







文章目录
利用Python实现爬虫,包括pandas库的read_html()方法、requests库和Scrapy库
我将通过理论结合实践去讲解一下内容,其中pandas库的read_html()方法将通过爬取基金重仓股-数据中心-新浪财经的列表数据;
其次request库将通过爬取豆瓣电影Top250结合BeautifulSoup库解析爬取的网页内容进行简单的统计分析;
最后,通过爬取
温馨提示:读者需要基础的python语言基础知识和web前端知识,本次工具选用的是JupyterLab notebook:
一、pandas库的read_html()方法
1.1.知识准备
read_html()的用法作用:快速获取在html中页面中table格式的数据
pd.read_html() 的一些主要参数
io:接收网址、文件、字符串
header:指定列名所在的行
encoding:The encoding used to decode the web page
attrs:传递一个字典,用其中的属性筛选出特定的表格
parse_dates:解析日期
注意:只是爬取table标签里面的数据,并放回很好的表格形式的数据,通过用Chrome浏览器检查html页面结构,页面通过有以下结构。
<table class="..." id="..." ...>
...
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
</tbody>
</table>
1.2.read_html()实践
爬取网址:http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml
代码如下:
import pandas as pd
df = pd.DataFrame()
for i in range(6):
url = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)
df = pd.concat([df, pd.read_html(url)[0]]) # 按行连接
print("第{page}页爬取成功!".format(page=i+1))
df.to_csv('./sina.csv', encoding='utf-8', index=0)
1.3.read_html()总结
当然你需要注意的是,你要针对不同的网址的特殊结构,设置不同的url,以完成各种各种网页翻页等数据的爬取,入上面代码中的p={page}.format(page=i+1)就是为了翻页功能。
二、requests库
2.1.requests知识准备
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
接下来,将重点讲解get方法和post方法
首先了解GET请求和POST的区别:
1.GET请求参数在请求行中,没有请求体
2.POST请求参数在请求体中
3.GET请求参数大小有限制,POST没有
2.1.1.get()基本语法
>>> import requests
>>> r=requests.get("http://baidu.com")
>>> r.status_code
200
