






190. 栈和堆在内存管理上的区别
-
栈
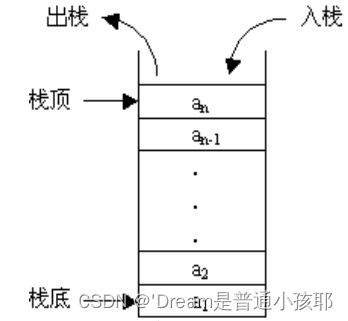
1) 栈是由系统自动分配和回收的内存。
2)栈的存储地址是由高地址向低地址扩展的。
3)栈是一个先进后出的结构。
4)栈的空间大小是一个在编译时确定常数,即栈的大小是有限制的,当申请的空间大小超限时会提示overflow。
5) 栈:就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
6) 栈可以视为一个临时存储空间,这种临时存放数据的特性,使得它经常用来存储局部变量,函数参数,上下文环境等。
7)栈的效率比较高:计算机分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。
-
堆
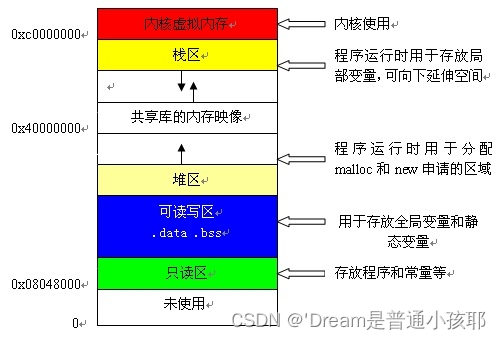
1)堆区是向上生长的用于分配程序员申请的空间。
2)在操作系统中有记录空闲内存地址的链表(也有可能是位图等其他方式),当系统受到程序的申请时就会遍历该链表寻找第一个大于该申请空间堆(假设是FIFS,当然也有可能是其他的如段进程优先等),然后将该节点从链表中删除,并将该节点的空间分配给程序;另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。若找到的堆节点的空间大小大于所申请的空间,则系统会自动将多余的空间重新放入空闲链表中,也就是说堆在进行空间分配后还要做一些后续工作就会引入效率问题。
3)栈是系统自动申请和释放的,而堆更加强调的是手动控制,需要手动申请和释放空间。
4)堆可分配的空间更大,但是也有较大的开销。
5)堆是在程序执行的过程中动态分配的,它最大的特性就是动态性。堆就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
-
其他存储区
1) 静态存储区
静态变量和全局变量都存储于静态存储区。
2)常量存储区
这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。
常量字符串都存放在静态存储区,返回的是常量字符串的首地址。
- 堆和栈的比较
- 数据结构中的堆和栈
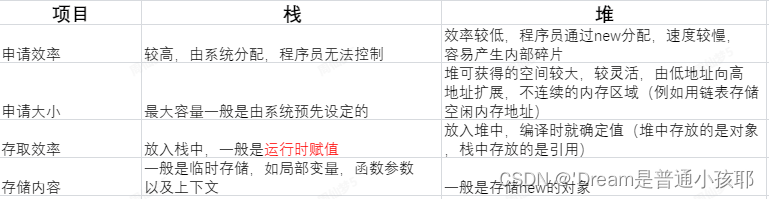
1)栈
① 栈是先进后出的数据结构
② 是一种运算受限的线性表
③ 只能够在栈顶进行插入和删除元素(栈顶即高地址位置)
2)堆
① 通常可以被看作一棵树的数组对象
② 堆中某个结点的值总是不大于或不小于其父结点的值;
③ 堆总是一棵完全二叉树。
191. 完全二叉树和二叉树的区别 以及在使用上的优劣
参考:完全二叉树和满二叉树
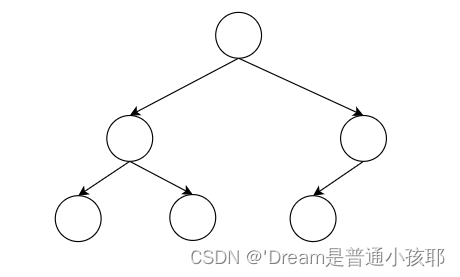
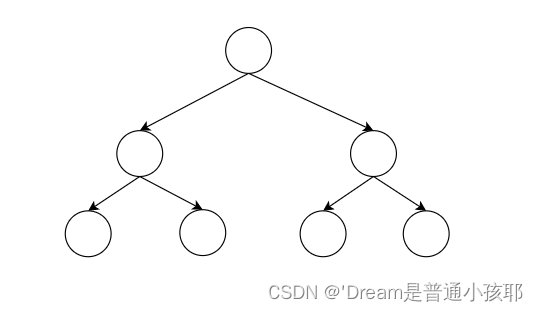
- 完全二叉树
1)除了最后一层外,每一层的节点都被填满。
2)如果最后一层存在节点,那么这些节点从左到右依次填充,不留空缺。
3)完全二叉树的高度通常较小,具有良好的平衡性。
4)完全二叉树在堆数据结构中广泛应用,如二叉最小堆和二叉最大堆,堆排序和优先级队列等。
-
满二叉树
1)满二叉树是特殊的完全二叉树
2)所有层的节点都被填满。
