






 本文介绍了如何使用Python的requests库从网易云音乐网站抓取歌曲数据,包括获取真实网址、发送POST请求获取歌曲资源,并将音乐文件下载到本地的过程。作者展示了通过网络请求和XPath解析来实现音乐下载的详细步骤。
本文介绍了如何使用Python的requests库从网易云音乐网站抓取歌曲数据,包括获取真实网址、发送POST请求获取歌曲资源,并将音乐文件下载到本地的过程。作者展示了通过网络请求和XPath解析来实现音乐下载的详细步骤。
选取目标:
打开目标网址
https://music.163.com/----网易云网页版
搜索要爬取得数据
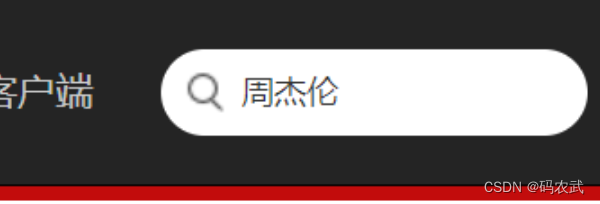
查找当前页面网址:
右键---检查---network
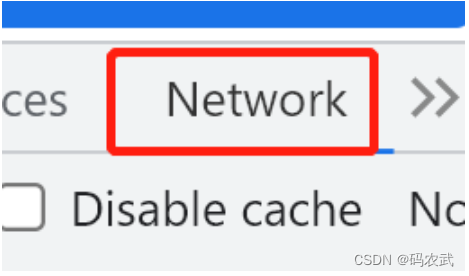
刷新页面---找到网址所在的位置:

找到真实网址:

赋值爬取目标地址,存储到程序里面

借助requests工具请求目标地址
安装requests模块
pip install requests
导入requests模块

查看请求方式:

借助requests工具,请求目标地址
查找携带资源:
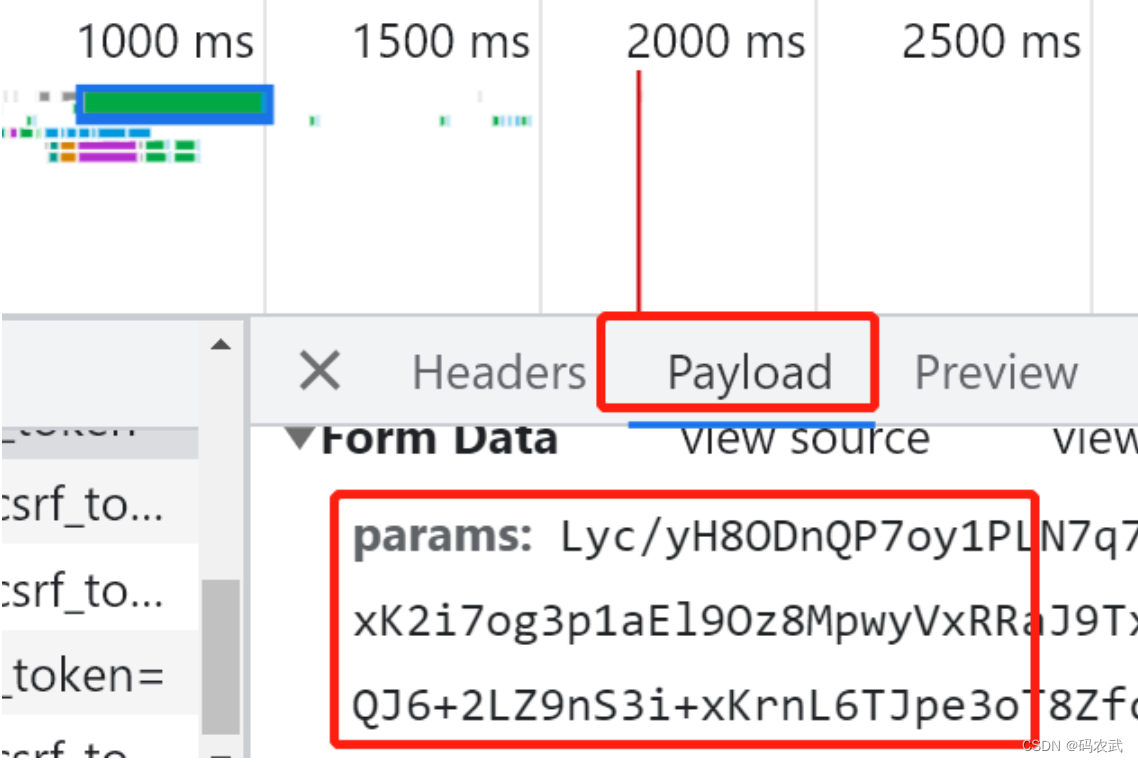
需要限制返回数据的格式:
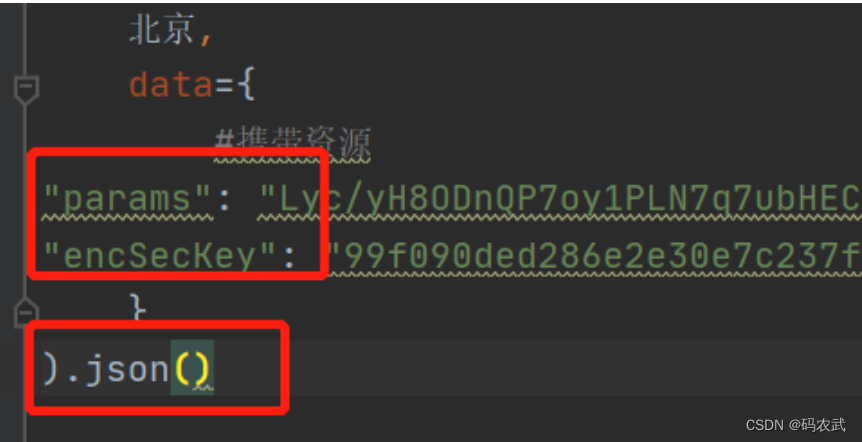
输出观察响应内容:
import requests
url = 'https://music.163.com/weapi/cloudsearch/get/web?csrf_token='
response = requests.post(
url,
data={
"params": "yfsK+MFOtMnAYOanVfbAsbybflSRebz9nBMuPk02kivvlAr23JROV1CZT9J4yZC2zeVwcBsUGWmqn1xHHg6WnezSGVPGnaLGSdnJdBDjhNPxA6TeCetfmMiaKh04xhLhxGWj4dDuEnNnqav20gAtpZA86wSrNIXKfz7pYPa3O4ISWypmcpHkbHFPAQhi5iBWnhprHrl8gFX2LnypO4x8XtqxWk+hzL4lF1Ua+8l6YHiDe5FUukEjR2YMhy5OjjBpLDzhD8nh0kwWO7/tJmxVYQ==",
"encSecKey": "3b6ea5ac36688247bfbb04517d6fb4fbd5958f8cd0b701be15aab32b58b3df8dbe36446dde379074a1b3076c80d54bc592c9f9e963a2c4d274617c7167a120a137a2fc2eacb80bba0188af8b1f06ed83faa556879db730a7bf5bf601e293b1a5645527285330ce8ac23de7926f94a2b1899718ccb6b2a38cef57519ed4378094"
}
).json()
#观察响应内容
#print(response)
#筛选内容
result = response['result']['songs']
#通过播放地址替换Id观察会员和非会员音乐的区别
#https://music.163.com/song/media/outer/url?id={}.mp3
for i in result:
name = i['name']
music_id = i["id"]
print(name,music_id)
url1 = "https://music.163.com/song/media/outer/url?id={}.mp3".format(music_id)
mp3 = requests.get(url1).content
with open("music/"+name+".mp3","wb")as f:
f.write(mp3)
print("下载完成!")
自己的代码:
"""
程序实现的思路:
1.下载歌曲从哪里来的? 网易云音乐网站的服务器下载下来的
2.怎么从网址中获取歌曲? 第三方请求库向网址发送网络请求 获取歌曲
3.筛选从网页中获取数据 保留歌曲数据 其他的丢掉
4.保存音乐数据为音乐文件 文件操作保存
"""
import time
import requests
from lxml import html
import time
etree=html.etree
proxies = {'http': None, 'https': None}