# r 是一个Response对象,一个包含服务器资源的对象
# 返回200状态码表明爬取成功
2.1.2.get()参数
| 参数 | 说明 |
|---|---|
| params | url为基准的url地址,不包含查询参数;该方法会自动对params字典编码,然后和url拼接 |
| url | requests 发起请求的地址 |
| headers | 请求头,发送请求的过程中请求的附加内容携带着一些必要的参数 |
| cookies | 携带登录状态 |
| proxies | 用来设置代理 ip 服务器 |
| timeout | 用于设定超时时间, 单位为秒 |
2.1.3.post()基本语法
gg = input("gg")
url = "https://fanyi.baidu.com/sug"
data = {
"gg": gg,
}
headers = {
'User-Agent': "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 96.0.4664 .93 Safari / 537.36",
}
resp = requests.post(url=url, data=data, headers=headers)
print(resp.json())
2.1.4.post()参数
| 参数 | 说明 |
|---|---|
| data | 作为向服务器提供或提交资源时提交,主要用于 post 请求 |
| json | json格式的数据, json合适在相关的html |
2.1.5.response对象相关信息
| 属性 | 说明 |
|---|---|
| resp.status_code | http请求的返回状态,若为200则表示请求成功。 |
| resp.raise_for_status() | 该语句在方法内部判断resp.status_code是否等于200,如果不等于,则抛出异常 |
| resp.text | http响应内容的字符串形式,即返回的页面内容 |
| resp.encoding | http响应内容的字符串形式,即返回的页面内容 |
| resp.apparent_encoding | 从http header 中猜测的相应内容编码方式 |
| resp.content | http响应内容的二进制形式 |
| resp.json() | 得到对应的 json 格式的数据,类似于字典 |
2.2.requests实践
爬取网址:https://movie.douban.com/top250
代码如下:
#导入库包
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
# url='https://movie.douban.com/top250'
movie_name = []
movie_url = []
movie_star = []
movie_star_people = []
movie_director = []
movie_actor = []
movie_year = []
movie_country = []
movie_type = []
for i in range(10):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.62'
