






基本操作不再叙述,对于cuda C 中的二维数组,可以直接采用cudaMalloc和cudaMemcpy进行操作,不使用cudaMallocPitch和cudaMemcpy2D也可以,
#include<stdlib.h>
#include <stdio.h>
#include<windows.h>
#include<time.h>
#include <math.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
printf("Error: %s:%d, ", __FILE__, __LINE__); \
printf("code:%d, reason: %s\n", error, cudaGetErrorString(error)); \
exit(-10*error); \
} \
}
double cpuSecond() {
clock_t start;//clock_t为clock()函数返回的变量类型
double duration;//记录被测函数运行时间,以秒为单位
start = clock();//开始计时
duration = (double)(start) / CLOCKS_PER_SEC;//计算运行时间
return duration;
}
void checkResult(float* hostRef, float* gpuRef, const int N) {
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++) {
if (fabs(hostRef[i] - gpuRef[i]) > epsilon) {
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
}
void initialData(float* ip, int size) {
// generate different seed for random number
time_t t;
srand((unsigned)time(&t));
for (int i = 0; i < size; i++) {
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
}
void sumMatrixOnHost(float* A, float* B, float* C, const int nx, const int ny) {
float* ia = A;
float* ib = B;
float* ic = C;
for (int iy = 0; iy < ny; iy++) {
for (int ix = 0; ix < nx; ix++) {
ic[ix] = ia[ix] + ib[ix];
}
ia += nx; ib += nx; ic += nx;
}
}
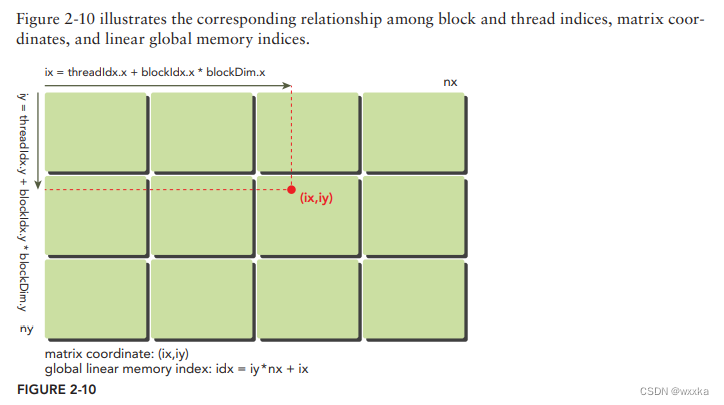
__global__ void sumMatrixOnGPU2D(float* MatA, float* MatB, float* MatC,
int nx, int ny) {
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
int main(int argc, char** argv) {
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up date size of matrix
int nx = 1 << 12;
int ny = 1 << 12;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d nx*ny = %lld\n", nx, ny, nxy * 52);
// malloc host memory
float* h_A, * h_B;
float* gpuRef;
float* hostRef;
h_A = (float*)malloc(nBytes);
h_B = (float*)malloc(nBytes);
hostRef = (float*)malloc(nBytes);
gpuRef = (float*)malloc(nBytes);
// initialize data at host side
double iStart = cpuSecond();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps[10];
iElaps[0] = cpuSecond() - iStart;
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = cpuSecond();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps[1] = cpuSecond() - iStart;
// malloc device global memory
float* d_MatA, * d_MatB, * d_MatC;
cudaMalloc((void**)&d_MatA, nBytes);
cudaMalloc((void**)&d_MatB, nBytes);
cudaMalloc((void**)&d_MatC, nBytes);
// transfer data from host to device
cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice);
// invoke kernel at host side
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
iStart = cpuSecond();
sumMatrixOnGPU2D << < grid, block >> > (d_MatA, d_MatB, d_MatC, nx, ny);
cudaDeviceSynchronize();
iElaps[2] = cpuSecond() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y, block.x, block.y, iElaps[2]);
printf("iElaps[0]: %lf iElaps[1]: %lf\n", iElaps[0], iElaps[1]);
// copy kernel result back to host side
cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost);
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
cudaFree(d_MatA);
cudaFree(d_MatB);
cudaFree(d_MatC);
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
cudaDeviceReset();
return (0);
}计算程序运行时间
double cpuSecond() {
clock_t start;//clock_t为clock()函数返回的变量类型
double duration;//记录被测函数运行时间,以秒为单位
start = clock();//开始计时
duration = (double)(start) / CLOCKS_PER_SEC;//计算运行时间
return duration;
}int main() {
double iStart = cpuSecond();//开始计时
//待测试程序段
//Sleep(100);
double iElaps = cpuSecond() - iStart;//计算距离开始的时间段
printf("%f sec\n", iElaps);
return 0;
}
摘自CUDA C Programming
➤ Computer architecture (hardware aspect)
➤ Parallel programming (software aspect)
In order to achieve parallel execution in software, the hardware must provide a platform that supports concurrent execution of multiple processes or multiple threads.
multiple processes or multiple threads.
Most modern processors implement the Harvard architecture, as shown in Figure 1-1, which is comprised of three main components:
➤ Memory (instruction memory and data memory)
➤ Central processing unit (control unit and arithmetic logic unit)
➤ Input/Output interfaces

