






1. 黑盒测试方法
黑盒测试:关注的是软件功能的实现,关注功能实现是否满足需求,测试对象是基于需求规格说明书。
1)等价类:有效等价类、无效等价类
2)边界值
3)因果图:不同的原因对应不同的结果
4)错误猜测:根据经验
5)场景设计
6)正交实验法:状态表、分析表
7)判定表:不同原因不同选择组合,如A原因选N、B原因选Y,组合结果为GO
2. 白盒测试方法
白盒测试关注程序内部逻辑的实现,白盒测试的测试对象是基于被测试程序的源代码。
1)语句覆盖:设计足够的测试用例,使得被测程序中每条语句至少执行一次
2)条件覆盖:使得每一个判定获得每一种可能的结果至少一次
3)判定覆盖:使判定语句中的每个逻辑条件取真值与取假值至少出现一次
4)判定条件覆盖:使得判定语句中所有条件的可能取值至少出现一次,同时,所有判定语句的可能结果也至少出现一次
5)条件组合覆盖:使得每个判定中条件的各种可能组合都至少执行一次
6)路径覆盖:设计足够的测试用例,使得程序中的每一条可能组合的路径都至少执行一次
3. 黑盒测试和白盒测试的区别
1)黑盒测试主要针对的是程序展现给用户的功能,而白盒测试则是主要针对程序的代码逻辑。前者测试最终功能,而后者测试后台程序。
2)测试方法不同
3)黑盒测试以规格需求说明书作为参考依据,而白盒测试需要以规格需求说明书以及程序设计文档等作为参考依据
无论采用哪种测试方法,毫无疑问都是为了找出缺陷,发现风险,从而确保软件的缺陷更少,质量更好。
4. 性能测试主要指标
-
以前后端的角度看
1)前端:
响应时间、加载速度、消耗的流量
2)后端:
响应时间(关注接口)、并发用户数、内存占用、吞吐量(每秒事务数,在没有遇到性能瓶颈时:TPS=并发用户数*事务数/响应时间)、错误率、资源使用率(CPU占用率、内存使用率、磁盘I/O、网络I/O) -
以测试分析角度看
1)系统性能指标:
响应时间、系统处理能力(HPS每秒点击次数、TPS每秒处理交易次数、QPS系统每秒处理查询次数)、吞吐量、并发量、错误率
2)资源性能指标
CPU(用户态、系统态、等待态、空闲态)、内存、磁盘吞吐量、网络吞吐量
3)稳定性能指标
最短稳定时间:系统按照最大容量的80%或标准压力(系统的预期日常压力)情况下运行,能够稳定运行的最短时间。
5. 测试用例万能公式
-
万能公式
功能+性能+界面+兼容性+容错性+安全性+易用性+弱网+安装/卸载 -
黑盒测试
1)功能测试:
(展示)① 排版正常,不出现缺失、重叠等现象; ② 图片正常展示,无明显拉伸; ③ 字体大小样式展示正确,过长截断; ④ 点击跳转正常; ⑤ 用户滑动无卡顿; ⑥ 加载更多无重复
(功能)① 账户在登录和非登录状态下的操作; ② 用户在缺失经纬度时的距离展示; ③ 用户重复操作的结果; ④ 数量的更新; ⑤ 达到上限后需求的下线; ⑥ 时间点等条件的限制
2)性能测试:
① CPU
② 内存占用
③ 耗流量
④ 低配置设备的体验效果
⑤ 弱网测试
⑥ 压测后的QPS、HPS、TPS
⑦ 并发
⑧ 吞吐
⑨ 错误率 -
白盒测试
1)功能测试:
① 正向功能
② 参数不存在
③ 参数为空
④ 参数类型不匹配
⑤ 参数取值:边界值
⑥ tooken无效
⑦ 参数格式不正确
2)性能测试:
① 压力测试:系统在极限压力下的处理能力
② 狭义性能测试:系统能够达到的处理能力
③ 并发测试:测试数据库和应用服务器对并发请求的处理能力
3)安全性测试:
① 伪造tooken攻击
② SQL注入攻击
③ 循环遍历id
4)其他:
同一用户提交的参数信息完全一致,返回结果应该是同一个
6. 如何测试一个post请求方式,参数是String、int的接口
POST方法提交数据给服务器,涉及到Content-Type和消息主体编码方式两部分。服务器根据请求头中的Content-Type来判断消息主体的数据格式和编码方式,数据则存储在body参数中上传。
其实主要考虑以下几点:
① 请求方式
② 无参传入
③ 参数为空
④ 参数类型不匹配
⑤ 参数边界值
⑥ body的格式类型
⑦ tooken无效
⑧ sql注入
⑨ 性能测试:极限压力处理能力、一定的处理能力、并发请求
⑩ 伪造tooken等
7. 事务隔离级别
事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)四个特性。
1. 事务隔离级别要实际解决的问题
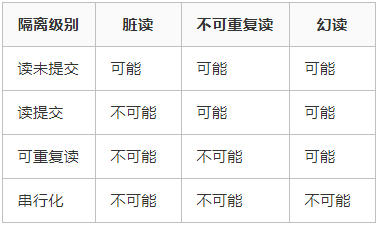
1)脏读:指的是读到了其他事务未提交的数据,即最终不一定存在的事务
2)可重复读:可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据都是一致的。通常针对数据更新(UPDATE)操作
3)不可重复读:对比可重复读,不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响,比如其他事务改了这批数据并提交了。通常针对数据更新(UPDATE)操作。
4)幻读:幻读是针对数据插入(INSERT)操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉,这就叫幻读。
2. 事务隔离级别
1.)SQL 标准定义了四种隔离级别,MySQL 全都支持。这四种隔离级别分别是:
读未提交(READ UNCOMMITTED)
读提交 (READ COMMITTED)
可重复读 (REPEATABLE READ)
串行化 (SERIALIZABLE)
从上往下,隔离强度逐渐增强,性能逐渐变差。采用哪种隔离级别要根据系统需求权衡决定,其中,可重复读是 MySQL 的默认级别。
2)修改隔离级别的语句是:set [作用域] transaction isolation level [事务隔离级别]
举个栗子:下面这个语句的意思是设置全局隔离级别为读提交级别。
mysql> set global transaction isolation level read committed;
3)具体可以参考:MySQL事务隔离级别和实现原因
8. 三次握手四次挥手
参考:TCP三次握手四次挥手
1. 三次握手
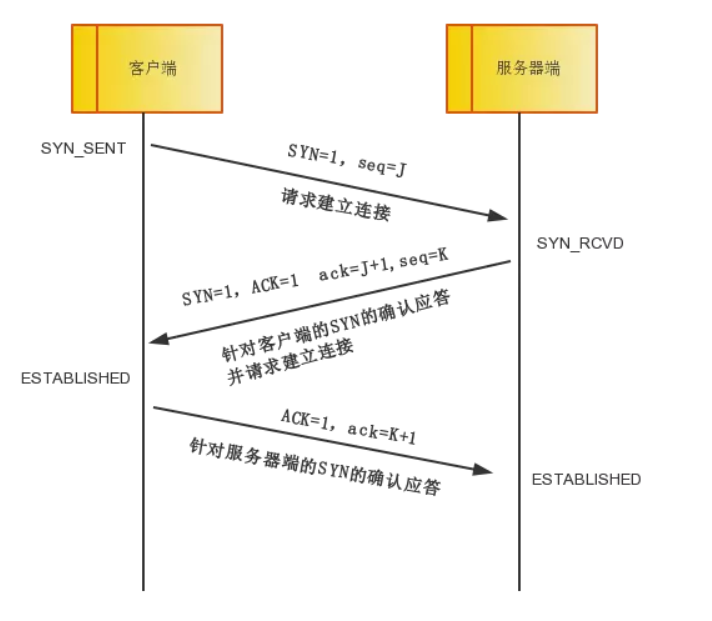
注意:我们上面写的ack和ACK,不是同一个概念:
- 小写的ack代表的是头部的确认号Acknowledge number, 缩写ack,是对上一个包的序号进行确认的号,ack=seq+1。
- 大写的ACK,则是我们上面说的TCP首部的标志位,用于标志的TCP包是否对上一个包进行了确认操作,如果确认了,则把ACK标志位设置成1
2. 四次挥手
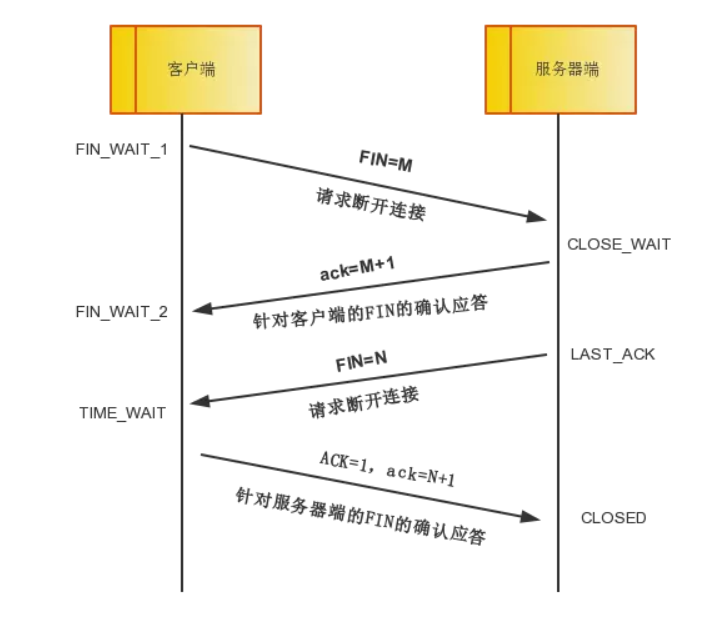
在第四次挥手时,Client端向Server端发送标志位是ACK的报文段,然后Client端进入TIME_WAIT状态。此时,Client端等待2MSL的时间后依然没有收到回复,则证明Server端已正常关闭,那好,Client端也可以关闭连接了。
3. 为何三次握手四次挥手
1)建立连接时因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。所以建立连接只需要三次握手。
2)由于TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议,TCP是全双工模式。这就意味着,关闭连接时,当Client端发出FIN报文段时,只是表示Client端告诉Server端数据已经发送完毕了。当Server端收到FIN报文并返回ACK报文段,表示它已经知道Client端没有数据发送了,但是Server端还是可以发送数据到Client端的,所以Server很可能并不会立即关闭SOCKET,直到Server端把数据也发送完毕。当Server端也发送了FIN报文段时,这个时候就表示Server端也没有数据要发送了,就会告诉Client端,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
4. 四次挥手时,Client端为何要等待2MSL时间
MSL:报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。
1)保证TCP协议的全双工连接能够可靠关闭
由于IP协议的不可靠性或者是其它网络原因,导致了Server端没有收到Client端的ACK报文,那么Server端就会在超时之后重新发送FIN,如果此时Client端的连接已经关闭处于CLOESD状态,那么重发的FIN就找不到对应的连接了,从而导致连接错乱,所以,Client端发送完最后的ACK不能直接进入CLOSED状态,而要保持TIME_WAIT,当再次收到FIN的收,能够保证对方收到ACK,最后正确关闭连接。
2)保证这次连接的重复数据段从网络中消失
如果Client端发送最后的ACK直接进入CLOSED状态,然后又再向Server端发起一个新连接,这时不能保证新连接的与刚关闭的连接的端口号是不同的,也就是新连接和老连接的端口号可能一样了,那么就可能出现问题:如果前一次的连接某些数据滞留在网络中,这些延迟数据在建立新连接后到达Client端,由于新老连接的端口号和IP都一样,TCP协议就认为延迟数据是属于新连接的,新连接就会接收到脏数据,这样就会导致数据包混乱。所以TCP连接需要在TIME_WAIT状态等待2倍MSL,才能保证本次连接的所有数据在网络中消失。
9. 进程通信方式
参考:进程通信和线程通信
-
进程通信:
1)管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2)有名管道namedpipe:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
3)信号量semophore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
4)消息队列messagequeue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5)信号signal:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
6)共享内存shared memeory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC (其实交“网络摄像机”,是IP Camera的简称)方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
7)套接字socket:套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同设备及其间的进程通信。 -
线程通信:
1)锁机制:包括互斥锁、条件变量、读写锁
-互斥锁提供了以排他方式防止数据结构被并发修改的方法。
-读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
-条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
2)信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
3)信号机制(Signal):类似进程间的信号处理 -
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
10. 数组和链表
-
数组
1)在内存中,数组是一块连续的区间
2)数组需要预留空间:在编译阶段就需要确定数组的空间,在运行阶段不允许更改,对空间的利用率较低,会存在浪费空间的现象
3)在数组的起始位置,插入和删除元素的效率较低
4)随机访问效率较高,时间复杂度可以达到O(1) 【优点】
5)数组的空间在不够用时需要进行扩容,扩容时需要将旧数组中所有元素向新数组中搬移,浪费资源
6)数组的空间是从栈分配的 -
链表
1)在内存中,元素的空间是分散的,不需要连续的空间
2)链表中的元素都会有两个属性,一个是元素的值,一个是指针地址,用于找到下一个元素的位置
3)查找数据效率较低,时间复杂度为O(N),需要遍历查找
4)空间不需要提前申请,是动态申请的,空间利用率高
5)任意位置插入元素和删除元素效率较高,时间复杂度为O(1)
5)链表的空间是从堆中分配的 -
优缺点
1)数组
优点:随机访问效率高
缺点:① 头插/头删效率低,时间复杂度为O(N); ② 空间利用率不高; ③ 对内存空间要求高,必须又足够的连续内存空间; ④ 数组大小固定,不能动态扩展
2)链表
优点:① 任意位置插入和删除元素效率高,时间复杂度为O(1); ② 内存利用率高,不会浪费内存; ③ 空间大小不是固定的,可以动态扩展
缺点:随机访问效率低,时间复杂度为O(N) -
小结
对于想要快速访问,而不经常进行插入删除元素就选择数组;
对于需要经常插入删除元素,对随机访问的效率要求不是很高时选择链表
11. java多线程实现方式(未弄完)
多线程的形式上实现方式主要有两种,一种是继承Thread类,一种是实现Runnable接口。本质上实现方式都是来实现线程任务,然后启动线程执行线程任务(这里的线程任务实际上就是run方法)。
1)继承Thread类,重写run方法,调用strat才可以启动线程
package com.kingh.thread.create;
/**
* 继承Thread类的方式创建线程
*
* @author <a href="https://blog.csdn.net/king_kgh>Kingh</a>
* @version 1.0
* @date 2019/3/13 19:19
*/
public class CreateThreadDemo1 extends Thread {
public CreateThreadDemo1() {
// 设置当前线程的名字
this.setName("MyThread");
}
@Override
public void run() {
// 每隔1s中输出一次当前线程的名字
while (true) {
// 输出线程的名字,与主线程名称相区分
printThreadInfo();
try {
// 线程休眠一秒
Thread.sleep(1000);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
public static void main(String[] args) throws Exception {
// 注意这里,要调用start方法才能启动线程,不能调用run方法
new CreateThreadDemo1().start();
// 演示主线程继续向下执行
while (true) {
printThreadInfo();
Thread.sleep(1000);
}
}
/**
* 输出当前线程的信息
*/
private static void printThreadInfo() {
System.out.println("当前运行的线程名为: " + Thread.currentThread().getName());
}
}
2)实现Runnable接口,重写run
3) 使用匿名内部类,实现创建Thread子类的方式new Thread(){ … run(){}}.start();
4) 使用匿名内部类,实现 实现Runnable接口的方式
5) 使用Lambda表达式(lambda本质上是一个“匿名函数”)
(其实lambda表达式一般用于一个方法的实现上,该方法可以作为参数传入)
6) 使用线程池
7) 使用Callable(中间类FutureTask进行辅助,是获取结果的凭证)
可参考:多线程创建方式
12. 线程的run()和start()有什么区别?
