








B-树
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(有些地方写 的是B-树,注意不要误读成"B减树")。
一棵M阶(M>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或 者满足一下性质:
- 根节点至少有两个孩子
- 每个非根节点至少有M/2(上取整)个孩子,至多有M个孩子
- 每个非根节点至少有M/2-1(上取整)个关键字,至多有M-1个关键字,并且以升序排列
- key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间
- 所有的叶子节点都在同一层
孩子永远比数据多一个。
- 根节点:关键字数量:[1,m-1],孩子的数量[2,m]
- 非根节点:关键字数量:[m/2-1,m-1],孩子的数量[m/2,m]
- 每个结点中,孩子的数量永远比关键字多1
B-数的插入
假设M = 3. 即三叉树,每个节点中存储两个数据,两个数据可以将区间分割成三个部分,因此节点应该有三个孩子,节点的结构如下:

用序列{53, 139, 75, 49, 145, 36, 101}构建B树设M=3
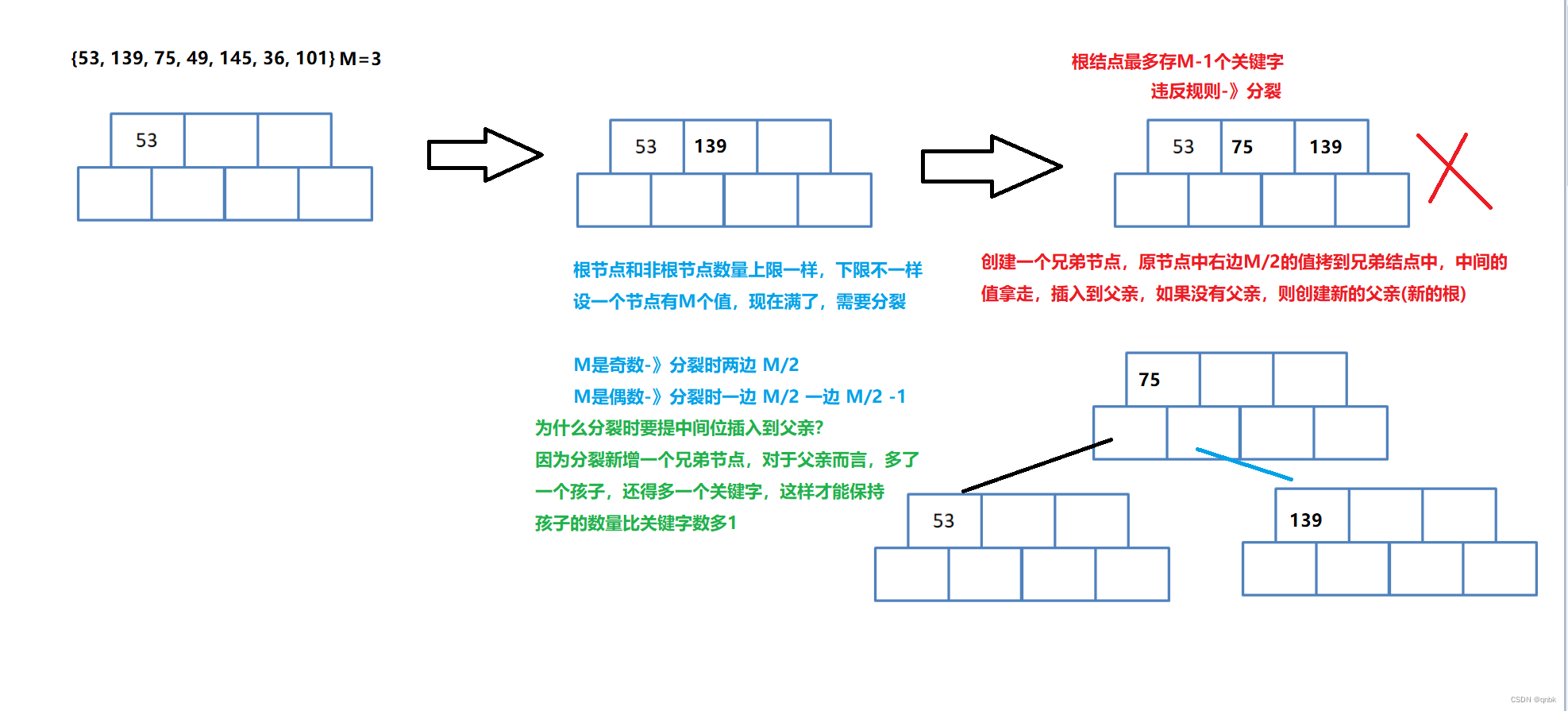
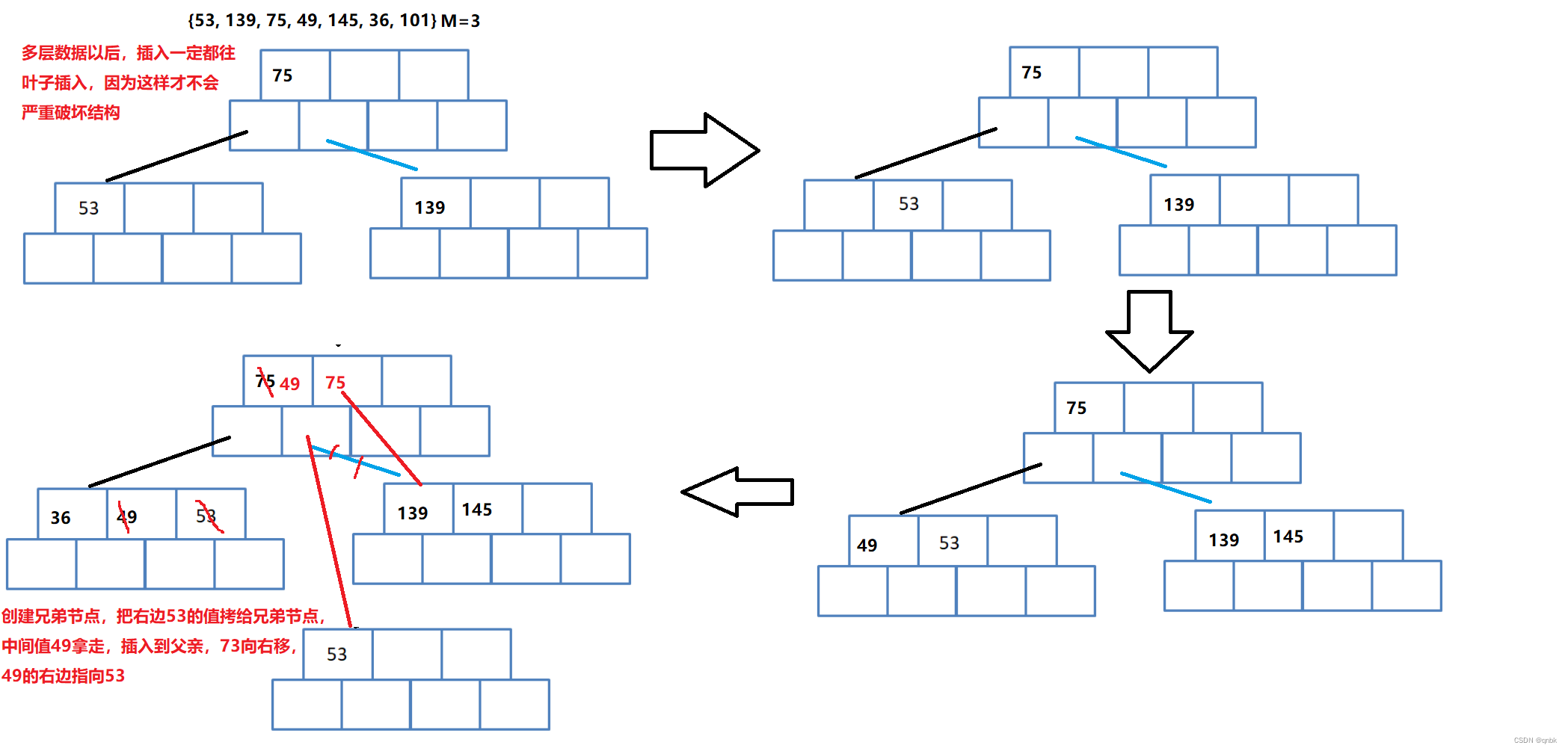
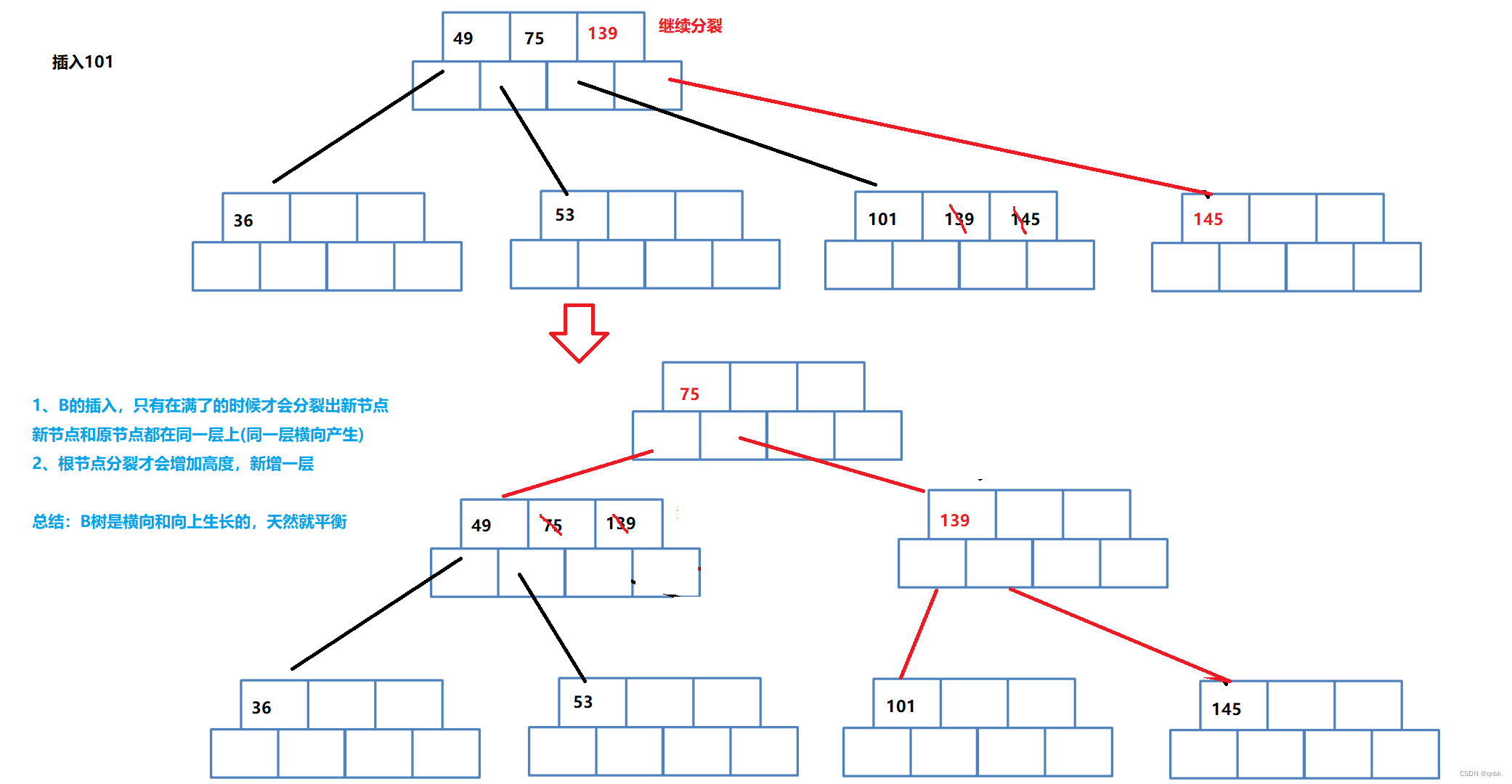

插入过程总结:
- 如果树为空,直接插入新节点中,该节点为树的根节点
- 树非空,找待插入元素在树中的插入位置(注意:找到的插入节点位置一定在叶子节点中)
- 检测是否找到插入位置(假设树中的key唯一,即该元素已经存在时则不插入)
- 按照插入排序的思想将该元素插入到找到的节点中
- 检测该节点是否满足B-树的性质:即该节点中的元素个数是否等于M,如果小于则满足
- 如果插入后节点不满足B树的性质,需要对该节点进行分裂:申请新节点,找到该节点的中间位置,将该节点中间位置右侧的元素以及其孩子搬移到新节点,将中间位置元素以及新节点往该节点的双亲节点中插入,即继续第4条
如果向上已经分裂到根节点的位置,插入结束
实现B-树的插入
#pragma once
#include <iostream>
using namespace std;
template<class K,class V,size_t M>
struct BTreeNode
{
/*