}
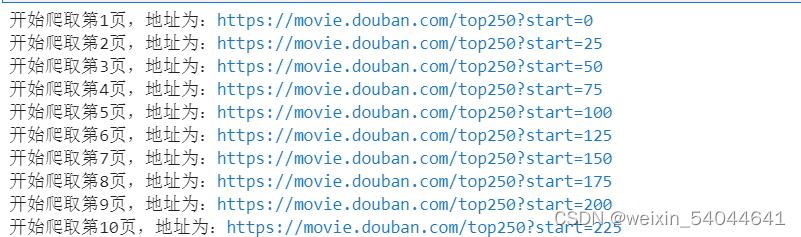
url = 'https://movie.douban.com/top250?start={}'.format(str(i*25))
print('开始爬取第{}页,地址为:{}'.format(str(i+1),url))
res = requests.get(url=url,headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
sleep(1)
for movie in soup.select('.item'):
name = movie.select('.hd a')[0].text.replace('\n', '') # 电影名称
movie_name.append(name)
url = movie.select('.hd a')[0]['href'] # 电影链接
movie_url.append(url)
star = movie.select('.rating_num')[0].text # 电影评分
movie_star.append(star)
star_people = movie.select('.star span')[3].text # 评分人数
star_people = star_people.strip().replace('人评价', '')
movie_star_people.append(star_people)
movie_infos = movie.select('.bd p')[0].text.strip() # 导演、主演,年份,国家,类型
director = movie_infos.split('\n')[0].split(':')[1]
director = director.replace('主演','')
movie_director.append(director)
try: # 页面既有导演,又有主演
actor = movie_infos.split('\n')[0].split(':')[2]
movie_actor.append(actor)
except:
movie_actor.append(None)
if name == '大闹天宫 / 大闹天宫 上下集 / The Monkey King':# 大闹天宫,特殊处理
year0 = movie_infos.split('\n')[1].split('/')[0].strip()
year1 = movie_infos.split('\n')[1].split('/')[1].strip()
year2 = movie_infos.split('\n')[1].split('/')[2].strip()
year = year0 + '/' + year1 + '/' + year2
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[3].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[4].strip()
movie_type.append(type)
else:
year = movie_infos.split('\n')[1].split('/')[0].strip()
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[1].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[2].strip()
movie_type.append(type)
# 将爬取并解析好的网页内容写入DataFrame里面
df = pd.DataFrame()
df['电影名称'] = movie_name
df['电影链接'] = movie_url
df['电影评分'] = movie_star
df['评分人数'] = movie_star_people
df['导演'] = movie_director
df['主演'] = movie_actor
df['上映年份'] = movie_year
df['国家'] = movie_country
df['类型'] = movie_type
# 写入Excel表
df.to_excel('电影top250_2.xlsx',encoding = 'utf_8_sig')
结果
2.3.requests总结
1.值得注意的是,笔者只是参考其他博主把整个爬取过程写了下来,也许您看来会很乱,希望笔者仔细阅读,并对代码进行优化,如各每一步进行分割成不同函数(爬取部分,解析网页部分,存入Excel部分)。
2.关于BeautifulSoup 库解析网页解析部分,需要笔者自己去学习,这里限于篇幅不加以赘述,可点击该网址:python之BeautifulSoup库
3.关于不同网页的HTML细节,该如何解析网页获得自己想要的数据和分割得到数据,还是需要读者慢慢去观察。
2.4.电影信息简单的统计分析(可视化)
关于数据清洗 检查是否有重复值、缺失值和异常值并处理,省略
#读入数据
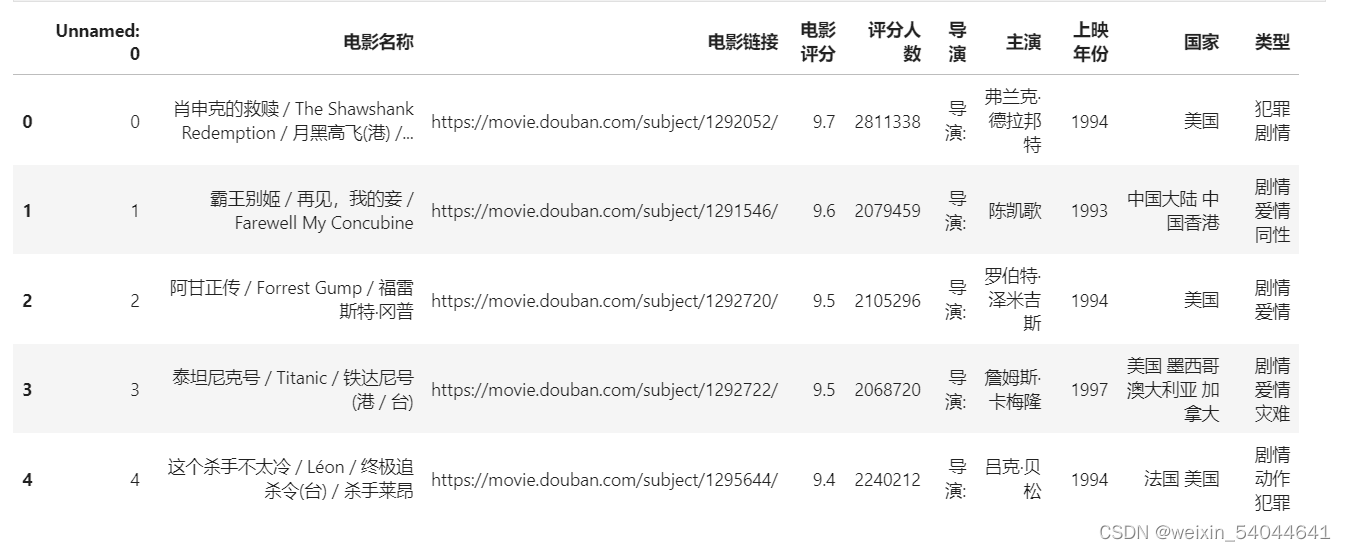
movie_df = pd.read_excel('电影top250_2.xlsx',header = 0)
display(movie_df.head())
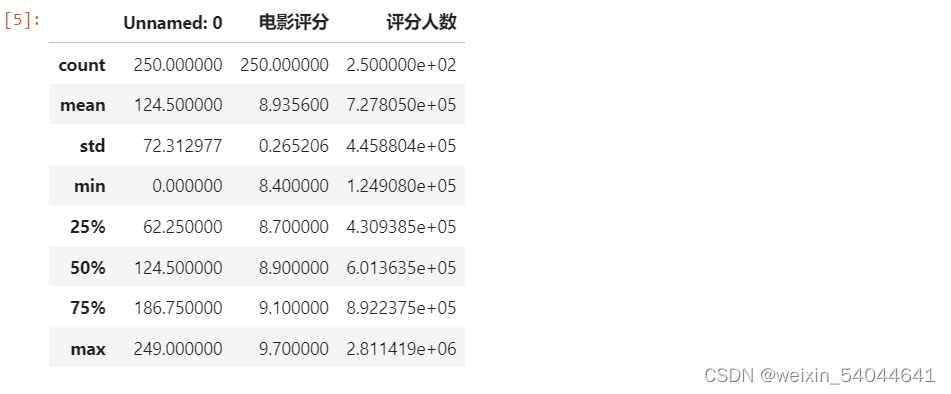
#描述性信息
display(movie_df.describe())
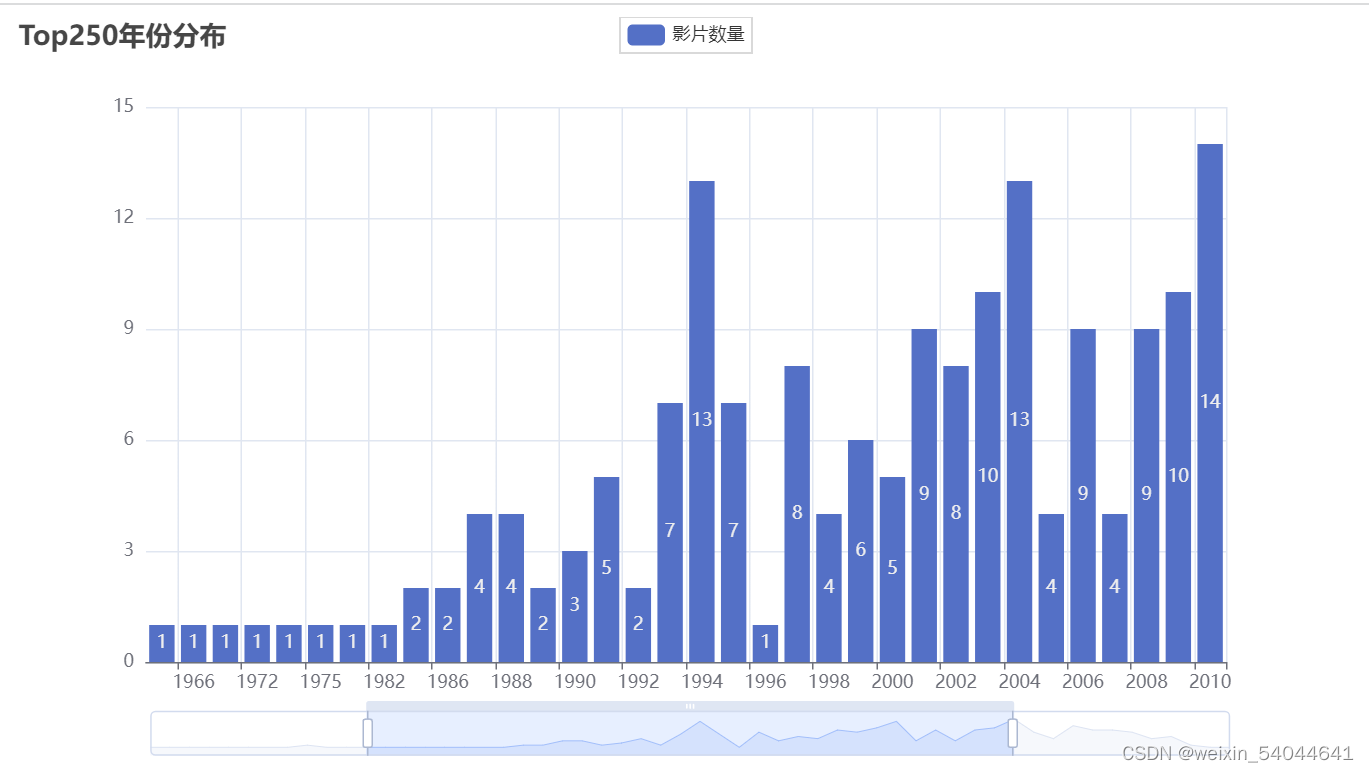
2.4.1.上映年份分布
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
df = movie_df
x1 = list(df["上映年份"].value_counts().sort_index().index)
y1 = list(df["上映年份"].value_counts().sort_index().values)
y1 = [str(i) for i in y1]
c1 = (
Bar()
.add_xaxis(x1)
.add_yaxis("影片数量", y1)
.set_global_opts(
title_opts=opts.TitleOpts(title="Top250年份分布"),