注意:在启动线程的时候,并不是调用线程类的run方法,而是调用了线程类的start方法。那么我们能不能调用run方法呢?
答案是肯定的,因为run方法是一个public声明的方法,因此我们是可以调用的,但是如果我们调用了run方法,那么这个方法将会作为一个普通的方法被调用,并不会开启线程。这里实际上是采用了设计模式中的模板方法模式,Thread类作为模板,而run方法是在变化的,因此放到子类来实现。
1)run()方法
run() 方法是线程的主体,它是线程需要执行的方法,线程启动后会自动执行 run() 方法中的代码。run() 方法通常包含线程的执行逻辑,可以通过重写 run() 方法来实现自定义逻辑。
2)start()方法
start() 方法是线程的启动方法,它是一个系统级别的方法,用于启动一个新线程。start() 方法会使 JVM 开辟一个新的线程,并在新的线程中运行当前线程对象的 run() 方法,而不是 run() 方法在当前线程中直接执行。也就是说,调用 start() 方法后,线程的状态变为可运行状态,JVM 会自动创建一个新线程,并在新线程中执行 run() 方法,直到 run() 执行结束或者调用了 stop() 方法。
3)小结
run() 方法是用户自定义的业务方法,直接调用 run() 仅仅是方法的调用;而 start() 方法是启动新线程的方法,内部会自动调用 run() 方法来执行线程的任务。
13. 索引的概念、类型、优劣和使用注意
- 概念
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构,实现原理(B+树) 。通俗点说类似于一本书的目录,通过目录可以快速查到你想要的数据。 - 优缺点
1)优点: 加快索引速度,大大减少查询时间,加索引比普通查询快很多
2)缺点:① 索引的创建和维护需要时间,随着数量增减需要的时间也会增加; ② 索引是需要占用物理空间的(也就是常说的用空间换时间),表空间是有最大上限设置的,如果一个表有大量索引会更快的到达上限值 - 使用注意
① 索引用在where条件经常使用的列
② 加索引列的内容不要频繁变化
③ 加索引列的内容不是唯一的几个值
④ 加索引列的值可以为null,并且可以存在多个null,但是不能有重复的空字符串“”
⑤ 对于创建多个列索引,如果不是一起使用的话,查询时索引不会起作用
⑥ 模糊查询时,like前面以%开头索引会失效
⑦ 如果该列类型是字符串,则作为条件查询时该列的值一定要用’ '引起来,否则索引失效
⑧ 如果条件中带or,那么条件中带索引会失效 - 类型
1)普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
CREATE INDEX index_name ON table(column)
2)唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
CREATE UNIQUE INDEX indexName ON table(column)
3)主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
CREATE TABLE 'table' (
'id' int(11) NOT NULL AUTO_INCREMENT ,
PRIMARY KEY ('id')
);
4)组合索引(复合索引)
用户可以在多个列上建立索引,这种索引叫做复合索引(组合索引) 。查询时使用创建时第一个开始索引才有效,使用遵循左前缀集合。
ALTER TABLE `tableName` ADD INDEX indexName (name,xb,age);
14. 数据库查询的左外连接、分组、排序、删除、修改、更新
-
左外连接LEFT JOIN或LEFT OUTER JOIN
左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。 -
右外连接right join
其实左外连接和右外连接就相当于是给字段匹配的行做笛卡尔积,不匹配的就保持原有行,另外的为null
select a.*,b.* from a left join b on a.id=b.parent_id
-
内连接inner join 和完全连接full join
① 内连接inner join:只输出匹配相等的值
② 完全连接full join:匹配成功的行以及左边表和右边表中未匹配成功的行,没有置null -
分组group by
select column_name from table_name group by column_name having conditions;
在 group by子句之后处理having 子句,所以不能通过使用列别名来引用选择列表中指定的聚合函数。也就是说group by之后select出满足的,再进行having筛选出select。
- 排序order by
select 表字段 from 表名 order by 表字段 desc
默认是升序asc
- 删除
delete from table_name where conditions;
truncate table table_name;
drop table table_name;
① delete属于DML(数据操纵语言),drop和truncate属于DDL(数据定义语言)
② 执行效率:drop>truncate>delete
③ delete删除的数据可以恢复,另外俩不可以
④ 补充:
DQL:数据查询语言,由select… from…where…组成的语句
DML:数据操作语言,如insert、update、delete
DDL:数据定义语言,如create、drop、truncate,隐式操作,不能回滚
DCL:数据控制语言,如GRANT授权,ROLLBACK [WORK] TO [SAVEPOINT]回滚,COMMIT [WORK]提交
- 修改alter
alter table table_name add/modify column_name ...
参考:alter的使用
- 更新update
UPDATE student SET
age=18,name='李'
WHERE name='赵' or age=16
15. delete、drop和truncate的区别
- 相同点:都可以删除整张表中的数据
- 不同点:
1)删除范围:drop(删除表中所有数据及表结构)>truncate(删除表中所有数据)>=delete(删除表中所有数据或部分数据)
2)查询条件:delete可以使用查询条件where进行表中数据删除,drop和truncate不可以
3)命令类型:delete属于DML,drop和truncate属于DDL
4)是否可恢复:delete删除的数据可以恢复/回滚,但是drop和truncate删除的数据不能恢复(隐式提交,不会触发触发器)
5)执行效率:drop>truncate>delete
6)删除方式:delete一行一行删除,并且由操作日志
7)空间释放:DELETE操作不会减少表或索引所占用的空间;当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小。
8)操作对象:DELETE可以是table和view,其余只能是table
参考:drop、delete和truncate的区别
16. 四种常用修饰符
public > protected > default > private

17. Linux常用命令并解释(未弄完)
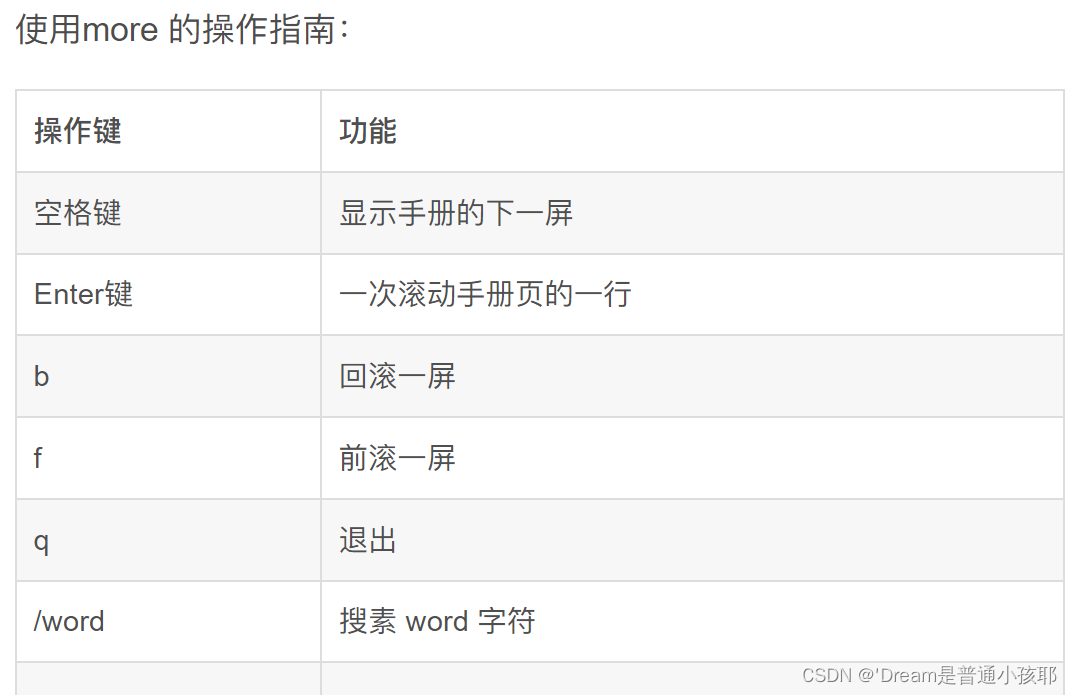
1)more:适用于查看内容较多的文本文件
2)echo终端输出,>和>>重定向
echo hello world > a.txt
(1)ls -l > 文件 (功能描述:列表的内容写入文件 a.txt 中(覆盖写))
(2)ls -al >> 文件 (功能描述:列表的内容追加到文件 aa.txt 的末尾)
(3)cat 文件 1 > 文件 2 (功能描述:将文件 1 的内容覆盖到文件 2)
(4)echo “内容” >> 文件
> 覆盖写
>>末尾追加
3)磁盘查看:df
4)查找文件:find path -name ‘file.txt’
18. OSI七层模型,每层的作用是什么
参考:OSI七层模型及其作用
-
OSI七层模型
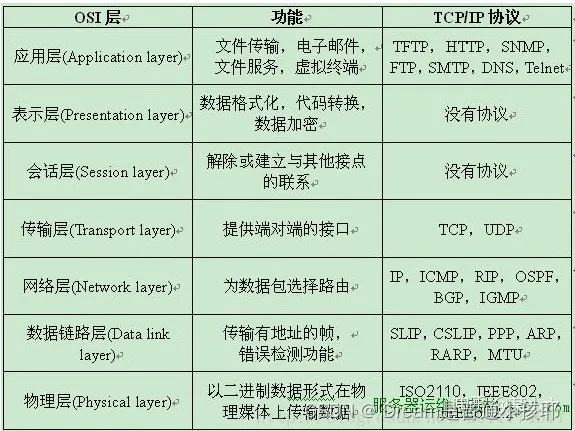
-
TCP/IP四层协议
tcpip协议规定为4层:分别是含应用层、传输层、网络层、网络接口层4层。 -
TCP/UDP协议
1)TCP (Transmission Control Protocol)和UDP(User Datagram Protocol)协议属于传输层协议。
2)其中TCP提供IP环境下的数据可靠传输,它提供的服务包括数据流传送、可靠性、有效流控、全双工操作和多路复用。通过面向连接、端到端和可靠的数据包发送。通俗说,它是事先为所发送的数据开辟出连接好的通道,然后再进行数据发送;而UDP则不为IP提供可靠性、 流控或差错恢复功能。
3)一般来说,TCP对应的是可靠性要求高的应用,而UDP对应的则是可靠性要求低、传输经济的应用。
4)TCP支持的应用协议主要 有:Telnet、FTP、SMTP等;UDP支持的应用层协议主要有:NFS(网络文件系统)、SNMP(简单网络管理协议)、DNS(主域名称系统)、TFTP(通用文件传输协议)等.