pair<K, V> _kvs[M];
BTreeNode<K, V, M>* _sub[M + 1];
*/
//孩子数比关键数多1
//K空间上多给一个,方便分裂,方便插入以后再分裂
pair<K, V> _kvs[M];
BTreeNode<K, V, M>* _sub[M + 1];
BTreeNode<K, V, M>* _parent;
size_t _kvSize;
BTreeNode()
:_kvSize(0)
, _parent(nullptr)
{
for (size_t i = 0; i < M + 1; ++i)
{
_sub[i] = nullptr;
}
}
};
template<class K, class V, size_t M>
class BTree
{
typedef BTreeNode<K, V, M> Node;
public:
pair<Node*,int> Find(const K& key)
{
//观察:左孩子下标跟key的下标相等,右孩子下标是key的下标+1
//第i个key的左孩子是sub[i],第i个key的右孩子是sub[i + 1]
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
size_t i = 0;
while (i < cur->_kvSize)
{
//如果M比较大,可以换成二分查找会快一些
if (cur->_kvs[i].first < key)//key大于当前位置往右找
i++;
else if (cur->_kvs[i].first > key)//key小于当前位置往左找
break;
else
return make_pair(cur, i);
}
parent = cur;
cur = cur->_sub[i];
}
//没找到
return make_pair(parent, -1);
}
void InsertKV(Node* cur, const pair<K, V> &kv, Node* sub)
{
//往cur里插入key和sub
int i = cur->_kvSize - 1;
for (;i >= 0; )
{
//将kv找到合适的位置插入
if (cur->_kvs[i].first < kv.first)
{
break;
}
else
{
//kv往后挪动,kv的有孩子也挪动
cur->_kvs[i + 1] = cur->_kvs[i];
cur->_kvs[i + 2] = cur->_kvs[i + 1];