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'https://music.163.com/'
}
singer_url = input("请输入你要下载的歌手页的链接")
url = singer_url.replace('/#','')
resp = requests.get(url=url,headers= header,proxies=proxies)
html = etree.HTML(resp.text)
music=html.xpath('//a[contains(@href,"/song")]')
for music in music:
href= music.xpath('./@href')[0]
music_id = href.split('=')[1]
music_name = music.xpath('./text()')[0]
print(music_id)
music_url = 'https://music.163.com/#/song?id='+music_id
# 在请求之间添加延迟
time.sleep(5) # 5秒的延迟,具体延迟时间可以根据需要调整
music1=requests.get(music_url,headers=header,proxies=proxies)
print(music1.content)
with open('./music/%s.mp3'%music_name,'wb')as file:
file.write(music1.content)
print('<%s>下载成功'%music_name)
能爬取一首歌的代码:
import time
import requests
from lxml import html
etree=html.etree
proxies = {'http': None, 'https': None}
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'https://music.163.com/'
}
music_url = 'http://m701.music.126.net/20240111210020/12db14c0e132ae282f12dde73dd7fc5d/jdymusic/obj/wo3DlMOGwrbDjj7DisKw/32407773353/f8a6/1163/aa19/7065abd5982bf7c5d91717d17036e05a.mp3'
# 在请求之间添加延迟
music_name='一首歌'
time.sleep(5) # 5秒的延迟,具体延迟时间可以根据需要调整
music1=requests.get(music_url,headers=header,proxies=proxies)
print(music1.content)
with open('./music/%s.mp3'%music_name,'wb')as file:
file.write(music1.content)
print('<%s>下载成功'%music_name)
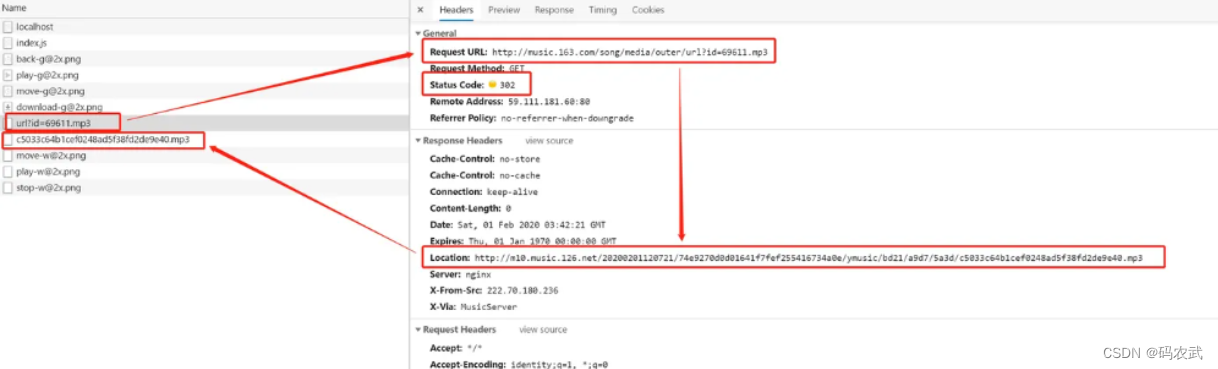
正确下载一首歌曲的方式:(仅限于可以生成外部链接的歌曲)
找真正的地址:
选择一首可以生成外部链接的歌曲