5)TCP/IP协议与低层的数据链路层和物理层无关,这也是TCP/IP的重要特点 -
OSI七层参考模型的各个层次的划分遵循下列原则:
1)同一层中的各网络节点都有相同的层次结构,具有同样的功能。
2)同一节点内相邻层之间通过接口(可以是逻辑接口)进行通信。
3)七层结构中的每一层使用下一层提供的服务,并且向其上层提供服务。
4)不同节点的同等层按照协议实现对等层之间的通信。
19. 左连接和右连接的区别
1)意思不一样:左连接只要左表有数据就可以检索到,影响的是右表
2)空值不一样:左连接中若左表条件数据在右表中没有,此时输出结果右表中数据置null
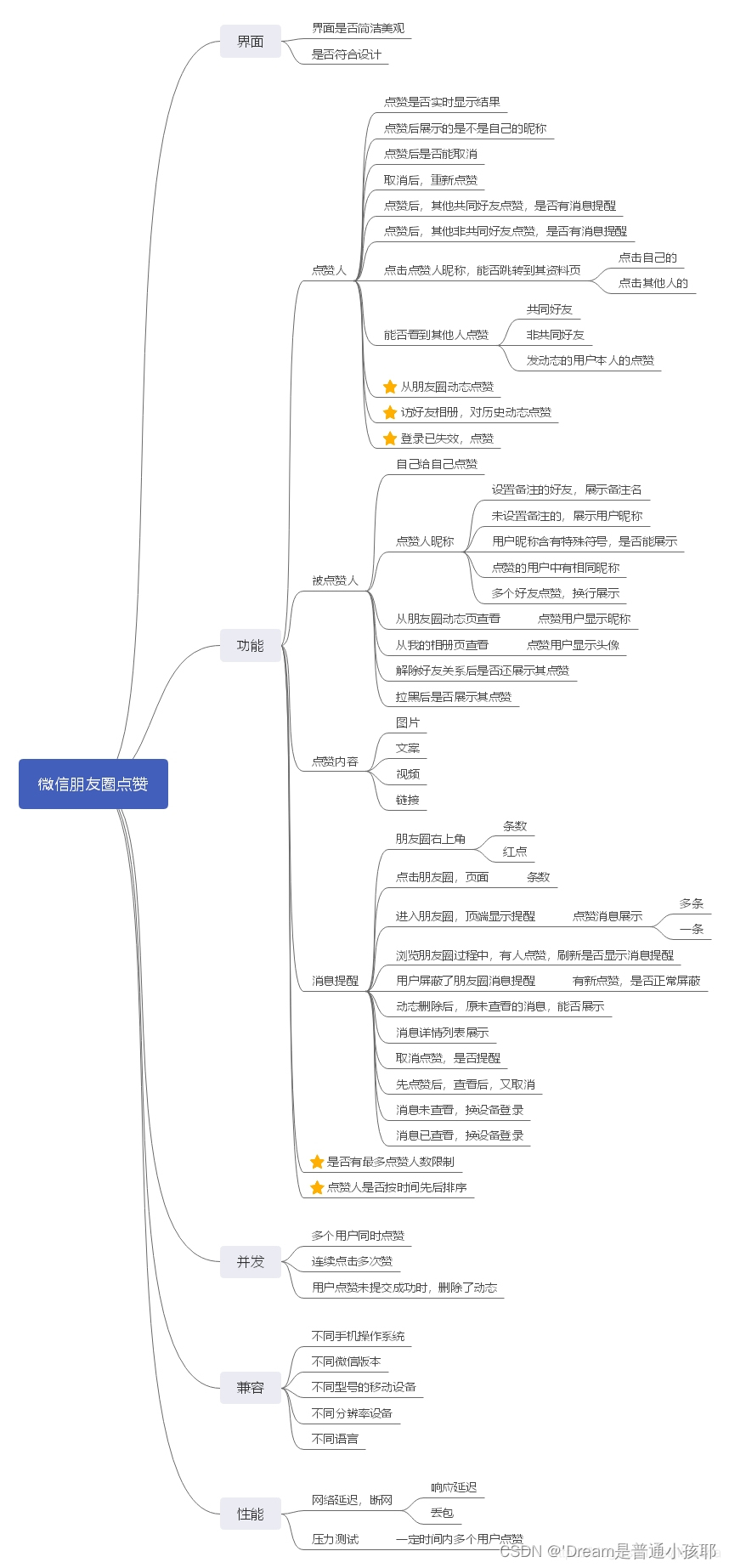
20. 微信朋友圈点赞如何设计测试用例
1)界面:图片、文字、排版、时间、版本的适应
2)功能:点赞人、被点赞人、消息提醒、内容类型、点赞人数、点赞展示是否按时间排序
3)性能:并发、压力
4)兼容性:系统、微信版本、手机型号、手机低配、加载速度
5)弱网:
6)安全性:其他人能否看到非共同好友点赞,屏蔽删除能否点赞
7)安装/卸载/换设备
8)未加好友能否点赞
9)易用性:
10)容错性:关机、内存不够、断网等
21. 动态规划描述
参考:动态规划详解
- 概念
通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。动态规划常常适用于有重叠子问题和最优子结构性质的问题。 - 核心思想
动态规划最核心的思想,就在于拆分子问题,记住过往,减少重复计算 - 解题特征
如果一个问题,可以把所有可能的答案穷举出来,并且穷举出来后,发现存在重叠子问题,就可以考虑使用动态规划。
比如一些求最值的场景,如最长递增子序列、最小编辑距离、背包问题、凑零钱问题等等,都是动态规划的经典应用场景。
- 解题思路
① 穷举分析
② 确定边界
③ 找出规律,确定最优子结构
④ 写出状态转移方程 - 经典题型
动态规划有几个典型特征:最优子结构、状态转移方程、边界、重叠子问题。
在青蛙跳阶问题中:
f(n-1)和f(n-2) 称为 f(n) 的最优子结构
f(n)= f(n-1)+f(n-2)就称为状态转移方程
f(1) = 1, f(2) = 2 就是边界啦
比如f(10)= f(9)+f(8),f(9) = f(8) + f(7) ,f(8)就是重叠子问题
public class Solution {
public int numWays(int n) {
if (n<= 1) {
return 1;
}
if (n == 2) {
return 2;
}
int a = 1;
int b = 2;
int temp = ;
for (int i = 3; i <= n; i++) {
temp = (a + b)% 1000000007;
a = b;
b = temp;
}
return temp;
}
}
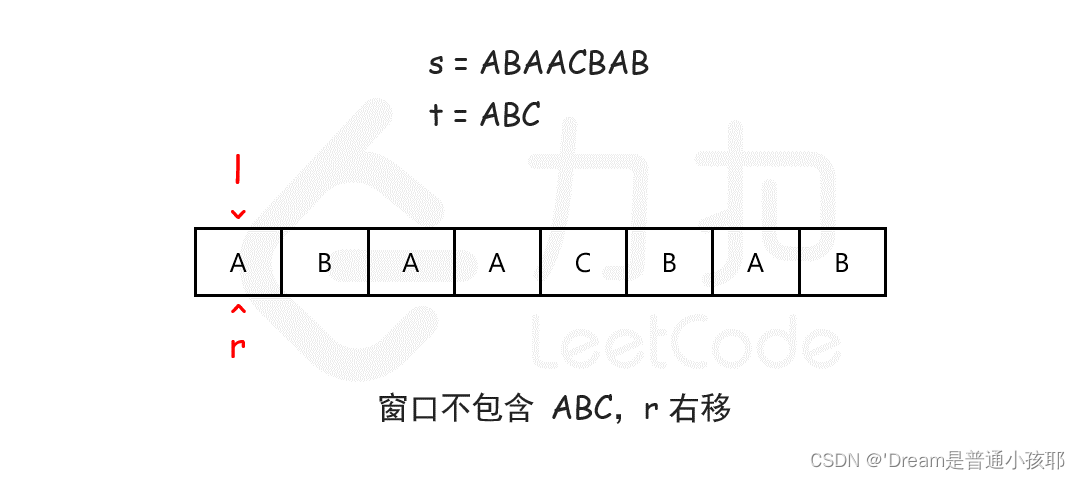
22. 字符串S和T,返回S中包含T中所有字符的连续字串
-
思路:判断长度比较,hashMap使用,使用滑动窗口双指针
left和right从左边开始,right开始移动,比较当前字符是否出现在t中,若t中所有字符串均出现,此时就是一个满足条件的字符串,可以使用subString进行输出;然后left++,看目前left到right的部分是否包含t中所有字符,包含则输出,然后left++;若不包含则right++。可以使用HashMap进行存储判断是否存在(以数量进行判断)
-
参考:最小覆盖字串
-
getOrDefault()的使用
① getOrDefault() 方法获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值。
② getOrDefault() 方法的语法为:
hashmap.getOrDefault(Object key, V defaultValue)
23. 判断一棵树是平衡二叉树
所谓的平衡二叉树是指以当前结点为根结点的树,左右子树的高度差不得超过1。
注意:空树也是平衡二叉树。
- 思路:
平衡:root左子树高度-root右子树高度<=1 && root左右子树都平衡(递归实现) +判断空树 - 代码:
1)时间复杂度:O(N2)
// 二叉树的最大深度:
public int maxDepth(TreeNode root) {
// 其实就相当于层序遍历并记录:注意递归不在三目运算符中
// 如何判断一层遍历结束
if(root==null) {
return 0;
}
// 返回是要判断左子树深还是右子树深
int leftTree = maxDepth(root.left);
int rightTree = maxDepth(root.right);
return (leftTree>rightTree? (leftTree+1):(rightTree+1));
}
// 判断平衡二叉树
public boolean isBalanced(TreeNode root) {
if(root==null) {
return true;
}
// 返回是要判断左子树深还是右子树深
int leftTree = maxDepth(root.left);
int rightTree = maxDepth(root.right);
// 为什么绝对值要小于等于1:平衡树的定义--每个结点的左右子树(子结点)高度相差<=1
// 平衡:每个结点的左右子树相差不超过1 && 左右子树均平衡
return ((Math.abs(leftTree-rightTree)<=1)
&& (isBalanced(root.left)) && (isBalanced(root.right)));
}
② 优化版:时间复杂度O(N)
// 但是上面的方法时间复杂度:O(N^2)
// 改进:边遍历边判断是否平衡,降低时间复杂度为O(n)
public int maxDepth2(TreeNode root) {
if (root==null) {
return 0;
}
int leftTree = maxDepth2(root.left);
int rightTree = maxDepth2(root.right);
if(leftTree>=0 && rightTree>=0 && (Math.abs(leftTree-rightTree)<=1)) {
return (Math.max(leftTree,rightTree)+1);
} else {
return -1;
}
}
public boolean isBalanced2(TreeNode root) {
return maxDepth2(root)>=0;
}
- 二叉树相关练习题参考二叉树练习题
24. 线程和进程的区别
1)进程包含线程;
2)线程比进程更轻量,创建更快、销毁也更快;
3) 同一个进程的多个线程之间共用一份内存和文件资源,而进程和进程之间则是独立的文件和内存资源;线程共用资源就省去了线程分配资源的过程
4) 进程是资源分配的基本单位,线程是调度执行的基本单位
25. 线程池是什么
具体参考线程池详解
-
概念
线程池是一种利用池化技术思想来实现的线程管理技术,主要是为了复用线程、便利地管理线程和任务、并将线程的创建和任务的执行解耦开来。我们可以创建线程池来复用已经创建的线程来降低频繁创建和销毁线程所带来的资源消耗。在JAVA中主要是使用ThreadPoolExecutor类来创建线程池,并且JDK中也提供了Executors工厂类来创建线程池(不推荐使用)。 -
优点
① 降低资源消耗,复用已创建的线程来降低创建和销毁线程的消耗。
② 提高响应速度,任务到达时,可以不需要等待线程的创建立即执行。
③ 提高线程的可管理性,使用线程池能够统一的分配、调优和监控。 -
ThreadPoolExecutor类的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
① corePoolSize,核心线程数量,决定是否创建新的线程来处理到来的任务
② maximumPoolSize,最大线程数量,线程池中允许创建线程地最大数量
③ keepAliveTime,线程空闲时存活的时间
④ unit,空闲存活时间单位
⑤ workQueue,任务队列,用于存放已提交的任务
⑥ threadFactory,线程工厂,用于创建线程执行任务
⑦ handler,拒绝策略,当线程池处于饱和时,使用某种策略来拒绝任务提交
-
handler拒绝策略
① AbortPolicy:中断策略,直接抛异常 handler(回调,处理方法)
② CallerRunsPolicy:调用者来执行,而不是被调用者来执行(按理来说是被调用者执行);如果调用者也不执行就丢弃该任务
③ DiscardOldestPolicy:丢弃最老的未处理请求
④ DiscardPolicy:直接丢弃最新的任务
(实际开发中,需要根据请求来决定使用哪种策略) -
线程池五种状态

26. get和post的区别
http请求方法get和post是最常被用到的两个方法,get常用于向服务器请求数据,post常用于提交数据给服务器处理。
GET方法其实也可以传递少量的数据。 但它存在以下问题:
- GET 方法不包含body,因此以在URL中拼接字段的方式传递数据,
2)GET方法中的URL参数会被显示到地址栏上,存在安全问题
3)GET传递的数据只能是键值对,无法传递其他类型的数据
因此出于传递大量、多种类型的数据和安全性的考虑,上传数据常使用post方法
① GET请求参数放在url中,不同浏览器和服务器会对长度进行不同的限制;post请求无限制
② get请求刷新服务器或者回退没有影响,post请求回退时会重新提交数据请求
③ get请求可以被缓存,post请求不会被缓存
④ get请求会被保存在浏览器历史记录当中,post不会。get请求可以被收藏为书签,因为参数就在url中;但post不能,它的参数不在url中。
⑤ get请求只能进行url编码(appliacation-x-www-form-urlencoded),post请求支持多种(multipart/form-data等)
参考get和post区别
27. 从输入一个网址到展示页面经历了哪些过程,用了哪些通信协议
1)DNS域名解析:本地hosts文件、 浏览器缓存、 本地域名解析服务器->根域名服务器 ->顶级域名服务器 -> 二级域名服务器 -> 将域名解析为IP地址。(通信协议:DNS协议)
2)三次握手建立连接:(通信协议:TCP)
3)发送HTTP请求:客户端给服务器发送HTTP请求,携带请求内容。(通信协议:HTTP)
4)服务器处理请求:服务器想文件系统等中检索需求所需内容
5)将处理结果返回给客户端:通过之前建立好的TCP进行返回
6)浏览器接收响应,并看情况关闭TCP(TCP四次挥手)
7)解析详细并进行渲染,最终在页面上显示
参考:url到页面渲染
28. 白盒测试需要遵循的原则
1)保证一个模块中的所有独立路径至少被测试一次。
2)对所有的逻辑判定均需测试取真和取假两种情况。
3)在上下边界及可操作范围内运行所有循环。
4)检查程序的内部数据结构,保证其结构的有效性。

29. 深拷贝和浅拷贝
Ps.基本数据类型储存在栈中,而引用数据类型在栈中存储的是引用地址,实际的值存储在堆中
- 深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是在进行对象拷贝时常用的两种方式,它们之间的主要区别在于是否复制了对象内部的数据。
1)浅拷贝只复制了对象本身,不会复制对象内部的数据。
2)深拷贝递归地复制了对象及其所有子对象的内容。
3) 引用拷贝是将一个对象的引用赋值给另一个变量,使得两个变量指向同一个对象。 - 浅拷贝修改原来对象的值会同步改变,深拷贝各自独立。
30. TCP和UDP的区别
1)连接:
TCP是面向连接的传输层协议,传输数据前需要先建立连接;UDP不需要建立连接,即时通信
