






目录
下载internlm2_5-chat-1_8b并打印示例输出
先来做任务:
任务一 InternLM模型下载
在正式下载之前,我们先要介绍一下HF的Transformers库,作为HF最核心的项目,它可以:
- 直接使用预训练模型进行推理
- 提供了大量预训练模型可供使用
- 使用预训练模型进行迁移学习 因此在使用HF前,我们需要下载Transformers等一些常用依赖库
以internlm2_5-1_8b举例,查看Hugging Face上该模型的地址:
https://huggingface.co/internlm/internlm2_5-1_8b
GitHub CodeSpace的使用
https://github.com/codespaces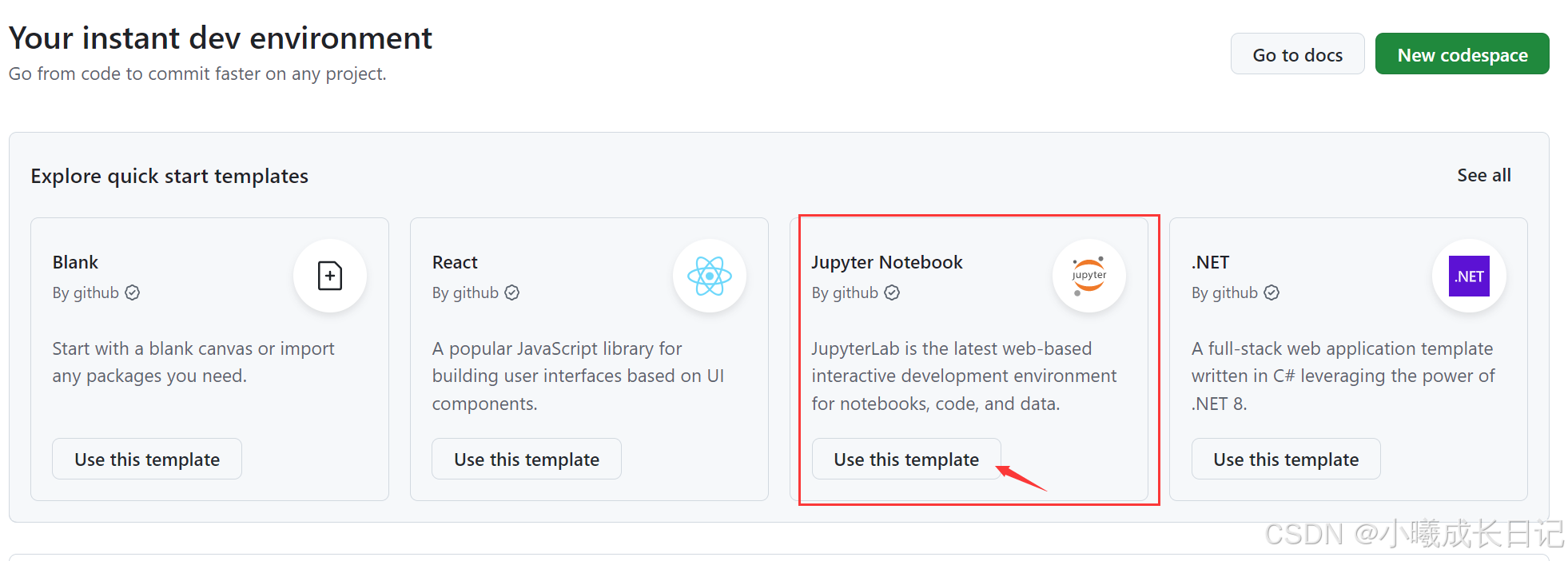
选择使用JN:
下载internlm2_5-7b-chat的配置文件
接着,在界面下方的终端(terminal)安装以下依赖,便于模型运行。
在终端运行以下命令进行相关模块的安装:
# 安装transformers
pip install transformers==4.38
pip install sentencepiece==0.1.99
pip install einops==0.8.0
pip install protobuf==5.27.2
pip install accelerate==0.33.0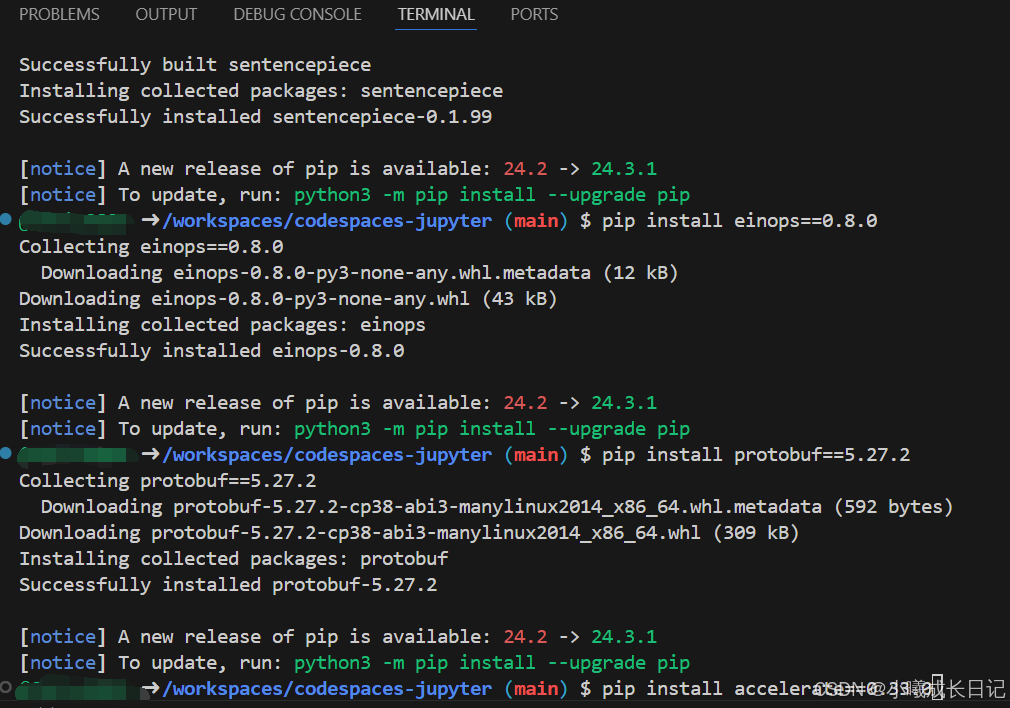
这里为方便演示直接在工作区创建文件,即 /workspaces/codespaces-jupyter 目录,以下载模型的配置文件为例,先新建一个hf_download_josn.py 文件
