi
}&
wait
done
获取ip

批量远程主机ssh配置
[root@wzb shell]# cat system_config01.sh
#!/bin/bash
for i in `cat $1`
do
{
ping -c1 -W1 $i &>/dev/null
if [ $? -eq 0 ];then
ssh $i "sed -r 's/^#(UseDNS).*$/\1 no/g' /etc/ssh/sshd_config -i"
ssh $i "sed -r 's/^(GSSAP.*tion).*/\1 no/g' /etc/ssh/sshd_config -i"
ssh $i "sed -r 's/^(SELINUX)=.*$/\1=disabled/g' /etc/selinux/config -i"
ssh $i "setenforce 0"
ssh $i "cd /home/wzb/;mkdir 123qq"
echo "done"
else
echo "cant ping "
fi
}&
wait
done
while语句创建用户
while 通过回车来进行分割,所以不用指定分隔符,可用于逐行处理
while不同于for,可以识别到空行
用输入重定向的方式
[root@wzb shell]# cat while_useradd02.sh
#!/bin/bash
while read line
do
if [ ${#line} -eq 0 ];then
continue
fi
user=`echo ${line} | awk '{print $1}'`
pass=`echo ${line} | awk '{print $2}'`
echo ${user}
echo ${pass}
done < username.txt
while 和 until
while 一直ping,ping不通则结束循环
结果为真就循环
while ping -c1 -W1 192.168.92.132 &>/dev/null
do
sleep 1
done
echo "ip is down"
until 一直ping,ping通了则结束循环
结果为假就循环
until ping -c1 -W1 192.168.92.132 &>/dev/null
do
sleep 1
done
echo "ip is up"
多进程,mkfifo
若 thread 的值为5,那么就会每5个输出一次
[root@wzb shell]# cat ping_multi.sh
#!/bin/bash
thread=4 #设置并发数量
tmp_fifofile=/tmp/$$.fifo ##以当前进程id作为文件名,不会重复
mkfifo $tmp_fifofile #建立一个管道文件
exec 8<> $tmp_fifofile #打开管道文件
rm $tmp_fifofile #删除,即使删除了,管道文件的内容依然存在
for i in `seq ${thread}` #令管道文件的内容为 ${thread} 行空格,其他值也可以,有内容就行
do
echo >&8
done
for i in {1..100}
do
read -u 8 #读取管道文件,读一次就少一行 -u 指定输入
{
ping -c1 -W1 ${i}.0.0.1 &> /dev/null
ip=${i}.0.0.1
if [ $? -eq 0 ];then
echo $ip > /home/tom/123.txt
echo "${ip} is ip"
else
echo "${ip} is down"
fi
echo >&8 #执行一次,就执行一次输出重定向,是管道文件依旧保持之前的行数
}&
done
wait
exec 8>&- #删除管道文件
echo "finish"
expect交互式
安装expectyum -y install expect
解释器换成#!/bin/expect
[root@wzb shell]# cat expect_ssh.sh
#!/bin/expect
spawn ssh root@192.168.92.132
expect {
"yes/no" { send "yes\r" ; exp_continue }
"passwd:" { send "123456\r" }
}
interact
expect变量的使用
引用变量的方式与bash不同,第一个变量的索引为0
[root@wzb shell]# cat expect_ssh02.sh
#!/bin/expect
set ip [lindex $argv 0] #没有空格
set user [lindex $argv 1]
set passwd 123456
set timeout 5
spawn ssh $user@$ip
expect {
"yes/no" { send ""yes\r ; exp_continue }
"passwd:" { send "$passwd\r" };
}
interact #进入交互式,结束由我来决定
[root@wzb shell]# cat expect_ssh02.sh
#!/bin/expect
#set ip [lindex $argv 0]
#set user [lindex $argv 1]
set ip 192.168.92.132
set uset root
set passwd 123456
set timeout 5
spawn ssh $user@$ip
expect {
"yes/no" { send ""yes\r ; exp_continue }
"passwd:" { send "$passwd\r" };
}
#interact
expect "#" #当要在同一种情况下要输入多个命令时可以用这样的形式,
send "useradd zhangsan\r"
send "pwd\r"
send "exit\r"
expect eof #结束
这样似乎只能执行第一条命令

EXPECT 实现批量主机公钥推送
[root@wzb shell]# cat get_ip.sh
#!/bin/bash
rpm -q expect &>/dev/null #装expect
if [ $? -ne 0 ];then
yum -y install expect
fi
if [ -f ~/.ssh/id_rsa ];then: #是否有公钥
else
ssh-keygen -P "" -f ~/.ssh/id_rsa