3)满二叉树的高度是固定的,由节点数量决定。
4)满二叉树在一些特定的数据存储和检索算法中有用,但相对较少见。
-
最优二叉树
1)最优二叉树,也叫哈夫曼树,是指带权路径长度最小的二叉树。在哈夫曼树中,带权路径长度等于树中所有叶子节点的权值乘以它们到根节点的路径长度之和。在构造哈夫曼树的过程中,节点的权值越大,它距离根节点就越近。
2)完全二叉树的构造不需要根据节点权值来确定,而是按照深度优先的原则,一层一层从左到右地填充节点。最优二叉树的构造则是基于贪心算法,按照节点权值从小到大的顺序来构造。
3)完全二叉树中,任何一个节点的左右子节点,如果存在,一定是连续的;而最优二叉树中,同一个节点的左右子节点可能会不连续。
4)最优二叉树则更多地用于信息编码和压缩等领域,比如哈夫曼编码。 -
完全二叉树在存储和定位节点上具有优势,但在插入和删除节点时可能会增加复杂度。
① 完全二叉树可以使用数组来表示,不需要使用指针来表示节点之间的关系,节省了存储空间
② 使用数组的下标可以快速定位到某个节点
③ 插入和删除节点时需要将其调整成完全二叉树,调整的过程会增加操作的复杂度。 -
二叉树不适合存储规模太大的数据(结构相对复杂),且会出现不平衡现象使得插删查操作减慢;另外,二叉树的存储需要额外的指针来连接节点,占用了额外的空间。
192. 哈希表的底层原理
参考:哈希表机器底层原理
1)哈希表(Hash Table)是一种常用的数据结构,用于实现键值对映射关系。它支持在平均常数时间内进行插入、删除和查找操作
2)哈希表的底层原理是将每个键(key)通过一个哈希函数(Hash Function)转换成一个索引(index),然后将该键值对存储在对应索引的位置上。当需要查找一个键值对时,再通过哈希函数计算出该键对应的索引,并在该索引位置上查找该键值对,从而实现快速查找。即:f表示哈希函数,而将key作为其参数来计算f(key)索引位置,将value存储到该位置上
3)哈希函数通常是将键值映射到一段固定长度的数字串,这个数字串可以看做是该键的指纹(fingerprint),可以用来唯一地标识该键。一个好的哈希函数应该能够尽量避免键的碰撞(Collision),即不同的键映射到同一个索引上的情况,否则会影响哈希表的性能。
4)为了解决碰撞问题,哈希表通常采用开放地址法(Open Addressing)或链地址法(Chaining)等方法来解决。在开放地址法中,当发生碰撞时,会继续往下一个空闲位置插入,直到找到一个空闲位置;而在链地址法中,每个索引位置上存储的是一个链表,当发生碰撞时,会将新的键值对添加到链表的末尾。
193. Linux的软连接和硬链接
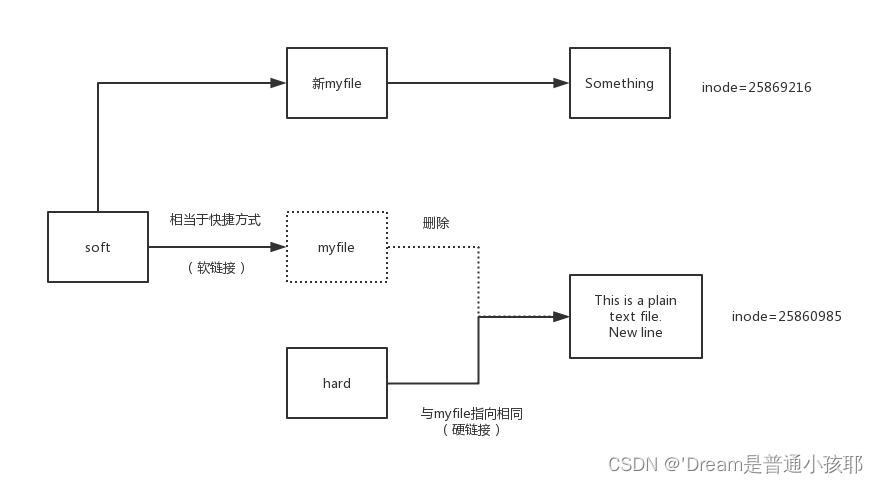
在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号inode 。
-
软连接
1)软连接其实就类似于咱们的快捷方式
2)每次软连接都是建立一个新的inode,文件的内容是指向源文件的指针
3)当源文件被删除,软连接就会找不到该文件或目录
4)软连接的建立: ln -s [filename] soft
5)当源文件不存在时也是可以建立软连接的 -
硬链接
1)硬链接必须源文件和inode存在,并且时共享一个inode,只是增加了连接数
2)当删除源文件的时候,只要硬链接的数量大于等于1就不会真正删除源文件
