






HTTP的请求和响应
General 全部的
1.Request URL 请求的地址
2.Request Method 请求的方式(get post)
3.Response Headers 服务器的响应
Request Headers 服务器的请求
1.Host:(主机和端口号)对应的网址
2.Connection:(链接类型)
3.User-Agent:用户代理
4.Accept:(传输文件的类型)
5.referer:(页面的跳转处)
6.Cookie:(记录了用户相关的信息)
7.Query String Paramerers 请求地址的的参数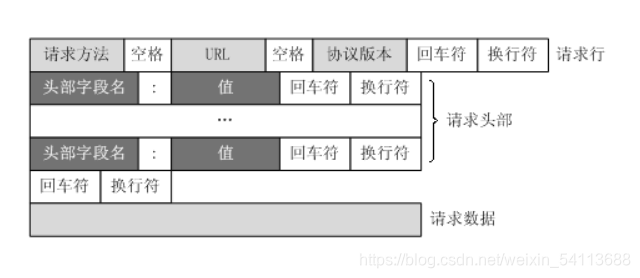
















 5468
5468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