fi
>ip.txt
password=123456
for i in {100..200}
do
{
ip=192.168.92.$i
ping -c1 -W1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo $ip >> ./ip.txt
/usr/bin/expect <<-EOF
set timeout 60
spawn ssh-copy-id -f $ip
expect {
"yes/no" { send "yes\r" ; exp_continue }
"password:" { send "$password\r" };
}
expect eof
EOF
else
echo "$ip is done"
fi
}&
done
wait
echo "ok"
提取文件内容来推送密钥
[root@wzb shell]# cat get_ip02.sh
#!/bin/bash
while read line
do
user=`echo $line | awk '{print $1}'`
pass=`echo $line | awk '{print $2}'`
#echo "$user"
#echo "$pass"
ping -c1 -W1 $user &>/dev/null
if [ $? -eq 0 ];then
/bin/expect <<-EOF
set timeout 60
spawn ssh-copy-id -f $user
expect {
"yes/no" { send "yes\r" exp_continue }
"password:" { send "$pass\r" };
}
expect eof
EOF
else
echo "$user is down"
fi
done < ip001.txt
将文件中的数据导入数组
while
[root@wzb shell]# cat list01.sh
#!/bin/bash
i=0
while read line
do
hosts[i]=${line}
let i++
done <./ip01.txt
for i in ${!hosts[@]}
do
echo "$i:${hosts[i]}"
done
for
将分隔符改为回车
若后续要再使用,IFS=$OLD_IFS可变回原来的样子
[root@wzb shell]# cat list02.sh
#!/bin/bash
IFS=$'\n'
OLD_IFS=$IFS
j=0
for line in `cat ./ip01.txt`
do
hosts01[j]=${line}
let j++
done
for i in ${!hosts01[@]}
do
echo "$i:${hosts01[i]}"
done
IFS=$OLD_IFS
统计性别
数据文件
[root@wzb shell]# cat sex.txt
jack m
alice f
tom m
rese f
rebin m
zhuzhu f
zhang x
原理是let sex[$type]++将性别作为索引,然后识别到相应的索引就+1
也可以直接用awk '{print $2}' set.txt| sort | uniq -c'
[root@wzb shell]# cat count_sex.sh
#!/bin/bash
declare -A sex
while read line
do
type1=`echo ${line} | awk '{print $2}'`
let sex[$type1]++
done < ./sex.txt
for i in ${!sex[@]}
do
echo "${i}: ${sex[$i]}" #关联数组,这里要加 $
done
统计解释器
[root@wzb shell]# cat count_shells.sh
#!/bin/bash
declare -A shells
while read line
do
type1=`echo ${line} | awk -F ":" '{print $7}'`
let shells[$type1]++
done < /etc/passwd
for i in ${!shells[@]}
do
echo "${i} : ${shells[$i]}"
done
用awk实现
[root@wzb shell]# awk -F ":" {'print $7'} /etc/passwd | sort | uniq -c
6 /bin/bash
1 /bin/sync
1 /sbin/halt
45 /sbin/nologin
1 /sbin/shutdown
统计端口运行状态
[root@wzb shell]# cat count_ss.sh
#!/bin/bash
unset status01
declare -A status01
type1=`ss -an | awk '{print $2}'`
for i in ${type1}
do
let status01[$i]++
done
for j in ${!status01[@]}
do
echo "${j} : ${status01[$j]}"
done
实时运行
watch -n1 ./count_ss.sh
计算阶乘
[root@wzb shell]# cat jiecheng.sh
#!/bin/bash
jc(){
re=1
for i in {1..5}
do
let re=$re*${i}
done
echo ${re}
}
jc
函数传参
[root@wzb shell]# cat jiecheng.sh
#!/bin/bash
jc(){
re=1
for i in `seq $1`
do
let re=$re*${i}
done
echo ${re}
}
jc 10 #函数传参
第二种
[root@wzb shell]# cat jiecheng02.sh
#!/bin/bash
jc(){
re=1
for ((i=1;i<=$1;i++)) #c语言的形式
do
let re=$[$re*${i}]
done
echo ${re}
}
jc 10
错误的函数返回值
代码
[root@wzb shell]# cat return01.sh
#!/bin/bash
fun2(){
read -p "enter num:" num
return $[2*$num]
}
fun2
echo "result is $?"