3)硬链接不可以跨文件系统
4)硬链接相当于是给文件创建了一个别名,同一个inode说明是同一个文件
5)硬链接的建立:ln [filename] hard
194. 产品上线之后应该关注哪些问题
1)上线前进行回归测试,保证主流程的流通性
2)上线后进行灰度测试:使用少量的数据将所有的业务流程走完,保证数据的正确性和流程的畅通完整性
3)上线之后还要进行监控和故障排查,确保系统的稳定性和可靠性
4)还要收集用户的反馈,可用于进行下一次的迭代
195. 刷卡、输密码、取款、余额查询以及取卡操作就功能、性能、安全性、易用性、弱网以及高并发设计测试用例
196. Java会存在内存泄漏问题吗?如果存在内存泄漏,怎么进行排查?
1)内存泄漏原因:
静态集合类引用(长生命周期持有短生命周期对象)、资源未关闭或释放(数据库连接、网络连接等)、不正确的equals和hashCode方法(如HashMap和HashSet集合中)、重写finalize()的类(finalize被重写侯GC会将其排队等待最后确定,若重写不合理或者finalizer队列无法跟上GC的速度)、ThreadLocal(提供线程本地变量,保证访问的变量是当前线程的,在每个线程中创建变量的副本,但是线程池有线程复用,只要ThreadLocal不标识删除则改变量副本不会被GC)、死循环、一次从数据库取出大量数据、第三方软件中有bug
2)排查内存泄漏:OutOfMemory Error
监控内存:比如使用jconsole观察内存的分配以及使用情况,若有突然升高,定位时间点结合日志
内存分析:比如使用MAT对程序进行分析,查找可能存在的内存泄漏对象和问题代码,帮助进行定位
检查代码:对对象的生命周期、资源的连接释放、循环等进行查看分析
监控GC日志:对对象的创建、销毁和回收,找到可能存在内存泄漏的问题
性能测试:进行压测,模拟真实环境,观察是否存在内存泄漏问题
197. 线程是如何共享资源的?
1)互斥锁(Mutex):互斥锁是一种最常见的线程同步机制,它可以确保在同一时间只有一个线程可以访问共享资源。当一个线程获得了互斥锁后,其他线程必须等待该线程释放锁才能访问共享资源。
2)信号量(Semaphore):信号量是一种计数器,用来控制对共享资源的访问。它可以允许多个线程同时访问共享资源,但需要限制同时访问的线程数量。
3)条件变量(Condition Variable):条件变量用于在线程之间进行通信和同步。它允许一个线程等待某个条件满足后再继续执行,而不是忙等待。条件变量通常与互斥锁一起使用,以确保在等待条件时不会发生竞争条件。
4)原子操作(Atomic Operation):原子操作是一种不可分割的操作,可以保证在多线程环境下对共享资源的操作是原子的。原子操作可以通过硬件支持或者特殊的指令来实现,它可以避免竞争条件和死锁等问题。
5)读写锁(Read-Write Lock):读写锁允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种方式可以提高读取操作的并发性能。
Ps. 忙等待:循环检测条件是否满足,不满足则继续等待,满足则执行后续操作。这样子会占用CPU资源。
















 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











