






线性回归是形式最简单的回归模型,这里就不对其概念和含义做过多叙述了。本篇先简单介绍下书写线性回归表达式以及提取模型结果的方法,从中也可以理解R语言进行回归分析的基本语法。
使用的数据集来自R中自带的mtcars,这里从中提取三个变量用于后续分析。首先使用plot.data.frame函数观察三个变量的相互关系:
(不理解plot.data.frame函数的可以点击graphics | 基础绘图系统(五)——plot函数功能再探和低级绘图函数)
data <- mtcars[, c("mpg", "wt", "qsec")]
plot(data)
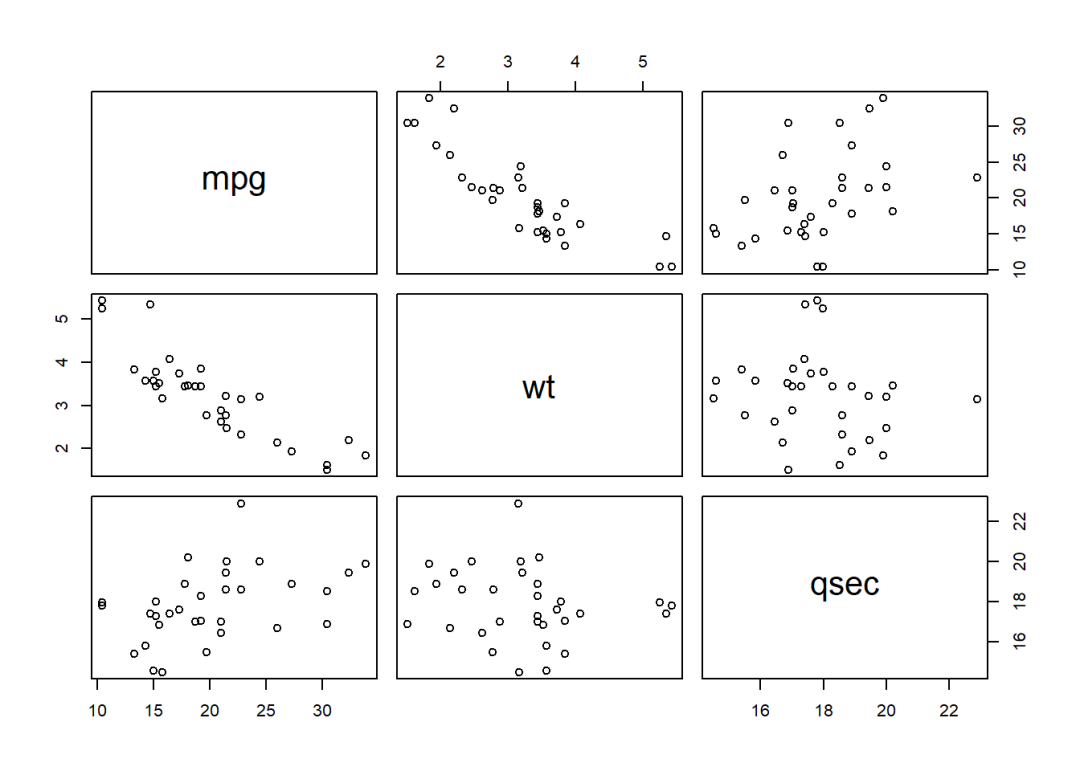
从中可以看出
wt和qsec两个变量都与mpg大致呈线性关系,其中前者更明显,因此下文就以mpg为因变量,wt和qsec为自变量;这里不考虑变量的实际含义,只做技术分析。
stats包中做线性回归的函数为lm,语法结构如下:
lm(formula, data, subset, weights, na.action,
method = "qr", model = TRUE, x = FALSE, y = FALSE, qr = TRUE,
singular.ok = TRUE, contrasts = NULL, offset, ...)