结果
因为shell中返回值在1-255之间,所以当想要的结果大于255时,结果会出错
一般是把结果传给变量,再由变量输出
[root@wzb shell]# ./return01.sh
enter num:12
result is 24
[root@wzb shell]# ./return01.sh
enter num:200
result is 144
数组传参
[root@wzb shell]# cat jiecheng03.sh
#!/bin/bash
num=(1 2 3)
num1=(2 4 6 8)
arrary(){
info=1
for i in "$@" #读取传入的数据,$@算是作为一个变量,若直接指定数组,就很不灵活
do
let info=$info*$i #计算阶乘
done
echo "$info"
}
arrary ${num[@]} #传入数组的数据
arrary ${num1[@]}
数组内部变量的使用
将数字*5在输出
[root@wzb shell]# cat arrary01.sh
#!/bin/bash
num=(1 2 3)
num1=(2 4 6)
arrary(){
local newnum=(`echo $@`) #将处于全局的数组在函数中重新设立,成为另一个一样的数组
local i
for i in ${!newnum[@]} #获取索引,有多种方法
do
let renum[$i]=${newnum[$i]}*5 #将数组中的元素*5,再赋给新的数组
done
echo "old:${newnum[@]}"
echo "new:${renum[@]}"}
arrary ${num[@]}
arrary ${num1[@]}
结果
[root@wzb shell]# ./arrary01.sh
old:1 2 3
new:5 10 15
old:2 4 6
new:10 20 30
break 的使用
A1234[root@wzb shell]# cat break01.sh
#!/bin/bash
for i in {A..D}
do
echo -n $i
for j in {1..9}
do
if [ $j -eq 5 ];then
#continue
break 2 #结束两层循环,这里结束了两个for循环
fi
echo -n $j
done
echo
done
break 1 等同于 break,结果
[root@wzb shell]# ./break01.sh
A1234
B1234
C1234
D1234
break 2 结果
[root@wzb shell]# ./break01.sh
A1234
continue 结果
5 不显示了
[root@wzb shell]# ./break01.sh
A12346789
B12346789
C12346789
D12346789
打印九九乘法表
[root@wzb shell]# cat 9901.sh
#!/bin/bash
for i in `seq 9`
do
for j in `seq 9`
do
if [ $i -lt $j ];then
continue
fi
let num=$i*$j
echo -n "$i*$j=$num " #-e 不换行的输出
done
echo ""
done
结果
[root@wzb shell]# ./9901.sh
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
shift的用法
shift 可以将位置参数向左移
[root@wzb shell]# cat shift.sh
#!/bin/bash
while [ $# -ne 0 ]
do
let sum+=$1
shift 1
done
echo "sum: $sum"
vim
匹配ip地址
[root@wzb shell]# egrep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' /etc/sysconfig/network-scripts/ifcfg-ens33
[root@wzb shell]# cat u.txt
tom TOM Tom tom123 TOM123 Tom123
命令
%s/tom/TOM/g # %表示全文,从第一行道最后一行,g表示全局
%s/\<[tT]om\>/TOM/g #\<...\> 限定了字符串的首和尾 只会将tom和Tom修改 只写 \< 则限制首
select 菜单
套了一个while 然后在每个选项后面加了 break
就可实现每输入一个命令,菜单就会显示一次
#!/bin/bash
PS3="your choice is:"
while :
do
select choice in disk_partition filesystem cpu_load men_util quit
do
case ${choice} in
disk_partition)
fdisk -l
break;;
filesystem)
df -h
break;;
cpu_load)
uptime
break;;
men_util)
free -m
break;;
quit)
exit 0;;
*)
echo "error"
exit 1
esac
done
done
实战项目 收集系统信息
[root@wzb shell]# cat show_sys_info.sh
#!/bin/bash
PS3="Your choice is: "
os_check(){
# 判断操作系统,centos:yum
if [ -e /etc/centos-release1 ];then
REDHAT=`cat /etc/centos-release1 | awk '{print $1}'`
elif [ -e /etc/issue1 ];then
DEBIAN=`cat /etc/issue1 | awk '{print $1}'`
elif [ -e /etc/qq/fedora-release ];then
FEDORA=`cat /etc/qq/fedora-release | awk '{print $1}'`
fi
if [ "${REDHAT}" == "CentOS" ];then
P_M=yum
elif [ "${DEBIAN}" == "Ubuntu" -o "${DEBIAN}" == "ubuntu" ];then
P_M=apt-get
elif [ "${FEDORA}" == "Fedora" ];then
P_M=dnf
else
echo "Operating system does not support."