打开开发工具:
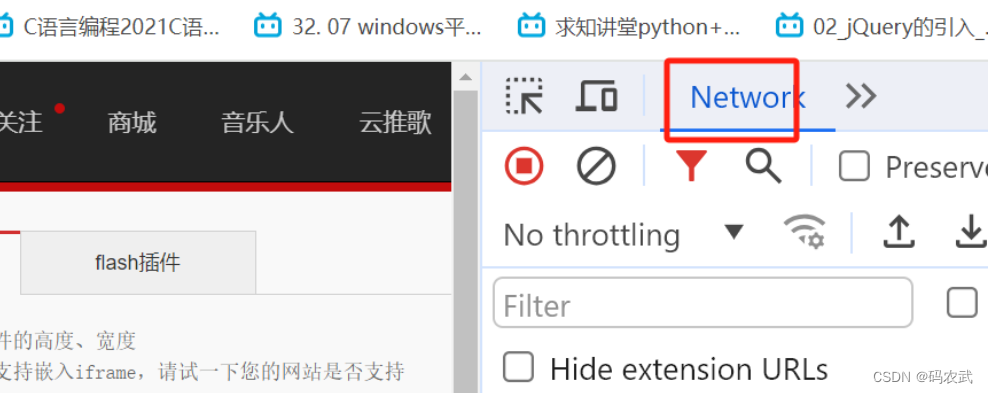
刷新页面
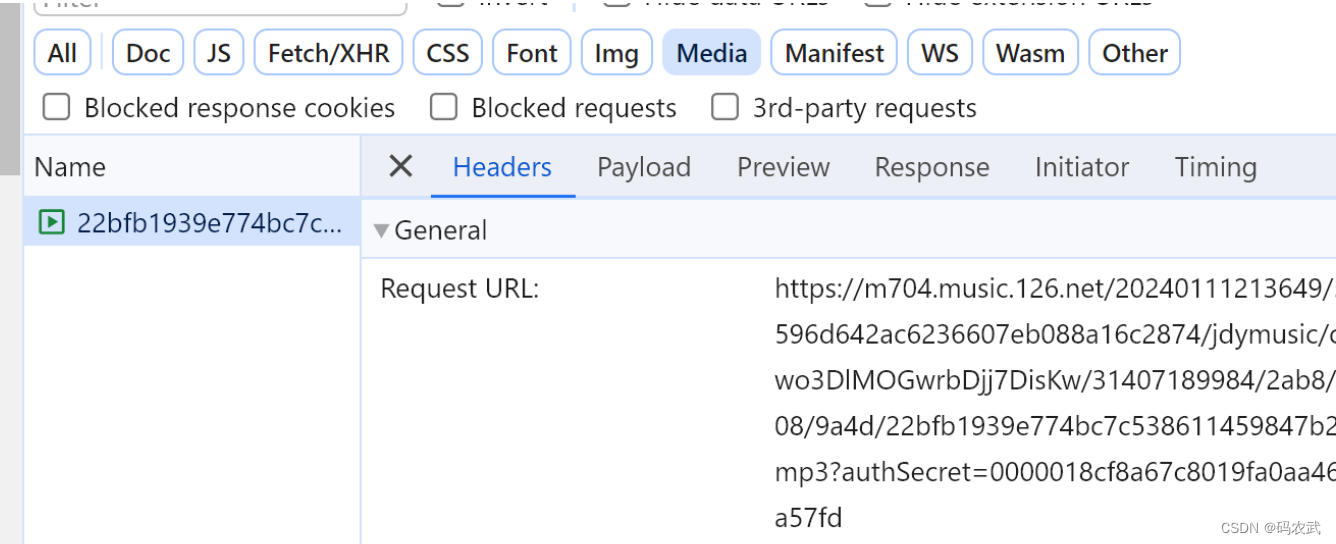
找到真实地址:正常爬取

















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