2)服务对象:
TCP 是一对一的两点服务,即一条连接只有两个端点。
UDP 支持一对一、一对多、多对多的交互通信。
3)可靠性:
TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达。
UDP 是尽最大努力交付,不保证可靠交付数据。
4)拥塞控制、流量控制
TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
5)首部开销
TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是 20 个字节,如果使用了「选项」字段则会变长的。
UDP 首部只有 8 个字节,并且是固定不变的,开销较小
6)传输方式
TCP 是流式传输,没有边界,但保证顺序和可靠。
UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
7)分片不同
TCP 的数据大小如果大于 MSS 大小(除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度),则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。
UDP 的数据大小如果大于 MTU 大小(最大传输单元,是可以在网络中传输的最大数据包大小),则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层
31. 锁(未弄完)
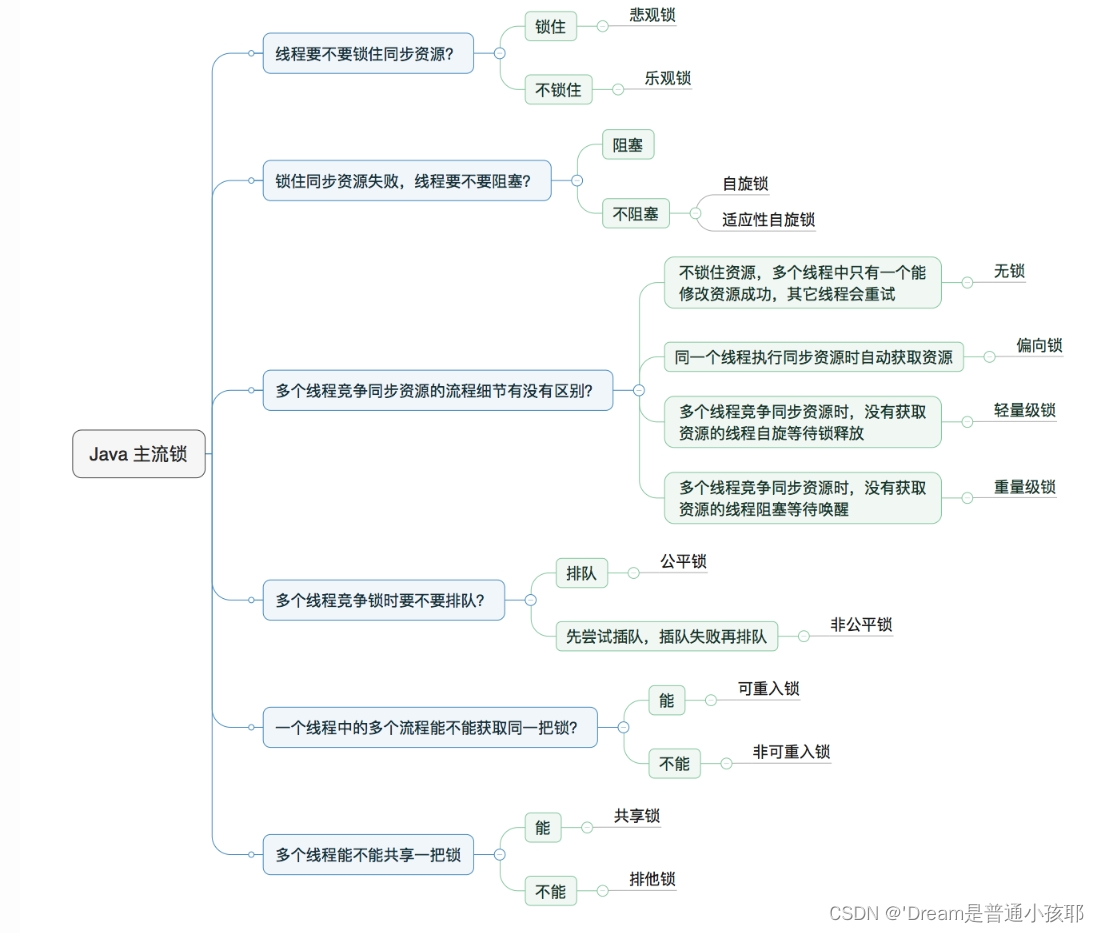
-
锁共有四种状态,级别从低到高分别是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。随着竞争情况锁状态逐渐升级、锁可以升级但不能降级。
-
队列同步器/同步器AQS,是用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队操作。
-
synchronized优化方法:
参考:synchronized优化
1)锁膨胀/升级:JDK 1.6 之前,synchronized 是重量级锁,也就是说 synchronized 在释放和获取锁时都会从用户态转换成内核态,而转换的效率是比较低的。但有了锁膨胀机制之后,synchronized 的状态就多了无锁、偏向锁以及轻量级锁了,这时候在进行并发操作时,大部分的场景都不需要用户态到内核态的转换了,这样就大幅的提升了 synchronized 的性能。
2)锁粗化:锁消除指的是在某些情况下,JVM 虚拟机如果检测不到某段代码被共享和竞争的可能性,就会将这段代码所属的同步锁消除掉,从而到底提高程序性能的目的。
锁消除的依据是逃逸分析的数据支持,如 StringBuffer 的 append() 方法,或 Vector 的 add() 方法,在很多情况下是可以进行锁消除的
3)锁消除:如果检测到同一个对象执行了连续的加锁和解锁的操作,则会将这一系列操作合并成一个更大的锁,从而提升程序的执行效率。
4)自适应自旋锁:自旋锁优点在于它避免一些线程的挂起和恢复操作,因为挂起线程和恢复线程都需要从用户态转入内核态,这个过程是比较慢的,所以通过自旋的方式可以一定程度上避免线程挂起和恢复所造成的性能开销。线程自旋的次数不再是固定的值,而是一个动态改变的值,这个值会根据前一次自旋获取锁的状态来决定此次自旋的次数。如果线程自旋成功了,则下次自旋的次数会增多,如果失败,下次自旋的次数会减少。 -
了解锁
1)乐观锁VS悲观锁
① Java中,synchronized关键字和Lock的实现类都是悲观锁
② 乐观锁在Java中是通过使用无锁编程来实现,最常采用的是CAS算法,Java原子类中的递增操作就通过CAS自旋实现的。
③ CAS全称 Compare And Swap(比较与交换),是一种无锁算法。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁。
④ CAS算法涉及到三个操作数:
需要读写的内存值 V,进行比较的寄存器值 A,要写入的新值 B。
(若V==A,则V=B,就是说内存值和寄存器值相等就是没有其他线程修改过,可以直接将新值赋值给内存中)
⑤ CAS虽然很高效,但是它也存在三大问题,简单说一下:
- ABA问题。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”。
JDK从1.5开始提供了AtomicStampedReference类来解决ABA问题,具体操作封装在compareAndSet()中。compareAndSet()首先检查当前引用和当前标志与预期引用和预期标志是否相等,如果都相等,则以原子方式将引用值和标志的值设置为给定的更新值。- 循环时间长开销大。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销。
- 只能保证一个共享变量的原子操作。对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作时,CAS是无法保证操作的原子性的。
Java从1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作。
⑤ 自旋锁:自旋锁与互斥锁很相似,本质上是一把锁,在访问共享资源之前对自旋锁进行上锁,在访问完成后释放自旋锁(解锁);从实现方式上来说,互斥锁是基于自旋锁来实现的,所以自旋锁相比较于互斥锁更加底层。 如果在获取自旋锁时,自旋锁处于未锁定状态,那么将立即获得锁(对自旋锁上锁);如果在获取自旋锁时,自旋锁已经能处于锁定状态了,那么获取锁操作将会在原地“自旋”,直到该自旋锁的持有者释放锁。
2)自旋锁VS非自旋锁
自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
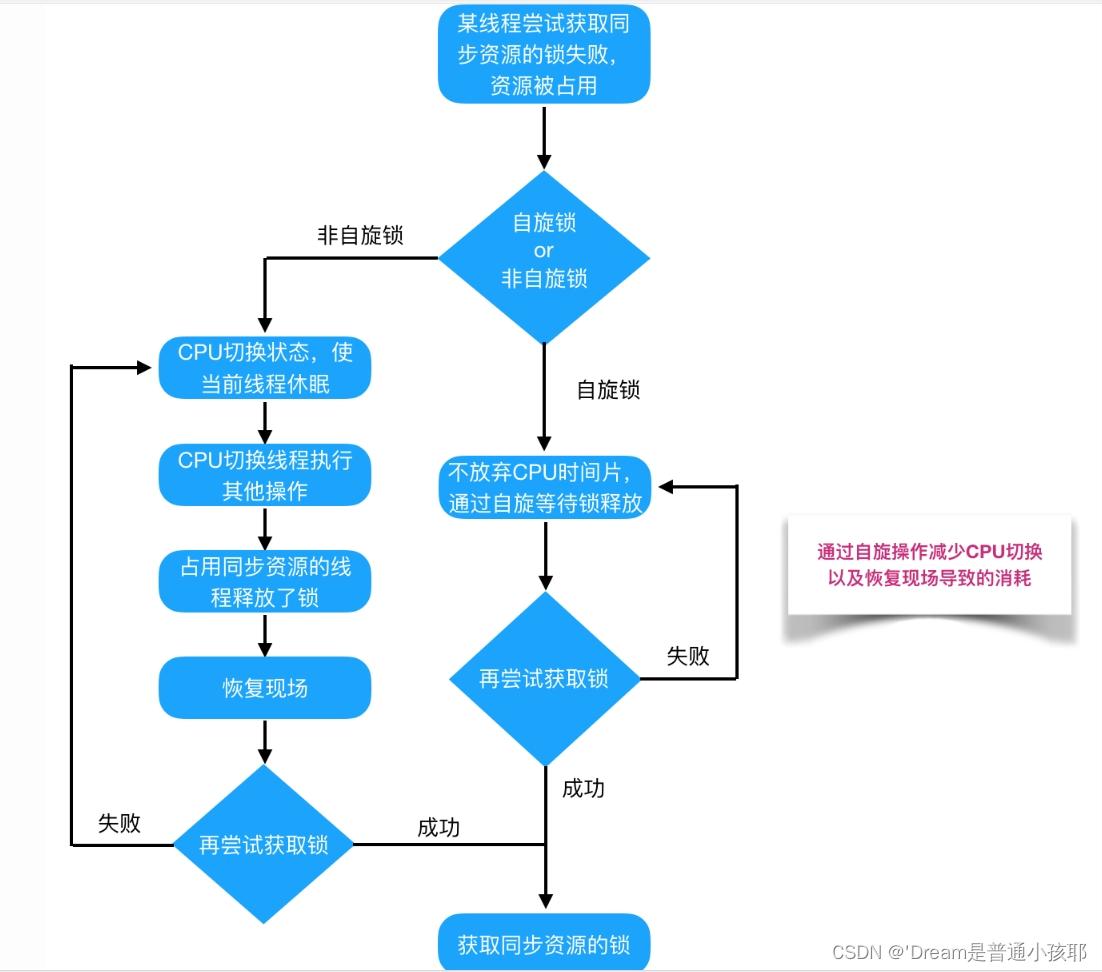
3)无锁 VS 偏向锁 VS 轻量级锁 VS 重量级锁
① 无锁:无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
② 偏向锁:偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。
③ 轻量级锁:是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
④ 重量级锁:等待锁的线程都会进入阻塞状态
4)公平锁VS非公平锁
① 公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
② 非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
5)可重入锁VS非可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。
6)独享锁VS共享锁
独享锁(排他锁)与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
-
Java中主流锁的介绍
-
隐式锁synchronized和显式锁Lock的区别

-
volatile和CAS

-
Lock接口中六种方法的含义

-
synchronized和ReentrantLock的区别

32. 自动化测试中selenium等待的类型
- 通过在脚本中设置等待的方式来避免由于网络延迟或浏览器卡顿导致的元素找不到的偶然失败问题
- 常用的三种等待
1)强制等待
① 利用time模块的sleep方法来实现,最简单粗暴的等待方法
② 弊端:严重影响代码的执行速度
# 强制等待3秒
time.sleep(3)
2)隐式等待
① implicitly_wait()方法用来等待页面加载完成(直观的就是浏览器tab页上的小圈圈转完)网页加载完成则执行下一步
② 隐式等待只需要声明一次,一般在打开浏览器后进行声明
③ 声明之后对整个drvier的生命周期都有效,后面不用重复声明
④ 弊端:程序会一直等待页面加载完成,直到超时。有时我们需要的元素已经加载完成,但是依旧需要等待页面上所有的元素都加载完成才能下一步
# 隐性等待5秒
driver.implicitly_wait(5)
3)显示等待
① WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了
② 它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步;否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException
③ 显示等待必须在每个需要等待的元素前面进行声明
33. 数据库常用语句(未弄完)
34. app与web测试的区别
参考:web与app端测试
Ps. APP需要关注:安装/卸载/更新、中断(如关机、电话、短信等)、专项测试(如网络适配性、运营商环境、WIFI)、交互(鼠标、点击/手势/横屏等)、升级测试(原有功能、用户数据等)
1)系统架构方面
web项目,b/s架构,基于浏览器的;web测试只要更新了服务器端,客户端就会同步会更新
app项目,c/s结构的,必须要有客户端;app 修改了服务端,则客户端用户所有核心版本都需要进行回归测试一遍
2)性能方面
web项目 需监测 响应时间、CPU、Memory、点击率、TPS、并发等
app项目 除了监测 响应时间、CPU、Memory外,还需监测流量、电量等
3)兼容方面
① web项目:
浏览器(火狐、谷歌、IE等)
操作系统(Windows7、Windows10、OSX、Linux等)
② app项目:
设备系统: iOS(ipad、iphone)、Android(三星、华为、联想等) 、Windows(Win7、Win8)、OSX(Mac)
手机设备可根据 手机型号、分辨率不同
4)相对于web项目,app华友专项测试
① 干扰测试:中断,来电,短信,关机,重启等
② 弱网络测试(模拟2g、3g、4g,wifi网络状态以及丢包情况);网络切换测试(网络断开后重连、3g切换到4g/wifi 等)
③ 安装、更新、卸载
安装:需考虑安装时的中断、弱网、安装后删除安装文件等情况
卸载:需考虑 卸载后是否删除app相关的文件
更新:分强制更新、非强制更新、增量包更新、断点续传、弱网状态下更新
5)测试工具
自动化工具:APP 一般使用 Appium; Web 一般使用 Selenium
性能测试工具:APP 一般使用 JMeter; Web 一般使用 LR、JMeter
6)界面操作:关于手机端测试,需注意手势,横竖屏切换,多点触控,前后台切换
7)安全测试:安装包是否可反编译代码、安装包是否签名、权限设置,例如访问通讯录等
8) 边界测试:可用存储空间少、没有SD卡/双SD卡、飞行模式、系统时间有误、第三方依赖(QQ、微信登录)等
9)权限测试:设置某个App是否可以获取该权限,例如是否可访问通讯录、相册、照相机等
10)升级测试:升级后原有功能是否受影响,用户数据是否丢失
35. wait和sleep的区别
参考:wait和sleep区别
1)使用限制
① 使用 sleep 方法可以让让当前线程休眠,时间一到当前线程继续往下执行,在任何地方都能使用,但需要捕获 InterruptedException 异常。
Thread.sleep(3000L);
② 而使用 wait 方法则必须放在 synchronized 块里面,同样需要捕获 InterruptedException 异常,并且需要获取对象的锁。
synchronized (lock){
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
而且 wait 还需要额外的方法 notify/ notifyAll 进行唤醒,它们同样需要放在 synchronized 块里面,且获取对象的锁。
2)使用场景