exit 1
fi
}
cpu_load(){
echo "------------"
i=1
while [ $i -le 3 ];do
echo -e "参考值${i}"
UTIL=`vmstat | awk '{if(NR==3){print 100-15"%"}}'`
USER=`vmstat | awk '{if(NR==3){print $13"%"}}'`
SYS=`vmstat | awk '{if(NR==3){print $14"%"}}'`
IOWAIT=`vmstat | awk '{if(NR==3){print $16"%"}}'`
echo "Util: $UTIL"
echo "User use:$USER"
echo "System use: $SYS"
echo "I/O wait: $IOWAIT"
let i++
sleep 1
done
echo "-----------"
}
diks_laod(){
echo "---------------"
i=1
while [ $i -le 3 ]
do
echo -e "参考值 ${i}"
UTIL=`iostat -x -k | awk '/^[v|s]/]{OFS=": ";print $1,$NF"%"}'`
READ=`iostat -x -k | awk '/^[v|s]/{OFS=": ";print $1,$7"KB"}'`
WRITE=`iostat -x -k | awk '/^[v|s]/{OFS=": "print $1,$7"KB"}'`
IOWAIT=`vmstat | awk '{if(NR==3){print $16 "%"}}'`
echo -e "Util:"
echo -e "${UTIL}"
echo -e "I/O wait: $IOWAIT"
echo -e "Read/s:\n$READ"
echo -e "Write/s:\n$WRITE"
let i+=1
sleep 1
done
}
disk_use(){
# 硬盘利用率
DISK_LOG=/tmp/disk_use.tmp
DISK_TOTAL=`fdisk -l | awk -F "[: ]" '/^磁盘 \/dev/{printf "%s %d",$2,$3;print ""}'`
USE_RATE=`df -h | awk '/^\/dev/{print int($5)}'`
for i in ${USE_RATE};do
if [ $i -gt 90 ];then
PART=`df -h | awk '{if(int($5)=='''$i''') {print $6}}'`
echo "$PART = ${i}%" >> $DISK_LOG
fi
done
echo "----------------"
echo -e "Disk total:\n${DISK_TOTAL}"
if [ -e $DISK_LOG ];then
cat $DISK_LOG
rm -f $DISK_LOG
else
echo "---------------"
echo "no disk more than 90%"
fi
break
}
disk_inode(){
# 硬盘inode利用率
INODE_LOG=/tmp/inode_use.tmp
INODE_USE=`df -i | awk '/^\/dev/{print int($5)}'`
for i in ${INODE_USE}
do
if [ $i -ge 90 ];then
PART=`df -h | awk {if(int($5)==```$i```){print $6}}`
echo "$PART = ${i}%" >> ${INODE_LOG}
fi
done
df -i | awk '/^\/dev/{printf "%s %s\n",$5,$6}'
if [ -e ${INODE_LOG} ];then
echo "-----------"
cat ${INODE_LOG}
rm -f ${INODE_LOG}
else
echo "nothing is more than 90%"
fi
}
mem_use(){
#内存利用率
MEM_TOTAL=`free -m | awk 'NR==2{printf "%.1f",$2/1024} END{print "G"}'`
USE=` free -m | awk 'NR==2{printf "%.1f",$3/1024} END{print "G"}'`
FREE=`free -m | awk 'NR==2{printf "%.1f",$4/1024} END{print "G"}'`
CACHE=`free -m | awk 'NR==2{printf "%.1f",$6/1024} END{print "G"}'`
echo -e "Total: $MEM_TOTAL"
echo -e "Use: $USE"
echo -e "Free: $FREE"
echo -e "Cache: $CACHE"
echo "---------"
}
tcp_status(){
# 网络连接状态
echo "--------------"
COUNT=`ss -ant | awk '!/State/{status[$1]++} END{for(i in status){print i,status[i]}}'`
echo "$COUNT"
echo "--------------"
}
cpu_top10(){
# 占用cpu高的前10个进程
echo "-----------"
CPU_LOG=/tmp/cpu_top.tmp
for i in `seq 3`
do
echo "参考值${i}"
cat aux | awk '!/%CPU/{printf "PID: %-8s CPU: %-s%\t ---> %s \n ",$2,$3,$NF}' | sort -t ":" -k3 -nr | head