datazoom_opts=opts.DataZoomOpts(),
)
.render("1.html")
)
结果:
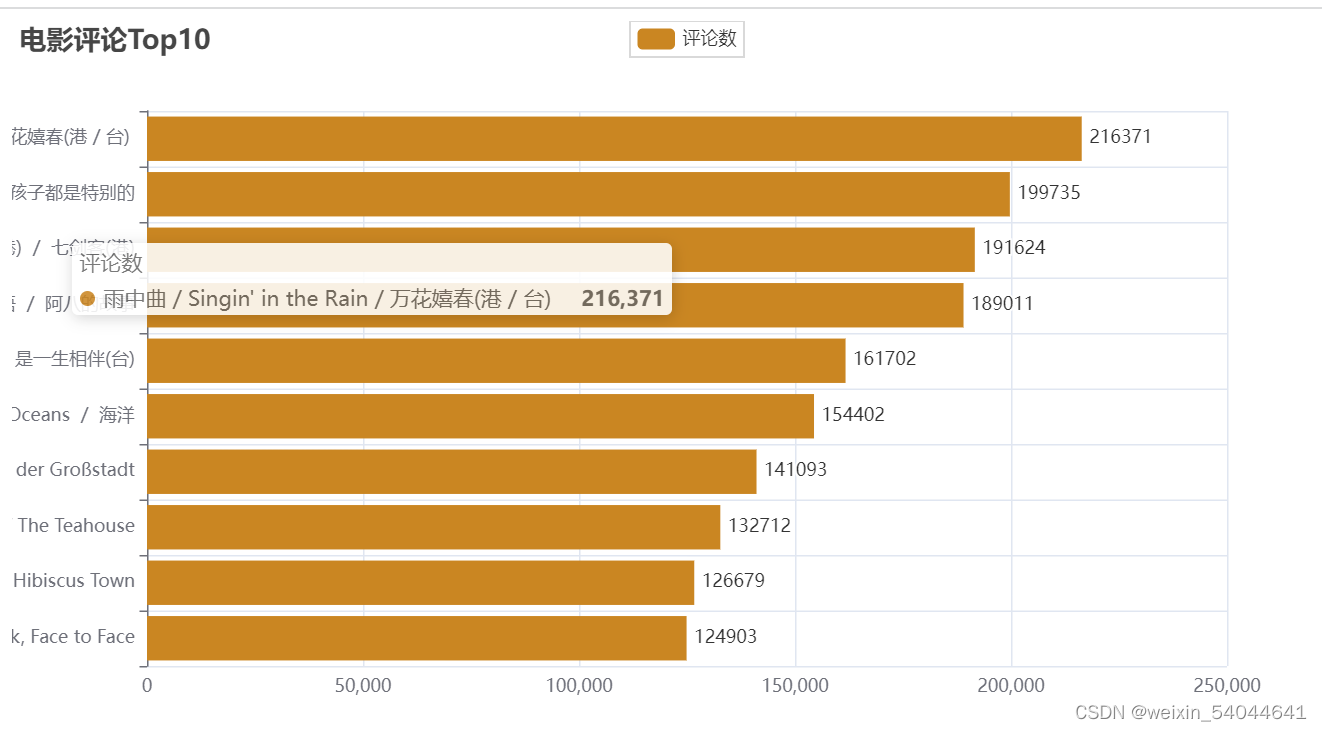
2.4.2.评论人数TOP10
df1 = df.sort_values(by = '评分人数')
c2 = (
Bar()
.add_xaxis(df1["电影名称"].head(10).to_list())
.add_yaxis("评论数", df1["评分人数"].head(10).to_list(),color=Faker.rand_color())
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="电影评论Top10"))
.render("2.html")
)
2.4.2.电影类型词云
简单统计处理
from collections import Counter
colors = ' '.join([i for i in df['类型']]).strip().split()
c = dict(Counter(colors))
#处理异常值
d = c.pop('1978(中国大陆)')
c
from os import path
import imageio
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
#设置词云函数
wc = WordCloud(
font_path='C:/Windows/Fonts/STXINGKA.TTF',
max_font_size=150,
random_state=42,
background_color = "white"
)
#导入词频字典格式
wc.generate_from_frequencies(c)
#绘制字体为颜色的图片
plt.imshow(wc.recolor())
plt.axis("off")
plt.show()
结果:

总结:读者可以继续进行分析,选择自己喜欢的字段进行分析,如可以分析导演排名图,上映国家占比图,电影评分分布散点图,电影评分与评分人数之间的关系等等。
2.5.补充:网络图片的爬取
import requests
import os
url = "https://imgcps.jd.com/ling-cubic/ling4/lab/amZzL3QxLzQ5MTQzLzI4LzE3MDM2LzIxOTg4OS82MTM4NDhkNkU2MDY1ZWM5OC9iM2I4ZWE1ODE5MmQzNmI0LnBuZw/5Lqs6YCJ5aW96LSn/5L2g5YC85b6X5oul5pyJ/1635183804528672769/cr/s/q.jpg"
root = "D://"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
三、Scrapy库
3.1.Scrapy知识准备
Scrapy一站式解决了Requests库和BeautifulSoup库两个库所做的工作;并且完善了爬虫调度流程,简化了数据爬取任务。
后续再更新…















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