1 模型表达式和输出结果
1.1 表达式
formula参数就是模型的表达式,data参数是表达式中变量所在的数据框。表达式的基本格式为y ~ x,具体可见下表[1]:

建立以下三个线性模型:
model.1 <- lm(mpg ~ wt, data = data)
model.2 <- lm(mpg ~ wt + qsec, data = data)
model.3 <- lm(mpg ~ wt + qsec + wt:qsec, data = data)
model.1:一元线性模型;
model.2:多元线性模型;
model.3:含交互项的线性模型。
使用as.formula函数构建模型表达式
xnam <- paste0("x", 1:25)
b <- paste("y ~ ", paste(xnam, collapse= "+"))
b
## [1] "y ~ x1+x2+x3+x4+x5+x6+x7+x8+x9+x10+x11+x12+x13+x14+x15+x16+x17+x18+x19+x20+x21+x22+x23+x24+x25"
as.formula(b)
## y ~ x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + x9 + x10 + x11 +
## x12 + x13 + x14 + x15 + x16 + x17 + x18 + x19 + x20 + x21 +
## x22 + x23 + x24 + x25
使用updata函数往已有表达式中添加变量
formula.1 <- mpg ~ wt
formula.2 <- update(formula.1, . ~ . + qsec)
formula.2
## mpg ~ wt + qsec
该函数还能直接对模型使用:
update(model.1, .~. + qsec)
##
## Call:
## lm(formula = mpg ~ wt + qsec, data = data)
##
## Coefficients:
## (Intercept) wt qsec
## 19.7462 -5.0480 0.9292
1.2 输出模型结果
使用summary函数即可预览模型结果的主要信息:
summary(model.1)
##
## Call:
## lm(formula = mpg ~ wt, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5432 -2.3647 -0.1252 1.4096 6.8727
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
## wt -5.3445 0.5591 -9.559 1.29e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.046 on 30 degrees of freedom
## Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
## F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
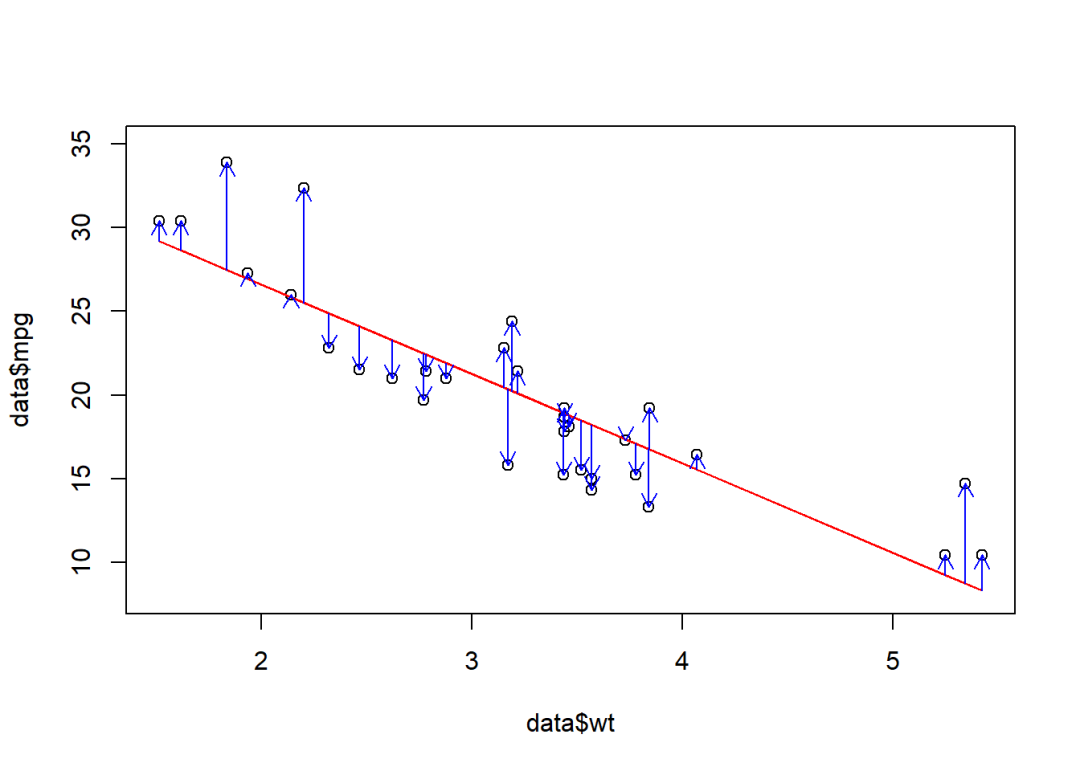
使用fitted函数输出模型对因变量的拟合结果:
fit.1 <- fitted(model.1)
plot(data$wt, data$mpg, ylim = c(8, 35))
lines(data$wt, fit.1, col = "red")
arrows(data$wt, fit.1, data$wt, data$mpg,
length = 0.1, col = "blue")
1.3 偏移项
偏移项也属于模型表达式的一部分,不同之处在于其系数固定为1,其数学含义是因变量已知的成分(或分量),因此不需要对其系数进行估计。偏移项在lm中使用offset参数表示。
model.11 <- lm(formula.1, data, offset = qsec)
summary(model.11)
##
## Call:
## lm(formula = formula.1, data = data, offset = qsec)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5322 -2.0295 -0.2541 1.4675 5.7309
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 18.4098 1.5754 11.69 1.08e-12 ***
## wt -5.0254 0.4691 -10.71 9.00e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.556 on 30 degrees of freedom
## Multiple R-squared: 0.8281, Adjusted R-squared: 0.8223
## F-statistic: 144.5 on 1 and 30 DF, p-value: 5.351e-13
在线性模型中,以下表达式等价:
为了验证这一点,比较下面的model.12和前面的model.11的结果:
data$diff <- data$mpg - data$qsec
model.12 <- lm(diff ~ wt, data)
summary(model.12)