echo "--------------"
sleep 1
done
}
mem_top10(){
# 占用内存高的前10个进程
echo "---------------"
MEM_LOG=/tmp/mem_top.tmp
for i in `seq 3`
do
echo "参考值${i}"
cat aux | awk '!/%CPU/{printf "PID: %-6s MEM: %.2f% ---> %s\n",$2,$4,$NF}' | sort -nr -k4 | head
echo "----------"
sleep 1
done
}
traffic(){
# 查看网络流量
while true
do
read -p "input your want to check network:" int_card
if [ `ifconfig | grep -c ${int_card}` -ge 1 ];then
ifconfig ${int_card}
break
else
echo "error"
fi
done
old_rx=`ifconfig ${int_card} | awk '{if(NR==5){print $5}}'`
old_tx=`ifconfig ${int_catd} | awk '{if(NR==7){print $5}}'`
sleep 2
new_rx=`ifconfig ${int_card} | awk '{if(NR==5){print $5}}'`
new_tx=`ifconfig ${int_catd} | awk '{if(NR==7){print $5}}'`
echo "in------out"
IN=$(echo "${new_rx} ${old_rx}" | awk '{printf "%.1f\n",$1-$2}')
OUT=$(echo "${new_tx} ${old_tx}" | awk '{printf "%.1f\n",$1-$2}')
echo "${IN} ${OUT}"
echo "-------------"
}
while true
do
select input in cpu_load disk_use disk_use disk_inode mem_use tcp_status cpu_top10 mem_top10 traffic quit
do
case $input in
cpu_load)
cpu_load
break;;
disk_use)
disk_use
break;;
disk_inode)
disk_inode
break;;
mem_use)
mem_use
break;;
tcp_status)
tcp_status
break;;
cpu_top10)
cpu_top10
break;;
mem_top10)
mem_top10
break;;
traffic)
traffic
break;;
quit)
exit 0
break;;
esac
done
done
判断主机存活
[root@wzb shell]# cat ping_count3.txt
192.168.92.2
192.168.92.5
192.168.1.1
33.33.33.33
33.33.33.34
[root@wzb shell]# cat ping_count3.sh
#!/bin/bash
i=0
while read line;do
for count in {1..3}
do
ping -c1 -W1 ${line} &>/dev/null
if [ $? -eq 0 ];then
echo "${line} is ok"
break
else
let i++
if [ $i -eq 3 ];then
echo "${line} is fail"
i=0
fi
fi
done
done < ping_count3.txt
判断主机存活 (函数)
[root@wzb shell]# cat ping_count3_02.sh
#!/bin/bash
ping_3(){
i=0
while read ip
do
for i in {1..3}
do
ping -c1 -W1 ${ip} &>/dev/null
if [ $? -eq 0 ];then
echo "${ip} is ok"
break
else
let i++
if [ ${i} -eq 3 ];then
echo "${ip} is fail"
fi
fi
done
done < $1
}
ping_3 $1
another
[root@wzb shell]# cat ping_count3_03.sh
#!/bin/bash
ping_3(){
ping -c1 -W1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo "$ip is ok"
continue
fi
}
while read ip
do
ping_3
ping_3
ping_3
echo "$ip is fail"
done < ping_count3.txt
输入的变量为 保存ip地址的文件 ping_count3.txt
[root@wzb shell]# ./ping_count3_02.sh ping_count3.txt
nginx 日志分析
统计某一天的PV量
[root@wzb logs]# grep "06/Aug/2022" text.log | wc -l
[root@wzb logs]# cat text.log | grep "06/Aug/2022" | wc -l
统计一天中某一时间段的PV量
如2022.8.14的21:00 - 21:40