sleep 一般用于当前线程休眠,或者轮循暂停操作;wait 则多用于多线程之间的通信
3)所属类不同
sleep 是 Thread 类的静态本地方法,wait 则是 Object 类的本地方法
4)释放锁
wait 可以释放当前线程对 lock 对象锁的持有,而 sleep 则不会。
5)线程切换
sleep 会让出 CPU 执行时间且强制上下文切换;而 wait 则不一定,wait 后可能还是有机会重新竞争到锁继续执行的。
36. 如何保证线程安全
参考线程安全
Java并发的三大基本特性:原子性、可见性以及有序性
解决办法:使用多线程之间使用关键字synchronized、或者使用锁(lock),或者volatile关键字。
① synchronized:自动锁,锁的释放是在synchronized同步代码执行完毕后自动释放。
弊端:多个线程需要判断锁,较为消耗资源、抢锁的资源。
② Lock锁是需要手动去加锁和释放锁,Lock相比于synchronized更加的灵活。tryLock()方法会尝试获取锁,如果锁不可用则返回false,如果锁是可以使用的,那么就直接获取锁且返回true。主动通过unLock()去释放锁。(竞争激烈使用Lock)
③ Volatile 关键字的作用是变量在多个线程之间可见。使用Volatile关键字将解决线程之间可见性,强制线程每次读取该值的时候都去“主内存”中取值。
volatile虽然具备可见性,但是不具备原子性。
37. 常见中间件
-
中间件概念
① 中间件(英语:Middleware)顾名思义是系统软件和用户应用软件之间连接的软件,以便于软件各部件之间的沟通
② 总的作用是为处于自己上层的应用软件提供运行与开发的环境,帮助用户灵活、高效地开发和集成复杂的应用软件。 -
了解补充
中间件与操作系统和数据库共同构成基础软件三大支柱,是一种应用于分布式系统的基础软件,位于应用与操作系统、数据库之间,为上层应用软件提供开发、运行和集成的平台。中间件解决了异构网络环境下软件互联和互操作等共性问题,并提供标准接口、协议,为应用软件间共享资源提供了可复用的“标准件”。
-
常见中间件
Tomcat
Weblogic
Jboss
Jetty
Webshere
Glassfish
38. 线程状态
参考:线程状态
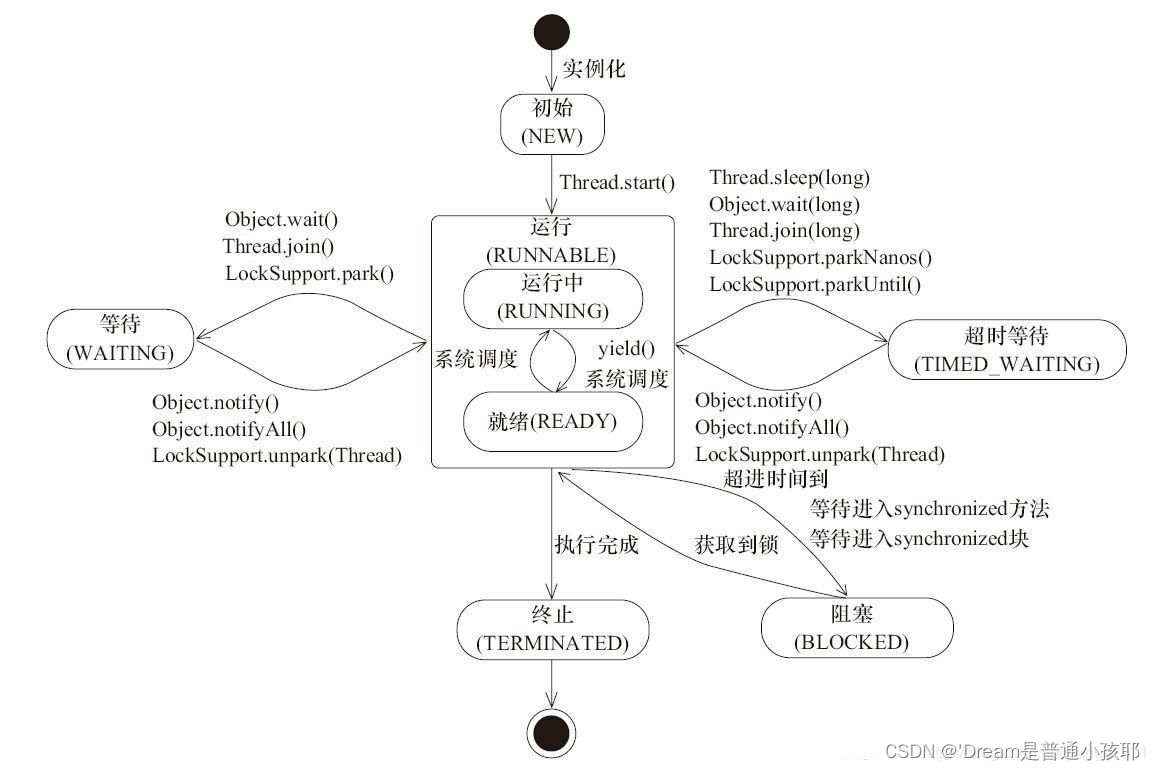
线程六种状态
① 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
② 运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。
线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
③ 阻塞(BLOCKED):表示线程阻塞于锁。
④ 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
⑤ 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
⑥ 终止(TERMINATED):表示该线程已经执行完毕。
39. 死锁产生的条件
循环等待、不可抢占、互斥、请求和保持
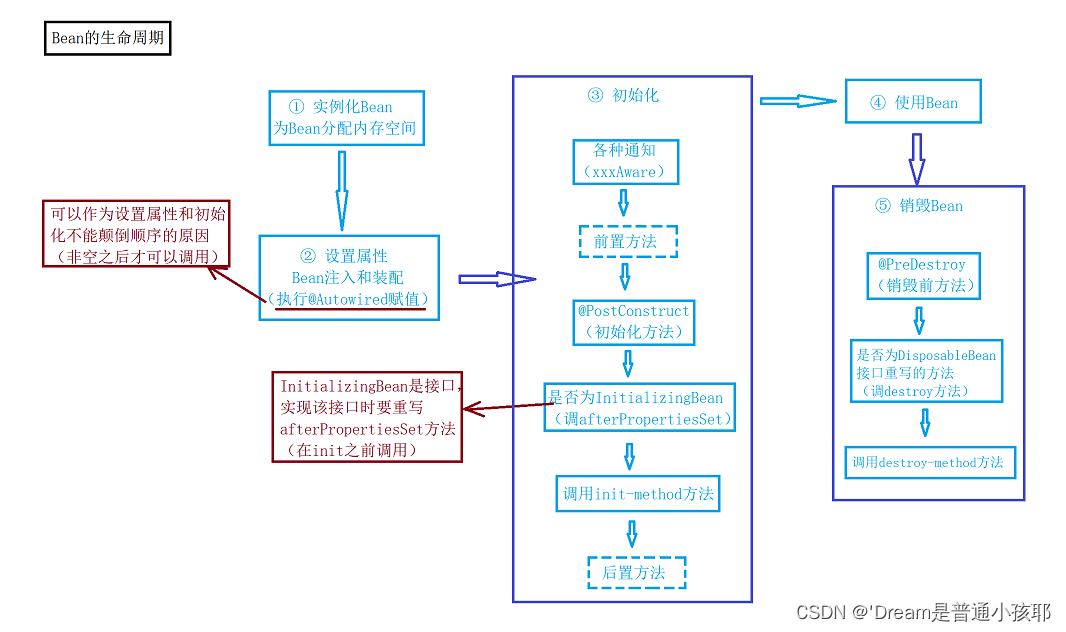
40. Bean的生命周期
41. 缺陷的生命周期
参考:缺陷介绍
1)发现缺陷
2)提交缺陷
3)确认缺陷
4)分配缺陷
5)修复缺陷
6)验证缺陷
7)关闭缺陷
42. awk使用
- 介绍
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。 - 具体使用参考:Linux awk命令
Linux命令使用手册
43. 最长回文子串(!!!未完成)
- 中心扩散法
1)思路:
时间复杂度:O(n2)
① 遍历每个字符
② 以每次遍历到的字符为中心(分奇数长度和偶数长度两种情况),不断向两边扩展
③ 如果两边都是相同的就是回文,不断扩大到最大长度即是以这个字符(或偶数两个)为中心的最长回文子串
④ 遍历完成后取最大值
2)代码:
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param A string字符串
* @return int整型
*/
public int getLongestPalindrome (String A) {
// write code here
// 存储最长字符串
String maxStr = "";
// 存储最大长度
int maxLen = 1;
// 每个点都有机会作为中心点
// 注意:循环最多只能到倒数第二个,因为会有+1情况
for(int i = 0; i < A.length() - 1; i++) {
// 分为奇数和偶数长度向两边扩展
maxLen = Math.max(maxLen,Math.max(fun(A,i,i), fun(A,i,i+1)));
// 注意:如果需要最长字符串的话,每次遍历的时候可以记住其实位置和终止位置,然后截取字符串
// 或者是每次遍历使用临时变量存储,然后发现如果此循环结束后长度大于之前就进行更新
}
return maxLen;
}
// 中心点扩展
private int fun(String s, int left, int right) {
// 从遍历到的点作为起点向两边扩展,一旦遇到不相等就停止计数
while(left >= 0 && right < s.length()
&& s.charAt(left) == s.charAt(right)) {
left--; // 左边扩展
right++; // 右边扩展
}
return right - left - 1;
}
}
- 动态规划
1)思路:
时间/空间复杂度:O(n2)
① 维护一个布尔型的二维数组dp[i][j]:表示i到j的子串是否为回文子串
② 从长度为2开始进行比较,里面的start从0开始可以最大到len-2,end最大到len-1
2)代码:
public int longestPalindrome (String s) {
// 动归思想
// 使用数组表示从i到j的字符串是否为回文串,true表示是,false表示不是
// i到i只有一个字符,标识为是回文串
int len = s.length();
boolean[][] dp = new boolean[len][len];
int maxLen = 1;
for (int i = 0; i < len; i++) {
dp[i][i] = true;
}
// 然后开始循环遍历
// 最外层为长度遍历
for (int length = 2; length <= len; length++) {
// 标识开始位置和结束位置
for (int start = 0; start <= len -length; start++) { // 只能到len -length,要留出最后的位置是为了给end让路
int end = start + length - 1;
// 首先比较首尾字符 如果相等 继续向中间比较
if(s.charAt(start) == s.charAt(end)) {
// 继续向中间比较
// 这里注意条件:等于2是为了长度为2时避免俩字符再比较一次dp
if(length==2 || dp[start+1][end-1]) {
// 那么更新最大长度
// 为什么可以直接更新,长度从小到大,确保了都是回文串的
maxLen = Math.max(maxLen,length);
// 更新dp
dp[start][end] = true;
}
}
}
}
return maxLen;
}
- 暴力法
1)思路:
① 进行双层循环遍历,第一层是标识开始的位置,从0开始到(length-1)的位置
② 第二层从第一层标识开始位置往后遍历,此时需要进行比较,如果两间隔小于已有的maxLength,此时就没有比较的必要,而是直接continue,第二层往后走;如果间隔大于已有的maxLength,则进行比较,一旦在比较过程中出现不相等就停止,直到左边<右边
③ 如果此时更新过maxLength,需要记录当前的起始下标以及结束下标,截取字符串拿到最长子串
2)代码:
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param s string字符串
* @return int整型
*/
public int longestPalindrome (String s) {
// write code here
int len = s.length();
// 特殊判断
if(len <= 1) {
return len;
}
// 说明需要求最长回文串
int maxLen = 1;
String maxStr = "";
// 双指针
// 第一层循环
for (int i = 0; i < len - 1; i++) {
// 第二层循环
for (int j = i; j < len; j++) {
// 开始进行判断
// 看两个字符间的间隔是否大于maxLen,如果不大于,其实就没有继续比较的必要了
if(j - i + 1 < maxLen) {
continue; // 直接第二层指针往后移
} else if (comp(s,i,j)) {
// 开始比较 并且是该子串是完全匹配上的
// 并且经过以上的过滤之后,此时的一定是更长的
maxLen = j - i + 1;
maxStr = s.substring(i,j+1);
}
}
}
System.out.println("max: " + maxStr);
return maxLen;
}
private static boolean comp(String s, int i, int j) {
while((i < j) && (s.charAt(i) == s.charAt(j))) {
i++; // 左边往后
j--; // 右边往前
}
// 出来两种情况
if(i >= j) {
// 说明是回文串
return true;
} else {
return false;
}
}
}
44. 查看进程
参考:Linux查看进程命令
① ps -aux | grep java 是以简单列表的形式显示出进程信息,通常用于查看进程的PID。(静态)
可以使用kill命令终止进程,如:kill -9 [PID],-9表示强迫进程立即停止
② top命令可以实时显示各个线程情况。要在top输出中开启线程查看,请调用top命令的“-H”选项,该选项会列出所有Linux线程。在top运行时,你也可以通过按“H”键将线程查看模式切换为开或关。
③ pstree命令以树状图的方式展现进程之间的派生关系,显示效果比较直观。
45. chmod的数字含义
-
Linux chmod(英文全拼:change mode)命令是控制用户对文件的权限的命令
-
Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)。
-
chmod 后面的数字含义:
① 注:每个级别下面的权限顺序:读r、写w、执行x
② 语法:chmod num file/directory
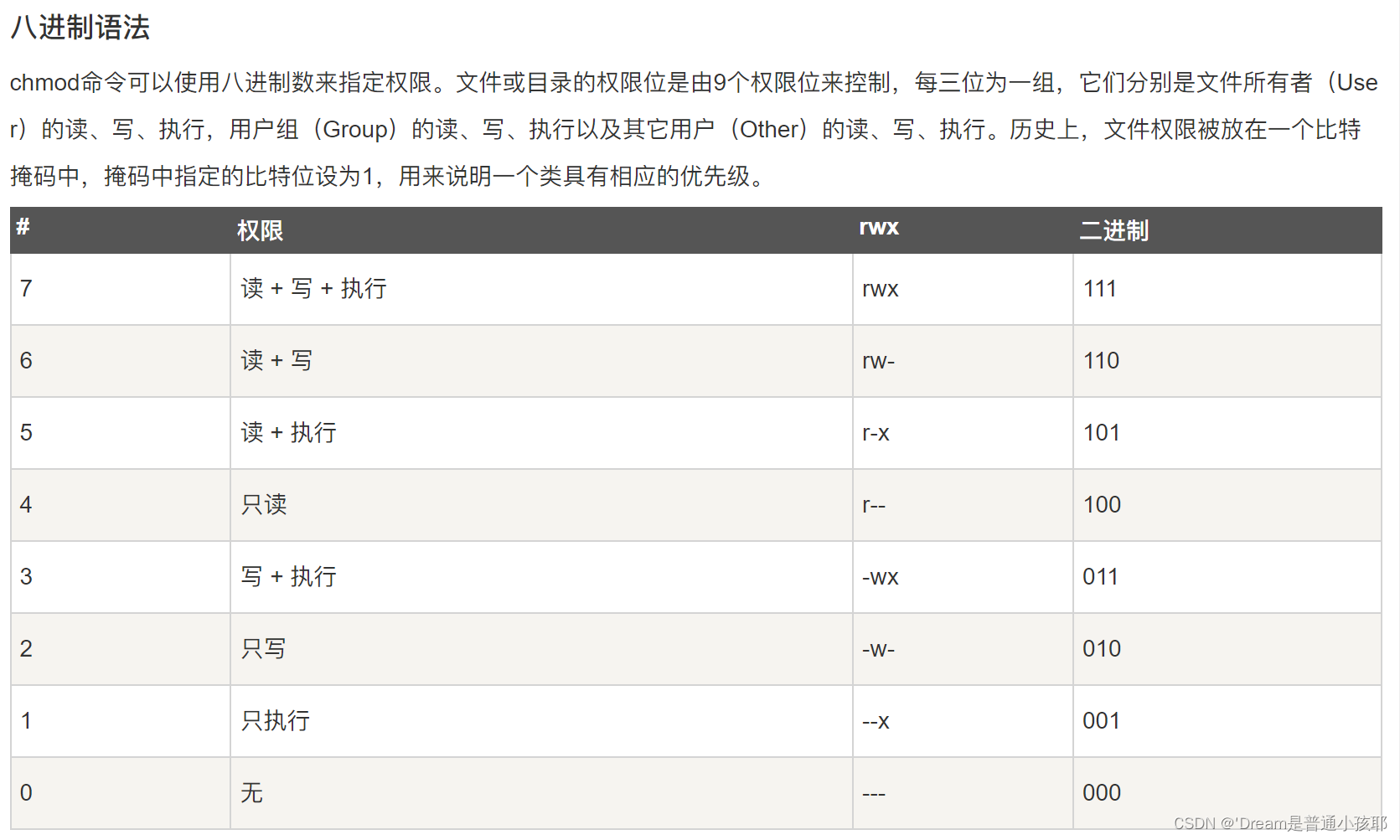
-
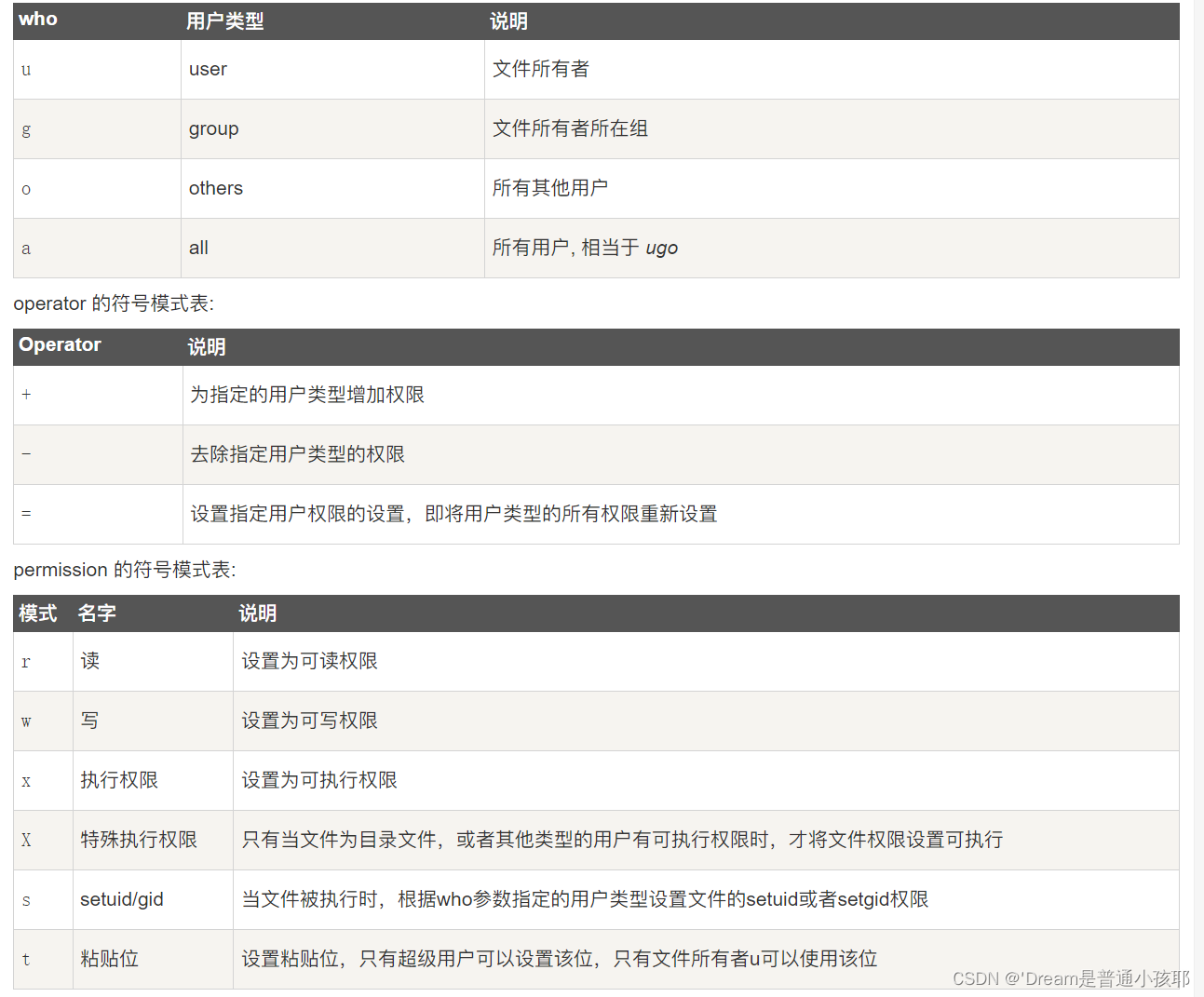
对特定级别进行权限限制
① 语法:chmod ug+w o-x file
② 相关符号表示
46. Java面向对象的三大特征并进行解释
- 对象
对象其实可以理解为就是一个实体:实体是某个类的实例;对象具有行为和属性;对象具有唯一性;对象具有可变性。 - 面向过程最小单位是函数,函数间相互调用;面向对象最小单位是类,强调的是具备某些功能的对象。
- 面向对象三大特征:封装、继承和多态。
1)继承
① 继承就是子类继承父类的特征和行为。