##
## Call:
## lm(formula = diff ~ wt, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5322 -2.0295 -0.2541 1.4675 5.7309
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 18.4098 1.5754 11.69 1.08e-12 ***
## wt -5.0254 0.4691 -10.71 9.00e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.556 on 30 degrees of freedom
## Multiple R-squared: 0.7928, Adjusted R-squared: 0.7858
## F-statistic: 114.8 on 1 and 30 DF, p-value: 8.995e-12
也可以不生成新变量,直接将mpg - qsec当作因变量写在表达式的左半部分:
model.13 <- lm((mpg - qsec) ~ wt, data)
summary(model.13)
##
## Call:
## lm(formula = (mpg - qsec) ~ wt, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5322 -2.0295 -0.2541 1.4675 5.7309
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 18.4098 1.5754 11.69 1.08e-12 ***
## wt -5.0254 0.4691 -10.71 9.00e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.556 on 30 degrees of freedom
## Multiple R-squared: 0.7928, Adjusted R-squared: 0.7858
## F-statistic: 114.8 on 1 and 30 DF, p-value: 8.995e-12
仔细观察以上三个模型的结果,model.12和model.13的输出结果完全一致,下文就以model.12代替两者,而model.11与它们的模型系数是一样的,但是R方和F检验结果是不一样的,这说明model.11与model.12并不完全等价。
model.11与model.12的残差是一致的:
head(residuals(model.11))
## Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
## -0.70328941 0.01818514 -2.56090653 -0.29318213
## Hornet Sportabout Valiant
## 0.55753071 -3.14196148
head(residuals(model.12))
## Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
## -0.70328941 0.01818514 -2.56090653 -0.29318213
## Hornet Sportabout Valiant
## 0.55753071 -3.14196148
但模型的拟合值不一样:
head(fitted(model.11))
## Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
## 21.70329 20.98181 25.36091 21.69318
## Hornet Sportabout Valiant
## 18.14247 21.24196
head(fitted(model.12))
## Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
## 5.243289 3.961815 6.750907 2.253182
## Hornet Sportabout Valiant
## 1.122469 1.021961
这是因为model.11的因变量是
mpg,而model.12的因变量是mpg - qsec的整体。也就是说,二者拟合的对象不同。
因为线性回归的R方等于真实值和拟合值相关系数的平方,可以做以下检验:
(cor(fitted(model.11), data$mpg))^2
## [1] 0.8260324
(cor(fitted(model.12), data$diff))^2
## [1] 0.7927538
可以发现,手动计算的model.12的R方与模型输出结果是一致的,而model.11的计算结果和输出结果存在略微差异。
以下是分割线
为了探究为什么会存在以上差异,考虑到R方与相关系数平方相等只在线性模型中成立,而模型中加入偏移项的线性模型和普通的线性模型可能存在区别,因此可以使用R方的真正定义去计算:
yerror <- residuals(model.11)
ycenter = scale(data$mpg, scale = F)
1 - sum(yerror^2)/sum(ycenter^2)
## [1] 0.8259889
ycenter = scale(data$diff, scale = F)
1 - sum(yerror^2)/sum(ycenter^2)
## [1] 0.7927538
结果显示,计算出model.11的R方还是与输出结果不一致,反而和使用相关系数平方计算的结果更接近,而model.12的计算结果仍然和输出结果一致。
有清楚原因的读者可以后台联系~
参考资料
[1]
表: R语言实战(第2版)


















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