[root@wzb logs]# cat text.log | awk '{if($4 >="[14/Aug/2022:21:00:00" && $4 <= "[14/Aug/2022:21:40:00"){print $0}}' | wc -l
12
统计一天内 访问最多的10个ip
[root@wzb logs]# cat text.log | awk '{list[$1]++} END{for(i in list){printf "%-15s %s\n",i,list[i]}}' | head -n 10 | sort -k2 -nr
192.168.92.133 99
192.168.92.1 45
192.168.92.160 5
192.168.92.5 3
统计在几天中 一段时间的ip访问
如 8.6-8.14 中 20:00-21:30
统计一天中 访问大于40次的ip
日期:2022.8.16
文件:text.log_2022.8.16
[root@wzb logs]# cat text.log | awk '/16\/Aug\/2022/ {list[$1]++} END{for(i in list){if (list[i]>=40){printf "%-15s %s\n",i,list[i]}}}' | sort -k2 -nr
192.168.92.133 99
统计访问页面
[root@wzb logs]# cat text.log | awk '{list[$7]++} END{for(i in list){printf "%-15s %s\n",i,list[i]}}' | sort -k2 -nr
/main/ 142
/main 5
/main1/ 4
/text1/ 2
/text1 1
/main1 1
统计某一天 每个URL访问内容总大小
($body_bytes_sent)
[root@wzb logs]# awk '{list[$7]+=$10} END{for(i in list){printf "%-20s %s\n",i,list[i]}}' text.log
/text1 356
/main1 169
/text2 169
/text2/jquery.js 0
/text1/ 58
/main 1014
/text2/ 448
/main1/ 786393
/main/ 9986672
[root@wzb logs]# grep "16/Aug/2022" text.log |awk '{list[$7]+=$10} END{for(i in list){printf "%-20s %s\n",i,list[i]}}'
/text1 356
/text2 169
/text2/jquery.js 0
/text1/ 58
/main 507
/text2/ 448
/main/ 3745002
统计每个ip访问状态码数量
既然是要统计 ip 和 访问状态码 的数量,那么就将ip 和 status 作为索引
要统计什么就将什么作为索引
[root@wzb logs]# awk '{list[$1" "$9]++} END{for (i in list){printf "%-20s %s\n",i,list[i]}}' text.log
192.168.92.1 301 7
192.168.92.5 301 1
192.168.92.160 301 1
192.168.92.1 304 69
192.168.92.133 301 1
192.168.92.5 304 1
192.168.92.160 304 2
192.168.92.1 200 13
192.168.92.133 304 98
192.168.92.5 200 1
192.168.92.160 200 2
192.168.92.133 200 1
整齐一点
[root@wzb logs]# awk '{list[$1" "$9]++} END{for (i in list){printf "%-20s %s\n",i,list[i]}}' text.log | awk '{printf "%-15s %s %s\n",$1,$2,$3}' | sort -nr -k3
192.168.92.133 304 98
192.168.92.1 304 69
192.168.92.1 200 13
192.168.92.1 301 7
192.168.92.160 304 2
192.168.92.160 200 2
192.168.92.5 304 1
192.168.92.5 301 1
192.168.92.5 200 1
192.168.92.160 301 1
192.168.92.133 301 1
192.168.92.133 200 1
统计状态码404出现的次数
[root@wzb logs]# awk '{if($9=="404"){list[$1" "$9]++}} END{for (i in list){print i,list[i]}}' text.log | awk '{printf "%-15s %-6s %s\n",$1,$2,$3}' | sort -nr -k3
192.168.92.5 404 8
192.168.92.133 404 7
192.168.92.1 404 2
统计前一分钟的PV量
date的用法
[root@wzb logs]# date -d '-5 minute' #输入前5分钟的时间
2022年 08月 17日 星期三 14:53:06 CST
[root@wzb logs]# date -d '+5 minute' #输入后5分钟的时间
2022年 08月 17日 星期三 15:03:22 CST
[root@wzb logs]# date -d '+5 week'
2022年 09月 21日 星期三 15:00:42 CST
[root@wzb logs]# date -d '+5 year'
2027年 08月 17日 星期二 15:00:47 CST