i--;
}
}
cur->_kvs[i + 1] = kv;
cur->_sub[i + 2] = sub;
cur->_kvSize++;
if (sub)
{
sub->_parent = cur;
}
}
bool Insert(const pair<K, V> &kv)
{
if (_root == nullptr)
{
_root = new Node;
_root->_kvs[0] = kv;
_root->_kvSize = 1;
return true;
}
pair<Node*, int> ret = Find(kv.first);
if (ret.second >= 0)//已经有了,不能插入(允许插入就是mutil版本)
{
return false;
}
//往cur节点插入一个newkv和sub
Node* cur = ret.first;
pair<K, V> newkv = kv;
Node* sub = nullptr;
while (1)
{
InsertKV(cur, newkv,sub);
//1\如果cur没满就结束
if (cur->_kvSize < M)
{
return true;
}
else //满了需要分裂
{
//2、如果满了就分裂,分裂出兄弟以后往父亲插一个关键字和孩子,再满还要继续分裂
Node* newnode = new Node;//分裂出一个兄弟节点
//\拷贝走右半区间给分裂的兄弟节点
int mid = M / 2;
int j = 0;
int i = mid + 1;
newkv = cur->_kvs[mid];
cur->_kvs[mid] = pair<K, V>();
for (; i < M; i++)
{
newnode->_kvs[j] = cur->_kvs[i];
cur->_kvs[i] = pair<K, V>();
newnode->_sub[j] = cur->_sub[i];//还需要拷贝孩子
cur->_sub[i] = nullptr;
if (newnode->_sub[j])
{
newnode->_sub[j]->_parent = newnode;
}
j++;
newnode->_kvSize++;
//printf("%d\n", newnode->_kvSize);
}
//最后一个右孩子
newnode->_sub[j] = cur->_sub[i];
if (newnode->_sub[j])
{
newnode->_sub[j]->_parent = newnode;