② 子类拥有父类中的一切(拥有不一定能使用),它可以访问和使用父类中的非私有成员变量,以及重写父类中的非私有成员方法。
③ 继承的作用就是能提高代码的复用性。
④ java中类的继承支持单继承
⑤ 子类代码示例:
public class Student extends Person {
@Override
public void say() {
super.say();
}
@Override
public void run() {
super.run();
}
public static void main(String[] args) {
Student stu = new Student();
//stu.a=1;//子类对象对父类的私有成员变量使用报错!
//stu.show();//子类对象调用父类的私有方法,同样报错!
stu.say();
stu.run();
}
}
2)封装
① 封装就是把类内部的实现细节隐藏起来,只暴露对外的接口。
② 封装又分为属性的封装和方法的封装。把属性定义为私有的,它们通过setter和getter方法来对属性的值进行设定和获取。
③ 代码示例:
public class Person {
private int id;
private String name;
private Person person;
public int getId() {
return id;
}
public String getName() {
return name;
}
public Person getPerson() {
return person;
}
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void setPerson(Person person) {
this.person = person;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + ", person=" + person + "]";
}
}
3)多态
① 多态就是指多种状态,就是说当一个操作在不同的对象时,会产生不同的结果。
② 在Java中,实现多态的方式有两种:一种是编译时的多态,另外一种是运行时多态。编译时的多态是通过方法的重载实现的,而运行时多态是通过方法的重写实现的。
③ 方法的重载是指在同一个类中,有多个方法名相同的方法,但是这些方法有着不同的参数列表,在编译期我们就可以确定到底调用哪个方法。
③ 方法的重写,子类重写父类中的方法(包括接口的实现),父类的引用不仅可以指向父类的对象,而且还可以指向子类的对象。当父类的引用指向子类的引用时,只有在运行时才能确定调用哪个方法。
④ 其实在运行时的多态的实现,需要满足三个条件:继承(包括接口的实现、方法的重写 、父类的引用指向子类对象
⑤ 运行时的多态
// 接口
public interface Animal {
void shout();
}
// 实现类
public class Dog implements Animal{
@Override
public void shout() {
System.out.println("wangwang...");
}
}
// 实现类
public class Cat implements Animal {
@Override
public void shout() {
System.out.println("miaomiao...");
}
}
//测试
public class AnimalTest {
public static void main(String[] args) {
//父类的引用指向子类对象
Animal d = new Dog();
animalShout(d);
//父类的引用指向子类对象
Animal c= new Cat();
animalShout(c);
}
public static void animalShout(Animal animal) {
animal.shout();
}
}
47. netstat的使用
- netstat 是一款命令行工具,可用于列出系统上所有的网络套接字连接情况,包括 tcp, udp 以及 unix 套接字,另外它还能列出处于监听状态(即等待接入请求)的套接字。如果你想确认系统上的 Web 服务有没有起来,你可以查看80端口有没有打开。
- 命令介绍
1)列出所有当前的连接:使用-a
netstat -a
2)只列出TCP或UDP协议的连接
① TCP协议的连接:-t
netstat -at
② UDP协议的连接:-u
netstat -au
3)禁用反向域名解析,加快查询速度
默认情况下 netstat 会通过反向域名解析技术查找每个 IP 地址对应的主机名。这会降低查找速度。如果你觉得 IP 地址已经足够,而没有必要知道主机名,就使用 -n 选项禁用域名解析功能。
netstat -ant
4)只列出监听中的连接
netstat -ntl
5)获取进程名、进程号以及用户 ID
sudo netstat -nlpt
6)打印统计数据
netstat 可以打印出网络统计数据,包括某个协议下的收发包数量。
netstat -s
7)更多参考:netstat的使用
netstat可以查询出TCP和UDP的状态:如TCP的LISTENING、ESTABLISHED、SYN_SEND、FIN_WAIT_1、FIN_WAIT_2、TIME_WAIT、CLOSE_WAIT状态
48. ping的工作原理
-
ping 是基于 ICMP 协议工作的(ICMP是网络层协议)
-
ICMP 主要的功能包括:确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。
-
在 IP 通信中如果某个 IP 包因为某种原因未能达到目标地址,那么这个具体的原因将由 ICMP 负责通知。ICMP的通知消息是使用IP进行发送的。
(ARP:地址解析协议,工作在网络层:用于将计算机的网络地址(IP地址32位)转化为物理地址(MAC地址48位))
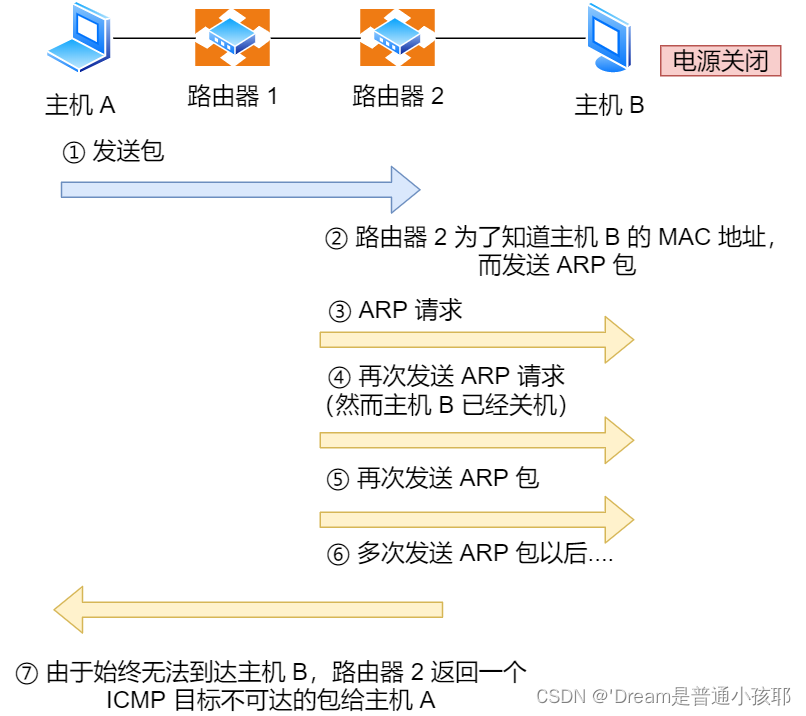
-
回送消息用于进行通信的主机或路由器之间,判断所发送的数据包是否已经成功到达对端的一种消息,ping 命令就是利用这个消息实现的。
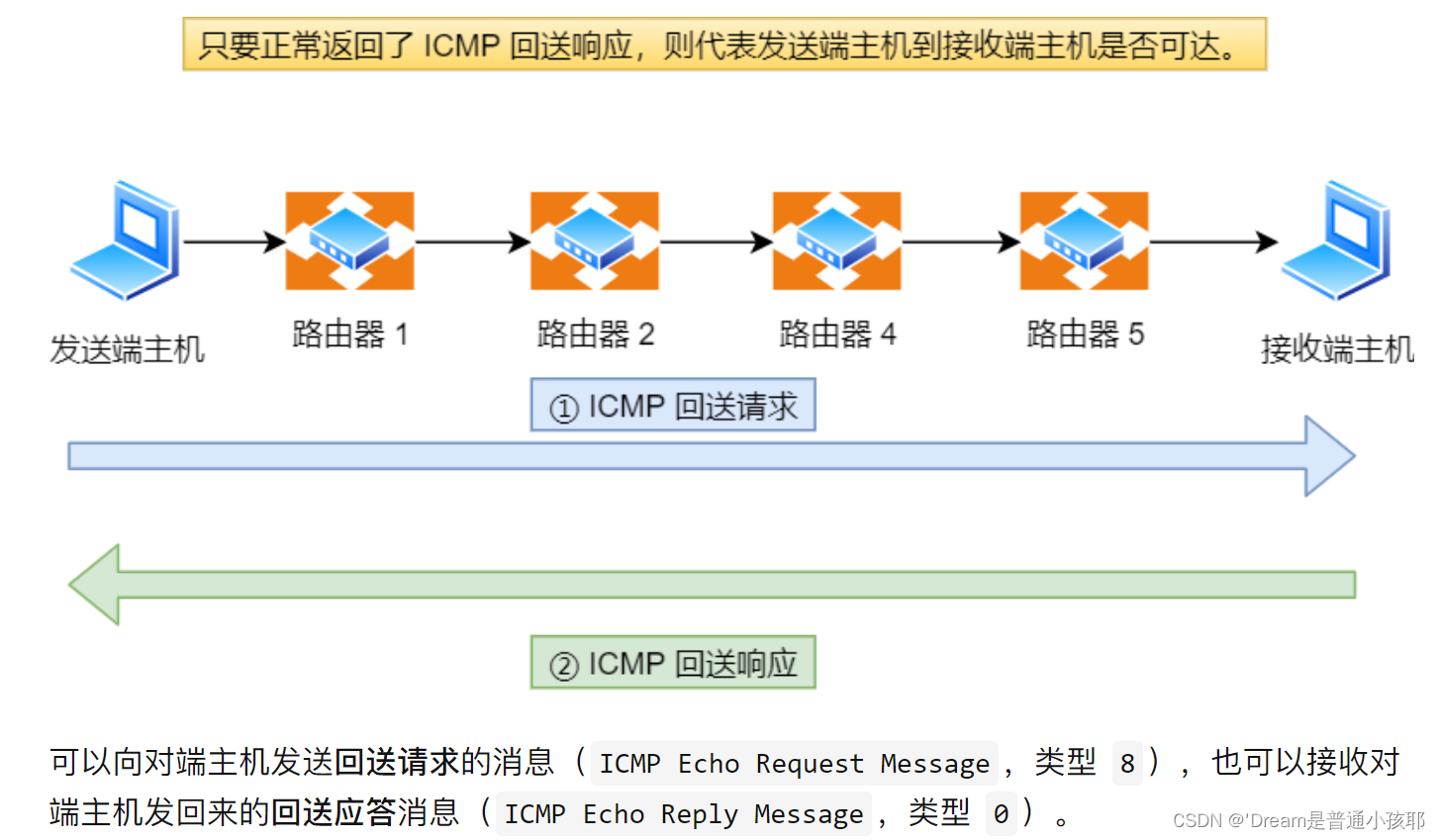
-
其他差错类型参考ping的工作原理
49. hashmap和hashset的区别
参考:HashMap和HashSet的区别
1)HashMap和HashSet都是collection框架的一部分,它们让我们能够使用对象的集合。collection框架有自己的接口和实现,主要分为Set接口,List接口和Queue接口。它们有各自的特点,Set的集合里不允许对象有重复的值;List允许有重复,它对集合中的对象进行索引;Queue的工作原理是FCFS算法(First Come, First Serve)。
2)HashSet:
HashSet实现了Set接口,它不允许集合中有重复的值,允许有null值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。
public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。
3)HashMap:
① HashMap实现了Map接口,Map接口对键值对进行映射。
② Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。
③ TreeMap保存了对象的排列次序,而HashMap则不能。
④ HashMap允许键和值为null。
⑤ HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。
⑥ public Object put(Object Key,Object value)方法用来将元素添加到map中。
4)HashMap和HashSet的区别

50. treemap和hashmap的区别
参考:treemap和hashmap的区别01
treemap和hashmap的区别02
1)内部实现
① HashMap:是基于哈希表来实现的,通过使用键的hashcode()和equals()来确定键值对的存储位置;为了优化HashMap的空间使用,可以调优初始容量和负载因子
② TreeMap:基于红黑树(一种自平衡的搜索二叉树)实现的,它根据键的自然顺序或者Comparator来组织键值对;TreeMap没有调优选项,因为红黑树总是处于平衡的状态
2)元素排序
① HashMap中元素是没有特定排序的,会随着键值对的添加和删除而变化;HashMap是通过hashcode()对其内容进行快速查找的
② TreeMap中的所有元素都是有某一固定的顺序的,TreeMap会根据键的自然顺序或者Comparator来对元素进行排序
3)线程安全
HashMap和TreeMap都不是线程安全的,如果在多线程环境中使用,需要使用者自行保证线程安全
4)父类
① HashMap继承自AbstractMap类;覆盖了hashcode() 和equals() 方法,以确保两个相等的映射返回相同的哈希值
② TreeMap继承自SortedMap类;保持键的有序顺序
5)键值对的存储限制
① HashMap允许使用null作为键和值
② TreeMap不允许使用null作为键,但允许使用null作为值
6)性能
① HashMap的插入、查找、删除操作的平均时间复杂度为O(1),对于需要频繁插入、查找、删除操作的场景,HashMap通常会有更好的性能。
② TreeMap的插入、删除、查找的平均时间复杂度为O(logn),适用于按自然顺序或自定义顺序遍历键key
51. 哪些是线程安全的
1)线程不安全
HashMap、HashSet、TreeMap、TreeSet、ArrayList、LinkedList
① HashMap:HashMap在put操作的时候,如果插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是resize,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
② ArrayList: List 对象在做 add 时,执行 Arrays.copyOf 的时候,返回一个新的数组对象。当有线程 A、B… 同时进入 grow方法,多个线程都会执行 Arrays.copyOf 方法,返回多个不同的 elementData 对象,假如,A先返回,B 后返回,那么 List.elementData ==A. elementData,如果同时B也返回,那么 List.elementData ==B. elementData,所以线程B就把线程A的数据给覆盖了,导致线程A的数据被丢失。
③ LinkedList:与Arraylist线程安全问题相似,线程安全问题是由多个线程同时写或同时读写同一个资源造成的。
④ HashSet:底层数据存储结构采用了Hashmap,所以Hashmap会产生的线程安全问题HashSet也会产生。
2)线程安全
① Vector:
Vector 是 Java 中最早的一个集合类,它使用 synchronized 关键字来实现线程安全。即使是在多线程环境下,多个线程操作同一个 Vector 实例时也可以保证线程安全。虽然 Vector 在多线程环境中有很好的线程安全性,但它的性能比较低,建议在单线程环境中使用。
② HashTable:
Hashtable 是 Java 中最早的一个键值对映射容器,也是使用 synchronized 关键字来实现线程安全的。它的每个 put、remove 和 get 操作都是原子性的,因此它能够保证对于多个线程同时访问 Hashtable 的情况下,没有线程会看到错误的值。
③ ConcurrentHashMap:
ConcurrentHashMap 是 Java 并发包中提供的一个线程安全的哈希表实现,它会将整个表分为多个段(Segment),每个段都是一个独立的哈希表,每个线程只能访问特定的段,从而实现了并发访问时的线程安全。(锁分段技术)
④ CopyOnWriteList:
CopyOnWriteArrayList 是 Java 并发包中提供的一个线程安全的 List 实现,它通过复制原有的 List 来实现并发访问的线程安全。每次对 CopyOnWriteArrayList 进行修改时都会创建一个新的数组,因此它的写操作性能比较低,但它的读操作性能非常高。
⑤ ConcurrentLinkedQueue:
ConcurrentLinkedQueue 是 Java 并发包中提供的一个线程安全的队列实现,它使用链表来存储元素,从而实现了高效的并发性能。和 CopyOnWriteArrayList 一样,它的读操作是非常高效的。
⑥ Stack:
栈也是线程安全的,继承于Vector。
52. 方法重载和方法重写的区别
① 方法的重写(Overriding)和重载(Overloading)是java多态性的不同表现,重写是父类与子类之间多态性的一种表现,重载可以理解成多态的具体表现形式。
② 构造方法可以进行重载,但不能被重写
1)方法重写/覆盖Overriding
① 参数列表必须一致:参数类型 & 顺序 & 个数
② 返回类型可以相同,也可以不同,不同则必须是原来返回类型的子类型(可隐式转换即可)
③ 方法名一致
④ 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
⑤ 重写的方法能够抛出任何非强制异常(运行时异常),无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
⑥ 构造方法不能被重写
⑦ 声明为final的方法不能被重写。
⑧ 声明为static的方法不能被重写,但是能够被再次声明。
⑨ 父类的成员方法只能被子类重写
2)方法重载Overloading
① 参数列表必须不一致:参数类型 or 个数 or 顺序
② 方法名必须一致
③ 返回值类型无要求
④ 访问修饰符无要求
⑤ 被重载的方法可以声明新的或更广的检查异常
⑥ 方法能够在同一个类中或者在一个子类中被重载
⑦ 不能通过访问权限、返回类型、抛出的异常进行重载,即不可以作为重载函数的区分标准
⑧ 构造方法可以被重载
Ps. 强制性异常/检查异常/编译时异常:具体参考强制异常和非强制异常
53. 常见错误码以及问题原因,出现在哪里,如何排查
-
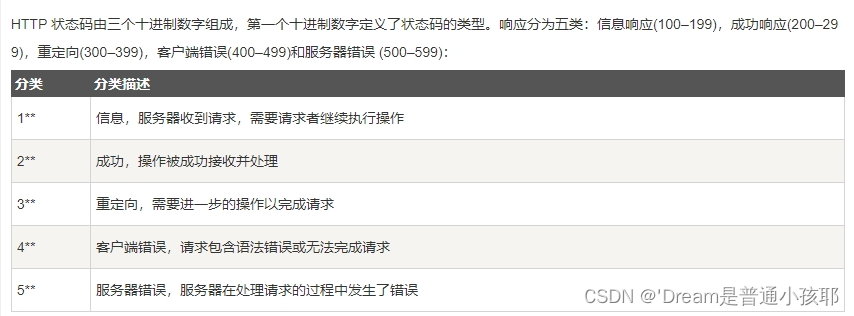
HTTP状态码
http状态码是用来表示web服务器响应http请求状态的的数字代码。每当web客户端向服务器发送一个http请求时,web服务器都会返回一个状态响应代码。这个状态码是一个3位数字代码,作用是告知web客户端此次的请求是否成功,或是采取其他的动作方式。 -
状态码范围及含义
1) 100-199
指定客户端相应的某些动作
2) 200-299
表示请求成功
3) 300-399
已经移动的文件且被包含在定位透信息中指定的新的地址信息
4)400-499
指出客户端的错误
5) 500-599
指出服务器的错误
-
常见状态码及解决方案
1)401:unauthorized
原因:您的web服务器开启了密码验证,客户端在请求的时候需要填入用户名和密码,只有输入正确的用户名和密码才能正常访问。
解决:输入正确的用户名和密码;关闭web服务器的密码验证功能
2)403:forbidden
原因:禁止访问,请求是合法的,但是却因为服务器配置规则而拒绝响应客户端请求,此类问题一般为服务器或服务权限配置不当导致。
解决:确保主页文件存在,如index.php或index.html;确保web服务器运行用户和站点的目录权限一致,比如你的nginx运行用户为www,你需要确保你的站点目录的所有者为www。
3)404:not found
原因:服务器找不到客户端请求的指定页面,可能是请求了一个服务器上不存在的资源导致的,也有可能是服务器上的该文件被删除。
解决:确保输入的是正确的url;确保你请求的文件在服务器上是真实存在的;如果你的云服务器配置了数据盘,且站点目录在数据盘中,这时候你需要检查数据盘是否被正确挂载或者是否到期被释放掉了。
4)500: internal server error
原因:内部服务器错误,服务器遇到了意料不到的错误,不能完成客户的请求。一般为服务器的配置或内部程序的问题
解决:此时可能是服务器资源占用过高,你需要查看一下服务器占用率,必要时清理内存或者重启服务器;文件权限问题,确保你的服务器程序文件权限为755;检查基础服务是否运行,如果您用的是LNMP架构,则需要检查php-fpm和mysql是否正常运行。
5)502: bad gateway
原因:坏的网关,一般是服务器作为代理服务器请求后端的服务器时,后端的服务不可用或没有完成响应给网关服务器,一般为反向代理服务器后端的服务器节点出现故障。
解决:检查代理服务器后端的服务器是否正常运行,以及后端服务器上的服务是否正常运行。
6)503: service unavailable
原因:服务当前不可用,可能是因为服务器超载或停机维护导致,或者是反向代理服务器后面没有可以提供服务的节点。
解决:服务器供应商可能正在维护或者暂停服务,你可以联系一下服务器供应商;还有可能就是服务器的cpu或内存占用过高,需要清理一下资源,必要时重启服务器。
7)504: gateway timeout
原因:网关超时,一般是网关代理服务器请求后端服务器或者cdn请求源站服务器时,服务器没有在特定的时间处理并相应请求,一般为服务器过载,没有在指定时间返回服数据。
解决:对服务器性能参数进行相关调整,包括php参数调整,数据库参数调整,web服务器参数调整;必要时可以选择升级服务器配置。
Ps.cdn相关参考:CDN基础知识 -
补充状态码
1)402:Payment Required
保留,将来使用
2)301:Moved Permanently
永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
3)302:Found。
临时移动。与301类似,但资源只是临时被移动。客户端应继续使用原有URI
4) 400: bad request
客户端请求语法错误,服务器无法理解
5) 303:see other
查看其它地址。与301类似,使用GET和POST请求查看
54. 哈希冲突的避免和解决方法
https://zhuanlan.zhihu.com/p/346079114#:~:text=%E8%A7%A3%E5%86%B3hash%E5%86%B2%E7%AA%81%E7%9A%84%E4%B8%89%E4%B8%AA%E6%96%B9%E6%B3%95%201%20%E4%BC%AA%E9%9A%8F%E6%9C%BA%E6%8E%A2%E6%B5%8B%E5%86%8D%E6%95%A3%E5%88%97%20di%3D%E4%BC%AA%E9%9A%8F%E6%9C%BA%E6%95%B0%E5%BA%8F%E5%88%97%E3%80%82%20…%202%20%E5%86%8D%E5%93%88%E5%B8%8C%E6%B3%95%20%E8%BF%99%E7%A7%8D%E6%96%B9%E6%B3%95%E6%98%AF%E5%90%8C%E6%97%B6%E6%9E%84%E9%80%A0%E5%A4%9A%E4%B8%AA%E4%B8%8D%E5%90%8C%E7%9A%84%E5%93%88%E5%B8%8C%E5%87%BD%E6%95%B0%EF%BC%9A,%E7%BC%BA%E7%82%B9%EF%BC%9A%20%E2%91%A0%E5%AD%98%E5%82%A8%E7%9A%84%E8%AE%B0%E5%BD%95%E6%98%AF%E9%9A%8F%E6%9C%BA%E5%88%86%E5%B8%83%E5%9C%A8%E5%86%85%E5%AD%98%E4%B8%AD%E7%9A%84%EF%BC%8C%E8%BF%99%E6%A0%B7%E5%9C%A8%E6%9F%A5%E8%AF%A2%E8%AE%B0%E5%BD%95%E6%97%B6%EF%BC%8C%E7%9B%B8%E6%AF%94%E7%BB%93%E6%9E%84%E7%B4%A7%E5%87%91%E7%9A%84%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%EF%BC%88%E6%AF%94%E5%A6%82%E6%95%B0%E7%BB%84%EF%BC%89%EF%BC%8C%E5%93%88%E5%B8%8C%E8%A1%A8%E7%9A%84%E8%B7%B3%E8%BD%AC%E8%AE%BF%E9%97%AE%E4%BC%9A%E5%B8%A6%E6%9D%A5%E9%A2%9D%E5%A4%96%E7%9A%84%E6%97%B6%E9%97%B4%E5%BC%80%E9%94%80%20…%208%20%E5%B0%81%E9%97%AD%E6%95%A3%E5%88%97%EF%BC%88closed%20hashing%EF%BC%89%2F%20%E5%BC%80%E6%94%BE%E5%AE%9A%E5%9D%80%E6%B3%95%20%E6%9B%B4%E5%A4%9A%E9%A1%B9%E7%9B%AE
https://blog.csdn.net/qq_48241564/article/details/118613312
https://blog.csdn.net/qq_41963107/article/details/107849048
55. HTTP变为HTTPS后用例如何修改
1)功能测试/界面测试
① 确保模块能够正确地重定向到HTTPS端口。
② 保证通过HTTPS访问模块时,是否能够正常加载和展示页面内容。
③ 检查模块的各种功能和业务逻辑是否能够正常工作。
2) 安全性测试
① 验证HTTPS证书的有效性和合法性。
② 模块进行漏洞扫描,确保没有安全漏洞和潜在的安全风险。
③ 测试敏感数据的加密传输,确保数据在传输过程中不被窃取或篡改。
3)兼容性测试
① 测试不同浏览器和操作系统是否能够正常支持HTTPS连接。
② 验证模块在各种设备上的显示效果和功能是否正常。
③ 验证浏览器和设备的不同版本功能和显示是否正常。
4)用户体验测试
① 邀请用户通过HTTPS访问模块,收集用户反馈,确保用户体验不受影响。
② 测试用户在进行表单提交、登录等操作时的流程是否顺畅。
5)性能测试
① 对模块进行压力测试,以测试在高负载情况下的性能表现。
② 对比HTTP和HTTPS的响应时间和性能指标,确保HTTPS不会对系统性能造成负面影响。
6)测试环境和数据清理
① 在测试环境中模拟各种情况下的测试场景,例如正常访问、异常访问、暴力破解等。
② 在测试过程中要保证测试数据的完整性和安全性,不要将敏感数据泄露给未授权人员。
③ 在测试结束后,要及时清理测试数据和记录,以保护用户隐私和企业数据安全。
56. 抓包工具的使用
https://zhuanlan.zhihu.com/p/631821119
https://blog.csdn.net/HarveyH/article/details/113731485
(小鲨鱼)
https://blog.csdn.net/Mubei1314/article/details/122389950(fidler)
57. 测试人员排查定位bug
参考:测试排查定位bug
-
定位技巧
用户层面问题 -> Web页面/软件界面 -> 中间件 -> 后端服务 -> 代码 -> 数据库
① 用户层:用户自己环境或操作问题
②Web页面:这类问题一般通过观察以及利用一些常识可以发现,比如样式问题一般是css的问题,交互问题一般是js的问题,文本问题一般是html的问题(当然有可能是其他问题,例如js生成html)
③ 中间件:如缓存服务器等