touch hf_download_josn.py在上述新建文件中添加下面的代码,并运行。
import os
from huggingface_hub import hf_hub_download
# 指定模型标识符
repo_id = "internlm/internlm2_5-7b"
# 指定要下载的文件列表
files_to_download = [
{"filename": "config.json"},
{"filename": "model.safetensors.index.json"}
]
# 创建一个目录来存放下载的文件
local_dir = f"{repo_id.split('/')[1]}"
os.makedirs(local_dir, exist_ok=True)
# 遍历文件列表并下载每个文件
for file_info in files_to_download:
file_path = hf_hub_download(
repo_id=repo_id,
filename=file_info["filename"],
local_dir=local_dir
)
print(f"{file_info['filename']} file downloaded to: {file_path}")python hf_download_josn.py可见,已经从Hugging Face上下载了相应配置文件:
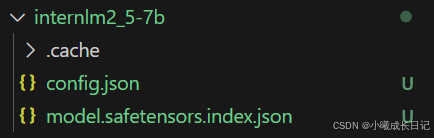
下载internlm2_5-chat-1_8b并打印示例输出
使用touch命令新建一个hf_download_1_8_demo.py文件,在里面粘贴如下内容并运行:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2_5-1_8b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("internlm/internlm2_5-1_8b", torch_dtype=torch.float16, trust_remote_code=True)
model = model.eval()
inputs = tokenizer(["A beautiful flower"], return_tensors="pt")
gen_kwargs = {
"max_length": 128,
"top_p": 0.8,
"temperature": 0.8,
"do_sample": True,
"repetition_penalty": 1.0
}
# 以下内容可选,如果解除注释等待一段时间后可以看到模型输出
# output = model.generate(**inputs, **gen_kwargs)
# output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
# print(output)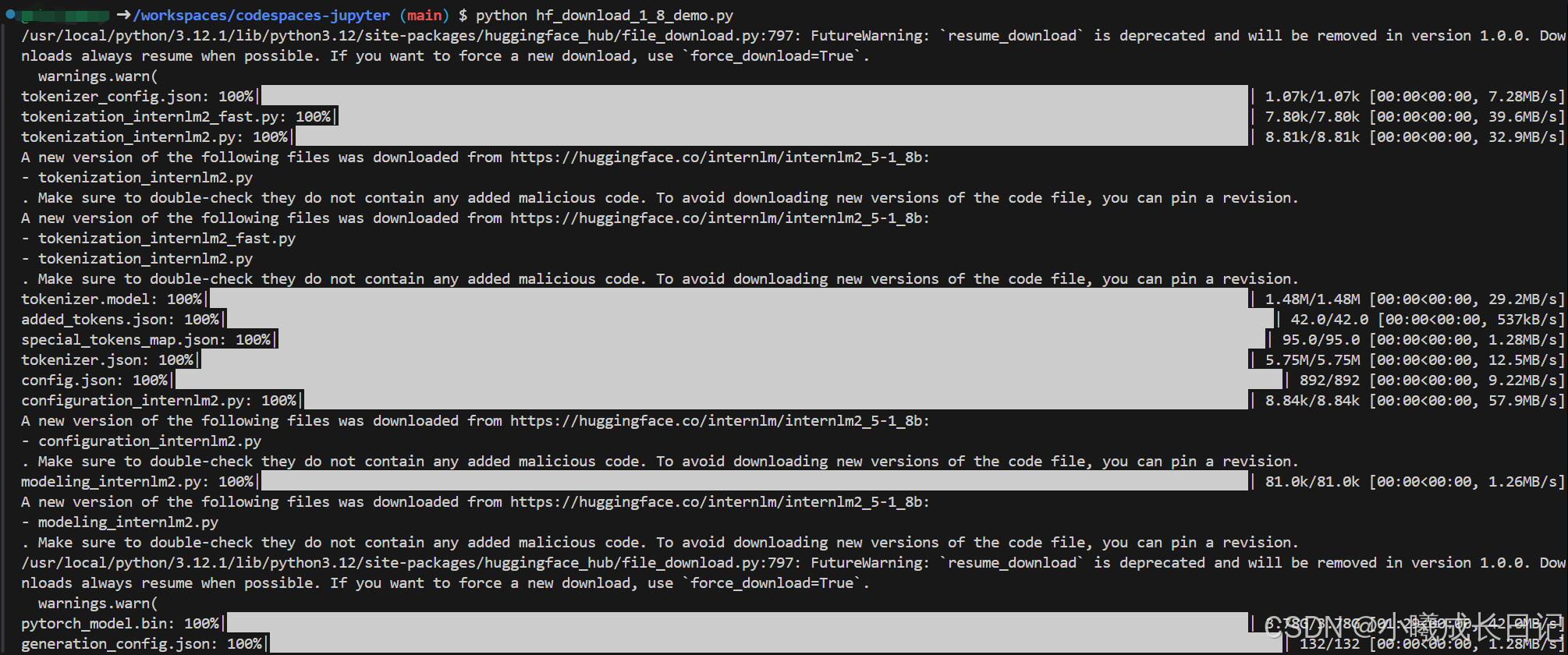
运行后得到以下生成的文本:

任务二——模型上传【选做-待更新】
欢迎大伙儿留言交流


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