}
newkv = cur->_kvs[mid];
cur->_kvSize = cur->_kvSize - newnode->_kvSize - 1;
//a、如果Cur没有父亲,cur就是根,产生新的根
//b、如果cur有父亲,那么就转换成cur的父亲中插入一个key和一个孩子
//c最坏的情况分裂到根,原来的根分裂产生新的根,最多分裂出高度次
if (cur->_parent == nullptr)
{
_root = new Node;
_root->_kvs[0] = newkv;
_root->_sub[0] = cur;
_root->_sub[1] = newnode;
cur->_parent = _root;
newnode->_parent = _root;
_root->_kvSize = 1;
return true;
}
else
{
//往父亲插入newkv和newnode,转换成迭代器
sub = newnode;
cur = cur->_parent;
}
}
}
return true;
}
private:
Node* _root = nullptr;
};
void test()
{
BTree<int, int, 3> t;
int a[] = { 53, 139, 75, 49, 145, 36, 101 };
for (auto e : a)
{
t.Insert(make_pair(e, e));
}
}
B+树和B*树
B+树
B+树是B-树的变形,也是一种多路搜索树,
其定义基本与B-树相同,除了:
- 非叶子节点的子树指针与关键字个数相同
- 非叶子节点的子树指针p[i],指向关键字值属于[k[i],k[i+1])的子树
- 为所有叶子节点增加一个链指针
- 所有关键字都在叶子节点出现
节点K数到M+1在分裂
分裂出兄弟,拷走一半
关键字就是兄弟中第一个K,孩子就是兄弟
B+树的插入:分裂时拷走一半,不需要把中位数插入到父亲,往上提,因为叶子分裂,所有的值都要存在叶子,非叶子只存孩子最小的值,方便查找,B+树存在重复存储K的问题,所有的值都在叶子,叶子再链接方便遍历树中的所有值
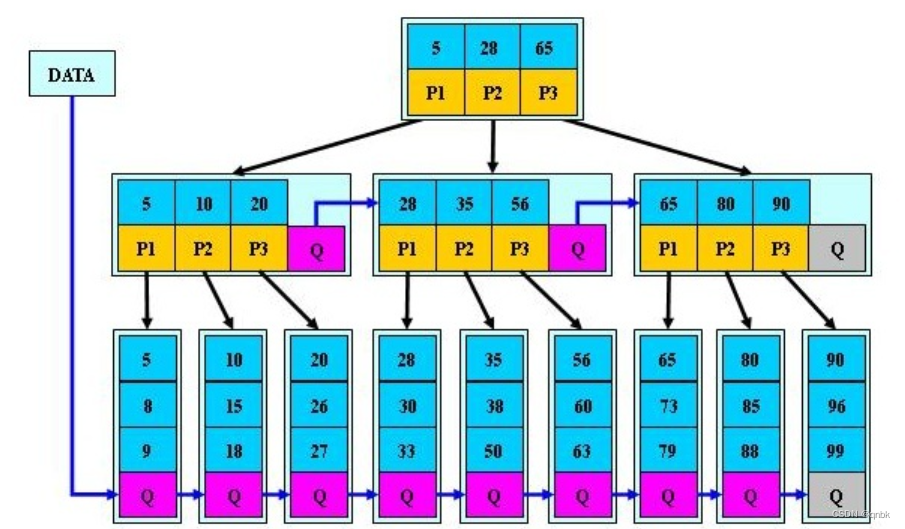
B+树的搜索与B-树基本相同,区别是B+树只有达到叶子节点才能命中(B-树可以在非叶子节点中命中),其性能也等价与在关键字全集做一次二分查找。
B+树的特性:
- 所有关键字都出现在叶子节点的链表中(稠密索引),且链表中的节点都是有序的。