首先定义变量date,以分钟显示
awk -v 引入外部变量 ;$0 ~ date 所有内容来匹配 date 若匹配到就 i+1
[root@wzb logs]# date=$(date -d '-1 minute' +%d/%b/%Y:%H:%M); awk -v date=$date '$0 ~ date {i++} END{print i}' text.log
8
another
[root@wzb logs]# date=$(date -d '-1 minute' +%d/%b/%Y:%H:%M); awk -v date=$date '$0 ~ date {print $0}' text.log | wc -l
3
统计某一天 17:30 ~ 18:30 状态码为404
[root@wzb logs]# awk '{if($4 >= "[17/Aug/2022:17:30:00" && $4 <= "[17/Aug/2022:18:30:30"){if($9 == "304"){list[$1" "$9]++}}} END{for(i in list){print i,list[i]}}' text.log | awk '{printf "%-20s %s\n",$1,$2}'
192.168.92.1 304
192.168.92.133 304
统计某一天各种状态码数量
[root@wzb logs]# awk '/16\/Aug\/2022/{list[$1" "$9]++} END{for(i in list){print i,list[i]}}' text.log | awk '{printf "%-20s %-5s %s\n",$1,$2,$3}'
192.168.92.133 404 7
192.168.92.1 301 5
192.168.92.1 304 37
192.168.92.133 301 1
192.168.92.1 200 18
192.168.92.1 404 2
192.168.92.133 304 98
192.168.92.5 404 8
192.168.92.133 200 1
显示百分比
[root@wzb logs]# awk '/16\/Aug\/2022/{list[$1" "$9]++;total++} END{for(i in list){printf "%-20s %-4s %.2f%\n",i,list[i],list[i]/total*100}}' text.log | sort -nr -k4
192.168.92.133 304 98 55.37%
192.168.92.1 304 37 20.90%
192.168.92.1 200 18 10.17%
192.168.92.5 404 8 4.52%
192.168.92.133 404 7 3.95%
192.168.92.1 301 5 2.82%
192.168.92.1 404 2 1.13%
192.168.92.133 301 1 0.56%
192.168.92.133 200 1 0.56%
定期删除目录下修改时间大于7天的文件
[root@wzb shell]# cat remove_file.sh
#!/bin/bash
back_dir=/usr/local/nginx/logs/log01
find $back_dir -mindepth 1 -mtime +7 | xargs rm -rf
这里 用 -mindepth 1是为了find结果不包含当前目录,若当前目录创建的时间大于7天,那么也会被删除,即使目录中含有修改时间小于7天的文件
防止被修改
chattr +i
定期清理/data
该目录仅工作日周一至周五自动生成文件zz
希望只保留最近2天的文件
无论过几个节假日/data 仍会有前两个工作日的备份文件
简单来说就是无论怎样都要保留最近的两个文件
[root@wzb shell]# cat remove_file01.sh
#!/bin/bash
back_dir=/usr/local/nginx/logs/log01
cd $back_dir
ls -t $back_dir | awk 'NR > 2' | xargs rm -rvf
因为 单纯的ls无法显示完整路径,所以cd一下
若日志文件命名有规律那么可以使用
[root@wzb ~]# ls /usr/local/nginx/logs/log01/*.log
/usr/local/nginx/logs/log01/1.log /usr/local/nginx/logs/log01/5.log
/usr/local/nginx/logs/log01/10.log /usr/local/nginx/logs/log01/6.log
/usr/local/nginx/logs/log01/2.log /usr/local/nginx/logs/log01/7.log
/usr/local/nginx/logs/log01/3.log /usr/local/nginx/logs/log01/8.log
/usr/local/nginx/logs/log01/4.log /usr/local/nginx/logs/log01/9.log
这样就带了完整的路径
若在最近的两个工作日生成的日志文件大于2
想要保留所有最近两日的日志,那么就可以结合起来
mysql 多机部署
pass
服务器系统配置初始化
需求:
1、设置时区并同步时间
2、禁用selinux
3、清空防火墙默认策略
4、历史命令显示操作时间
5、禁止root远程登陆
6、禁止定时任务发送邮件
7、设置最大打开文件数
8、减少Swap使用
9、系统内核参数优化
10、安装系统性能分许工具及其他















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