④ 后端服务:如果发现内存溢出,那么就可能会定位到是tomcat配置的问题;如果请求返回404,也可能是nginx配置不当。
Ps.nginx参考:nginx代理服务器了解
⑤ 数据库:如字段约束问题,假如一个文本框的前端校验和接口校验的文本长度最大是50,但数据表字段设定的是varchar(30),那么在存数据的时候肯定会报错。 -
定位板斧
1)问题复现,保留现场。
有一类问题就是脏数据,我们有时候会遇到服务端报500错误,查看日志后,报空指针,那么很有可能就是数据库中关联表的数据被人为删掉导致的。
2)查看状态码。
① 4xx状态码一般表示是客户端问题(当然也有可能是服务器端配置问题),比如发生了401,那么要看下是否带了正确的身份验证信息;发生了403则要看下是否有权限访问;404则要看下对应的URL是否真实存在。
②5xx一般表示服务端问题。比如发生了500错误,则表明是服务器内部错误,这个时候要配合服务器log进行定位;发生了502则可能是服务器挂了导致的;发生503可能是由于网络过载导致的;发生504则可能是程序执行时间过长导致超时。
3)查看服务器日志。
如果发生5xx问题,或者检查后端接口执行的sql是否正确,我们最常见的排查方法就是去看服务器日志比如tomcat日志,开发人员一般会打出关键信息和报错信息,从而找到问题所在。测试人员要养成看日志的习惯。并且,如果将来进行开发,也要养成打日志的习惯,否则发现问题真不知道到哪哭去。
4)接口请求和返回以及js执行。
① 如果js执行报错,那就是前端的问题,比如跨域问题。
② 请求URL不正确,是前端bug,传参不正确,是前端bug,响应内容不正确,则是后端bug。如果是响应内容response不正确的后端问题,那就要继续深挖,是接口吐数据的时候出错了,还是数据库中的数据就错了,还是缓存中的数据错了(如果用到了缓存的话)。
③ 经常见到后端开发人员有的负责接口,有的负责写入数据库,有的负责维护缓存,所以如果发现是后端的问题,可以更进一步确认下是哪块的问题。
5)看需求文档。
有时候,前端和服务端的交互都正确,但是从测试的角度看不合理。这个时候,我们应该翻翻需求文档(如果没有的话,就直接抛出这个问题)。如果和需求文档不符,那么就要看下谁改合理,是前端改,还是服务端改,或者两者都得改。这里有一个原则,就是前端尽可能少地去承担逻辑,只负责渲染展现。当然,不要以为需求文档就全部正确,它也可能会有错误,我们也应该去发现需求文档的bug,然后再去协调PM,敦促FE或者RD进行修改。
6)合并代码冲突。
常见的可能还有构建的问题,比如代码本身都没错,但是合并代码到主干后出问题了,常见的就是代码存在冲突时手动解决的时候。可以咨询开发合并代码的时候是否有冲突,时什么地方存在冲突。
7)注意点:
在发现问题或者定位到问题原因后,一定要进行一步,就是再次确认问题。所谓确认问题,就是弄清楚问题是否每次都发生,还是概率事件,或者是工具相关的问题(比如换个浏览器是否依然出现?如果换个浏览器不出现的话,很可能就是前端的兼容性问题)。比如翻页控件,我们待测的系统有很多页面都有翻页控件,那么就要看下是否每个页面都会出现这个问题,进而报bug时进行统一说明,也更加方便开发人员批量处理,防止漏改。 -
案例解析
修改某个表单中文本框内的文字并提交,跳转到结果列表页后发现该文本内容显示不全,该如何排查?
这个问题的可能性有很多,我们可能需要这样排查:首先查看下表单提交时,前端发送的请求中该文本内容是否正确,如果正确就再去数据库中查看记录,然后去看后端响应内容是否正确,然后去看前端渲染是否正确,以此来判断是前后端交互的哪个环节出了问题。
58. TCP长连接和短连接的区别
区别:简而言之就是长连接是建立一次连接之后可以多次进行数据的传输,直到一方关闭,并且TCP还有保活功能;短连接是每次发送数据都需要去建立连接。
-
概念
1)长连接:指在一个连接上可以发送多个数据包,在连接保持期间,如果没有数据包发送,需要双方发链路检测包。(心跳机制,默认2h)
2)短连接:是相对于长连接而言的概念,指的是在数据传送过程中,只在需要发送数据时才去建立一个连接,数据发送完成后断开此连接,即每次连接只完成一项业务的发送。
3)通俗理解:
① 长连接:连接->传输数据->保持连接 ->传输数据->…->直到一方关闭连接。长连接指建立SOCKET连接后无论使用与否都要保持连接。
② 短连接:连接->传输数据->关闭连接。下次需要传输数据需要再次连接。 -
应用场景
1)长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。每个TCP连接都需要三次握手,这会花费一定的时间以及资源。
如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
2)并发量大,但每个用户无需频繁操作情况下用短连好。
如:像WEB网站的http服务一般都用短链接,如果使用长连接就意味着成千上万甚至过亿的用户会各自占用一个连接。 -
优势
1)TCP短连接
在TCP三次握手建立连接后,client向server发送消息,server回应client,然后一次读写就完成了,此时任何一方都可以发起close操作,不过一般是client首先发起close操作。
优点:管理起来方便,存在的连接都是有效的连接,不需要额外的控制手段。
2)TCP长连接
在TCP三次握手建立连接后,client向server发送消息,server回应client,然后一次读写就完成了,此时它们之间的连接不会关闭而是保持,后续的读写操作都会使用该连接。(TCP的保活功能) -
TCP保活
1)TCP的保活功能主要为服务器应用提供。如果客户端已经消失而连接未断开,则会使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,此时服务器将永远等待客户端的数据。保活功能就是试图在服务端器端检测到这种半开放的连接。(也就是说服务器需要检测到客户端是否还处于连接状态,双方是否可以再通信)
2)如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于以下4个状态之一:
①客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保证定时器复位。
②客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
③客户主机崩溃并已经重新启动。服务器将收到一个对其保证探测的响应,这个响应是一个复位,使得服务器终止这个连接。
④ 客户机正常运行,但是服务器不可达,这种情况与②类似,TCP能发现的就是没有收到探查的响应。
3)在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损。如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数 -
HTTP与TCP/IP
1)HTTP协议的长连接和短连接,本质上是TCP协议的长连接和短连接。
① HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议。 IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠地传递数据包,使得网络上接收端收到发送端所发出的所有包,并且接受顺序与发送顺序一致。TCP协议是可靠的、面向连接的。TCP才负责连接,只有负责传输的这一层才需要建立连接!!
②在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
③从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码(但要服务器和客户端都设置):Connection:keep-alive
④在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的TCP连接。也就是说在长连接情况下,多个HTTP请求可以复用同一个TCP连接,这就节省了很多TCP连接建立和断开的消耗
⑤Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接
2)HTTP协议是无状态的。
HTTP协议是无状态的,指的是HTTP协议对事务处理没有记忆能力,服务器不知道客户端是什么状态。即第一次和第二次发起对应的请求之间没有任何联系。 -
长轮询与短轮询
1)了解
① 以电商中的库存量为例,短轮询就是一直不停地请求服务器获取数据并实时更新,而长轮询则是服务器若检测不到数据变化时会将当前请求挂起一段时间(超时时间),在该时间里若检测到变化就立即返回,否则就一直等到超时为止。
② 对于客户端来说,不管是长轮询还是短轮询,客户端的动作都是一样的,就是不停的去请求,不同的是服务端,短轮询情况下服务端每次请求不管有没有变化都会立即返回结果,而长轮询情况下,如果有变化才会立即返回结果,而没有变化的话,则不会再立即给客户端返回结果,直到超时为止。
③ 不管是长轮询还是短轮询,都不太适用于客户端数量太多的情况,因为每个服务器所能承载的TCP连接数是有上限的,这种轮询很容易把连接数顶满。
④ 短轮询:浪费服务器和客户端的资源,但是数据是实时更新的; 长轮询:客户端的请求次数大大减少(节省了网络流量),但是请求挂起的操作同样也会导致资源的浪费
2)长短轮询和长短连接的区别
① 决定方式:一个TCP连接是否为长连接,是通过设置HTTP的Connection Header来决定的,而且是需要两边(服务器端与应用端)都设置才有效。而一种轮询方式是否为长轮询,是根据服务端的处理方式来决定的,与客户端没有关系。
② 实现方式:连接的长短是通过协议来规定和实现的。而轮询的长短,是服务器通过编程的方式手动挂起请求来实现的。
59. jmeter获取上一个接口返回参数的方法
https://www.cnblogs.com/xiaocaicai-cc/p/14780574.html (有正则表达式介绍)
https://blog.csdn.net/qq_22219911/article/details/102621008 (正则表达式or后置处理器)
60. 接口自动化测试
https://zhuanlan.zhihu.com/p/646052949
61. Spring中Bean的生命周期
参考:突击:Spring中Bean的生命周期、Spring生命周期七过程
62. String、StringBuffer和StringBuilder的区别
参考:String、StringBuffer和StringBuilder的区别
1)String
① String声明为final的,即不可以被继承
② String实现了Serializable接口,说明字符串支持可序列化;实现了Comparable接口,说明可以比较大小
③ String 不可变性体现在:当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的 value 进行赋值。当对现有字符串进行连接操作时,需要重新赋值,不能在原有基础上赋值
④ 通过字面量给一个字符串赋值,此时的字符串值声明在字符串常量池中
2)StringBuffer和StringBuilder
① 和 String 类不同,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象
② StringBuffer 每次获取 toString 都会直接使用缓存区的 toStringCache 值来构造一个字符串; StringBuilder 则每次都需要复制一次字符数组,再构造一个字符串
③ StringBuffer 是线程安全的,它的所有公开方法都是同步的;StringBuilder 没有对方法加锁同步,所以StringBuilder 的性能要远好于 StringBuffer

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