- 不可能在非叶子节点中命中。
- 非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储数据的数据层。
- 更适合文件索引系统
B*树
B*树是B+树的变形,在B+树的非根和非叶子节点再增加指向兄弟节点的指针。
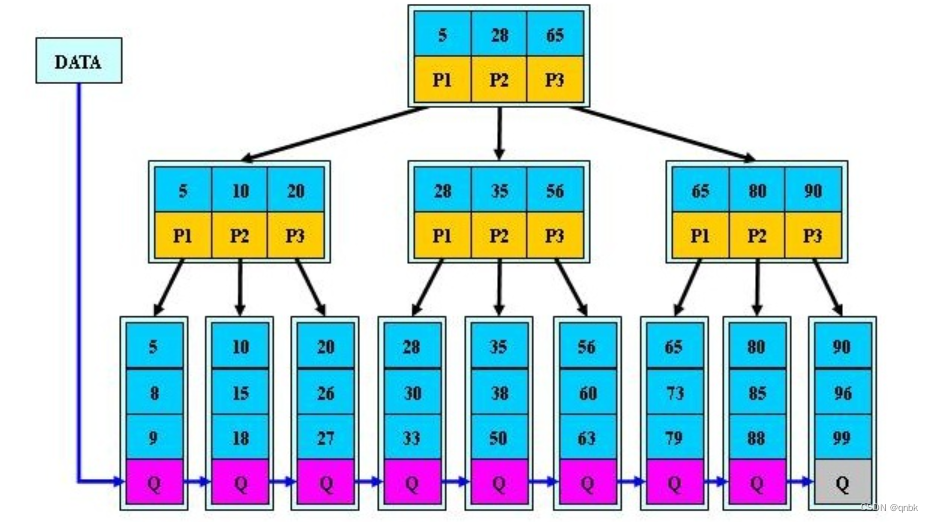
-
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3 (代替B+树的1/2);
-
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据
复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父 结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分
数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字 (因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针; -
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
总结
-
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
-
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
-
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的素引;B+树总是到叶子结点才命中, -
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
B-树的应用
索引
B-树最常见的应用就是用来做索引。索引(index)是帮助MySQL高效获取数据的数据结构,简单来说:索引就是数据结构。
当数据量很大时,为了能够方便管理数据,提高数据查询的效率,一般都会选择将数据保存到数据库,因此数据库不仅仅是帮助用户管理数据,而且数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法,该数据结构就是索引。















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