Figure 1-1
Sequential and Parallel Programming
Figure 1-2
precedence restraint
From the eye of a programmer, a program consists of two basic ingredients: instruction and data. When a computational problem is broken down into many small pieces of computation, each piece is called a task. In a task, individual instructions consume inputs, apply a function, and produce outputs. A data dependency occurs when an instruction consumes data produced by a preceding instruction. Therefore, you can classify the relationship between any two tasks as either dependent, if one consumes the output of another, or independent.
Analyzing data dependencies is a fundamental skill in implementing parallel algorithms because dependencies are one of the primary inhibitors to parallelism, and understanding them is necessary to obtain application speedup in the modern programming world. In most cases, multiple independent chains of dependent tasks offer the best opportunity for parallelization.
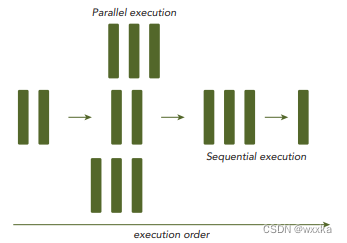
Figure 1-3
Parallelism
Nowadays, parallelism is becoming ubiquitous, and parallel programming is becoming mainstream in the programming world. Parallelism at multiple levels is the driving force of architecture design. There are two fundamental types of parallelism in applications:
➤ Task parallelism
➤ Data parallelism
Task parallelism arises when there are many tasks or functions that can be operated independently and largely in parallel. Task parallelism focuses on distributing functions across multiple cores.
Data parallelism arises when there are many data items that can be operated on at the same time. Data parallelism focuses on distributing the data across multiple cores.
CUDA programming is especially well-suited to address problems that can be expressed as data-parallel computations. The major focus of this book is how to solve a data-parallel problem with CUDA programming. Many applications that process large data sets can use a data-parallel model to speed up the computations. Data-parallel processing maps data elements to parallel threads.
The first step in designing a data parallel program is to partition data across threads, with each thread working on a portion of the data. In general, there are two approaches to partitioning data: block partitioning and cyclic partitioning. In block partitioning, many consecutive elements of data are chunked together. Each chunk is assigned to a single thread in any order, and threads generally process only one chunk at a time. In cyclic partitioning, fewer data elements are chunked together. Neighboring threads receive neighboring chunks, and each thread can handle more than one chunk. Selecting a new chunk for a thread to process implies jumping ahead as many chunks as there are threads.
A heterogeneous application consists of two parts:
➤ Host code
➤ Device code
Host code runs on CPUs and device code runs on GPUs. An application executing on a heterogeneous platform is typically initialized by the CPU. The CPU code is responsible for managing the environment, code, and data for the device before loading compute-intensive tasks on the device. With computational intensive applications, program sections often exhibit a rich amount of data parallelism. GPUs are used to accelerate the execution of this portion of data parallelism. When a hardware component that is physically separate from the CPU is used to accelerate computationally intensive sections of an application, it is referred to as a hardware accelerator. GPUs are arguably the most common example of a hardware accelerator. There are two important features that d escribe GPU capability:
➤ Number of CUDA cores
➤ Memory size
Accordingly, there are two different metrics for describing GPU performance:
➤ Peak computational performance
➤ Memory bandwidth
Peak computational performance is a measure of computational capability, usually defi ned as how many single-precision or double-precision fl oating point calculations can be processed per second. Peak performance is usually expressed in gflops (billion fl oating-point operations per second) or tflops (trillion fl oating-point calculations per second). Memory bandwidth is a measure of the ratio at which data can be read from or stored to memory. Memory bandwidth is usually expressed in gigabytes per second, GB/s. Table 1-1 provides a brief summary of Fermi and Kepler architectural and performance features.
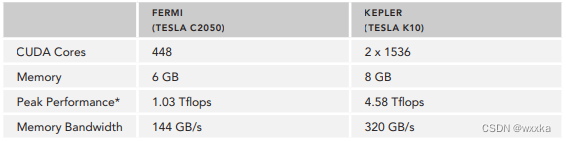
TABLE 1-1: Fermi and Kepler
截图:




排查错误,利用printf函数,输出,观察结果是否符合预期,在C++构造函数调用情况,多线程调试,CUDA C 中host和device数据交互传送及各自数据管理,都有具体应用,其他编程语言同理,排查错误,输出指定区域变量值,输出变量处理前后值,输出变量处理过程中的值的变化过程。















 1692
1692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









